Hadoop3:MapReduce之简介、WordCount案例源码阅读、简单功能开发
一、概念
MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析
应用”的核心框架。
MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的
分布式运算程序 ,并发运行在一个 Hadoop集群上。
1、MapReduce是集群上的并行计算框架
2、平时开发中只需要基于MapReduce接口,编写业务逻辑代码即可。
二、优缺点
优点
1、易于编程
2、良好的扩展性
3、高容错性
4、适合PB级以上海量数据的离线处理
缺点
1、不擅长实时计算
Spark Streaming
2、不擅长流式计算
Spark Streaming、Flink
3、不擅长DAG(有向无环图)计算
Spark
三、算法思想
学过Java8的都知道MapReduce框架。
它是一款并发任务框架。
但是开发难度较大
在Hadoop中的MapReduce框架算法思想是一样的。
分两个阶段
第一阶段,任务分发阶段(Map阶段),并行计算数据,所有数据是互不相干。所有计算任务也是互不相干的。
第二阶段,结果汇总阶段(Reduce阶段),并行统计Map计算出的结果,汇总出最终结果,返回给用户。
如果,我们拿到的一批数据,并非是等价的,可能之间存在数据依赖,那么,我们就需要写多个MapReduce任务,分别计算各个层级的数据。
所以,开发MapReduce,首先要分析数据的依赖关系,然后,编写分多个MapReduce进行计算即可。
四、WordCount案例源码阅读
1、WordCount源码
package org.apache.hadoop.examples;import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount
{public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private static final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}public static class IntSumReducerextends Reducer<Text, IntWritable, Text, IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}this.result.set(sum);context.write(key, this.result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; i++) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}
}
2、源码结构分析
主要三部分
1、程序入口,main函数
主要关注7个job配置
2、Mapper内部类
主要关注四个泛型配置:输入的key,输入的value,输出的key,输出的value
3、Reducer内部类
主要关注四个泛型配置:输入的key,输入的value,输出的key,输出的value
3、数据类型对应关系
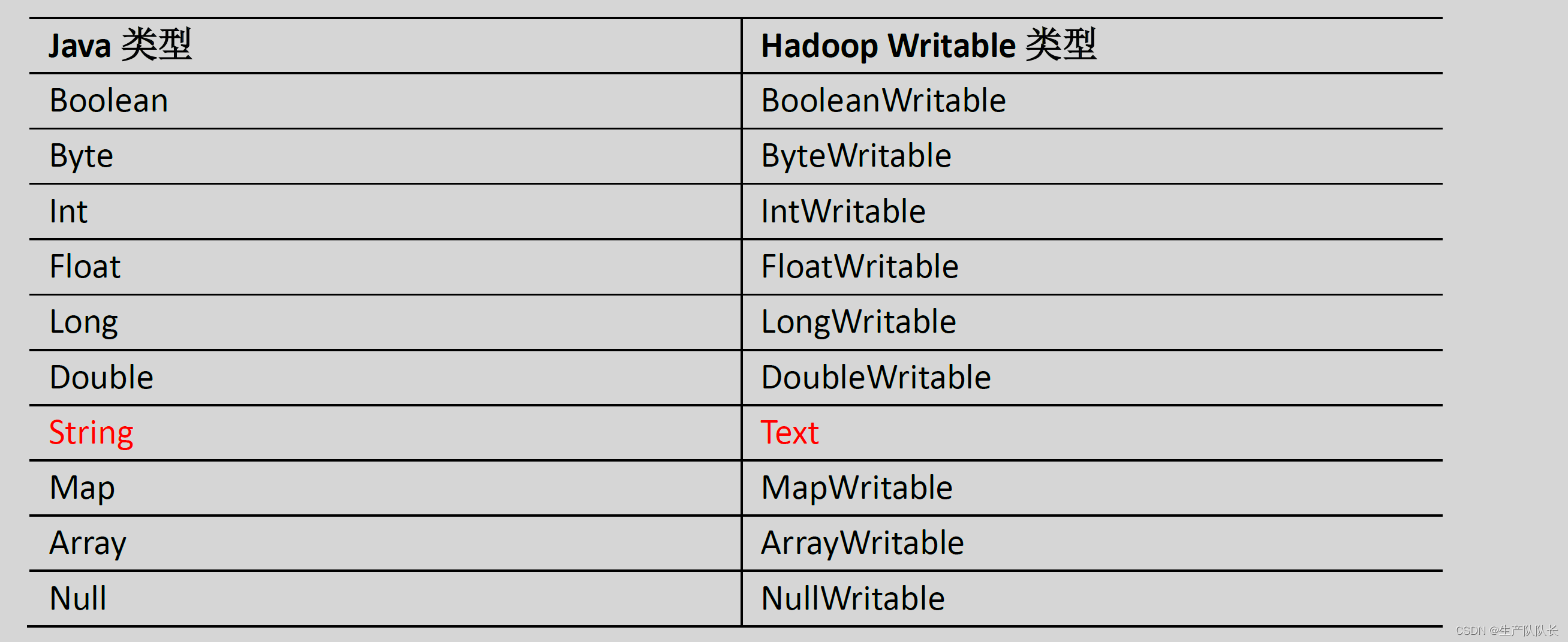
五、自定义开发WordCount
1、案例需求分析
从图中,我们需要注意的是:
Mapper阶段,数据结构的变化过程,最终输出的数据结构
Reducer阶段,收到的数据结构和输出的数据结构

