第十三章 进程与线程
第十三章 进程与线程
程序与进程的概念
程序:
英文单词为Program,是指一系列有序指令的集合,使用编程语言所编写,用于实现一定的功能。
进程:
进程则是指启动后的程序,系统会为进程分配内存空间。

函数式创建子进程
在Python中创建进程有两种方式:
第一种使用os模块中的fork函数,但该函数只适用于Unix、Linux和MacOS。
Windows只能使用第二种方式:使用 multiprocessing模块 中的 Process类 创建进程。
第二种方式创建进程的语法结构:
Process(group = None,target,name,args,kwargs)
参数说明:
- group:表示分组,实际上不使用,值默认为None即可
- target:表示子进程要执行的任务,支持函数名
- name:表示子进程的名称
- args:表示调用函数的位置参数,以元组的形式进行传递
- kwargs:表示调用函数的关键字参数,以字典的形式进行传递
【注】:
target支持函数名,即函数可以作为这个参数传入(函数作为参数时不带小括号,函数调用时才带小括号)。如果target传入的函数有位置参数,就需要用args进行传入;如果target传入的函数有关键字参数,就需要用kwargs进行传入。
因此group,name可以不写;target必须写;args、kwargs有就写,没有就不写。
# 使用内置模块multiprocessing中的Process类创建进程
from multiprocessing import Process
import os, time# 函数中的代码是子进程要执行的代码
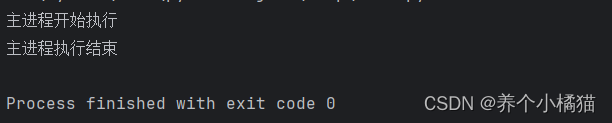
def test():print(f'我是子进程,我的PID是:{os.getpid()},我的父进程是:{os.getppid()}')time.sleep(1)if __name__ == '__main__':# main是主进程print('主进程开始执行')lst = []# 创建五个子进程for i in range(5):# 创建子进程p = Process(target=test) # 函数作为参数时不加小括号,函数调用时才加小括号# 启动子进程p.start()# 启动中的进程添加到列表中lst.append(p)print('主进程执行结束')
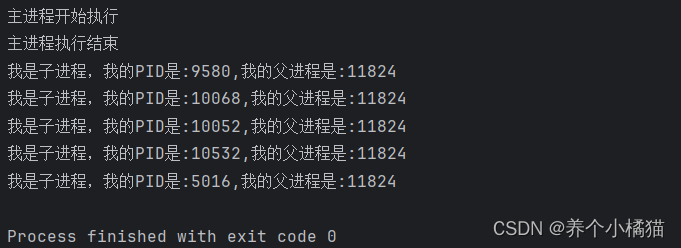
这里会发现子进程还没执行结束时,主进程就已经执行结束了。
原因见下方图示:
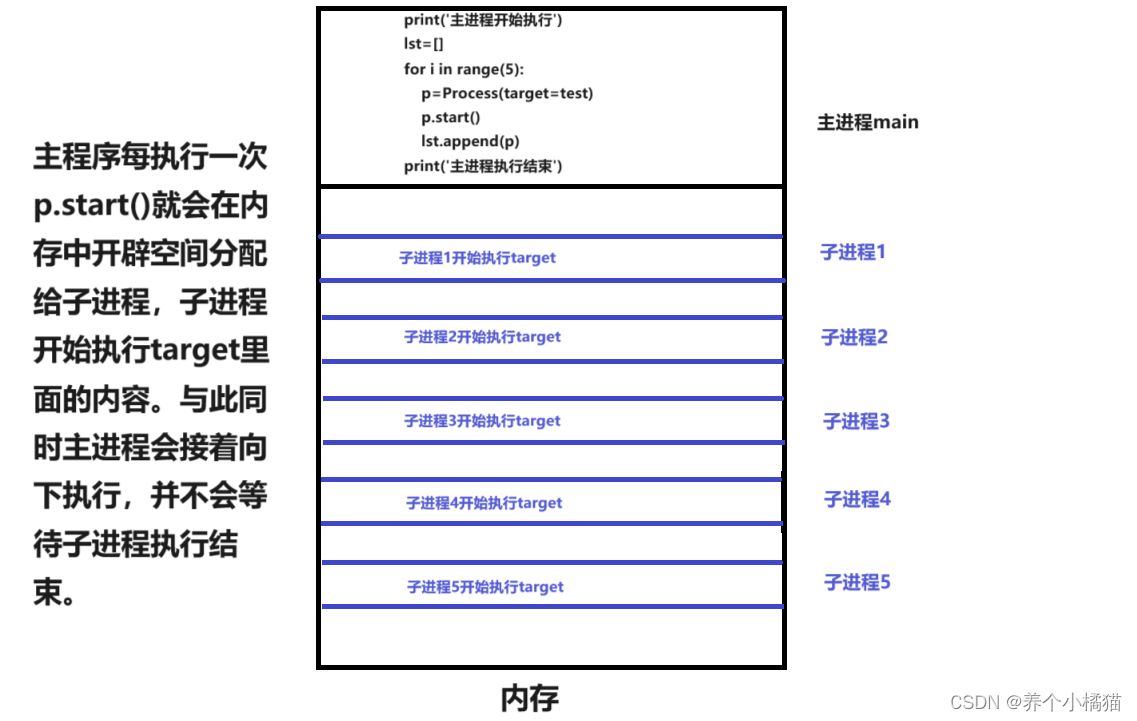
那么怎么让所有子进程执行结束之后主进程再执行结束呢?——需要用到 join() 进行阻塞。
# 使用内置模块multiprocessing中的Process类创建进程
from multiprocessing import Process
import os, time# 函数中的代码是子进程要执行的代码
def test():print(f'我是子进程,我的PID是:{os.getpid()},我的父进程是:{os.getppid()}')time.sleep(1)if __name__ == '__main__':# main是主进程print('主进程开始执行')lst = []# 创建五个子进程for i in range(5):# 创建子进程p = Process(target=test) # 函数作为参数时不加小括号,函数调用时才加小括号# 启动子进程p.start()# 启动中的进程添加到列表中lst.append(p)# 当所有子进程执行结束后主进程再执行结束--->使用join()阻塞主进程# 遍历lst,列表中五个子进程for item in lst: # item的数据类型是Process类型# join()-->主进程和子进程在一起执行时,看到join()后主进程便不再执行了,先让子进程执行,子进程执行结束之后再去执行主进程item.join() # join()是Process对象的方法,作用是阻塞主进程# 有了join()后主进程要等到所有子进程执行完毕之后,主进程才会执行结束print('主进程执行结束')
Process类常用的属性和方法
Process类中常用的属性和方法:
| 方法/属性名称 | 功能描述 |
|---|---|
| name | 当前进程实例别名,默认为Process-N |
| pid | 当前进程对象的PID值 |
| is_alive() | 进程是否执行完,没执行完结果为True,否则为False |
| join(timeout) | 等待结束或等待timeout秒 |
| start() | 启动进程 |
| run() | 如果没有指定target参数,则启动进程后,会调用父类(Process)中的run()方法 |
| terminate() | 强制终止进程 |
from multiprocessing import Process
import os, time# 函数中的代码是子进程要执行的代码
# 函数式方式创建子进程
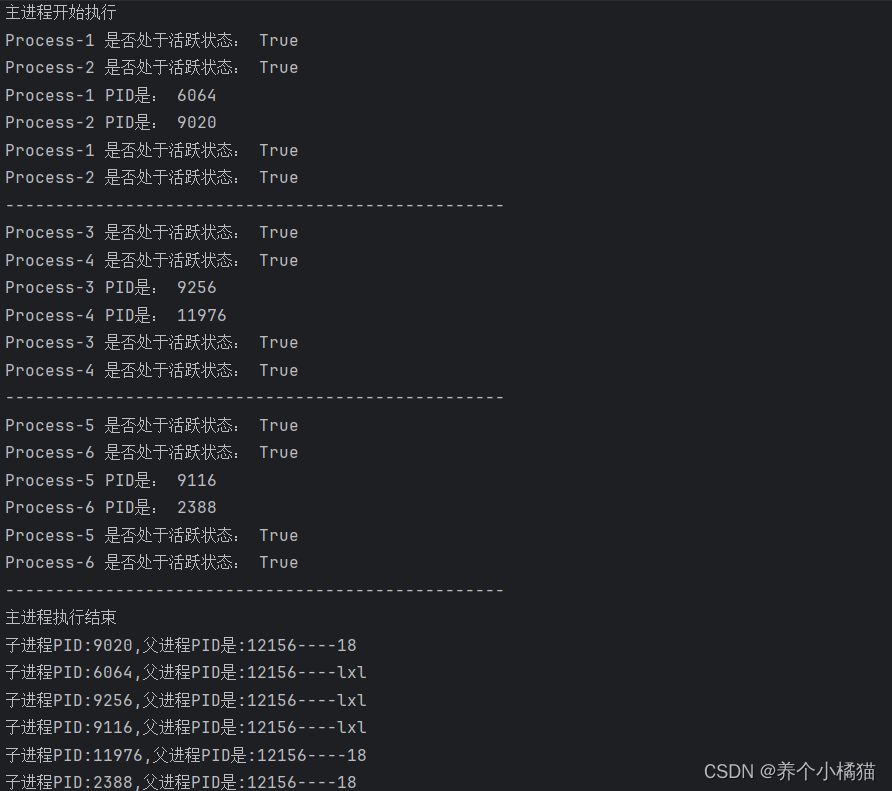
def sub_process(name):print(f'子进程PID:{os.getpid()},父进程PID是:{os.getppid()}----{name}')time.sleep(1)def sub_process2(name):print(f'子进程PID:{os.getpid()},父进程PID是:{os.getppid()}----{name}')time.sleep(1)if __name__ == '__main__':# main是主进程print('主进程开始执行')for i in range(3):# 创建第一种子进程# sub_process()有一个位置参数,因此需要用args传入该函数的位置参数,以元组方式p1 = Process(target=sub_process, args=('lxl',))# 创建第二种子进程# sub_process2()有一个位置参数,因此需要用args传入该函数的位置参数,以元组方式p2 = Process(target=sub_process2, args=(18,))# 调用start()启动子进程p1.start()p2.start()print(p1.name, '是否处于活跃状态:', p1.is_alive())print(p2.name, '是否处于活跃状态:', p2.is_alive())print(p1.name, 'PID是:', p1.pid)print(p2.name, 'PID是:', p2.pid)# 阻塞主进程p1.join() # 主进程要等待p1执行结束p2.join() # 主进程要等待p2执行结束print(p1.name, '是否处于活跃状态:', p1.is_alive())print(p2.name, '是否处于活跃状态:', p2.is_alive())print('-' * 50)print('主进程执行结束')

