爬虫面试手册
爬虫面试手册
薪资13~20k
岗位职责:
- 负责公司数据平台的数据采集、运维优化;
- 负责自动化脚本,爬虫脚本;
- 研究数据采集策略和防屏蔽规则,提升数据采集系统的稳定性、可扩展性,提高抓取的效率和质量;
岗位要求
- 本科及以上学历,计算机、信息科学及相关专业毕业;
- 熟悉java、python或go编程语言,熟悉分布式多线程编程,熟悉网络协议及数据交换标准;
- 熟悉反爬原理,有成熟的绕过网站屏蔽解决方案;
- 熟悉scrapy、nutch等常用爬虫框架及原理;
- 熟悉app抓取技术,熟悉常规反爬虫策略和规避方法,能够独立承担爬虫运维工作;
- 熟悉beautifulsoup、selenium技术等;
- 使用过爬虫工具八爪鱼、火车头等;
- 能解决封账号、封IP、验证码识别、图像识别、风控等问题、有解决封号经验优先;
- 具有丰富的JS逆向经验,熟悉反混淆、JS跟踪、JS 逆向、WASM、JSVMP还原技能;
- 熟练使用AST还原JS、能绕过常见的JS反调试;
- 分析问题逻辑清晰,有高度的责任心,有良好的团队协作意识和沟通能力,善于学习和钻研技术;
- 加分项:爬取数据日均超100w次,深度参与至少一个大规模分布式爬虫系统的架构设计。
- http 协议与 https 协议的区别?
- http 协议需要到 ca 申请证书,一般免费证书较少,因而需要一定费用;
- http 是超文本传输协议,信息是明文传输,https 则是具有安全性的 ssl加密传输协议;
- http 和 https 使用的是完全不同的连接方式,用的端口不一样,前者是 80,后者是 443;
- http 的连接很简单,是无状态的,https 协议是有 ssl +http 协议构建的可进行加密传输、身份认证的网络协议,比 http 协议安全;
- 什么是 robots 协议?阐述 robots 协议与 爬虫的关系?
- Robots 协议是约定哪些内容允许哪些爬虫抓取;
- 通用爬虫无需遵守 robots 协议,而我们写的聚焦爬虫则需要遵守。
- 简述聚焦爬虫的设计思路?
- 确定 url,模拟浏览器向服务器发送请求;
- 获取响应数据并进行数据解析;
- 将目标数据持久化到本地;
- 简述爬虫的分类及各类爬虫的概念。
- 通用爬虫:爬取网页数据,为搜索引擎提供检索服务;
- 聚焦爬虫:针对某一领域爬取特定数据的爬虫;又分为深度爬虫和增量式爬虫。
- 请写出 8 中常用的请求方法。
Get、 Post、Put、 Delete、Trace、 Head、Connect、Option
- 列举反爬虫机制。
- UA 检测;
- Robots 协议;
- 验证码;
- IP 封禁;
- 账号封禁;
- 动态数据加载;
- Js 数据加密;
- 隐藏参数;
- 字体反爬
- Requests 模块发送 get 请求的参数。
- Url;
- Headers;
- Params;
- Proxies;
- Requests 发送请求时携带 headers 参数及作用。
- User-Agent:实现 UA 伪装;
- Cookie:模拟登陆;
- Connection:保持连接;
- Accept:接受数据类型。
- Requests 向服务器发送文件时,文件的打开模式是什么?
Wb
- Requests 模块那个类自动封装 cookie。
session
- 针对 requests 请求的响应对象,如何获取其文本形式,二进制形式及 json数据
- Res.text:获取 html 源码;
- Res.content:获取二进制流,多用于图片、视频下载等;
- Res.json():获取 json 数据,多用 ajax 请求。
- 请列举数据持久化的方式。
Csv、Json、Mysql、Mongodb、Redis
- Cookie 和 session 的区别?
- 数据存储位置不同,cookie 存在客户端,session 存在服务器;
- 安全程度不同,cookie 存客户端本地,分析 cookie,实现 cookie 欺骗,考虑到安全性,所以用 session;
- 性能不同,session 存服务器,访问量大时,会增加服务器负载,考虑到性能,所以用 cookie;
- 数据存储大小不同,单个 cookie 不超过 4k,部分浏览器会限制 cookie的存储个数,但 session 存在服务器,故不受客户端浏览器限制。
- 请写出 tcp/udp 协议,ip 协议,arp 协议,http/https 协议及 ftp 协议分别位于 tcp/ip 五层模型的哪一层。