2、Mapper类实现
package com.atguigu.mapreduce.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** KEYIN, map阶段输入的key的类型:LongWritable,偏移量,可以理解为txt文本内容中,字符的下标。下标按行累加* VALUEIN,map阶段输入value类型:Text* KEYOUT,map阶段输出的Key类型:Text* VALUEOUT,map阶段输出的value类型:IntWritable*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {private Text outK = new Text();private IntWritable outV = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//可以看出,这个案例中,key偏移量没有起作用// 1 获取一行// atguigu atguiguString line = value.toString();// 2 切割// atguigu// atguiguString[] words = line.split(" ");// 3 循环写出for (String word : words) {// 封装outkoutK.set(word);// 写出context.write(outK, outV);}}
}
3、Reducer类实现
package com.atguigu.mapreduce.wordcount;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** KEYIN, reduce阶段输入的key的类型:Text* VALUEIN,reduce阶段输入value类型:IntWritable* KEYOUT,reduce阶段输出的Key类型:Text* VALUEOUT,reduce阶段输出的value类型:IntWritable*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {private IntWritable outV = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int sum = 0;// atguigu, (1,1)// 累加for (IntWritable value : values) {sum += value.get();}outV.set(sum);// 写出context.write(key,outV);}
}
4、WordCountDriver类实现
这里需要注意的是,这里的4和5两步骤。
4步骤,确定Mapper的输入类型,Mapper的输出类型要和Reducer的输入类型一致。
5步骤,确定Reducer的输出类型。
package com.atguigu.mapreduce.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;public class WordCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {// 1 获取jobConfiguration conf = new Configuration();Job job = Job.getInstance(conf);// 2 设置jar包路径job.setJarByClass(WordCountDriver.class);// 3 关联mapper和reducerjob.setMapperClass(WordCountMapper.class);job.setReducerClass(WordCountReducer.class);// 4 设置map输出的kv类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// 5 设置最终输出的kV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);// 6 设置输入路径和输出路径
// FileInputFormat.setInputPaths(job, new Path("E:\\workspace\\data\\input\\inputword"));
// FileOutputFormat.setOutputPath(job, new Path("E:\\workspace\\data\\ouputword"));FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));// 7 提交jobboolean result = job.waitForCompletion(true);System.exit(result ? 0 : 1);}
}
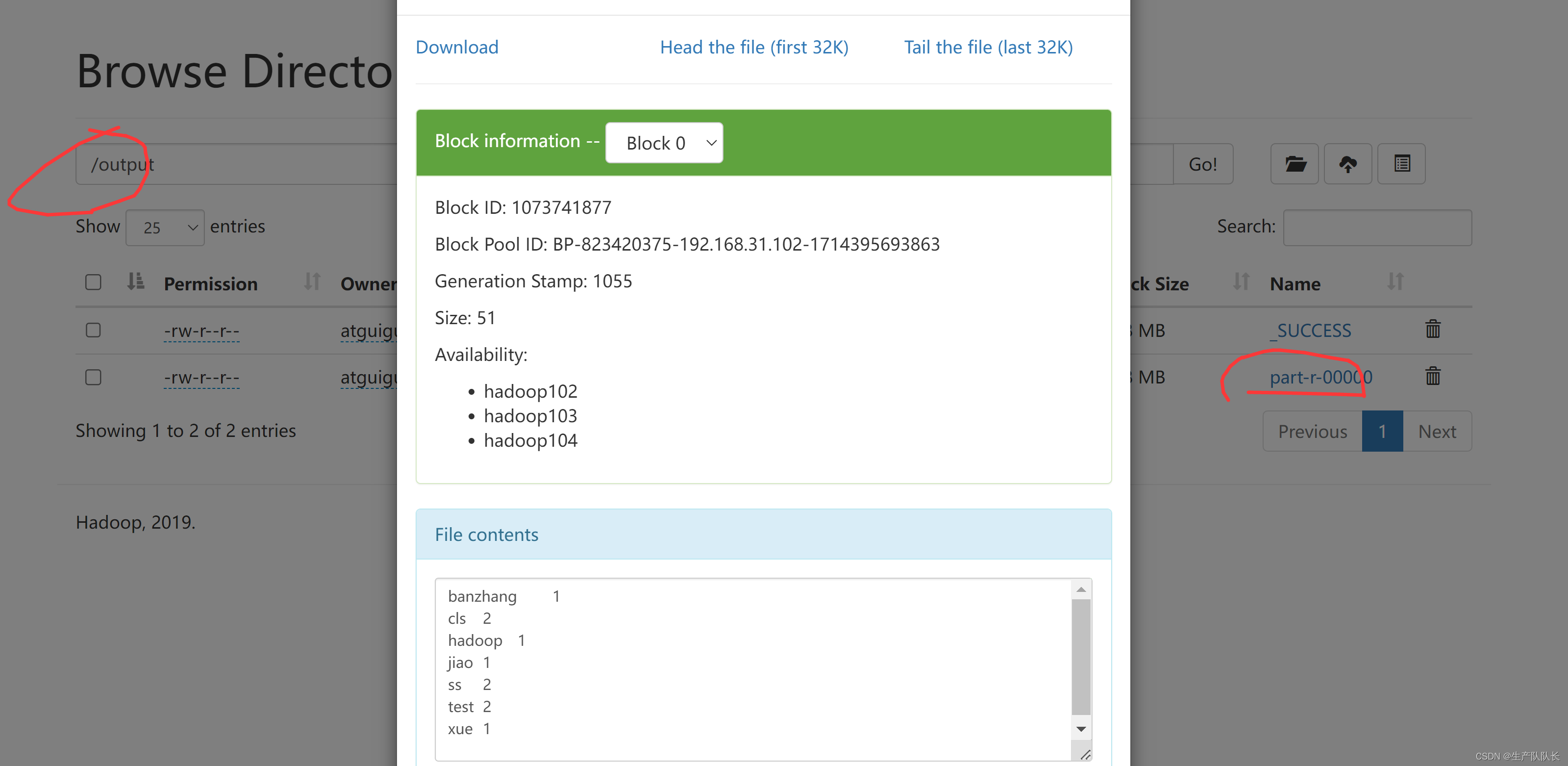
六、运行验证
1、本地运行
直接IDEA中,运行main函数即可
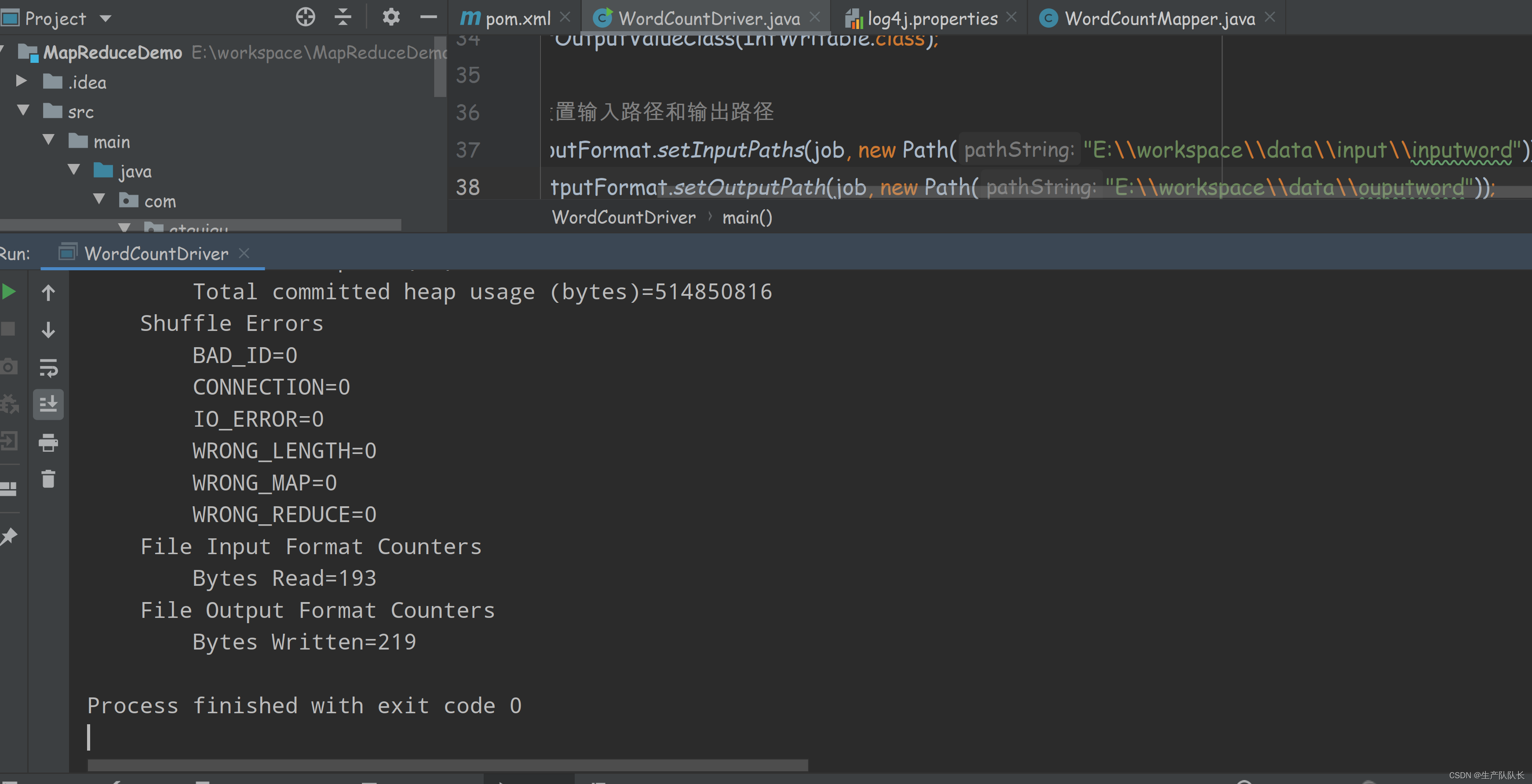

