【MySQL精通之路】InnoDB磁盘I/O和文件空间管理(11)
主博客:
【MySQL精通之路】InnoDB存储引擎-CSDN博客
目录
1.InnoDB磁盘I/O
1.1 预读
1.2 双写缓冲区
2.文件空间管理
2.1 Pages, Extents, Segments, and Tablespaces(很重要)
2.2 配置保留文件段页面的百分比
2.3 页与表行的关系
3.InnoDB检查点
4.对表进行碎片整理
5.TRUNCATE TABLE回收磁盘空间
作为DBA,您必须管理磁盘I/O以防止I/O子系统饱和,并管理磁盘空间以避免填满存储设备。
ACID设计模型需要一定数量的I/O,这些I/O看起来可能是多余的,但有助于确保数据的可靠性。
在这些限制条件下,InnoDB试图优化数据库工作和磁盘文件的组织,以最大限度地减少磁盘I/O量。
有时,I/O操作会推迟到数据库闲时,或者直到所有东西都需要保持一致状态,例如在快速关闭后的数据库重新启动期间。
本节讨论了默认类型MySQL表(也称为InnoDB表)的I/O和磁盘空间的主要注意事项:
控制用于提高查询性能的后台I/O量。
启用或禁用以牺牲额外I/O为代价提供额外耐用性的功能。
将表组织成许多小文件、几个大文件或两者的组合。
平衡redolog日志文件的大小与日志文件变满时发生的I/O活动。
如何重新组织表以获得最佳查询性能。
1.InnoDB磁盘I/O
InnoDB在可能的情况下使用异步磁盘I/O,通过创建多个线程来处理I/O操作,同时允许其他数据库操作在I/O仍在进行时继续执行。
在Linux和Windows平台上,InnoDB使用可用的操作系统和库函数来执行“本地”异步I/O。
在其他平台上,InnoDB仍然使用I/O线程,但线程实际上可能会等待I/O请求完成;
这种技术被称为“模拟”异步I/O。
1.1 预读
如果InnoDB能够确定很有可能很快就需要数据,它会执行预读操作,将数据放入缓冲池,以便在内存中可用。对连续数据发出几个大的读取请求可能比发出几个分散的小请求更有效。InnoDB中有两种预读启发法:
在顺序预读中,如果InnoDB注意到对表空间中某个段的访问模式是顺序的,它会提前向I/O系统发布一批数据库页面的读取。
在随机预读中,如果InnoDB注意到表空间中的某个区域似乎正在被完全读取到缓冲池中,它会将剩余的读取发布到I/O系统。
有关配置启发式预读的信息,请参阅“配置InnoDB缓冲池预取(预读)”。
【MySQL精通之路】InnoDB配置(8)-缓存池配置-CSDN博客
1.2 双写缓冲区
InnoDB使用了一种新颖的文件刷新技术,该技术涉及一种称为doublewrite缓冲区的结构,在大多数情况下默认启用该结构(InnoDB_doublewrite=ON)。
它为意外退出或停电后的恢复增加了安全性,并通过减少对fsync()操作的需求来提高大多数Unix的性能。
在将页面写入数据文件之前,InnoDB首先将它们写入一个称为双写缓冲区的存储区域。
只有在对双写缓冲区的写入和刷新完成后,InnoDB才会将页面写入数据文件中的正确位置。
如果在页面写入过程中出现操作系统、存储子系统或意外的mysqld进程退出(导致页面撕裂),InnoDB稍后可以在恢复期间从doublewrite缓冲区中找到页面的良好副本。
有关双写缓冲区的更多信息,请参阅“双写缓冲”。
【MySQL精通之路】InnoDB(6)-磁盘结构(4)-双写缓冲区-CSDN博客
2.文件空间管理
使用innodb_data_file_path配置选项在配置文件中定义的数据文件形成innodb系统表空间。
这些文件在逻辑上连接起来,形成系统表空间。
没有使用分段。您不能定义表在系统表空间中的分配位置。在新创建的系统表空间中,InnoDB从第一个数据文件开始分配空间。
为了避免在系统表空间中存储所有表和索引时出现的问题,可以启用innodb_file_per_table配置选项(默认选项),该选项将每个新创建的表存储在一个单独的表空间文件中(扩展名为.ibd)。对于以这种方式存储的表,磁盘文件中的碎片较少,当表被截断时,空间会返回到操作系统,而不是由InnoDB在系统表空间中保留。
有关更多信息,请参阅“FPT表空间”。