- TCP/UDP 协议:传输层;
- IP:网络层;
- ARP 协议:数据链路层;
- HTTP/HTTPS:应用层;
- FTP 协议:应用层。
- 请说出 tcp/ip 五层模型。
- 应用层;
- 传输层;
- 网络层;
- 数据链路层;
- 物理层。
- 谈谈 tcp 三次握手四次挥手中为什么要三次握手?
- TCP 连接的三次握手是为了建立可靠的连接;
- 第一次握手:客户端向服务器发送 SYN 包,并进入 SYN_SENF 状态,等待服务器确认;
- 第二次握手:服务器收到 SYN 包,确认并发送 SYN+ACK 包,同时进入 SYN_RECV 状态;
- 第三次握手:客户端收到服务器 SYN+ACK 包,向服务器确认 ACK 包,进入 ESTABLISHED 状态
- 请写出 ftp、ssh、mysql、MongoDB、redis 协议或软件的默认端口。
- ftp:21;
- Ssh:22;
- Mysql:3306;
- Mongodb:27017;
- Redis:6379。
- Mongodb 数据库的优点。
- 模式自由,面向集合存储,项目增删字段不影响程序运行;
- 具有丰富的查询表达式,支持动态查询,以满足项目的数据查询需求;
- 良好的索引支持,文档内嵌对象和数组,均可创建索引;
- 支持二进制数据存储,可以将图片视频等文件转换为二进制流存储起来;
- 以内存映射为存储引擎,大幅度提升性能。
- 多线程爬虫共封装了几个类?每个类的作用是什么?
- 两个类:爬虫类、解析类;
- 爬虫类;定义爬取的行为,将响应数据提交给响应数据队列;
- 解析类:定义数据解析规则并与数据库交互,将数据持久化进数据库。
- 简述 scrapy 五大核心组件及作用。
- 引擎:负责各个组件之间的通讯信号及数据的传递;
- 爬虫:定义了爬取行为和解析规则,提交 item 并传给管道;
- 调度器:接受引擎传递的 request,并整理排列,然后进行请求的调度;
- 下载器:负责下载 request,提交响应给引擎,引擎传递给 spider;
- 管道: 负责处理 spider 传递来 的 item,如 去重、持久化存储等。
- Scrapy 框架有哪些优点?
- 框架封装的组件丰富,适用于开发大规模的抓取项目;
- 框架基于 Twisted 异步框架,异步处理请求,更快捷,更高效;
- 拥有强大的社区支持,拥有丰富的插件来扩展其功能;
- 如何判断 scrapy 管道类是否需要 return item?
在 scrapy 框架中,可以自定义多个管道类,以满足不同的数据持久化需求,当定义多管理类时,多个管道需传递 item 来进行存储,管道类各有自己的权重,权重越小,我们认为越接近引擎,越先接受引擎传递来的 item 进行存储, 故欲使权重大的管道能够接受到 item,前一个管道必须 return item,如果一个管道类后无其他管道类,该管道则无需return item。
- 请问为什么下载器返回的相应数据不是直接通过擎传递给管道,而是传递给 spider?
由于在 scrapy 中,spider 不但定义了爬取的行为,还定义了数据解析规则,所以响应数据需传递给 spider 进行数据解析后,才能将目标数据传递给管道,进行持久化存储。
- 简述详情页爬取的思路。
- 访问列表页;
- 从列表页的响应数据中获取详情页 url;
- 请求详情页 url,使用 scrapy.request 手动发送请求并指定回调;
- 解析数据在回调中获取目标数据;
- 简述多页爬取的思路。
- 思路一:将所有的页面 url 生成后放在 start_urls 中,当项目启动后会对 start_urls 中的 url 发起请求,实现多页爬取;
- 思路二:在解析方法中构建 url,使用 scrapy 手动发送请求并指定回调,实现多页爬取。
- 请谈谈动态数据加载的爬取思路。
在 scrapy 项目中正常对动态加载的页面发起请求,在下载中间件中拦截动态加载页面的响应数据,在process_response方法中,调用selenium抓取相应的 url,获取 html 源码后再替换原有响应
- 请列举几种反爬机制及其对应的反爬策略。
- Ua检测:ua 伪装;
- Robots 协 议 : requests 模 块 无 须 理 会 , settings 配 置 中 将ROBOTSTXT_OBEY 改为 False;
- 动态数据加载:selenium 抓取;
- 图片懒加载:根据响应数据获取实际的 src 属性值;
- Ip 封禁:使用代理 ip。
相关文章:

爬虫面试手册
爬虫面试手册 薪资13~20k 岗位职责: 负责公司数据平台的数据采集、运维优化;负责自动化脚本,爬虫脚本;研究数据采集策略和防屏蔽规则,提升数据采集系统的稳定性、可扩展性,提高抓取的效率和质量; 岗位要求 本科及…...
)
k8s cephfs(动态pvc)
官方参考文档:GitHub - ceph/ceph-csi at v3.9.0 测试版本 Ceph Version Ceph CSI Version Container Orchestrator Name Version Tested v17.2.7 v3.9.0 Kubernetes v1.25.6 安装Ceph-csi Step 1 Download GitHub - ceph/ceph-csi at v3.9.0 rootsd-k8s…...

dubbo复习:(9)配置中心的大坑,并不能像spring cloud那样直接从配置中心读取自定义的配置
配置中心只是为 Dubbo 配置提供管理使用的(比如配置服务超时时间等)。不要尝试通过Value类似的方式从dubbo 配置中心(比如nacos、zookeeper、Apollo)来获取数据 https://github.com/apache/dubbo/issues/11200可以在application.yml中主要写注册中心的配置…...
建设现代智能工业-智能化、数字化、自动化节能减排
建设现代智能工业-智能化节能减排 遵循“一体化”能源管理(Integrated Energy Management)的设计宗旨,集成城市各领域(如工业.交通、建筑等)的能源生产和消费信息,面向城市政府、企业、公众三类实体,提供“一体化”的综合能源管理…...

据报导,SK海力士的HBM团队源自三星,暗示三星不幸失去HBM优势
最新科技动态显示,三星的高带宽记忆体(High Bandwidth Memory, HBM)技术尚未获得GPU巨头英伟达(NVIDIA)的认证,导致其落后于竞争对手SK海力士。这一挫折直接导致三星半导体部门负责人更迭。尽管三星官方否认…...

Verilog HDL基础知识(一)
引言:本文我们介绍Verilog HDL的基础知识,重点对Verilog HDL的基本语法及其应用要点进行介绍。 1. Verilog HDL概述 什么是Verilog?Verilog是IEEE标准的硬件描述语言,一种基于文本的语言,用于描述最终将在硬件中实现…...

Django之文件上传(一)
一、环境搭建 建立项目 django-admin startproject project_demo配置数据库(以MySQL为例) # settings.py DATABASES = {default: {ENGINE: django.db.backends.mysql,NAME: django_file4,USER: root,PASSWORD: 123,HOST: 192.168.31.151,PORT: 3306,} }建立模型 class UploadF…...

光纤现网与接入网概念对应
OLT 一般在机房 一级分光可能在机房也可能在光交交接箱 路边的光交交接箱功能有分光或者光纤汇聚转换一下 二级分光在分光光纤箱里,楼道里面挂着的那种 ONU是家里的光猫...

