Python Selenium 详解:实现高效的UI自动化测试

落日余辉,深情不及久伴。大家好,在当今软件开发的世界中,自动化测试已经成为保障软件质量和快速迭代的重要环节。而在自动化测试的领域中,UI自动化测试是不可或缺的一部分,它可以帮助测试团队快速验证用户界面的正确性和功能性。
然而,UI自动化测试也面临着许多挑战,比如复杂的页面结构、动态加载的内容、不稳定的元素定位等等。为了有效应对这些挑战,测试人员需要借助强大的工具和框架。在这方面,Python与Selenium的结合成为了一种常见且强大的选择。
本文将深入探讨Python和Selenium在UI自动化测试中的应用。我们将从基础开始,介绍Python和Selenium的安装和设置,然后逐步深入到各种功能和技巧。我们将通过丰富的示例代码和详细的解释,帮助测试人员更好地理解和利用这些工具,从而实现高效、稳定的UI自动化测试。
一、Python和Selenium介绍
1、Python
Python是一种高级编程语言,以其简单易学、功能强大和丰富的生态系统而闻名。由于其简洁的语法和广泛的应用领域,Python已经成为了软件开发、数据科学、人工智能等领域的首选语言之一。Python具有丰富的第三方库和工具,可用于各种用途,包括网络开发、数据分析、自动化测试等。
2、Selenium
Selenium是一个用于自动化Web应用程序测试的工具。它提供了一组工具和API,使开发人员能够模拟用户在Web浏览器中的操作,如点击按钮、输入文本、提交表单等。Selenium最初是为Web开发人员设计的,但随着时间的推移,它成为了自动化测试领域的标准之一。
3、Python和Selenium的问题解决
Python和Selenium的结合解决了UI自动化测试中的许多挑战和问题。在传统的手动测试中,测试人员需要反复进行相同的操作,这样既费时又容易出错。而通过使用Python编写Selenium脚本,可以自动化执行这些操作,从而提高测试效率、减少人为错误,并且可以在短时间内快速验证大量的测试用例。
4、安装Selenium
在命令行中运行以下命令来安装Selenium:
pip install selenium
5、下载WebDriver
Selenium需要与浏览器驱动程序(WebDriver)一起使用,以便模拟用户在浏览器中的操作。需要根据要测试的浏览器类型下载相应的WebDriver。例如,如果要测试Chrome浏览器,可以下载ChromeDriver;如果要测试Firefox浏览器,可以下载geckodriver。将WebDriver下载并将其添加到系统路径中,以便Selenium能够找到它。
Chrome WebDriver下载地址(浏览器版本114之前):
https://chromedriver.storage.googleapis.com/index.html
Chrome WebDriver下载地址(浏览器版本123以后):
Chrome for Testing availability
Firefox GeckoDriver下载地址:
https://github.com/mozilla/geckodriver/releases
下载完成后,需要将驱动文件设置在环境变量中,如果是linux系统,可以参考下面文章。
在Linux上使用Selenium驱动Chrome浏览器无头模式
二、第一个Selenium脚本
当准备好开始编写您的第一个Selenium脚本时,您需要确保已经按照前面提到的步骤安装了Python、Selenium和适当的浏览器驱动程序。现在,让我们编写一个简单的脚本来打开一个网页:
# 导入Selenium库中的webdriver模块
from selenium import webdriver# 创建一个浏览器对象,这里我们选择Chrome浏览器,也可以选择其他浏览器
driver = webdriver.Chrome()# 打开一个网页,这里以百度为例
driver.get("https://www.baidu.com")# 在网页上查找一个元素,例如百度的搜索框
search_box = driver.find_element_by_name("wd")# 在搜索框中输入关键词
search_box.send_keys("Python Selenium")# 提交搜索
search_box.submit()# 等待一段时间,让搜索结果加载完成(这里使用隐式等待,等待最多10秒)
driver.implicitly_wait(10)# 打印当前网页的标题
print("网页标题:", driver.title)# 关闭浏览器
driver.quit()
解释一下这个简单的脚本:
-
首先,我们导入了Selenium库中的webdriver模块,它包含了浏览器的各种操作功能。
-
接着,我们创建了一个WebDriver对象,这里我们选择了Chrome浏览器,并将其赋值给
driver变量。 -
然后,我们使用
get()方法打开了一个网页,这里我们选择了百度搜索首页。 -
接下来,我们使用
find_element_by_name()方法找到了百度搜索框的元素,并将其赋值给search_box变量。 -
我们使用
send_keys()方法在搜索框中输入了关键词“Python Selenium”。 -
然后,我们调用了
submit()方法,提交了搜索请求。 -
使用
implicitly_wait()方法设置了隐式等待,等待搜索结果加载完成,最多等待10秒。 -
最后,我们打印了当前网页的标题,然后调用了
quit()方法关闭了浏览器。
三、元素定位
元素定位是Selenium中的一个重要概念,它指的是在网页上找到需要操作的元素的过程。在Selenium中,有多种元素定位方法可供选择,每种方法都有其特点和适用场景。
下面我们将详细介绍几种常用的元素定位方法:
1、通过ID定位
通过ID定位是Selenium中最常用的一种定位方法之一,因为ID是HTML元素的唯一标识符,每个元素都应该具有唯一的ID。因此,通过ID定位是一种快速有效的定位方法。
使用find_element_by_id()方法来通过元素的ID定位元素,其基本语法如下:
element = driver.find_element_by_id("element_id")
其中,element_id是要定位元素的ID值。
通过ID定位的示例:
假设我们有以下HTML代码:
<div id="login_form"><input type="text" id="username" name="username" placeholder="请输入用户名"><input type="password" id="password" name="password" placeholder="请输入密码"><button type="submit" id="login_button">登录</button>
</div>
我们可以使用Selenium通过ID定位用户名输入框,其ID为username,示例代码如下:
username_input = driver.find_element_by_id("username")
同样地,我们可以使用ID定位登录按钮,其ID为login_button,示例代码如下:
login_button = driver.find_element_by_id("login_button")
注意事项:
-
确保元素具有唯一的ID:ID在HTML中应该是唯一的,如果有多个元素具有相同的ID,则会导致定位失败或定位到错误的元素。
-
ID定位是一种高效的定位方法:由于ID是唯一标识符,因此使用ID定位通常比其他定位方法更快速有效。
2、通过类名定位
通过类名定位是Selenium中常用的一种定位方法,特别适用于那些具有相同class属性的元素。在HTML中,一个元素可以拥有一个或多个class属性,每个class属性可以包含一个或多个类名,类名之间用空格分隔。通过类名定位的基本思想是根据元素的class属性值来定位元素。
使用find_element_by_class_name()方法来通过元素的类名定位元素,其基本语法如下:
element = driver.find_element_by_class_name("class_name")
其中,class_name是要定位元素的类名。
通过类名定位的示例:
假设我们有以下HTML代码:
<div class="login-form"><input type="text" class="username-input" name="username" placeholder="请输入用户名"><input type="password" class="password-input" name="password" placeholder="请输入密码"><button type="submit" class="login-button">登录</button>
</div>
我们可以使用Selenium通过类名定位用户名输入框,其类名为username-input,示例代码如下:
username_input = driver.find_element_by_class_name("username-input")
同样地,我们可以使用类名定位登录按钮,其类名为login-button,示例代码如下:
login_button = driver.find_element_by_class_name("login-button")
注意事项:
-
类名定位仅适用于单一类名:如果元素有多个类名,而您只知道其中一个类名,那么只能通过该类名来定位元素,无法同时使用多个类名来定位。
-
类名定位不适用于复合类名:如果元素的class属性值包含了多个类名,例如
class="class1 class2 class3",那么类名定位将不适用,需要使用其他定位方法,如CSS选择器或XPath。
3、通过标签名定位
通过标签名定位是Selenium中一种简单而常用的定位方法,它通过元素的标签名来定位元素。在HTML文档中,每个元素都有一个标签名,例如<div>、<input>、<a>等,通过标签名定位可以方便地找到页面上所有具有相同标签名的元素。
