【机器学习】Pandas中to_pickle()函数的介绍与机器学习中的应用
【机器学习】Pandas中to_pickle()函数的介绍和机器学习中的应用

🌈 欢迎莅临我的个人主页👈这里是我深耕Python编程、机器学习和自然语言处理(NLP)领域,并乐于分享知识与经验的小天地!🎇
🎓 博主简介:
我是云天徽上,一名对技术充满热情的探索者。多年的Python编程和机器学习实践,使我深入理解了这些技术的核心原理,并能够在实际项目中灵活应用。尤其是在NLP领域,我积累了丰富的经验,能够处理各种复杂的自然语言任务。
🔧 技术专长:
我熟练掌握Python编程语言,并深入研究了机器学习和NLP的相关算法和模型。无论是文本分类、情感分析,还是实体识别、机器翻译,我都能够熟练运用相关技术,解决实际问题。此外,我还对深度学习框架如TensorFlow和PyTorch有一定的了解和应用经验。
📝 博客风采:
在博客中,我分享了自己在Python编程、机器学习和NLP领域的实践经验和心得体会。我坚信知识的力量,希望通过我的分享,能够帮助更多的人掌握这些技术,并在实际项目中发挥作用。机器学习博客专栏几乎都上过热榜第一:https://blog.csdn.net/qq_38614074/article/details/137827304,欢迎大家订阅
💡 服务项目:
除了博客分享,我还提供NLP相关的技术咨询、项目开发和个性化解决方案等服务。如果您在机器学习、NLP项目中遇到难题,或者对某个算法和模型有疑问,欢迎随时联系我,我会尽我所能为您提供帮助,个人微信(xf982831907),添加说明来意。
在数据分析和机器学习的项目中,我们经常需要存储和处理大量的数据。Pandas是一个强大的Python库,用于数据处理和分析。其中,pd.to_pickle()函数提供了一种高效的序列化Pandas对象(如DataFrame、Series等)到磁盘的方式,以便后续加载和使用。本文将深入解析pd.to_pickle()函数的各个参数,并通过实际案例展示如何使用该函数来保存和加载数据,特别是机器学习模型。
一、pd.to_pickle()函数概述
pd.to_pickle()函数是Pandas库中的一个方法,用于将Pandas对象(如DataFrame、Series)序列化并保存到磁盘上的pickle文件中。Pickle是Python提供的一种标准序列化方法,它可以将Python对象转换为一种可以存储或传输的格式。
1.1 函数签名
DataFrame.to_pickle(path, compression='infer', protocol=4)
1.2 参数详解
path:字符串类型,指定输出文件的路径。compression:字符串类型或None,指定压缩方式。'infer’表示自动选择合适的压缩方式,‘gzip’、‘bz2’、‘zip’、‘xz’或None表示使用特定的压缩方式。默认为’infer’。protocol:整数类型,指定pickle协议版本。pickle协议定义了序列化和反序列化时使用的数据格式和特性。Pandas默认使用pickle协议版本4,因为它支持Python 3的所有特性,并且兼容性较好。
二、使用案例
2.1 保存DataFrame到pickle文件
假设我们有一个名为df的DataFrame,包含一些示例数据:
import pandas as pd
import numpy as np# 创建一个示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'Salary': [50000, 60000, 70000]
}
df = pd.DataFrame(data)# 使用to_pickle()保存DataFrame到文件
df.to_pickle('data.pkl')
在上面的代码中,我们使用df.to_pickle('data.pkl')将DataFrame对象df保存到名为data.pkl的pickle文件中。
2.2 加载pickle文件到DataFrame
要加载pickle文件中的数据到DataFrame,我们可以使用pd.read_pickle()函数:
# 加载pickle文件中的数据到DataFrame
loaded_df = pd.read_pickle('data.pkl')
print(loaded_df)
执行上述代码后,我们将看到与原始DataFrame相同的输出。
2.3 保存和加载机器学习模型
除了DataFrame和Series外,pd.to_pickle()函数还可以用于保存和加载机器学习模型。虽然模型本身不是Pandas对象,但我们可以将模型作为Python对象保存到pickle文件中。以下是一个使用scikit-learn库训练一个简单的线性回归模型,并将其保存到pickle文件的示例:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split# 假设我们有一个名为X的特征矩阵和一个名为y的目标变量向量
X = np.random.rand(100, 5)
y = np.random.rand(100, 1).ravel()# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练线性回归模型
model = LinearRegression()
model.fit(X_train, y_train)# 将模型保存到pickle文件
with open('model.pkl', 'wb') as f:pickle.dump(model, f)# 加载pickle文件中的模型
