YOLOv5改进 | 注意力机制 | 添加双重注意力机制 DoubleAttention【附代码/涨点能手】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡
在图像识别中,学习捕捉长距离关系是基础。现有的CNN模型通常通过增加深度来建立这种关系,但这种形式效率极低。因此,双重注意力被提出,这是一个新颖的组件,它能够从输入图像的整个时空空间聚合和传播信息丰富的全局特征,使得后续的卷积层能够高效地访问整个空间特征。这个组件通过两步的双重注意力机制来设计,第一步通过二阶注意力池化从整个空间收集特征到一组紧凑集合,第二步通过另一种注意力自适应选择和分配特征到每个位置。在本文中,给大家带来的教程是将原来的网络添加DoubleAttention。文章在介绍主要的原理后,将手把手教学如何进行模块的代码添加和修改,并将修改后的完整代码放在文章的最后,方便大家一键运行,小白也可轻松上手实践。以帮助您更好地学习深度学习目标检测YOLO系列的挑战。
专栏地址: YOLOv5改进+入门——持续更新各种有效涨点方法 点击即可跳转
目录
1.原理
2. DoubleAttention代码实现
2.1 将DoubleAttention添加到YOLOv5中
2.2 新增yaml文件
2.3 注册模块
2.4 执行程序
3. 完整代码分享
4.GFLOPs
5. 进阶
6. 总结
1.原理

官方论文:A2 -Nets: Double Attention Networks——点击即可跳转
官方代码:A2 -Nets: Double Attention Networks官方代码仓库——点击即可跳转
双重注意力网络(Double Attention Networks)是一种用于计算机视觉任务的神经网络架构,旨在有效地捕获图像中的全局和局部信息,以提高任务的性能。它是建立在注意力机制的基础上的,通过两个注意力模块来分别关注全局和局部信息。以下是关于Double Attention Networks的详细解释:
-
注意力机制: 注意力机制是一种模仿人类视觉系统的方法,它允许神经网络在处理输入数据时集中注意力在最相关的部分上。在计算机视觉中,这意味着网络可以动态地选择关注图像的不同部分,从而提高任务的性能。
-
双重注意力: 双重注意力网络引入了两个注意力模块,分别用于全局和局部信息。这两个模块分别关注图像的整体结构和局部细节,从而充分利用了图像中的各种信息。
-
全局注意力模块: 全局注意力模块负责捕获图像中的全局信息。它通常采用全局池化(global pooling)操作,将整个特征图进行压缩,然后通过一系列的神经网络层来学习全局上下文信息。这个模块能够帮助网络理解图像的整体语义结构。
-
局部注意力模块: 局部注意力模块专注于捕获图像中的局部信息。它通常采用一种局部感知机制(local perception),通过对图像进行分块或者使用卷积操作来提取局部特征,并且通过注意力机制来选择最相关的局部信息。这个模块有助于网络在处理具有局部结构的图像时更加准确。
-
特征融合: 在双重注意力网络中,全局和局部注意力模块学习到的特征需要被合并起来以供最终任务使用。这通常通过简单地将两个模块的输出进行融合,例如连接或者加权求和操作。这种特征融合使得网络能够综合利用全局和局部信息来完成任务。
通过以上的双重注意力网络架构,神经网络可以更有效地利用图像中的全局和局部信息,从而在各种计算机视觉任务中取得更好的性能。
2. DoubleAttention代码实现
2.1 将DoubleAttention添加到YOLOv5中
关键步骤一: 将下面代码粘贴到/projects/yolov5-6.1/models/common.py文件中

