Percona Toolkit 神器全攻略(实用类)
Percona Toolkit 神器全攻略(实用类)

Percona Toolkit 神器全攻略系列共八篇,前文回顾:
| 前文回顾 |
|---|
| Percona Toolkit 神器全攻略 |
| |
全文约定:
$为命令提示符、greatsql>为GreatSQL数据库提示符。在后续阅读中,依据此约定进行理解与操作
实用类
在Percona Toolkit中实用类共有以下工具
pt-align:将其它工具输出内容与列对齐pt-archiver:将表中的行存档到另一个表或文件中pt-find:查找表并执行命令pt-fingerprint:将查询转成密文pt-kill:Kill掉符合条件的SQLpt-k8s-debug-collector:从 k8s/OpenShift 集群收集调试数据(日志、资源状态等)pt-secure-collect:收集、清理、打包和加密数据
pt-align
概要
通过读取行并将其分成单词的方式来执行列对齐。该工具首先计算每行包含的单词数量,并尝试确定是否有一个占主导地位的数字,将其假设为每行的单词数量。接下来,pt-align会排除所有不符合该数量的行,并将下一行视为第一个非标题行。根据每个单词是否看起来像数字,它会决定列的对齐方式。最后,工具会遍历数据集,确定每列的宽度,并将它们格式化打印出来。
这对于调整vmstat或iostat的输出非常有帮助,使其更易于阅读。
用法
将其它工具的输出与列对齐,如果未指定FILES(文件)则读取STDIN(输入)
- pt-align [FILES]
如果工具打印以下输出(没有对齐)
DATABASE TABLE ROWS
foo bar 100
long_db_name table 1
another long_name 500使用 pt-align 将输出重新打印为(有对齐)
DATABASE TABLE ROWS
foo bar 100
long_db_name table 1
another long_name 500选项
该工具的命令行参数如下
| 参数 | 含义 |
|---|---|
| --help | 帮助,显示帮助并退出 |
| --version | 版本,显示版本并推出 |
最佳实践
对齐vmstat
当查看 vmstat 时,有时会遇到列对齐不整齐的情况。此时,可以使用 pt-align 工具来解决这个问题
# 未使用pt-align工具
$ vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----r b swpd free buff cache si so bi bo in cs us sy id wa st1 0 205472 181304 60 948960 0 0 0 1 1 1 1 2 98 0 0# 使用pt-align工具
$ vmstat | pt-align
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 205472 181260 60 948992 0 0 0 1 1 1 1 2 98 0 0对齐iostat
当查看 iostat 时,有时会遇到列对齐不整齐的情况。此时,可以使用 pt-align 工具来解决这个问题
# 未使用pt-align工具
$ iostat
avg-cpu: %user %nice %system %iowait %steal %idle0.86 0.00 1.51 0.00 0.00 97.62Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.11 0.33 1.31 6746368 27046909
dm-0 0.09 0.30 1.23 6263958 25261569
dm-1 0.03 0.02 0.09 452072 1782864# 使用pt-align工具
$ iostat | pt-align
0.86 0.00 1.51 0.00 0.00 97.62
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.11 0.33 1.31 6746368 27049993
dm-0 0.09 0.30 1.23 6263958 25264653
dm-1 0.03 0.02 0.09 452072 1782864pt-archiver
将MySQL/GreatSQL表中的行存档到另一个表或文件中
概要
pt-archiver 是一款在线归档工具,不会影响生产,但是用此命令操作的表必须要有主键,它可以实现如下功能:
- 归档历史数据
- 在线删除大量数据
- 数据导出和备份
- 数据远程归档
- 数据清理
用法
- pt-archiver [OPTIONS] --source DSN --where WHERE
将表从oltp实例归档到olap的实例中
$ pt-archiver --source h=oltp_server,D=test,t=tbl --dest h=olap_server --file '/var/log/archive/%Y-%m-%d-%D.%t' --where "1=1" --limit 1000 --commit-each从子表删除孤立行
$ pt-archiver --source h=host,D=db,t=child --purge --where 'NOT EXISTS(SELECT * FROM parent WHERE col=child.col)'选项
至少指定
--dest、--file或--purge之一如果 COPY 为 yes,
--dest中的 DSN 值默认为--source中的值
部分参数选项存在互斥,不可同时存在,详见:
| 选项A | 选项B | 关系 |
|---|---|---|
| --ignore | --replace | 互斥 |
| --txn-size | --commit-each | 互斥 |
| --low-priority-insert | --delayed-insert | 互斥 |
| --share-lock | --for-update | 互斥 |
| --analyze | --optimize | 互斥 |
| --no-ascend | --no-delete | 互斥 |
所有参数选项如下:
| 参数 | 含义 |
|---|---|
| --analyze | 为d则在dest上使用analyze,为s则在source上使用analyze,ds则表示两者都执行 |
| --ascend-first | 仅升序第一个索引列 |
| --ask-pass | 连接 MySQL/GreatSQL 时提示输入密码 |
| --buffer | 指定file时,仅在事务提交的时候刷新到磁盘 |
| --bulk-delete | 批量删除 |
| --[no]bulk-delete-limit | 是否开启批量删除限制,delete ... limit |
| --bulk-insert | 通过LOAD DATA批量插入 |
| --channel | 指定复制通道 |
| --charset | 字符集 |
| --[no]check-charset | 是否检查字符集,默认检查 |
| --[no]check-columns | 检查列,确保 --source 和 --dest 具有相同的列 |
| --check-interval | 定义归档每次暂停多长时间 |
| --check-slave-lag | 暂停归档,直到此副本的滞后小于--max-lag |
| --columns | 归档指定的字段,逗号分隔 |
| --commit-each | 提交每组获取和归档的行,与--limit配合使用 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --database | 连接到该数据库 |
| --delayed-insert | 将 DELAYED 修饰符添加到 INSERT 或 REPLACE 语句,低优先级插入。 不过此参数在5.6版本弃用,8.0版本不支持,服务器识别但忽略DELAYED关键字 |
| --dest | 此项指定一个表。pt-archiver 将插入从 --source 归档的行。 它使用与 --source 相同的 key=val 参数格式。 大多数缺失值默认为与 --source 相同的值,因此您不必重复 --source 和 --dest 中相同的选项。 使用 --help 选项查看从 --source 复制了哪些值。 |
| --dry-run | 打印查询并退出而不执行任何操作 |
| --file | 要存档到的文件,%D Database name;%t Table name,时间的格式化如例子中所描述,与--output-format结合使用可以指定输出的内容是dump(使用制表符作为分隔符)还是csv(使用逗号作为分隔符),与--header配合使用指定是否打印字段名字在第一行 |