with open('model.pkl', 'rb') as f:loaded_model = pickle.load(f)# 使用加载的模型进行预测
predictions = loaded_model.predict(X_test)
print(predictions)
注意,在上述代码中,我们使用了Python内置的pickle模块来保存和加载模型,而不是pd.to_pickle()函数。这是因为模型本身不是Pandas对象,但我们可以将其视为普通的Python对象进行处理。使用pickle.dump()和pickle.load()函数可以实现相同的功能。
三、总结
pd.to_pickle()函数是Pandas库中的to_pickle()函数提供了一种简单且高效的方式来序列化和保存Pandas对象(如DataFrame、Series等)到磁盘上的pickle文件中。这种方法对于长期存储或在不同Python会话之间共享数据特别有用。在本博文中,我们将进一步探讨to_pickle()函数的参数以及如何使用它来保存和加载数据,特别是机器学习模型。
1. to_pickle()函数参数详解
path:这是必需的参数,指定了pickle文件的保存路径。你可以使用相对路径或绝对路径。compression:这个参数允许你指定压缩算法,用于减少pickle文件的大小。默认值为'infer',意味着Pandas将尝试选择最优的压缩算法(如gzip)。你也可以显式地指定'gzip'、'bz2'、'xz'等压缩算法,或者直接使用'none'不进行压缩。protocol:这个参数决定了pickle协议的版本。pickle协议有多个版本,每个版本都有其特定的优势和兼容性。Pandas默认使用协议版本4,它支持Python 3的所有特性,并且具有相对较好的兼容性和性能。
2. 使用案例
2.1 保存DataFrame到pickle文件
假设我们有一个DataFrame对象df,我们想将其保存到pickle文件中:
import pandas as pd# 创建一个示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35],'Salary': [50000, 60000, 70000]
}
df = pd.DataFrame(data)# 使用to_pickle()保存DataFrame到文件
df.to_pickle('data.pkl', compression='gzip')
在这个例子中,我们使用了compression='gzip'参数来压缩pickle文件。
2.2 加载pickle文件到DataFrame
要从pickle文件中加载数据到DataFrame,你可以使用pd.read_pickle()函数:
# 加载pickle文件中的数据到DataFrame
loaded_df = pd.read_pickle('data.pkl')
print(loaded_df)
2.3 保存和加载机器学习模型
虽然机器学习模型本身不是Pandas对象,但你可以使用pickle模块来保存和加载它们。以下是一个使用scikit-learn训练模型并将其保存到pickle文件的示例:
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
import pickle# 创建模拟数据
X, y = make_regression(n_samples=100, n_features=1, noise=0.1)# 训练线性回归模型
model = LinearRegression()
model.fit(X, y)# 将模型保存到pickle文件
with open('model.pkl', 'wb') as f:pickle.dump(model, f)# 加载pickle文件中的模型
with open('model.pkl', 'rb') as f:loaded_model = pickle.load(f)# 使用加载的模型进行预测
predictions = loaded_model.predict([[2]])
print(predictions)
在这个例子中,我们使用了Python内置的pickle模块来保存和加载模型。注意,我们使用了'wb'和'rb'模式来打开文件,分别表示以二进制写入和读取模式。
3. 注意事项
- 安全性:pickle文件可以包含任意的Python代码,因此加载来自不可信来源的pickle文件可能存在安全风险。确保只加载你信任来源的pickle文件。
- 兼容性:不同版本的Python和库可能生成不兼容的pickle文件。尽量使用与生成pickle文件时相同的Python和库版本来加载它。
- 性能:对于非常大的数据集,pickle文件的加载和保存可能会比较慢。在这种情况下,你可能需要考虑使用其他序列化方法或格式,如HDF5、Parquet等。
4. 结论
pd.to_pickle()函数是Pandas库中一个强大的工具,用于保存Pandas对象到磁盘。通过了解该函数的参数和使用案例,你可以更有效地利用它来处理和分析数据。然而,也需要注意pickle文件的安全性和兼容性问题,并在必要时考虑使用其他序列化方法或格式。
相关文章:
【机器学习】Pandas中to_pickle()函数的介绍与机器学习中的应用
【机器学习】Pandas中to_pickle()函数的介绍和机器学习中的应用 🌈 欢迎莅临我的个人主页👈这里是我深耕Python编程、机器学习和自然语言处理(NLP)领域,并乐于分享知识与经验的小天地!🎇 &#…...

