2.8万字总结:金融核心系统数据库升级路径与场景实践

谈及数字化转型,如果说过去还只是头部金融机构带动效应下的“选择题”。那么现在,我相信数字化转型已经成为不论大、中、小型金融机构的“必答题”。
本文为OceanBase最新发布的《万字总结:金融核心系统数据库升级路径与场景实践》部分摘要。
请可点击下载完整版电子书 >>
走向现代数据架构,数据库成为金融数字化转型关键环节
数字化转型的本质是利用数据,重塑传统业务与组织模式,构建企业的新型竞争力。随着数字经济时代的到来,数据量正在从TB级跃升至PB级、甚至ZB级。根据IDC测算,我国数据总量预计2025年将高达48.6ZB,占全球总量的27.8%。如今数据总量的 “大”已经和过去不是一个级别,IT领域“旧瓶”(旧的数据架构)难装“新酒”(新的数据量级),数字化转型需要一套现代数据架构有力支撑。
近年来,数据架构的演进大多从最易升级、风险相对可控的SaaS层开始,再到对业务影响较小且相对标准化的IaaS层,最后才到与业务相关、有状态的PaaS层。而在最难的PaaS层中,考虑到与应用的耦合度以及状态数据的重要性,最难升级的又属数据库。
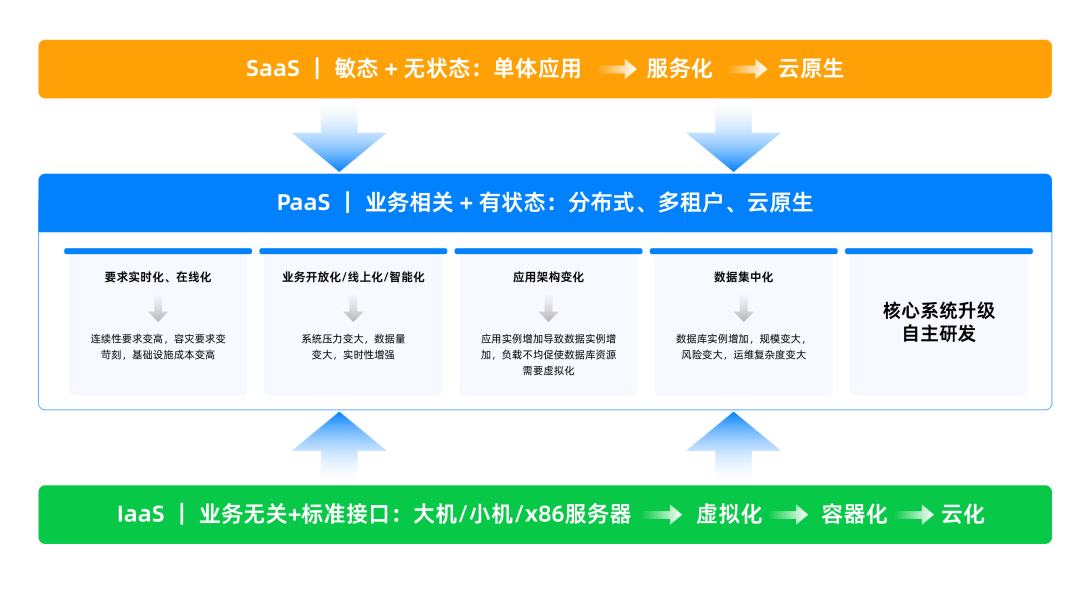
图1 IaaS 层、PaaS 层、SaaS 层的演进关系
数据库相当于“大树”(数据架构)的“根基”,“根基”决定了“果实”(数字化转型)的优良。传统数据库已然不能满足现代数据架构的需求,金融机构亟需彻底重构“根基”。
从边缘到核心,数据库升级全面提速
核心系统是金融机构的交易中枢,不仅沉淀了大量的数据资产,更是与周边系统盘根错节,可以说是“牵一发而动全身”。因此,大多数金融机构在信息化系统数据库升级时,通常采取循序渐进、风险可控的策略,即先边缘系统再核心系统,不仅是为了新数据库技术的逐步掌握,更是为了业务的风险可控。
赛迪顾问显示,OceanBase已经成为核心系统升级首选,并在中国金融行业分布式数据库占有率第一。我们累计服务数百家金融机构,大部分都涉及核心系统。尤其以头部银行、头部保险为代表的金融机构开始涉足“无人区”,均取得了不错的成绩。这些先行者的尝试,已经验证了金融核心系统升级的可行性,并积累了大量方法论。
根据我们的经验,从核心系统开始升级,有助于彻底抛弃原有的陈旧数据架构,更快地使用新数据库技术满足现代金融业务发展。当然,核心系统数据库升级改造工作的同时,也伴随着边缘系统的数据库升级改造工作,并且得益于核心系统的经验积累,部分边缘系统上线更快。
此外,核心系统(含数据库)的整体升级大概需要持续需2~3年。加之时间窗口有限,核心系统数据库的升级已经到了必须提上日程的时期。
金融行业需要怎样的数据库
1. 金融行业数据库技术架构演进
回溯IT技术的发展史,金融行业的IT应用基本走在行业前列。到了移动互联网时代,金融机构纷纷开启加速数字化转型。柜面交易量逐步被替代,由智能手机承载的金融服务方便随身携带。并且在业务范围上延伸服务客户的范围,开放金融、供应链金融、全场景金融等不断涌现。
传统集中式数据库依赖单机的处理能力,因而存在架构上的单点。随着摩尔定律的失效,依靠垂直扩展的集中式走到了尽头,而金融业务的发展要求数据库具备海量数据下的高并发的事务处理能力。部分金融架构在转型中尝试中间件架构的分布式,在国外开源数据库上做二次开发,并取得一定效果,但随着深入应用依然出现瓶颈。为彻底解决海量数据、高并发场景的数据库的问题,原生分布式数据库架构诞生。
