Python机器学习 Tensorflow + keras 实现CNN
一、实验目的
1. 了解SkLearn Tensorlow使用方法
2. 了解SkLearn keras使用方法
二、实验工具:
1. SkLearn
三、实验内容 (贴上源码及结果)
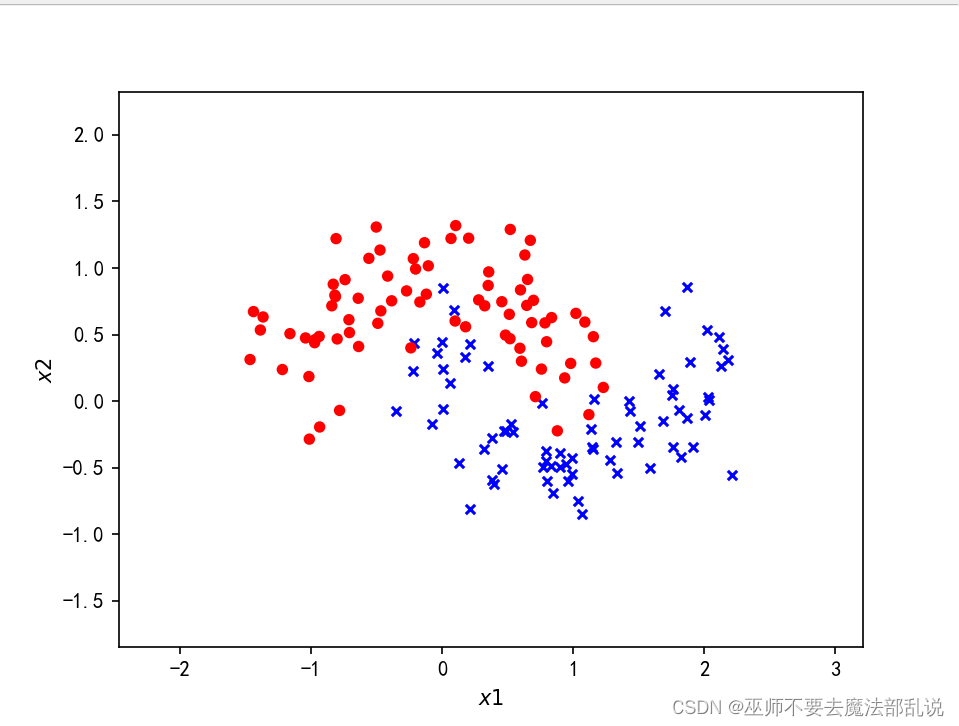
使用Tensorflow对半环形数据集分
#encoding:utf-8import numpy as npfrom sklearn.datasets import make_moonsimport tensorflow as tffrom sklearn.model_selection import train_test_splitfrom tensorflow.keras import layers,Sequential,optimizers,losses, metricsfrom tensorflow.keras.layers import Denseimport matplotlib.pyplot as plt#产生一个半环形数据集X,y= make_moons(200,noise=0.25,random_state=100)#划分训练集和测试集X_train,X_test, y_train, y_test= train_test_split(X, y, test_size=0.25,random_state=2)print(X.shape,y.shape)def make_plot(X,y,plot_name,XX=None, YY=None, preds=None):plt.figure()axes = plt.gca()x_min=X[:,0].min()-1x_max=X[:,0].max()+ 1y_min=X[:,1].min()-1y_max=X[:,1].max()+ 1axes.set_xlim([x_min,x_max])axes.set_ylim([y_min,y_max])axes.set(xlabel="$x 1$",ylabel="$x 2$")if XX is None and YY is None and preds is None:yr = y.ravel()for step in range(X[:,0].size):if yr[step]== 1:plt.scatter(X[step,0],X[step,1],c='b',s=20,edgecolors='none',marker='x')else:plt.scatter(X[step,0],X[step,1],c='r',s=30,edgecolors='none',marker='o')plt.show()else:plt.contour(XX,YY,preds,cmap=plt.cm.spring,alpha=0.8)plt.scatter(X[:, 0], X[:, 1], c = y, s = 20, cmap=plt.cm.Greens, edgecolors = 'k')plt.rcParams['font.sans-serif'] =['SimHei']plt.rcParams['axes.unicode_minus'] = Falseplt.title(plot_name)plt.show()make_plot(X, y, None)# 创建容器model = Sequential()# 创建第一层model.add(Dense(8, input_dim = 2, activation = 'relu'))for _ in range(3):model.add(Dense(32, activation='relu'))# 创建最后一层,激活model.add(Dense(1, activation='sigmoid'))model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])history = model.fit(X_train, y_train, epochs = 30, verbose = 1)# 绘制决策曲线x_min = X[:,0].min() - 1x_max = X[:, 0].max() + 1y_min = X[:1].min() - 1y_max = X[:, 1].max() + 1XX, YY = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))Z = np.argmax(model.predict(np.c_[XX.ravel(), YY.ravel()]), axis=-1)preds =Z.reshape(XX.shape)title = "分类结果"make_plot(X_train, y_train, title, XX, YY, preds)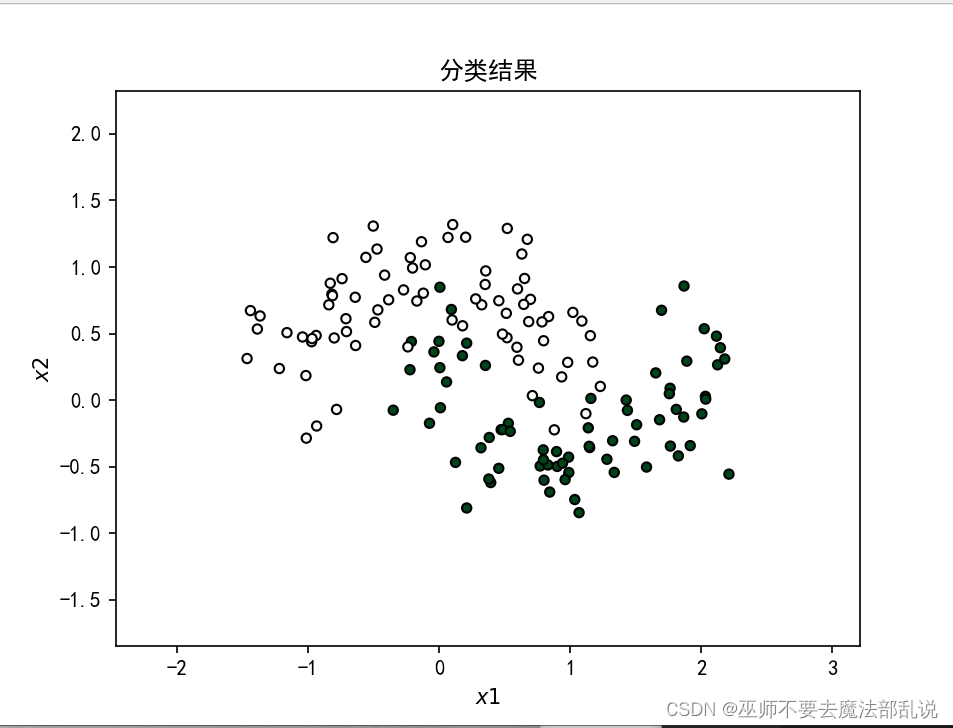
使用VGGNet 识别猫狗
from tensorflow import keras from keras.applications.resnet import ResNet50 from keras.preprocessing import image# #手写文字识别 from keras.applications.resnet import preprocess_input,decodimport numpy as np# #载人 MNIST 数据集 from PIL import ImageFont,ImageDraw,Image# #拆分数据集 # (x_train,y_train),(x_test,y_test)= mnist.load_data() # #将样本进行预处理,并从整数转换为浮点数 # x_train,x_test=x_train/255.0,x_test /255.0 img1=r'C:\Users\PDHuang\Downloads\ch11\dog.jpg'# #使用 tf.kerasimg2=r'C:\Users\PDHuang\Downloads\ch11\cat.jpg'# model= tf.keimg3=r'C:\Users\PDHuang\Downloads\ch11\deer.jpg'# tf.keras.laweight_path=r'C:\Users\PDHuang\Downloads\ch11\resnet50_weightimg=image.load_img(img1,target_size=(224,224))# tf.keras.x=image.img_to_array(img)# tf.keras.layers.Dense(10,activx=np.expand_dims(x,axis=0)# ]) x=preprocess_input(x)# #设置模型的优化器和损失函数 def get_model():# model.compile(optimizer='adam',loss='sparsemodel=ResNet50(weights=weight_path)# #训练并验证模型 print(model.summary())# model.fit(x_train,y_train,epochs=return model# model.evaluate(x_test,y_test,verbose=2) model=get_model() #预测图片 preds=model.predict(x) #打印出top-5的结果 print('predicted',decode_predictions(preds,top=5)[0]) 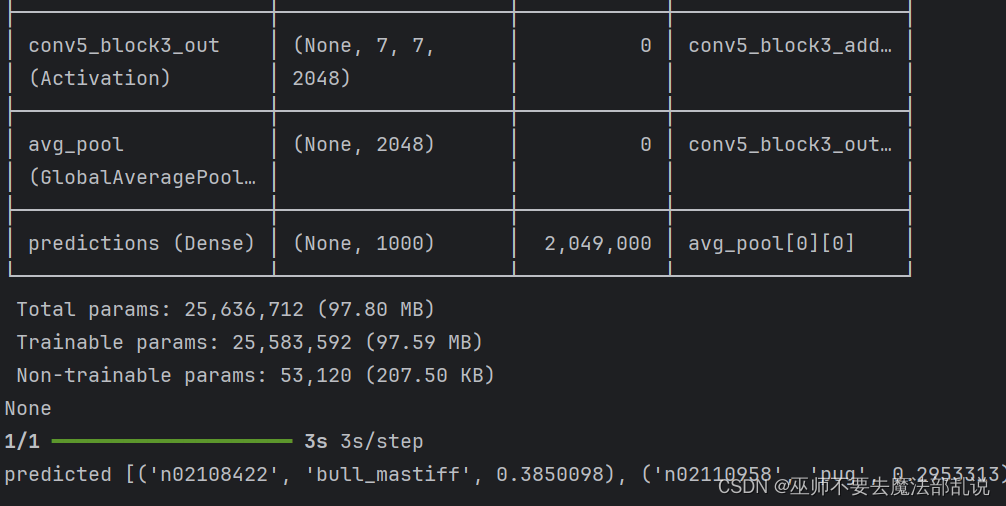
使用深度学习进行手写数字识别
#手写文字识别 import tensorflow as tf #载人 MNIST 数据集 mnist= tf.keras.datasets.mnist #拆分数据集 (x_train,y_train),(x_test,y_test)= mnist.lo#将样本进行预处理,并从整数转换为浮点数 x_train,x_test=x_train/255.0,x_test /255.0#使用 tf.keras.Sequential将模型的各层堆看,并设置参数 model= tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28tf.keras.layers.Dense(128,activation='rtf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10,activation='so]) #设置模型的优化器和损失函数 model.compile(optimizer='adam',loss='sparse#训练并验证模型 model.fit(x_train,y_train,epochs=5) model.evaluate(x_test,y_test,verbose=2) 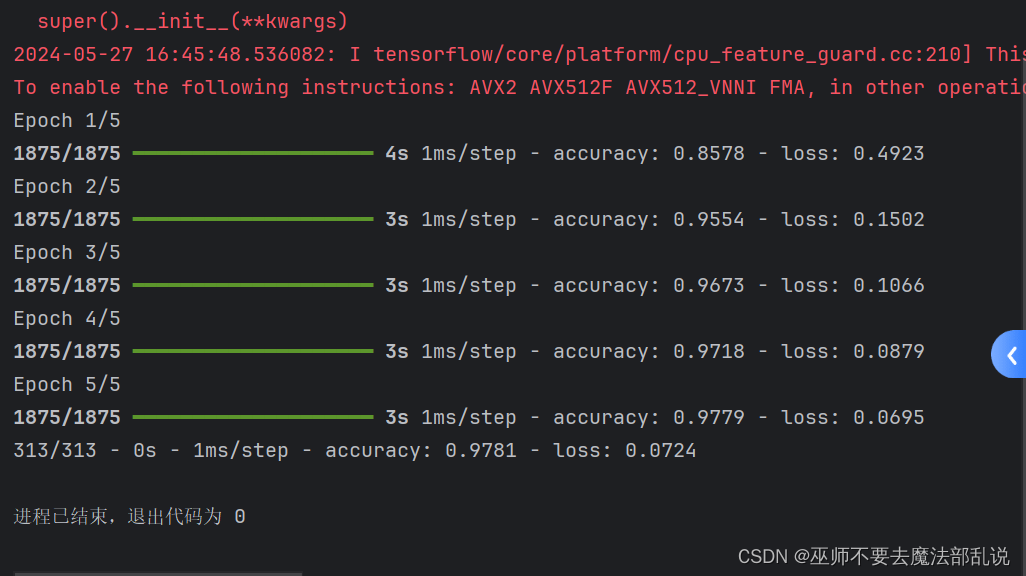
使用Tensorflow + keras 实现人脸识别