lightning的hook顺序
结果 setup: 训练循环开始前设置数据加载器和模型。 configure_optimizers: 设置优化器和学习率调度器。 on_fit_start: 训练过程开始。 on_train_start: 训练开始。 on_train_epoch_start: 每个训练周期开始。 on_train_batch_start: 每个训练批次开始。 on_before_bac…...
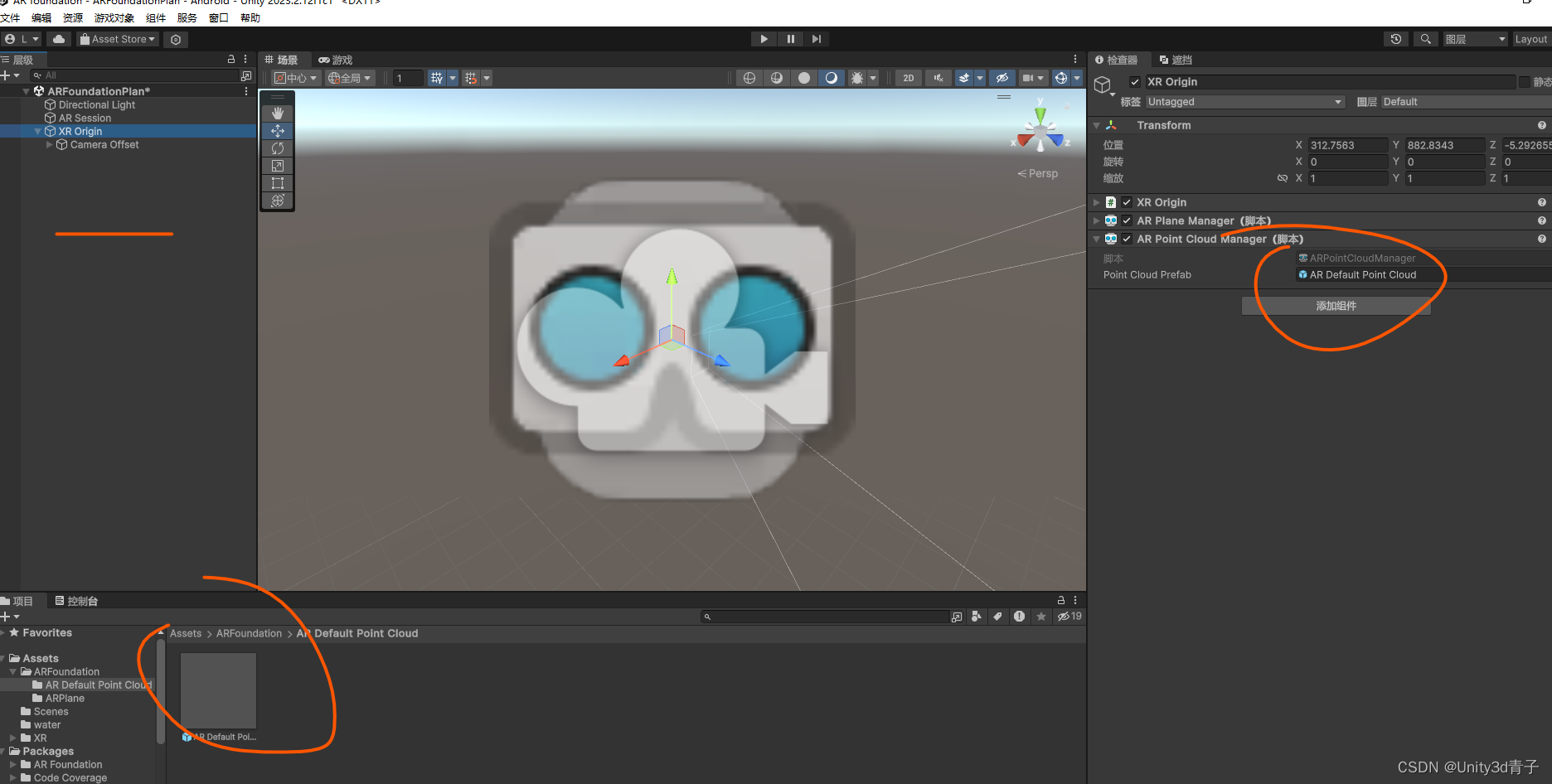
【ARFoundation自学03】AR Point Cloud 点云(参考点标记)功能详解
和平面识别框架一样 1为XR Origin添加AR Point Cloud Manager组件 然后你的ar应用就具备了点云识别功能,就这么简单 2.可视化这些云点 创建一个美术效果的预制体,人家提供了预设模板 然后拖到仓库(ASSETS)创建预制体ÿ…...