中国信息通信研究院在《大数据白皮书(2018年)》中给出了数据库架构的发展方向,包含两重含义:一是分布式替代集中式是发展的必然,而原生分布式数据库是数据库发展的方向;二是中间件架构的分布式只是过渡态。
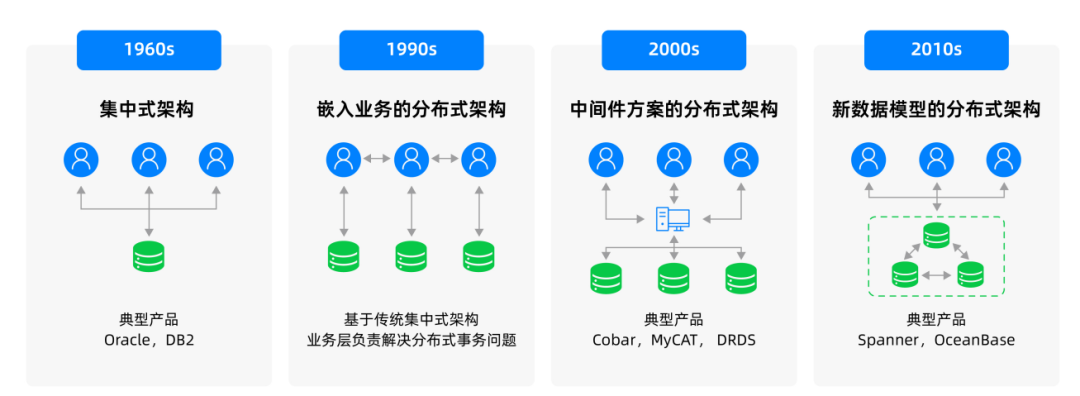
图2 数据库架构演进图
* 中国信息通信研究院《大数据白皮书(2018年)》
2. 中国场景驱动数据库技术创新,新一代数据库需要具备四大核心能力
Forrester 相关报告指出,传统数据库在数字经济时代面临技术架构、使用成本以及安全性等严峻的挑战。新一代数据库需要具备低成本的极致性能、全维度的弹性灵活、洞察驱动的融合分析,以及全方位的安全可靠性四大核心能力。
数据库是用出来的。OceanBase 过去 14 年的发展,基于“根自研”这条完全自主研发的路线,得益于中国独特的场景,带来前所未有的对海量数据、高并发的数据处理需求,以及这些年大量企业尤其是金融核心系统,带来复杂业务场景下的数据处理需求,倒逼分布式数据库技术的再次突破、创新和成熟。
这条成长路径对基础软件的发展而言在全球都很难复制,使得 OceanBase 能够始终坚持创新探索,穿越无人区。
3. 一体化数据库:支持不同规模金融机构/业务系统
我们在不断解决各种场景问题,尤其是关键业务的数据存储、处理、使用过程中,摸索出分布式架构数据库的最佳实践,逐步形成了“一体化”的解决思路。
从 2010 年至今,OceanBase 专注于 OLTP 场景,开始逐步打造满足现代数据架构需求的TP&AP一体化、多模、云上云下一体化、单机分布式一体化等核心能力,推出一体化数据库,支持不同规模金融机构/系统的关键业务负载。“一体化”的理念包含两个方面:
第一,“一体化”的体验;
第二,一个数据库解决 80% 的问题。
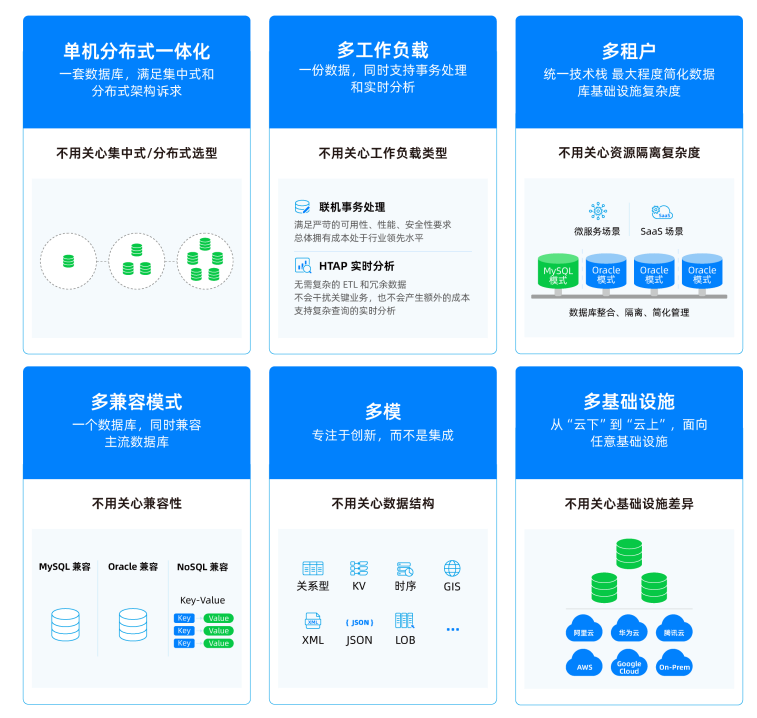
图3 OceanBase 一体化数据库
OceanBase如何解决金融行业面临的数据库升级挑战
对于数据库产品,无论是架构升级还是自身能力迭代演进,首要目标都需要确保稳定可靠,数据库升级过程要平滑,分层解耦,风险可控。同时,作为基础软件的数据库,对应用系统的影响要尽可能做到最小,除了自身要提供完善的功能,还要对应用系统屏蔽自身的架构复杂度,让应用简单地使用数据库。比较一致的是,数据库要具备独立演进能力,保证技术栈的可持续发展和自主掌控。
OceanBase主要通过以下5点解决金融行业面临的数据库升级挑战:
1. 深度强化稳定可靠,保障服务不中断、数据不丢失;
2. 持续平衡性能与成本,助力性能不回退、成本不增加;
3. 不断降低运维复杂度,集中式体验享受分布式性能;
4. 完善平滑迁移方案,打造应用基本无感的稳妥升级;
5. OLTP-Based HTAP,实时分析回归业务本质需求。
核心系统数据库升级最佳路径实践
金融核心系统更换数据库,就好比飞机在运行过程中更换发动机。如何在更换发动机的过程中不影响飞机的正常飞行,甚至让乘客感受不到这个过程,对金融机构和数据库厂商而言都是一场“大考”。
1. 八个步骤