from os import listdirimport numpy as npfrom PIL import Imageimport cv2from spyder.plugins.findinfiles.widgets.combobox import FILE_PATHfrom tensorflow.keras.models import Sequential, load_modelfrom tensorflow.keras.layers import Dense, Activation, Convolution2D,MaxPooling2D,Flattenfrom sklearn.model_selection import train_test_splitfrom tensorflow.python.keras.utils import np_utils#读取人脸图片数据def img2vector(fileNamestr):#创建向量returnVect=np.zeros((57,47))image = Image.open(fileNamestr).convert('L')img=np.asarray(image).reshape(57,47)return img#制作人脸数据集def GetDataset(imgDataDir):print('| Step1 |: Get dataset...')imgDataDir='C:/Users/PDHuang/Downloads/ch11/faces_4/'FileDir=listdir(imgDataDir)m= len(FileDir)imgarray=[]hwLabels=[]hwdata=[]#逐个读取文件for i in range(m):#提取子目录className=isubdirName='C:/Users/PDHuang/Downloads/ch11/faces_4/'+str(FileDir[i])+'/'fileNames= listdir(subdirName)lenFiles=len(fileNames)#提取文件名for j in range(lenFiles):fileNamestr=subdirName+fileNames[j]hwLabels.append(className)imgarray=img2vector(fileNamestr)hwdata.append(imgarray)hwdata= np.array(hwdata)return hwdata,hwLabels,6# CNN 模型类class MyCNN(object):FILE_PATH= 'C:/Users/PDHuang/Downloads/ch11/face_recognition.h5'picHeight=57picwidth=47#模型存储/读取目录#模型的人脸图片长47,宽57def __init__(self):self.model = None#获取训练数据集def read_trainData(self,dataset):self.dataset=dataset#建立 Sequential模型,并赋予参数def build_model(self):print('| step2 |:Init CNN model...')self.model=Sequential()print('self.dataset.x train.shape[1:]',self.dataset.X_train.shape[1:])self.model.add(Convolution2D(filters=32,kernel_size=(5,5),padding='same',#dim ordering='th',input_shape=self.dataset.X_train.shape[1:]))self.model.add(Activation('relu'))self.model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2),padding='same'))self.model.add(Convolution2D(filters=64,kernel_size=(5,5),padding='same'))self.model.add(Activation('relu'))self.model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2),padding='same'))self.model.add(Flatten())self.model.add(Dense(512))self.model.add(Activation('relu'))self.model.add(Dense(self.dataset.num_classes))self.model.add(Activation('softmax'))self.model.summary()# 模型训练def train_model(self):print('| Step3 l: Train CNN model...')self.model.compile(optimizer='adam', loss='categorical_crossentropy',metrics = ['accuracy'])# epochs:训练代次;batch size:每次训练样本数self.model.fit(self.dataset.X_train, self.dataset.Y_train, epochs=10,batch_size=20)def evaluate_model(self):loss, accuracy = self.model.evaluate(self.dataset.X_test, self.dataset.Y_test)print('|Step4|:Evaluate performance...')print('=------=---------------------=----')print('Loss Value is:', loss)print('Accuracy Value is :', accuracy)def save(self, file_path = FILE_PATH):print('| Step5 l: Save model...')self.model.save(file_path)print('Model',file_path, 'is successfully saved.')def predict(self, input_data):prediction = self.model.predict(input_data)return prediction#建立一个用于存储和格式化读取训练数据的类class DataSet(object):def __init__(self, path):self.num_classes = Noneself.X_train = Noneself.X_test = Noneself.Y_train = Noneself.Y_test = Noneself.picwidth=47self.picHeight=57self.makeDataSet(path)#在这个类初始化的过程中读取path下的训练数据def makeDataSet(self, path):#根据指定路径读取出图片、标签和类别数imgs,labels,classNum = GetDataset(path)#将数据集打乱随机分组X_train,X_test,y_train,y_test= train_test_split(imgs, labels, test_size=0.2,random_state=1)#重新格式化和标准化X_train=X_train.reshape(X_train.shape[0],1,self.picHeight, self.picwidth)/255.0X_test=X_test.reshape(X_test.shape[0],1,self.picHeight, self.picwidth)/255.0X_train=X_train.astype('float32')X_test=X_test.astype('float32')#将labels 转成 binary class matricesY_train=np_utils.to_categorical(y_train, num_classes=classNum)Y_test =np_utils.to_categorical(y_test,num_classes=classNum)#将格式化后的数据赋值给类的属性上self.X_train=X_trainself.X_test=X_testself.Y_train= Y_trainself.Y_test = Y_testself.num_classes=classNum#人脸图片目录dataset= DataSet('C:/Users/PDHuang/Downloads/ch11/faces_4/')model = MyCNN()model.read_trainData(dataset)model.build_model()model.train_model()model.evaluate_model()model.save()import osimport cv2import numpy as npfrom tensorflow.keras.models import load_modelhwdata =[]hwLabels =[]classNum = 0picHeight=57picwidth=47#人物标签(编号 0~5)#图像高度#图像宽度#根据指定路径读取出图片、标签和类别数hwdata,hwLabels,classNum= GetDataset('C:/Users/PDHuang/Downloads/ch11/faces_4/')#加载模型if os.path.exists('face recognition.h5'):model= load_model('face recognition.h5')else:print('build model first')#加载待判断图片photo= cv2.imread('C:/Users/PDHuang/Downloads/ch11/who.jpg')#待判断图片调整resized_photo=cv2.resize(photo,(picHeight, picwidth)) #调整图像大小recolord_photo=cv2.cvtColor(resized_photo, cv2.COLOR_BGR2GRAY)#将图像调整成灰度图recolord_photo= recolord_photo.reshape((1,1,picHeight,picwidth))recolord_photo= recolord_photo/255#人物预测print('| Step3 |:Predicting......')result = model.predict(recolord_photo)max_index=np.argmax(result)#显示结果print('The predict result is Person',max_index+ 1)cv2.namedWindow("testperson",0);cv2.resizeWindow("testperson",300,350);cv2.imshow('testperson',photo)cv2.namedWindow("PredictResult",0);cv2.resizeWindow("PredictResult",300,350);cv2.imshow("predictResult",hwdata[max_index * 10])#print(resultrile)k= cv2.waitKey(0)#按Esc 键直接退出if k == 27:cv2.destroyWindow()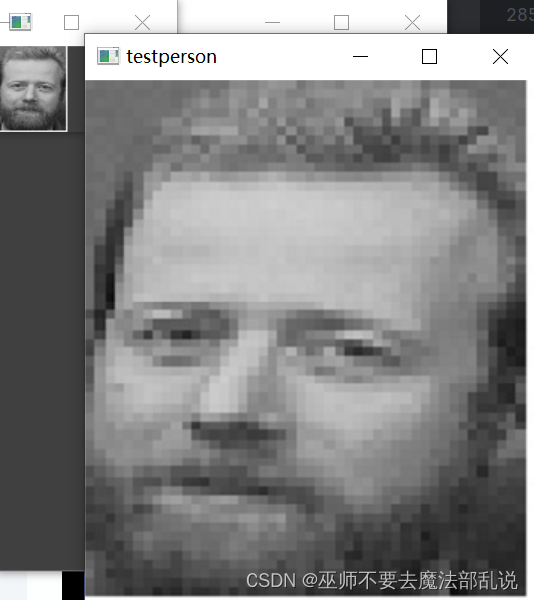
