清华大学提出IFT对齐算法,打破SFT与RLHF局限性
监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是预训练后提升语言模型能力的两大基础流程,其目标是使模型更贴近人类的偏好和需求。
考虑到监督微调的有效性有限,以及RLHF构建数据和计算成本高昂,这两种方法常常被结合使用。但由于损失函数、数据格式的差异以及对辅助模型的需求,两个方法之间存在范式鸿沟,仅能通过串联的方法实现模型的训练。
清华大学最近提出将SFT与RLHF合二为一,引入了一种统一的对齐算法,称为直观微调(Intuitive Fine-Tuning,IFT),它以类似人类的方式直观地建立策略偏好估计,让模型在看到问题后,能够对完整答案有一个模糊的感知。相较于SFT,IFT更接近真实的策略偏好,因此在性能上达到了与SFT和RLHF结合使用相当甚至更好的对齐效果。
并且相比SFT+RLHF,RLHF仅依赖于正样本和单个策略,从预训练的基础模型开始进行对齐,大大提高了计算效率,降低了训练成本。
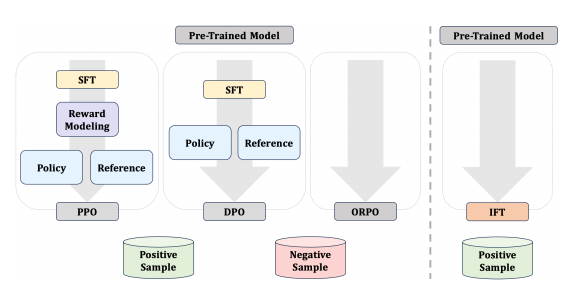
IFT无需额外的数据收集或处理,其效率仅次于SFT,且表现出与其它对齐算法相当甚至更优的性能,这使得IFT在偏好数据难以获取或成本高昂的领域中也具有极高的实用价值。
论文标题:
Intuitive Fine-Tuning:Towards Unifying SFT and RLHF into a Single Process
论文链接:
https://arxiv.org/pdf/2405.11870
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
预备知识
为了对SFT和RLHF有更深入和统一的理解,作者试图通过在马尔可 夫决策过程 (MDP) 框架下定义偏好估计和状态-动作对优化,来解释SFT和RLHF之间的相似性和差异。
马尔科夫决策过程
马尔可夫决策过程(MDP)在语言模型中的应用可以被简洁地描述为一个五元组 。这里, 是由词汇表的有序排列形成的状态空间, 是基于分词器定义的词汇动作空间。 是转移矩阵,它描述了从一个状态转移到另一个状态时生成特定词汇的概率。 代表在特定状态执行动作后获得的奖励,而 是基于给定指令的初始状态分布。
语言建模的核心目标是训练一个策略 ,其对应的转移矩阵为 ,以模仿人类策略的转移矩阵 ,使两者变得完全一致:
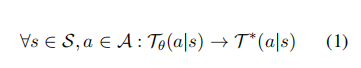
这个过程也可以用状态-状态转移矩阵来表示,其中等同于,但表示从一个状态到另一个状态的转移概率:
![]()
偏好估计
当给定初始指令 ρ 时,可以定义策略 的偏好 为一个映射:
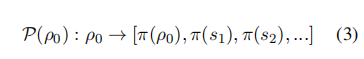
