英特尔LLM技术挑战记录
英特尔技术介绍:
Flash Attention
Flash Attention 是一种高效的注意力机制实现,旨在优化大规模 Transformer 模型中的自注意力计算。在深度学习和自然语言处理领域,自注意力是 Transformer 架构的核心组件,用于模型中不同输入元素之间的交互和信息整合。然而,随着模型规模和输入长度的增加,传统的自注意力机制的计算复杂度和内存需求迅速增长,这限制了模型的扩展性和效率。Flash Attention 主要通过以下几个方面优化自注意力的计算:
-
内存效率提升:Flash Attention 通过重新设计计算流程,减少了中间结果的存储需求。它通过分批处理输入序列,并在每个批次中计算注意力权重,从而减少了同时需要在内存中保持的数据量。
-
计算优化:该方法采用了一种新的计算策略,通过优化矩阵运算和利用现代硬件(如 GPU 和 TPU)的并行处理能力,显著提高了计算效率。例如,它可以更有效地利用内存带宽和计算单元。
-
减少冗余计算:在传统的注意力机制中,对于每一对输入元素都需要计算一个得分,而 Flash Attention 通过智能分组和预处理输入数据,减少了不必要的重复计算。
-
适应不同的硬件和场景:Flash Attention 设计灵活,可以根据不同的硬件配置和具体应用场景进行调整,以达到最佳的性能和效率平衡。
通过这些优化,Flash Attention 不仅能够处理更长的序列,而且能够在保持甚至提高模型性能的同时,降低资源消耗和提高处理速度。这使得它在处理大规模数据集或需要实时响应的应用中尤为有用。
总之,Flash Attention 是对传统 Transformer 自注意力机制的一种重要改进,它通过减少计算复杂度和内存需求,使得大规模模型的训练和推理变得更加高效。
Flash Decoding
Flash Decoding 是一种用于自然语言生成任务的高效解码方法,特别是在使用 Transformer 模型进行文本生成时。在自然语言处理中,解码是从模型生成输出的过程,例如在机器翻译、文本摘要或聊天机器人应用中生成连贯的文本。传统的解码方法,如贪婪解码、束搜索(Beam Search)等,虽然广泛使用,但在处理大规模模型或长文本时可能会遇到效率和扩展性问题。Flash Decoding 通过以下方式优化解码过程:
-
并行化处理:Flash Decoding 能够在生成每个词时更有效地利用并行计算资源。它通过同时处理多个解码步骤来减少序列生成的总时间,与传统的逐步生成方法相比,这种方法可以显著加速解码过程。
-
减少重复计算:在传统的解码过程中,每生成一个新词后,整个输入序列(包括所有已生成的词)通常会重新输入到模型中进行处理。Flash Decoding 通过智能缓存先前的计算结果,减少了这种重复计算的需要。
-
优化搜索策略:尽管 Flash Decoding 可以与传统的解码策略(如贪婪解码或束搜索)结合使用,但它也可能引入更高效的搜索算法来快速定位最优或近似最优的输出序列。
-
动态终止:Flash Decoding 可以根据生成文本的质量或其他实时评估指标动态决定何时停止解码,从而避免不必要的计算,并提高整体效率。
-
适应性调整:该方法能够根据不同的任务需求和硬件配置调整其性能,以实现在保证输出质量的同时最大化解码速度。
总的来说,Flash Decoding 是一种创新的解码技术,旨在提高文本生成任务中的解码速度和效率,特别适用于需要快速响应或处理大量数据的应用场景。通过减少计算负担和优化资源使用,Flash Decoding 能够使大规模 Transformer 模型的部署和实际应用变得更加可行和高效。
实验过程及结果:
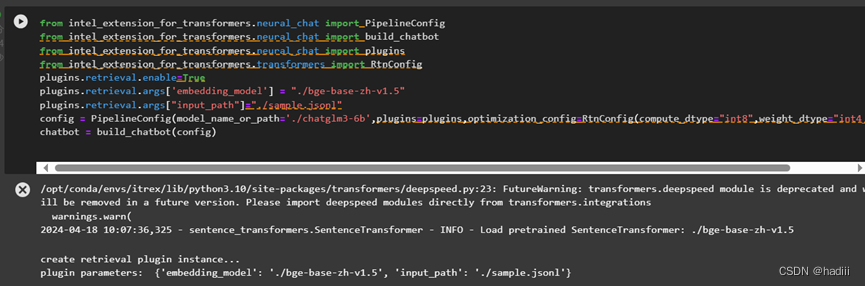