也可以将表存储在通用表空间中。通用表空间是使用CREATE TABLESPACE语法创建的共享表空间。它们可以在MySQL数据目录之外创建,能够容纳多个表,并支持所有行格式的表。
有关更多信息,请参阅“通用表空间”。
2.1 Pages, Extents, Segments, and Tablespaces(很重要)
页、区、段和表空间
每个表空间都由数据库页面组成。
MySQL实例中的每个表空间都具有相同的页面大小。
默认情况下,所有表空间的页面大小为16KB;
您可以在创建MySQL实例时通过指定innodb_page_size选项将页面大小减少到8KB或4KB。您也可以将页面大小增加到32KB或64KB。
有关更多信息,请参阅innodb_page_size文档。
对于大小不超过16KB的页面(64个连续的16KB页面、128个8KB页面或256个4KB页面),页被分组为大小为1MB的扩展区。
对于32KB的页面大小,一个区大小为2MB。对于64KB的页面大小,一个区大小为4MB。表空间内的“文件”在InnoDB中被称为段(Segments)。(这些段与回滚段不同,回滚段实际上包含许多表空间段。)
当一个段在表空间内增长时,InnoDB会一次性为其分配前32个页。之后,InnoDB开始将整个区分配给该段。InnoDB一次最多可以向一个段添加4个区,以确保数据的良好顺序性。
InnoDB中为每个索引分配了两个段。一个用于B+树的非叶节点,另一个用于叶节点。在磁盘上保持叶节点连续可以实现更好的顺序I/O操作,因为这些叶节点包含实际的表数据。
表空间中的一些页面包含其他页面的Bitmap位图,因此InnoDB表空间中一些区不能作为一个整体分配给段,而只能作为单独的页面。
当您通过发出SHOW TABLE STATUS语句来请求表空间中的可用区时,InnoDB会报告表空间中绝对空闲的区。InnoDB总是保留一些区用于清理和其他内部目的;这些保留的区不包括在可用区中。
当您从表中删除数据时,InnoDB会收缩相应的B树索引。释放的空间是否可供其他用户使用取决于删除模式是否将单个页或区释放到表空间。
删除表或从表中删除所有行可以保证将空间释放给其他用户,但请记住,删除的行仅通过purge操作进行物理删除,清除操作在事务回滚或一致性读取不再需要这些行后自动发生。(参见“InnoDB多版本”。)
2.2 配置保留文件段页面的百分比
innodb_segment_reserve_factor变量是MySQL 8.0.26中引入的一个高级功能,它允许定义保留为空页的表空间文件段页面的百分比。
为将来的增长保留一定比例的页面,以便可以连续分配B树中的页面。修改保留页面百分比的能力允许对InnoDB进行微调,以解决数据碎片或存储空间使用效率低下的问题。
该设置适用于FPT表空间和通用表空间。
innodb_segment_reserve_factor默认设置为12.5%,与之前MySQL版本中保留的页面百分比相同。
innodb_segment_reserve_factor变量是动态的,可以使用SET语句进行配置。例如
mysql> SET GLOBAL innodb_segment_reserve_factor=10;2.3 页与表行的关系
对于4KB、8KB、16KB和32KB innodb_page_size设置,最大行长度略小于数据库页大小的一半。
例如
对于默认的16KB InnoDB页大小,最大行长度略小于8KB。
对于64KB的innodb_page_size设置,最大行长度略小于16KB。
如果一行不超过最大行长度,则所有行都存储在页面的本地。
如果一行超过最大行长,则会选择可变长度列用于外部页外存储,直到该行符合最大行长限制。
可变长度列的外部页存储因行格式而异:
COMPACT和REDUNDANT行格式
当选择可变长度列用于外部页外存储时,InnoDB将前768个字节存储在行的本地,其余字节存储在溢出页的外部。每个这样的列都有自己的溢出页列表。768字节的前缀附带一个20字节的值,该值存储列的真实长度,并指向存储该值其余部分的溢出列表。
参见“InnoDB行格式”
DYNAMIC和COMPRESSED行格式
DYNAMIC和COMPRESSED当选择可变长度列作为外部页外存储时,InnoDB将一个20字节的指针本地存储在行中,其余存储到溢出页中。