from torch import nn
import torch
from torch.autograd import Variable
import torch.nn.functional as Fclass DoubleAttentionLayer(nn.Module):"""Implementation of Double Attention Network. NIPS 2018"""def __init__(self, in_channels: int, c_m: int, c_n: int, reconstruct=False):"""Parameters----------in_channelsc_mc_nreconstruct: `bool` whether to re-construct output to have shape (B, in_channels, L, R)"""super(DoubleAttentionLayer, self).__init__()self.c_m = c_mself.c_n = c_nself.in_channels = in_channelsself.reconstruct = reconstructself.convA = nn.Conv2d(in_channels, c_m, kernel_size=1)self.convB = nn.Conv2d(in_channels, c_n, kernel_size=1)self.convV = nn.Conv2d(in_channels, c_n, kernel_size=1)if self.reconstruct:self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size=1)def forward(self, x: torch.Tensor):"""Parameters----------x: `torch.Tensor` of shape (B, C, H, W)Returns-------"""batch_size, c, h, w = x.size()assert c == self.in_channels, 'input channel not equal!'A = self.convA(x) # (B, c_m, h, w) because kernel size is 1B = self.convB(x) # (B, c_n, h, w)V = self.convV(x) # (B, c_n, h, w)tmpA = A.view(batch_size, self.c_m, h * w)attention_maps = B.view(batch_size, self.c_n, h * w)attention_vectors = V.view(batch_size, self.c_n, h * w)# softmax on the last dimension to create attention mapsattention_maps = F.softmax(attention_maps, dim=-1) # 对hxw维度进行softmax# step 1: feature gatheringglobal_descriptors = torch.bmm( # attention map(V)和tmpA进行tmpA, attention_maps.permute(0, 2, 1)) # (B, c_m, c_n)# step 2: feature distribution# (B, c_n, h * w) attention on c_n dimension - channel wiseattention_vectors = F.softmax(attention_vectors, dim=1)tmpZ = global_descriptors.matmul(attention_vectors) # B, self.c_m, h * wtmpZ = tmpZ.view(batch_size, self.c_m, h, w)if self.reconstruct:tmpZ = self.conv_reconstruct(tmpZ)return tmpZ双重注意力网络的主要过程涉及以下几个关键步骤:
-
输入图像的特征提取: 首先,输入的图像经过一个预训练的卷积神经网络(CNN)模型,例如ResNet、VGG等,以提取图像的特征。这些特征通常是一个高维度的张量,表示了图像在不同层次上的抽象特征信息。
-
全局注意力模块: 对于提取的图像特征,首先通过全局注意力模块进行处理。这个模块通常包括以下几个步骤:
-
使用全局池化操作(如全局平均池化)将特征图进行降维,得到全局上下文信息。
-
将降维后的全局特征通过一个全连接网络(FCN)进行处理,以学习全局信息的表示。
-
使用激活函数(如ReLU)来增加网络的非线性表示能力。
-
-
局部注意力模块: 接下来,提取的特征经过局部注意力模块的处理。这个模块主要负责捕获图像中的局部信息,并结合全局信息进行处理。其主要步骤包括:
-
将特征图分成不同的区域或者使用卷积操作来提取局部特征。
-
对每个局部特征使用注意力机制,计算其与全局信息的相关程度,以得到局部的重要性权重。
-
使用得到的权重对局部特征进行加权合并,以得到最终的局部表示。
-
-
特征融合: 全局和局部模块得到的特征需要被合并起来以供最终任务使用。通常的融合方式包括简单的连接、加权求和或者其他组合方式。这种特征融合能够让网络充分利用全局和局部信息,从而提高任务性能。
-
任务特定的输出: 最后,融合后的特征被送入一个或多个任务特定的神经网络层,例如全连接层或者卷积层,以完成具体的任务。这个任务可以是图像分类、目标检测、语义分割等。

2.2 新增yaml文件
关键步骤二:在下/projects/yolov5-6.1/models下新建文件 yolov5_DANet.yaml并将下面代码复制进去
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, DoubleAttentionLayer, [128,3]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 15], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 11], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[18, 21, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]温馨提示:本文只是对yolov5l基础上添加swin模块,如果要对yolov8n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLOv5n
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple# YOLOv5s
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple# YOLOv5l
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# YOLOv5m
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple# YOLOv5x
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple2.3 注册模块
关键步骤三:在yolo.py中注册, 大概在260行左右添加 ‘DoubleAttentionLayer’