x264 码率控制中实现 VBV 算法源码分析
关于 VBV 的解释与原理可以参考x264 码率控制 VBV 原理。 x264中 VBV 算法执行的流程 vbv 参数配置相关函数 x264_param_default函数 功能:编码参数默认设置,关于 vbv的参数的默认设置;函数内vbv相关代码:/* ... */ //代码有删减 param->rc.i_vbv_max_bitrate = 0; par…...

宝兰德入选“鑫智奖·2024金融数据智能运维创新优秀解决方案”榜单
近日,由金科创新社主办、全球金融专业人士协会支持的“2024 鑫智奖第六届金融数据智能优秀解决方案”评选结果正式公布。凭借卓越的技术实力和方案能力,宝兰德「智能全链路性能监控解决方案」从90个参选方案中脱颖而出,荣誉入选“鑫智奖2024金…...

Unity3D雨雪粒子特效(Particle System)
系列文章目录 unity工具 文章目录 系列文章目录👉前言👉一、下雨的特效1-1.首先就是创建一个自带的粒子系统,整几张贴图,设置一下就能实现想要的效果了1-2 接着往下看视频效果 👉二、下雪的特效👉三、下雪有积雪的效果3-1 先把控…...
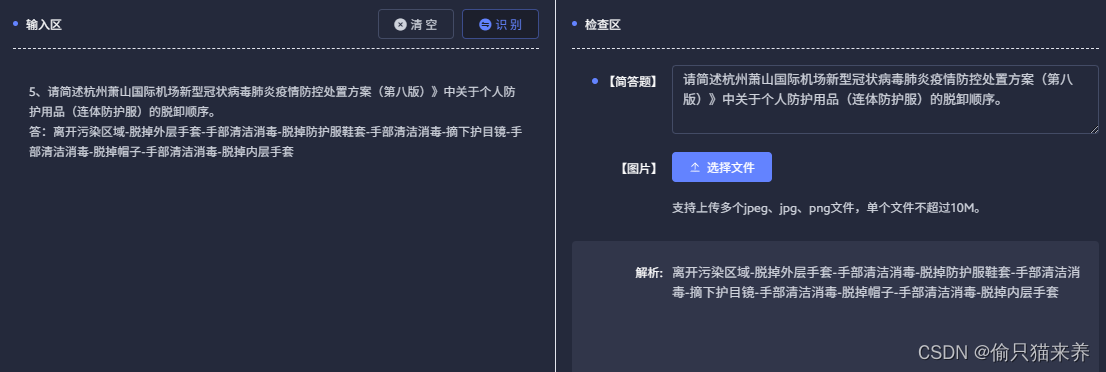
记录使用自定义编辑器做试题识别功能
习惯了将解析写在代码注释,这里就直接上代码啦,里面用到的bxm-ui3组件库是博主基于element-Plus做的,可以通过npm i bxm-ui3自行安装使用 // 识别方法: // dom 当前识别数据所在区域, questionType 当前点击编辑选择的题目类型&a…...

