Filebeat进阶指南:核心架构与功能组件的深度剖析

🐇明明跟你说过:个人主页
🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅
🔖行路有良友,便是天堂🔖
目录
一、引言
1、什么是ELK
2、FileBeat在ELK中的角色
二、FileBeat核心架构
1、Filebeat的整体架构图
2、核心组件 注册表(Registrar)
3、核心组件 爬虫(Harvester)
4、核心组件 发布者(Publisher)
三、 数据传输机制
1、异步发送与确认机制
异步发送机制
确认机制
2、背压(Backpressure)与流量控制
背压(Backpressure)
流量控制
背压与流量控制的工作流程
一、引言
1、什么是ELK
ELK 是一个流行的开源日志管理解决方案,由三个主要组件组成:
- Elasticsearch: 是一个分布式的实时搜索和分析引擎,用于存储、搜索和分析大规模的数据。它是 ELK 堆栈的核心组件,负责处理和存储从日志源收集的数据,并提供灵活的搜索和分析功能。
- Logstash: 是一个用于日志数据收集、转换和传输的数据处理管道。Logstash 可以从多种来源收集数据,如日志文件、消息队列等,然后对数据进行结构化处理和转换,最后将数据发送到 Elasticsearch 或其他目标存储中。
- Kibana: 是一个基于 Web 的用户界面,用于可视化和分析 Elasticsearch 中的数据。Kibana 提供了丰富的图表、图形和仪表板,使用户可以轻松地探索和分析日志数据,并生成各种可视化报告。
ELK 堆栈通常被用于实时日志监控、日志分析、安全事件分析等用途。它的灵活性和可扩展性使其成为许多组织和开发团队首选的日志管理解决方案。

2、FileBeat在ELK中的角色
Filebeat 是 ELK(Elasticsearch、Logstash、Kibana)堆栈中的一个组件,用于从不同的日志文件位置收集数据并将其发送到 Logstash 或者 Elasticsearch 进行进一步处理和分析。它的主要角色是作为一个轻量级的日志收集器,专门负责从各种来源(如日志文件、系统日志等)收集日志数据,并将其传输到其他 ELK 组件进行处理。
Filebeat 的主要功能和角色包括:
- 数据收集:Filebeat 可以监视指定的日志文件、日志目录或者其他位置,并实时地收集其中的日志数据。
- 数据传输:收集到的日志数据被 Filebeat 发送到指定的目标,通常是 Logstash 或者直接发送到 Elasticsearch 进行索引。
- 轻量级:Filebeat 是一个轻量级的日志收集器,具有低内存消耗和低 CPU 占用的特点,适合于在各种环境中部署和运行。
- 模块化配置:Filebeat 提供了丰富的模块化配置选项,可以轻松地配置和管理不同类型日志数据的收集和传输。
总的来说,Filebeat 在 ELK 堆栈中扮演着数据收集和传输的角色,帮助用户将日志数据从各种来源收集起来,并将其传输到 ELK 的其他组件中进行存储、处理和分析。

二、FileBeat核心架构
1、Filebeat的整体架构图
Filebeat是Elastic Stack(通常称为ELK Stack)中的一个轻量级数据发送器,专门用于从日志文件和其他数据源收集和发送数据到Elasticsearch或Logstash。
其架构可以分为以下几个主要部分:
Input(输入):
- Filebeat的输入模块负责读取日志文件的数据。它支持多种类型的输入源,例如文件、stdin等。
- Input模块会监控指定的日志文件路径,当检测到新日志数据时,会立即读取并处理这些数据。
Harvester(采集器):
- 每个输入源都有一个或多个采集器。采集器负责打开并读取具体的日志文件。
- 每个采集器都会跟踪文件的读取位置(偏移量),以便在Filebeat重启时可以从上次读取的位置继续。
Spooler(缓冲区):
- 采集器读取到的数据首先会被发送到缓冲区(Spooler)。
- 缓冲区的作用是临时存储这些数据,以便后续批量发送,提高传输效率。
Publisher(发布者):
- 缓冲区中的日志数据会被Publisher模块取出,并按照预定义的规则进行处理,例如添加元数据、进行数据转换等。
- 处理完成后,Publisher负责将数据发送到输出目的地,例如Elasticsearch、Logstash、Kafka等。
Output(输出):
- Filebeat支持多种输出方式,可以直接将数据发送到Elasticsearch,或者先发送到Logstash进行进一步处理。
- 输出模块根据配置将数据传输到目标系统,并处理网络连接、重试机制等问题,确保数据可靠传输。