2.4 执行程序
在train.py中,将cfg的参数路径设置为yolov5_DANet.yaml的路径
建议大家写绝对路径,确保一定能找到
🚀运行程序,如果出现下面的内容则说明添加成功🚀
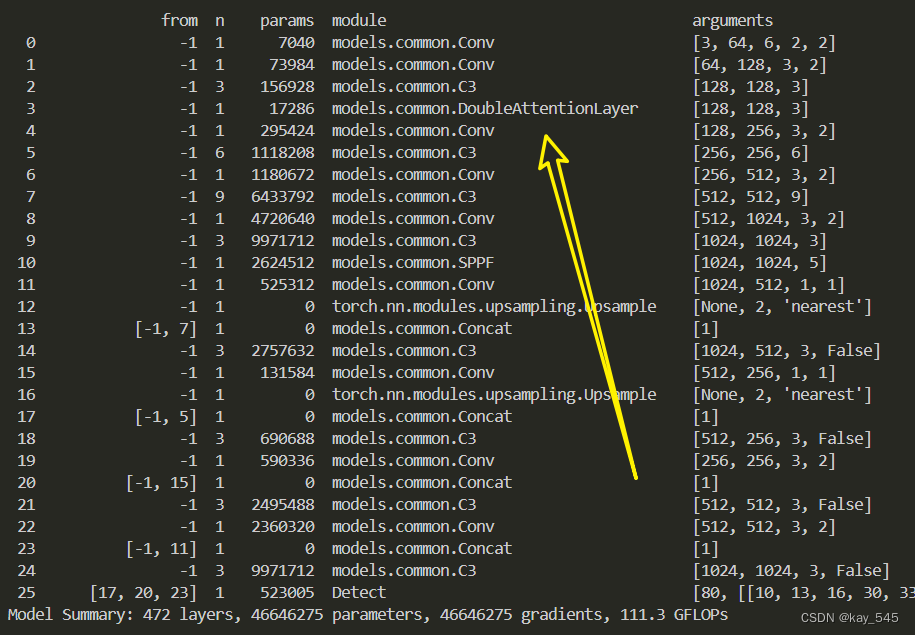
3. 完整代码分享
https://pan.baidu.com/s/1z8fKOHrX0-zTRD8QHmBC4w?pwd=vi9l提取码:vi9l
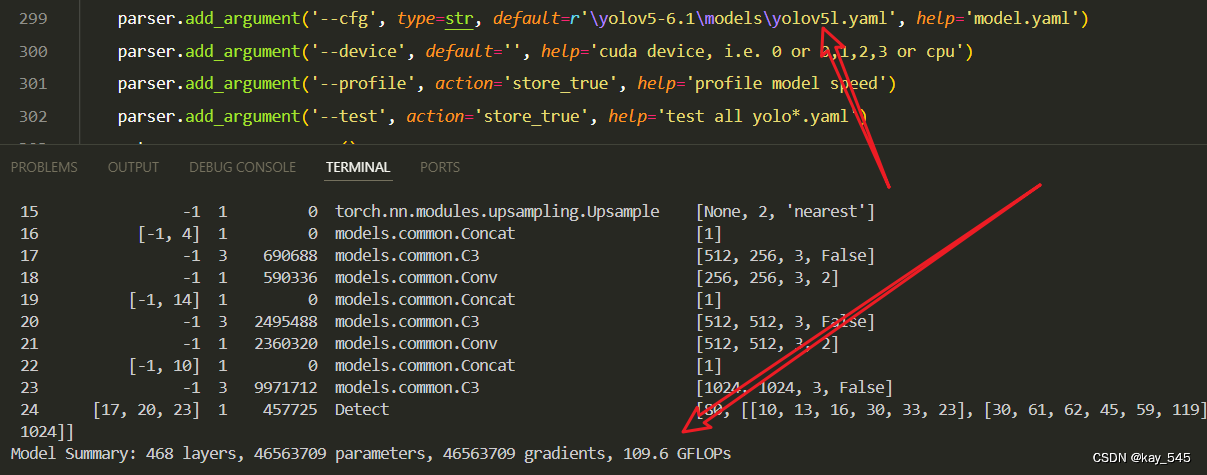
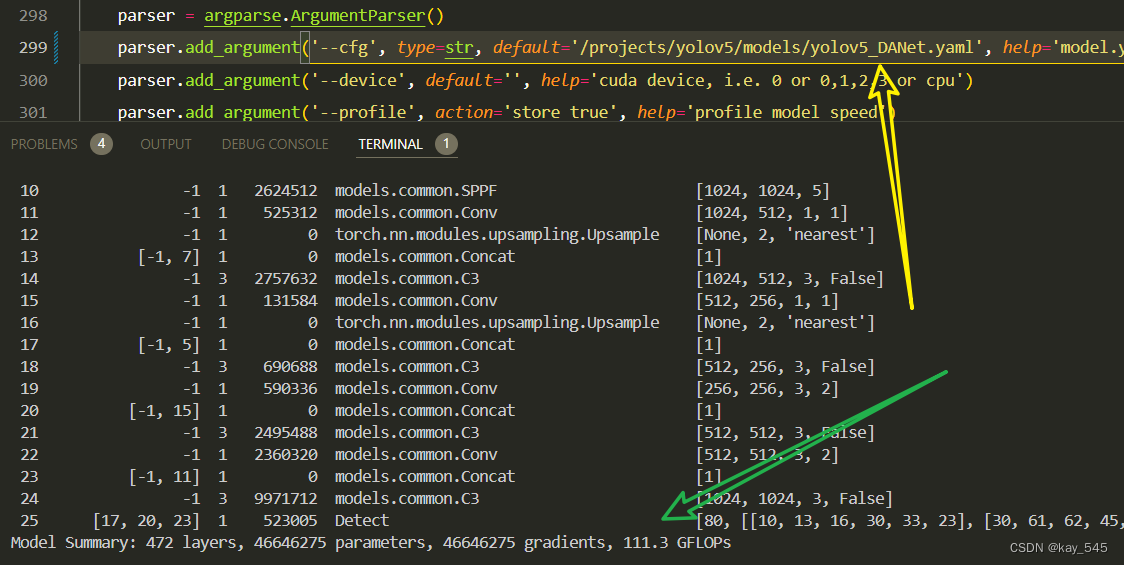
4.GFLOPs
关于GFLOPs的计算方式可以查看:百面算法工程师 | 卷积基础知识——Convolution
未改进的GFLOPs
改进后的GFLOPs
5. 进阶
你能在不同的位置添加双重注意力机制吗?这非常有趣,快去试试吧
6. 总结
双重注意力网络是一种用于计算机视觉任务的神经网络架构,旨在通过注意力机制有效地捕获图像中的全局和局部信息,从而提高任务性能。该网络引入了两个关键的注意力模块,分别用于全局和局部信息的关注,全局模块通过全局池化操作学习图像的整体语义结构,而局部模块则专注于提取图像的局部特征并通过局部感知机制选择最相关的信息。这两个模块学习到的特征最终被融合起来以供任务使用,通常通过连接或加权求和的方式进行特征融合。双重注意力网络通过端到端的训练和优化,使用适当的损失函数和正则化技术来提高模型的泛化能力和训练稳定性。这种架构使得神经网络能够更全面地利用图像中的全局和局部信息,从而在各种计算机视觉任务中取得更好的性能表现。
相关文章:
YOLOv5改进 | 注意力机制 | 添加双重注意力机制 DoubleAttention【附代码/涨点能手】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 在图像识别中,学习捕捉长距离关系是基础。现有的CNN模型通常通过增加深度来建立这种关系,但这种形式效率极低。因此&…...