个人心得:
在这个实验中,我尝试将大型语言模型(LLM)与检索增强生成(RAG)相结合。这种组合的目的是利用LLM的生成能力和RAG的信息检索能力,以期提高回答问题的准确性和相关性。
实验的基本设定包括使用一个预训练的语言模型作为基础,通过RAG框架在回答过程中实时检索外部信息。具体来说,当模型接收到一个查询时,它首先对查询进行理解,然后利用RAG从一个大型的文档库中检索相关信息。这些信息被用作生成回答的上下文,从而帮助模型生成更加丰富和准确的内容。
在实验过程中,我观察到结合使用LLM和RAG可以显著提高回答的质量。特别是在处理专业或深度问题时,这种方法能够提供更多的细节和精确度,因为模型能够接入更广泛的知识库。此外,这种方法还有助于减少生成错误或不相关回答的情况,因为回答是基于检索到的具体证据生成的。
然而,这种方法也存在一些挑战。首先,依赖于外部知识库的质量和更新频率,如果知识库内容过时或质量不高,可能会影响回答的准确性。其次,检索和生成的过程需要相对较高的计算资源和时间,这可能会影响模型的实时响应能力。
总体来说,LLM结合RAG的实验表明这是一个有前景的方向,尤其是在需要高质量和信息丰富的答案的应用场景中。未来的工作可以集中在优化检索效率、扩展知识库的覆盖面以及提高系统整体的稳定性和可靠性上。
相关文章:
英特尔LLM技术挑战记录
英特尔技术介绍: Flash Attention Flash Attention 是一种高效的注意力机制实现,旨在优化大规模 Transformer 模型中的自注意力计算。在深度学习和自然语言处理领域,自注意力是 Transformer 架构的核心组件,用于模型中不同输入元…...

在 MFC 中 UNICODE 加 _T 与 L 长字符串,有什么区别?
在MFC(Microsoft Foundation Classes)和更广泛的Windows编程环境中,UNICODE宏用于指示程序应使用Unicode字符集(通常是UTF-16)来处理文本。当定义了UNICODE宏时,编译器和库函数会期待和处理宽字符ÿ…...

synopsys EDA 2016 合集 下载
包含如下安装包,如需安装服务也可联系我 FineSim_vL_2016.03 Laker201612 Library Compiler M-2016.12 Update Training PrimeTime M-2016.12 Update Training StarRC M-2016.12 Update Training SynopsysInstaller_v3.3 TSMC-65nm(OA) fm_vL-2016.03-SP1 fpga_vL-…...

CentOS 7如何使用systemctl管理应用
说明:本文介绍如何使用systemctl命令的方式来启动、查看、停止和重启应用,以安装后的prometheus、alertmanager为例; Step1:创建文件 在系统/etc/systemd/system/路径下,创建一个xxx.service文件,该文件内…...

武大深度学习期末复习-常见神经网络概念
深度学习经典神经网络概念、优缺点及应用场景 文章目录 一、多层感知机(MLP)1.1 结构和原理1.2 优缺点1.3 应用场景 二、卷积神经网络(CNN)2.1 结构和原理2.2 优缺点2.3 应用场景 三、循环神经网络(RNN)3.1…...

Leetcode3161. 物块放置查询(Go语言的红黑树 + 线段树)
题目截图 题目分析 每次1操作将会分裂成两块区间长度,以最近右端点记录左侧区间的长度即可 因此涉及到单点更新和区间查询 然后左右侧最近端点则使用redBlackTree,也就是python中的sortedlist ac code type seg []int// 把 i 处的值改成 val func (t …...

基于springboot实现医疗挂号管理系统项目【项目源码+论文说明】
基于springboot实现医疗挂号管理系统演示 摘要 在如今社会上,关于信息上面的处理,没有任何一个企业或者个人会忽视,如何让信息急速传递,并且归档储存查询,采用之前的纸张记录模式已经不符合当前使用要求了。所以&…...

ScrumMaster认证机构及CSM、PSM、RSM价值比较
企业现有的经营管理模式和传统的瀑布式交付模式,已经不能适应快速变化的市场响应和客户需求,现代的敏捷工作方式在过去数年涌现,比如Scrum,XP,看板,DevOps等敏捷方法,近十年Scrum在国内企业中备…...