使用find_element_by_tag_name()方法来通过元素的标签名定位元素,其基本语法如下:
element = driver.find_element_by_tag_name("tag_name")
其中,tag_name是要定位元素的标签名。
通过标签名定位的示例:
假设我们有以下HTML代码:
<div class="login-form"><input type="text" name="username" placeholder="请输入用户名"><input type="password" name="password" placeholder="请输入密码"><button type="submit">登录</button>
</div>
我们可以使用Selenium通过标签名定位用户名输入框,其标签名为input,示例代码如下:
username_input = driver.find_element_by_tag_name("input")
注意,这将返回页面上第一个<input>标签元素,如果有多个<input>标签元素,将只定位到第一个。
注意事项:
-
标签名定位返回第一个匹配的元素:如果页面上有多个相同标签名的元素,那么标签名定位将返回第一个匹配的元素,如果需要定位到其他匹配的元素,可以使用其他定位方法或结合使用定位方法来定位。
-
标签名定位适用于通用元素:标签名定位适用于那些没有唯一属性(如ID、类名)的通用元素,但对于具有唯一属性的元素,建议使用更精确的定位方法,以提高定位的准确性和稳定性。
4、通过名称定位
通过名称定位是Selenium中常用的一种定位方法,特别适用于那些具有name属性的元素。在HTML中,一个元素可以具有一个name属性,通过该属性可以为元素指定名称。通过名称定位的基本思想是根据元素的name属性值来定位元素。
使用find_element_by_name()方法来通过元素的名称定位元素,其基本语法如下:
element = driver.find_element_by_name("element_name")
其中,element_name是要定位元素的名称。
通过名称定位的示例:
假设我们有以下HTML代码:
<form id="login_form"><input type="text" name="username" placeholder="请输入用户名"><input type="password" name="password" placeholder="请输入密码"><button type="submit">登录</button>
</form>
我们可以使用Selenium通过名称定位用户名输入框,其名称为username,示例代码如下:
username_input = driver.find_element_by_name("username")
同样地,我们可以使用名称定位密码输入框,其名称为password,示例代码如下:
password_input = driver.find_element_by_name("password")
注意事项:
-
名称定位仅适用于单一名称:如果元素有多个name属性,而您只知道其中一个名称,那么只能通过该名称来定位元素,无法同时使用多个名称来定位。
-
名称定位不适用于没有name属性的元素:如果元素没有name属性,那么名称定位将不适用,需要使用其他定位方法,如ID、类名、标签名等。
5、通过链接文本定位
通过链接文本定位是Selenium中常用的一种定位方法,特别适用于那些由<a>标签表示的链接元素。在HTML中,链接元素通常用<a>标签表示,其中的文本内容即为链接文本。通过链接文本定位的基本思想是根据链接文本来定位链接元素。
使用find_element_by_link_text()方法来通过链接文本定位元素,其基本语法如下:
element = driver.find_element_by_link_text("Link Text")
其中,Link Text是要定位的链接文本。
通过链接文本定位的示例:
假设我们有以下HTML代码:
<a href="https://www.example.com">Example Link</a>
我们可以使用Selenium通过链接文本定位链接元素,其链接文本为Example Link,示例代码如下:
example_link = driver.find_element_by_link_text("Example Link")
注意事项:
-
链接文本定位匹配完整文本:使用链接文本定位时,Selenium会精确匹配指定的文本内容,因此必须确保文本内容与页面上显示的完全一致,包括大小写和空白字符。
-
链接文本定位不适用于部分文本:如果需要匹配部分文本,可以考虑使用部分链接文本定位方法,后面会介绍。
6、通过部分链接文本定位
通过部分链接文本定位是Selenium中常用的一种定位方法,特别适用于那些链接文本太长或不完整的情况。有时候,页面上的链接文本可能过长,或者只需要匹配部分文本来定位链接元素。通过部分链接文本定位的基本思想是根据链接文本的部分内容来定位链接元素。
使用find_element_by_partial_link_text()方法来通过部分链接文本定位元素,其基本语法如下:
element = driver.find_element_by_partial_link_text("Partial Link Text")
其中,Partial Link Text是要定位的部分链接文本。
通过部分链接文本定位的示例:
假设我们有以下HTML代码:
<a href="https://www.example.com">Example Link</a>
我们可以使用Selenium通过部分链接文本定位链接元素,其链接文本为Example,示例代码如下:
example_link = driver.find_element_by_partial_link_text("Example")
注意,这将匹配所有包含Example的链接文本,不论它们位于链接文本的什么位置。
注意事项:
-
部分链接文本定位匹配包含指定文本的所有链接:使用部分链接文本定位时,Selenium会匹配包含指定文本的所有链接文本,因此可能匹配到多个链接元素。
-
部分链接文本定位可能不唯一:如果页面上存在多个包含相同部分文本的链接,部分链接文本定位可能不唯一,需要结合其他定位方法来定位唯一的元素。
7、通过XPath定位
XPath(XML Path Language)是一种用于定位XML文档中节点的语言,它在Selenium中被广泛用于定位Web页面上的元素。XPath通过节点的层级关系或属性来定位元素,具有很强的灵活性和表达能力。
XPath有两种类型:绝对路径和相对路径。
-
绝对路径: 绝对路径从文档的根节点开始,描述了从根节点到目标节点的完整路径。它以斜杠(/)开头,例如:
/html/body/div[1]/input[1] -
相对路径: 相对路径不从根节点开始,而是从当前节点开始,描述了从当前节点到目标节点的路径。它以双斜杠(//)开头,例如:
//input[@id='username']
XPath的常用语法:
-
节点名称: 使用节点名称来定位元素,例如:
//input -
属性定位: 使用节点的属性来定位元素,例如:
//input[@id='username'] -
索引定位: 使用索引号来定位元素,例如:
//div[1]/input[2] -
逻辑运算符: 使用逻辑运算符(and、or)来组合多个条件,例如:
//input[@id='username' and @name='user'] -
文本内容: 使用元素的文本内容来定位元素,例如:
//a[text()='Next'] -
模糊匹配: 使用
contains()函数进行模糊匹配,例如://input[contains(@class, 'form-control')] -
父子关系: 使用斜杠(/)表示父子关系,例如:
//div[@id='parent']/input[@name='child']
下面是一个示例,演示如何使用XPath来定位一个元素:
假设我们有以下HTML代码:
<html><body><div id="container"><input type="text" id="username" name="username" placeholder="请输入用户名"><input type="password" id="password" name="password" placeholder="请输入密码"><button type="submit">登录</button></div></body>
</html>
我们可以使用XPath来定位用户名输入框,其XPath表达式为://input[@id='username']
然后,我们可以使用Selenium的find_element_by_xpath()方法来定位该元素:
element = driver.find_element_by_xpath("//input[@id='username']")
这样就能够成功定位到用户名输入框了。
8、通过CSS选择器定位
通过CSS选择器定位是Selenium中常用的一种定位方法,它利用元素的CSS属性来定位元素,具有灵活性和强大的定位能力。CSS选择器可以根据元素的标签名、类名、ID、属性等来定位元素,支持多种选择器语法,包括标签选择器、类选择器、ID选择器、属性选择器、层级选择器等。
使用find_element_by_css_selector()方法来通过CSS选择器定位元素,其基本语法如下:
element = driver.find_element_by_css_selector("css_selector")
其中,css_selector是要定位元素的CSS选择器。
通过CSS选择器定位的示例:
假设我们有以下HTML代码:
<div id="login_form" class="form-container"><input type="text" id="username" name="username" placeholder="请输入用户名"><input type="password" id="password" name="password" placeholder="请输入密码"><button type="submit" class="login-button">登录</button>