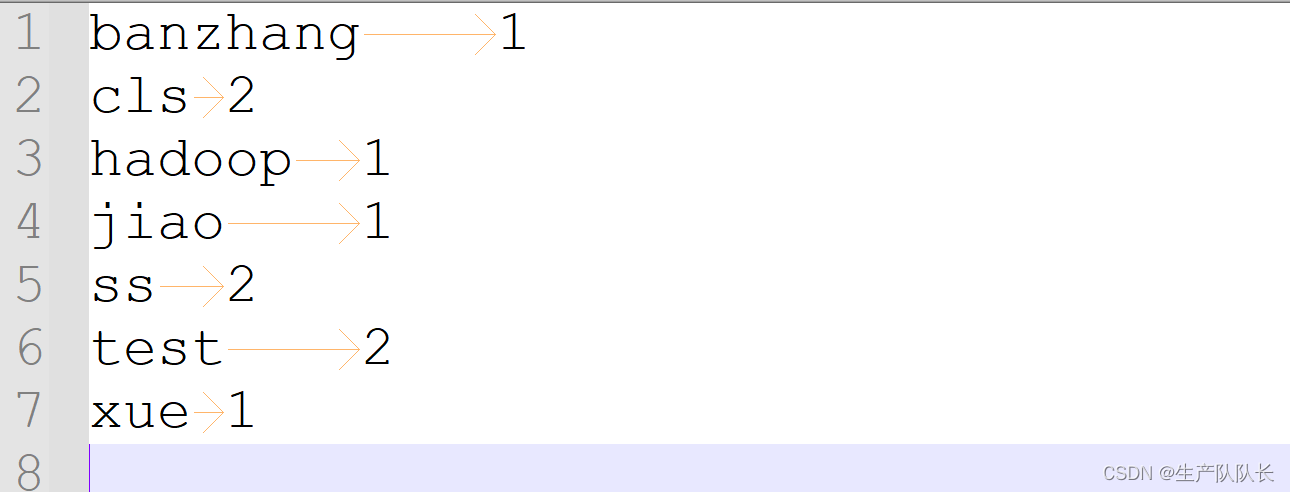
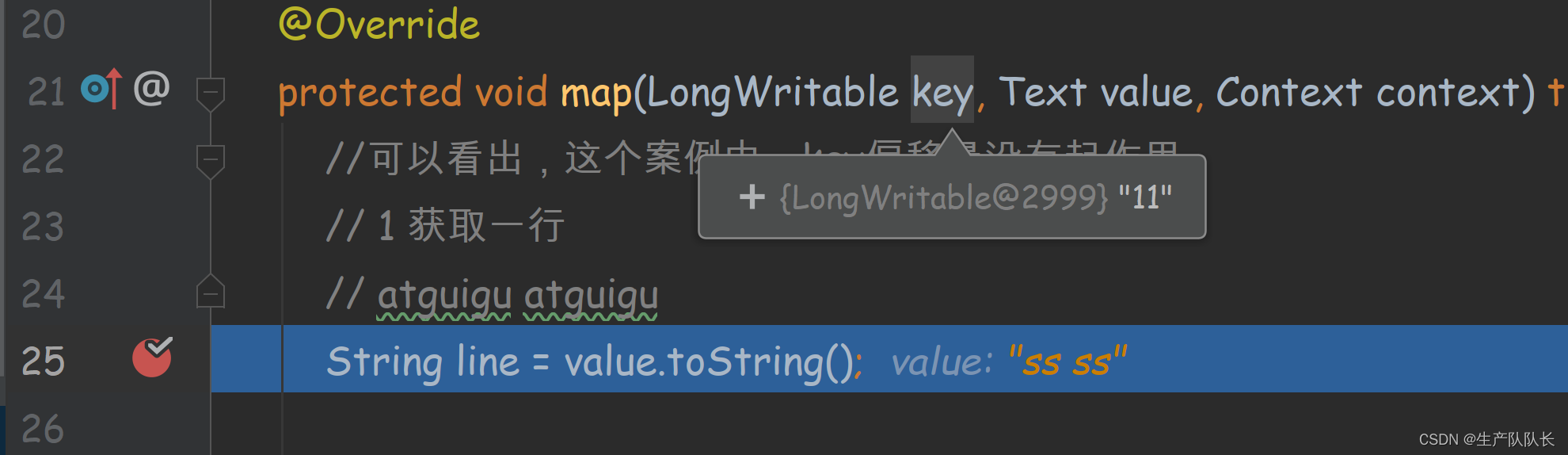
debug查看偏移量
可以发现,第二行的偏移量是11,因为,第一行2个test,一个空格,一个换行刚好10个
第二行的s就是11开始
所以,MapReduce程序是按行读取文件内容的,偏移量就是每行的第一个字符在文本中的位置
空格,回车等都占一个字符。
可能出现的错误
java.lang.ClassNotFoundException: Class org.apache.hadoop.hdfs.DistributedFileSystem
我的完整pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu</groupId><artifactId>MapReduceDemo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