从应用演进的角度,常见的金融核心系统数据库升级有“平滑迁移”和“完全新建”两种,迁移侧重应用不改或者仅有少量修改,保持库表结构基本不变的情况下,将数据库替换成分布式数据库;完全新建是建设一套新的核心系统,然后将老核心的数据与新核心的数据结构映射后完成数据的转换和迁移。
OceanBase 在服务众多金融机构的核心系统数据库升级过程中,沉淀出一套升级替换的八个步骤,包括需求分析与战略规划、技术选型与方案设计、应用适配&业务测试与评估、系统迁移与优化、业务验证与持续监控、安全与合规、培训与文档、持续迭代与优化。
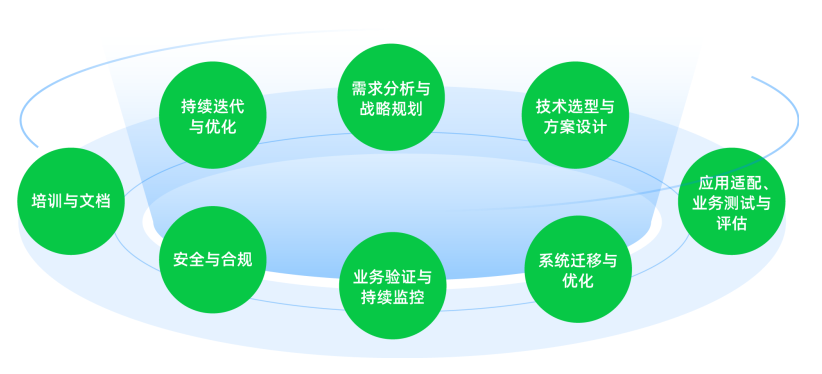
图4 传统方式 VS HTAP方式
2. 四条路径
此外,我们也总结出核心系统数据库升级的四条技术路径:
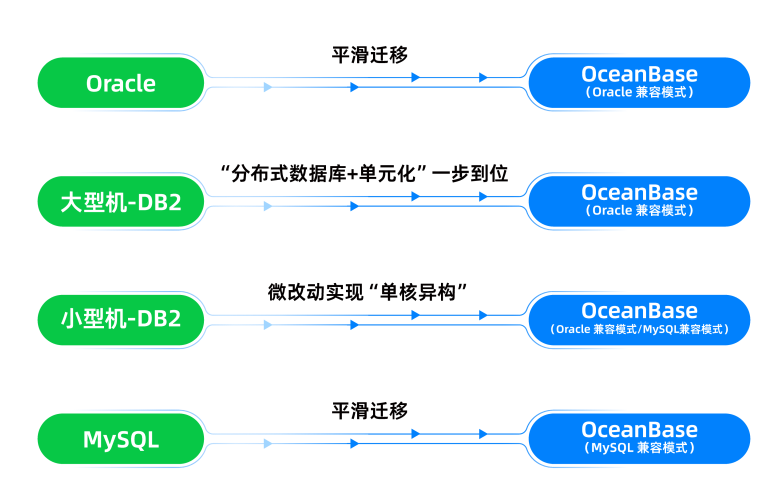
图5 核心系统数据库升级的四条技术路径
路径一:Oracle平滑升级迁移
该路径的特点是,应用代码少改或者不改的情况下,依靠分布式数据库的兼容性实现。OceanBase基于自身对于Oracle的高度兼容及多年积累的体系化的迁移工具与迁移经验,通过“全面语法兼容”配合客户实现平滑迁移。采用此路径的有某国有特大型保险机构、中国太平洋保险的“P17核心客户服务系统”、金华银行新一代核心系统,以及广发证券的核心估值系统等。
路径二: 大型主机DB2迁移分布式数据库+单元化方案
在金融行业的头部国有大行中,因业务规模大、范围广、复杂度高等,是分布式转型中的难点,同时国有大行在新一代核心建设中有单元化等架构方面的建设要求。某国有大行的贷记卡核心、借记卡核心、ECIF核心这三大核心系统均已转型分布式,其中,贷记卡核心采用“阿里云+SOFA中间件+OceanBase分布式数据库”整体技术栈,实现“两地四中心”多地多活+单元化设计。
路径三:小型机DB2升级OceanBase
小型机DB2在中小银行核心系统的数据库中占用重要位置,而中小银行普遍采用新建的方式建设新一代核心系统。其中,一部分选择OB-Oracle模式,实现一套核心应用分别部署在OB-Oracle和DB2-Oracle两种数据库上,实现双逃生;另一部分选择OB-MySQL模式,分批切换,一步到位。采用此路径的有常熟农商行、云南红塔银行、深圳农商银行的新一代核心系统等。
路径四:MySQL平滑升级迁移
诚然,MySQL主要用在互联网核心或非核心系统,且大部分情况下为“完全新建”,“平滑迁移”为少数。与“Oracle平滑迁移方案”类似,得益于高兼容性,选择OB-MySQL模式即可在应用基本零改动的情况下,从源数据库完成平滑迁移。采用此路径的有西安银行的快捷支付系统改造等。
3. 核心系统数据库选型建议概述
赛迪顾问在2023年2月发表的《核心数据库升级选型参考》报告显示,核心数据库选型因素涵盖数据、功能、效果三个层面,为金融机构的核心系统数据库选型提供了清晰的思路。
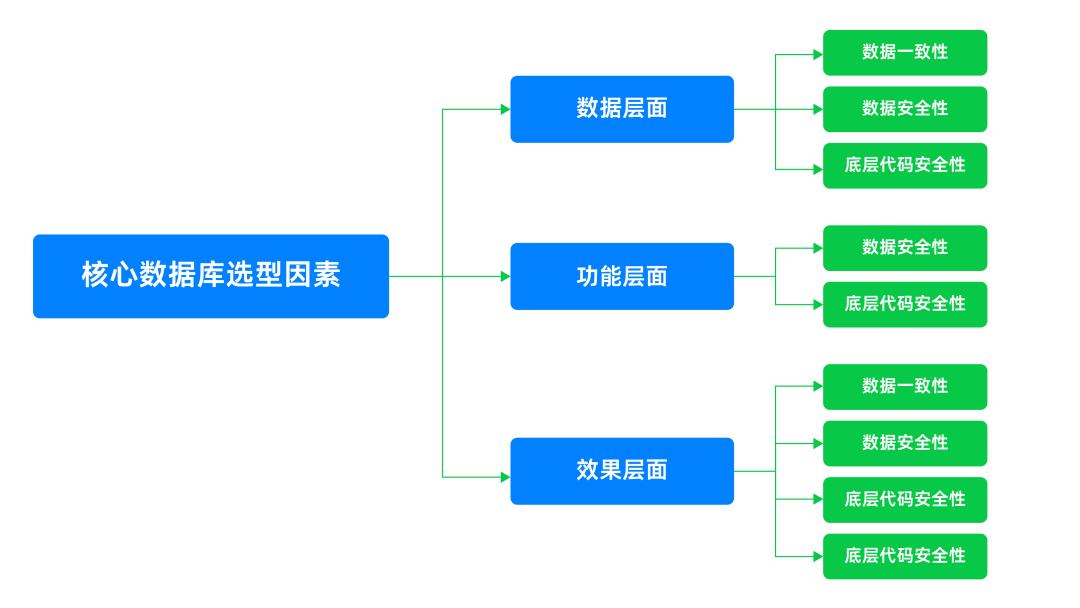
图6 核心系统数据库选型因素
*赛迪顾问《核心系统升级选型参考》
首先是数据层面,主要包括数据一致性、数据安全性以及底层代码安全性。数据层面的选型考量相当于“1”,只有这个层面具备足够能力的数据库,后续拥有其他的“0”,比如更高的性能、更低的成本等,才有意义。其次是功能层面,主要包括兼容与迁移、双写及回迁能力、事务处理能力、大数据实时分析能力。最后是效果层面,主要包括稳定性与可靠性、性价比。