使用Tensorflow + keras 实现电影评论情感分类
# 导包import matplotlib as mplimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport os# 导入tfimport tensorflow as tffrom tensorflow import kerasprint(tf.__version__)print(keras.__version__)# 加载数据集# num_words:只取10000个词作为词表imdb = keras.datasets.imdb(train_x_all, train_y_all),(test_x, test_y)=imdb.load_data(num_words=10000)# 查看数据样本数量print("Train entries: {}, labels: {}".format(len(train_x_all), len(train_y_all)))print("Train entries: {}, labels: {}".format(len(test_x), len(test_y)))print(train_x_all[0]) # 查看第一个样本数据的内容print(len(train_x_all[0])) # 查看第一个和第二个训练样本的长度,不一致print(len(train_x_all[1]))# 构建字典 两个方法,一个是id映射到字,一个是字映射到idword_index = imdb.get_word_index()word2id = { k:(v+3) for k, v in word_index.items()}word2id['<PAD>'] = 0word2id['START'] = 1word2id['<UNK>'] = 2word2id['UNUSED'] = 3id2word = {v:k for k, v in word2id.items()}def get_words(sent_ids):return ' '.join([id2word.get(i, '?') for i in sent_ids])sent = get_words(train_x_all[0])print(sent)# 句子末尾进行填充train_x_all = keras.preprocessing.sequence.pad_sequences(train_x_all,value=word2id['<PAD>'],padding='post', #pre表示在句子前面填充, post表示在句子末尾填充maxlen=256)test_x = keras.preprocessing.sequence.pad_sequences(test_x,value=word2id['<PAD>'],padding='post',maxlen=256)print(train_x_all[0])print(len(train_x_all[0]))print(len(train_x_all[1]))#模型编写vocab_size = 10000model = keras.Sequential()model.add(keras.layers.Embedding(vocab_size, 16))model.add(keras.layers.GlobalAveragePooling1D())model.add(keras.layers.Dense(16, activation='relu'))model.add(keras.layers.Dense(1, activation='sigmoid'))model.summary()model.compile(optimizer='adam', loss=keras.losses.binary_crossentropy, metrics=['accuracy'])train_x, valid_x = train_x_all[10000:], train_x_all[:10000]train_y, valid_y = train_y_all[10000:], train_y_all[:10000]# callbacks Tensorboard, earlystoping, ModelCheckpoint# 创建一个文件夹,用于放置日志文件logdir = os.path.join("callbacks")if not os.path.exists(logdir):os.mkdir(logdir)output_model_file = os.path.join(logdir, "imdb_model.keras")# 当训练模型到什么程度的时候,就停止执行 也可以直接不用,然后直接训练callbacks = [# 保存的路径(使用TensorBoard就可以用命令,tensorboard --logdir callbacks 来分析结果)keras.callbacks.TensorBoard(logdir),# 保存最好的模型keras.callbacks.ModelCheckpoint(filepath=output_model_file, save_best_only=True),# 当精度连续5次都在1乘以10的-1次方之后停止训练keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3)]history = model.fit(train_x, train_y,epochs=40,batch_size=512,validation_data=(valid_x, valid_y),callbacks = callbacks,verbose=1 # 设置为1就会打印日志到控制台,0就不打印)def plot_learing_show(history):pd.DataFrame(history.history).plot(figsize=(8,5))plt.grid(True)plt.gca().set_ylim(0,1)plt.show()plot_learing_show(history)result = model.evaluate(test_x, test_y)print(result)test_classes_list = model.predict_classes(test_x)print(test_classes_list[1][0])print(test_y[1])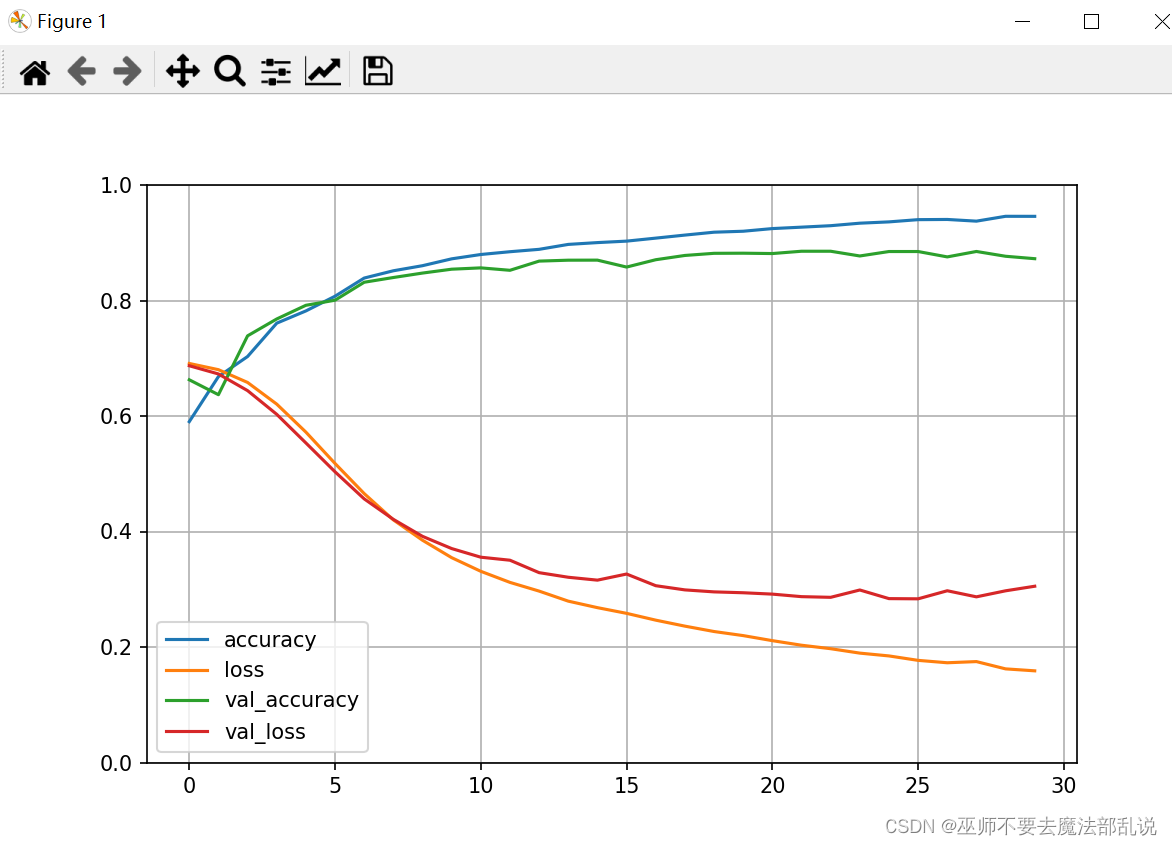
使用Tensorflow + keras 解决 回归问题预测汽车燃油效率
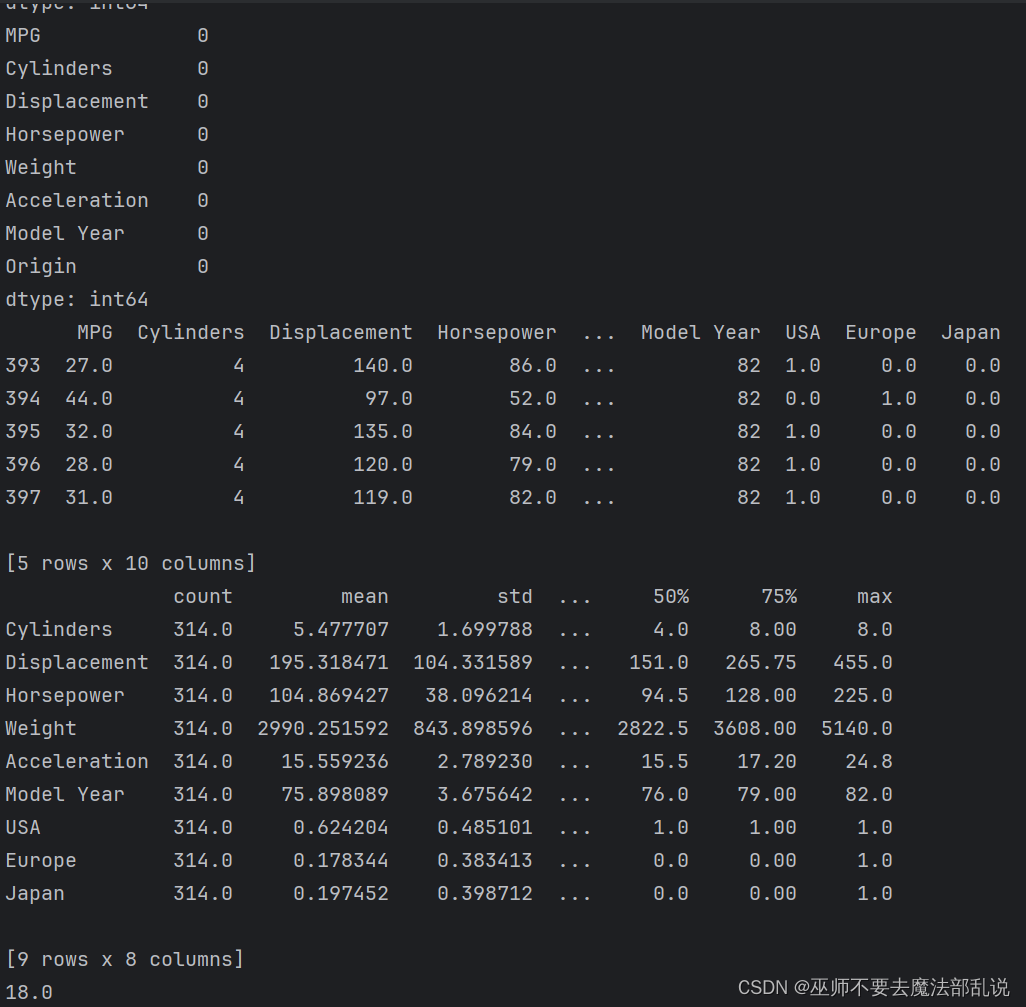
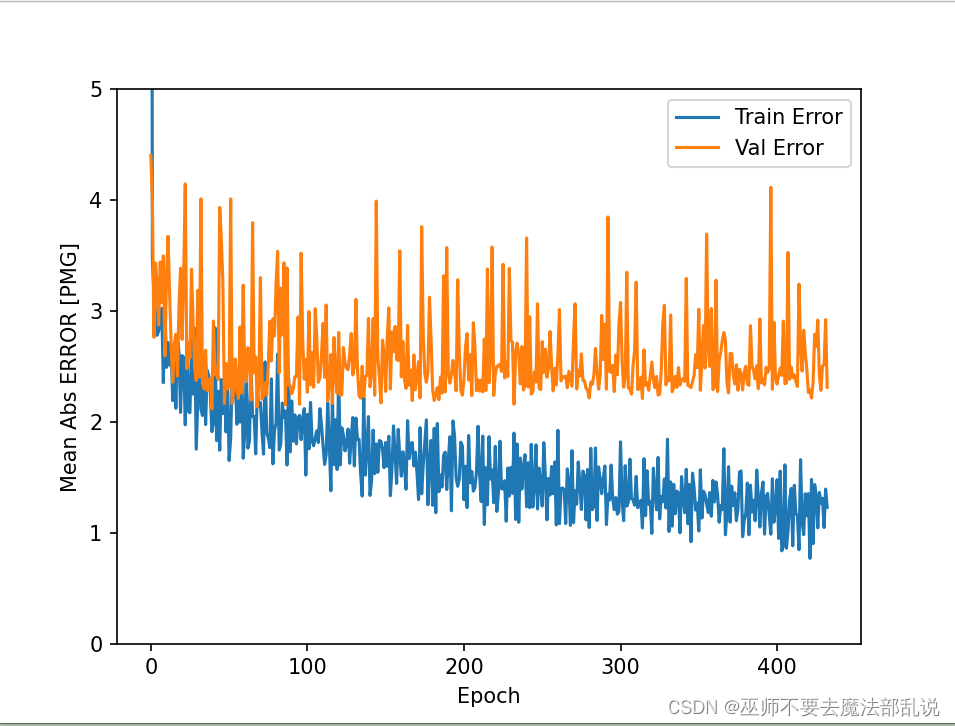
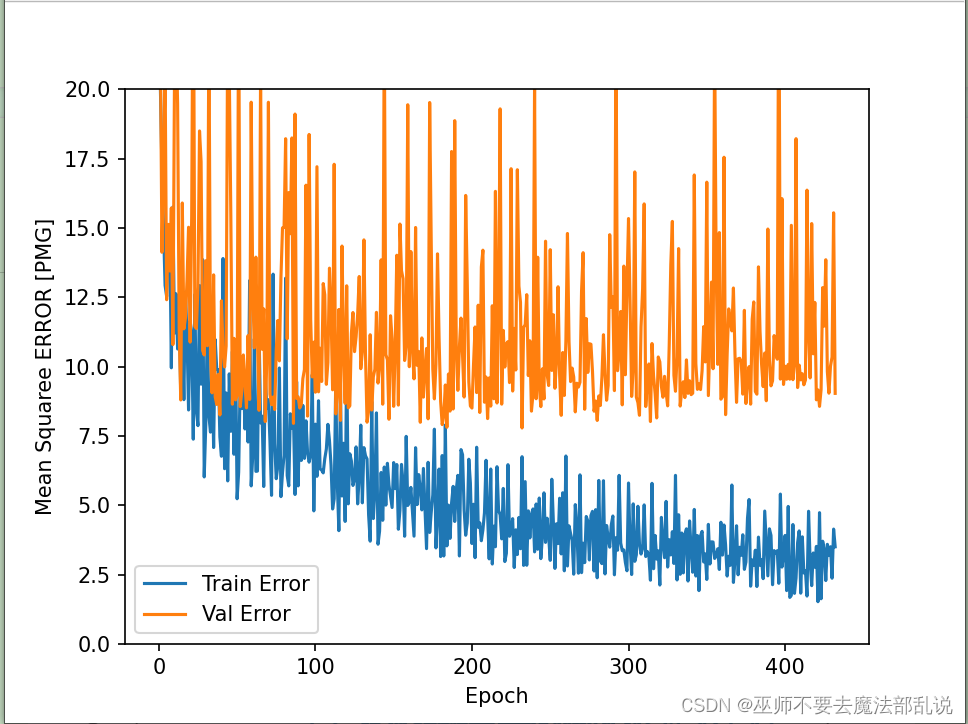
# 导包import matplotlib as mplimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport osimport pathlibimport seaborn as sns# 导入tfimport tensorflow as tffrom tensorflow import kerasprint(tf.__version__)print(keras.__version__)# 加载数据集dataset_path = keras.utils.get_file('auto-mpg.data',"http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")print(dataset_path)# 使用pandas导入数据集column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight', 'Acceleration', 'Model Year', 'Origin']raw_dataset = pd.read_csv(dataset_path, names=column_names, na_values='?', comment='\t',sep=' ', skipinitialspace=True)dataset = raw_dataset.copy()print(dataset.tail())# 数据清洗print(dataset.isna().sum())dataset = dataset.dropna()print(dataset.isna().sum())# 将origin转换成one-hot编码origin = dataset.pop('Origin')dataset['USA'] = (origin == 1) * 1.0dataset['Europe'] = (origin == 2) * 1.0dataset['Japan'] = (origin == 3) * 1.0print(dataset.tail())# 拆分数据集 拆分成训练集和测试集train_dataset = dataset.sample(frac=0.8, random_state=0)test_dataset = dataset.drop(train_dataset.index)# 总体数据统计train_stats = train_dataset.describe()train_stats.pop("MPG")train_stats = train_stats.transpose()print(train_stats)# 从标签中分类特征train_labels = train_dataset.pop('MPG')test_labels = test_dataset.pop('MPG')print(train_labels[0])# 