</div>
我们可以使用Selenium通过CSS选择器定位用户名输入框,其ID为username,示例代码如下:
username_input = driver.find_element_by_css_selector("#username")
我们也可以使用CSS选择器定位登录按钮,其类名为login-button,示例代码如下:
login_button = driver.find_element_by_css_selector(".login-button")
CSS选择器的常见语法:
- 标签选择器: 使用标签名定位元素,例如:
div、input。 - 类选择器: 使用类名定位元素,以点号
.开头,例如:.login-button。 - ID选择器: 使用ID定位元素,以井号
#开头,例如:#username。 - 属性选择器: 使用元素的属性来定位元素,例如:
input[type='text']。 - 层级选择器: 使用元素的层级关系来定位元素,例如:
div.container input[type='text']。
注意事项:
- CSS选择器定位可以使用多种选择器语法,根据需要选择合适的选择器。
- CSS选择器定位相比其他定位方法更加灵活,但在编写选择器时要确保选择器的准确性和唯一性,以避免定位到错误的元素。
9、定位一组元素
在 Selenium 中,可以使用多种方法来定位一组元素。find_elements_by_xxx() 方法是Selenium中用于定位一组元素的方法之一,它与 find_element_by_xxx() 方法类似,但是返回的是一个元素列表,而不是单个元素。这意味着它可以定位页面上匹配给定条件的所有元素,而不仅仅是第一个匹配的元素。可以使用各种定位方法来定位一组元素,如通过ID、类名、标签名、XPath、CSS选择器等。
下面是一些常用的方法:
- find_elements_by_xpath(xpath):通过 XPath 表达式定位一组元素。
- find_elements_by_css_selector(selector):通过 CSS 选择器定位一组元素。
- find_elements_by_id(id):通过元素的 id 属性定位一组元素。
- find_elements_by_class_name(class_name):通过元素的 class 属性定位一组元素。
- find_elements_by_tag_name(tag_name):通过元素的标签名定位一组元素。
- find_elements_by_name(name):通过元素的 name 属性定位一组元素。
- find_elements_by_link_text(link_text):通过链接文本定位一组链接元素。
- find_elements_by_partial_link_text(partial_link_text):通过部分链接文本定位一组链接元素。
一旦找到了一组元素,可以对其进行遍历,或者使用索引来访问特定的元素。例如:
for element in elements:# 对每个元素执行操作pass# 访问第一个元素
first_element = elements[0]# 访问最后一个元素
last_element = elements[-1]
五、模拟用户操作
当使用 Selenium 模拟用户操作时,主要目标是使自动化测试尽可能地模拟真实用户的行为。这包括点击按钮、填写表单、上传文件等常见的操作。下面是一些常见用户操作的示例以及如何使用 Selenium 进行模拟:
1、点击按钮
使用 click() 方法来模拟点击按钮。
button = driver.find_element_by_id("button_id")
button.click()
2、填写表单
使用 send_keys() 方法来填写表单字段。
input_field = driver.find_element_by_id("input_field_id")
input_field.send_keys("Input value")
3、上传文件
使用 send_keys() 方法来模拟文件上传操作。
file_input = driver.find_element_by_id("file_input_id")
file_input.send_keys("/path/to/file")
这里,/path/to/file 是想要上传的文件的路径。
4、下拉框选择
对于下拉框(select),可以使用 Select 类来模拟选择操作。
from selenium.webdriver.support.ui import Selectselect_element = driver.find_element_by_id("select_id")
select = Select(select_element)
select.select_by_visible_text("Option text")
这里的 "Option text" 是下拉框中选项的可见文本。
5、鼠标操作
在某些情况下,需要模拟鼠标操作,比如悬停或双击。可以使用 ActionChains 类来实现这些操作。
from selenium.webdriver.common.action_chains import ActionChainselement_to_hover_over = driver.find_element_by_id("element_id")
ActionChains(driver).move_to_element(element_to_hover_over).perform()
这个例子演示了如何悬停在一个元素上。
六、处理动态内容
处理动态内容是 UI 自动化测试中至关重要的一部分,特别是当页面通过 JavaScript 动态加载内容时。在 Selenium 中,你可以使用不同的等待机制来处理这些情况,确保测试脚本在正确的时机执行操作。
1、等待页面加载完成
有时页面上的某些元素可能需要一段时间才能加载完成。在这种情况下,你可以使用隐式等待或显式等待来等待页面加载完成。
(1)隐式等待:
driver.implicitly_wait(10) # 等待最多10秒钟
这将使 WebDriver 在查找元素时等待一段时间,直到元素出现或超时为止。
(2)显式等待:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECelement = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "element_id"))
)
这个例子将等待最多10秒钟,直到页面上具有指定 ID 的元素出现。
(3)处理元素可见:
有时元素虽然存在于 DOM 中,但可能不可见或不可交互。在这种情况下,你可以等待元素可见或可交互,然后执行相应的操作。
等待元素可见
element = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "element_id"))
)
这个例子将等待最多10秒钟,直到页面上具有指定 ID 的元素可见。
等待元素可交互
element = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "element_id"))
)
这个例子将等待最多10秒钟,直到页面上具有指定 ID 的元素可交互(即可被点击)。
处理异步加载内容
有时页面上的内容是通过异步加载的,例如通过 AJAX 请求。在这种情况下,你需要等待特定的条件来确保内容已经加载完成。
element = WebDriverWait(driver, 10).until(lambda driver: driver.execute_script("return jQuery.active == 0")
)
这个例子将等待最多10秒钟,直到页面上没有活动的 jQuery AJAX 请求。
七、数据驱动测试
数据驱动测试是一种测试方法,其中测试用例的输入数据和预期结果从外部数据源加载,而不是硬编码在测试脚本中。这种方法使得测试更灵活、可维护性更高,因为可以轻松地修改输入数据或添加新的测试用例,而无需修改测试脚本本身。
1、使用外部数据源驱动测试用例
在这种方法中,通常会将测试数据存储在外部文件中,如 Excel、CSV 文件或数据库。然后,测试脚本会读取这些文件中的数据,并将其用于执行测试用例。
假设我们有一个 CSV 文件 testdata.csv,其中包含测试数据,格式如下:
username,password
user1,password1
user2,password2
我们可以使用 Python 的 csv 模块来读取这个文件,并在测试中使用其中的数据。
import csv# 读取 CSV 文件
with open('testdata.csv', 'r') as file:reader = csv.DictReader(file)for row in reader:username = row['username']password = row['password']# 在这里执行测试用例,使用 username 和 password 变量作为输入数据
假设我们有一个 Excel 文件 testdata.xlsx,其中包含测试数据,格式如下:
| username | password |
|----------|-----------|
| user1 | password1 |
| user2 | password2 |
我们可以使用 Python 的 openpyxl 或 xlrd 等库来读取这个 Excel 文件,并在测试中使用其中的数据。
import openpyxl# 读取 Excel 文件
workbook = openpyxl.load_workbook('testdata.xlsx')
sheet = workbook.active