典型金融场景实践
1. 银行
场景一:跑批类场景
跑批类场景,天生就是高并发的联机交易,最重要的是时效。若跑批时间过长,轻则客诉,重则资损,甚至出现舆情事件。这类场景对数据库处理能力的有效检验方式之一就是如何快速完成批量交易,因为需要频繁地对数据库进行增删改查,进行大量的I/O物理读和逻辑读计算操作,应用访问数据库的吞吐量也尤为关键。
原生分布式数据库通过多台机器的并发能力,并通过弹性扩缩实现动态的资源调整,因而对跑批场景具备优势。如避免分布式事务和远程访问,让所有服务器全部参与批量结息过程,提高处理速度;分散负载到多个节点,减少单一节点的压力;迅速扩容以应对流量高峰,同时在低峰期自动缩减资源以节约成本;允许读操作分散到多个副本,而写操作则在主节点上进行,减少读写竞争等,大幅提升批量场景效率。
场景二:交易类场景
交易类场景,最重要的是单笔交易耗时和交易吞吐量。若单笔交易耗时过长,则影响用户体验;若性能容量的TPS不足,则会造成高并发场景下部分客户的业务连续性无法保障。
伴随新一代核心系统的分布式转型,分布式数据库在交易性能容量方面有天然优势。在单笔耗时方面,应用和数据库同时转型分布式时,耗时增加有限,业务上完全可接受。例如,某大行信用卡核心转型分布式从60毫秒提升80毫秒,在耗时有限增长的情况下,提供了机房级容灾能力,为业务连续性提供更好的保障。
银行新一代核心系统中无论是跑批场景还是交易场景,原生分布式数据库都能够为业务提供更好的支撑力。某国有大行、常熟农商银行、云南红塔银行、深圳农商银行等新一代核心系统,以及某国有大行ECIF系统等均选择升级至原生分布式数据库。
2. 保险
场景一:寿险核心场景
保险机构的寿险核心业务系统重构频率相对银行较低,很多都有超过10年、甚至20年的历史,这些业务代码完全推翻重构难度和风险极高,可以说既是宝贵财富也是沉重负担。寿险业务主要具有业务场景复杂、业务数据量大、业务突发流量高的特点。
过去,寿险核心业务系统基本90%以上使用Oracle数据库,面对以上业务特点,随着数据经济的加速前行,传统集中式数据库在容量、性能、云化、多模等方面都已经愈发力不从心。一是面对复杂SQL、大数据量的性能挑战;二是面对突发流量的挑战。
某国有特大型保险机构的寿险核心系统数据库升级至OceanBase后,最大化资源利用,通过动态弹性调整租户计算资源,敏捷应对业务负载要求的变化,经受住开门红TPS 5 万+、QPS 21万+ 的严苛考验,稳妥保障业务连续性和数据准确性。
场景二:客服系统场景
客户服务系统通常是保险机构关联关系最为复杂、商业数据库绑定程度最深、业务影响最多的核心业务系统之一。秉承“以客户为中心”,该系统要求7X24小时服务,此外还呈现数据量庞大、割接要求高等特点。
以中国太平洋保险的“P17核心客户服务系统”(以下简称“P17”)为例,是其产、寿、健康、长江等所有子公司客户服务系统的整合,为公司6的8个电话中心超过2000坐席提供系统服务,对接周边系统超过200个。升级难度主要体现在对Oracle兼容性要求高、周边对接产品多。