在对齐阶段,模型偏好逐渐接近人类偏好:
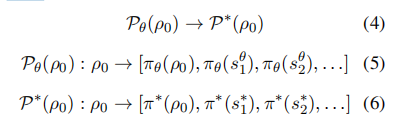
由于真正的偏好难以获取,通常通过模型和人类的偏好估计来进行对齐。为了让偏好变得可优化,每个策略的偏好也可以表示为:
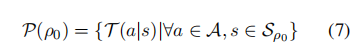
在这里, 表示由初始状态 ρ限定的条件状态空间,因此可以通过转移矩阵来优化模型偏好。本文将这种方法叫做Transition Optimization。接下来将详细描述这个过程。
Transition Optimization
理想情况下,希望在受到ρ约束的状态空间中,使模型和人类的状态动作转移矩阵保持一致:
![]()
这相当于以下由状态-状态转移矩阵表示的格式:
![]()
然而,考虑到有限的数据,只有表示数据集中包含的状态-动作/状态-状态对的矩阵元素才会对齐。给定指令为ρ、答案长度为N的目标样本,目标为:
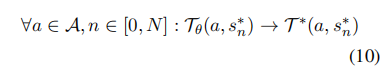
同样等价于:
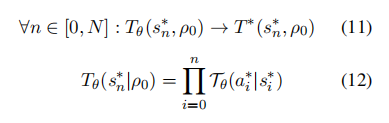
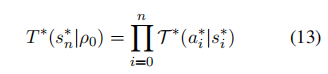
其中,初始状态对应于ρ,并且最优的转换矩阵ρρ与模型θρρ在初始状态下的值均为1。因此,损失函数可以通过比较模型和人类的转换矩阵差异来推导得出。
从SFT 到RLHF
按照上述框架,本文重新表述了SFT、PPO和DPO,具体形式见下表:
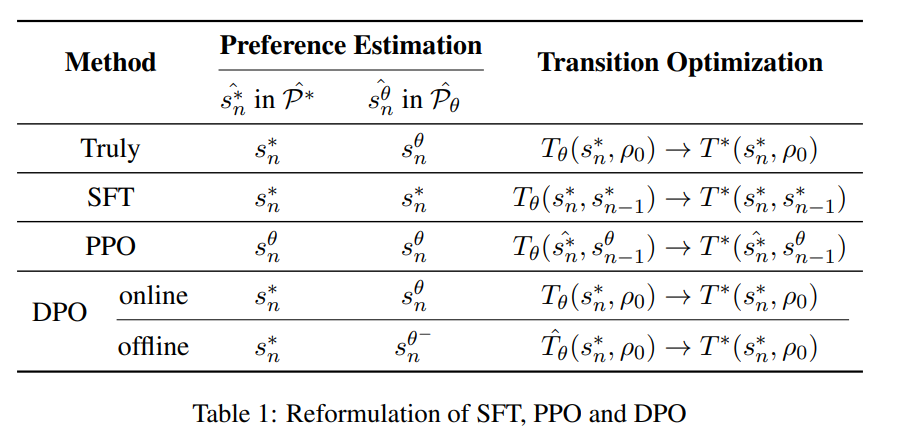
更易理解的版本如下图所示:
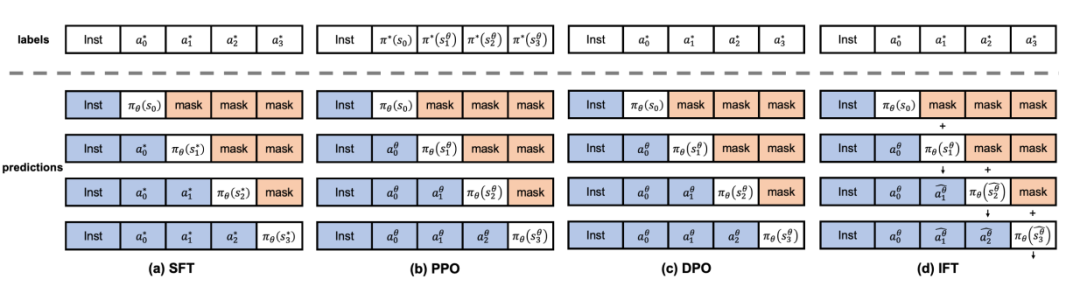
图中的符号*和θ分别表示人类和模型。其中π(),。与PPO和DPO相比,SFT使用偏离模型分布的先验,导致对模型偏好的估计更有偏差。IFT利用临时剩余连接实现了比SFT更接近的估计,同时保持了SFT的数据和计算效率。
为了比较它们的差异,首先引入一个基本定理和推论:
定理: 对于一组事件 Z,任何事件 z ∈ Z的概率在0到1之间,如果所有事件相互独立,它们的概率之和等于1,最有可能的事件的概率大于或等于其他任何事件的概率:
语言模型作为一个概率估计模型,可以推论:语言模型倾向于给自己的一致性预测分配更高的概率,而非人类偏好。也就是说在给定相同初始指令的情况下,语言模型倾向于给自己生成的内容分配更高的概率,而不是目标答案。
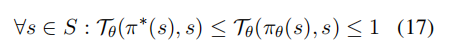
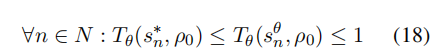
SFT虽然提供了人类偏好的无偏估计,但对模型来说是带有偏见的估计。这是由于在预测每个后续token时使用了错误的先验状态所导致的。SFT 的状态转换优化目标为:
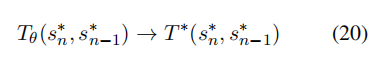
但是在对齐与时,这导致了模型的过渡概率和偏好估计过高,从而影响了SFT的优化进程。因此,需要RLHF进行进一步的偏好校准。
PPO提供了模型偏好的无偏估计,同时采用逐步无偏的人类偏好估计:
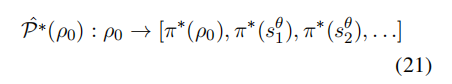
初始时,这种估计存在偏差,但随着模型随着时间逐渐与人类偏好一致,它变得越来越无偏。因此, 相对于SFT, PPO在模型优化中的过渡阶段提供了更接近实际情形:
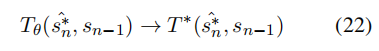
DPO理论上在所有情况下都能提供最佳估计,即使不进行奖励建模。然而,获取在线的成对偏好数据代价高昂,因为需要实时从模型中获取负样本并由人类进行偏好标注。因此,主流实现往往依赖优化模型外的非同分布的 off-policy 负样本,这可能导致偏好估计偏差和过渡优化不足,从而产生不稳定和次优的结果。
提出新方法
虽然SFT在数据和计算方面都很高效,但它在偏好估计和转移优化方面的近似效果较差。另一方面,以PPO和DPO为代表的RLHF在近似效果上做得更好,但这需要付出构建偏好数据的代价。因此,本文将结合两者的优点,提出了——Intuitive Preference Estimation直觉偏好估计。
直觉偏好估计
SFT和RLHF之间的关键区别在于是否对每个初始指令的模型偏好分布进行了采样。与RLHF不同,SFT中用于先验的目标答案的中间状态可能远离模型偏好,从而导致较差的结果。
为了获得更接近模型偏好的状态估计,作者引入了一个基于模型的分布扰动函数δθ,用于纠正偏差状态:
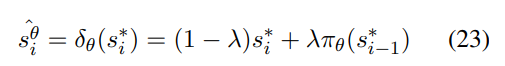
这也可以解释为一个时间上的残差连接。通过这种方法,模型不仅能根据目标答案的中间状态预测下一个 token,还能仅凭初始指令发展出对整个答案生成的直观理解,从而得出更精确的偏好估计:
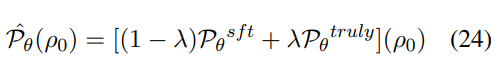
动态关系传播
随着改进的偏好估计,可以实现了更接近原始目标的过渡优化过程:
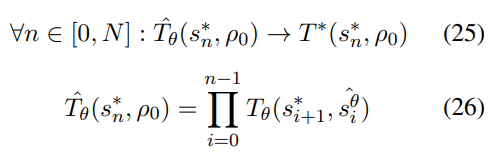
这可以通过量化模型与人类之间过渡差异的损失函数进行优化:
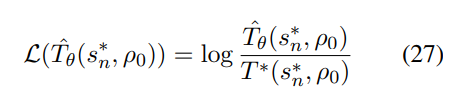
与SFT相同,每个目标中间状态的优化目标的概率为1。因此损失函数可以重写为:
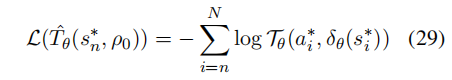