如果将以下两句注释掉:
# p1.join() # 主进程要等待p1执行结束# p2.join() # 主进程要等待p2执行结束
则会出现:
具体原因同上面一样。
from multiprocessing import Process
import os, time# 函数中的代码是子进程要执行的代码
# 函数式方式创建子进程
def sub_process(name):print(f'子进程PID:{os.getpid()},父进程PID是:{os.getppid()}----{name}')time.sleep(1)def sub_process2(name):print(f'子进程PID:{os.getpid()},父进程PID是:{os.getppid()}----{name}')time.sleep(1)if __name__ == '__main__':# main是主进程print('主进程开始执行')for i in range(3):# 创建第一种子进程# 若没有给定target参数,则不会执行自己编写的函数中的代码,会调用执行Process类中run方法p1 = Process(target=sub_process, args=('lxl',))# 创建第二种子进程p2 = Process(target=sub_process2, args=(18,))# 调用start()启动子进程p1.start() # 如果Process类创建对象时没有指定target参数,则会调用Process类中的run方法去执行p2.start() # 如果Process类创建对象时指定了target参数,start()调用target指定的函数去执行# 强制终止进程p1.terminate() # target指定的函数还没有执行,进程就会被终止p2.terminate()print('主进程执行结束')
继承式创建子进程
除了使用函数式创建子进程,亦可以使用Python面向对象中的继承创建子进程。
使用继承创建进程的语法结构:
class 子进程(Process):
pass
即编写一个类,这个类继承Process类,然后重写Process类中的run()方法。
from multiprocessing import Process
import os, time# 自定义一个类
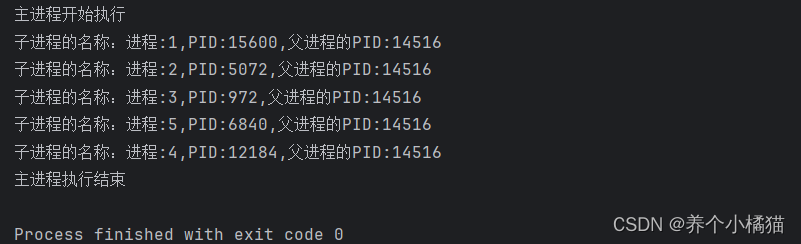
class SubProcess(Process):# 编写初始化方法def __init__(self, name):# 调用父类中的初始化方法super().__init__()self.name = name# 重写父类中的run()方法def run(self):print(f'子进程的名称:{self.name},PID:{os.getpid()},父进程的PID:{os.getppid()}')if __name__ == '__main__':print('主进程开始执行')lst = []for i in range(1, 6):p1 = SubProcess(f'进程:{i}')# 启动进程p1.start() # SubProcess类中没有start()方法,实际上会去调用父类中的start()方法lst.append(p1)# 阻塞主进程for item in lst:item.join()print('主进程执行结束')
进程池的使用
当进程数量比较少时,可以使用上面的两种方法Process类或Process的子类创建进程。但如果要创建的进程数量很多,再使用上述的方法创建进程和销毁进程就会耗费大量时间,这时可以使用multiprocessing模块中的 Pool类 创建进程池。
进程池的原理:
创建一个进程池,并设置进程池中最大的进程数量。假设进程池中最大的进程数为3,现在有10个任务需要执行,那么进程池一次可以执行3个任务,4次即可完成全部任务的执行。
创建进程池的语法结构:
进程池对象 = Pool(N)
进程池对象的方法:
| 方法名 | 功能描述 |
|---|---|
| apply_async(func,args,kwargs) | 使用非阻塞方式调用函数func |
| apply(func,args,kwargs) | 使用阻塞方式调用函数func |
| close() | 关闭进程池,不再接收新任务 |
| terminate() | 不管任务是否完成,立即终止 |
| join() | 阻塞主进程,必须在terminate()或close()之后使用 |
使用进程池:非阻塞和阻塞方式调用函数func有什么区别:
先来看非阻塞方式:
from multiprocessing import Pool
import os, time# 编写函数(即要执行的任务)
def task(name):print(f'子进程的PID:{os.getppid()},执行的任务:{name}')time.sleep(1)# 使用进程池:非阻塞和阻塞方式调用函数func有什么区别
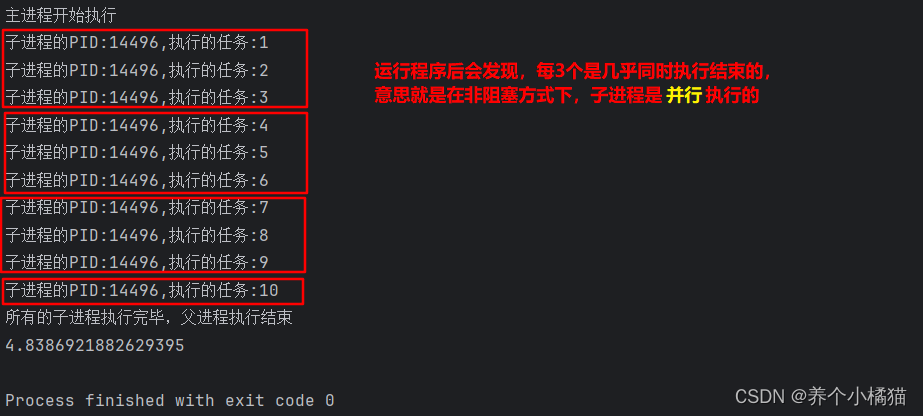
if __name__ == '__main__':# 主进程start = time.time()print('主进程开始执行')# 创建进程池p = Pool(3)# 创建任务for i in range(1, 11):# 以非阻塞方式# task()有一个位置参数,因此需要用args传入该函数的位置参数,以元组方式p.apply_async(func=task, args=(i,)) # 函数作为参数不带小括号,调用才带小括号p.close() # 关闭进程池,不再接收新任务p.join() # 阻塞父进程,等待所有的子进程执行完毕之后,才会执行父进程中的代码print('所有的子进程执行完毕,父进程执行结束')print(time.time() - start)
再来看阻塞方式(只需将 apply_async 方法改成 apply 方法即可):
from multiprocessing import Pool
import os, time# 编写函数(即要执行的任务)
def task(name):print(f'子进程的PID:{os.getppid()},执行的任务:{name}')time.sleep(1)# 使用进程池:非阻塞和阻塞方式调用函数func有什么区别
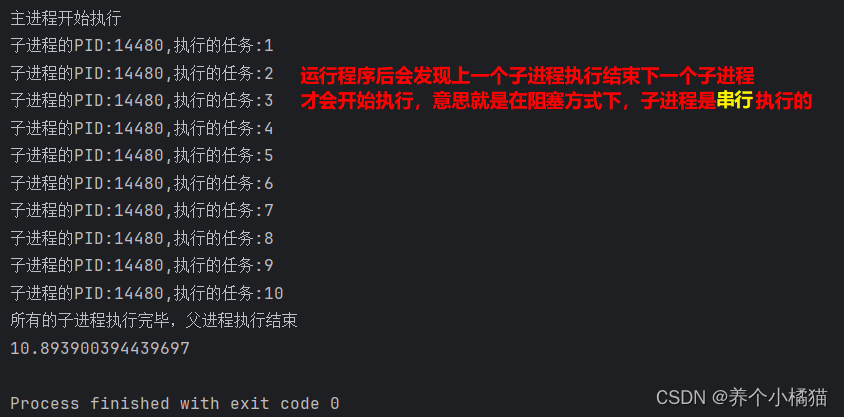
if __name__ == '__main__':# 主进程start = time.time()print('主进程开始执行')# 创建进程池p = Pool(3)# 创建任务for i in range(1, 11):# 以阻塞方式# task()有一个位置参数,因此需要用args传入该函数的位置参数,以元组方式p.apply(func=task, args=(i,)) # 函数作为参数不带小括号,调用才带小括号p.close() # 关闭进程池,不再接收新任务p.join() # 阻塞父进程,等待所有的子进程执行完毕之后,才会执行父进程中的代码print('所有的子进程执行完毕,父进程执行结束')print(time.time() - start)
并发和并行的概念
并发:
是指两个或多个事件同一时间间隔发生,多个任务被交替轮换着执行。比如A事件是吃苹果,在吃苹果的过程中有快递员敲门让你收下快递,收快递就是B事件,那么收完快递继续吃没吃完的苹果。这就是并发。