for row in sheet.iter_rows(min_row=2, values_only=True):username = row[0]password = row[1]# 在这里执行测试用例,使用 username 和 password 变量作为输入数据
2、动态地生成测试数据
有时候,测试需要使用动态生成的测试数据。Python 提供了许多库来生成测试数据,如 Faker、faker、mimesis 等。
使用 Faker 库生成测试数据示例:
from faker import Fakerfake = Faker()# 生成随机的用户名和密码
username = fake.user_name()
password = fake.password()
# 在这里执行测试用例,使用生成的 username 和 password 变量作为输入数据
这样,我们就可以通过外部数据源或动态生成的方式来驱动测试用例,使得测试更加灵活和可维护。
八、测试报告
生成详细的测试报告对于分析测试结果、发现问题并改进测试流程至关重要。在 Python Selenium 中,可以使用各种测试报告生成工具来生成报告,例如 unittest、pytest、HTMLTestRunner 等。下面是如何使用 pytest 和 pytest-html 来生成详细的测试报告的示例:
1、安装 pytest 和 pytest-html
pip install pytest pytest-html
关于Pytest的使用,可以参考:
Pytest自动化测试框架详解
2、编写测试用例
编写测试用例并使用 pytest 的装饰器 @pytest.mark.parametrize 来传递测试数据。
import pytest
from selenium import webdriver@pytest.mark.parametrize("username, password", [("user1", "password1"), ("user2", "password2")])
def test_login(username, password):driver = webdriver.Chrome()driver.get("http://example.com/login")driver.find_element_by_id("username").send_keys(username)driver.find_element_by_id("password").send_keys(password)driver.find_element_by_id("login_button").click()assert "Welcome" in driver.titledriver.quit()
3、运行测试并生成报告
使用 pytest 命令运行测试,并使用 --html 选项生成 HTML 格式的测试报告。
pytest --html=report.html
这将生成一个名为 report.html 的测试报告文件,其中包含了测试的详细结果、测试用例的执行情况、失败的断言等信息。
九、实践和技巧
当进行 Python Selenium UI 自动化测试时,有一些最佳实践和技巧可以帮助你编写更加稳健、可维护和可扩展的测试脚本。下面是一些常见的实用技巧:
1、隐式等待和显式等待
隐式等待(Implicit Waits): 设置一个全局的等待时间,使得 WebDriver 在查找元素时等待一段时间,直到元素出现或超时为止。
driver.implicitly_wait(10) # 等待最多10秒钟
显式等待(Explicit Waits): 显式等待允许在特定条件下等待元素的出现、可见性、可点击等,可以使测试更加精确和稳健。
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECelement = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.ID, "element_id"))
)
2、页面对象模型(Page Object Model,POM)
使用页面对象模型将页面的元素和操作封装到单独的页面对象类中,使测试脚本更加模块化、可读性更高,降低了测试维护的难度。
class LoginPage:def __init__(self, driver):self.driver = driverdef login(self, username, password):self.driver.find_element_by_id("username").send_keys(username)self.driver.find_element_by_id("password").send_keys(password)self.driver.find_element_by_id("login_button").click()
# 在测试用例中使用页面对象
login_page = LoginPage(driver)
login_page.login("user1", "password1")
3、使用 CSS 选择器优于 XPath
尽可能使用 CSS 选择器而不是 XPath,因为 CSS 选择器通常比 XPath 执行更快,更简洁,并且更易于阅读和维护。
十、Selenium的常用函数或者方法
Selenium 提供了丰富的函数和方法,用于模拟用户与网页的交互,定位元素,执行操作等。下面是一些 Selenium 中常用的函数和方法:
1、元素定位
find_element(by='id', value=None):根据指定的定位方式和值找到页面上的单个元素。find_elements(by='id', value=None):根据指定的定位方式和值找到页面上的一组元素。find_element_by_id(id):根据元素的 id 属性找到元素。find_element_by_name(name):根据元素的 name 属性找到元素。find_element_by_xpath(xpath):根据 XPath 表达式找到元素。find_element_by_css_selector(css_selector):根据 CSS 选择器找到元素。find_element_by_class_name(class_name):根据元素的 class 属性找到元素。find_element_by_tag_name(tag_name):根据元素的标签名找到元素。
2、元素操作
click():点击元素。send_keys(*value):在输入框中输入文本。clear():清除输入框中的文本。submit():提交表单。get_attribute(name):获取元素的属性值。is_displayed():判断元素是否可见。is_enabled():判断元素是否可用(即是否可以与用户交互)。
3、等待
implicitly_wait(time_to_wait):设置隐式等待时间,全局性地等待一定时间直到元素出现。WebDriverWait(driver, timeout).until(EC.condition()):显式等待,直到指定条件满足或超时。expected_conditions模块提供了多种等待条件,如元素可见、元素存在、元素可点击等。
4、浏览器操作
get(url):打开指定的 URL。back():返回上一个页面。forward():前进到下一个页面。refresh():刷新当前页面。close():关闭当前窗口。quit():退出整个浏览器。
十一、示例
下面是一个简单的示例,演示了如何使用 Python 和 Selenium 进行基本的网页自动化测试。在这个示例中,我们将访问一个测试页面,输入用户名和密码,然后点击登录按钮进行登录,最后验证登录是否成功。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 启动 Chrome 浏览器
driver = webdriver.Chrome()# 打开测试页面
driver.get("http://example.com/login")# 找到用户名和密码输入框,并输入用户名和密码
username_input = driver.find_element_by_id("username")
username_input.send_keys("test_user")password_input = driver.find_element_by_id("password")
password_input.send_keys("test_password")# 点击登录按钮
login_button = driver.find_element_by_id("login_button")
login_button.click()# 等待页面跳转,验证登录是否成功
try:# 等待页面标题包含 "Welcome"WebDriverWait(driver, 10).until(EC.title_contains("Welcome"))print("Login successful!")
except Exception as e:print("Login failed:", e)# 关闭浏览器
driver.quit()
在这个示例中,我们使用了 Selenium 提供的 webdriver.Chrome() 方法来启动 Chrome 浏览器。然后,使用 driver.get() 方法打开测试页面。接着,我们找到用户名和密码输入框,分别输入用户名和密码。然后,通过 find_element_by_id() 方法找到登录按钮,并通过 click() 方法点击登录按钮。最后,我们使用显式等待来等待页面跳转,验证登录是否成功。
我们添加了一个断言,验证页面标题是否包含 "Welcome"。如果页面标题包含 "Welcome",则认为登录成功,否则认为登录失败。如果断言失败,将会打印相应的错误消息。
相关文章:
Python Selenium 详解:实现高效的UI自动化测试
落日余辉,深情不及久伴。大家好,在当今软件开发的世界中,自动化测试已经成为保障软件质量和快速迭代的重要环节。而在自动化测试的领域中,UI自动化测试是不可或缺的一部分,它可以帮助测试团队快速验证用户界面的正确性…...