凭借OceanBase的高度Oracle兼容性、完善的迁移工具链,经过近一年的技术攻坚,将“P17”完全迁移到OceanBase,百万行PL/SQL代码平迁复用,至今已经稳定运行了接近一年。全面升级后,数据库软件的运维费用大幅降低,每年可节省设备投入数亿元。特别是OceanBase的高级压缩技术,结合“数据库瘦身”,将存储容量节省80%以上。升级后的应⽤系统弹性扩缩容、处理速度、数据加⼯能⼒均实现⼤幅提升。
3. 证券&基金
场景一:UF3.0核心交易系统
证券机构的集中交易系统, “委托”和“成交”是最主要的功能,也称为“路由”功能,同时还有资金买空或者证券卖空的“监控”功能,以及“查询”功能。
传统集中交易系统通常直接引入Oracle一体机解决性能问题,但是众多系统仍以“竖井”的方式建设,配套硬件成本、部署成本等整体成本投入大。且由于单体架构的先天限制,在容量和性能遇到瓶颈时无法横向动态扩容,制约系统的整体处理能力。
恒生的 UF3.0 采用分布式微服务架构实现交易、清算、管理的三大模块,整体架构设计与 OceanBase 相契合,提升业务处理能力,加快交易结算速度,提高证券客户满意度。
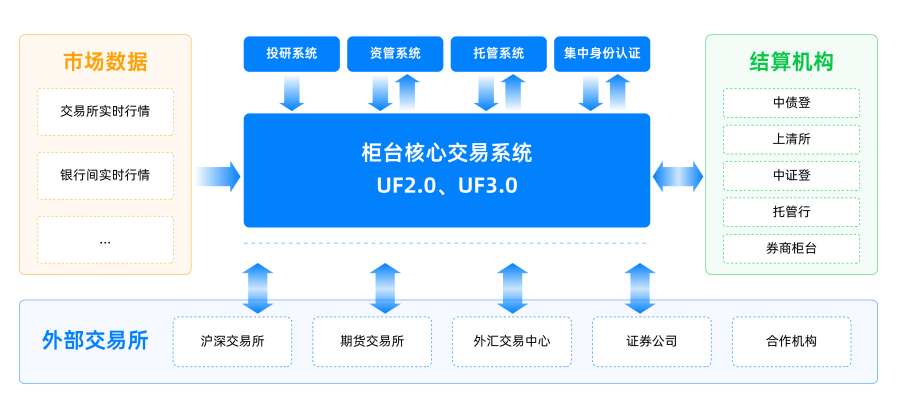
图7 10:UF3.0业务架构
招商证券、东方证券等券商公司新一代核心交易系统选用基于OceanBase 的 UF3.0 支持整体 IT 业务平台,提供综合金融服务。以招商证券为例,OceanBase 承载了包括 UF3.0、数据中台服务、Level2 行情数据等共计百套业务系统,节约整体拥有成本约70%。
场景二:ETF_TA系统
TA系统全称为开放式基金登记过户系统,与典型的OLTP业务(比如在线联机交易)不同,清算跑批必须在规定的窗口时间内完成。同时,TA系统属于比较复杂的“跑批”业务,涉及的数据量较大,计算逻辑也比较复杂,存在多表关联和复杂查询,并且步骤多。因此,TA系统对数据库的综合要求较高,不仅要高稳定、高可靠,同时也要高性能。
OceanBase通过稳定的SQL引擎保障复杂查询的执行效率,完全满足系统的高并发、数据高并行的业务特性,通过多租户架构,支撑TA系统的分布式微服务架构,提升资源利用率。分布式数据库的扩展性,让TA系统跑批效率随数据库节点增加而提升,未来基金用户数、交易数上升时,能在不调整业务架构的前提下,通过数据库层的横向扩展支撑业务发展。
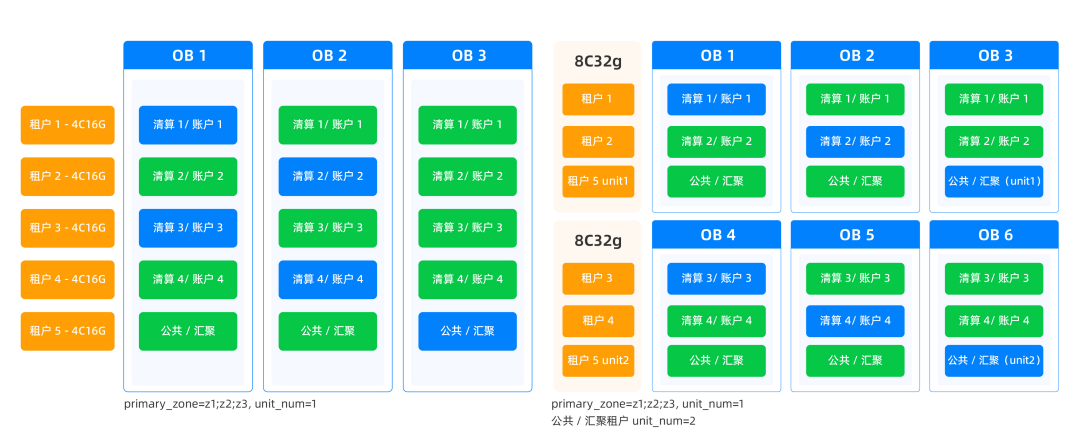
图8 OceanBase多租户的TA数据分布
易方达基金、安信证券等金融机构的TA系统均选择搭载OceanBase。以安信证券为例,新一代TA系统上线后登记过户的跑批清算时间由2小时降低为1小时,TA系统的清算时间缩短为原先的50%,对上下游业务系统而言,登记过户相关的整体运营效率得到显著提升。
写在最后
“九层之台,起于累土”。 作为一款“根自研”的分布式数据库,OceanBase致力于打造负载关键业务系统的一体化数据库,让更多金融机构在数字化转型升级的过程中,用一个数据库就能解决80%的问题,数据架构更加适应现代应用开发、AI延展等,享受一体化架构带来的技术红利;我们将继续携手服务、技术、ISV等生态伙伴攻坚关键业务系统,为金融数字化转型贡献更多的、更大的力量。
点击下载《万字总结:金融核心系统数据库升级路径与场景实践》完整版电子书 >>

