JavaWeb_MySQL数据库
数据库:
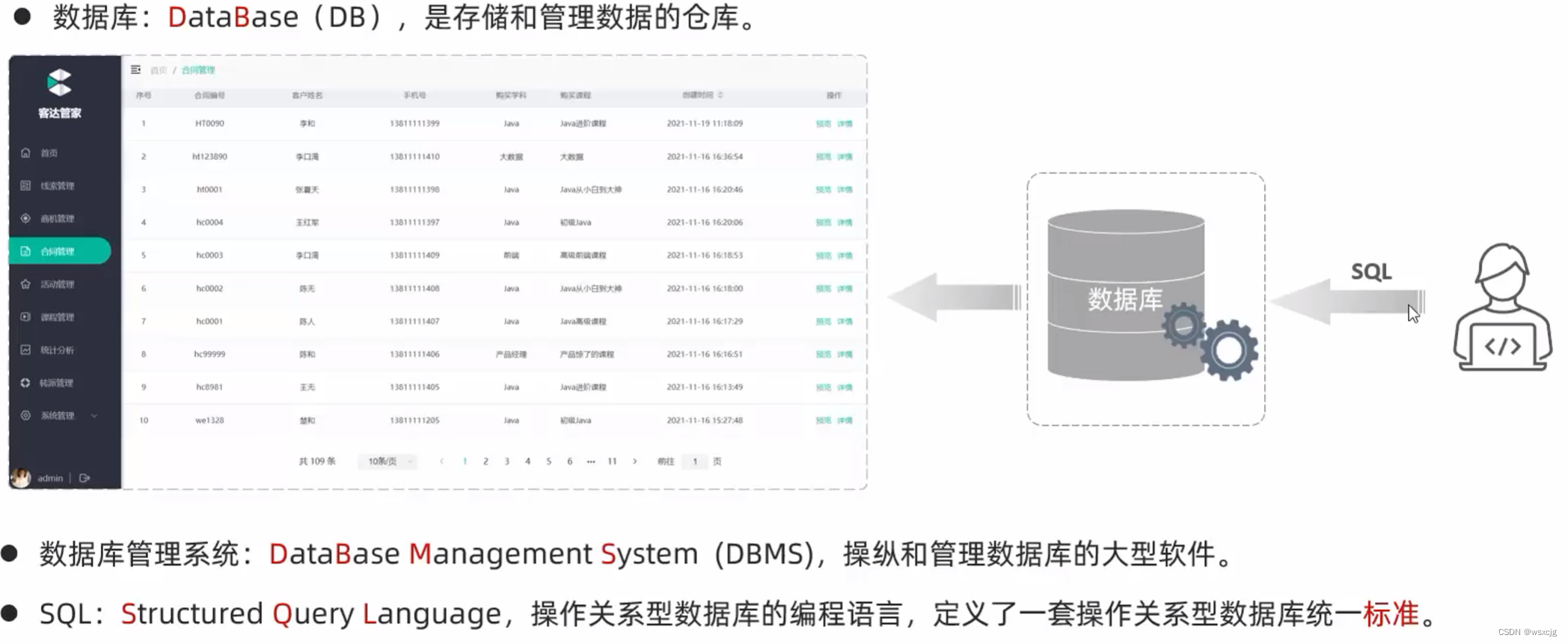
MySQL数据模型:
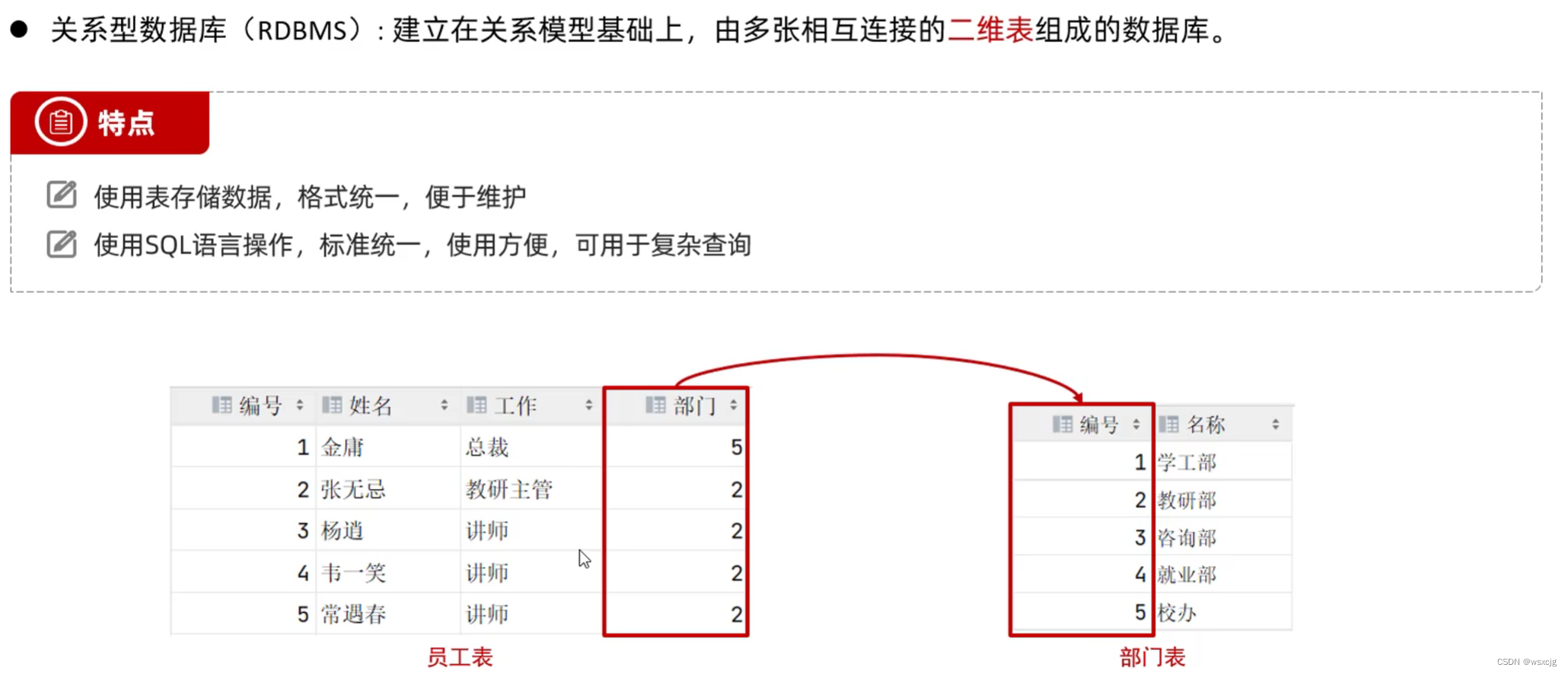
MySQL是关系型数据库。