通过扩展指令增强基于覆盖引导的模糊测试
本文由Bruno Oliveira于2024年4月25日发表于IncludeSec的官方网站上。作为IncludeSec的安全研究人员,在他们日常的安全审计和渗透测试工作中,有时需要为客户开发一些模糊测试工具。在安全评估方法中使用模糊测试技术,可以有效地在复杂的现代化…...
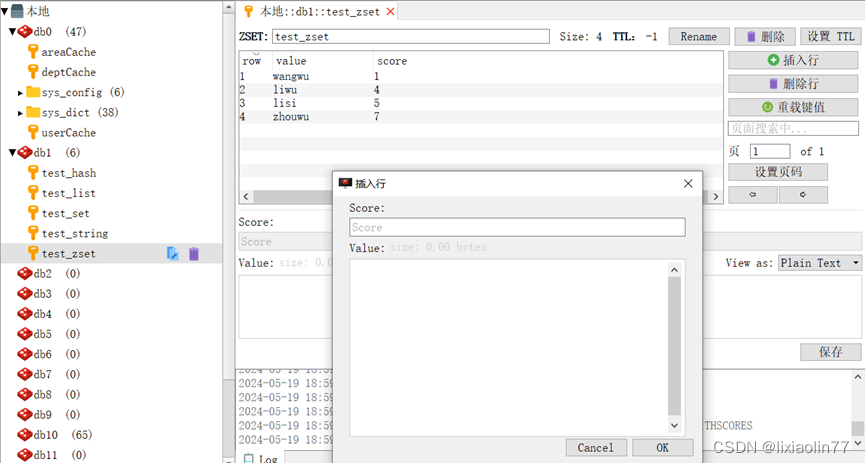
第一节:Redis的数据类型和基本操作
最近整理了关于Redis的一些文档,分享给大家,后续会持续更新...... Redis的数据类型 字符串String String:字符串,可以存储String、Integer、Float型的数据,甚至是二进制数据,一个字符串最大容量是512M 列表…...
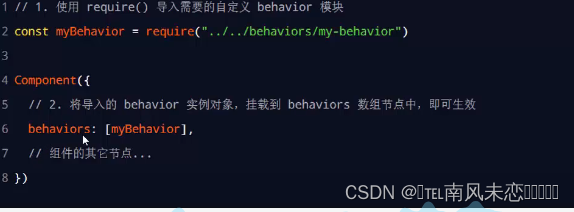
组件的传参等
一:组件的生命周期函数 组件的生命周期函数: created只是创建了组件内的实例对象 attached,给组件实例绑定了属性,绑定到页面节点树之后 ready准备好渲染之后,还未渲染之前 moved组件实例被移动到另一个位置后执行 detached在整个组件被被移除执行 error执行的时候,组件内…...
构建php环境、安装、依赖、nginx配置、ab压力测试命令、添加php-fpm为系统服务
目录 php简介 官网php安装包 选择下载稳定版本 (建议使用此版本,文章以此版本为例) 安装php解析环境 准备工作 安装依赖 zlib-devel 和 libxml2-devel包。 安装扩展工具库 安装 libmcrypt 安装 mhash 安装mcrypt 安装php 选项含…...
服装服饰商城小程序的作用是什么
要说服装商家,那数量是非常多,厂家/经销门店/小摊/无货源等,线上线下同行竞争激烈,虽然用户群体广涵盖每个人,但每个商家肯定都希望更多客户被自己转化,渠道运营方案营销环境等不可少。 以年轻人为主的消费…...
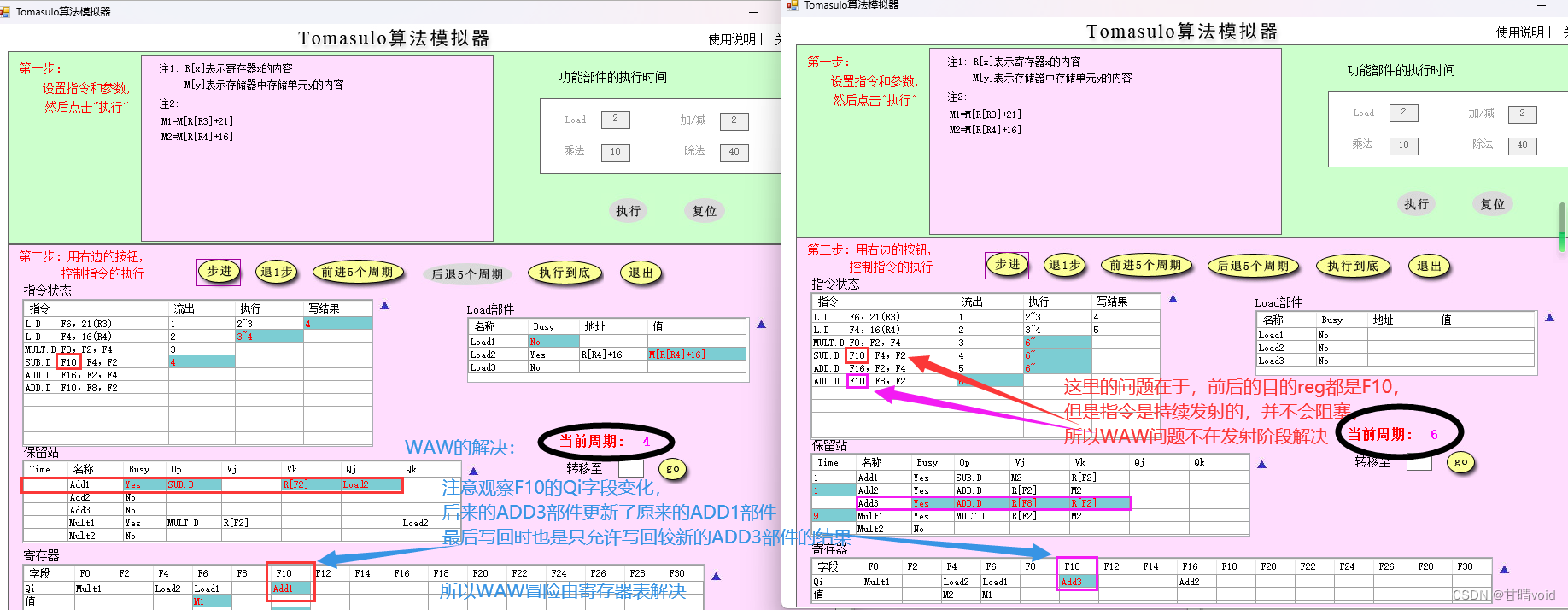
HNU-计算机体系结构-实验2-Tomasulo算法
计算机体系结构 实验2 计科210X 甘晴void 202108010XXX 1 实验目的 熟悉Tomasulo模拟器同时加深对Tomasulo算法的理解,从而理解指令级并行的一种方式-动态指令调度。 掌握Tomasulo算法在指令流出、执行、写结果各阶段对浮点操作指令以及load和store指令进行什么…...