并行:
指两个或多个事件在同一时刻发生,多个任务在同一时刻在多个处理器上同时执行。比如A事件是泡脚,B事件是打电话,C事件是记录电话内容,这三件事则可以在同一时刻发生,这就是并行。

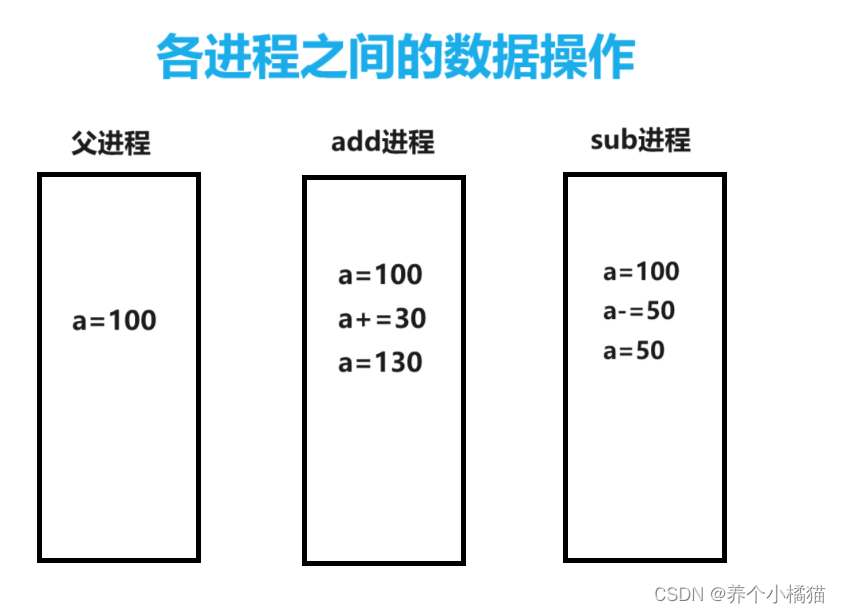
进程之间数据是否共享
结论:
进程之间数据是不共享的。
from multiprocessing import Processa = 100def add():print('子进程1开始执行')global aa += 30print('a=', a)print('子进程1执行完毕')def sub():print('子进程2开始执行')global aa -= 50print('a=', a)print('子进程2执行完毕')if __name__ == '__main__':# 主进程print('主进程开始执行')print('a=', a)# 创建 加法 的子进程p1 = Process(target=add)# 创建 减法 的子进程p2 = Process(target=sub)# 启动子进程p1.start()p2.start()# 阻塞主进程p1.join()p2.join()print('主进程执行结束')print('a=', a)