npm获取yarn在安装依赖时 git://github.com/user/xx.git 无法访问解决方法 -- 使用 insteadOf设置git命令别名
今天在使用一个node项目时突然遇到 一个github的拉取异常,一看协议居然是git://xxx 貌似github早就不用这种格式了, 而是使用的gitgithub.com:xxx 这种或者https协议,解决方法: 使用insteadof设置git别名 url.<base>.inste…...

Centos7网络故障,开机之后连不上网ens33mtu 1500 qdisc noop state DOWN group default qlen 1000
说明 这是Linux系统网络接口的信息,其中"mtu 1500"表示最大传输单元大小为1500字节,“qdisc noop”表示没有设置特殊的队列算法,“state down”表示该接口当前处于关闭状态,“group default”表示该接口属于“default”…...

分析 Base64 编码和 URL 安全 Base64 编码
前言 在处理数据传输和存储时,Base64 编码是一种非常常见的技术。它可以将二进制数据转换为文本格式,便于在文本环境中传输和处理。Go 语言提供了对标准 Base64 编码和 URL 安全 Base64 编码的支持。本文将通过一个示例代码,来分析这两种编码…...

cocos 屏幕点击坐标转换为节点坐标
let scPos event.getLocation(); let camera find(Canvas/Camera).getComponent(Camera).screenToWorld(new Vec3(scPos.x,scPos.y,0));//摄像机 let p this.node.getComponent(UITransform).convertToNodeSpaceAR(camera);//this.node为指定的节点为原点(0,0&…...

电瓶车进电梯识别报警摄像机
随着电动车的普及,越来越多的人选择电动车作为出行工具。在诸多场景中,电梯作为一种常见的交通工具,也受到了电动车用户的青睐。然而,电动车进入电梯时存在一些安全隐患,为了提高电动车进电梯的安全性,可以…...

数据库到服务器提权
数据库提权流程: 1、先获取到数据库用户密码 -网站存在SQL注入漏洞 -数据库的存储文件或备份文件 -网站应用源码中的数据库配置文件 -采用工具或脚本爆破(需解决外联问题) 2、利用数据库提权项目进行连接 MDUT //jkd1.8 启动 Databasetools …...
-表和页压缩(1)-表压缩)
【MySQL精通之路】InnoDB(9)-表和页压缩(1)-表压缩
目录 1.表压缩概述 2.创建压缩表 2.1 在FPT表空间中创建压缩表 2.2 在通用表空间中创建压缩表 2.3 压缩表的限制 3.优化InnoDB表的压缩 4.运行时监控InnoDB表压缩 5.InnoDB表的压缩工作原理 5.1 压缩算法 5.2 InnoDB数据存储和压缩 5.3 B树页面的压缩 5.4 压缩BLOB、…...