相关文章:
2.8万字总结:金融核心系统数据库升级路径与场景实践
OceanBase CEO 杨冰 谈及数字化转型,如果说过去还只是头部金融机构带动效应下的“选择题”。那么现在,我相信数字化转型已经成为不论大、中、小型金融机构的“必答题”。 本文为OceanBase最新发布的《万字总结:金融核心系统数据库升级路径…...
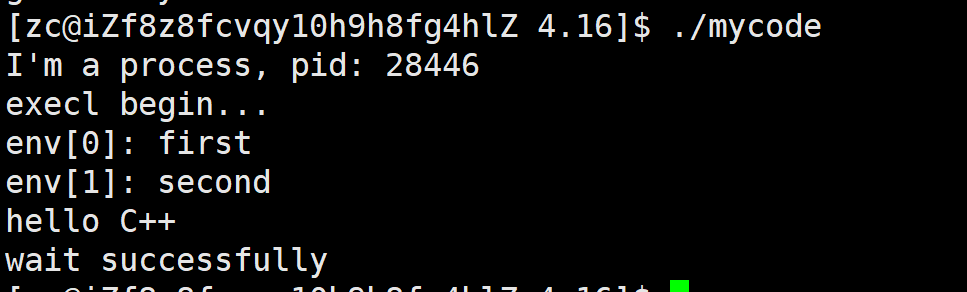
Linux:进程控制(二.详细讲解进程程序替换)
上次讲了:Linux:进程地址空间、进程控制(一.进程创建、进程终止、进程等待) 文章目录 1.进程程序替换1.1概念1.2原理1.3使用一个exec 系列函数execl()函数结论与细节 2.多进程时的程序替换3.其他几个exec系…...
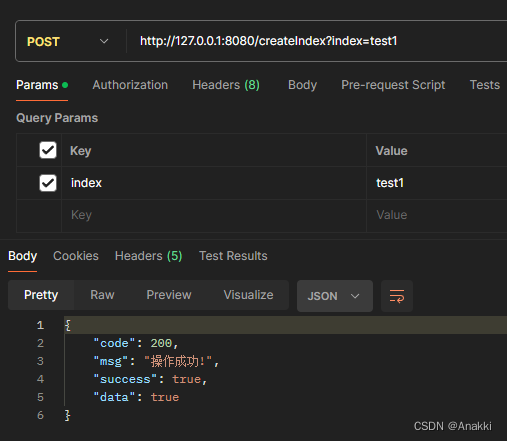
Elasticsearch8.13.4版本的Docker启动关闭HTTPS
博主环境是: 开发环境:SpringbootElasticSearch客户端对应的starter 2.6.3版本 maven配置 <!-- ElasticSearch --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elas…...
- ION简化版本)
linux 之dma_buf (8)- ION简化版本
一、前言 我们学习了如何使用 alloc_page() 方式来分配内存,但是该驱动只能分配1个PAGE_SIZE。本篇我们将在上一篇的基础上,实现一个简化版的ION驱动,以此来实现任意 size 大小的内存分配。 二、准备 为了和 kernel 标准 ion 驱动兼容&…...