加氢站压缩液驱比例泵放大器
加氢站压缩液驱液压系统的要求是实现换向和速度控制,对液压动力机构而言,按原理可区分为开式(阀控)- 节流控制系统和闭式(泵控)- 容积控制系统: 阀控系统 – 节流调速系统:由BEUEC比…...
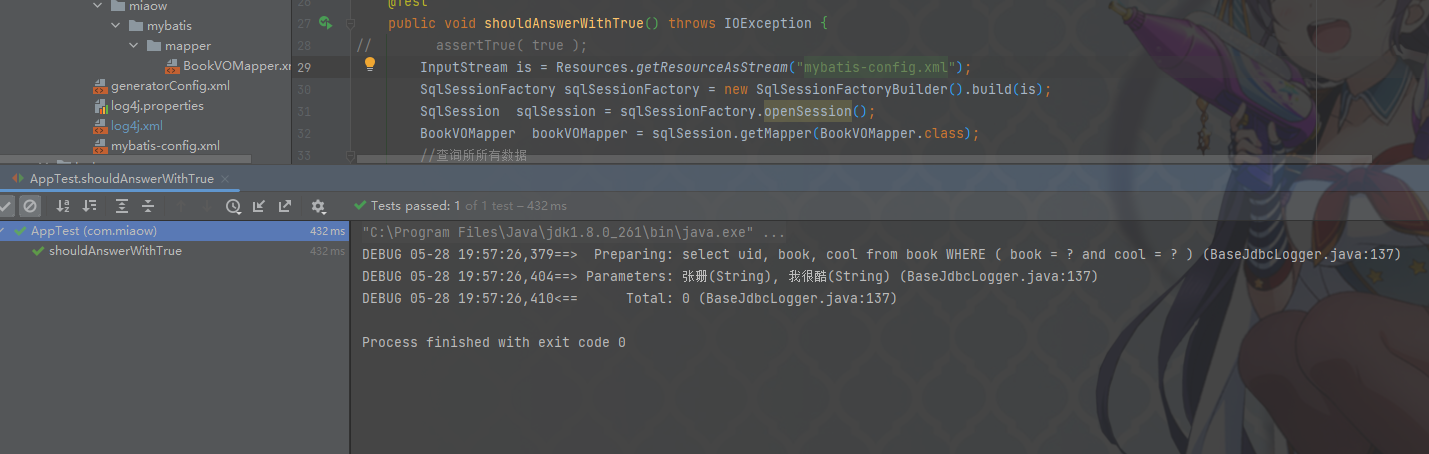
MyBatis系统学习篇 - MyBatis逆向工程
MyBatis的逆向工程是指根据数据库表结构自动生成对应的Java实体类、Mapper接口和XML映射文件的过程。逆向工程可以帮助开发人员快速生成与数据库表对应的代码,减少手动编写重复代码的工作量。 我们在MyBatis中通过逆向工具来帮我简化繁琐的搭建框架,减少…...
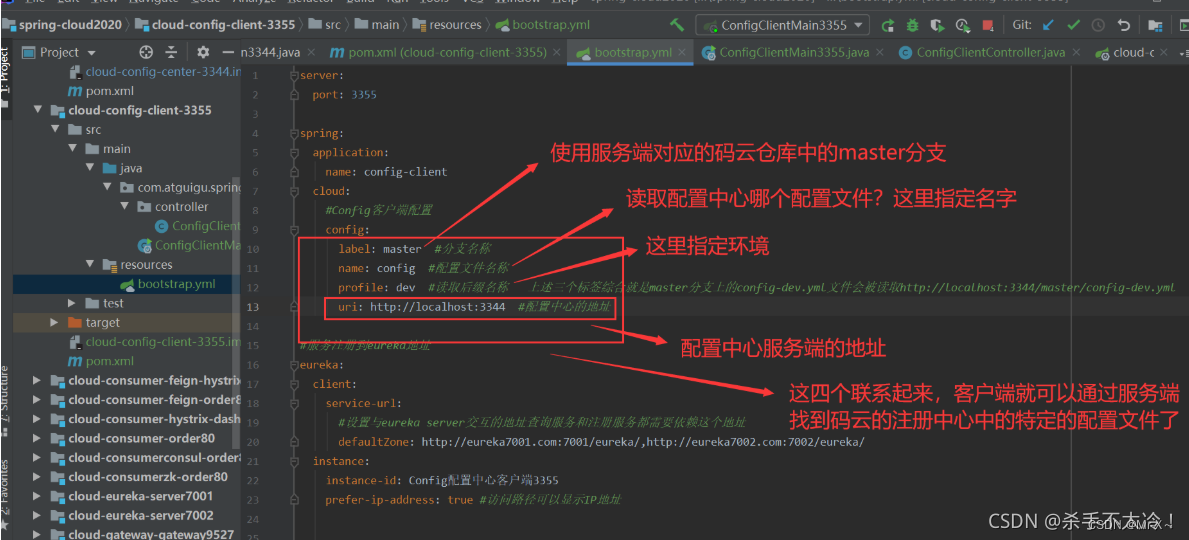
SpringCloud的Config配置中心,为什么要分Server服务端和Client客户端?
SpringCloud的Config配置中心,为什么要分Server服务端和Client客户端? 在SpringCloud的Config配置中心中分了Server服务端和Client客户端,为什么需要这样分呢?它的思想是所有微服务的配置文件都放到git远程服务器上,让…...