这使得并行实现变得更加容易。并且通过这个损失函数优化的目标在对策略进行在线学习的情况下,隐含地满足贝尔曼方程。这确保了优化过程更接近RLHF。它还保证了优化目标不仅反映了当前 token 的预测准确性,而且考虑了当前选择对后续生成的影响,帮助模型获得对生成的直观理解,以及更好的因果性和事实遵循性。
实验
实验设置
本文选择UltraChat-200k 作为单目标数据集,UltraFeedback-60k 作为配对数据集。在Mistral-7B-v0.1 基础模型和已在UltraChat-200k上经过微调的版本Mistral-7B-sft-beta上进行实验。
考虑两种训练场景:一、单独使用RLHF训练;二、先用SFT再用RLHF顺序训练。在第一种场景中,直接使用基础模型Mistral-7B-v0.1与UltraFeedback进行对齐,并从UltraChat中随机抽取60k数据用于补充SFT和IFT,这两种方法仅使用目标数据。第二种场景则更为常见:首先使用SFT对Mistral-7B-sft-beta进行微调,随后再利用UltraFeedback通过RLHF进行进一步微调,该模型已先用SFT在UltraChat上微调过。
评估基准选用广泛使用的Open-LLM LeaderBoard和基于语言模型的评估,包括Alpaca-Eval和Alpaca-Eval-2。
实验结果与分析
实验结果如下所示:
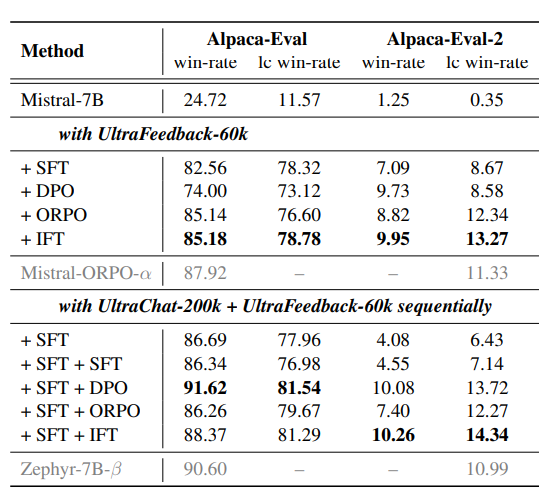
在基于LLMs的基准测试上。在顺序训练场景中,SFT+DPO仍然取得最高分,IFT的表现略逊一筹。但是,当直接从基础模型进行调整时,IFT不仅表现出色,而且与序列方法相当。这表明,IFT使用最少的数据和计算资源就达到了不错的效果。
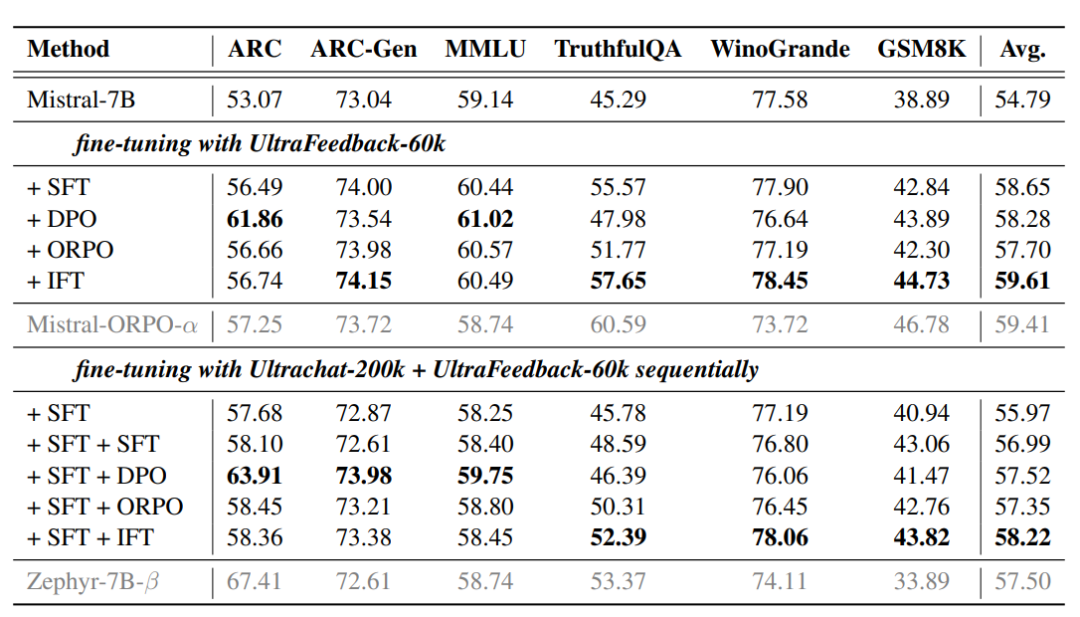
在开放LLM排行榜的聊天模板评估中,当使用相同的调参方法时,IFT在所有方法中实现了最高的平均分数。直接使用IFT使用最少的数据和计算资源进行对齐,但在所有方法中显示出最好的性能。
IFT更擅长生成任务
从以上的实验结果,作者还发现在Open-LLM基准测试中,IFT更擅长生成任务,但在多选任务上则相对较弱;相反,DPO在多选任务上表现更佳。
这种差异可能源于两种任务不同的评估指标以及IFT和DPO的训练目标差异。多选任务通过评估模型对每个完整正确答案的似然度来度量性能,而生成任务要求模型根据Token构建最终答案,更能体现因果关系和推理能力。
DPO侧重于指令与完整答案的映射,而IFT则更强调Token间的因果关系,因此在需要模型逐Token探索的生成任务中表现更佳,而在多选这样的分布映射任务上,DPO则表现更优。
考虑到这一点,作者在ARC-Challenge中将其转换为生成任务,问题和候选答案会提前显示,答案将从模型生成中提取。在不改变基准测试分布的情况下,IFT在该设置中显示出优势。总的来说,IFT在不同任务上保持了最佳平衡,实现了最高的平均得分。