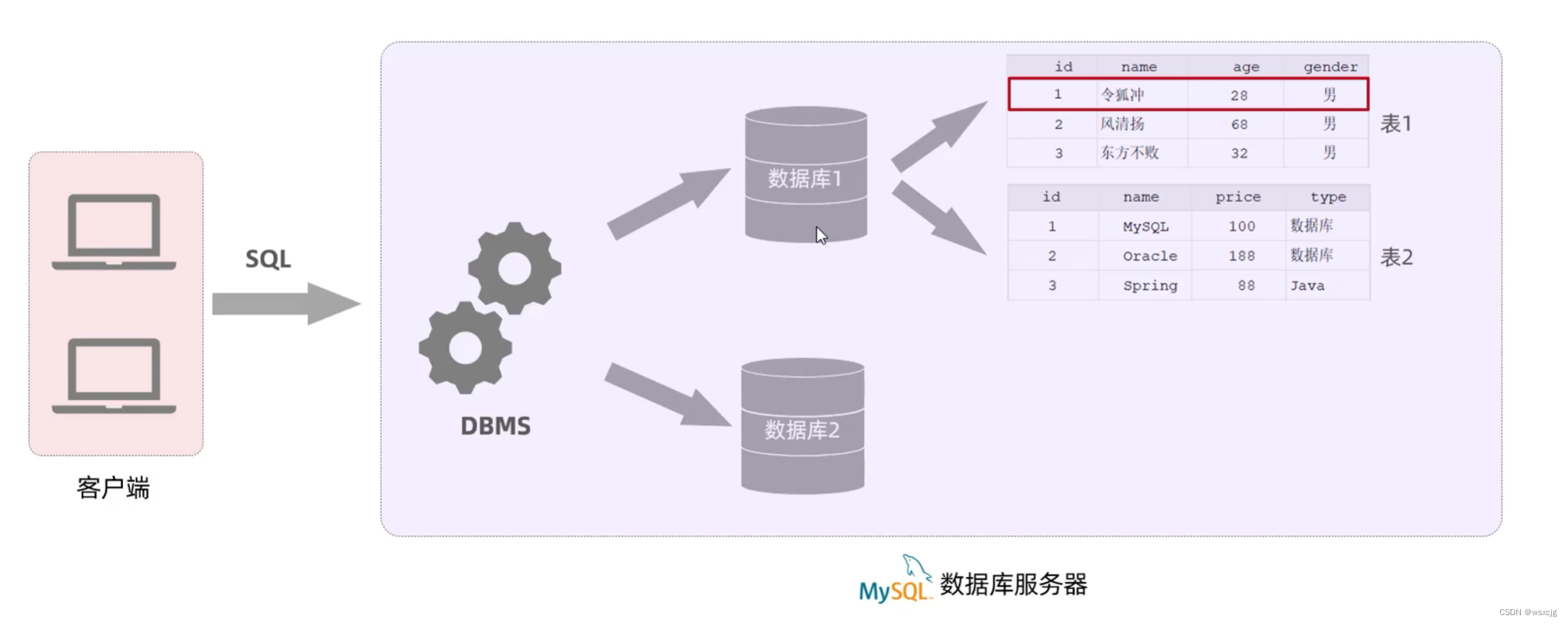
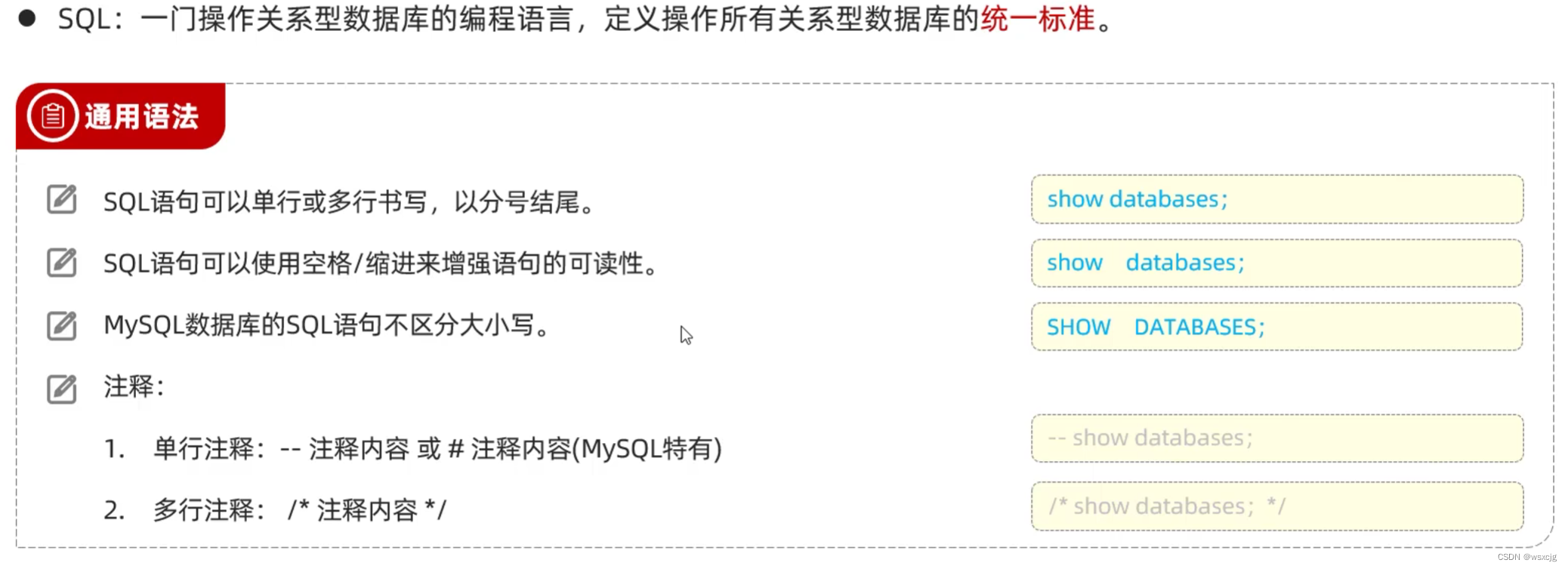