2、核心组件 注册表(Registrar)
Filebeat中的核心组件之一是注册表(Registrar)。注册表的主要职责是跟踪和管理Filebeat已经处理的文件的状态,确保在Filebeat重启或发生故障时,能够从正确的位置继续读取日志文件,从而避免数据丢失或重复。
注册表(Registrar)的功能
1. 跟踪文件偏移量:
- Registrar记录每个被监控文件的读取位置(偏移量)。当Filebeat重启时,能够从上次读取的位置继续处理文件。
2. 持久化状态:
- Registrar将这些偏移量和文件状态信息定期持久化到磁盘(通常是一个名为registry的文件)。这保证了即使Filebeat意外停止或重启,日志处理的进度也不会丢失。
3. 管理文件标识:
- Registrar不仅记录文件路径,还记录文件的唯一标识符(如inode),以处理文件轮换(log rotation)的情况。这样可以防止在文件名相同但内容不同的情况下出现混淆。
注册表的工作流程
1. 启动阶段:
- 在Filebeat启动时,Registrar会读取之前保存的注册表文件,恢复文件的读取进度。
2. 运行阶段:
Filebeat的Harvester模块读取日志文件的数据并将当前读取位置的偏移量发送给Registrar。
- Registrar会在内存中更新这些偏移量,并在一定间隔或特定事件(如文件关闭)发生时,将更新后的状态写入到磁盘。
3. 关闭阶段:
- 当Filebeat停止时,Registrar会确保所有的偏移量都被正确地持久化到磁盘,以便下次启动时能够恢复。
3、核心组件 爬虫(Harvester)
Filebeat的核心组件之一是爬虫(Harvester)。Harvester负责实际读取日志文件中的数据,并将这些数据传递给其他组件进行处理和输出。每个Harvester实例对应一个被监控的日志文件,它们独立运行,以确保高效的日志数据收集。
Harvester 的主要功能
1. 文件读取:
- Harvester负责打开和读取指定的日志文件。它使用操作系统的文件读取机制来逐行读取日志文件中的新数据。
2. 文件轮换处理:
- Harvester能够处理日志文件的轮换(log rotation)。即使文件名发生变化(例如,日志文件被压缩或归档,新的日志文件被创建),Harvester也能继续正确读取日志数据。
3. 文件状态跟踪:
- Harvester会跟踪文件的读取位置(偏移量)。这与Registrar组件合作,以确保Filebeat能够在重启或故障后从正确的位置继续读取日志。
4. 数据处理:
- Harvester读取的日志数据会先经过一些基本处理,如解码、过滤等,然后传递给Filebeat的缓冲区(Spooler)。
Harvester 的工作流程
1. 启动:
- Filebeat启动时,根据配置文件指定的路径,初始化一个或多个Harvester实例。
- 每个Harvester会打开并读取对应的日志文件,从指定的起始位置开始(通常是文件末尾)。
2. 读取数据:
- Harvester逐行读取日志文件的新数据。
- 读取的数据被临时存储在缓冲区中,等待进一步处理和传输。
3. 发送数据:
- 从缓冲区读取的数据会被发送到Filebeat的其他组件(如Spooler),最终被传输到配置的输出目标(如Elasticsearch、Logstash等)。
4. 处理文件轮换:
- 如果日志文件被轮换,Harvester会检测到文件变化,并重新打开新的日志文件进行读取。
- Harvester使用文件的唯一标识符(如inode)来跟踪文件,即使文件名发生变化也能继续正确处理。
4、核心组件 发布者(Publisher)
Filebeat的核心组件之一是发布者(Publisher)。Publisher在Filebeat的整体架构中起着关键作用,负责将收集到的日志数据处理后发送到预配置的目标系统,如Elasticsearch、Logstash、Kafka等。
Publisher的主要功能
1. 数据处理:
- Publisher从缓冲区(Spooler)获取数据后,会对数据进行处理,包括应用过滤器、添加元数据和格式转换等操作。
- 处理过程中,Publisher可能会根据配置的处理器(processors)来执行数据增强和转换任务,例如添加时间戳、解析JSON等。
2. 数据传输:
- Publisher将处理好的数据按批次发送到目标系统。它支持多种输出目标,并能并行处理多个输出。
- 在数据传输过程中,Publisher负责处理网络连接的建立和维护,确保数据传输的可靠性和效率。
3. 故障处理与重试机制:
- 为了保证数据不丢失,Publisher内置了故障处理机制。如果在发送过程中发生网络故障或目标系统不可用,Publisher会进行重试。
- 重试机制包括指数退避(exponential backoff)等策略,以最大限度地提高数据传输的成功率。
Publisher的工作流程
1. 数据收集与初步处理:
- Filebeat的Harvester模块读取日志数据,并通过缓冲区传递给Publisher。
- Publisher从缓冲区批量获取数据,进行预处理。
2. 数据处理:
- Publisher应用配置的处理器对数据进行处理,如添加额外的字段、过滤不需要的数据、格式转换等。
- 处理后的数据被组织成批次,准备发送。
3. 数据发送:
- Publisher根据配置,将数据发送到一个或多个输出目标。
- 支持的输出包括Elasticsearch、Logstash、Kafka、Redis等,具体的输出方式由配置文件中的output部分定义。
4. 错误处理与重试:
- 在发送过程中,如果发生错误,Publisher会根据配置的重试策略重新尝试发送。
- 重试过程中,Publisher使用退避算法来控制重试频率,并在多次重试失败后记录错误日志,避免无限制的重试导致资源浪费。