数据规范化def norm(x):return (x - train_stats['mean']) / train_stats['std']norm_train_data = norm(train_dataset)norm_test_data = norm(test_dataset)# 构建模型def build_model():model = keras.Sequential([keras.layers.Dense(512, activation='relu', input_shape=[len(train_dataset.keys())]),keras.layers.Dense(256, activation='relu'),keras.layers.Dense(128, activation='relu'),keras.layers.Dense(64, activation='relu'),keras.layers.Dense(1)])optimizer = keras.optimizers.RMSprop(0.001)model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])return model# 构建防止过拟合的模型,加入正则项L1和L2def build_model2():model = keras.Sequential([keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001),input_shape=[len(train_dataset.keys())]),keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),keras.layers.Dense(1)])optimizer = keras.optimizers.RMSprop(0.001)model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])return model# 构建防止过拟合的模型,加入正则项L1def build_model3():model = keras.Sequential([keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001),input_shape=[len(train_dataset.keys())]),keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001)),keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001)),keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l1(0.001)),keras.layers.Dense(1)])optimizer = keras.optimizers.RMSprop(0.001)model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])return model# 构建防止过拟合的模型,加入正则项L2def build_model4():model = keras.Sequential([keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001),input_shape=[len(train_dataset.keys())]),keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)),keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)),keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l2(0.001)),keras.layers.Dense(1)])optimizer = keras.optimizers.RMSprop(0.001)model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])return model# 构建模型 使用dropout来防止过拟合def build_model5():model = keras.Sequential([keras.layers.Dense(512, activation='relu', input_shape=[len(train_dataset.keys())]),keras.layers.Dropout(0.5),keras.layers.Dense(256, activation='relu'),keras.layers.Dropout(0.5),keras.layers.Dense(128, activation='relu'),keras.layers.Dropout(0.5),keras.layers.Dense(64, activation='relu'),keras.layers.Dropout(0.5),keras.layers.Dense(1)])optimizer = keras.optimizers.RMSprop(0.001)model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])return model# 构建模型 使用正则化L1和L2以及dropout来预测def build_model6():model = keras.Sequential([keras.layers.Dense(512, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001),input_shape=[len(train_dataset.keys())]),keras.layers.Dropout(0.5),keras.layers.Dense(256, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),keras.layers.Dropout(0.5),keras.layers.Dense(128, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),keras.layers.Dropout(0.5),keras.layers.Dense(64, activation='relu', kernel_regularizer=keras.regularizers.l1_l2(0.001)),keras.layers.Dropout(0.5),keras.layers.Dense(1)])optimizer = keras.optimizers.RMSprop(0.001)model.compile(loss='mse', optimizer=optimizer, metrics=['mae', 'mse'])return modelmodel = build_model()model.summary()early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=200)# 模型训练history = model.fit(norm_train_data, train_labels, epochs=1000, validation_split=0.2, verbose=0, callbacks=[early_stop])def plot_history(history):hist = pd.DataFrame(history.history)hist['epoch'] = history.epochplt.figure()plt.xlabel('Epoch')plt.ylabel('Mean Abs ERROR [PMG]')plt.plot(hist['epoch'], hist['mae'], label='Train Error')plt.plot(hist['epoch'], hist['val_mae'], label='Val Error')plt.ylim([0, 5])plt.legend()plt.figure()plt.xlabel('Epoch')plt.ylabel('Mean Squaree ERROR [PMG]')plt.plot(hist['epoch'], hist['mse'], label='Train Error')plt.plot(hist['epoch'], hist['val_mse'], label='Val Error')plt.ylim([0, 20])plt.legend()plt.show()plot_history(history)# 看下测试集合的效果loss, mae, mse = model.evaluate(norm_test_data, test_labels, verbose=2)print(loss)print(mae)print(mse)# 做预测test_preditions = model.predict(norm_test_data)test_preditions = test_preditions.flatten()plt.scatter(test_labels, test_preditions)plt.xlabel('True Values [MPG]')plt.ylabel('Predictios [MPG]')plt.axis('equal')plt.axis('square')plt.xlim([0, plt.xlim()[1]])plt.ylim([0, plt.ylim()[1]])_ = plt.plot([-100, 100], [-100, 100])# 看一下误差分布error = test_preditions - test_labelsplt.hist(error, bins=25)plt.xlabel("Prediction Error [MPG]")_ = plt.ylabel('Count')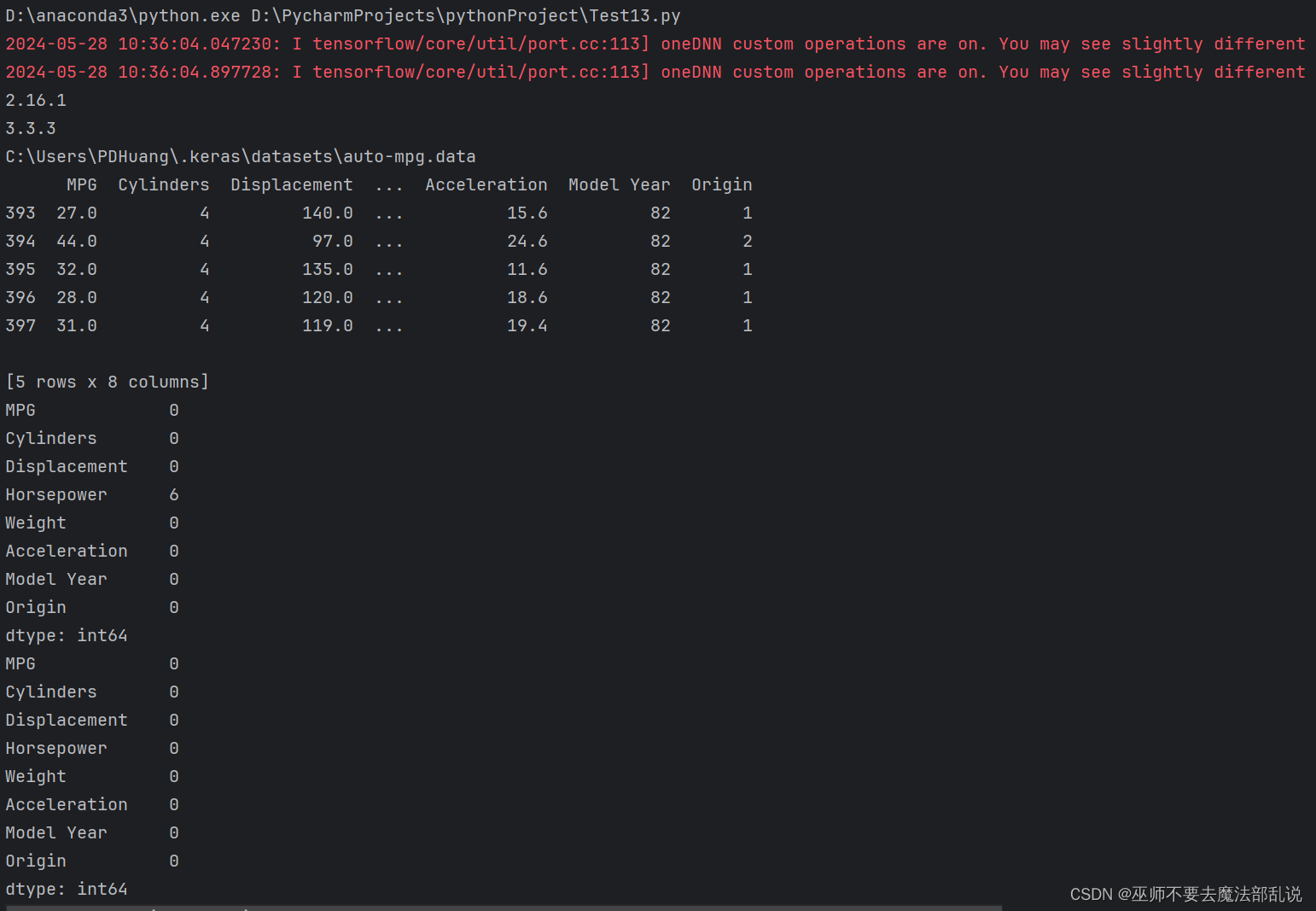