【前端】vue+element项目中select下拉框label想要显示多个值多个字段
Vue Element项目中select下拉框label想要显示多个值 <el-selectv-model"form.plantId"collapse-tagsfilterableplaceholder"请选择品种种类"style"width: 270px;"><el-optionv-for"item in plantIdArray":key"item.id&…...
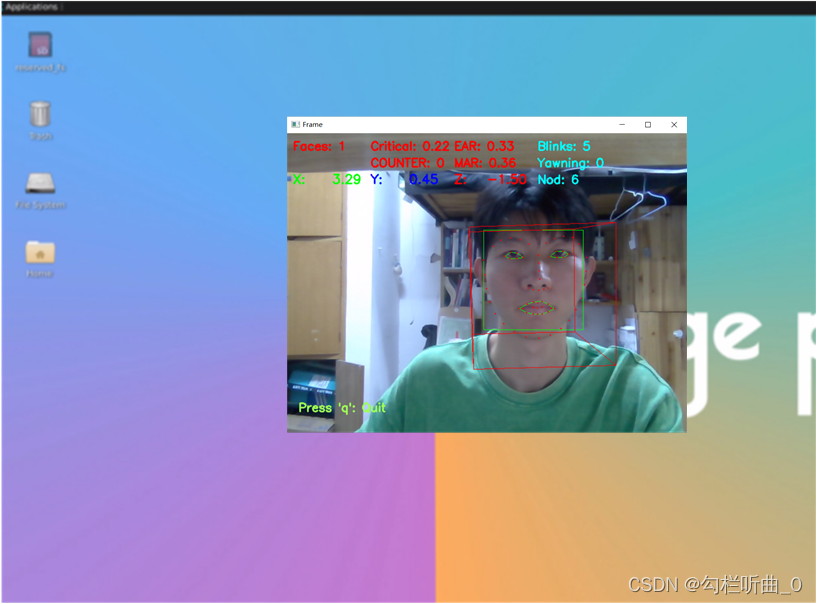
橙派探险记:开箱香橙派 AIpro 与疲劳驾驶检测的奇幻之旅
目录 引子:神秘包裹的到来 第一章:香橙派AIpro初体验 资源与性能介绍 系统烧录 Linux 镜像(TF 卡) 调试模式 登录模式 第二章:大胆的项目构想 系统架构设计 香橙派 AIpro 在项目中的重要作用 第三章…...

云计算期末复习(1)
云计算基础 作业(问答题) (1)总结云计算的特点。 透明的云端计算服务 “无限”多的计算资源,提供强大的计算能力 按需分配,弹性伸缩,取用方便,成本低廉资源共享,降低企…...