参见“InnoDB行格式”
LONGBLOB和LONGTEXT列必须小于4GB,并且包括BLOB和TEXT列在内的总行长度必须小于4GB。
3.InnoDB检查点
使日志文件非常大可能会减少检查点操作期间的磁盘I/O。
将日志文件的总大小设置为与缓冲池一样大甚至更大通常是有意义的。
检查点处理的工作原理
InnoDB实现了一种称为模糊检查点的检查点机制。
InnoDB以小批量从缓冲池中刷新修改后的数据库页面。
不需要在一个批次中刷新缓冲池,因为这会在检查点过程中中断对用户SQL语句的处理。
在崩溃恢复过程中,InnoDB会查找写入日志文件的检查点标签。它知道在标签之前对数据库的所有修改都存在于数据库的磁盘映像中。然后InnoDB从检查点向前扫描日志文件,将记录的修改应用于数据库。
4.对表进行碎片整理
在二级索引中随机插入或从二级索引删除会导致索引变得碎片化。
碎片化意味着磁盘上索引页的物理顺序与页上记录的索引顺序不接近,或者在分配给索引的64页块中有许多未使用的页。
碎片化的一个症状是表占用的空间超过了它“应该”占用的空间。
这到底是多少,很难确定。所有InnoDB数据和索引都存储在B树中,它们的填充因子可能在50%到100%之间变化。
碎片化的另一个症状是,像这样的表扫描所花费的时间比“应该”花费的时间更长:
SELECT COUNT(*) FROM t WHERE non_indexed_column <> 12345;前面的查询要求MySQL执行完整的表扫描,这是大表中最慢的查询类型。
为了加快索引扫描速度,您可以定期执行“null”ALTER TABLE操作,这会导致MySQL重新生成表:
ALTER TABLE tbl_name ENGINE=INNODB您还可以使用ALTER TABLE tbl_name FORCE执行一个空修改操作来重新构建表。
ALTER TABLE tbl_name ENGINE=INNODB和ALTER TABLE tbl_name FORCE都使用联机DDL。
有关更多信息,请参阅“InnoDB和在线DDL”。
执行碎片整理操作的另一种方法是使用mysqldump将表转储到文本文件中,删除表,然后从转储文件中重新加载它。
如果索引中的插入始终是升序的,并且只从末尾删除记录,那么InnoDB文件空间管理算法可以保证索引中不会出现碎片。
5.TRUNCATE TABLE回收磁盘空间
要在TRUNCATE InnoDB表时回收操作系统磁盘空间,该表必须存储在自己的.ibd文件中。
要将表存储在其自己的.ibd文件中,必须在创建表时启用innodb_file_per_table。
此外,被TRUNCATE的表和其他表之间不能有外键约束,否则TRUNCATE TABLE操作将失败。但是,允许在同一表中的两列之间使用外键约束。
当表被TRUNCATE时,它会被删除并在新的.ibd文件中重新创建,释放的空间会返回到操作系统。这与TRUNCATE存储在InnoDB系统表空间内的InnoDB表(当InnoDB_file_per_table=OFF时创建的表)和存储在共享通用表空间中的表形成对比,其中只有InnoDB可以在TRUNCATE表后使用释放的空间。
TRUNCATE表并将磁盘空间返回到操作系统的能力也意味着物理备份可以更小。TRUNCATE存储在系统表空间(innodb_file_per_table=OFF时创建的表)或通用表空间中的表会在表空间中留下未使用的区域。
相关文章:
)
【MySQL精通之路】InnoDB磁盘I/O和文件空间管理(11)
主博客: 【MySQL精通之路】InnoDB存储引擎-CSDN博客 目录 1.InnoDB磁盘I/O 1.1 预读 1.2 双写缓冲区 2.文件空间管理 2.1 Pages, Extents, Segments, and Tablespaces(很重要) 2.2 配置保留文件段页面的百分比 2.3 页与表行的关系 …...
基于springboot+html的二手交易平台(附源码)
基于springboothtml的二手交易平台 介绍部分界面截图如下联系我 介绍 本系统是基于springboothtml的二手交易平台,数据库为mysql,可用于毕设或学习,附数据库 部分界面截图如下 联系我 VX:Zzllh_...