「数据结构」队列
目录 队列的基本概念 队列的实现 头文件queue.h 实现函数接口 1.初始化和销毁 2.出队列和入队列 3.获取队头元素和队尾元素 4.队列长度判空 后记 前言 欢迎大家来到小鸥的博客~ 个人主页:海盗猫鸥 本篇专题:数据结构 多谢大家的支持啦ÿ…...

Python01 注释,关键字,变量,数据类型,格式化输出
# 导入模块 import keyword# 我的第一个Python程序 这是单行注释 快捷键:CTRL/这里是多行注释 可以写多行,用 三个单引号 包起来print(Hello work) print(你好,中国)aa 这是不是注释了,是多行文本。print(aa)# 快速创建 python …...
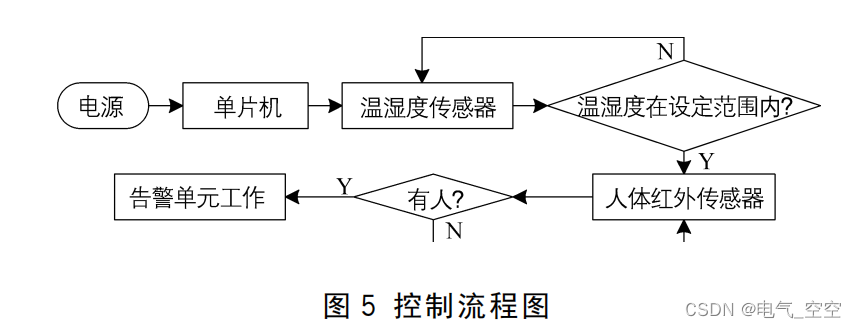
基于单片机智能防触电装置的研究与设计
摘 要 : 针对潮湿天气下配电线路附近易发生触电事故等问题 , 对单片机的控制算法进行了研究 , 设 计 了 一 种 基 于 单片机的野外智能防触电装置。 首先建立了该装置的整体结构框架 , 再分别进行硬件设计和软件流程分析 …...

机械行业工程设计资质乙级需要哪些人员
申请机械行业工程设计资质乙级需要的人员主要包括以下几个方面,具体要求和数量根据参考文章归纳如下: 一、主要专业技术人员 数量要求:主要专业技术人员数量应不少于所申请行业资质标准中主要专业技术人员配备表规定的人数。学历和职称要求…...
vivado改变波形图窗口颜色
点击右上角的设置图标 翻译对照...

蓝桥杯练习系统(算法训练)ALGO-932 低阶行列式计算
资源限制 内存限制:64.0MB C/C时间限制:1.0s Java时间限制:3.0s Python时间限制:5.0s 问题描述 给出一个n阶行列式(1<n<9),求出它的值。 输入格式 第一行给出两个正整数n,p; 接下来n行&…...

四川古力未来科技抖音小店安全靠谱,购物新体验
在数字化浪潮席卷而来的今天,电商行业蓬勃发展,各种线上购物平台如雨后春笋般涌现。其中,抖音小店凭借其独特的短视频直播购物模式,迅速赢得了广大消费者的青睐。而四川古力未来科技抖音小店,更是以其安全靠谱、品质保…...