自用网站合集
总览 线上工具-图片压缩 TinyPNG线上工具-url参数解析 线上工具-MOV转GIF UI-Vant微信小程序版本其他-敏捷开发工具 Leangoo领歌 工具 线上工具-图片压缩 TinyPNG 不能超过5m,别的没啥缺点 线上工具-url参数解析 我基本上只用url参数解析一些常用的操作在线…...

【Golang】gin框架如何在中间件中捕获响应并修改后返回
【Golang】gin框架如何在中间件中捕获响应并修改后返回 本文讲述如何捕获中间件响应以及重写响应如果想在中间件中记录响应日志等操作,我们该如何获取响应数据呢?假如需要统一对响应数据做加密,如何修改这个返回数据再响应给客户端呢…...

电脑同时配置两个版本mysql数据库常见问题
1.配置时,要把bin中的mysql.exe和mysqld.exe 改个名字,不然两个版本会重复,当然,在初始化数据库的时候,如果时57版本的,就用mysql57(已经改名的)和mysqld57 代替 mysql 和 mysqld 例如 mysql -u root -p …...
Java | Leetcode Java题解之第112题路径总和
题目: 题解: class Solution {public boolean hasPathSum(TreeNode root, int sum) {if (root null) {return false;}if (root.left null && root.right null) {return sum root.val;}return hasPathSum(root.left, sum - root.val) || has…...
HaloDB 的 Oracle 兼容模式
↑ 关注“少安事务所”公众号,欢迎⭐收藏,不错过精彩内容~ 前倾回顾 前面介绍了“光环”数据库的基本情况和安装办法。 哈喽,国产数据库!Halo DB! 三步走,Halo DB 安装指引 ★ HaloDB是基于原生PG打造的新一代高性能安…...