正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-24.3,4 SPI驱动实验-I.MX6U SPI 寄存器
前言: 本文是根据哔哩哔哩网站上“正点原子[第二期]Linux之ARM(MX6U)裸机篇”视频的学习笔记,在这里会记录下正点原子 I.MX6ULL 开发板的配套视频教程所作的实验和学习笔记内容。本文大量引用了正点原子教学视频和链接中的内容。…...

【Pandas】数据处理方法
1.数据拆分 pandas.Series.str.extract() Series.str.extract(pat, flags0, expandTrue)[source]extract(提取) 参数 pat: 带分组的正则表达式。 flag: re模块中的标志,例如re.IGNORECASE,修改正则表达式匹配的大小写、空格等 expand: 默认为True&…...
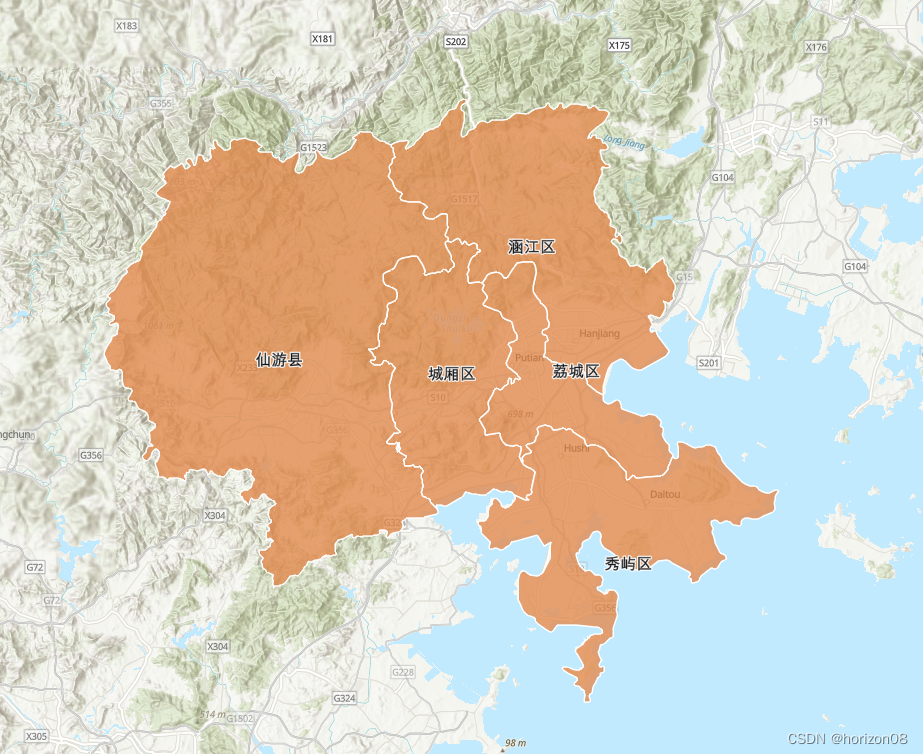
【ArcGIS For JS】前端geojson渲染行政区划图层并加标签
原理 通过DataV工具 生成行政区的geojson(得到各区的面元素数据), 随后使用手动绘制featureLayer与Label,并加载到地图。 //vue3加载geojson数据public/geojson/pt.json,在MapView渲染上加载geojson数据 type是"MultiPolygon"fetc…...