-mapreduce-client-app</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-yarn-server-resourcemanager</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
2、集群中运行
集群中运行,我们需要将代码生成jar包
然后,上传到器群中,运行即可。
1、生成jar包
生成jar包有两种情况
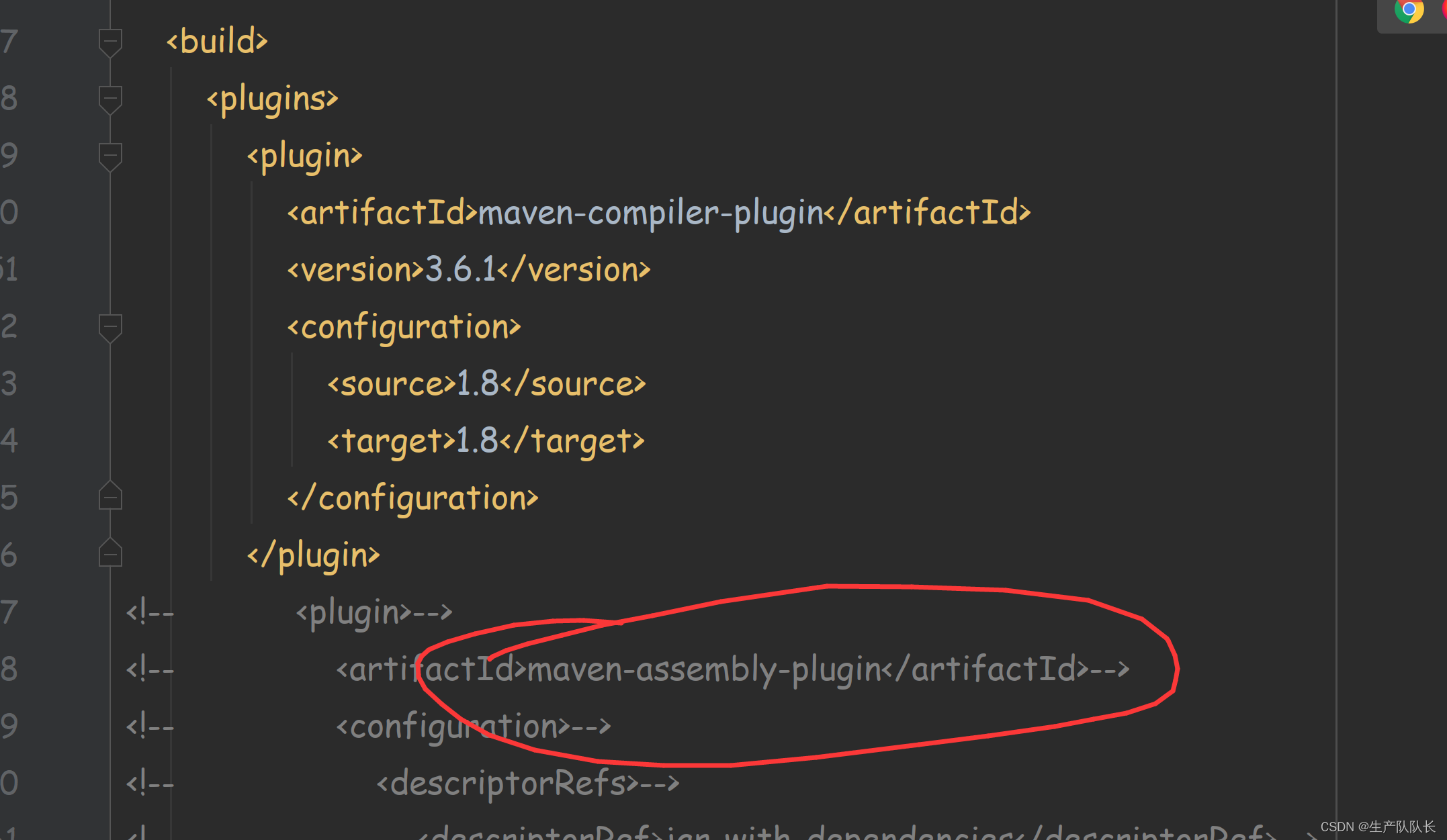
1、不将相关依赖包生成到jar包中
这个情况比较常用,因为,集群上都有相关环境,所以,这样可以节省jar大小,从而上传快。
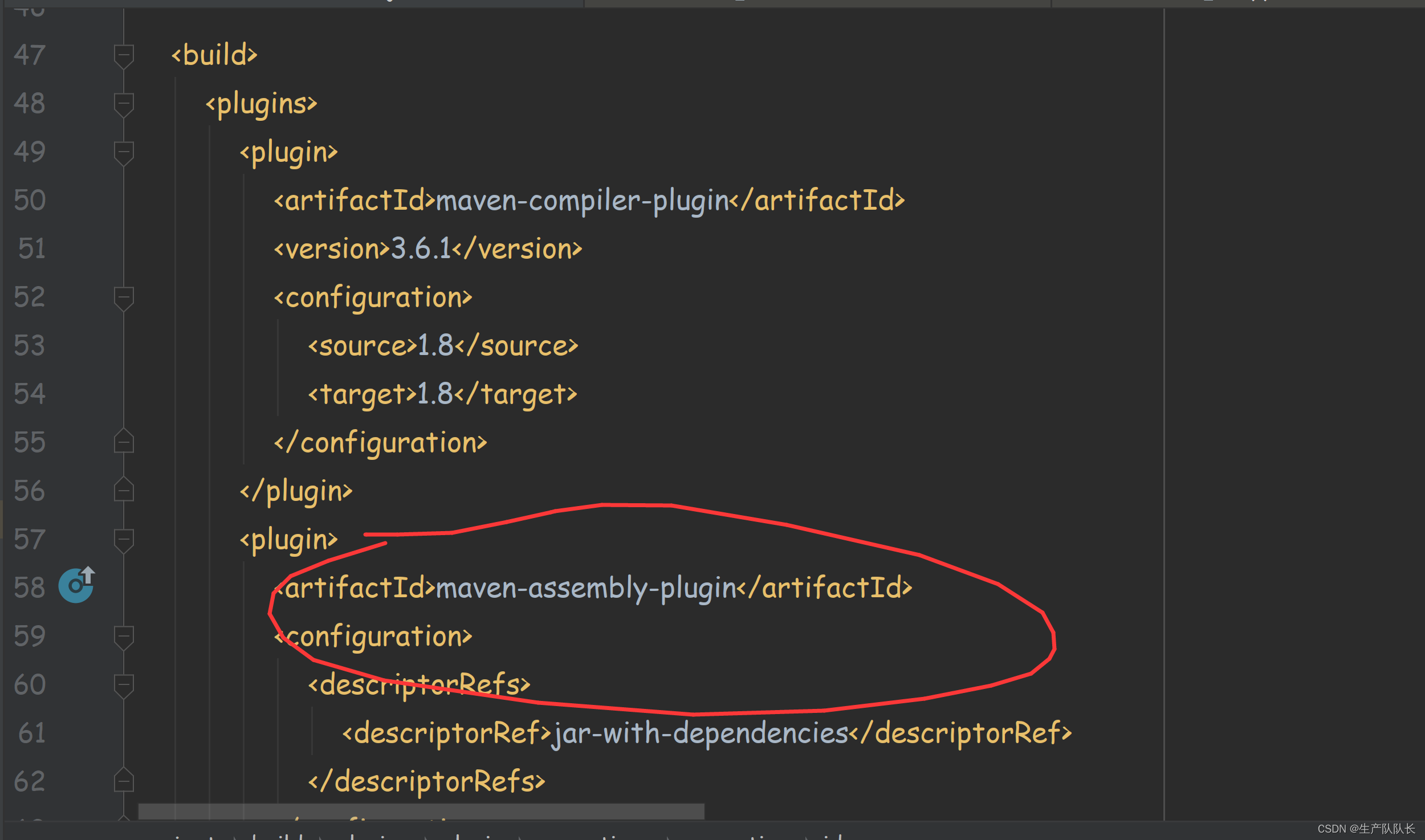
2、将相关依赖包生成到jar包中
这种,比较少用。
2、器群中测试jar包
Driver类修改如下