| --for-update | 指定加读锁还是写锁。将 FOR UPDATE 修饰符添加到 SELECT 语句。与--share-lock互斥。 |
| --header | 在--file顶部打印列标题 |
| --help | 显示帮助 |
| --high-priority-select | 将 HIGH_PRIORITY 修饰符添加到 SELECT 语句。只适用表级别存储引擎(MyISAM、MEMORY等) |
| --host | 连接到主机 |
| --ignore | 忽略在执行INSERT时出现的可忽略错误。与--replace互斥 |
| --limit | 每个语句要获取和归档的行数。默认为一行 |
| --local | 不要将 OPTIMIZE 或 ANALYZE 查询写入 binlog |
| --low-priority-delete | 将 LOW_PRIORITY 修饰符添加到 DELETE 语句。此时会延迟执行该 DELETE 直到没有其他客户端从表中读取数据为止。只适用表级别存储引擎(MyISAM、MEMORY等) |
| --low-priority-insert | 低优先级插入。只适用表级别存储引擎(MyISAM、MEMORY等) |
| --max-flow-ctl | 用于pxc集群的类max-lag参数 |
| --max-lag | 暂停校验和,直到所有副本的滞后小于此值 |
| --no-ascend | 不使用升序索引优化。和no-delete互斥 |
| --no-delete | 不删除数据。和no-ascend互斥 |
| --optimize | 表示执行optimize,使用方式与analyze一致。和analyze互斥 |
| --output-format | 与--file一起使用指定输出格式 |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件。如果 PID 文件已存在且其中包含的 PID 与当前 PID 不同,则该工具将不会启动。但是,如果 PID 文件存在并且其中包含的 PID 不再运行,则该工具将使用当前 PID 覆盖 PID 文件。工具退出时,PID 文件会自动删除 |
| --plugin | 用作通用插件的 Perl 模块名称 |
| --port | 用于连接的端口号 |
| --primary-key-only | 仅主键列。使用主键列指定--columns的快捷方式 |
| --progress | 指定多少行打印一次进度信息 |
| --purge | 只清除,不归档。最好配合 --primary-key-only 指定表的主键列。这将防止无缘无故地从服务器获取所有列。 |
| --quick-delete | 给DELETE加quick修饰符。使用 QUICK 修饰符时,存储引擎不会合并索引叶子节点,从而提高删除操作的速度。只适用表级别存储引擎(MyISAM、MEMORY等) |
| --quiet | 不输出任何信息,包括statistics信息 |
| --replace | 导致--dest中的 INSERT 被写入 REPLACE。与--ignore互斥 |
| --retries | 遇到超时或死锁的重试次数 |
| --run-time | 指定运行时间,s=seconds, m=minutes, h=hours, d=days; 如果不指定用的是s |
| --[no]safe-auto-increment | 不要归档具有最大 AUTO_INCRMENT 的行 |
| --sentinel | 默认文件是/tmp/pt-archiver-sentinel,该文件存在则退出归档 |
| --slave-user | 从库用户 |
| --slave-password | 从库密码 |
| --set-vars | 设置执行时的MySQL/GreatSQL参数 |
| --share-lock | 指定加读锁还是写锁。将 LOCK IN SHARE MODE 修饰符添加到 SELECT 语句。与--for-update互斥 |
| --skip-foreign-key-checks | 使用 SET FOREIGN_KEY_CHECKS=0 禁用外键检查 |
| --sleep | 两次提取中间的休眠时间,默认不休眠 |
| --sleep-coef | 指定sleep时间为最后一次 SELECT 时间的多少倍 |
| --socket | 用于连接的套接字文件 |
| --source | 对于制动归档的表,选项“i”用于指定索引,默认情况下使用主键。选项“a”和“b”可用于调整语句通过二进制日志的流向。使用“b”选项会禁用指定连接上的二进制日志记录。若选择“a”选项,则连接将使用指定的数据库,可通过此方式防止二进制日志事件在服务器上执行时使用 --replicate-ignore-db 选项。这两个选项提供了实现相同目标的不同方法,即将数据从主服务器归档,同时在从服务器上保留它。可以在主服务器上运行清理作业,并通过所选方式防止其在从服务器上执行。 |
| --statistics | 收集和打印时间统计数据 |
| --stop | 通过创建sentine文件来停止归档 |
| --txn-size | 指定每次事务提交的行数。与commit-each互斥 |
| --unstop | 删除sentine文件 |
| --user | 登录的用户 |
| --version | 显示版本号 |
| --[no]version-check | 自动检查更新功能,默认是检查的 |
| --where | 指定 WHERE 子句限制归档哪些行。如果不需要 WHERE 条件,可使用 WHERE 1=1 |
| --why-quit | 打印退出原因 |
最佳实践
创建一张archiver_test表,并生成1000条数据
greatsql> CREATE TABLE archiver_test (id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(255),age INT,gender VARCHAR(10),timestamp TIMESTAMP
);greatsql> select count(*) from archiver_test;
+----------+
| count(*) |
+----------+
| 1000 |
+----------+
1 row in set (0.01 sec)在使用过程中可能会需要依赖例如:Cannot connect to MySQL because the Perl DBD::mysql module is not installed or not found.此时按提示安装相应依赖包即可
归档到同一实例上的不同表
注意!此操作会删除源表的数据,若不删除源表数据请加上使用
--no-delete
$ pt-archiver --source h=localhost,P=3306,u=root,D=test_db,t=archiver_test --charset=utf8mb4 --ask-pass --dest h=localhost,P=3306,u=root,D=test_db,t=archiver_test2 --ask-pass --where "id<100" --limit 1000 --commit-each
# 会让你输入密码(源端)
# 会让你输入密码(目标端)伪代码如下
pt-archiver --source h=源ip,P=源端口,u=用户,p=密码,D=库名,t=表名 --ask-pass --dest h=目标IP,P=端口,u=用户,p=密码,D=库名,t=表名 --ask-pass --where "id<100" --limit 1000 --commit-each需要目标表已创建且字段一致,否则报错:
"Table 'test_db.archiver_test2' doesn't exist "字段不一致报错:
”The following columns exist in --dest but not --source: name2“
检查下是否已经归档成功
greatsql> select count(*) from archiver_test2;
+----------+
| count(*) |
+----------+
| 99 |
+----------+
1 row in set (0.00 sec)因为--dest会从--source继承相同的值,所以上面也可以改写成以下方式
$ pt-archiver --source h=localhost,P=3306,u=root,D=test_db,t=archiver_test --charset=utf8mb4 --ask-pass --dest t=archiver_test2 --where "id<100" --limit 1000 --commit-each也可用Socket来进行登录,如果使用单机多实例部署GreatSQL的时候采用这种方法要尤其注意选择对应Socket