Spring AOP原理详解:动态代理与实际应用
1. Spring AOP概述 1.1 什么是AOP AOP(Aspect-Oriented Programming,面向切面编程)是一种编程范式,旨在将横切关注点(Cross-Cutting Concerns)从业务逻辑中分离出来。横切关注点是指那些分散在应用程序多…...

死锁的四个必要条件
死锁的四个必要条件如下: 互斥条件(Mutual Exclusion):资源是独占的,即在同一时间内一个资源只能被一个进程或线程所使用,其他进程或线程无法访问该资源。 请求与保持条件(Hold and Wait&#…...
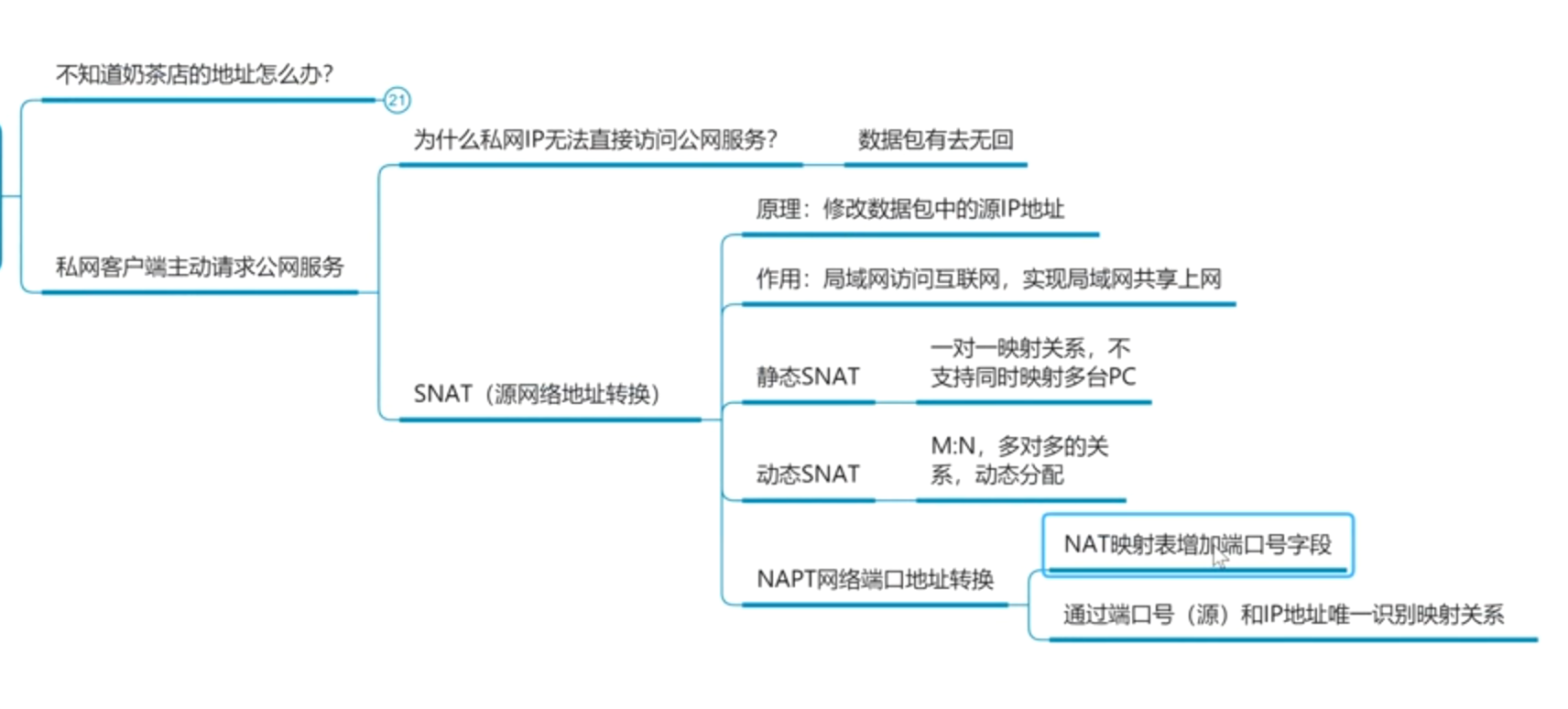
源网络地址转换SNAT
左上角的是访问互联网发送的数据包,第一个是访问,第二个是网页传回来的 3、4项是源端口号和目的端口号(3是随机的(1024-65535),那个是http的网页服务端口就是80) 那么往回传数据的时候源和目的…...