相关文章:
Python机器学习 Tensorflow + keras 实现CNN
一、实验目的 1. 了解SkLearn Tensorlow使用方法 2. 了解SkLearn keras使用方法 二、实验工具: 1. SkLearn 三、实验内容 (贴上源码及结果) 使用Tensorflow对半环形数据集分 #encoding:utf-8import numpy as npfrom sklearn.datasets i…...

基于事件的架构工作机制和相关产品
基于事件的架构 基于事件的架构可否这样理解,每个事件相当于传统API的一次函数调用请求,比如Add(123,456)。区别在于,基于事件的架构只是把这个请求发出,并不急于得到结果,而是等合适的子系统处理完这个请求ÿ…...
OSINT 与心理学:通过开源情报进行剖析和行为分析
在不断发展的心理学领域,人们越来越认识到通过应用开源情报 (OSINT) 方法取得进步的潜力。OSINT 主要以其在安全和情报领域的应用而闻名,并且越来越多地展示其在心理分析和行为分析方面的潜力。本文探讨了 OSINT 和心理学的迷人交叉点,研究如…...

yarn 设置淘宝镜像配置
为了提升在中国大陆地区的下载速度,你可以将Yarn的包仓库配置为淘宝镜像。最新的推荐做法是使用npmmirror.com作为镜像源,替代旧的npm.taobao.org。以下是设置Yarn使用淘宝镜像(npmmirror.com)的步骤: 查询当前镜像配置…...