三、 数据传输机制
1、异步发送与确认机制
异步发送机制
什么是异步发送?
异步发送是指Filebeat在发送数据时,不需要等待目标系统的即时响应,而是可以继续处理其他数据。这种方式能够提高数据传输的效率和吞吐量。
异步发送的工作流程
1. 数据收集与处理:
- Harvester模块读取日志文件,并将数据发送到缓冲区(Spooler)。
- Publisher从缓冲区中批量获取数据,并应用必要的处理器(如添加元数据、过滤等)。
2. 批量发送:
- Publisher将处理后的数据组织成批次,并异步发送到配置的输出目标。
- 在发送过程中,Publisher会将每个批次的数据放入发送队列,然后立即返回继续处理新的数据,而不等待发送完成的结果。
3. 异步回调:
- 目标系统接收数据后,会异步地返回确认或错误消息。Publisher会使用回调函数处理这些响应。
- 通过回调机制,Publisher可以知道哪些数据发送成功,哪些需要重试或处理错误。
确认机制
什么是确认机制?
确认机制(acknowledgment mechanism)指的是在数据发送后,目标系统返回的响应,用于确认数据已经成功接收或处理。这是确保数据传输可靠性的关键部分。
确认机制的类型
1. Elasticsearch:
- Elasticsearch使用bulk API来接收数据。每个批次的请求会返回一个响应,包含每个文档的处理结果。Publisher会检查这些响应,确认哪些文档成功处理,哪些失败。
2. Kafka:
- Kafka支持多种确认模式:
- acks=0:生产者不等待任何确认。
- acks=1:生产者等待Leader节点确认接收数据。
- acks=all:生产者等待所有副本节点确认接收数据。
- Filebeat通常配置为acks=1或acks=all,以确保数据的可靠性。
3. Logstash:
- 当使用Beats输入插件时,Logstash会在接收到数据后返回一个确认响应。Publisher会根据这个响应确定数据是否成功发送。