SFT+RLHF甚至不如单独使用SFT
传统的RLHF方法在指令跟随能力的增强方面表现出色,但使用SFT+RLHF的顺序训练方法需要更多的超参数的权衡,因此这种方法表现明显较差,甚至不如单独使用SFT。ORPO和IFT通过直接在基础模型上进行对齐,避免了超参数的权衡,从而实现更好的性能。
IFT的效率和扩展潜力
IFT不仅在性能上出众,甚至超越其他方法,更在多个方面展现了其高效性。与SFT和ORPO相似,IFT无需依赖参考模型,从而显著节省了GPU内存和计算资源。
更值得一提的是,IFT和SFT是仅有的两种无需偏好数据进行对齐的方法,这一特性带来了诸多优势:减少了GPU上同步存储和计算对偶数据的压力,降低了内存消耗和训练时间;同时,省去了生成负样本和标注偏好标签的繁琐过程,大大降低了对齐成本。此外,IFT仅依赖目标答案进行对齐,为流程扩展提供了可能性,进一步彰显了预训练技术的核心优势。
冰湖环境测试
Frozen-Lake Environment(冰湖环境)是一个经典的强化学习环境,常用于演示和测试强化学习算法。在这个环境中,一个agent试图在一个几乎结冰的湖面上找到一个礼物,游戏在找到礼物 或掉入洞中时结束。有限的状态和动作数量使得使用经典强化学习方法可以容易地得出最优策略。
为了模拟参数化策略的对齐,作者使用一个两层全连接神经网络,并设计了一个包含一个最优和一个次优轨迹的环境。最优的参数 化策略使用先前获得的最优状态-动作概率进行训练,然后比较各种来自语言模型的微调方法。通过计算最优和训练策略参数之间的 均方误差(MSE)距离来评估性能。
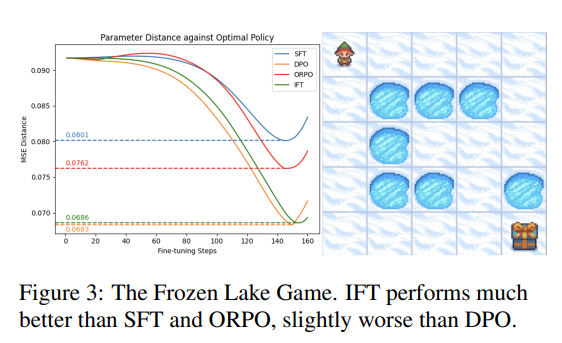
实验结果显示,IFT在优化方面显著优于SFT和ORPO,但略逊于DPO。这主要归因于在探索网格与agent偏好对齐方面,DPO > IFT> ORPO > SFT。尽管ORPO考虑了从策略中采样的负轨迹,但其直接融入SFT损失并使用融合系数,一定程度上削弱了其效果。相比之下,DPO、ORPO和IFT探索的网格更为广泛,有助于agent更深入地理解环境。
结语
本文首先将SFT和一些典型的RLHF方法解释为一个统一的框架,即偏好估计和过渡优化。接着,提出了一种高效且有效的方法 IFT, 它直接从基础模型开始,使用无偏好标签的数据实现对齐。
通过实验来看,IFT可以使用更少的资源与成本实现与其他方法相当甚至更优的效果,为预训练技术的发展提供了一种新思路。

相关文章:
清华大学提出IFT对齐算法,打破SFT与RLHF局限性
监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是预训练后提升语言模型能力的两大基础流程,其目标是使模型更贴近人类的偏好和需求。 考虑到监督…...