$ pt-archiver --source u=root,D=test_db,t=archiver_test -S /data/MySQL/GreatSQL.sock --charset=utf8mb4 --dest t=archiver_test2 --where "id<100" --limit 1000 --commit-each也可以通过 my.cnf 配置文件读取用户名和密码,但是在 my.cnf 文件中需要配置好用户名和密码
$ vim /etc/my.cnf
[client]
user=your_user_name
pass=sectet$ pt-archiver --source F=/etc/my.cnf,u=root,D=test_db,t=archiver_test --charset=utf8mb4 --dest t=archiver_test2 --where "id<100" --limit 1000 --commit-each归档时不写入Binlog
添加b=true指定归档操作不写入Binlog中
$ pt-archiver --source b=true,h=localhost,P=3306,u=root,D=test_db,t=archiver_test --charset=utf8mb4 --ask-pass --dest b=true,t=archiver_test3 --where "id<100" --limit 1000 --commit-each归档到文件
导出到外部文件,且不删除源端表的数据
$ pt-archiver --source h=localhost,D=test_db,t=archiver_test,u=root --where '1=1' --no-check-charset --no-delete --file="/data/bk/archiver_test.dat"因文件没有utf8mb4编码,所以设置了
no-check-charset不检查字符集
检查备份情况
$ tail -n 3 /data/bk/archiver_test.dat
997 Fukuda Akina 449 F 2022-02-15 05:54:27
998 Sara Nguyen 45 F 2018-07-08 13:35:45
999 Chan Ka Man 644 M 2012-02-08 18:18:14pt-find
概要
此工具可以查找符合条件的表,并做一些相应的操作。默认操作是打印数据库和表名称
用法
- pt-find [OPTIONS] [DATABASES]
选项
| 参数 | 含义 |
|---|---|
| --ask-pass | 连接 MySQL/GreatSQL 时提示输入密码 |
| --case-insensitive | 指定所有正则表达式搜索不区分大小写 |
| --charset | 默认字符集 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --database | 连接到该数据库 |
| --day-start | 从今天开始而不是从当前时间开始测量时间 |
| --defaults-file | 只从给定文件中读取 MySQL/GreatSQL 选项 |
| --help | 显示帮助 |
| --host | 连接到主机 |
| --or | 用 OR(而不是 AND)组合测试 |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件 |
| --port | 用于连接的端口号 |
| --[no]quote | 使用 MySQL/GreatSQL 的标准反引号字符引用 MySQL/GreatSQL 标识符名称 |
| --set-vars | 在这个以逗号分隔的 variable=value 对列表中设置 MySQL/GreatSQL 变量 |
| --socket | 用于连接的套接字文件 |
| --user | 登录的用户 |
| --version | 显示版本 |
| --[no]version-check | 版本检查 |
最佳实践
查找大于1G的表
$ pt-find --socket=/data/GreatSQL/mysql.sock --user=root --port=3306 --tablesize +1G
`tpch`.`customer`
`tpch`.`lineitem`
`tpch`.`orders`
`tpch`.`part`
`tpch`.`partsupp`查找修改过的表
# 30分钟之内
$ pt-find --socket=/data/GreatSQL/mysql.sock --user=root --port=3306 --mmin -30
`mysql`.`gtid_executed`
`test_db`.`archiver_test`# 30分钟之前
$ pt-find --socket=/data/GreatSQL/mysql.sock --user=root --port=3306 --mmin +30
`aptest`.`sys_dept`
`aptest`.`sys_user`此查找基于
INFORMATION_SCHEMA.TABLES表中的Update_time列,如果information_schema_stats_expiry设置的更新时间过长,将导致Update_time列不会实时更新。因此,在这种情况下,将无法准确地检索在过去30分钟内发生修改的表。
查找无数据的表
$ pt-find --socket=/data/GreatSQL/mysql.sock --user=root --port=3306 --empty
`db2`.`t1`
`db2`.`t2`查找表并修改存储引擎
# 查找1天内创建的MyISAM表
$ pt-find --socket=/data/GreatSQL/mysql.sock --user=root --port=3306 --ctime -1 --engine MyISAM
`test_db`.`myisam`# 查找1天内的MyISAM表并修改为InnoDB
$ pt-find --socket=/data/GreatSQL/mysql.sock --user=root --port=3306 --ctime -1 --engine MyISAM --exec "ALTER TABLE %D.%N ENGINE=InnoDB"# 验证下是否修改成功,此时可以用到上述的pt-align工具使输出更加美观
$ mysql -e "SHOW TABLE STATUS FROM test_db" | pt-align | grep your_table_name
myisam InnoDB ......# 查找1天前的InnoDB表
$ pt-find --socket=/data/GreatSQL/mysql.sock --user=root --port=3306 --ctime +1 --engine InnoDB
InnoDB和MyISAM两个存储引擎名字必须按照标准输入,否则将无法进行正确的查找
查找空表并删除
# 避免不必要的删除错误,先查找哪些是空表,在删除
$ pt-find --socket=/data/GreatSQL/mysql.sock --empty test_db
`test_db`.`archiver_test3`# 查找test_db库中空表并删除
$ pt-find --socket=/data/GreatSQL/mysql.sock --empty test_db --exec-plus "DROP TABLE %s"验证是否删除成功
greatsql> SHOW TABLES IN test_db LIKE 'archiver_test3';
Empty set (0.00 sec)所有表数据和索引总大小排序
$ pt-find --socket=/data/GreatSQL/mysql.sock --printf "%T\t%D.%N\n" | sort -rn
7992197120 `tpch`.`orders`
7817084928 `tpch`.`lineitem`
......# 输出有些没对齐,可以使用pt-align工具对齐
$ pt-find --socket=/data/GreatSQL/mysql.sock --printf "%T\t%D.%N\n" | sort -rn | pt-align
7992197120 `tpch`.`orders`
7817084928 `tpch`.`lineitem`
......pt-fingerprint
将查询转成密文
概要
此工具可以将SQL语句重新格式化为另一种抽象形式,既所有具体值都以?代替。可以适用于数据脱敏的场景。
用法
- pt-fingerprint [OPTIONS] [FILES]
选项
| 参数 | 含义 |
|---|---|
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --help | 显示帮助并退出 |