SQL:
简介
分类:
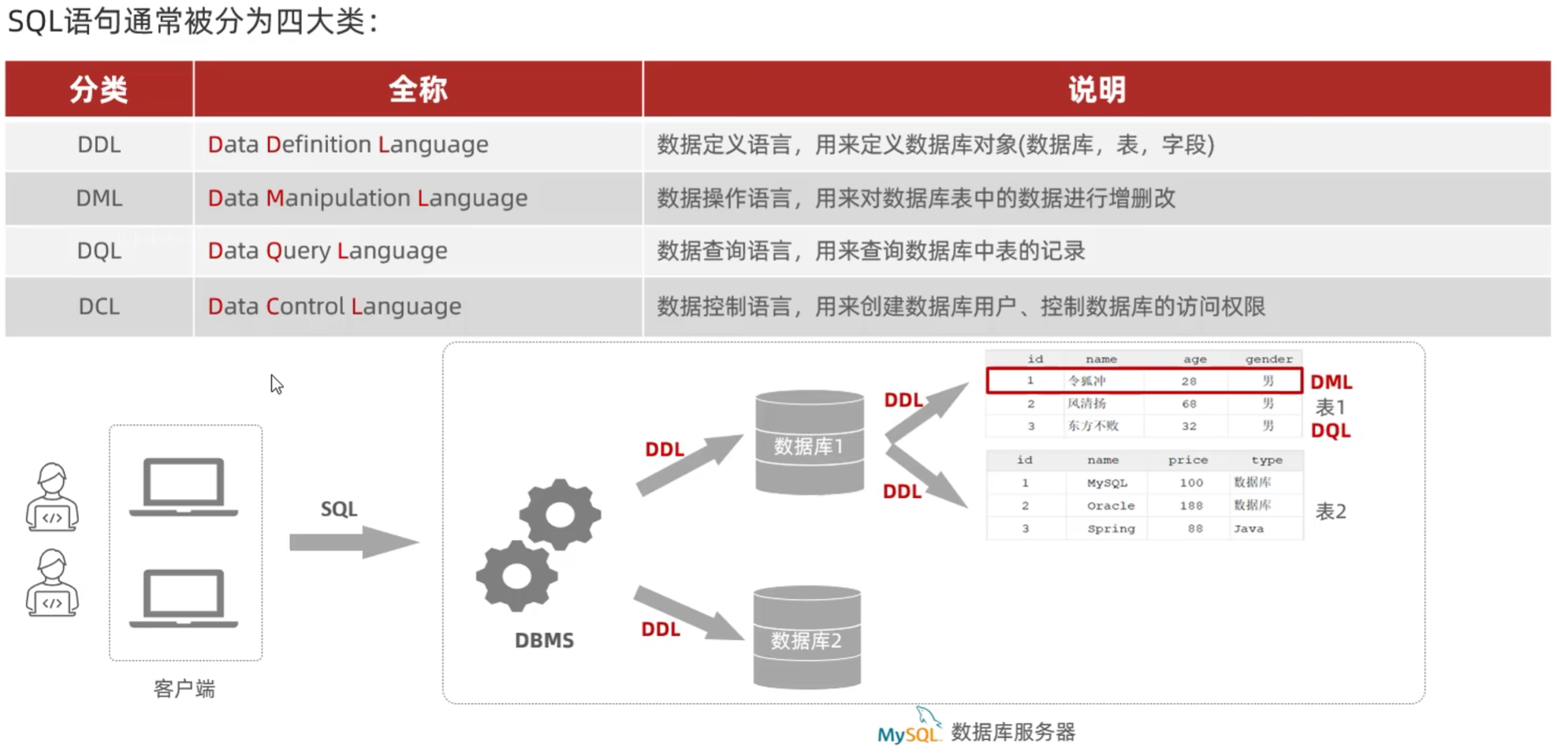
数据库设计-DDL
对数据库操作:

表操作:
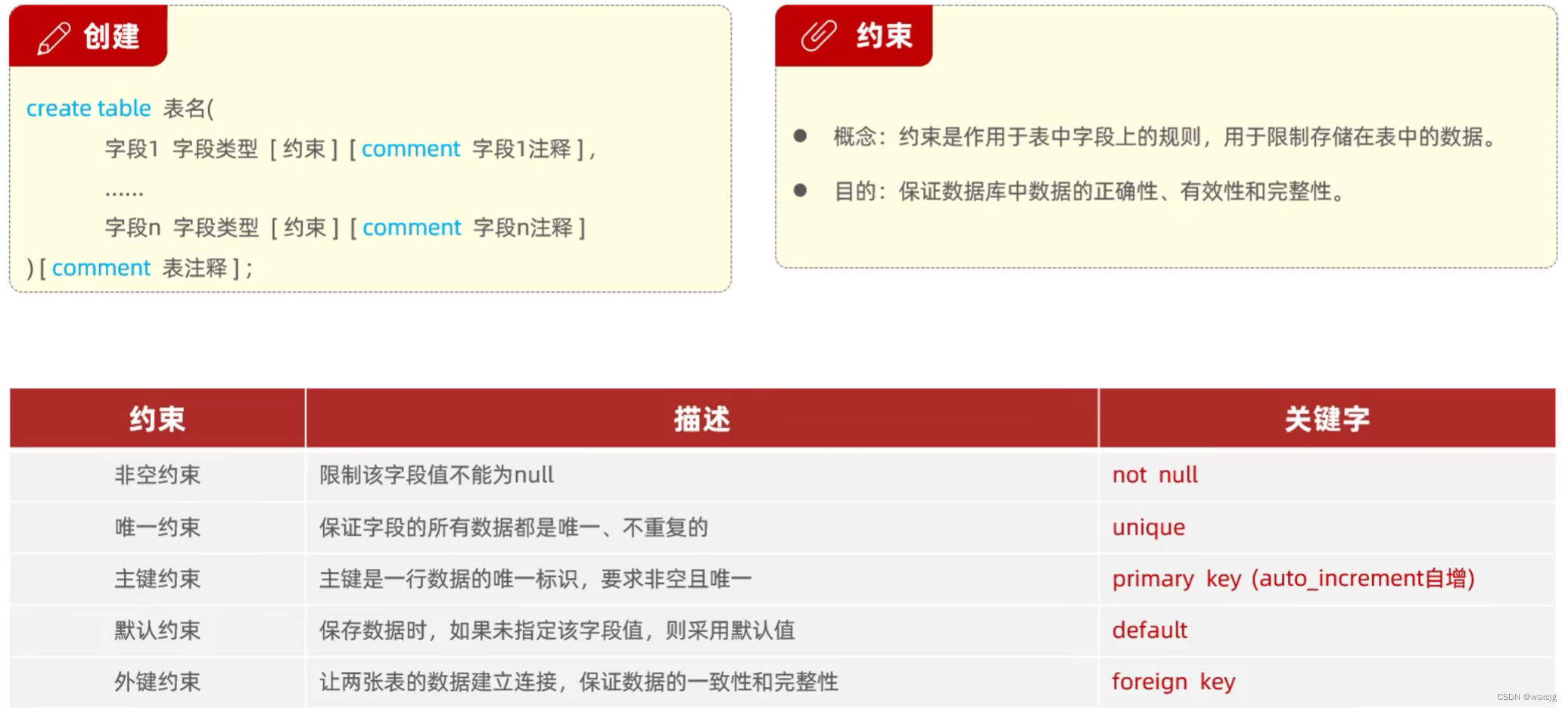



小练习:
创建下表
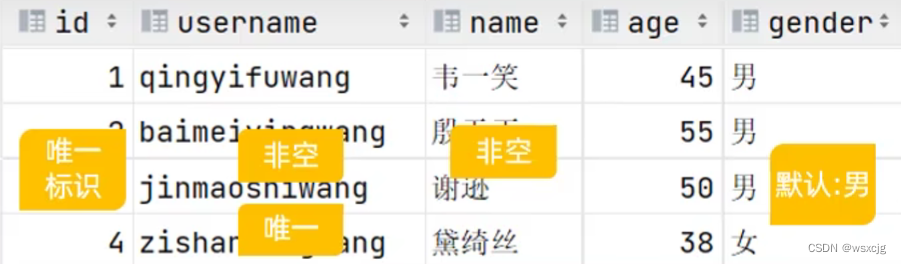
SQL代码:
create table tb_user
(id int primary key auto_increment comment 'ID,唯一标识',username varchar(20) not null unique comment '用户名,非空,唯一',name varchar(10) not null comment '姓名,非空',age int comment '年龄',gender char(1) default '男' comment '默认:男'
) comment '用户表'运行结果:
数据类型:
MySQL中的数据类型有很多,主要分为三类:数值类型,字符串类型,日期事件类型。
数值类型:
| 分类 | 类型 | 大小(byte) | 有符号(SIGNED)范围 | 无符号(UNSIGNED)范围 | 描述 | 备注 |
| 数值类型 | tinyint | 1 | (-128,127) | (0,255) | 小整数值 | |
| smallint | 2 | (-32768,32767) | (0,65535) | 大整数值 | ||
| mediumint | 3 | (-8388608,8388607) | (0,16777215) | 大整数值 | ||
| int | 4 | (-2147483648,2147483647) | (0,4294967295) | 大整数值 | ||
| bigint | 8 | (-2^63,2^63-1) | (0,2^64-1) | 极大整数值 | ||
| float | 4 | (-3.402823466 E+38,3.402823466351 E+38) | 0 和 (1.175494351 E-38,3.402823466 E+38) | 单精度浮点数值 | float(5,2):5表示整个数字长度,2 表示小数位个数 | |
| double | 8 | (-1.7976931348623157 E+308,1.7976931348623157 E+308) | 0 和 (2.2250738585072014 E-308,1.7976931348623157 E+308) | 双精度浮点数值 | double(5,2):5表示整个数字长度,2 表示小数位个数 | |