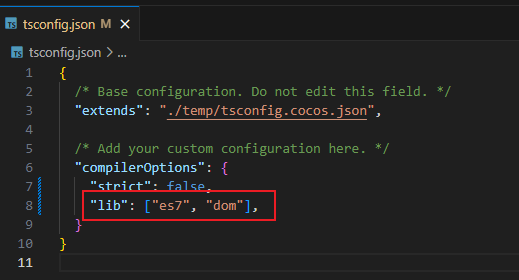
TS(TypeScript)中Array数组无法调出使用includes方法,显示红色警告
解决方法 打开tsconfig.json文件,添加"lib": ["es7", "dom"]即可。 如下图所示。...
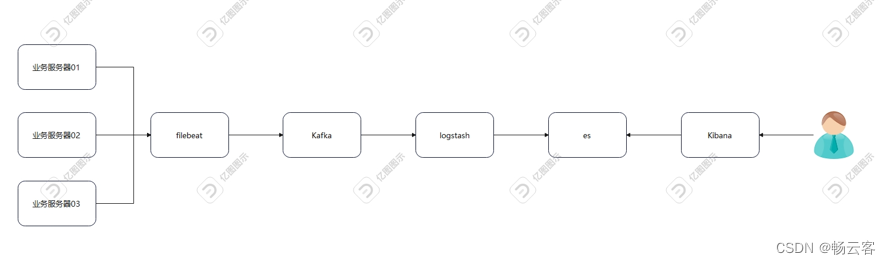
基于Kafka的日志采集
目录 前言 架构图 资源列表 基础环境 关闭防护墙 关闭内核安全机制 修改主机名 添加hosts映射 一、部署elasticsearch 修改limit限制 部署elasticsearch 修改配置文件 启动 二、部署filebeat 部署filebeat 添加配置文件 启动 三、部署kibana 部署kibana 修…...
某烟草企业数字化转型物流信息化咨询项目规划方案(117页PPT)
方案介绍: 烟草企业数字化转型物流信息化咨询项目规划方案将为企业带来多方面的价值,包括提升物流运营效率、降低物流成本、优化供应链管理、增强企业竞争力和促进可持续发展等。这些价值的实现将有助于企业在激烈的市场竞争中保持领先地位并实现可持续…...
失落的方舟 命运方舟台服封号严重 游戏封IP怎么办
步入《失落的方舟》(Lost Ark),这款由Smilegate精心打造的宏大规模在线角色扮演游戏(MMORPG),您将启程前往阿克拉西亚这片饱经沧桑的奇幻大陆,展开一场穿越时空的壮阔探索。在这里,一…...
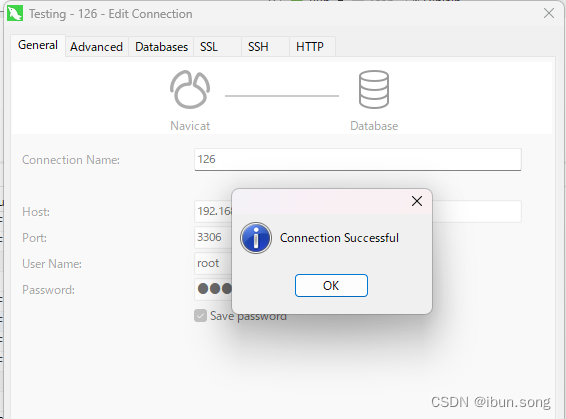
2.10 mysql设置远程访问权限
2.10 mysql设置远程访问权限 目录1. 管理员运行mysql命令窗口2. 使用 root 用户重新登录 MySQL3. 修改用户权限4. 修改mysql安装目录下的my.ini 目录 说明: Mysql8.0 设置远程访问权限 一、Mysql8.0 设置远程访问权限 1. 管理员运行mysql命令窗口 2. 使用 root 用…...