frp转发服务
将内网服务转发到外网,我准备了一台阿里云ubuntu22.04服务器,两台内网ubuntu22.04服务器 下载frpc和frps以及配置文件 链接: https://pan.baidu.com/s/1auvcWWnyfpYPYatYhHFYag?pwdqkgh 提取码: qkgh 复制这段内容后打开百度网盘手机App,操作…...
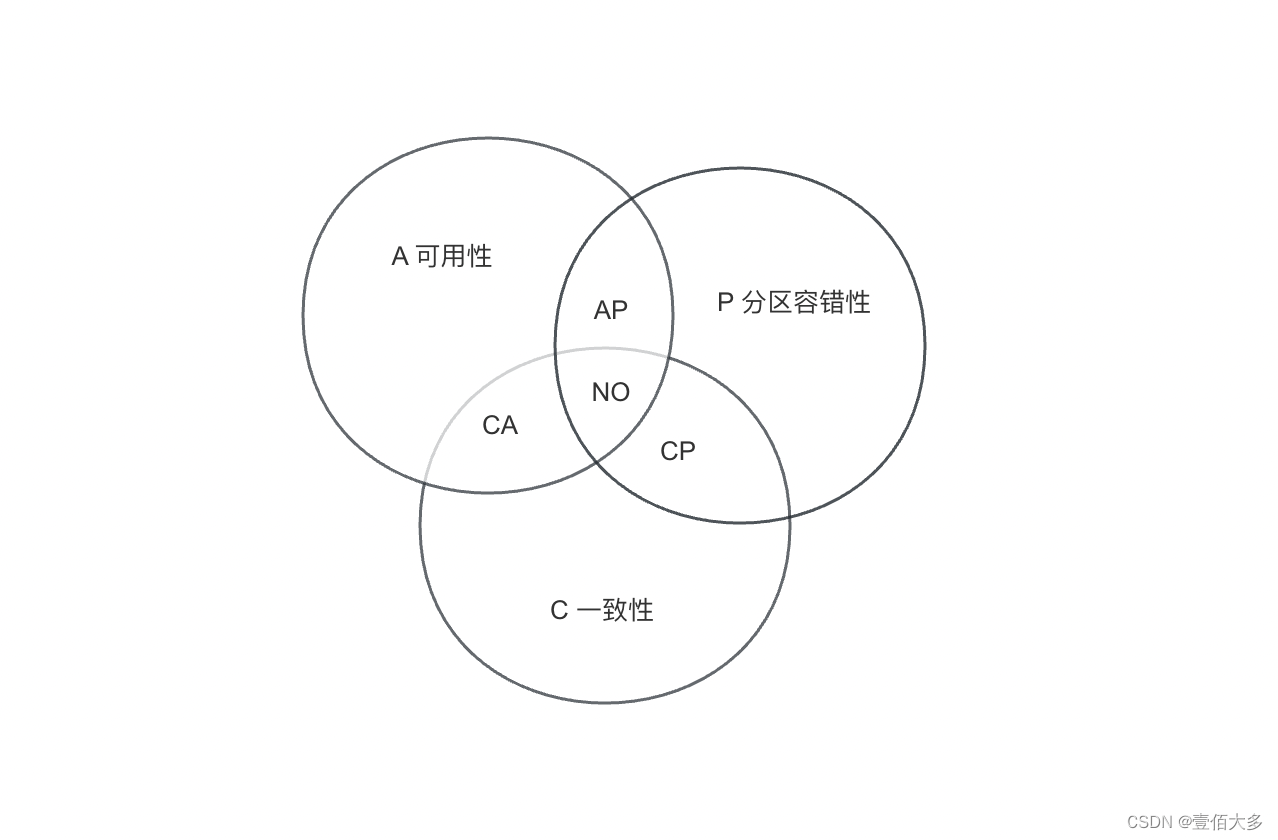
【主流分布式算法总结】
文章目录 分布式常见的问题常见的分布式算法Raft算法概念Raft的实现 ZAB算法Paxos算法 分布式常见的问题 分布式场景下困扰我们的3个核心问题(CAP):一致性、可用性、分区容错性。 1、一致性(Consistency):…...
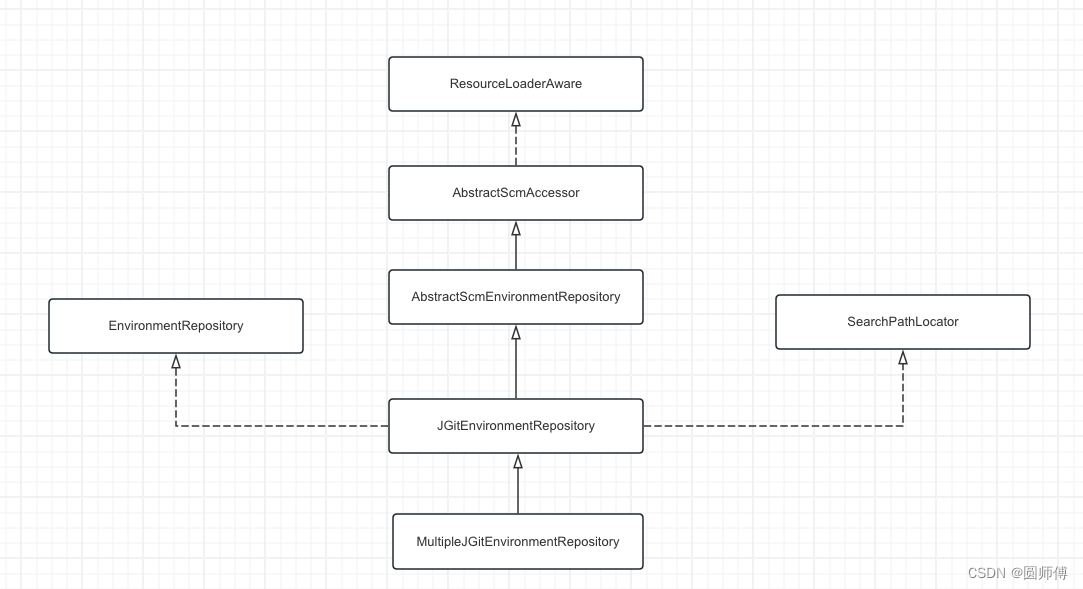
spring cloud config server源码学习(一)
文章目录 1. 注解EnableConfigServer2. ConfigServerAutoConfiguration2.1 ConditionalOnBean和ConditionalOnProperty2.2 Import注解2.2.1. EnvironmentRepositoryConfiguration.class2.2.2. CompositeConfiguration.class2.2.3. ResourceRepositoryConfiguration.class2.2.4.…...
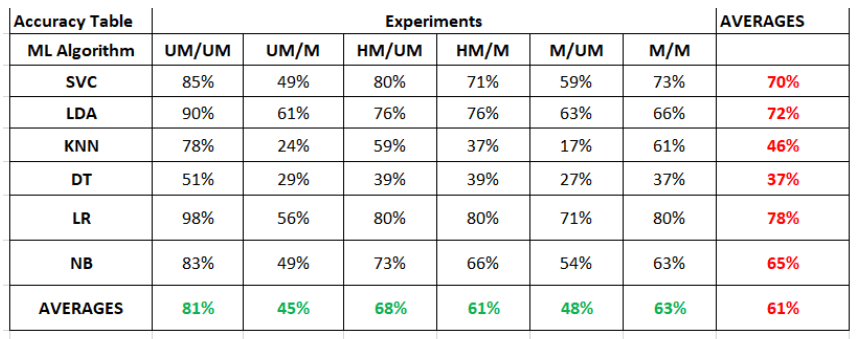
人脸识别——探索戴口罩对人脸识别算法的影响
1. 概述 人脸识别是一种机器学习技术,广泛应用于各种领域,包括出入境管制、电子设备安全登录、社区监控、学校考勤管理、工作场所考勤管理和刑事调查。然而,当 COVID-19 引发全球大流行时,戴口罩就成了日常生活中的必需品。广泛使…...
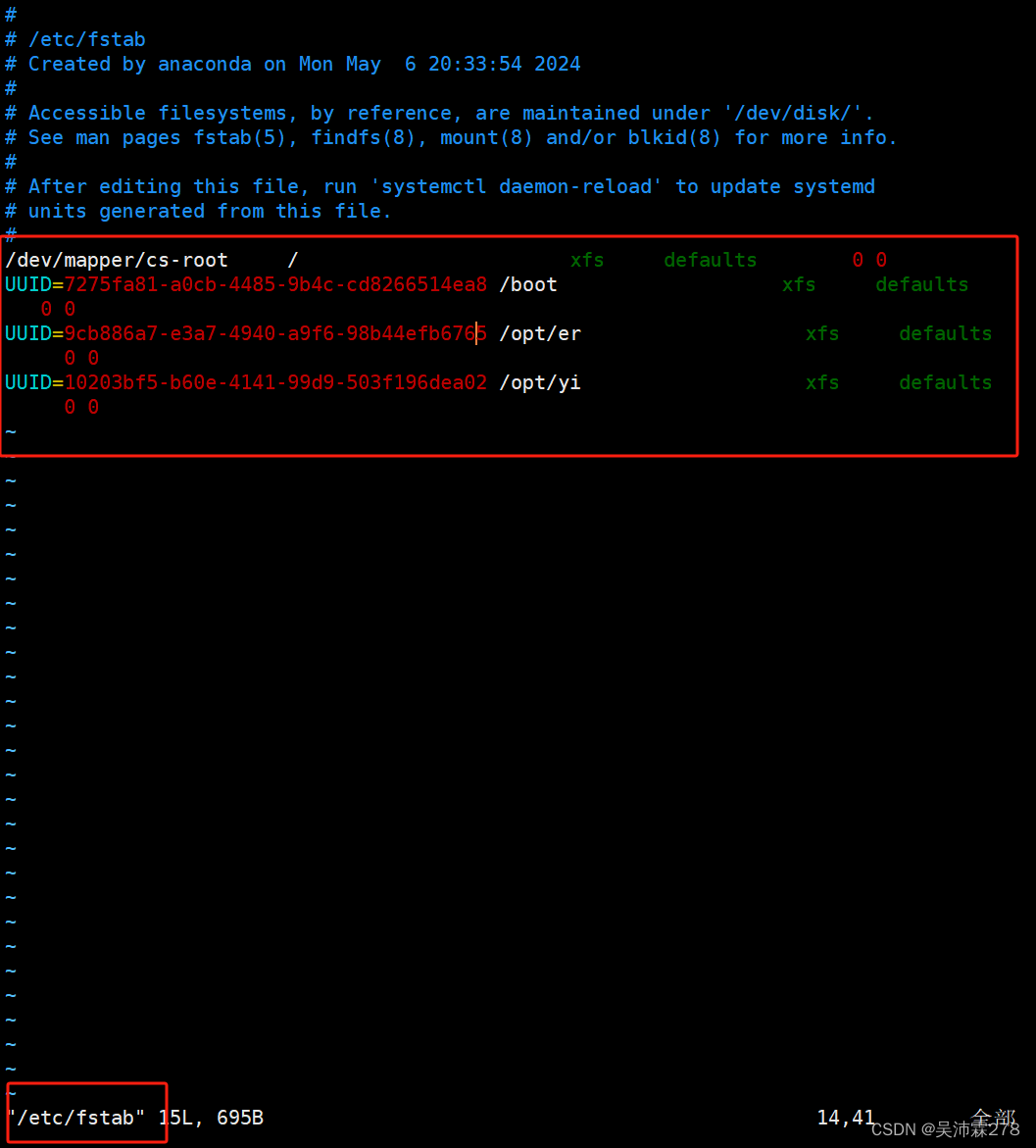
磁盘管理后续——盘符漂移问题解决
之前格式化磁盘安装了文件系统,且对磁盘做了相应的挂载,但是服务器重启后挂载信息可能有问题,或者出现盘符漂移、盘符变化、盘符错乱等故障,具体是dev/sda, sdb, sdc 等等在某些情况下会混乱掉 比如sda变成了sdb或者sdc变成了sdb等…...
基于GO 写的一款 GUI 工具,M3u8视频下载播放器-飞鸟视频助手
M3u8视频下载播放器-飞鸟视频助手 M3u8视频飞鸟视频助手使用m3u8下载m3u8 本地播放 软件下载地址m3u8嗅探 M3u8视频 M3u8视频格式是为网络视频播放设计,视频网站多数采用 m3u8格式。如腾讯,爱奇艺等网站。 m3u8和 mp4的区别: 一个 mp4是一个…...