| --match-embedded-numbers | 匹配单词中嵌入的数字并替换为单个值 |
| --match-md5-checksums | 匹配 MD5 校验和并替换为单个值 |
| --query | 要转换为加密的查询 |
| --version | 显示版本并退出 |
最佳实践
替换单个语句
$ pt-fingerprint --query "select a, b, c from users where id = 5 and greatsql = 666"
select a, b, c from users where id = ? and greatsql = ?$ pt-fingerprint --query "INSERT INTO product(ID,NAME,PRICE) VALUES(1,'greatsql',666)"
insert into product(id,name,price) values(?+)如果SQL语句中字段名或表名有数字,也会被替换
$ pt-fingerprint --query "select a1, b2, c3 from users4 where id = 500 and greatsql = 8032"
select a?, ?, c? from users? where id = ? and greatsql = ?若不想替换字段名或表名可加上--match-embedded-numbers
$ pt-fingerprint --match-embedded-numbers --query "select a1, b2, c3 from users4 where id = 5 and greatsql = 666"
select a1, b2, c3 from users4 where id = ? and greatsql = ?
--match-md5-checksums参数使用也是同理,避免MD5值被替换
替换文件中语句
创建文件pt_fingerprint_test_sql.txt
$ vim pt_fingerprint_test_sql.txt
select a from users where greatsql = 666;
select b from users where greatsql = 777;
select c from users where
greatsql = 888;替换文件中的所有SQL语句
$ pt-fingerprint pt_fingerprint_test_sql.txt
select a from users where greatsql = ?
select b from users where greatsql = ?
select c from users where greatsql = ?不管文件内格式如何,pt-fingerprint工具都会规范化空格等
当然也可以用作替换慢日志(Slow.log)的SQL内容
pt-kill
Kill掉符合条件的SQL
概要
pt-kill可以Kill掉任何语句,特别出现大量的阻塞,死锁,或某个有问题的SQL导致MySQL/GreatSQL负载很高的情况。会默认过滤掉复制线程。
用法
- pt-kill [OPTIONS] [DSN]
选项
至少指定 --kill 、 --kill-query 、 --print 、 --execute-command 或 --stop 之一
部分参数选项存在互斥,不可同时存在,详见:
| 选项A | 选项B | 关系 |
|---|---|---|
| --any-busy-time | --each-busy-time | 互斥 |
| --kill | --kill-query | 互斥 |
| --daemonize | --test-matching | 互斥 |
所有参数选项如下:
| 选项 | 含义 |
|---|---|
| --ask-pass | 连接 MySQL/GreatSQL 时提示输入密码 |
| --charset | 默认字符集 |
| --config | 读取这个逗号分隔的配置文件列表,如果指定,这必须是命令行上的第一个选项 |
| --create-log-table | 如果--log-dsn表不存在,则创建 |
| --daemonize | 放在后台以守护进程的形式运行 |
| --database | 用于连接的数据库 |
| --defaults-file | 只从给定文件中读取 MySQL/GreatSQL 选项 |
| --filter | 丢弃此 Perl 代码不返回 true 的事件 |
| --group-by | 将匹配应用于由此 SHOW PROCESSLIST 列分组的每一类查询 |
| --help | 显示帮助并退出 |
| --host | 连接到主机 |
| --interval | 检查要终止的查询的频率 |
| --log | 守护进程时将所有输出打印到此文件 |
| --log-dsn | 将终止的每个查询存储在此 DSN 中 |
| --json | 将终止的查询打印为 JSON,必须与--print一起使用。 |
| --json-fields | 使用--json时指定要包含在 JSON 输出中的附加键 |
| --password | 连接时使用的密码 |
| --pid | 创建给定的 PID 文件 |
| --port | 用于连接的端口号 |
| --query-id | 打印刚刚被终止的查询的 ID |
| --rds | 表示相关实例位于 Amazon RDS 上 |
| --run-time | 退出前要运行多长时间 |
| --sentinel | 如果该文件存在则退出 |
| --slave-user | 设置用于连接从机的用户 |
| --slave-password | 设置用于连接从机的密码 |
| --set-vars | 在这个以逗号分隔的variable=value对列表中设置 MySQL/GreatSQL 变量 |
| --socket | 用于连接的套接字文件 |
| --stop | 使 pt-kill 创建 --sentinel 指定的哨兵文件并退出 |
| --[no]strip-comments | 从 PROCESSLIST 的 Info 列中的查询中删除 SQL 注释 |
| --user | 登录的用户 |
| --version | 显示版本并退出 |
| --[no]version-check | 版本检查 |
| --victims | 每个类中的哪些匹配查询将被终止 |
| --wait-after-kill | 杀死一个查询后等待,然后再寻找更多要杀死的查询 |
| --wait-before-kill | 在终止查询之前等待 |
最佳实践
Kill查询指定时间的连接
每十秒钟记录一下用时超过三十秒的查询语句,并且将这些语句输出到/data/pt_slow.log文件中
$ pt-kill --user=root --ask-pass --match-info "select|SELECT" --match-command='Query' --busy-time 30 --victims all --interval 10 --daemonize --print --log=/data/pt_slow.log--match-command:匹配当前连接的命令,对应 SHOW PROCESSLIST 捕获的 Command 对应值(可选值:Query、Sleep、Binlog Dump、Connect、Delayed insert、Execute、Fetch、Init DB、Kill、Prepare、Processlist、Quit、Reset stmt、Table Dump);--match-info:正则匹配正则运行的 SQL,区分大小写;--interval:多久运行一次。默认单位秒。默认值30秒
也可以加上--kill直接Kill掉符合条件的查询语句
$ pt-kill --user=root --ask-pass --match-info "select|SELECT" --match-command='Query' --busy-time 30 --victims all --interval 10 --daemonize --kill --log=/data/pt_slow.log
--victims默认是oldest只Kill最先发起,存在时间最长的查询。all Kill掉所有满足的线程。all-but-oldest只保留最长的不Kill其它都Kill掉
Kill指定IP的会话
打印出指定IP的会话
$ pt-kill --user=root --ask-pass --match-db='test_db' --match-host "192.168.6.55" --busy-time 30 --victims all --interval 10 --daemonize --print --log=/data/pt_ip.logKill指定IP的会话