上传jar包
在集群中找可用文件
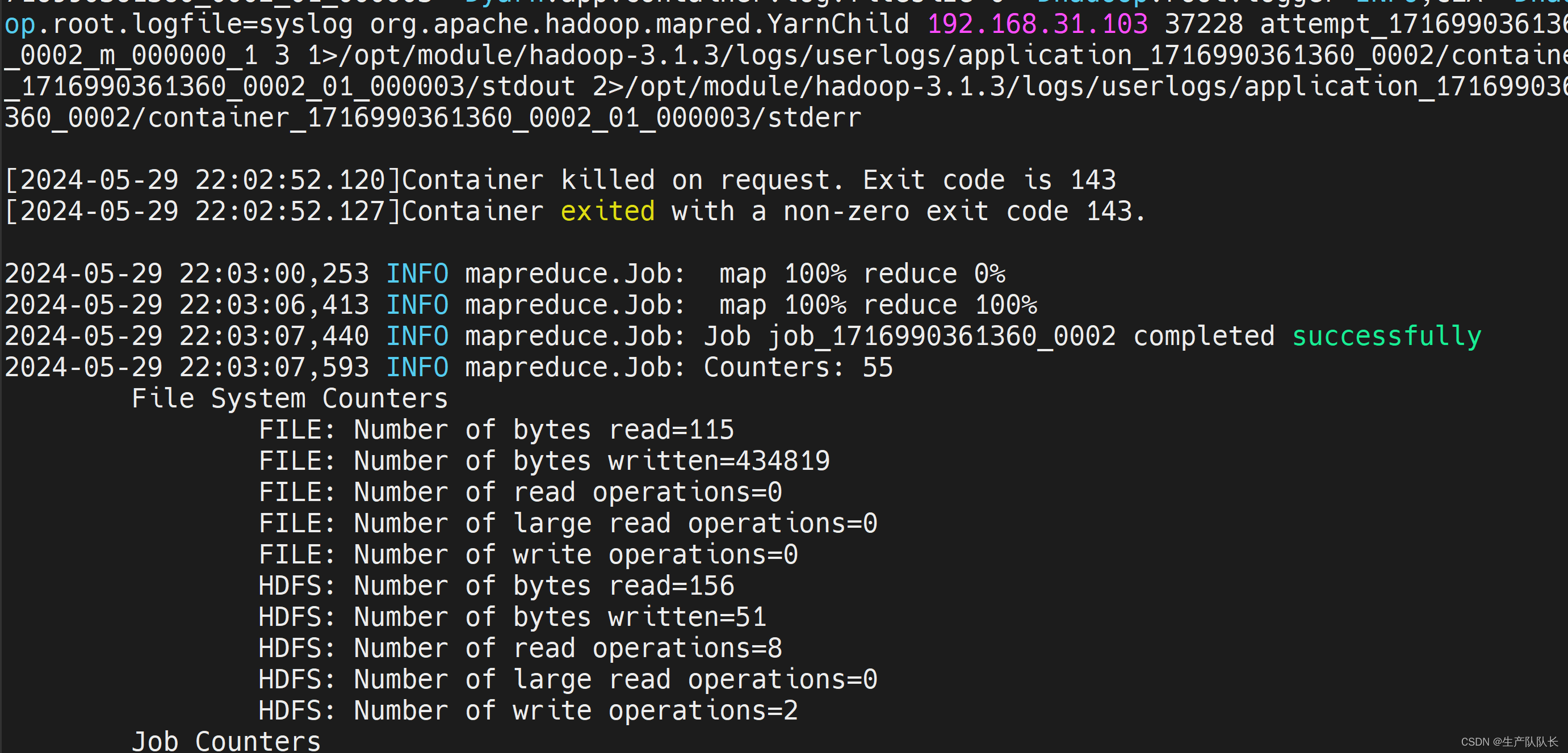
执行wc.jar任务
hadoop jar wc.jar com.atguigu.mapreduce.wordcount.WordCountDriver /input/hello.txt /output
在企业中,差不多也是这样
本地搭建Hadoop的开发环境
分析数据的依赖关系,然后,编写MapReduce业务代码
上传集群,执行
相关文章:
Hadoop3:MapReduce之简介、WordCount案例源码阅读、简单功能开发
一、概念 MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析 应用”的核心框架。 MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的 分布式运算程序 ,并发运行在一个 Hadoop集群上。 1、M…...

