linux 之dma_buf (8)- ION简化版本
一、前言
我们学习了如何使用 alloc_page() 方式来分配内存,但是该驱动只能分配1个PAGE_SIZE。本篇我们将在上一篇的基础上,实现一个简化版的ION驱动,以此来实现任意 size 大小的内存分配。
二、准备
为了和 kernel 标准 ion 驱动兼容,本篇引用了 driver/staging/android/uapi/ion.h 头文件,目的是为了方便 userspace 直接使用 struct ion_allocation_data 和 ION_IOC_ALLOC 宏:
struct ion_allocation_data {__u64 len;__u32 heap_id_mask;__u32 flags;__u32 fd;__u32 unused; };#define ION_IOC_MAGIC 'I' #define ION_IOC_ALLOC _IOWR(ION_IOC_MAGIC, 0, \struct ion_allocation_data)
本篇 ion 驱动只使用 ion_allocation_data 结构体中的 len 和 fd 这两个元素,其它元素不做处理。
三、示例
exporter-ion.c
#include <linux/dma-buf.h>
#include <linux/highmem.h>
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/miscdevice.h>struct ion_allocation_data {__u64 len;__u32 heap_id_mask;__u32 flags;__u32 fd;__u32 unused;
};#define ION_IOC_MAGIC 'I'
#define ION_IOC_ALLOC _IOWR(ION_IOC_MAGIC, 0, \struct ion_allocation_data)struct ion_data {int npages;struct page *pages[];
};static int ion_attach(struct dma_buf *dmabuf, struct device *dev,struct dma_buf_attachment *attachment)
{pr_info("dmabuf attach device: %s\n", dev_name(dev));return 0;
}static void ion_detach(struct dma_buf *dmabuf, struct dma_buf_attachment *attachment)
{pr_info("dmabuf detach device: %s\n", dev_name(attachment->dev));
}static struct sg_table *ion_map_dma_buf(struct dma_buf_attachment *attachment,enum dma_data_direction dir)
{struct ion_data *data = attachment->dmabuf->priv;struct sg_table *table;struct scatterlist *sg;int i;table = kmalloc(sizeof(*table), GFP_KERNEL);sg_alloc_table(table, data->npages, GFP_KERNEL);sg = table->sgl;for (i = 0; i < data->npages; i++) {sg_set_page(sg, data->pages[i], PAGE_SIZE, 0);sg = sg_next(sg);}dma_map_sg(NULL, table->sgl, table->nents, dir);return table;
}static void ion_unmap_dma_buf(struct dma_buf_attachment *attachment,struct sg_table *table,enum dma_data_direction dir)
{dma_unmap_sg(NULL, table->sgl, table->nents, dir);sg_free_table(table);kfree(table);
}static void ion_release(struct dma_buf *dma_buf)
{struct ion_data *data = dma_buf->priv;int i;pr_info("dmabuf release\n");for (i = 0; i < data->npages; i++)put_page(data->pages[i]);kfree(data);
}
static void *ion_vmap(struct dma_buf *dma_buf)
{struct ion_data *data = dma_buf->priv;return vm_map_ram(data->pages, data->npages, 0, PAGE_KERNEL);
}static void ion_vunmap(struct dma_buf *dma_buf, void *vaddr)
{struct ion_data *data = dma_buf->priv;vm_unmap_ram(vaddr, data->npages);
}static int ion_mmap(struct dma_buf *dma_buf, struct vm_area_struct *vma)
{struct ion_data *data = dma_buf->priv;unsigned long vm_start = vma->vm_start;int i;for (i = 0; i < data->npages; i++) {remap_pfn_range(vma, vm_start, page_to_pfn(data->pages[i]),PAGE_SIZE, vma->vm_page_prot);vm_start += PAGE_SIZE;}return 0;
}static int ion_begin_cpu_access(struct dma_buf *dmabuf,enum dma_data_direction dir)
{struct dma_buf_attachment *attachment;struct sg_table *table;attachment = list_first_entry(&dmabuf->attachments, struct dma_buf_attachment, node);table = attachment->sgt;dma_sync_sg_for_cpu(NULL, table->sgl, table->nents, dir);return 0;