$ pt-kill --user=root --ask-pass --match-db='test_db' --match-host "192.168.6.55" --busy-time 30 --victims all --interval 10 --daemonize --kill --log=/data/pt_ip.logKill指定用户的会话
Kill指定用户的会话
$ pt-kill --user=root --ask-pass --match-db='test_db' --match-user "greatsql" --victims all --interval 10 --daemonize --kill --log=/data/pt_user.logKill指定用户大于10秒的空闲链接
$ pt-kill --user=root --ask-pass --match-db='db_name' --match-user "greatsql" --victims all --interval 10 --daemonize --kill --match-command='Sleep' --idle-time 10 --log=/data/pt_user.logpt-kill工具会挂在后台定时Kill符合条件的用户、语句。
若需要停止请使用
kill -9 $(ps -ef| grep pt-kill |grep -v grep |awk '{print $2}')
pt-secure-collect
概要
pt-secure-collect用于收集、清理、打包和加密数据
用法
- pt-secure-collect [ ]
[ ...]
默认情况下,pt-secure-collect 将收集以下输出:
- pt-stalk
- pt-summary
- pt-mysql-summary
采集命令
- pt-secure-collect collect
解密命令
- pt-secure-collect decrypt
加密命令
- pt-secure-collect encrypt
清理命令
- pt-secure-collect sanitize
选项
最佳实践
收集GreatSQL信息
以非加密方式收集GreatSQL信息并且不删除临时文件
$ pt-secure-collect collect --mysql-user=root --mysql-password="" --mysql-port=3306 --mysql-host=localhost --bin-dir=/usr/bin --temp-dir=/data/data_collection --no-encrypt --no-remove-temp-filesINFO[2024-03-11 17:05:02] Creating temporary directory: /data/data_collection
INFO[2024-03-11 17:05:02] Temp directory is "/data/data_collection"
INFO[2024-03-11 17:05:02] Creating output file "/data/data_collection/pt-stalk_2024-03-11_17_05_02.out"
INFO[2024-03-11 17:05:02] Running pt-stalk --no-stalk --iterations=2 --sleep=30 --host=localhost --dest=/data/data_collection --port=3306 --user=root --password=********
INFO[2024-03-11 17:06:35] Creating output file "/data/data_collection/pt-summary_2024-03-11_17_06_35.out"
INFO[2024-03-11 17:06:35] Running pt-summary
INFO[2024-03-11 17:06:36] Creating output file "/data/data_collection/pt-mysql-summary_2024-03-11_17_06_36.out"
INFO[2024-03-11 17:06:36] Running pt-mysql-summary --host=localhost --port=3306 --user=root --password=********
INFO[2024-03-11 17:06:49] Sanitizing output collected data
INFO[2024-03-11 17:06:57] Creating tar file "/data/data_collection/data_collection.tar.gz"
--mysql-port和--mysql-host虽有默认值但是还是需要指定,否则在调用运行其它工具时会报错
可以从输出上看到,pt-secure-collect工具调用了pt-stalk、pt-summary、pt-mysql-summary这三款工具
进入data_collection文件夹即可看到所有的临时文件,以及一个data_collection.tar.gz压缩文件
$ ls /data/data_collection
2024_03_11_17_05_03-df 2024_03_11_17_05_03-opentables2 2024_03_11_17_05_33-diskstats 2024_03_11_17_05_33-processlist
2024_03_11_17_05_03-disk-space 2024_03_11_17_05_03-output 2024_03_11_17_05_33-dmesg data_collection.tar.gz .......其余省略加密文件
pt-secure-collect encrypt /data/pt_secure_collect.txt --outfile=/data/pt_secure_collect.aes
Encryption password: # 这里输入加密密码
Re type password: # 再次输入加密密码
INFO[2024-03-12 09:36:39] Encrypting file "/data/pt_secure_collect.txt" into "/data/pt_secure_collect.aes" # 加密成功加密成功后此时会生成一个后缀为aes的文件,直接查看会乱码
$ ls
pt_secure_collect.aes pt_secure_collect.txt$ cat pt_secure_collect.aes
5�66~x�y��+� ?i`��pESϡ>()�g�,�e�u #乱码解密文件
$ pt-secure-collect decrypt /data/pt_secure_collect.aes
Encryption password: # 输入加密的密码
INFO[2024-03-12 09:41:35] Decrypting file "/data/pt_secure_collect.aes" into "pt_secure_collect" $ cat pt_secure_collect
111
aaa
select * from test where id =2;假设输入错误密码,不会提示密码错误,而是输出乱码结果
$ pt-secure-collect decrypt /data/pt_secure_collect.aes
Encryption password: # 这里假设输入错误密码
INFO[2024-03-12 09:44:45] Decrypting file "/data/pt_secure_collect.aes" into "pt_secure_collect" $ cat pt_secure_collect
; �}X����#z1�e��s�/��E���OeB�6��,�� �# 加密文件
这个功能和上面介绍的pt-fingerprint工具有点类似,都是使用?替换关键信息
先造一个文本
$ cat pt_secure_collect.txt
select * from test where id =2;
ip = 192.168.6.66使用sanitize功能,会隐去关键信息和主机名
$ pt-secure-collect sanitize --input-file=/data/pt_secure_collect.txt --no-sanitize-queries
select * from test where id =?;
ip = hostname如果不隐去主机可以使用
--no-sanitize-hostnames如果不隐去查询可以使用
--no-sanitize-queries
本文完 :) 下章节将介绍Percona Toolkit 神器全攻略(配置类)
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:

社区有奖建议反馈: https://greatsql.cn/thread-54-1-1.html
社区博客有奖征稿详情: https://greatsql.cn/thread-100-1-1.html
(对文章有疑问或者有独到见解都可以去社区官网提出或分享哦~)
技术交流群:
微信&QQ群:
QQ群:533341697
微信群:添加GreatSQL社区助手(微信号:wanlidbc )好友,待社区助手拉您进群。
相关文章:
Percona Toolkit 神器全攻略(实用类)
Percona Toolkit 神器全攻略(实用类) Percona Toolkit 神器全攻略系列共八篇,前文回顾: 前文回顾Percona Toolkit 神器全攻略 全文约定:$为命令提示符、greatsql>为GreatSQL数据库提示符。在后续阅读中,…...

ARM GIC 和NVIC的区别
ARM GIC(Generic Interrupt Controller)和NVIC(Nested Vectored Interrupt Controller)是两种不同的中断控制器,它们在ARM架构中扮演着重要的角色,但各自有不同的设计和应用场景。 ARM GIC: G…...

CSS文本粒子动画特效之爱心粒子文字特效-Canvas
1. 效果图 2.完整代码 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><style>body,html {margin: 0;paddin…...
小熊家务帮day5 客户管理模块1 (小程序认证,手机验证码认证等)
客户管理模块 1.认证模块1.1 认证方式介绍1.1.1 小程序认证1.1.2 手机验证码登录1.1.3 账号密码认证 1.2 小程序认证1.2.1 小程序申请1.2.2 创建客户后端工程jzo2o-customer1.2.3 开发部署前端1.2.4 小程序认证流程1.2.4.1 customer小程序认证接口设计Controller层Service层调用…...
快捷键记录)
Blender 学习笔记(一)快捷键记录
Blender 的快捷键映射非常强大,如果学会将会快速提高工作效率,本文抄自 Blender 4.1 Manual,基于 Blender 4.1,因为自己使用 Windows,所以只记录 Windows 相关快捷键。 全局快捷键 键位作用ctrl0打开文件ctrls保存文…...
 源码编译cryptopp库 - apt版本过旧)
ubuntu linux (20.04) 源码编译cryptopp库 - apt版本过旧
下载最新版 https://www.cryptopp.com/#download 编译安装: #下载Cryptopp源码 #git clone https://gitee.com/PaddleGitee/cryptopp.git#进入文件夹 cd cryptopp #编译,多cpu处理 make -j8 #安装,默认路径:/usr/local sudo m…...
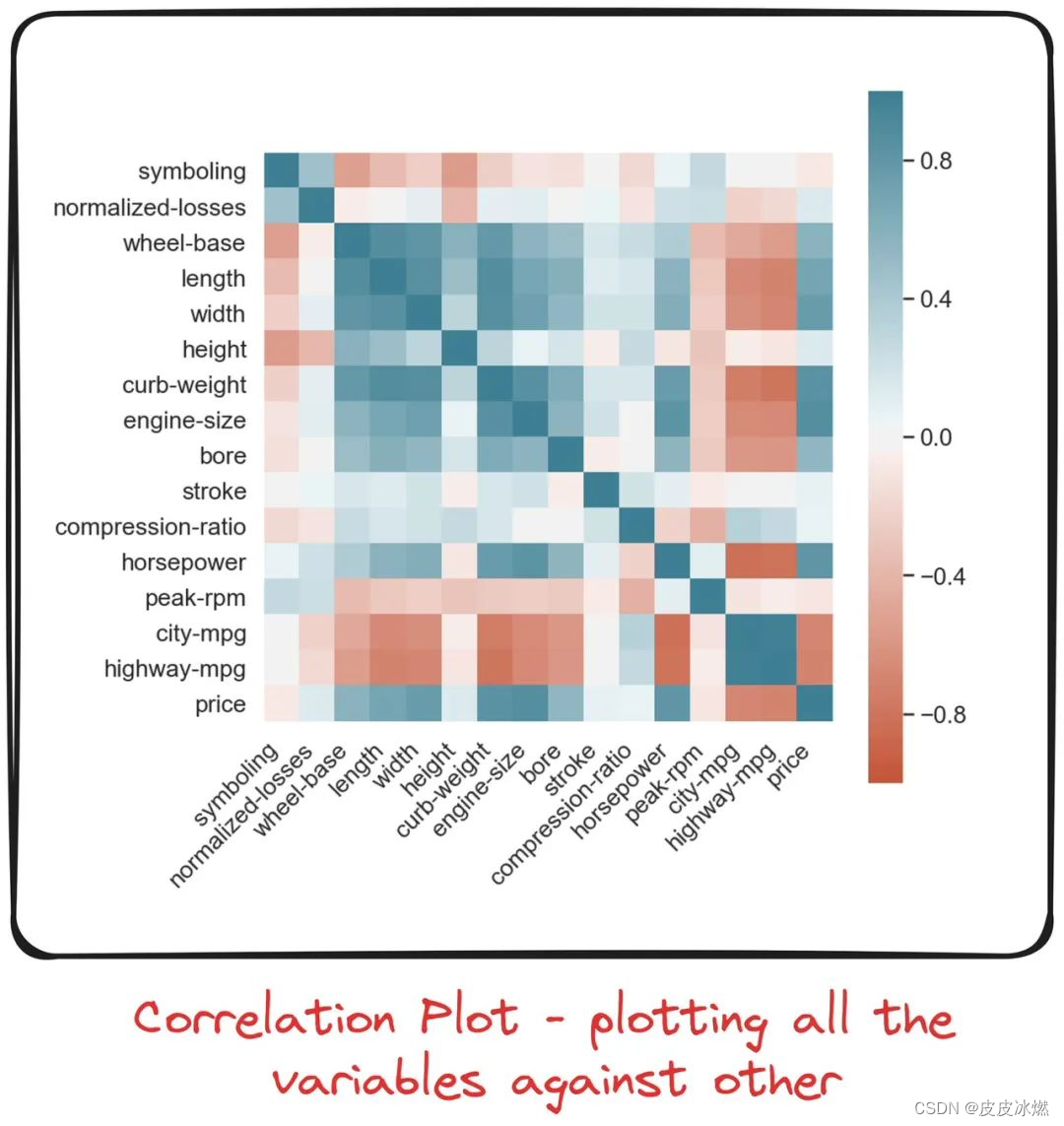
机器学习-3-特征工程的重要性及常用特征选择方法
参考特征重要性:理解机器学习模型预测中的关键因素 参考[数据分析]特征选择的方法 1 特征重要性 特征重要性帮助我们理解哪些特征或变量对模型预测的影响最大。 特征重要性是数据科学中一个至关重要的概念,尤其是在建立预测性任务的模型时。想象你正在尝试预测明天是否会下…...