centos8stream 编译安装 php-rabbit-mq模块
官方GitHub:https://github.com/php-amqp/php-amqp 环境依赖安装 dnf install cmake make -y 1.安装rabbitmq-c cd /usr/local/src/ wget https://github.com/alanxz/rabbitmq-c/archive/refs/tags/v0.14.0.tar.gz tar xvf v0.14.0.tar.gz cd rabbitmq-c-0.14.0/…...

「异步魔法:Python数据库交互的革命」(二)
哈喽,我是阿佑,上篇文章带领了大家跨入的异步魔法的大门——Python数据库交互,一场魔法与技术的奇幻之旅! 从基础概念到DB-API,再到ORM的高级魔法,我们一步步揭开了数据库操作的神秘面纱。SQLAlchemy和Djan…...

php正则中的i,m,s,x,e分别表示什么
正则表达式模式修饰符(也称为标志或模式修饰符)用于改变正则表达式的行为。这些修饰符可以附加在正则表达式的定界符之后,通常为正斜杠(/)或井号(#),以改变搜索或替换的方式。 1、i…...

最新!2023年台湾10米DEM地形瓦片数据
上次更新谷歌倾斜摄影转换生成OSGB瓦片V1.1版本,使用该版本生产了台北、台中、桃园三个地方的倾斜摄影OSGB数据,在OSGB可视化软件中进行展示,可视化效果和加载效率俱佳。已经很久没更新地形瓦片数据,主要是热点地区的原始数据没有…...
 |深入解析客户端缓存与服务器缓存:HTTP缓存控制头字段及优化实践)
网络学习(11) |深入解析客户端缓存与服务器缓存:HTTP缓存控制头字段及优化实践
文章目录 客户端缓存与服务器缓存的区别客户端缓存浏览器缓存应用程序缓存优点缺点 服务器缓存优点缺点 HTTP缓存控制头字段Cache-ControlExpiresLast-ModifiedETag 缓存策略的优化与实践经验分享1. 使用合适的缓存头字段2. 结合使用Last-Modified和ETag3. 利用CDN进行缓存4. 实…...

uniapp中二次封装jssdk和使用
直接上代码 // import wx from "weixin-js-sdk"; /*** 考虑到包的大小,所以直接在 index.html 文件中cdn引入了jssdk* <script src"https://res.wx.qq.com/open/js/jweixin-1.6.0.js"></script>* 注意:这里 jWeixin 一…...
只刷题可以通过PMP考试吗?
咱们都知道,PMBOK那本书,哎呀,读起来确实有点费劲。所以,有些人就想了,干脆我就刷题吧,题海战术,没准儿也能过。这话啊,听起来似乎有点道理,但咱们得好好琢磨琢磨。 刷题…...

Python Selenium 详解:实现高效的UI自动化测试
落日余辉,深情不及久伴。大家好,在当今软件开发的世界中,自动化测试已经成为保障软件质量和快速迭代的重要环节。而在自动化测试的领域中,UI自动化测试是不可或缺的一部分,它可以帮助测试团队快速验证用户界面的正确性…...

npm获取yarn在安装依赖时 git://github.com/user/xx.git 无法访问解决方法 -- 使用 insteadOf设置git命令别名
今天在使用一个node项目时突然遇到 一个github的拉取异常,一看协议居然是git://xxx 貌似github早就不用这种格式了, 而是使用的gitgithub.com:xxx 这种或者https协议,解决方法: 使用insteadof设置git别名 url.<base>.inste…...

Centos7网络故障,开机之后连不上网ens33mtu 1500 qdisc noop state DOWN group default qlen 1000
说明 这是Linux系统网络接口的信息,其中"mtu 1500"表示最大传输单元大小为1500字节,“qdisc noop”表示没有设置特殊的队列算法,“state down”表示该接口当前处于关闭状态,“group default”表示该接口属于“default”…...

分析 Base64 编码和 URL 安全 Base64 编码
前言 在处理数据传输和存储时,Base64 编码是一种非常常见的技术。它可以将二进制数据转换为文本格式,便于在文本环境中传输和处理。Go 语言提供了对标准 Base64 编码和 URL 安全 Base64 编码的支持。本文将通过一个示例代码,来分析这两种编码…...

cocos 屏幕点击坐标转换为节点坐标
let scPos event.getLocation(); let camera find(Canvas/Camera).getComponent(Camera).screenToWorld(new Vec3(scPos.x,scPos.y,0));//摄像机 let p this.node.getComponent(UITransform).convertToNodeSpaceAR(camera);//this.node为指定的节点为原点(0,0&…...

电瓶车进电梯识别报警摄像机
随着电动车的普及,越来越多的人选择电动车作为出行工具。在诸多场景中,电梯作为一种常见的交通工具,也受到了电动车用户的青睐。然而,电动车进入电梯时存在一些安全隐患,为了提高电动车进电梯的安全性,可以…...