}static int ion_end_cpu_access(struct dma_buf *dmabuf,enum dma_data_direction dir)
{struct dma_buf_attachment *attachment;struct sg_table *table;attachment = list_first_entry(&dmabuf->attachments, struct dma_buf_attachment, node);table = attachment->sgt;dma_sync_sg_for_device(NULL, table->sgl, table->nents, dir);return 0;
}static const struct dma_buf_ops exp_dmabuf_ops = {.attach = ion_attach,.detach = ion_detach,.map_dma_buf = ion_map_dma_buf,.unmap_dma_buf = ion_unmap_dma_buf,.release = ion_release,.mmap = ion_mmap,.vmap = ion_vmap,.vunmap = ion_vunmap,.begin_cpu_access = ion_begin_cpu_access,.end_cpu_access = ion_end_cpu_access,
};
static struct dma_buf *ion_alloc(size_t size)
{DEFINE_DMA_BUF_EXPORT_INFO(exp_info);struct dma_buf *dmabuf;struct ion_data *data;int i, npages;npages = PAGE_ALIGN(size) / PAGE_SIZE;data = kmalloc(sizeof(*data) + npages * sizeof(struct page *),GFP_KERNEL);data->npages = npages;for (i = 0; i < npages; i++)data->pages[i] = alloc_page(GFP_KERNEL);exp_info.ops = &exp_dmabuf_ops;exp_info.size = npages * PAGE_SIZE;exp_info.flags = O_CLOEXEC;exp_info.priv = data;dmabuf = dma_buf_export(&exp_info);return dmabuf;
}static long ion_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{struct dma_buf *dmabuf;struct ion_allocation_data alloc_data;/* currently just only support ION_IOC_ALLOC ioctl */if (cmd != ION_IOC_ALLOC)return -EINVAL;copy_from_user(&alloc_data, (void __user *)arg, sizeof(alloc_data));dmabuf = ion_alloc(alloc_data.len);alloc_data.fd = dma_buf_fd(dmabuf, O_CLOEXEC);copy_to_user((void __user *)arg, &alloc_data, sizeof(alloc_data));return 0;
}static struct file_operations ion_fops = {.owner = THIS_MODULE,.unlocked_ioctl = ion_ioctl,
};static struct miscdevice mdev = {.minor = MISC_DYNAMIC_MINOR,.name = "ion",.fops = &ion_fops,
};static int __init ion_init(void)
{return misc_register(&mdev);
}static void __exit ion_exit(void)
{misc_deregister(&mdev);
}module_init(ion_init);
module_exit(ion_exit);从上面可以看出,任意大小的参数,在驱动中就是for循环申请页。因为申请的内存不一定时连续物理内存,所以使用sg table .
应用程序
ion_test.c
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/ioctl.h>struct ion_allocation_data {__u64 len;__u32 heap_id_mask;__u32 flags;__u32 fd;__u32 unused;
};#define PAGE_SIZE 4096int main(int argc, char *argv[])
{int fd;struct ion_allocation_data alloc_data;fd = open("/dev/ion", O_RDWR);alloc_data.len = 3 * PAGE_SIZE;ioctl(fd, ION_IOC_ALLOC, &alloc_data);printf("ion alloc success: size = %llu, dmabuf_fd = %u\n",alloc_data.len, alloc_data.fd);close(fd);return 0;
}
该应用程序通过 ION_IOC_ALLOC ioctl 请求分配了3个 page 的物理 buffer,如果底层驱动分配成功,则会将该 dma-buf 所对应的 fd 返回给应用程序,以便后续执行 mmap 操作或将 fd 传给其它模块。
需要注意的是,这里的3个 pages 是通过3次调用 alloc_page() 来分配的,因此每个 page 之间可能是不连续的,也可以近似的认为该 ion 驱动分配的 buffer 属于 ION_HEAP_TYPE_SYSTEM。如果要分配物理连续的 pages,请使用 alloc_pages() 进行分配。
上面的驱动中,通过变长数组,实现虚拟地址连续,但是物理地址不一定连续的方法。
相关文章:
- ION简化版本)
linux 之dma_buf (8)- ION简化版本
一、前言 我们学习了如何使用 alloc_page() 方式来分配内存,但是该驱动只能分配1个PAGE_SIZE。本篇我们将在上一篇的基础上,实现一个简化版的ION驱动,以此来实现任意 size 大小的内存分配。 二、准备 为了和 kernel 标准 ion 驱动兼容&…...