QGis3.34.5工具软件保存样式,软件无反应问题
在使用QGis软件保存SLD样式的时候,每次保存样式,软件都进入无反应状态,导致无法生成样式文件 百度中多次查询问题点,终未能在在3.34.5这个版本上解决问题。 考虑到可能是软件本身问题,于是删除了3.34.5这个版本&#x…...

JavaScript(ES6)入门
ES6 1、介绍 ECMAScript 6(简称ES6)是于2015年6月正式发布的JavaScript 语言的标准,正式名为ECMAScript 2015(ES2015)。它的目标是使得JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语言。…...

深入分析 Android Activity (十)
文章目录 深入分析 Android Activity (十)1. Activity 的资源管理1.1 使用资源 ID 访问资源1.2 Drawable 资源1.3 使用 TypedArray 管理资源1.4 使用资源配置 2. Activity 的数据存储2.1 SharedPreferences2.2 文件存储2.3 SQLite 数据库2.4 ContentProvider 3. Activity 的性能…...

考试“挂了“用日语怎么说,柯桥商务日语培训
1、もえる 热衷于……,燃烧 除了“燃烧”,还有“热衷于……”的意思,如“家が燃える(房子着火了)”,“勉強に燃える(热衷于学习)”。 A:今(いま&…...
【机器学习300问】103、简单的经典卷积神经网络结构设计成什么样?以LeNet-5为例说明。
一个简单的经典CNN网络结构由:输入层、卷积层、池化层、全连接层和输出层,这五种神经网络层结构组成。它最最经典的实例是LeNet-5,它最早被设计用于手写数字识别任务,包含两个卷积层、两个池化层、几个全连接层,以及最…...

【代码随想录算法训练营第37期 第二十一天 | LeetCode530.二叉搜索树的最小绝对差、501.二叉搜索树中的众数、236. 二叉树的最近公共祖先】
代码随想录算法训练营第37期 第二十一天 | LeetCode530.二叉搜索树的最小绝对差、501.二叉搜索树中的众数、236. 二叉树的最近公共祖先 一、530.二叉搜索树的最小绝对差 解题代码C: /*** Definition for a binary tree node.* struct TreeNode {* int val;* …...

2023 年网络等级保护考试题库及答案
一、单项选择题 1.在等保 1.0 的根本要求中,网络设备防护的内容归属于网络安全,在等保 2.0 中将其归属到〔〕。 A 安全通信网络 B 安全区域边界 C 安全计算环境 D 安全治理中心 答案:c 2.应成立指导和治理网络安全工作的委员会或领导小组&…...
springboot集成nacos
springboot集成nacos 1.版本2. POM依赖3. nacos服务3.1 下载nacos压缩包3.2 启动nacos 4. yaml配置5.Demo5.1 配置中心简单格式获取方式普通方式还可以再启动类上添加注解完成5.2 获取json格式的demo5.2 自动注册根据yaml配置 1.版本 nacos版本:2.3.2 springboot版本ÿ…...