C# 证件照替换底色与设置背景图---PaddleSegSharp
PaddleSegSharp 是一个基于百度飞桨PaddleSeg项目的人像分割模块而开发的.NET的工具类库。 PaddleSegSharp 中PaddleSeg.dll文件是基于开源项目最新发布版本PaddleSeg PaddleSeg的版本修改而成的C动态库,基于opencv的x64编译而成的。 PaddleSeg是基于飞桨PaddlePa…...

HCIA-HarmonyOS Device Developer 课程大纲
一:OpenHarmony 介绍 - ( 3 课时) - OpenHarmony 简介;OpenHarmony 设计理念;OpenHarmony 设计理念概述; - OpenHarmony 试图解决的问题;应用生态割裂问题;用户数据割裂问题&#…...

洗地机哪个牌子最好用?十大名牌洗地机排行榜
作为一种新兴的智能家居产品,洗地机的市场规模已经突破了百亿大关。如此庞大的市场自然吸引了大量资本的涌入,许多品牌纷纷推出自己的洗地机产品,试图在这个竞争激烈的市场中占据一席之地。然而,面对如此多的品牌和型号࿰…...
Unity开发——XLua热更新之Hotfix配置(包含xlua获取与导入)
一、Git上获取xlua 最新的xlua包,下载地址链接:https://github.com/Tencent/xLua 二、Unity添加xlua 解压xlua压缩包后,将xlua里的Assets里的文件直接复制进Unity的Assets文件夹下。 成功导入后,unity工具栏会出现xlua选项。 …...

Qt 基于FFmpeg的视频转换器 - 转GIF动图
Qt 基于FFmpeg的视频转换器 - 转GIF动图 引言一、设计思路二、核心源码三、参考链接 引言 gif格式的动图可以通过连续播放一系列图像或视频片段来展示动态效果,使信息更加生动形象,可以很方便的嵌入到网页或者ppt中。上图展示了视频的前几帧转为gif动图的…...
HTML新春烟花盛宴
目录 写在前面 烟花盛宴 完整代码 修改文字...

第十四届蓝桥杯c++研究生组
A 混乘数字 关键思路是求每个十进制数的数字以及怎么在一个数组中让判断所有的数字次数相等。 求每个十进制的数字 while(n!0){int x n%10;//x获取了n的每一个位数字n/10;}扩展:求二进制的每位数字 (注意:进制转换、1的个数、位运算&#…...

KDD 2024|基于隐空间因果推断的微服务系统根因定位
简介:本文介绍了由清华大学、南开大学、eBay、微软、中国科学院计算机网络信息中心等单位共同合作的论文《基于隐空间因果推断的受限可观测性场景的微服务系统根因定位》。该论文已被KDD 2024会议录用。 论文标题:Microservice Root Cause Analysis Wit…...
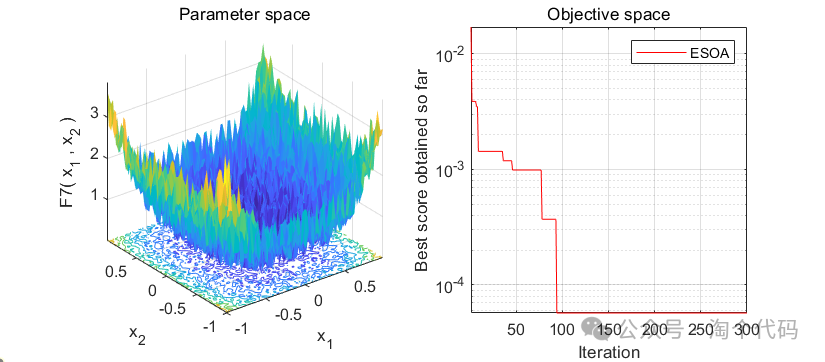
白鹭群优化算法,原理详解,MATLAB代码免费获取
白鹭群优化算法(Egret Swarm Optimization Algorithm,ESOA)是一种受自然启发的群智能优化算法。该算法从白鹭和白鹭的捕食行为出发,由三个主要部分组成:坐等策略、主动策略和判别条件。将ESOA算法与粒子群算法(PSO)、遗传算法(GA)…...