2、背压(Backpressure)与流量控制
在数据流处理中,背压(Backpressure)与流量控制是关键机制,确保系统在高负载情况下稳定运行,防止数据丢失和系统崩溃。Filebeat通过这两种机制,管理数据从输入到输出的流动,确保高效和可靠的日志传输。
背压(Backpressure)
背压机制用于在下游组件(例如输出模块)无法跟上上游组件(例如Harvester)处理速度时,调节数据流动速度,防止系统过载。
背压的实现
1. 内部队列:
- Filebeat使用内部队列存储临时数据。如果输出模块处理速度较慢,队列中的数据会积压,Harvester会感受到背压,从而减缓数据读取速度。
2. 队列大小限制:
- 可以通过配置限制队列的大小。当队列达到最大容量时,Filebeat会暂停新的数据读取,等待队列中的数据被处理后再继续。
流量控制
流量控制机制用于管理和限制数据流动速率,确保系统各组件之间的数据流动保持平衡,避免资源过度消耗。
流量控制的实现
1. 数据批次大小:
- 限制每次发送的数据量,防止一次发送过多数据导致目标系统过载。
2. 发送频率:
- 控制数据发送的频率,通过配置发送间隔,平衡数据流动速率。
3. 并发限制:
- 限制同时进行的数据发送操作数,防止并发过高导致资源竞争和性能下降。
背压与流量控制的工作流程
1. 数据收集与处理:
- Harvester读取日志数据,并将其传递到内部队列。
- 如果队列达到容量上限,背压机制会触发,减缓或暂停Harvester的读取速度。
2. 数据传输:
- Publisher从队列中批量获取数据,进行处理后发送到目标系统。
- 流量控制机制限制每次发送的数据量和发送频率,防止目标系统过载。
3. 错误处理与重试:
- 在数据传输过程中,如果发送失败,Publisher会根据重试策略进行重试。
- 背压机制确保在重试期间不会继续读取和积累新数据,避免系统负载过高。
优点
- 系统稳定性:通过背压和流量控制机制,Filebeat能够在高负载情况下维持系统稳定,防止过载和数据丢失。
- 资源优化:限制并发操作和数据发送频率,优化资源使用,提高整体系统效率。
- 数据可靠性:确保数据从输入到输出的流动有序、可靠,避免数据积压或丢失。

💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于ELK的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
相关文章:
Filebeat进阶指南:核心架构与功能组件的深度剖析
🐇明明跟你说过:个人主页 🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是ELK 2、FileBeat在ELK中的角色 二、Fil…...

深度神经网络
深度神经网络(Deep Neural Networks,DNNs)是机器学习领域中的一项关键技术,它基于人工神经网络的概念,通过构建多层结构来模拟人脑的学习过程。以下是关于深度神经网络的清晰回答: 一、定义与特点 深度神…...

c++【入门】你多大了
时间限制 : 1 秒 内存限制 : 128 MB 一天玩仔跑来问周周你多大了,周周告诉他自己 1010 岁了,玩仔又说自己也是,你听到了这个对话,想用程序显示出两个人的对话内容,现在就来试一试吧。 输入 无 输出 输出三行&…...

地质考察AR远程交互展示系统辅助老师日常授课
广东这片充满活力的土地,孕育了一家引领ARVR科技潮流的杰出企业——深圳华锐视点,作为一家专注于VR/AR技术研究与业务开发的先锋公司。多年来,我们不断突破技术壁垒,将AR增强现实技术与各行各业的实际需求完美结合,助力…...

容器是什么
什么是容器? 容器技术近年来在软件开发和部署中变得越来越重要,尤其是在云计算和微服务架构中。本文将详细介绍什么是容器、其工作原理、优势以及常见的容器技术。 容器的定义 容器是一种轻量级、可移植的虚拟化技术,它允许在一个主机操作…...

一分钟学习数据安全——数字身份的三种模式
微软首席身份架构师金卡梅隆曾说:互联网的构建缺少一个身份层。互联网的构建方式让你无法得知所连接的人和物是什么。这限制了我们对互联网的使用,并让我们面临越来越多的危险。如果我们坐视不管,将面临迅速激增的盗窃和欺诈事件,…...

WPF实现搜索文本高亮
WPF实现搜索文本高亮 1、使用自定义的TextBlock public class HighlightTextblock : TextBlock{public string DefaultText { get; set; }public string HiText{get { return (string)GetValue(HiTextProperty); }set { SetValue(HiTextProperty, value); }}// Using a Depend…...
)
Vue小程序项目知识积累(三)
1.CSS中的var( ) var() 函数用于插入自定义属性(也称为CSS变量)的值。 var(--main-bg-color,20rpx) 设置一个CSS变量的值,但是如果 --main-bg-color 变量不存在,它将默认返回 20rpx。 CSS变量必须在一个有效的CSS规则…...
)
React Native 之 像素比例(十七)
在 React Native 中,PixelRatio 是一个用于获取设备像素比(Pixel Ratio)的实用工具。像素比(或称为设备像素密度、DPI 密度等)是物理像素和设备独立像素(DIPs 或 DPs)之间的比率。设备独立像素是…...

Leetcode 112:路径总和
给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。 说明: 叶子节点是指没有子节点的节点。 思路:遍历存储每条路径。当前节点为叶子节点时,求和。并判断是否等于目标…...