NoSQL数据库技术与应用 教学设计
《NoSQL数据库技术与应用》 教学设计 课程名称:NoSQL数据库技术与应用 授课年级: 20xx年级 授课学期: 20xx学年第一学期 教师姓名: 某某老师 2020年5月6日 课题 名称 第1章 初识NoSQL 计划 学时 3 课时 内容 分析 随着云计算、…...
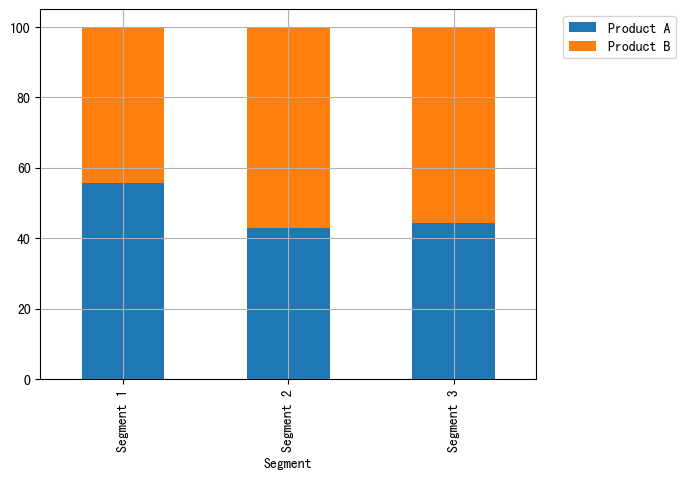
比较(一)利用python绘制条形图
比较(一)利用python绘制条形图 条形图(Barplot)简介 条形图主要用来比较不同类别间的数据差异,一条轴表示类别,另一条则表示对应的数值度量。 快速绘制 基于seaborn import seaborn as sns import matplo…...

【面试】Oracle JDK和Open JDK什么关系?
目录 1. 起源与发展2. 代码与许可3. 功能与组件4. 使用场景5. 版本更新与支持 1. 起源与发展 1.Oracle JDK是由Oracle公司基于Open JDK源代码开发的商业版本。2.Open JDK是java语言的一个开源实现。 2. 代码与许可 1.Oracle JDK包含了闭源组件,并根据二进制代码许…...

科学技术创新杂志科学技术创新杂志社科学技术创新编辑部2024年第10期目录
科技创新 单桩穿越岩溶发育地层力学特征与溶洞处置措施研究 刘飞; 1-7《科学技术创新》投稿:cnqikantg126.com 基于多目标优化的中低压配电网电力规划研究 向星山;杨承俊;张寒月; 8-11 激光雷达测绘技术在工程测绘中的应用研究 张军伟;闫宏昌; 12-15 …...

ES数据导出成csv文件
推荐使用es2csv 工具。 命令行实用程序,用Python编写,用于用Lucene查询语法或查询DSL语法查询Elasticsearch,并将结果作为文档导出到CSV文件中。该工具可以在多个索引中查询批量文档,并且只获取选定的字段,这减少了查…...
百科全书从“深“到“无限深“)
深度神经网络(DNN)百科全书从“深“到“无限深“
一、开篇:深度的奇迹 2012 年 9 月 30 日。 ImageNet 挑战赛的结果在 Florence 公布。所有人都以为冠军会延续过去 3 年的传统——传统计算机视觉方法(SIFT、HOG、SVM)小幅领先。 但那一年,一个叫 AlexNet 的"怪物"出现了。8 层的卷积神经网络,Top-5 错误率 …...

STM32体重秤电子秤称重超重报警Proteus仿真资源包
STM32体重秤电子秤称重超重报警Proteus仿真资源包 【下载地址】STM32体重秤电子秤称重超重报警Proteus仿真资源包 本资源包提供了基于STM32单片机的体重秤电子秤称重超重报警系统的完整解决方案。资源内容包括源代码、Proteus仿真文件以及全套相关资料,帮助用户快速…...

【亲测免费】 提升数据传输效率:AccessDatabaseEngine_X64 2010 安装包推荐
提升数据传输效率:AccessDatabaseEngine_X64 2010 安装包推荐 【下载地址】AccessDatabaseEngine_X642010安装包 本仓库提供了一个名为 AccessDatabaseEngine_X64_2010.rar 的资源文件下载。该文件是 Microsoft Access 2010 数据库引擎的可再发行程序包,…...

别死磕Datasheet了!用ADI官方ADF435x软件工具,5分钟搞定频点计算与寄存器配置
告别手动计算:ADI官方ADF435x工具的高效频点配置指南 在射频电路设计中,频率合成器的配置往往是工程师面临的第一个挑战。ADF4350作为业界广泛使用的宽带频率合成器芯片,其强大的性能背后是复杂的寄存器配置体系。传统方法依赖Datasheet中的公…...

对比直接使用厂商API体验Taotoken在计费透明度上的优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商API体验Taotoken在计费透明度上的优势 在集成大模型能力到实际业务的过程中,除了模型的性能和稳定性&…...

如何快速掌握Wallpaper Engine资源处理工具:面向初学者的完整指南
如何快速掌握Wallpaper Engine资源处理工具:面向初学者的完整指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 你是否曾经遇到过想要修改Wallpaper Engine动态壁纸&a…...

Windows远程桌面终极解锁指南:RDP Wrapper完整使用方案
Windows远程桌面终极解锁指南:RDP Wrapper完整使用方案 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap 还在为Windows家庭版无法使用远程桌面而烦恼吗?是否曾经羡慕专业版用户能够享受多用户…...

告别元器件搜索焦虑:立创EDA专业版+立创商城联动使用技巧全解析
告别元器件搜索焦虑:立创EDA专业版立创商城联动使用技巧全解析 在电子设计领域,元器件选型与供应链管理一直是工程师面临的核心挑战之一。当项目进入关键阶段,一个看似简单的0.1uF电容缺货或封装不匹配,就可能引发连锁反应&#x…...

接入Taotoken多模型路由后服务端响应稳定性提升感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 接入Taotoken多模型路由后服务端响应稳定性提升感受 1. 背景:生产环境对AI服务稳定性的需求 在构建依赖大模型API的生…...

Windows驱动存储管理终极指南:DriverStore Explorer高效清理系统驱动垃圾
Windows驱动存储管理终极指南:DriverStore Explorer高效清理系统驱动垃圾 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer Windows驱动存储管理是系统管理员和高级用户面临的…...