数据库到服务器提权
数据库提权流程: 1、先获取到数据库用户密码 -网站存在SQL注入漏洞 -数据库的存储文件或备份文件 -网站应用源码中的数据库配置文件 -采用工具或脚本爆破(需解决外联问题) 2、利用数据库提权项目进行连接 MDUT //jkd1.8 启动 Databasetools …...
-表和页压缩(1)-表压缩)
【MySQL精通之路】InnoDB(9)-表和页压缩(1)-表压缩
目录 1.表压缩概述 2.创建压缩表 2.1 在FPT表空间中创建压缩表 2.2 在通用表空间中创建压缩表 2.3 压缩表的限制 3.优化InnoDB表的压缩 4.运行时监控InnoDB表压缩 5.InnoDB表的压缩工作原理 5.1 压缩算法 5.2 InnoDB数据存储和压缩 5.3 B树页面的压缩 5.4 压缩BLOB、…...

【前端】vue+element项目中select下拉框label想要显示多个值多个字段
Vue Element项目中select下拉框label想要显示多个值 <el-selectv-model"form.plantId"collapse-tagsfilterableplaceholder"请选择品种种类"style"width: 270px;"><el-optionv-for"item in plantIdArray":key"item.id&…...
橙派探险记:开箱香橙派 AIpro 与疲劳驾驶检测的奇幻之旅
目录 引子:神秘包裹的到来 第一章:香橙派AIpro初体验 资源与性能介绍 系统烧录 Linux 镜像(TF 卡) 调试模式 登录模式 第二章:大胆的项目构想 系统架构设计 香橙派 AIpro 在项目中的重要作用 第三章…...

云计算期末复习(1)
云计算基础 作业(问答题) (1)总结云计算的特点。 透明的云端计算服务 “无限”多的计算资源,提供强大的计算能力 按需分配,弹性伸缩,取用方便,成本低廉资源共享,降低企…...

frp转发服务
将内网服务转发到外网,我准备了一台阿里云ubuntu22.04服务器,两台内网ubuntu22.04服务器 下载frpc和frps以及配置文件 链接: https://pan.baidu.com/s/1auvcWWnyfpYPYatYhHFYag?pwdqkgh 提取码: qkgh 复制这段内容后打开百度网盘手机App,操作…...

3分钟掌握Seraphine:英雄联盟智能助手完全指南
3分钟掌握Seraphine:英雄联盟智能助手完全指南 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine Seraphine是一款基于英雄联盟官方LCU API开发的智能游戏助手,通过自动BP系统和实时战绩查…...

Gitclaw:封装复杂Git操作,提升开发效率的命令行工具
1. 项目概述:一个为Git操作注入“爪牙”的命令行工具如果你和我一样,日常开发工作重度依赖Git,那你肯定也经历过这样的时刻:面对一个需要多步操作才能完成的复杂Git任务,比如清理多个已合并的分支、批量重写提交历史中…...

本地化AI代码助手LLMDog:模块化框架与开源模型集成实践
1. 项目概述:一个为开发者设计的本地化AI代码助手最近在GitHub上闲逛,发现了一个挺有意思的项目叫“LLMDog”,作者是doganarif。乍一看这个名字,可能会联想到“AI狗”或者某种宠物,但它的全称其实是“Large Language M…...

基于Nginx-Lua镜像构建高性能可编程网关的实践指南
1. 项目概述:一个为现代Web架构而生的Nginx镜像如果你和我一样,长期在容器化环境中部署和管理Web服务,那么你一定对Nginx的灵活性和Lua脚本的强大能力印象深刻。但将这两者结合,并打包成一个稳定、安全、功能齐全的Docker镜像&…...

安得医疗冲刺港股:年营收9亿,利润1.5亿 上海亿瑞控制41%股权
雷递网 雷建平 5月16日山东安得医疗用品股份有限公司(简称:“安得医疗”)日前递交招股书,准备在港交所上市。截至2023年、2024年及2025年12月31日止年度,安得医疗分别宣派及派付股息6670万元、4670万元及4000万元。年营…...

PaperDebugger:解决机器学习代码复现危机的调试框架
1. 项目概述:当代码遇上论文,一场“可复现性”的硬仗如果你和我一样,常年混迹在机器学习、数据科学或者计算物理这类前沿领域,那你一定对下面这个场景不陌生:读到一篇顶会论文,作者声称他们的模型在某个基准…...

体育科学论文降AI工具免费推荐:2026年体育科学研究毕业论文知网AIGC超标4.8元亲测达标完整指南
体育科学论文降AI工具免费推荐:2026年体育科学研究毕业论文知网AIGC超标4.8元亲测达标完整指南 帮同学选过降AI工具,综合价格、效果、保障来看,推荐嘎嘎降AI(www.aigcleaner.com)。 4.8元,达标率99.26%&a…...

ModbusTool:工业自动化通信调试的技术实现与实践指南
ModbusTool:工业自动化通信调试的技术实现与实践指南 【免费下载链接】ModbusTool A modbus master and slave test tool with import and export functionality, supports TCP, UDP and RTU. 项目地址: https://gitcode.com/gh_mirrors/mo/ModbusTool 在工业…...

基于RP2040 PIO与CircuitPython的IBM Model F键盘USB转接方案
1. 项目概述:让经典IBM键盘在现代电脑上重生如果你和我一样,对老式机械键盘那种扎实、清脆的“咔嗒”声和独特手感念念不忘,同时又对它们无法直接插在现代电脑上感到惋惜,那么这个项目就是为你准备的。我最近从朋友的一堆旧物里淘…...

大模型涌现能力:从原理到工程实践的探索与分类
1. 项目概述:从“玄学”到“科学”的涌现能力探索最近和几个做模型研发的朋友聊天,大家不约而同地提到了一个词:“涌现能力”。这个词听起来有点玄乎,像是某种不可预测的“魔法”,但当我们深入讨论时,发现它…...