⌈ 传知代码 ⌋ 高速公路车辆速度检测软件
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦&#x…...

scrapy 整合 mitm
1.mitm 是什么 MITMproxy 是一个开源的中间人代理,常用于网络流量的拦截、查看和修改。 2.scrapy 整合 mitm步骤 2.1 安装mitm PS F:\studyScrapy\itcastScrapy> pip install mitmproxy2.2 在settings 中配置下载器中间件 # settings.pyDOWNLOADER_MIDDLEWARES…...

linux大文件切割
在一些小众的场景下出现的大文件无法一次性传输 当然我遇到了 ,work中6G镜像文件无法一次性刻盘到4.7G大小的盘 split split -b 3G 源大文件 目标文件 #安静等待会生成目标文件名a、b、c......-b <大小>:指定每个输出文件的大小,单位为…...

图像分割模型LViT-- (Language meets Vision Transformer)
参考:LViT:语言与视觉Transformer在医学图像分割-CSDN博客 背景 标注成本过高而无法获得足够高质量标记数据医学文本注释被纳入以弥补图像数据的质量缺陷半监督学习:引导生成质量提高的伪标签医学图像中不同区域之间的边界往往是模糊的&…...
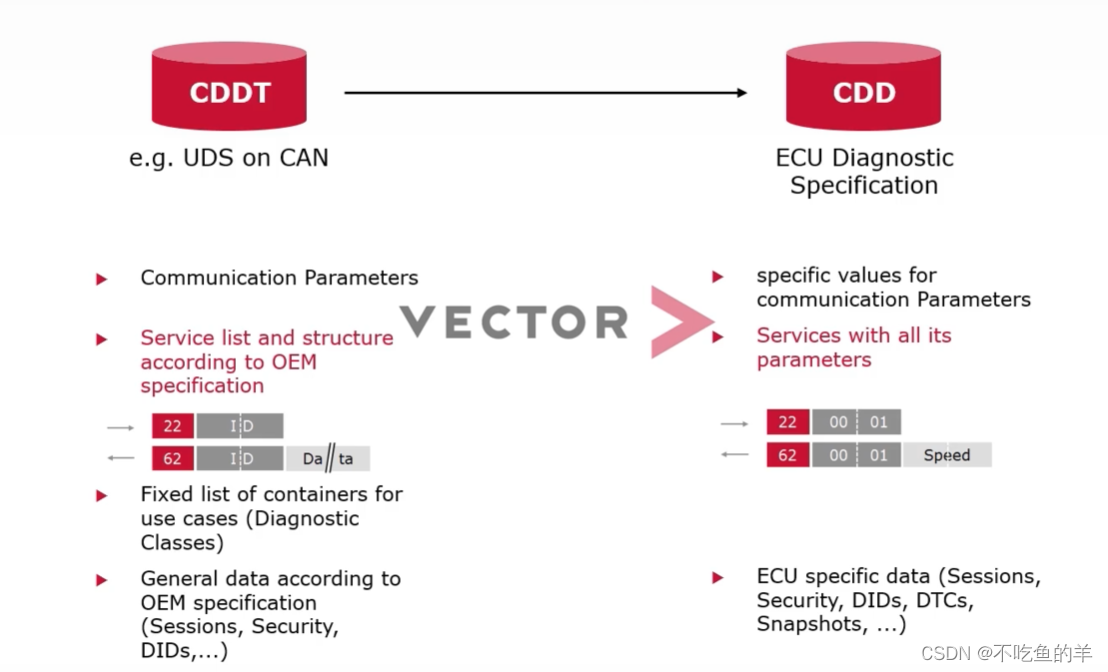
CANDela studio之CDDT与CDD
CDDT有更高的权限,作为模板规范CDD文件。 CDD可修改的内容比CDDT少。 CDDT根据诊断协议提供诊断格式,主要就是分类服务和定义服务,一般是OEM释放,然后由供应商细化成自己零部件的CDD文件。 在这里举个例子,OEM在CDDT…...
是什么?它们有什么用途?)
Java中的注解(Annotation)是什么?它们有什么用途?
技术难点 在Java中,注解(Annotation)是一种元数据(metadata)的形式,用于为Java代码(类、方法、变量、参数和包等)提供额外的信息。这些信息在运行时可以通过反射机制进行读取和处理…...
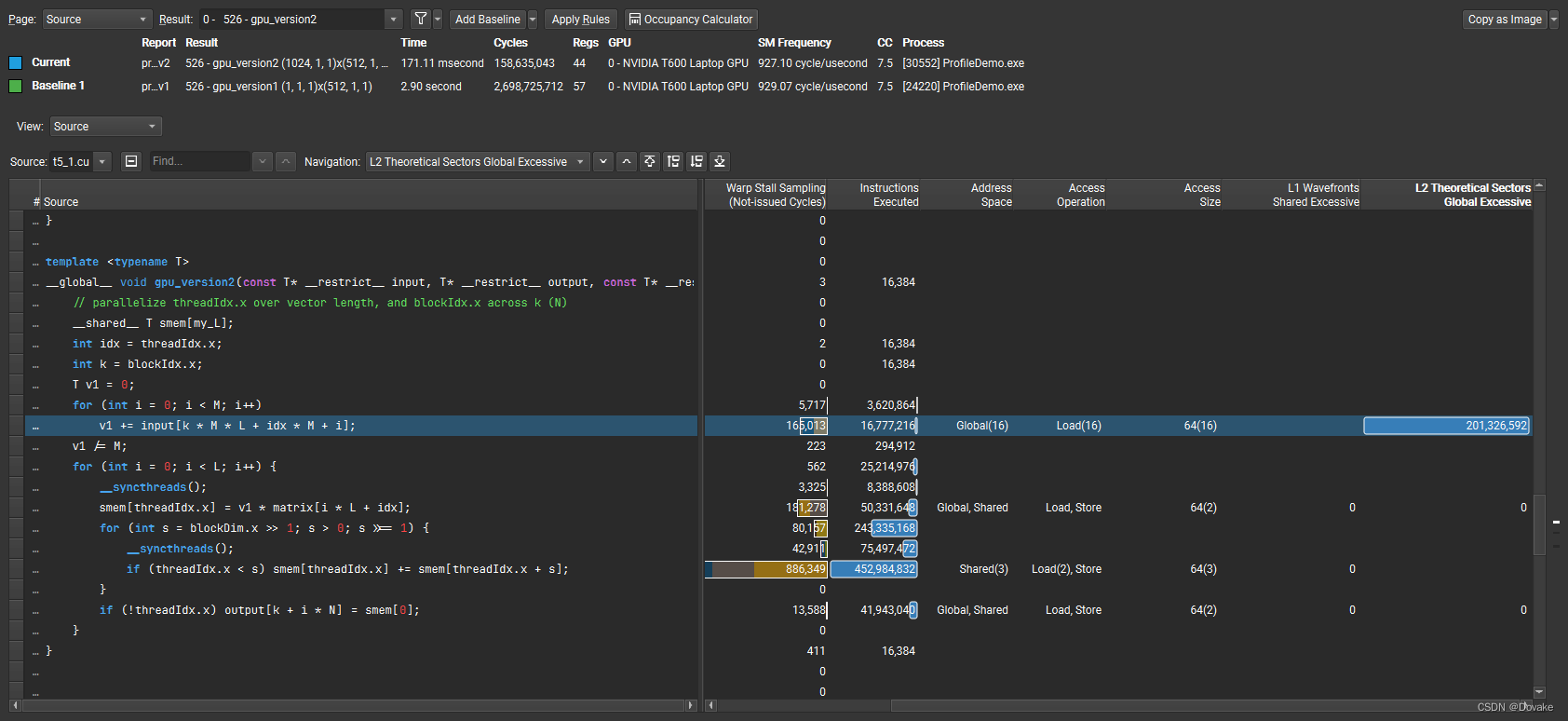
【CUDA】Nsight profile驱动的CUDA优化
前置准备 安装NVIDIA Nsight Compute。 安装好后选择使用管理员权限启动下载官方 Demo 代码官方博客Shuffle warp 1. 任务介绍及CPU版本 1.1 任务介绍 任务理解: 有一个 L x M 的矩阵 M 1 M_1 M1 对其每行取平均值 得到 V 1 ∈ R L 1 V_1 \in \mathbb{R}^{…...