深入分析 Android Activity (一)
文章目录 深入分析 Android Activity (一)1. Activity 的窗口管理2. Activity 的生命周期管理onCreateonStartonResumeonPauseonStoponDestroyonRestart 3. Activity 与 Fragment 的交互添加 FragmentFragment 的生命周期 4. Activity 的任务和返回栈5. 配置变化处理 总结 深入…...
Python 调整PDF文件的页面大小
在处理PDF文件时,我们可能会遇到这样的情况:原始PDF文档不符合我们的阅读习惯,或者需要适配不同显示设备等。这时,我们就需要及时调整PDF文档中的页面尺寸,以满足不同应用场景的需求。 利用Python语言的高效性和灵活性…...

支付功能、支付平台、支持渠道如何测试?
有学员提问:作为一个支付平台,接入了快钱、易宝或直连银行等多家的渠道,内在的产品流程是自己的。业内有什么比较好的测试办法,来测试各渠道及其支持的银行通道呢? 作为产品,我自己办了十几张银行卡方便测…...
和元空间(Metaspace))
永久代(Permanent Generation)和元空间(Metaspace)
永久代(Permanent Generation)和元空间(Metaspace)是Java虚拟机(JVM)内存管理中的两个概念,主要区别在于它们的实现方式和内存分配策略。 永久代(Permanent Generation)…...

前端面试题23-34
23. 说说你对 Promise 的理解 Promise 是 ECMAScript6 引入的一种异步编程解决方案,用于处理异步操作。它表示一个尚未完成但最终会结束的操作,具有三种状态:pending(进行中)、fulfilled(已完成࿰…...