MySQL索引和视图
MySQL索引和视图是关系型数据库MySQL中的两个重要概念。索引用于优化数据库的查询性能,而视图用于提供一个逻辑上的表结构,方便用户查询和操作数据。 索引是一种数据结构,可以加速对数据库表中的数据进行查询的速度。通过创建索引࿰…...

Java单元测试Mock的用法,关于接口测试的用例
Testvoid getAllTradeDateList() {// 创建模拟对象Bc6CalculateService calculateService Mockito.mock(Bc6CalculateService.class);String allTradeDateListStr ExcelUtil.excelToJsonStr("bc6/NibTradeDate.xlsx");// 设置模拟行为List<NibTradeDateCloudDto…...

《心理学报》文本分析技术最新进展总结盘点
这些研究展示了文本分析在多个心理学领域内的强大应用,包括情境判断测验的自动化评分、自闭症儿童教育干预的学习效果评估、中文文本阅读的词切分和词汇识别机制、网络突发事件的负性偏向分析,以及小学生羞怯特质的预测与语言风格模型构建。通过采用机器…...

json格式文件备份redis数据库 工具
背景: 项目组要求使用 json备份redis缓存数据库内容。 附件里工具是一个包含redis-dump工具的镜像文件,方便用户在局域网中使用容器备份redis缓存数据库。 使用步骤: 解压tar文件,导入镜像 docker load < redis_dump_of_my…...

JAVA系列:NIO
NIO学习 一、前言 先来看一下NIO的工作流程图: NIO三大核心组件,channel(通道)、Buffer(缓冲区)、selector(选择器)。NIO利用的是多路复用模型,一个线程处理多个IO的读…...

偏微分方程算法之抛物型方程差分格式编程示例二
目录 一、研究问题 二、C++代码 三、结果分析 一、研究问题 采用向后欧拉格式计算抛物型方程初边值问题:...

linux 查看 线程名, 线程数
ps -T -p 3652 ps H -T <PID> ps -eLf | grep process_name top -H -p <pid> 查看进程创建的所有线程_ps 显示一个进程的所有线程名字-CSDN博客...

python class __getattr__ 与 __getattribute__ 的区别
在Python中,__getattr__是一个特殊的方法,用于处理访问不存在的属性时的行为。它通常在类中被重写,以便在属性访问失败时提供自定义的处理逻辑。 __getattr__ 的使用 1. 基本用法 __getattr__方法在访问类实例的某个不存在的属性时自动调用…...