字符串的拼接
字符串拼接方式1 之前的算术运算符,只是用来数值类型进行数学运算的,而string不存在算术运算符不能计算,但是可以通过号来进行字符串拼接。 string str "123"; //用进行拼接 str str "456"; Console.WriteLine(str)…...
HIVE3.1.3+ZK+Kerberos+Ranger2.4.0高可用集群部署
目录 一、集群规划 二、介质下载 三、基础环境准备 1、解压文件 2、配置环境变量 四、配置zookeeper 1、创建主体 2、修改zoo.cfg 3、新增jaas.conf 4、新增java.env 5、重启ZK 6、验证ZK 五、配置元数据库 六、安装HIVE 1、创建Hiver的kerberso主体 2…...
Android ANR Trace日志阅读分析技巧
什么是Trace日志 Trace日志是指ANR目录下的一份txt文件 adb pull /data/anr/traces.txt Trace日志有什么用 分析应用ANR无响应的问题, Trace怎么用 Cmd line: com.xx ABI: arm Build type: optimized Zygote loaded classes3682 post zygote classes3750 Intern…...

前端Ajax、Axios和Fetch的用法和区别笔记
前端 JavaScript 开发中,进行 HTTP 请求的三种主要方式是 Ajax、Axios 和 Fetch。这三种方式各有优缺点,并且适用于不同的场景。在合适的业务场景下使用,以下是它们的区别和使用举例。 1. Ajax Ajax(Asynchronous JavaScript an…...
)
Android的Framework(TODO)
(TODO)...

牛客小白月赛94 EF题解
题目描述 注:此版本为本题的hard(困难版),与easy(简单版)唯一的不同之处只有数据范围。 小苯有一个容量为 k 的背包,现在有 n 个物品,每个物品有一个体积 v 和价值 w࿰…...

大数据开发面试题【Flink篇】
148、flink架构 flink是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算 特点: 高吞吐和低延迟:每秒数百万个事件,毫秒级延迟 结果的准确性:提供了事件时间和处理时间语义,提供结果的一致…...
)
Java技术深度解析:高级面试问题与精粹答案(二)
Java 面试问题及答案 1. 什么是Java的垃圾回收机制?它是如何工作的? 答案: Java的垃圾回收机制(Garbage Collection,GC)是Java运行时环境(JRE)中的一个功能,用于自动管…...

算数运算符
算术运算符是用于数值类型变量计算的运算符。 它的返回结果是数值。 赋值符号 关键知识点:先看右侧,再看左侧,把右侧的值赋值给左侧的变量。 附上代码: string myName "唐唐"; int myAge 18; float myHeight 177.5…...
全流程实操:从ONNX转换到INT8/FP16量化加速)
YOLOv8在Jetson上导出TensorRT引擎(.engine)全流程实操:从ONNX转换到INT8/FP16量化加速
YOLOv8在Jetson平台上的TensorRT引擎部署与量化加速实战指南 当目标检测模型需要部署到边缘计算设备时,性能优化往往成为最关键的技术挑战。本文将深入探讨如何将YOLOv8模型高效转换为Jetson平台专用的TensorRT引擎,并通过INT8/FP16量化技术实现推理速度…...

从零到部署:在Linux服务器上用Python搭建并调用WPS地理处理服务
从零到部署:在Linux服务器上用Python搭建并调用WPS地理处理服务 当遥感影像分析遇上自动化处理流程,地理信息系统(GIS)开发者常面临一个关键挑战:如何将复杂的空间运算封装成可远程调用的标准化服务?这正是…...

AArch64虚拟内存系统架构与64KB粒度地址转换详解
1. AArch64虚拟内存系统架构概述现代处理器架构通过虚拟内存机制实现物理内存与虚拟地址空间的隔离映射,AArch64作为ARMv8/ARMv9架构的64位执行状态,其虚拟内存系统架构(VMSA)采用多级页表机制实现地址转换。与传统x86架构相比&am…...

【云计算学习之路】学习Centos7系统-Linux网络配置管理
Linux网络TCP/IP协议概述OSI 七层模型与 TCP/IP 四层模型 协议对照表IP地址及网络常识IP地址A类IP地址B类IP地址C类IP地址D类IP地址特殊的网址子网掩码网关地址MAC地址Linux服务器IP命名规范Linux服务器网卡及主机名命名Linux服务器上网DNS设置Linux服务器默认网卡配置文件在/e…...

AI 写作一键生成超简单,焦圈儿免费积分福利等你来领
「现在写一篇公众号推文,没三四个小时都下不来。」一位做个人 IP 的朋友跟我抱怨。问题不在于工具太少,而在于门槛太高, 要么你得自己熬夜改稿,要么你得学一堆复杂 Prompt,才能把 AI 伺候好。内容行业正在进入一个悖论…...

VMware 17 开机自启实战:从配置到故障排查的完整指南
1. VMware 17开机自启基础配置 很多运维工程师在生产环境中都会遇到这样的需求:让VMware虚拟机像系统服务一样随宿主机自动启动。这个功能对于无人值守的服务器、工控机等场景特别重要。下面我就以VMware Workstation 17为例,手把手教你配置全过程。 首…...

ModelSim TCL脚本自动化仿真:从基础到IP核集成的实战指南
1. ModelSim TCL脚本自动化仿真入门 第一次接触ModelSim仿真时,我也像大多数人一样在GUI界面里手动添加文件、设置波形。直到遇到一个包含200多个信号的项目,反复点击鼠标的操作让我彻底崩溃。这时才发现,TCL脚本才是FPGA工程师的救星。 TCL&…...

AI Agent Harness Engineering 后端架构选型:微服务 vs 单体架构的取舍
AI Agent Harness Engineering 后端架构选型深度指南:微服务 vs 单体架构的取舍、落地与最佳实践 摘要/引言 你有没有过这样的经历:团队好不容易赶完了AI Agent的POC验证,正准备规模化落地,却卡在了后端架构选型上? 有人说“微服务是未来”,上来就拆了8个服务,结果3个后…...

开发过程中如何利用Taotoken的容灾路由保障服务高可用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发过程中如何利用Taotoken的容灾路由保障服务高可用 在构建依赖大模型API的企业级应用时,服务的持续可用性是核心考量…...

【公安基础知识】01
治安管理处罚- 行政处罚 治安管理处罚- 行政处罚概念特点处罚种类适用范围违反行为处罚程序立案(旧 受案)调查 &&&&&&&&&&&&&&&&&&&&&&&&&&&…...