【Python】解决Python报错:TypeError: ‘xxx‘ object does not support item assignment
🧑 博主简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向…...
Spring-注解
Spring 注解分类 Spring 注解驱动模型 Spring 元注解 Documented Retention() Target() // 可以继承相关的属性 Inherited Repeatable()Spirng 模式注解 ComponentScan 原理 ClassPathScanningCandidateComponentProvider#findCandidateComponents public Set<BeanDefin…...

旧手机翻身成为办公利器——PalmDock的介绍也使用
旧手机有吧!!! 破电脑有吧!!! 那恭喜你,这篇文章可能对你有点用了。 介绍 这是一个旧手机废物利用变成工作利器的软件。可以在 Android 手机上快捷打开 windows 上的文件夹、文件、程序、命…...

期货交易的雷区
一、做自己看不懂的行情做交易计划一样要做有把握的,倘若你在盘中找机会交易,做自己看不懂的行情,即便你做进去了,建仓时也不会那么肯定,自然而然持仓也不自信,有点盈利就想平仓,亏损又想扛单。…...

东方通TongWeb结合Spring-Boot使用
一、概述 信创需要; 原状:原来的服务使用springboot框架,自带的web容器是tomcat,打成jar包启动; 需求:使用东方通tongweb来替换tomcat容器; 二、替换步骤 2.1 准备 获取到TongWeb7.0.E.6_P7嵌入版 这个文件,文件内容有相关对应的依赖包,可以根据需要来安装到本地…...
6.S081的Lab学习——Lab5: xv6 lazy page allocation
文章目录 前言一、Eliminate allocation from sbrk() (easy)解析: 二、Lazy allocation (moderate)解析: 三、Lazytests and Usertests (moderate)解析: 总结 前言 一个本硕双非的小菜鸡,备战24年秋招。打算尝试6.S081࿰…...
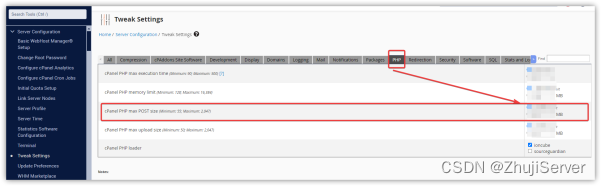
在WHM中如何调整max_post_size参数大小
今日我们在搭建新网站时需要调整一下PHP参数max_post_size 的大小,我们公司使用的Hostease的美国独立服务器产品默认5个IP地址,也购买了cPanel面板,因此联系Hostease的技术支持,寻求帮助了解到如何在WHM中调整PHP参数,…...

智能监控技术助力山林生态养鸡:打造智慧安全的养殖新模式
随着现代科技的不断发展,智能化、自动化的养殖方式逐渐受到广大养殖户的青睐。特别是在山林生态养鸡领域,智能化监控方案的引入不仅提高了养殖效率,更有助于保障鸡只的健康与安全。视频监控系统EasyCVR视频汇聚/安防监控视频管理平台在山林生…...

那些不起眼但很好玩的API合辑
那些不起眼但很好玩的API,为我们带来了许多出人意料的乐趣和惊喜。这些API可能看起来并不起眼,但它们却蕴含着无限的创意和趣味性。它们可以是一些小游戏API,让我们可以在闲暇时刻尽情娱乐;也可以是一些奇特的音乐API,…...