| decimal | 小数值(精度更高) | decimal(5,2):5表示整个数字长度,2 表示小数位个数 |
字符串类型:
| 分类 | 类型 | 大小 | 描述 | |||||
| 字符串类型 | char | 0-255 bytes | 定长字符串 | char(10): 最多只能存10个字符,不足10个字符,占用10个字符空间 | AB | 性能高 | 浪费空间 | |
| varchar | 0-65535 bytes | 变长字符串 | varchar(10): 最多只能存10个字符,不足10个字符, 按照实际长度存储 | ABC | 性能低 | 节省空间 | ||
| tinyblob | 0-255 bytes | 不超过255个字符的二进制数据 | ||||||
| tinytext | 0-255 bytes | 短文本字符串 | ||||||
| blob | 0-65 535 bytes | 二进制形式的长文本数据 | ||||||
| text | 0-65 535 bytes | 长文本数据 | phone char(11) | |||||
| mediumblob | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 | username varchar(20) | |||||
| mediumtext | 0-16 777 215 bytes | 中等长度文本数据 | ||||||
| longblob | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 | ||||||
| longtext | 0-4 294 967 295 bytes | 极大文本数据 |
日期时间类型:
| 分类 | 类型 | 大小(byte) | 范围 | 格式 | 描述 |
| 日期类型 | date | 3 | 1000-01-01 至 9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | -838:59:59 至 838:59:59 | HH:MM:SS | 时间值或持续时间 | |