[ C++ ] 类和对象( 下 )
初始化列表 初始化列表:以一个冒号开始,接着是一个以逗号分隔的数据成员列表,每个"成员变量"后面跟 一个放在括号中的初始值或表达式。 class Date { public: Date(int year, int month, int day): _year(year), _month(month), _d…...
这么多不同接口的固态硬盘,你选对了嘛!
固态硬盘大家都不陌生,玩游戏、办公存储都会用到。如果自己想要给电脑或笔记本升级下存储,想要存储更多的文件,该怎么选购不同类型的SSD固态盘呐,下面就来认识下日常使用中常见的固态硬盘。 固态硬盘(Solid State Drive, SSD)作为数据存储技术的革新力量,其接口类型的选…...
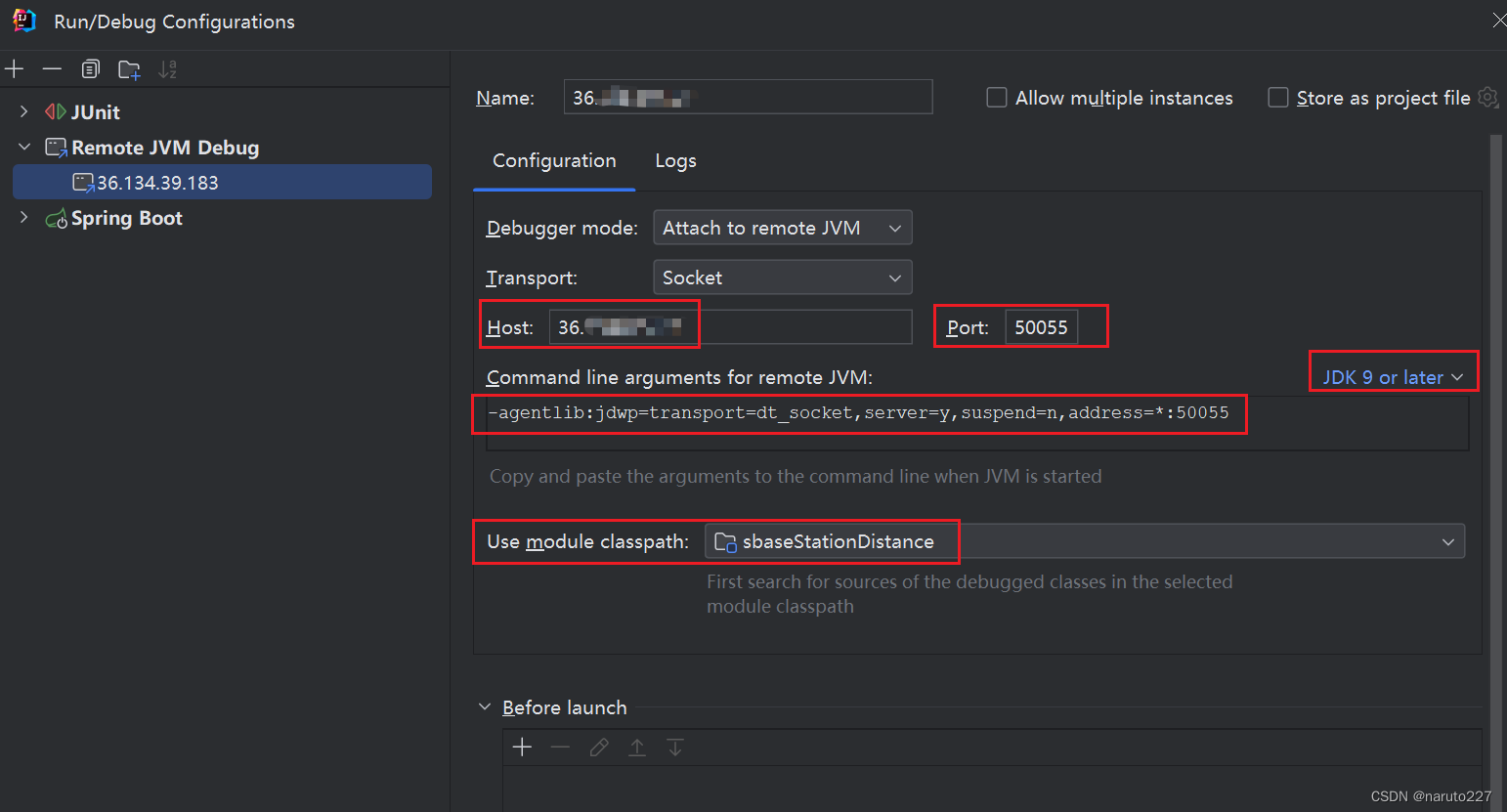
使用IDEA远程debug调试
文章目录 应用背景开启方式IDEA设置启动脚本改造 参考资料 应用背景 springboot项目,部署到服务器上,需要开启远程debug跟踪代码。 使用idea开启远程debug。 开启方式 IDEA设置 选择 Edit Configuration 如图,点击加号,选择Re…...

开源自定义表单系统源码 一键生成表单工具 可自由DIY表单模型+二开
分享一款开源自定义表单系统源码,能够实现99%各行业的报名、预约、加盟申请、调查等应用,而且同时多开创建多个表单,支持自定义各种字段模型,市面上需要的表单模型都含了,随便自定义啦,含完整的代码包和详细…...