电源模块测试系统怎么测试输入电压范围?
在现代电子设备中,电源模块的性能直接影响着整个系统的稳定性和效率。其中,电源输入电压范围是指电源能够接受的输入电压的最小值和最大值,它是确保电源正常工作的重要参数。为了提高测试效率和精度,自动化的测试方法逐渐取代了传…...
实战指南:Vue 2基座 + Vue 3 + Vite + TypeScript微前端架构实现动态菜单与登录共享
实战指南:Vue 2基座 Vue 3 Vite TypeScript子应用vue2微前端架构实现动态菜单与登录共享 导读: 在当今的前端开发中,微前端架构已经成为了一种流行的架构模式。本文将介绍如何结合Vue 2基座、Vue 3子应用、Vite构建工具和TypeScript语言…...
)
Java面试进阶指南:高级知识点问答精粹(一)
Java 面试问题及答案 1. 什么是Java中的集合框架?它包含哪些主要接口? 答案: Java集合框架是一个设计用来存储和操作大量数据的统一的架构。它提供了一套标准的接口和类,使得我们可以以一种统一的方式来处理数据集合。集合框架主…...

儿童礼物笔记
文章目录 女孩礼物毛绒玩具音乐水晶系列水彩笔 男孩礼物益智类玩具积木类泡沫类机动玩具类 小孩过生日或儿童节,选礼物想破脑袋,做个笔记吧。 如果自家的小孩,还好说些,送亲友就需要动动脑筋。 女孩礼物 毛绒玩具 不错的选择&a…...

LeetCode215数组中第K个最大元素
题目描述 给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。 解析 快速排序的思想ÿ…...

LeetCode //C - 143. Reorder List
143. Reorder List You are given the head of a singly linked-list. The list can be represented as: L0 → L1 → … → Ln - 1 → Ln Reorder the list to be on the following form: L0 → Ln → L1 → Ln - 1 → L2 → Ln - 2 → … You may not modify the values i…...

速盾:cdn如何解析?
CDN是内容分发网络(Content Delivery Network)的缩写,它是一种通过在全球范围内分布节点服务器来提供高性能、高可用性的网络服务的技术。CDN的主要功能是通过将内容分发到离用户更近的服务器节点,从而加速用户对网站、应用程序、…...
K8s集群调度续章
目录 一、污点(Taint) 1、污点(Taint) 2、污点组成格式 3、当前taint effect支持如下三个选项: 4、查看node节点上的污点 5、设置污点 6、清除污点 7、示例一 查看pod状态,模拟驱逐node02上的pod …...
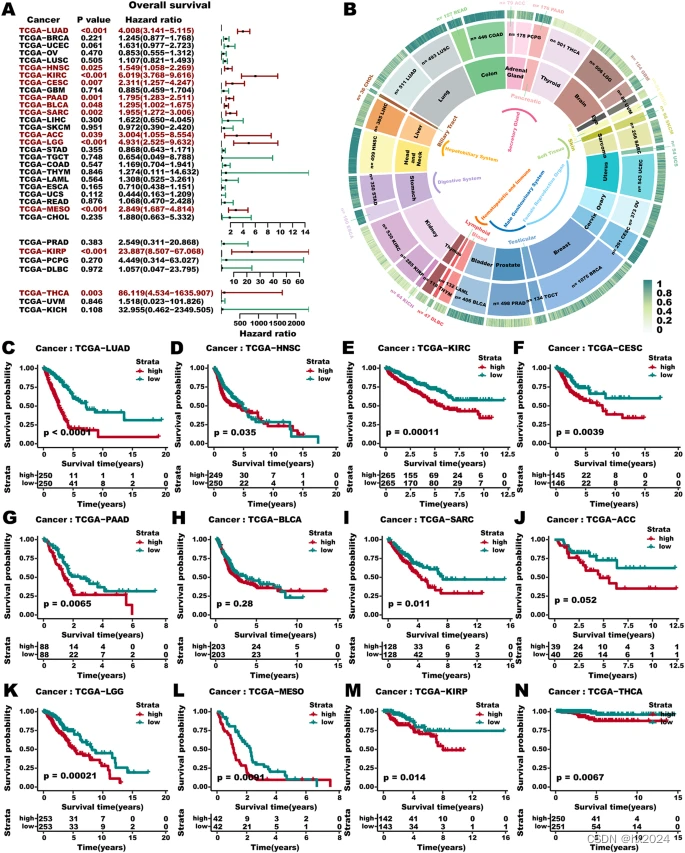
大工作量LUAD代谢重编程模型多组学(J Transl Med)
目录 1,单细胞早期、晚期和转移性 LUAD 的细胞动力学变化 2,细胞代谢重编程介导的LUAD驱动恶性转移的异质性 3,模型构建 S-MMR评分管线构建 4,S-MMR 模型的预后评估 5, 还开发了S-MMR 评分网络工具 6,…...