debian 常用命令
Debian 是一个广泛使用的 Linux 发行版,这里列出了一些常用的 Debian 命令,适用于系统管理和日常使用: ### 文件与目录操作 1. **ls** - 列出目录内容: bash ls ls -l # 长格式显示 ls -a # 显示所有文件ÿ…...
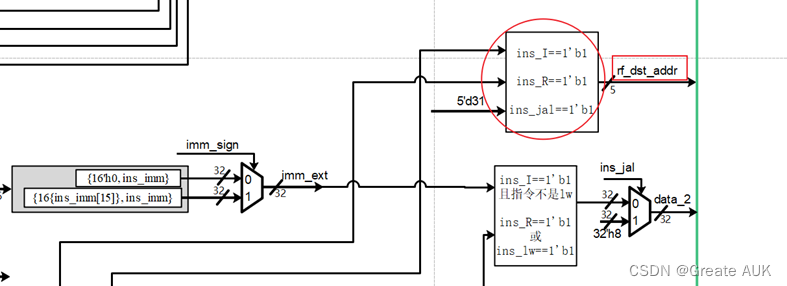
流水账(CPU设计实战)——lab3
Lab3 Rewrite V1.0 版本控制 版本描述V0V1.0相对V0变化: 修改了文件名,各阶段以_stage结尾(因为if是关键词,所以module名不能叫if,遂改为if_stage,为了统一命名,将所有module后缀加上_stage&a…...