图示分析:
队列的基本使用
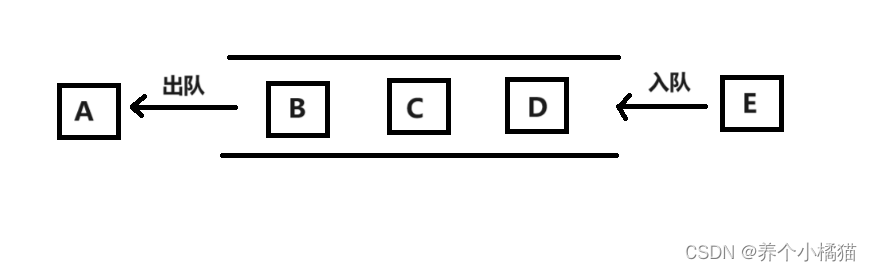
前面说到进程之间的数据是不共享的,但是可以通过队列来实现进程之间的数据共享。
进程之间可以通过队列(Queue)进程通信,队列是一种先进先出(First In First Out)的数据结构。
创建队列的语法结构:
队列对象 = Queue(N)
在multiprocessing模块中有一个Queue类。
Queue类中的常用方法:
| 方法名称 | 功能描述 |
|---|---|
| qsize() | 获取当前队列包含的消息数量 |
| empty() | 判断队列是否为空,为空结果为True,否则为False |
| full() | 判断队列是否满了,满结果为True,否则为False |
| get(block=True) | 获取队列中的一条消息,然后从队列中移除(出队),block默认值为True |
| get_nowait() | 相当于get(block=False),消息队列为空时,抛出异常 |
| put(item,block=True) | 将item消息放入队列,block默认为True |
| put_nowait(item) | 相当于put(item,block=False) |
注意:
在上面的方法中参数 block 表示 阻塞 的意思。使用get(block=True)【表示进行等待】,当队列为空并不会报错,而且会一直等待,等到队列中有消息时再取出一条消息。使用get_nowait()【相当于get(block=False)表示不进行等待】,当队列为空会报错。使用put(item,block=True)【表示进行等待】,当队列满时并不会报错,而且会一直等待,等到队列中有空位置时再入队。使用put_nowait(item)【put(item,block=False)表示不等待】,当队列满时会报错。

from multiprocessing import Queueif __name__ == '__main__':# 创建一个队列q = Queue(3) # 最多可以接收3条信息print('队列是否为空:', q.empty()) # Trueprint('队列是否为满:', q.full()) # False# 向队列中添加消息q.put('hello')q.put('world')print('队列是否为空:', q.empty()) # Falseprint('队列是否为满:', q.full()) # Falseq.put('Python')print('队列是否为空:', q.empty()) # Falseprint('队列是否为满:', q.full()) # Trueprint('队列当中信息的个数:', q.qsize())# 出队print(q.get())print('队列当中信息的个数:', q.qsize())# 入队q.put_nowait('html')# q.put_nowait('sql') # 报错,queue.Full# q.put('sql') # 不报错,会一直等待,等到队列中有空位置在入队# 遍历if not q.empty():for i in range(q.qsize()):print(q.get_nowait()) # nowait() 不等待print('队列是否为空:', q.empty()) # Trueprint('队列是否为满:', q.full()) # Falseprint('队列当中信息的个数:', q.qsize())

使用队列实现进程之间的通信
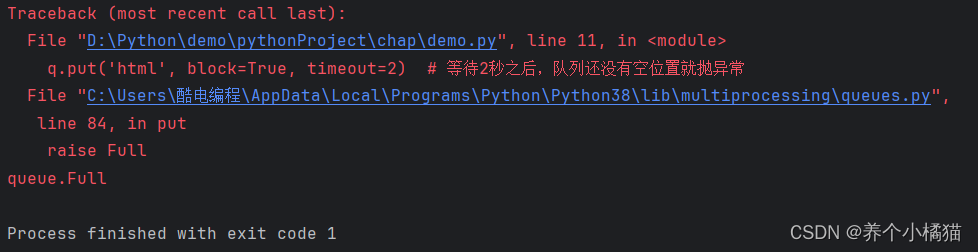
前面说过使用put(item,block=True)【表示进行等待】,当队列满时并不会报错,而且会一直等待,等到队列中有空位置时再入队。

而事实上还有一个参数put(item,block=True,timeout=n),timeout表示等待n秒后,若队列还没有空位置就抛异常 。
from multiprocessing import Queueif __name__ == '__main__':# 创建一个队列q = Queue(3) # 最多可以接收3条信息# 向队列中添加元素(入队)q.put('hello')q.put('world')q.put('Python')q.put('html', block=True, timeout=2) # 等待2秒之后,队列还没有空位置就抛异常
进程之间可以使用队列进行通信,实际上就是入队和出队操作,两个进程,一个进程负责入队,另一个进程负责出队即可。
下面例子,使用队列实现进程之间通信,去操作全局变量的值:
# 使用队列实现进程之间通信。注意这个队列应该是共享的,写和读用的是同一个队列
from multiprocessing import Queue, Process
import timea = 100def writ_msg(q): # q队列global aif not q.full():for i in range(6): # 写6条消息a -= 10q.put(a) # 入队print('a入队时的值:', a)# 出队
def read_msg(q):time.sleep(1)while not q.empty():print('出队时a的值:', q.get())if __name__ == '__main__':print('父进程开始执行')q = Queue() # 由父进程创建队列,没有指定参数,表示可接收的消息个数没有上限# 创建两个子进程p1 = Process(target=writ_msg, args=(q,))p2 = Process(target=read_msg, args=(q,))# 启动两个子进程p1.start()p2.start()# 等待写的进程执行结束,再去执行主进程p1.join()p2.join()print('父进程执行结束')