⌈ 传知代码 ⌋ 高速公路车辆速度检测软件
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...

scrapy 整合 mitm
1.mitm 是什么 MITMproxy 是一个开源的中间人代理,常用于网络流量的拦截、查看和修改。 2.scrapy 整合 mitm步骤 2.1 安装mitm PS F:\studyScrapy\itcastScrapy> pip install mitmproxy2.2 在settings 中配置下载器中间件 # settings.pyDOWNLOADER_MIDDLEWARES…...

linux大文件切割
在一些小众的场景下出现的大文件无法一次性传输 当然我遇到了 ,work中6G镜像文件无法一次性刻盘到4.7G大小的盘 split split -b 3G 源大文件 目标文件 #安静等待会生成目标文件名a、b、c......-b <大小>:指定每个输出文件的大小,单位为…...

图像分割模型LViT-- (Language meets Vision Transformer)
参考:LViT:语言与视觉Transformer在医学图像分割-CSDN博客 背景 标注成本过高而无法获得足够高质量标记数据医学文本注释被纳入以弥补图像数据的质量缺陷半监督学习:引导生成质量提高的伪标签医学图像中不同区域之间的边界往往是模糊的&…...
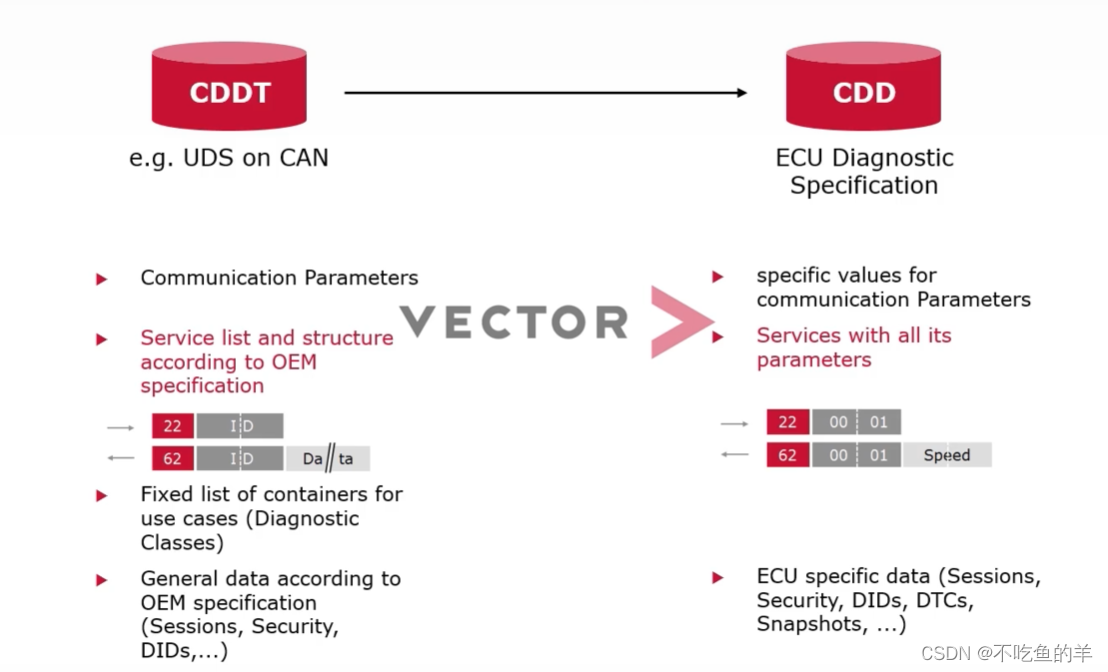
CANDela studio之CDDT与CDD
CDDT有更高的权限,作为模板规范CDD文件。 CDD可修改的内容比CDDT少。 CDDT根据诊断协议提供诊断格式,主要就是分类服务和定义服务,一般是OEM释放,然后由供应商细化成自己零部件的CDD文件。 在这里举个例子,OEM在CDDT…...
是什么?它们有什么用途?)
Java中的注解(Annotation)是什么?它们有什么用途?
技术难点 在Java中,注解(Annotation)是一种元数据(metadata)的形式,用于为Java代码(类、方法、变量、参数和包等)提供额外的信息。这些信息在运行时可以通过反射机制进行读取和处理…...
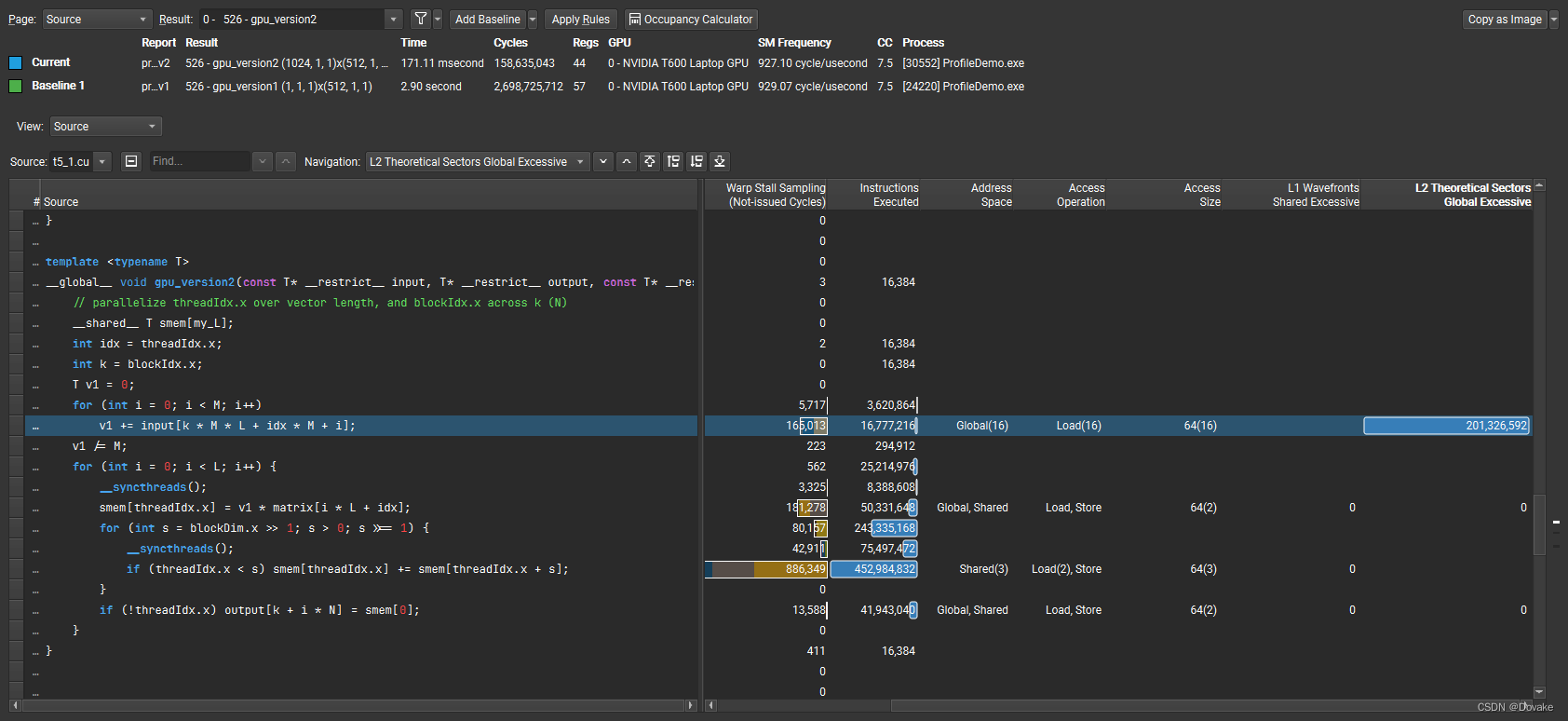
【CUDA】Nsight profile驱动的CUDA优化
前置准备 安装NVIDIA Nsight Compute。 安装好后选择使用管理员权限启动下载官方 Demo 代码官方博客Shuffle warp 1. 任务介绍及CPU版本 1.1 任务介绍 任务理解: 有一个 L x M 的矩阵 M 1 M_1 M1 对其每行取平均值 得到 V 1 ∈ R L 1 V_1 \in \mathbb{R}^{…...