【算法】平衡二叉搜索树的左旋和右旋
树旋转是一种维护平衡树结构的重要操作,主要用于平衡二叉搜索树(如AVL树和红黑树)。树旋转分为左旋和右旋。 1. 树旋转的定义 左旋 (Left Rotation) 左旋操作将节点及其右子树进行调整,使其右子树的左子节点成为根节点…...

介绍Django Ninja框架
文章目录 安装快速开始特性详解自动文档生成定义请求和响应模型异步支持中间件支持测试客户端 结论 Django Ninja是一个基于Python的快速API开发框架,它结合了Django和FastAPI的优点,提供了简单易用的方式来构建高性能的Web API。 安装 使用以下命令安…...

使用uniapp内置组件checkbox-group所遇到的问题
checkbox-group属性说明 属性名类型默认值说明changeEventHandle <checkbox-group> 中选项发生改变触发change事件 detail { value:[选中的checkbox的value的数组] } 问题代码 <checkbox-group change"handleEVent()"><view style&qu…...

嵌入式学习记录5.23(超时检测、抓包分析)
目录 一.自带超时参数的函数 1.1 select函数 1.2 poll函数的自带超时检测参数 二、不带超时检测参数的函数 三、通过信号完成时间的设置 四、更新下载源 五、wireshark使用 5.1. 安装 5.2. wireshark 抓包 5.2.1 wireshark与对应的OSI七层模型 编辑5.2.2 包头分析 …...
Linux|如何在 awk 中使用流控制语句
引言 当您从 Awk 系列一开始回顾我们迄今为止介绍的所有 Awk 示例时,您会注意到各个示例中的所有命令都是按顺序执行的,即一个接一个。但在某些情况下,我们可能希望根据某些条件运行一些文本过滤操作,这就是流程控制语句的方法。 …...