【java10】集合中新增copyof创建只读集合
在Java中,集合(如List、Set、Map等)是编程中常用的数据结构。然而,在某些场景下,我们可能希望集合中的数据是只读的,即不允许修改集合中的元素。在Java8及之前,要实现这样的功能,我们…...

webpack-blocks生态全景:从官方块到第三方扩展的完整盘点
webpack-blocks生态全景:从官方块到第三方扩展的完整盘点 【免费下载链接】webpack-blocks 📦 Configure webpack using functional feature blocks. 项目地址: https://gitcode.com/gh_mirrors/we/webpack-blocks webpack-blocks是一个革命性的w…...

10. Doris 系列第10篇:数据查询全攻略|Join/子查询/窗口函数,从基础到高级实战
适合人群:大数据开发、Doris查询调优工程师、数仓分析师、BI工程师核心价值:吃透Doris 2.x数据查询核心能力,掌握Join算法选型、子查询优化、多维聚合、窗口函数实战,解决查询慢、资源浪费、语法报错等问题系列说明:本…...

告别写死地址!CH32V IAP升级实战:用函数传参实现APP跳转地址的动态配置
CH32V IAP升级进阶:动态跳转地址的工程实践与安全设计 在嵌入式开发中,IAP(In-Application Programming)技术是实现固件远程更新的重要手段。对于CH32V系列RISC-V MCU而言,官方示例中"写死"跳转地址的做法虽…...

Windows DLL注入工具Xenos全攻略:从原理到实践的系统指南
Windows DLL注入工具Xenos全攻略:从原理到实践的系统指南 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos 一、技术原理:Xenos注入引擎的底层架构 1.1 三级注入引擎的工作机制 Xenos作为专业的…...
)
Windows 10/11下Frida逆向分析环境搭建避坑指南(含ADB驱动安装)
Windows 10/11逆向工程实战:Frida环境搭建全流程与疑难解析 逆向工程的世界就像一场数字考古,而Frida无疑是当前最趁手的工具之一。但很多新手在Windows平台搭建Frida环境时,往往会陷入Python版本地狱、ADB驱动失效、设备连接失败等连环陷阱。…...
 | 往届两年已完成 EI 、 IEEE Xplore检索 | 大咖组委】第三届人工智能与电力系统国际学术会议(AIPS 2026))
【衢州学院主办,上海交通大学协办 | IET出版(有ISSN号) | 往届两年已完成 EI 、 IEEE Xplore检索 | 大咖组委】第三届人工智能与电力系统国际学术会议(AIPS 2026)
第三届人工智能与电力系统国际学术会议(AIPS 2026) 2026 3rd International Conference on Artificial Intelligence and Power System 大会官网:www.icaips.org【参会投稿】 大会时间:2026年5月22-24日 大会地点:中国-浙江-衢…...

利用快马平台快速构建鸿蒙pc镜像下载验证工具原型
最近在研究鸿蒙系统的PC版本适配工作,发现获取官方镜像是个不小的门槛。官方渠道的下载链接分散在不同页面,版本信息也不够直观,每次下载完还得手动校验文件完整性,整个过程相当繁琐。于是想做个工具来简化这个流程,正…...

告别公式迁移难题:3步实现LaTeX到Word的无缝转换体验
告别公式迁移难题:3步实现LaTeX到Word的无缝转换体验 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 问题溯源:学术公式迁…...

Windows DLL注入工具Xenos深度技术解析与实践指南
Windows DLL注入工具Xenos深度技术解析与实践指南 【免费下载链接】Xenos Windows dll injector 项目地址: https://gitcode.com/gh_mirrors/xe/Xenos 一、技术内核:Xenos注入引擎的架构解析 1.1 注入技术的三级引擎架构 Xenos作为一款专业的Windows DLL注…...

多功能 PEG 衍生物 Ergosterol-PEG-MAL,Ergosterol-PEG-Maleimide详解
试剂基本信息中文名称:麦角固醇-聚乙二醇-马来酰亚胺英文名称:Ergosterol-PEG-MAL,Ergosterol-PEG-Maleimide分子量:0.4k,0.6k,1k,2k,3.4k,5k,10k,…...