函数式创建线程
一个应用程序内多任务的方式采用的是多进程,一个进程内的多任务方式采用多线程。
线程:
线程是CPU可调度的最小单位,被包含在进程中,是进程中实际的运作单位。一个进程中可以拥有N多个线程并发执行,而每个线程并行执行不同的任务。
threading模块中有Thread类。
函数式创建线程的语法结构(类似进程):
t = Thread(group,target,name,args,kwargs)
参数说明:
- group:创建线程对象的进程组
- target:创建的线程对象所要执行的目标函数
- name:创建线程对象的名称,默认为“Thread-n”
- args:用元组以位置参数的形式传入target对应函数的参数
- kwargs:用字典以关键字参数的形式传入target对应函数的参数
import threading
from threading import Thread
import time# 编写函数
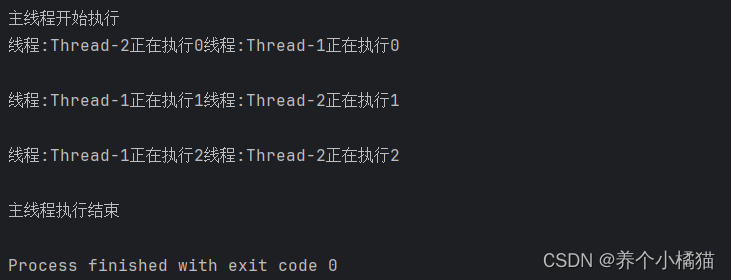
def test():for i in range(3):time.sleep(1)print(f'线程:{threading.current_thread().name}正在执行{i}')if __name__ == '__main__':start = time.time()print('主线程开始执行')# 创建两个线程,使用列表生成式lst = [Thread(target=test) for i in range(2)]for item in lst: # item的数据类型是Thread类型# 启动线程item.start()# 阻塞主线程for item in lst:item.join()print(f'一共耗时{time.time() - start}')'''
多个线程并发执行,每个线程并行执行不同的任务。
该程序中共有一个进程(main),三个线程(main,Thread-1,Thread-2)。三个线程并行执行的任务是:主线程负责执行main中的代码Thread-1线程执行test()三次循环Thread-2线程执行test()三次循环三个线程又是并发执行,Thread-1和Thread-2谁先执行不一定。
'''

继承式创建线程
使用Thread子类创建线程的操作步骤(类似进程):
- 自定义类继承threading模块下的Thread类
- 重写run()方法
import threading
from threading import Thread
import timeclass SubThread(Thread):# 重写run()方法def run(self):for i in range(3):time.sleep(1)print(f'线程:{threading.current_thread().name}正在执行{i}')if __name__ == '__main__':print('主线程开始执行')# 继承式创建两个线程,使用列表生成式lst = [SubThread() for i in range(2)]for item in lst: # item的数据类型是Thread类型# 启动线程item.start()# 阻塞主线程for item in lst:item.join()print('主线程执行结束')
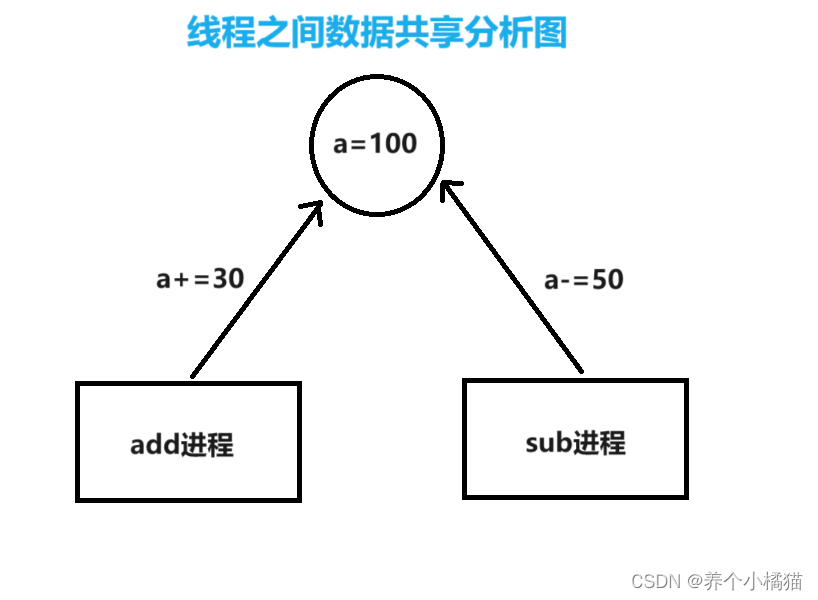
线程之间数据共享
进程之间的数据不共享,线程之间的数据共享。这是因为线程之间会共享该进程中的资源。
from threading import Threada = 100 # 全局变量def add():print('加线程开始执行')global aa += 30print(f'a的值为:{a}')print('加的线程执行结束')def sub():print('减线程开始执行')global aa -= 50print(f'a的值为:{a}')print('减的线程执行结束')if __name__ == '__main__':print('主线程开始执行')print(f'全局变量a的值:{a}')# 线程add = Thread(target=add)sub = Thread(target=sub)# 启动add.start()sub.start()# 阻塞主线程add.join() # 当加线程执行完毕主线程才能继续执行sub.join() # 当减线程执行完毕主线程才能继续执行print(f'主线程执行结束,a的值:{a}')

图示分析:
多个线程共享数据带来的问题以及Lock锁的使用
在上一小节中知道线程共享该进程的资源,所以全局变量a,被这个进程中的所有线程共享。
又因为多个线程是并发执行的,执行顺序无法确定(由CPU调度决定),所以这就可能造成数据错乱。
下面看一个多线程操作共享数据带来的安全性问题:
# 多线程操作共享数据的安全性问题
import threading
from threading import Thread
import timeticket = 50 # 全局变量。代表50张票def sale_ticket():global ticket# 每个排队窗口(线程)假设有100人for i in range(100): # 每个线程要执行100次循环if ticket > 0:print(f'{threading.current_thread().name}正在出售第{ticket}张票')ticket -= 1time.sleep(1)if __name__ == '__main__':for i in range(3): # 创建三个线程,代表3个排队窗口t = Thread(target=sale_ticket)t.start() # 启动线程
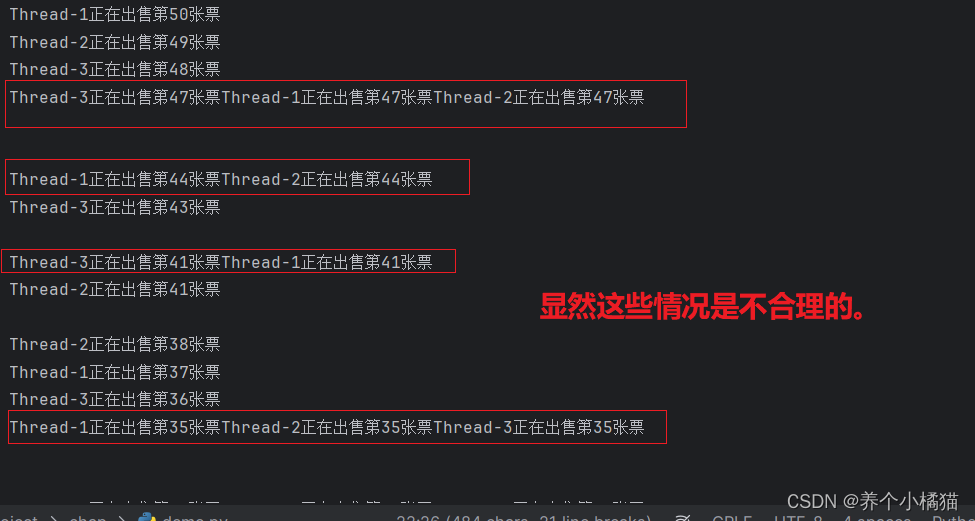