OceanBase数据库诊断调优,与高可用架构——【DBA从入门到实践】第八期
在学习了《DBA从入门到实践》的前几期课程后,大家对OceanBase的安装部署、日常运维、数据迁移以及业务开发等方面应当已经有了全面的认识。若在实际应用中遇到任何疑问或挑战,欢迎您在OceanBase社区问答论坛中交流、讨论。此次,《DBA从入门到…...
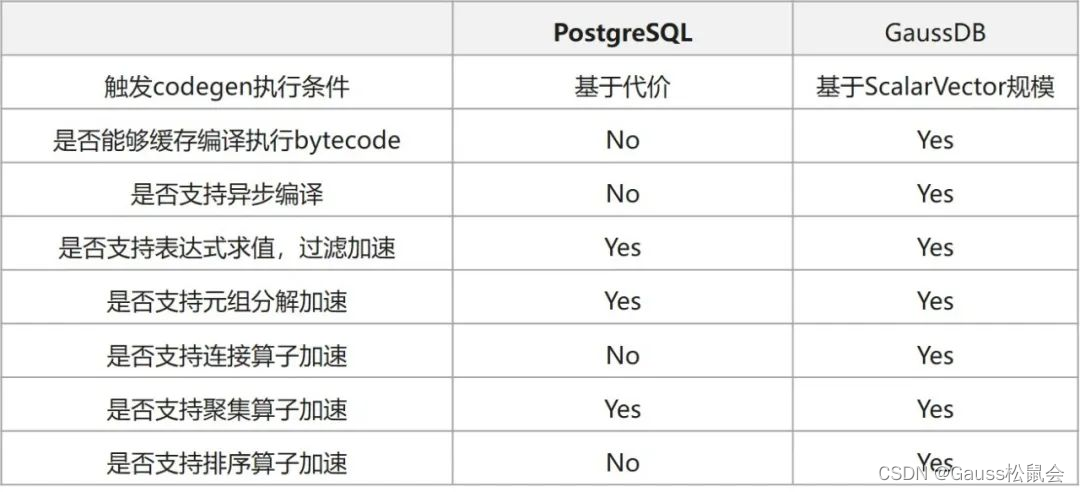
LLVM技术在GaussDB等数据库中的应用
目录 LLVM和数据库 LLVM适用场景 LLVM对所有类型的SQL都会有收益吗? LLVM在OLTP中就一定没有收益吗? GaussDB中的LLVM 1. LLVM在华为应用于数据库的时间线 2. GaussDB LLVM实现简析 3. GaussDB LLVM支持加速的场景 支持LLVM的表达式:…...

【SQL学习进阶】从入门到高级应用(三)
文章目录 ✨条件查询✨条件查询语法格式✨等于、不等于✨等于 ✨不等于 <> 或 ! ✨大于、大于等于、小于、小于等于✨大于 >✨大于等于 >✨小于 <✨小于等于 < ✨and✨or✨and和or的优先级问题✨between...and... 🌈你好呀!我是 山顶风…...

迷你手持小风扇哪个品牌续航强?五款强续航迷你手持小风扇推荐!
夏天就俩字儿:热和空调!太阳大得让人想躲,一出汗,感觉全身毛孔都在喊“太热啦”!这时空调简直是救命恩人啊,热得只想赖在屋里不出来。但出门总得面对大太阳,一出门就哗哗流汗。所以,…...
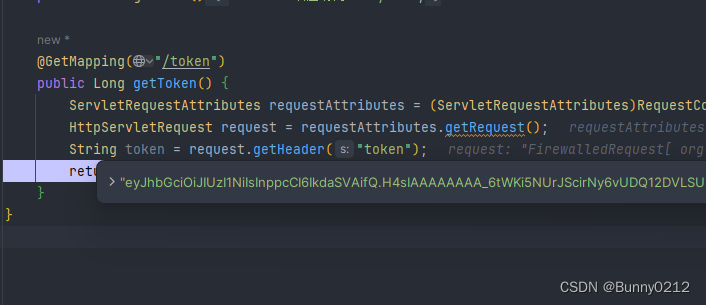
SpringBoot 微服务中怎么获取用户信息 token
SpringBoot 微服务中怎么获取用户信息 token 当我们写了一个A接口,这个接口需要调用B接口,但是B接口需要包含请求头内容,比如需要用户信息、用户id等内容,由于不在同一个线程中,使用ThreadLocal去获取数据是无法获取的…...

npm包-fflate
fflate 是一个快速、轻量级且纯JavaScript实现的压缩库,用于处理gzip、zlib和Deflate格式的数据压缩与解压缩。它专注于提供高性能的压缩算法实现,特别适合于浏览器环境及Node.js环境中使用,且不依赖任何外部库。fflate的优势在于其极小的体积…...