关于EasyExcel导入数据时表格日期格式识别为数字问题
参考官方地址 自定义日期转字符串转换器 /*** 自定义excel日期转换器** author li* date 2024-05-29*/ public class CustomStringDateConverter implements Converter<String> {Overridepublic Class<?> supportJavaTypeKey() {return String.class;}Overridep…...

高通Android 12/13打开省电模式宏开关
1、添加到SettingsProvider配置项宏开关 默认节电助手自动开启百分比battery saver frameworks\base\packages\SettingsProvider\src\com\android\providers\settings\DatabaseHelper.java private void loadGlobalSettings(SQLiteDatabase db) {在该方法中添加 ......final i…...

2023年西安交通大学校赛(E-雪中楼)
E.雪中楼 如果算出按南北的序列,再转成从低到高的编号序列,岂不是太麻烦了,幸好,没有在这方面费长时间,而是意识到,本质就是要从低到高的编号序列,所以我就按样例模拟了一下,当a[i]0…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

83.人工智能实战:RAG 表格问答怎么做?从前期发现“表格被切碎”到结构化解析、行列索引与答案校验
人工智能实战:RAG 表格问答怎么做?从前期发现“表格被切碎”到结构化解析、行列索引与答案校验 一、问题场景:Word 文档能答,Excel 表格一问就错 很多企业知识库不只有 Word 和 PDF,还有大量表格: 1. 报销标准表 2. 产品价格表 3. 客户等级表 4. SLA 服务等级表 5. 部门…...

n8n-claw:在自动化工作流中实现零代码网页抓取
1. 项目概述与核心价值最近在折腾自动化工作流,发现了一个挺有意思的项目,叫freddy-schuetz/n8n-claw。乍一看名字,你可能会有点懵,“n8n”我知道,是那个开源的自动化工具,但这个“claw”是啥?爪…...

AI编码工具选型指南:从原理到实践的全方位解析
1. 项目概述:为什么我们需要一份AI编码工具的“藏宝图”如果你是一名开发者,过去一年里,你的工作流可能已经被AI工具彻底重塑了。从最初用ChatGPT写几行注释,到后来用GitHub Copilot自动补全整段代码,再到如今各种能直…...

汽车该多久换一代
汽车该多久换一代 买车的人其实不怕四年换代,怕的是刚提车半年就被新款打成旧款。李想这句话能引起讨论,原因也在这里:车企说的是研发验证周期,车主感受到的是价格、配置和二手残值。 汽车确实没法完全照着手机节奏跑。手机坏了可…...
)
告别串口线!用STM32CubeMX给STM32F103C8T6做个USB DFU Bootloader(Keil工程+完整代码)
STM32F103C8T6 USB DFU Bootloader实战:从实验室到产品的完整方案 在嵌入式产品开发中,固件升级是一个绕不开的话题。想象一下,当你的设备已经部署在现场,却发现需要修复一个关键bug或增加新功能时,传统的JTAG/SWD调试…...

AI智能体可观测性实战:用AgentOps实现全链路追踪与性能优化
1. 项目概述:当AI智能体遇上“黑匣子”,我们如何看清它的每一步?如果你最近在折腾AI智能体(Agent),无论是用LangChain、AutoGPT还是自己手搓的框架,大概率会遇到一个共同的痛点:调试…...

显存又爆了?移动云弹性KV缓存:让你告别“显存焦虑”
上下文越长,显存越吃紧对话轮次越多,延迟越明显并发量一高,服务就卡顿……随着AI大模型向超长上下文、高并发、多轮交互深度演进,AI推理所需缓存的内容呈指数级增长。显存容量的需求爆炸与显存采购的高昂成本,使得超长…...

Claude API与内部知识库深度耦合方案:零代码改造实现RAG增强,已验证QPS提升4.8倍
更多请点击: https://intelliparadigm.com 第一章:Claude API与内部知识库深度耦合方案:零代码改造实现RAG增强,已验证QPS提升4.8倍 该方案通过在 Claude API 请求链路中注入轻量级 RAG 中间件,无需修改业务侧任何模型…...