C语言#include<>和#include““有什么区别?
一、问题 有两种头⽂件包含的形式,⼀种是⽤尖括号将头⽂件括起,⼀种是⽤双引号将⽂件括起。那么,这两种形式有什么区别呢? 二、解答 这两种包含头⽂件的形式都是合法的,也是经常在代码中看到的,两者的区别…...

TS9580,TS3440,TS3400,G3000,G1810,G2810,G3810,G4810,TS9020,TS9120报错5B00,P07,E08,1700,5b04废墨垫清零,亲测有用。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1WrPFvdV8sq-qI3_NgO2EvA?pwd0000 常见型号如下: G系列 G1000、G1100、G1200、G1400、G1500、G1800、G1900、G1010、G1110、G1120、G1410、G1420、G1411、G1510、G1520、G1810、G1820、…...

curatedMetagenomicData 应用宝典:3步实现人类微生物组数据分析实战
curatedMetagenomicData 应用宝典:3步实现人类微生物组数据分析实战 【免费下载链接】curatedMetagenomicData Curated Metagenomic Data of the Human Microbiome 项目地址: https://gitcode.com/gh_mirrors/cu/curatedMetagenomicData curatedMetagenomicD…...

AI临床研究助手会先在哪些环节跑出来,真正的效率杠杆是什么
AI 临床研究助手最先落地的地方,不会是直接替代研究者做关键判断,而是进入高频、重复、可审计、边界清晰的研究流程节点。本文从技术架构角度拆解它会优先出现在哪些环节,以及开发团队如何用 workflow engine、LLM API、audit log 和 metrics…...

HS2-HF_Patch:一键解决《Honey Select 2》三大核心问题的终极增强补丁
HS2-HF_Patch:一键解决《Honey Select 2》三大核心问题的终极增强补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 厌倦了《Honey Select 2》原版…...

终极科学文库PDF解密完整指南:永久解除CAJViewer限制的3步方案
终极科学文库PDF解密完整指南:永久解除CAJViewer限制的3步方案 【免费下载链接】ScienceDecrypting 破解CAJViewer带有效期的文档,支持破解科学文库、标准全文数据库下载的文档。无损破解,保留文字和目录,解除有效期限制。 项目…...

对比直接使用官方api体验taotoken在计费透明性与灵活性上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用官方 API 体验 Taotoken 在计费透明性与灵活性上的优势 在开发基于大模型的应用时,除了模型效果和稳定性&…...

51单片机计算器DIY:除了加减乘除,你的LCD1602和矩阵键盘还能这样玩?
51单片机计算器进阶指南:解锁LCD1602与矩阵键盘的隐藏玩法 当你在51单片机上成功实现了一个基础计算器后,是否想过这两个核心外设——LCD1602液晶屏和4x4矩阵键盘——还能玩出什么新花样?本文将带你超越简单的加减乘除,探索硬件模…...

自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现
自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 【下载地址】自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现 本项目提供了一个完整的工程代码,用于实现自适应滤波器提取胎儿心电信号的MATLAB及FPGA实现。自适应滤波器是一种能够根据环境变化自动调整滤波器参数…...

初次接触Taotoken从注册到发出第一个API请求的全流程耗时
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次接触Taotoken从注册到发出第一个API请求的全流程耗时 本文记录了一名新用户从零开始,完成Taotoken平台注册、获取A…...

Perplexity实时新闻查询效率翻倍:从API调用到结果过滤的7个隐藏技巧
更多请点击: https://codechina.net 第一章:Perplexity实时新闻查询效率翻倍:从API调用到结果过滤的7个隐藏技巧 Perplexity 的实时新闻 API(如 /search/news 端点)在默认配置下常因冗余字段、未压缩响应和同步阻塞而…...