华为WLAN无线组网技术与解决方案
WLAN无线组网技术与解决方案 网络拓扑采用AP和AC旁挂式无线组网 配置思路: 1.让AP上线 1.1,使得AP能够获得IP地址 配置步骤: 1.把AC当作一个一个有管理功能的三层交换机 sys Enter system view, return user view with CtrlZ. [AC6605]vlan …...

DCNv4:重塑视觉模型核心,三倍速率的动态稀疏卷积如何炼成?
1. 从标准卷积到DCNv4的进化之路 计算机视觉领域的核心算子就像乐高积木里的基础模块,决定了整个模型的表达能力。传统卷积就像用固定形状的积木拼图,虽然稳定但缺乏灵活性。2017年诞生的可变形卷积(DCN)首次给积木加上了"可…...

RT-Thread裁剪实战:从98KB到28KB的嵌入式系统瘦身指南
1. 项目概述:为什么我们需要裁剪RT-Thread?如果你是一名嵌入式软件工程师,或者正在学习RT-Thread,那么“裁剪”这个词对你来说一定不陌生。RT-Thread作为一款优秀的国产开源实时操作系统,其标准版(或称完整…...

【亲测免费】 ADS1118驱动程序
ADS1118驱动程序 【下载地址】ADS1118驱动程序 本仓库提供了专用于ADS1118模数转换器(ADC)的驱动程序。ADS1118是一款高性能、高精度的16位模拟到数字转换器,广泛应用于需要精准测量的应用场景中,例如传感器数据采集系统、医疗设备…...

3步掌握抖音内容批量下载技巧:无水印视频保存终极指南
3步掌握抖音内容批量下载技巧:无水印视频保存终极指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppo…...

不只是远程桌面:用向日葵在Ubuntu上实现无人值守文件传输与SSH隧道
超越远程桌面:向日葵在Ubuntu上的高阶自动化实践 当大多数人提起向日葵时,第一反应往往是"远程控制软件"。但这款工具的实际能力远不止于此——在开发者手中,它可以成为打通内外网的生产力中枢。想象这样一个场景:你正在…...

React Fiber vs Vue 响应式:从调用栈到依赖图,前端两大架构的底层对决
写在前面 前端框架之争吵了快十年。但坦白说,大多数争论卡在"React 好用还是 Vue 好用"的层面,很少有人真正追问:这两个框架为什么从根上就是两套东西? 它们的差异不是 API 设计喜好不同,而是对"UI 的…...

终极免费Windows音频调校指南:用Equalizer APO解锁专业音质
终极免费Windows音频调校指南:用Equalizer APO解锁专业音质 【免费下载链接】equalizerapo Equalizer APO mirror 项目地址: https://gitcode.com/gh_mirrors/eq/equalizerapo 你是否对电脑的音质总是不满意?无论是听音乐、看电影还是玩游戏&…...

任天堂Switch游戏备份终极指南:nxdumptool完全解析
任天堂Switch游戏备份终极指南:nxdumptool完全解析 【免费下载链接】nxdumptool Generates XCI/NSP/HFS0/ExeFS/RomFS/Certificate/Ticket dumps from Nintendo Switch gamecards and installed SD/eMMC titles. 项目地址: https://gitcode.com/gh_mirrors/nx/nxd…...

重新定义光学设计:Inkscape光线追踪插件带来的矢量图形仿真新范式
重新定义光学设计:Inkscape光线追踪插件带来的矢量图形仿真新范式 【免费下载链接】inkscape-raytracing An extension for Inkscape that makes it easier to draw optical diagrams. 项目地址: https://gitcode.com/gh_mirrors/in/inkscape-raytracing 当…...

Rime中州韵配置避坑指南:从安装小狼毫到实现Emoji、花字、彩色文本的完整流程
Rime中州韵配置避坑指南:从安装小狼毫到实现Emoji、花字、彩色文本的完整流程 第一次接触Rime输入法的用户,往往会被其高度定制化的特性所吸引——无论是动态状态栏、彩色候选词,还是随心所欲的Emoji混输,都让人眼前一亮。但当真…...