k8s集群配置普通用户权限
集群管理员:负责管理 Kubernetes 集群的用户,拥有最高权限,可以对集群中的资源进行任何操作。 开发者:在 Kubernetes 集群中部署和管理自己的应用,可能有限制的权限,仅能管理特定的命名空间或资源。 第三…...

clickhouse——clickhouse单节点部署及基础命令介绍
clickhouse支持运行在主流的64位CPU架构的linux操作系统之上,可以通过源码编译,预编译压缩包,docker镜像和rpm等多种方式进行安装。 一、单节点部署 1、安装curl工具 yum install -y curl 2、添加clickhouse的yum镜像 curl -s https://pack…...
)
MATLAB基础应用精讲-【数模应用】价格敏感度PSM分析(附python代码实现)
目录 前言 算法原理 什么是价格敏感度分析? 原理 示例 PSM用途...

数据驱动的UI艺术:智能设计的视觉盛宴
数据驱动的UI艺术:智能设计的视觉盛宴 引言 在当今这个数据泛滥的时代,大数据不仅仅是一种技术手段,它更是一种艺术形式。当大数据遇上UI设计,两者的结合便催生了一种全新的艺术形式——数据驱动的UI艺术。本文将探讨如何将数据…...

栈的特性及代码实现(C语言)
目录 栈的定义 栈的结构选取 链式储存结构和顺序栈储存结构的差异 栈的代码实现 "stack.h" "stack.c" 总结 栈的定义 栈:栈是限定仅在表尾进行插入和删除操作的线性表。 我们把运行插入的和删除的一段叫做栈顶(TOPÿ…...
防火墙如何端口映射?
防火墙端口映射(Firewall Port Mapping)是一种网络技术,通过对防火墙配置进行调整,允许外部网络用户访问内部网络中的指定端口。该技术使得外部用户可以通过公共网络访问内部网络中的特定服务或应用程序,从而实现远程访…...

咖啡看书休闲时光404错误页面源码
源码介绍 咖啡看书休闲时光404错误页面源码,源码由HTMLCSSJS组成,记事本打开源码文件可以进行内容文字之类的修改,双击html文件可以本地运行效果,也可以上传到服务器里面,重定向这个界面 源码效果 源码下载 咖啡看书…...

中央事件bus
中央事件bus的使用 使用场景:当需要传递给多个组件的时候例如父组件->子组件->孙组件,甚至还得传递到更深的组件的时候中央事件就起到了作用,不需要一直传递。bus其实就是一个发布订阅模式,利用vue的自定义事件机制 // 事…...