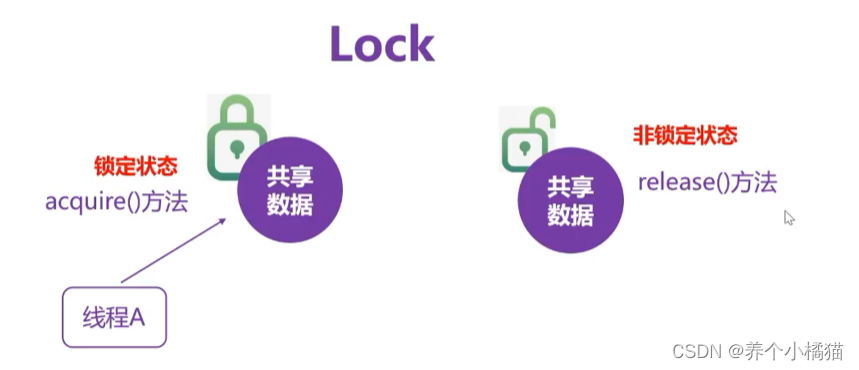
解决这个问题可以采用Lock锁。
当线程A去操作共享数据时,对共享数据加一把锁,这时如果线程B想要操作共享数据就只能等待而不可以操作。只有当锁解开时才允许其他线程进行操作。
Lock对象的acquire()、release()方法:
使用Lock锁机制可以解决共享数据带来的安全性问题,那么如何锁,把锁上在什么地方呢?
在使用Lock锁时要把尽量少的、不耗时的代码放到锁中。
threading模块中的Lock类。
# 使用Lock锁解决多线程操作共享数据的安全性问题
import threading
from threading import Thread, Lock
import timeticket = 50 # 全局变量。代表50张票
lock_obj = Lock() # 创建锁对象def sale_ticket():global ticket# 每个排队窗口(线程)假设有100人for i in range(100): # 每个线程要执行100次循环lock_obj.acquire() # 上锁if ticket > 0:print(f'{threading.current_thread().name}正在出售第{ticket}张票')ticket -= 1time.sleep(1)lock_obj.release() # 释放锁if __name__ == '__main__':for i in range(3): # 创建三个线程,代表3个排队窗口t = Thread(target=sale_ticket)t.start() # 启动线程
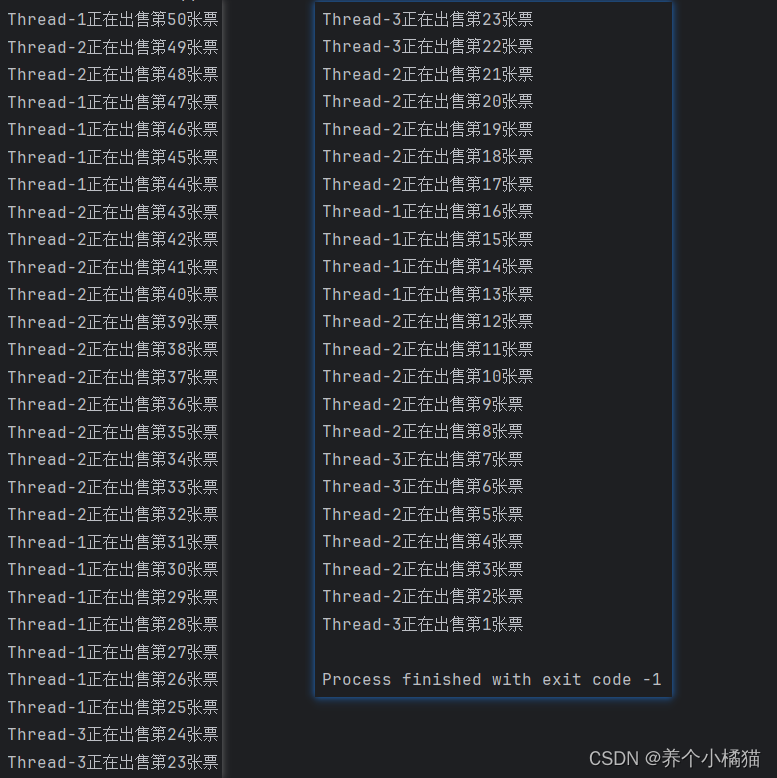
使用Lock锁降低了并发度,但可以解决多线程操作共享数据的安全性问题。
生产者与消费者问题
生产者与消费者模式:
是线程模型中的经典问题,与编程语言无关。当程序中出现了明确的两类任务,一个任务负责生产数据,一个任务负责处理生产的数据时就可以使用该模式。
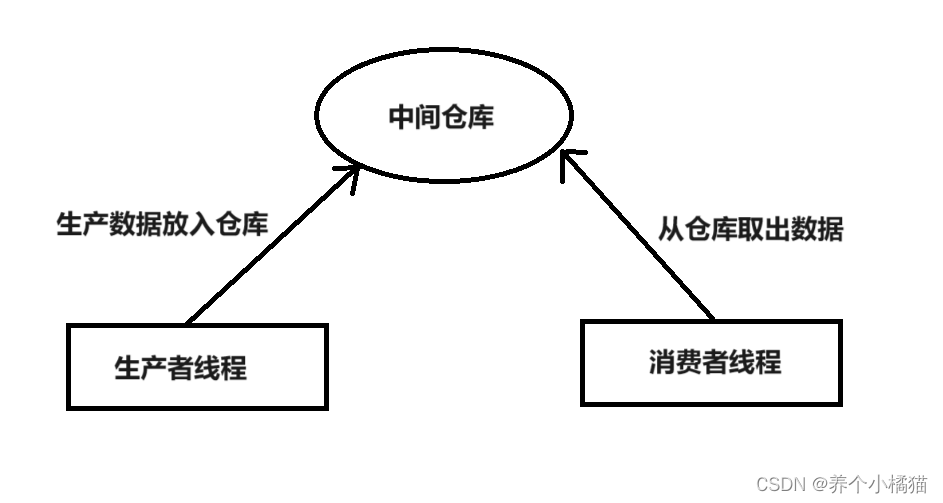
生产者与消费者问题会出现等待与唤醒问题,如果中间仓库满,生产者等待;如果中间仓库空,消费者等待。
使用Python实现生产者与消费者模式需要用到Python内置模块queue中的Queue类。【注意在进程通信中提到的队列是multiprocessing模块中的Queue类】
Python内置模块queue中的Queue类中常用的方法:
| 方法名称 | 功能描述 |
|---|---|
| put(item) | 向队列中放置数据,如果队列为满,则阻塞 |
| get() | 从队列中取走数据,如果队列为空,则阻塞 |
| join() | 如果队列不为空,则等待队列变为空 |
| task_done() | 消费者从队列中取走一项数据,当队列变为空时,唤醒调用join()的线程 |
# 生产者与消费者模式
from queue import Queue
from threading import Thread
import time# 创建一个生产者类
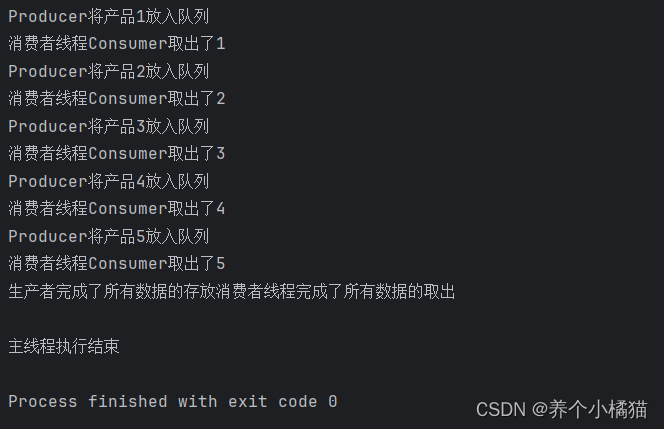
class Producer(Thread):def __init__(self, name, queue):Thread.__init__(self, name=name)self.queue = queuedef run(self):for i in range(1, 6):print(f'{self.name}将产品{i}放入队列')self.queue.put(i)time.sleep(1)print('生产者完成了所有数据的存放')# 创建一个消费者类
class Consumer(Thread):def __init__(self, name, queue):Thread.__init__(self, name=name)self.queue = queuedef run(self):for i in range(5):value = self.queue.get()print(f'消费者线程{self.name}取出了{value}')time.sleep(1)print('消费者线程完成了所有数据的取出')if __name__ == '__main__':# 创建队列queue = Queue() # 该队列表示中间仓库。# 创建生产者线程p = Producer('Producer', queue)# 创建消费者线程c = Consumer('Consumer', queue)# 启动线程p.start()c.start()# 阻塞主线程p.join()c.join()print('主线程执行结束')
相关文章:
第十三章 进程与线程
第十三章 进程与线程 程序与进程的概念 程序: 英文单词为Program,是指一系列有序指令的集合,使用编程语言所编写,用于实现一定的功能。 进程: 进程则是指启动后的程序,系统会为进程分配内存空间。 函数式…...
、状态后端选择和调优等有所了解)
Flink面试整理-对Flink的高级特性如CEP(复杂事件处理)、状态后端选择和调优等有所了解
Apache Flink 提供了一系列高级特性,使其成为一个强大的实时数据处理框架,特别适用于复杂的数据处理场景。其中,复杂事件处理(CEP)、状态后端的选择和调优是其中重要的几个方面。 复杂事件处理(CEP) CEP 概念:CEP 是用于在数据流中识别复杂模式的技术。它允许用户指定事…...