java —— 克隆对象、枚举
一、克隆对象 (一)在基本数据类型中,直接将对象 A 的值赋给对象 B,当更改对象 B 的时候,对象 A 的值保持不变。例如: public static void main(String[] args) {int a5;int ba; //将…...
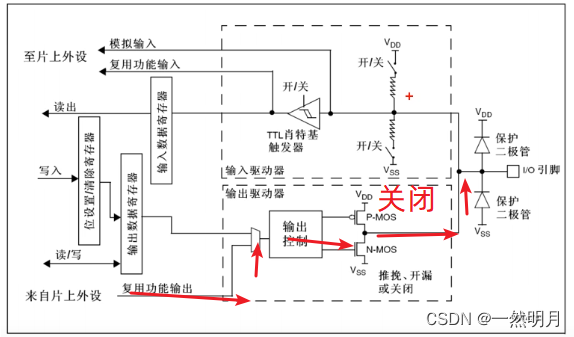
STM32-GPIO八种输入输出模式
图片取自 江协科技 STM32入门教程-2023版 细致讲解 中文字幕 p5 【STM32入门教程-2023版 细致讲解 中文字幕】 https://www.bilibili.com/video/BV1th411z7sn/?p5&share_sourcecopy_web&vd_source327265f5c70f26411a53a9226af0b35c 目录 编辑 一.STM32的四种输…...
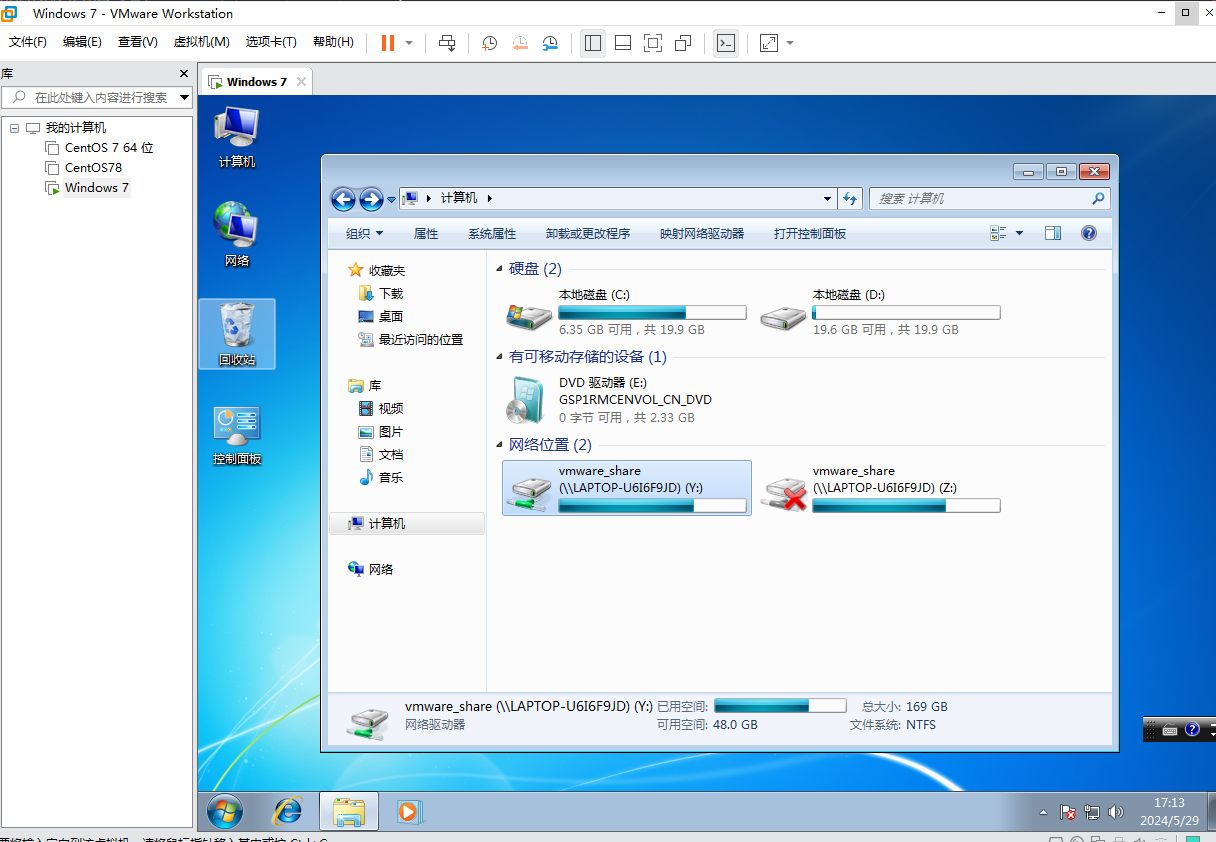
windows镜像虚拟机创建共享文件夹详细步骤 -- 和本地电脑传输文件
第一步:关闭客户机 第二步:右击“虚拟机名称”或菜单栏的“虚拟机”–>“设置” 网络适配器选择NAT或者其他的都可以 来到“选项”,启用共享文件夹,具体如下图:点击添加,添加主机文件夹。然后确定 第三步…...