Hadoop3:HDFS中DataNode与NameNode的工作流程
一、DataNode中的数据情况 数据位置 /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-823420375-192.168.31.102-1714395693863/current/finalized/subdir0/subdir0块信息 每个块信息,由两个文件保存,xxx.meta保存的是数据长度、校验和、时间戳&am…...

球阀市场增长预测:预计到2032年将增长至1473.1亿元
据恒州诚思调研统计,2025年全球球阀市场规模达1078.8亿元,预计到2032年将增长至1473.1亿元,2026-2032年复合增长率(CAGR)为4.5%。同期,全球球阀产量达19,894万件,平均售价为75美元/件。作为流体…...

视频技术三要素:码率、帧率与分辨率的实战解析
1. 视频三要素的基础认知 第一次接触视频制作时,我被各种专业术语搞得晕头转向。直到有前辈告诉我:"其实只要搞懂码率、帧率和分辨率这三个参数,就能解决80%的视频质量问题。"这句话让我茅塞顿开,今天我就把这些年积累的…...

Packet Tracer实战:交换机基础配置与常见问题排查
1. Packet Tracer与交换机配置入门 第一次接触网络设备配置的朋友可能会觉得交换机是个神秘的黑盒子。其实用Cisco Packet Tracer这个仿真工具,你完全可以在自己的电脑上搭建一个虚拟实验室。我刚开始学习时也是从这个工具入手的,它比真机操作更友好——…...

终极指南:如何用Ice打造清爽Mac菜单栏?2025年最强大的macOS菜单栏管理工具
终极指南:如何用Ice打造清爽Mac菜单栏?2025年最强大的macOS菜单栏管理工具 【免费下载链接】Ice Powerful menu bar manager for macOS 项目地址: https://gitcode.com/GitHub_Trending/ice/Ice Ice是一款强大的macOS菜单栏管理工具,它…...

状态量: 轮速、滑移率、附着系数
基于分布式驱动电动汽车的路面附着系数估计,分别采用无迹卡尔曼滤波(UKF)和容积卡尔曼滤波(CKF)对电动汽车四个车轮的路面附着系数进行估计。可高速,低速,高附着系数,低附着系数&…...

CRNN OCR文字识别镜像:开箱即用,轻松集成到你的项目中
CRNN OCR文字识别镜像:开箱即用,轻松集成到你的项目中 1. 项目概述 在现代数字化场景中,OCR(光学字符识别)技术已成为从图像中提取文本信息的关键工具。本镜像基于工业级CRNN(卷积循环神经网络࿰…...

Windows 11 零基础搞定 Coze Studio 本地部署:Docker 配置 + 豆包模型实战
Windows 11 零基础搞定 Coze Studio 本地部署:Docker 配置 豆包模型实战 1. 环境准备与Docker安装 对于Windows 11用户来说,Docker是运行Coze Studio的基础环境。与Linux或macOS不同,Windows平台需要特别注意虚拟化支持和镜像源配置。 硬…...

Alt App Installer革新:突破微软商店限制的Windows应用安装解决方案
Alt App Installer革新:突破微软商店限制的Windows应用安装解决方案 【免费下载链接】alt-app-installer A Program To Download And Install Microsoft Store Apps Without Store 项目地址: https://gitcode.com/gh_mirrors/alt/alt-app-installer 微软商店…...

SDMatte提示词库共建:分享与收集高效抠图的魔法指令
SDMatte提示词库共建:分享与收集高效抠图的魔法指令 1. 为什么需要提示词库 抠图是设计工作中最常见的需求之一,但每次都要从头开始描述需求既费时又低效。这就好比每次做饭都要从认识食材开始,而不是直接使用现成的菜谱。SDMatte作为智能抠…...

不用公网IP!用cpolar内网穿透实现PicHome多设备同步的3种方案对比
零公网IP实现PicHome多端同步:cpolar内网穿透全方案解析 在数字资产爆炸式增长的今天,如何安全高效地管理个人媒体库成为现代人的刚需。PicHome作为一款开源网盘系统,凭借其Docker化部署的便捷性和AI增强的媒体管理能力,正在成为家…...