算法:树状数组
文章目录 面试题 10.10. 数字流的秩327. 区间和的个数315. 计算右侧小于当前元素的个数 树状数组可以理解一种数的存储格式。 面试题 10.10. 数字流的秩 假设你正在读取一串整数。每隔一段时间,你希望能找出数字 x 的秩(小于或等于 x 的值的个数)。 请实现数据结构…...

Kafka SASL_SSL集群认证
背景 公司需要对kafka环境进行安全验证,目前考虑到的方案有Kerberos和SSL和SASL_SSL,最终考虑到安全和功能的丰富度,我们最终选择了SASL_SSL方案。处于知识积累的角度,记录一下kafka SASL_SSL安装部署的步骤。 机器规划 目前测试环境公搭建了三台kafka主机服务,现在将详…...
同城交友论坛静态页面app Hbuild
关注...

spring session+redis存储session,实现用户登录功能,并在拦截器里面判断用户session是否过期,过期就跳转到登录页面
在Spring应用中,使用Redis存储Session是一种常见的方式,可以实现分布式环境下的Session管理。以下是实现用户登录功能,并在拦截器中判断Session是否过期并跳转到登录页面的基本步骤: 添加依赖:首先,确保你的…...

Debug-013-el-loading中显示倒计时时间
前言: 今天实现一个小小的优化,业务上是后端需要从设备上拿数据,所以前端需要不断调用一个查询接口,直到后端数据获取完毕,前后端根据一个ending字段为true判断停止调用查询接口。由于这个查询时间比较久&…...

5月29日,每日信息差
第一、据悉,微信视频号直播电商团队将并入到微信开放平台(小程序、公众号等)团队,原微信视频号直播电商团队转由微信开放平台负责人负责。知情人士表示,此次调整,将有助于微信视频号直播电商业务更好地融入…...

2024年弘连网络FIC大会竞赛题线下决赛题
总结: FIC决赛的时候,很多小问题没发现,在pve平台做题确实很方便。 这套题目复盘完,服务器这块的知识确实收获了很多,对pve集群平台和网络拓扑也有了一定的认识,感谢各位大佬悉心指导。 接下来࿰…...

Element-UI 入门指南:从安装到自定义主题的详细教程
Element-UI 是一个基于 Vue.js 的前端组件库,它提供了丰富的 UI 组件,可以帮助开发者快速构建高质量的用户界面。以下是使用 Element-UI 的快速入门指南: 安装 Element-UI Element-UI 是一个基于 Vue.js 的组件库,它提供了丰富的…...
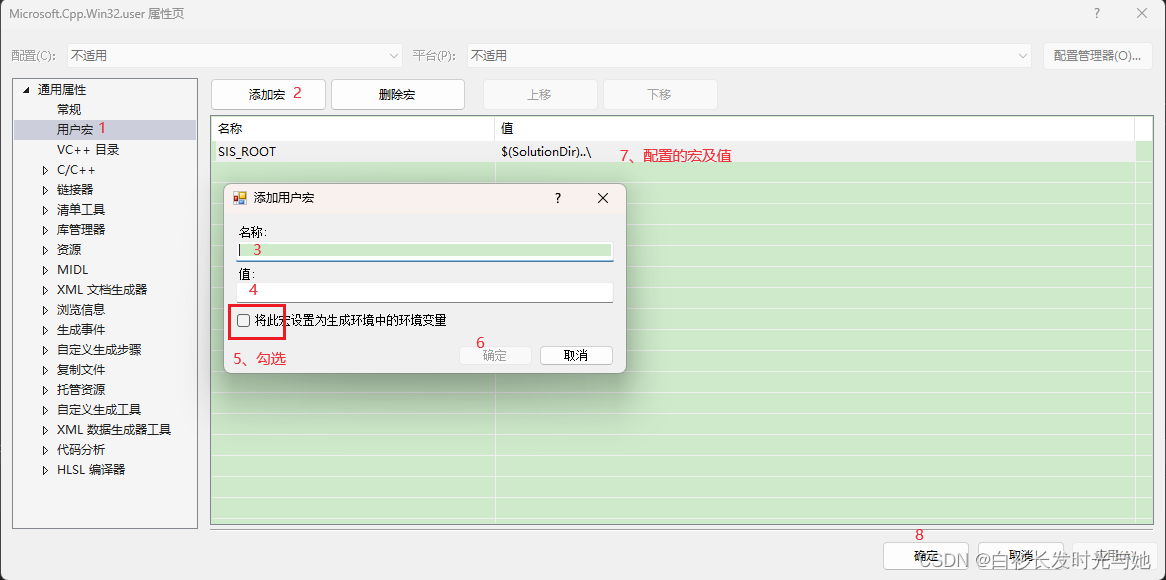
vs工程添加自定义宏
一、简介 用户可以添加自定义宏变量方便工程路径名称的修改和配置 例:$(SolutionDir) 为解决方案路径,$(PojectDir) 为工程所在路径 测试环境:vs2017,qt5.14.0 二、配置 1、打开属性窗口:视图-》其他窗口-》属性管…...

shell脚本:将一维数组以二维数组显示
shell脚本:将一维数组改成二维数组显示 1.编辑脚本文件 vi output_array.sh2.编写脚本 #!/bin/bash# 假设一维数组one_array已经包含9个元素 one_array(1 2 3 4 5 6 7 8 9) # 获取数组长度 length${#one_array[]} # 数组长度除以3获得新数组行数n n$((length / …...