通关!游戏设计之道Day18
过场动画,或者说根本没人看的东西 过场动画是一系列的动画或实时的动作序列,用来推进剧情制造大场面,烘托气氛,展示对话和角色成长,以及显现在某些情况下被玩家忽略的相关线索。 过场动画是一把双刃剑,一方…...

写Python时不用import,你会遭遇什么
from *** import *** 想必你已经再熟悉不过这样的python语法。 当你的 python 代码需要获取外部的一些功能(一些已经造好的轮子),你就需要使用到 import 这个声明关键字。import可以协助导入其他 module 。(类似 C 预约的 inclu…...

Qdrant 如何配置 API Key 认证
Qdrant 如何配置 API Key 认证 Qdrant 是当下最流行的向量数据库之一,广泛应用于 RAG(检索增强生成)、相似度搜索、AI 应用等场景。生产环境中,API Key 认证是保障数据安全的基本手段。本文详细介绍 Qdrant 的 API Key 配置方法&a…...

爆单实操课:从3C到美妆,跨境商家如何用AI神器搞定TikTok本土化
每天都有无数跨境卖家在各大社群里发问:怎么用ai生成带货视频,有哪些工具比较好用? 在 TikTok 这个极度依赖内容爆发的平台上,不同类目的产品对视频素材的需求千差万别。靠人工剪辑不仅效率低,且极难跨越本土化语言的障…...

一键获取国家中小学智慧教育平台电子课本:开源解析工具完全指南
一键获取国家中小学智慧教育平台电子课本:开源解析工具完全指南 【免费下载链接】tchMaterial-parser 国家中小学智慧教育平台 电子课本下载工具,帮助您从智慧教育平台中获取电子课本的 PDF 文件网址并进行下载,让您更方便地获取课本内容。 …...

如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题
如何高效使用炉石传说脚本:终极完整指南解决你的自动化难题 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 你是否厌倦了炉石传说中重复性的…...

SpringBoot项目启动报错Could not resolve placeholder?别慌,这10种排查思路总有一种能帮你搞定
SpringBoot配置占位符解析失败的10种深度排查策略 当你正沉浸在SpringBoot项目的开发中,突然控制台抛出那行刺眼的红色错误——"Could not resolve placeholder xxx in value ${xxx}",这种场景对于Java开发者来说再熟悉不过。这个看似简单的报…...

纯Java实现Gemma大模型推理:在JVM中部署轻量级AI的工程实践
1. 项目概述:当Gemma遇上Java,一个轻量级AI推理的新选择最近在开源社区里,一个名为mukel/gemma4.java的项目引起了我的注意。作为一名长期在Java生态和机器学习边缘部署领域摸爬滚打的开发者,看到这个标题的第一反应是:…...

Steam SDK上传游戏包体避坑指南:路径、验证码与BuildID那些事儿
Steam SDK上传游戏包体避坑指南:路径、验证码与BuildID那些事儿 第一次通过Steam SDK上传游戏包体时,开发者往往会遇到各种意料之外的"坑"。这些看似小问题却可能导致数小时的无效排查。本文将从实战角度,分享那些官方文档没细说但…...

LibreHardwareMonitor:你的电脑健康管家,硬件监控从此无忧
LibreHardwareMonitor:你的电脑健康管家,硬件监控从此无忧 【免费下载链接】LibreHardwareMonitor Libre Hardware Monitor is free software that can monitor the temperature sensors, fan speeds, voltages, load and clock speeds of your computer…...

深度重构黑苹果系统架构:OpenCore实战解析与性能优化
深度重构黑苹果系统架构:OpenCore实战解析与性能优化 【免费下载链接】Hackintosh 国光的黑苹果安装教程:手把手教你配置 OpenCore 项目地址: https://gitcode.com/gh_mirrors/hac/Hackintosh 在传统PC硬件与macOS系统兼容性的技术探索中…...

VMware Workstation Pro 17免费激活实战:5分钟解锁专业虚拟化
VMware Workstation Pro 17免费激活实战:5分钟解锁专业虚拟化 【免费下载链接】VMware-Workstation-Pro-17-Licence-Keys Free VMware Workstation Pro 17 full license keys. Weve meticulously organized thousands of keys, catering to all major versions of V…...