深入理解Seata:分布式事务的解决方案
在现代的微服务架构中,随着业务系统的不断拆分和模块化,分布式事务成为一个重要的挑战。为了解决微服务架构下的分布式事务问题,Seata应运而生。Seata(Simple Extensible Autonomous Transaction Architecture)是一款开…...

【TC8】如何测试IOP中PHY芯片的Llink-up time
在TC8一致性测试用例中,物理层的测试用例分为两个部分:IOP和PMA。其中IOP中对PHY芯片的Link-up时间的测试,又包含三个测试用例。它们分别是: OABR_LINKUP_01: Link-up time - Trigger: Power on Link PartnerOABR_LINKUP_02: Link-up time - Trigger: Power on DUTOABR_LIN…...

从零到告警:用Prometheus+SNMP监控华为交换机,并配置Grafana看板与告警规则
从零构建华为交换机智能监控体系:PrometheusSNMP实战指南 当机房里的华为交换机突然宕机时,运维团队往往要面对业务部门的连环追问。传统的人工巡检方式就像用体温计量火山喷发——既滞后又无力。本文将手把手带您搭建从数据采集到告警响应的完整监控闭环…...

电脑安装双系统
电脑安装双系统 本次是在Windows 10的环境下安装Ubuntu的系统。 1、可能需要的准备工作 首先打开cmd输入msinfo32的命令查看电脑的BIOS的模式是不是UEFI,如下所示: 本次安装系统基于以上的BIOS模式下。此外如果遇到安装之后不能跳转到ubuntu系统的问题ÿ…...

2026年AI文字做海报工具横评:6款实测对比,设计小白也能5分钟出图
摘要 2026年,AI做海报已经不是新鲜事,但"输入文字就能出海报"和"出一张能用的海报"之间,差距大得离谱。 我测了6款主流的可以AI文字做海报的工具,有的生成速度很快但排版像模板套娃,有的效果惊艳…...

测试工程师必知的10个Linux命令:提升工作效率的利器
在软件测试领域,Linux系统是绕不开的重要工具。绝大多数应用后台都部署在Linux服务器上,从环境搭建、日志分析到性能监控,熟练掌握Linux命令能让测试工程师的工作效率大幅提升。不同职级的测试工程师对Linux的需求各有侧重:初级工…...

《深入理解Linux网络技术内幕》全套学习资料合集
目录 第一部分 全书分章节课后习题标准答案第二部分 配套全套Demo源码(内核模块应用层C程序)第三部分 Linux内核TCP协议栈逐行源码深度解析第四部分 书本知识点 → RK3588硬件落地实战教程第一部分 分章节课后练习题标准答案 第1章 Linux网络体系架构 一…...

linux service和systemctl命令、systemd
文章目录service命令(老版本)systemctl命令(推荐)systemdsystemd示例-Hello Worldsystemd语法如何查看service对应的脚本service命令(老版本) 都是服务控制相关的命令,差别不大,之前用service,现在一般用systemctl。 service命令例子&#…...

Autoswagger与Intruder生态集成:企业级API安全解决方案的完整指南
Autoswagger与Intruder生态集成:企业级API安全解决方案的完整指南 【免费下载链接】autoswagger Autoswagger by Intruder - detect API auth weaknesses 项目地址: https://gitcode.com/gh_mirrors/au/autoswagger 在当今API驱动的数字世界中,AP…...

不只是远程桌面:用向日葵在Ubuntu上实现无人值守文件传输与SSH隧道
超越远程桌面:向日葵在Ubuntu上的高阶自动化实践 当大多数人提起向日葵时,第一反应往往是"远程控制软件"。但这款工具的实际能力远不止于此——在开发者手中,它可以成为打通内外网的生产力中枢。想象这样一个场景:你正在…...

从开发者视角看Taotoken文档与示例代码对降低接入门槛的帮助
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从开发者视角看Taotoken文档与示例代码对降低接入门槛的帮助 作为一名经常需要集成不同AI模型服务的开发者,我经历过不…...

启动我进入数据科学的那一个思维方式转变
原文:towardsdatascience.com/the-one-mindset-change-that-launched-me-into-data-science-3f72bd1df46f?sourcecollection_archive---------2-----------------------#2024-10-19 让它成为现实:微小的改变帮助你进入数据科学或任何梦想职业 https://…...