QT C++ 读写mySQL数据库 图片 例子
在上篇文章中描述了怎样搭建读写数据库的环境。 本文更进一步,描述了读写mySQL数据库,字符、整型数字、图片。读写图片相对难点。 数据库的图片字段用BLOB,如果图片较大要用longblob,否则会报错。 另外,读写数据库都使用了短连…...

Unix环境高级编程--8-进程控制---8.1-8.2进程标识-8.3fork函数-8.4 vfork函数
1、进程控制几个过程 创建进程--》执行进程---》终止进程 2、进程标识 (1)专用进程:ID为0的进程是调度进程,常常被称为交换进程,也称为系统进程; ID为1通常是init进程,在自举结束时由内核调用…...

Facebook之魅:数字社交的体验
在当今数字化时代,Facebook作为全球最大的社交平台之一,承载着数十亿用户的社交需求和期待。它不仅仅是一个简单的网站或应用程序,更是一个将世界各地的人们连接在一起的社交网络,为用户提供了丰富多彩、无与伦比的数字社交体验。…...
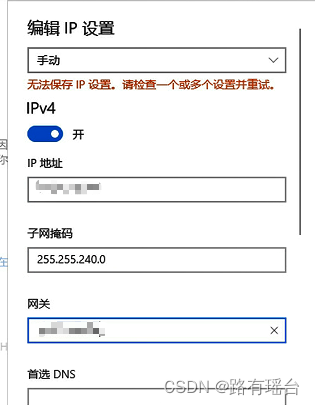
【重装windows遇到网络适配器无法更改】
可以尝试手动在cmd中修改,命令: netsh interface ip set address name"以太网 x" static 新IP地址 子网掩码 网关 注意以太网x之间有空格,以太网外面的引号是英文的。 也可以先在cmd依次输入“netsh”、“interface”࿰…...

FFmpeg+QT播放器实战1---UI页面的设计
1、播放器整体布局的设计 该部分使用QT的UI工具,进行整体页面设置,如下图1所示: 2、控制布局的设计 创建ctrBar的UI页面并进行页面布局设置,如下图2所示: 将图1中ctrBarWind对象提升为ctrBar类(该界面替代原先的控…...

C/C++语法|pthread线程库的使用
笔记主要内容来自 爱编程的大柄–线程 爱编程的大柄–线程同步 在进入代码实践之前,我们应该搞清楚。 线程是成语的最小执行单位,进程是操作系统中最小的资源分配单位。 这样的话我们可以理解以下两点: 同一地址空间中的多个线程独有的是&…...

四川汇聚荣聚荣科技有限公司是正规的吗?
在当今社会,随着科技的飞速发展,越来越多的科技公司如雨后春笋般涌现。然而,在这个信息爆炸的时代,如何判断一家公司是否正规成为了许多人关注的焦点。本文将围绕“四川汇聚荣聚荣科技有限公司是否正规”这一问题展开讨论…...
tomcat学习--部署java项目
主流开发项目,springboot框架下,jar部署java传统的tomcat发布war包 一 什么是tomcat? 是一个用于运行java程序的软件,发布的时候:开发将源码使用maven打包,生产war包 二 安装tomcat tomcat是java写的&a…...

保姆级教程:在Mac/Linux上为RuoYi项目永久修复SQL Server的SSL连接问题
保姆级教程:在Mac/Linux上为RuoYi项目永久修复SQL Server的SSL连接问题 当你在Mac或Linux系统上使用RuoYi框架连接SQL Server数据库时,可能会遇到令人头疼的SSL协议错误。这些错误通常表现为连接池初始化失败或安全连接无法建立,核心问题往往…...
)
破局与重构:基于“智慧大脑”的企业全面数据化经营深度解构(PPT)
“在数字时代,企业最大的风险不是数据的匮乏,而是决策依然依赖经验直觉而非数据驱动。” —— 这份《数字化建设企业经营解决方案》文档,不仅是一份技术蓝图,更是对传统企业经营管理模式的一次彻底颠覆。它描绘了一个从“人治”迈…...

PROFINET通信进阶:S7-1200作为服务器与S7-200 SMART的高效数据交换
PROFINET通信进阶:S7-1200作为服务器与S7-200 SMART的高效数据交换 在工业自动化领域,PROFINET通信协议因其高实时性和稳定性而广受青睐。当S7-1200 PLC作为服务器与S7-200 SMART进行数据交换时,如何优化通信性能成为工程师们关注的焦点。本文…...

终极指南:如何使用Docker Stacks与Git Hooks实现自动化代码质量检查
终极指南:如何使用Docker Stacks与Git Hooks实现自动化代码质量检查 【免费下载链接】docker-stacks Ready-to-run Docker images containing Jupyter applications 项目地址: https://gitcode.com/gh_mirrors/do/docker-stacks Docker Stacks是一个提供现成…...

如何快速实现分布式定时任务?Disque完整指南详解
如何快速实现分布式定时任务?Disque完整指南详解 【免费下载链接】disque Disque is a distributed message broker 项目地址: https://gitcode.com/gh_mirrors/di/disque 分布式定时任务在现代应用中至关重要,而Disque作为Redis作者antirez开发的…...

从数据到洞察:如何利用2024版建筑高度SHP数据,5步完成城市热岛效应初步分析
从数据到洞察:如何利用2024版建筑高度SHP数据,5步完成城市热岛效应初步分析 城市热岛效应是城市化进程中普遍存在的环境问题,表现为城市中心区域温度明显高于周边郊区的现象。这种现象不仅影响居民的生活质量,还会加剧能源消耗和空…...

wxappUnpacker:让微信小程序源代码重见天日的开发者利器
wxappUnpacker:让微信小程序源代码重见天日的开发者利器 【免费下载链接】wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 在微信小程序开发过程中,开发者常常面临源代码被打包加密的困境,特别是当需…...

C++实战:用代码构建你的斗罗大陆武魂觉醒系统
1. 从零开始搭建武魂觉醒系统 第一次看到斗罗大陆的武魂觉醒桥段时,我就被这个充满想象力的设定吸引了。作为程序员,我总忍不住思考:如果用代码实现这个系统会怎样?去年带新人培训时,我尝试用C还原了这个过程ÿ…...

SpringBoot+Vue企业员工薪酬管理系统源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...

告别窗口混乱:Loop如何让macOS窗口管理效率提升300%
告别窗口混乱:Loop如何让macOS窗口管理效率提升300% 【免费下载链接】Loop MacOS窗口管理 项目地址: https://gitcode.com/GitHub_Trending/lo/Loop 痛点场景:被窗口吞噬的工作效率 产品经理陈默的桌面上永远摊着至少7个窗口:左侧是S…...