字符串的拼接
字符串拼接方式1 之前的算术运算符,只是用来数值类型进行数学运算的,而string不存在算术运算符不能计算,但是可以通过号来进行字符串拼接。 string str "123"; //用进行拼接 str str "456"; Console.WriteLine(str)…...
HIVE3.1.3+ZK+Kerberos+Ranger2.4.0高可用集群部署
目录 一、集群规划 二、介质下载 三、基础环境准备 1、解压文件 2、配置环境变量 四、配置zookeeper 1、创建主体 2、修改zoo.cfg 3、新增jaas.conf 4、新增java.env 5、重启ZK 6、验证ZK 五、配置元数据库 六、安装HIVE 1、创建Hiver的kerberso主体 2…...
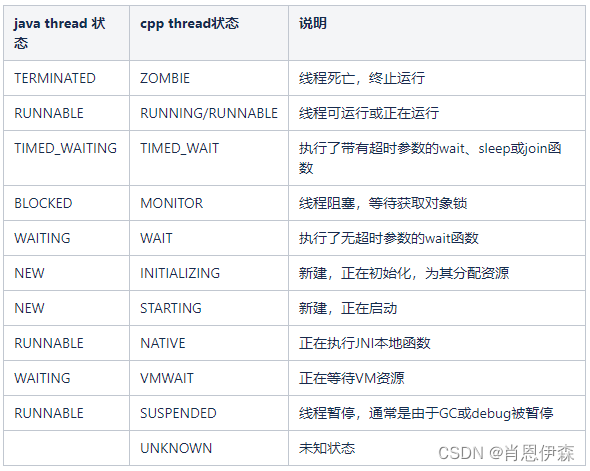
Android ANR Trace日志阅读分析技巧
什么是Trace日志 Trace日志是指ANR目录下的一份txt文件 adb pull /data/anr/traces.txt Trace日志有什么用 分析应用ANR无响应的问题, Trace怎么用 Cmd line: com.xx ABI: arm Build type: optimized Zygote loaded classes3682 post zygote classes3750 Intern…...

前端Ajax、Axios和Fetch的用法和区别笔记
前端 JavaScript 开发中,进行 HTTP 请求的三种主要方式是 Ajax、Axios 和 Fetch。这三种方式各有优缺点,并且适用于不同的场景。在合适的业务场景下使用,以下是它们的区别和使用举例。 1. Ajax Ajax(Asynchronous JavaScript an…...
)
Android的Framework(TODO)
(TODO)...

牛客小白月赛94 EF题解
题目描述 注:此版本为本题的hard(困难版),与easy(简单版)唯一的不同之处只有数据范围。 小苯有一个容量为 k 的背包,现在有 n 个物品,每个物品有一个体积 v 和价值 w࿰…...

大数据开发面试题【Flink篇】
148、flink架构 flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算 特点: 高吞吐和低延迟:每秒数百万个事件,毫秒级延迟 结果的准确性:提供了事件时间和处理时间语义,提供结果的一致…...
)
Java技术深度解析:高级面试问题与精粹答案(二)
Java 面试问题及答案 1. 什么是Java的垃圾回收机制?它是如何工作的? 答案: Java的垃圾回收机制(Garbage Collection,GC)是Java运行时环境(JRE)中的一个功能,用于自动管…...

算数运算符
算术运算符是用于数值类型变量计算的运算符。 它的返回结果是数值。 赋值符号 关键知识点:先看右侧,再看左侧,把右侧的值赋值给左侧的变量。 附上代码: string myName "唐唐"; int myAge 18; float myHeight 177.5…...