【源码】2024完美运营版商城/拼团/团购/秒杀/积分/砍价/实物商品/虚拟商品等全功能商城
后台可以自由拖曳修改前端UI页面 还支持虚拟商品自动发货等功能 前端UNIAPP 后端PHP 一键部署版本 获取方式: 微:uucodes...
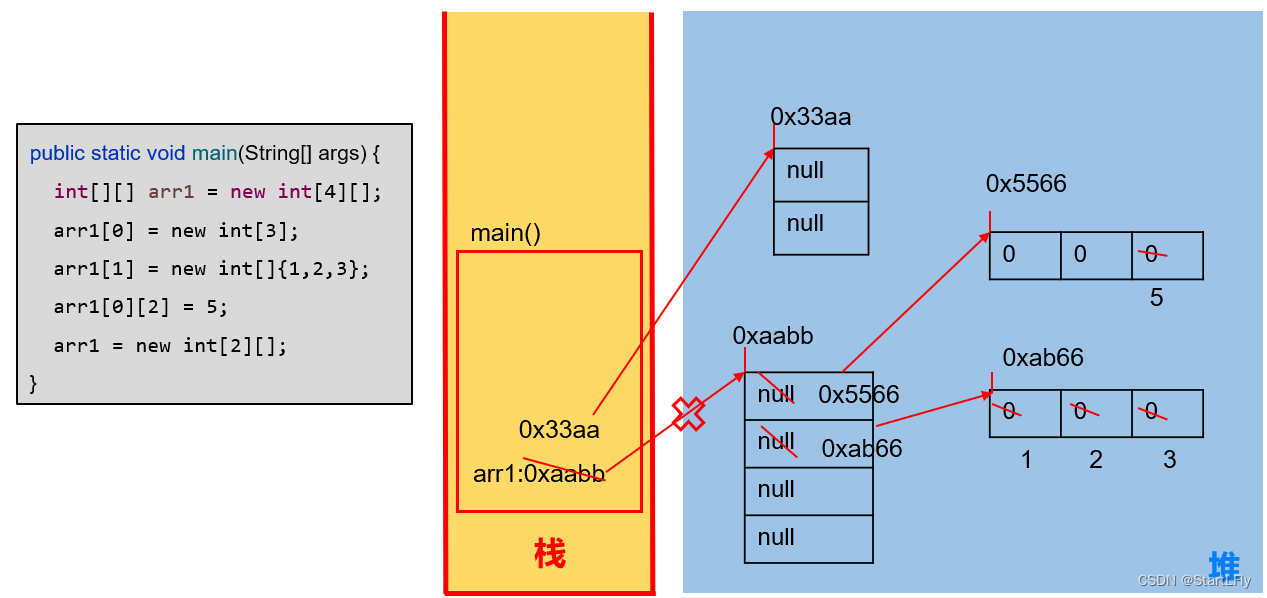
Java-数组内存解析
文章目录 1.内存的主要结构:栈、堆2.一维数组的内存解析3.二维数组的内存解析 1.内存的主要结构:栈、堆 2.一维数组的内存解析 举例1:基本使用 举例2:两个变量指向一个数组 3.二维数组的内存解析 举例1: 举例2&am…...

Spring Cache --学习笔记
一、概述 Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。 Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,例如: EHCache Caffeine Redis(常…...

NTP服务的DDoS攻击:原理和防御
NTP协议作为一种关键的互联网基础设施组件,旨在确保全球网络设备间的时钟同步,对于维护数据一致性和安全性至关重要。然而,其设计上的某些特性也为恶意行为者提供了发动大规模分布式拒绝服务(DDoS)攻击的机会。以下是NTP服务DDoS攻击及其防御…...

【面试干货】事务的并发问题(脏读、不可重复读、幻读)与解决策略
【面试干货】事务的并发问题(脏读、不可重复读、幻读)与解决策略 一、脏读(Dirty Read)二、不可重复读(Non-repeatable Read)三、幻读(Phantom Read)四、总结 💖The Begi…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...
)
C++课设:简易日历程序(支持传统节假日 + 二十四节气 + 个人纪念日管理)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、为什么要开发一个日历程序?1. 深入理解时间算法2. 练习面向对象设计3. 学习数据结构应用二、核心算法深度解析…...