中国上市企业行业异质性数据分析
数据简介:企业行业异质性数据是指不同行业的企业在运营、管理、财务等方面的差异性数据。这些数据可以反映不同行业企业的特点、优势和劣势,以及行业间的异质性对企业经营和投资的影响。通过对企业行业异质性数据的分析,投资者可以更好地了解…...
【全开源】防伪溯源一体化管理系统源码(FastAdmin+ThinkPHP和Uniapp)
一款基于FastAdminThinkPHP和Uniapp进行开发的多平台(微信小程序、H5网页)溯源、防伪、管理一体化独立系统,拥有强大的防伪码和溯源码双码生成功能(内置多种生成规则)、批量大量导出防伪和溯源码码数据、支持代理商管理…...

鸿蒙ArkUI-X跨语言调用说明:【平台桥接(@arkui-x.bridge)】
平台桥接(arkui-x.bridge) 简介 平台桥接用于客户端(ArkUI)和平台(Android或iOS)之间传递消息,即用于ArkUI与平台双向数据传递、ArkUI侧调用平台的方法、平台调用ArkUI侧的方法。 以Android平台为例,Ark…...

ts面试题: 面试题2
31. 计算字符串长度 // 计算字符串的长度,类似于 String#length 。答案 type test Str1<"abc123">; type Str1<T extends string, L extends any[] []> T extends ${infer f}${infer b} ? Str1<b, [...L, f]> : L[length];32. 接…...
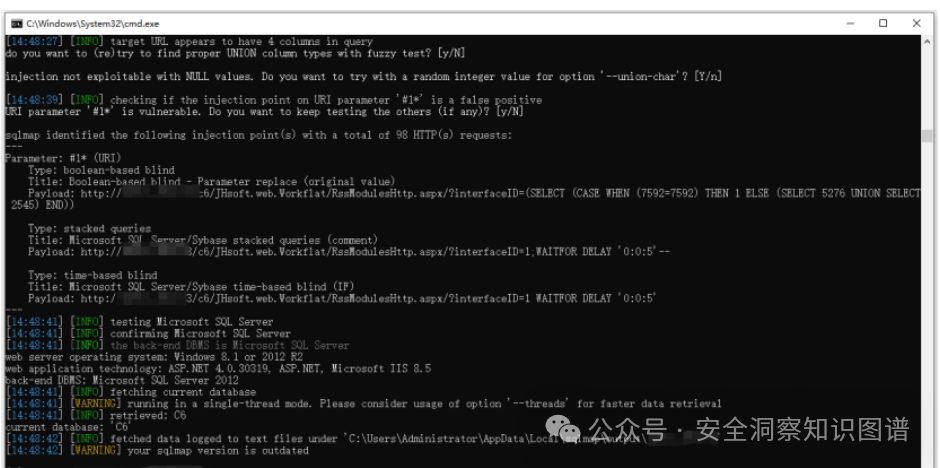
.NET 某和OA办公系统全局绕过漏洞分析
转自先知社区 作者:dot.Net安全矩阵 原文链接:.NET 某和OA办公系统全局绕过漏洞分析 - 先知社区 0x01 前言 某和OA协同办公管理系统C6软件共有20多个应用模块,160多个应用子模块,从功能型的协同办公平台上升到管理型协同管理平…...
Git-01
Git是一个免费且开源的分布式版本控制系统,它可以跟踪文件的修改、记录变更的历史,并且在多人协作开发中提供了强大的工具和功能。 Git最初是由Linus Torvalds开发的,用于Linux内核的开发,现在已经成为了广泛使用的版本控制系统&a…...

大模型微调实战:用LoRA技术微调LLaMA 2模型
在人工智能技术飞速发展的当下,大语言模型(LLM)在自然语言处理领域展现出了强大的能力。LLaMA 2作为Meta推出的开源大模型,凭借其出色的性能和广泛的适用性,成为了众多开发者和研究人员的首选。对于软件测试从业者而言…...
)
告别手动传Token!用JMeter的JSON Extractor搞定接口自动化登录(附实战配置)
告别手动传Token!用JMeter的JSON Extractor实现无缝接口自动化登录 在接口测试的世界里,登录态管理就像一场永无止境的接力赛——每次请求都需要准确传递Token这个"接力棒"。传统的手工复制粘贴Token不仅效率低下,更是自动化测试流…...

芯片HAST测试:通电工作下如何精准模拟极端环境挑战?
为了确保产品在高温、高湿等恶劣条件下仍能正常工作,HAST(Highly Accelerated Stress Test)测试成为不可或缺的一部分。本文将深入解析HAST测试,并探讨如何在通电工作状态下进行精准模拟,以应对极端环境挑战。什么是HA…...

Altium Designer 21 多通道设计保姆级教程:用Repeat语句快速搞定4路蜂鸣器模块
Altium Designer 21 多通道设计实战:4路蜂鸣器模块的高效实现 在复杂的电子系统设计中,我们常常会遇到需要重复使用相同功能模块的情况。传统的手动复制粘贴不仅效率低下,更会给后期维护带来巨大挑战。Altium Designer 21的多通道设计功能正…...

人机协同中AI的示弱策略
在人机协同中,AI的“示弱策略”并非指AI真的能力不足,而是一种主动暴露自身局限性、不确定性,从而激发人类智慧、建立信任并优化整体协作效能的高级策略。这种策略的核心在于打破人类对AI“全知全能”的盲目崇拜或恐惧,将人机关系…...

IT6520:USB‑C 转 MIPI 芯片方案 4K@120Hz 高清显示
一、前言平板、便携屏、AR/VR 头显、车载中控、会议终端等设备,对USB‑C 一线通视频输出的需求越来越强。 传统方案必须用:PD 控制器 DP 接收芯片 MIPI 桥接芯片 外置 MCU Flash,多芯片拼凑导致电路复杂、成本高、兼容性差、开发周期长。…...

从MobileNet到HRNet:如何为你的DeepLabV3+项目挑选最合适的PyTorch骨干网络?
从MobileNet到HRNet:DeepLabV3骨干网络选型实战指南 当你面对Pascal VOC数据集上89%的mIoU和Cityscapes上82.1%的基准成绩时,是否思考过这些数字背后隐藏的工程抉择?在图像分割领域,骨干网络的选择往往决定着项目成败——它既影响…...

PyTorch模型从GPU‘搬家’到昇腾Ascend:除了装插件,这些性能调优和环境变量你设置对了吗?
PyTorch模型从GPU到昇腾Ascend的深度迁移指南:性能调优与实战陷阱解析 当我们将PyTorch模型从NVIDIA GPU迁移到华为昇腾Ascend平台时,简单的环境安装只是第一步。真正考验开发者功力的,是如何在异构计算架构间实现性能无损甚至提升的迁移。本…...

基于CircuitPython与RP2040打造可编程USB脚踏开关:从硬件到软件的完整指南
1. 项目概述:为什么你需要一个可编程的脚踏开关? 在剪辑视频、处理音频、写代码或者玩游戏的时候,你的双手是不是永远不够用?频繁地在键盘、鼠标、调音台或者剪辑软件的面板之间切换,不仅效率低下,还容易打…...

从零构建嵌入式Linux平板:基于全志H3与Qt5的实战指南
1. 项目概述:为什么我们要自己动手做一块“平板”?几年前,我在一个嵌入式展会上看到一块工业平板,功能简单但价格不菲。当时我就在想,它的核心无非就是一块屏幕、一个主控板和一个定制的用户界面。既然我们有开源的Lin…...