闲话 .NET(3):.NET Framework 的缺点
前言 2016 年,微软正式推出 .NET Core 1.0,并在 2019 年全面停止 .NET Framework 的更新。 .NET Core 并不是 .NET Framework 的升级版,而是一个从头开始开发的全新平台,一个跟 .NET Framework 截然不同的开源技术框架。 微软为…...

WPF实现简单的3D图形
简述 Windows 演示基础 (WPF) 提供了一种功能,用于根据应用程序要求绘制、转换 3D 图形并为其添加动画效果。它不支持完整的3D游戏开发,但在某种程度上,您可以创建3D图形。 通过组合 2D 和 3D 图形,您还可以…...

设计模式之创建型模式---原型模式(ProtoType)
文章目录 概述类图原型模式优缺点优点缺点 代码实现 概述 在有些系统中,往往会存在大量相同或者是相似的对象,比如一个围棋或者象棋程序中的旗子,这些旗子外形都差不多,只是演示或者是上面刻的内容不一样,若此时使用传…...

不止于获取数据:用baostock+Pandas+Matplotlib打造你的第一个股票分析仪表盘
从数据获取到洞察生成:构建股票分析仪表盘的全流程实战 在金融数据分析领域,获取原始数据只是万里长征的第一步。真正有价值的是如何将这些数据转化为可操作的洞察。本文将带你使用Python生态中的baostock、Pandas和Matplotlib等工具,构建一个…...

从零到部署:在Linux服务器上用Python搭建并调用WPS地理处理服务
从零到部署:在Linux服务器上用Python搭建并调用WPS地理处理服务 当遥感影像分析遇上自动化处理流程,地理信息系统(GIS)开发者常面临一个关键挑战:如何将复杂的空间运算封装成可远程调用的标准化服务?这正是…...

从源码到实战:手把手教你自定义一个比StringUtils更强大的Java数字校验工具类
从源码到实战:构建超越StringUtils的Java数字校验工具类 在Java开发中,数字校验是每个开发者都会遇到的常见需求。虽然Apache Commons Lang的StringUtils提供了基础的isNumeric方法,但在实际业务场景中,我们经常需要处理更复杂的…...

告别卡顿!用Sunshine打造私人游戏串流服务器的完整指南
告别卡顿!用Sunshine打造私人游戏串流服务器的完整指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 你是否曾经梦想过在任何设备上流畅玩PC游戏?无论是躺…...

SAP SD新手避坑指南:交货工厂和装运点配置错了,小心订单发不出去!
SAP SD配置实战:交货工厂与装运点配置错误的深度排查手册 当销售订单在SAP系统中卡在发货环节时,背后往往隐藏着交货工厂(Plant)与装运点(Shipping Point)的配置逻辑问题。这类错误不仅会导致业务流程中断&…...

G-Helper:华硕笔记本轻量化控制工具完整指南
G-Helper:华硕笔记本轻量化控制工具完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertbook,…...

学习第六天,python
元组(tuple)一、元组的本质与特点核心:不可变性二、元组的创建方式三、元组的访问四、元组的操作五、元组的经典使用场景六、元组的注意事项与陷阱字典(dict)字典以 key: value 的形式存储数据,通过 key 就…...

告别光流计算!用PyTorch复现MotionNet,5分钟搞定视频动作识别
5分钟实现视频动作识别:PyTorch版MotionNet实战指南 在咖啡还没凉透的间隙里,让AI看懂视频动作——这曾是计算机视觉领域最耗时的任务之一。传统双流网络需要预计算光流,像手工制作意大利面般繁琐;而2017年问世的MotionNet就像发…...

【Perplexity文献管理终极指南】:20年科研老炮亲授AI时代参考文献零误差管理法
更多请点击: https://intelliparadigm.com 第一章:Perplexity文献管理的底层逻辑与范式革命 Perplexity 并非传统意义上的本地文献数据库工具,其核心突破在于将文献管理从“静态存储—手动索引”范式,跃迁至“动态语义理解—上下…...

影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案
影像技术实战12:图片清晰度评估不准?Laplacian、Tenengrad、噪声干扰与模糊图片批量筛选方案 一、问题场景:数据集里混入模糊图,模型效果怎么调都上不去 在图像识别、OCR、人脸识别、商品图审核、视频抽帧数据清洗中,经…...