| year | 1 | 1901 至 2155 | YYYY | 年份值 | |
| datetime | 8 | 1000-01-01 00:00:00 至 9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 | |
| timestamp | 4 | 1970-01-01 00:00:01 至 2038-01-19 03:14:07 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值,时间戳 |
设计表流程:
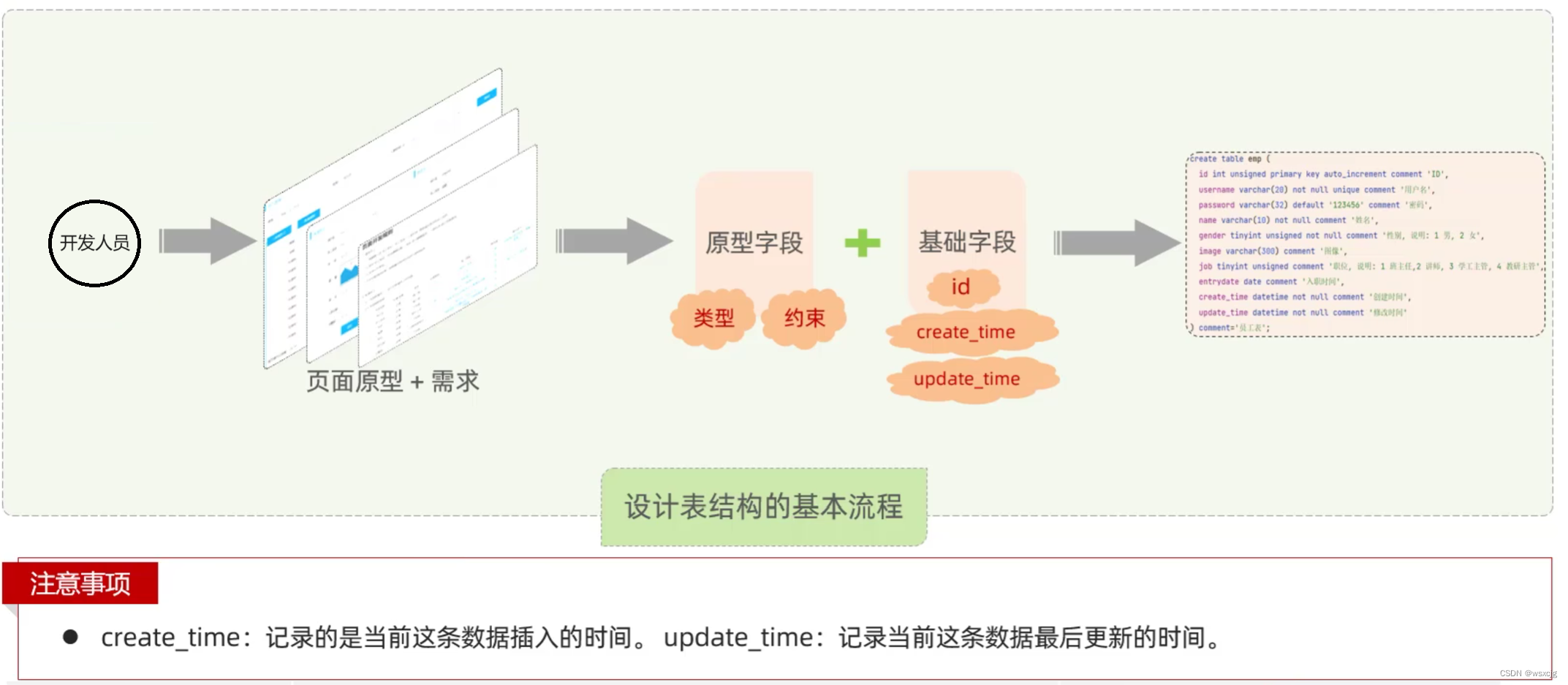
根据下面需求设计表
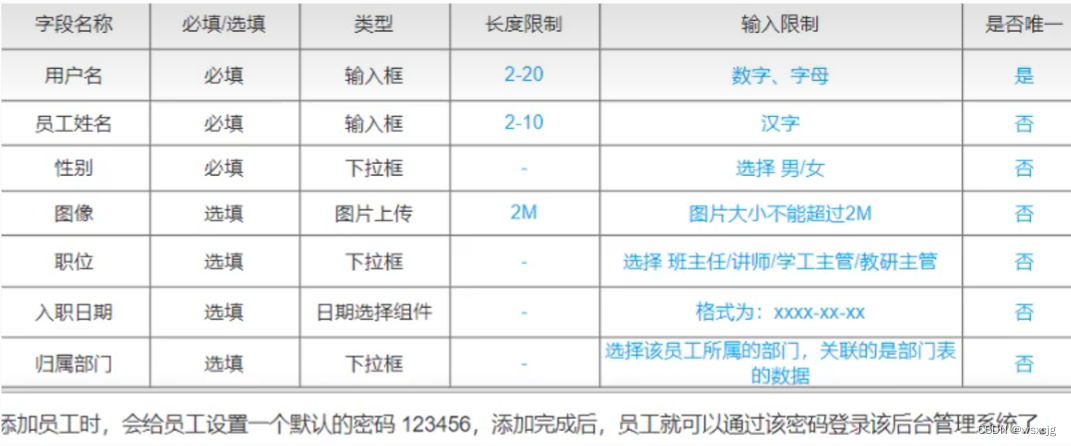
SQL代码:
CREATE TABLE `tb_emp` (`id` int NOT NULL AUTO_INCREMENT COMMENT 'ID',`username` varchar(20) NOT NULL COMMENT '用户名',`password` varchar(32) DEFAULT '123456' COMMENT '密码,默认123456',`name` varchar(10) NOT NULL COMMENT '员工姓名',`gender` tinyint unsigned NOT NULL COMMENT '性别 1:男 2:女',`image` varchar(30) DEFAULT NULL COMMENT '图像',`position` tinyint unsigned DEFAULT NULL COMMENT '职位 1:班主任 2:讲师 3:学工主管 4:校验主管',`joined_time` date DEFAULT NULL COMMENT '入职日期',`create_time` datetime NOT NULL COMMENT '创建日期',`update_time` datetime NOT NULL COMMENT '更新日期',PRIMARY KEY (`id`),UNIQUE KEY `tb_emp_pk_2` (`username`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci数据库操作:
DML:
添加数据:

注意事项:

代码演示:
-- 为tb_emp表的username,name,gender字段插入值
insert into tb_emp(username,name,gender,create_time,update_time) values('han','han',1,now(),now());-- 为tb_emp表的所有字段插入值
insert into tb_emp values(null,'jq','123','han',1,'1.jpg',1,'2000-10-10',now(),now());-- 批量为tb_emp表的username,name,gender字段插入值
insert into tb_emp(username,name,gender,create_time,update_time) values('ma','han',1,now(),now()),('zhao','han',1,now(),now());更新数据

注意事项:
![]()
代码演示:
-- 将tb_emp表的ID为1员工的姓名name字段更新为‘张三’
update tb_emp
set name = '张三',update_time = now()
where id = 1;-- 将tb_emp表的所有员工的入职日期更新为‘2010-01-01’
update tb_emp
set joined_time='2010-01-01',update_time = now();删除操作:

注意事项:

代码演示:
-- 删除tb_emp表中ID为1的员工
delete
from tb_emp
where id = 1;-- 删除tb_emp表中的所有员工
delete
from tb_emp;DQL:

基本查询:

注意事项:

代码演示:
-- 查询指定字段name,entrydate 并返回
select name, entrydate
from tb_emp;-- 查询所有字段并返回
-- 推荐
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp;
-- 不推荐
select *
from tb_emp;-- 查询所有员工的name,entrydate 并起别名(姓名,入职日期)
select name as '姓名', entrydate as '入职日期'
from tb_emp;-- 查询已有的员工关联了哪几种职位(不要重复)
select distinct job
from tb_emp;条件查询:

运算符:

代码演示:
-- 查询姓名为杨逍的员工
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name = '杨逍';-- 查询id小于等于5的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where id <= 5;-- 查询没有分配职位的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job is null;-- 查询有职位的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job is not null;-- 查询密码不等于'123456'的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where password != '123456';-- 查询入职日期在'2000-01-01'(包含)到'2010-01-01'(包含)之间的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where entrydate between '2000-01-01' and '2010-01-01';-- 查询入职日期在'2000-01-01'(包含)到'2010-01-01'(包含)之间且性别为女的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where entrydate between '2000-01-01' and '2010-01-01'and gender = 2;-- 查询职位是2(讲师),3(学工主管),4(校验主管)的员工信息
-- 第一种写法
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job = 2 or job = 3 or job = 4;
-- 第二种写法
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where job in (2,3,4);-- 查询姓名为两个字的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name like '__';-- 查询姓'张'的员工信息
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name like '张%';分组查询:
这里先讲解聚合函数,再讲解分组查询。
聚合函数:

注意事项:

代码演示:
-- 统计该企业员工的数量
-- 1.count(字段)
select count(id)
from tb_emp;
-- 2.count(常量)
select count('1')
from tb_emp;
-- 3.count(*)--推荐
select count(*)
from tb_emp;-- 统计该企业最早入职的员工
select min(entrydate)
from tb_emp;-- 统计该企业最迟入职的员工
select max(entrydate)
from tb_emp;-- 统计该企业员工ID的平均值
select avg(id)
from tb_emp;-- 统计该企业员工的ID之和
select sum(id)
from tb_emp;分组查询:

注意事项:

代码演示:
-- 根据性别分组,统计男性和女性员工的数量
select gender,count(*)
from tb_emp
group by gender;-- 先查询入职时间在'2015-01-01'(包含)以前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job,count(*)
from tb_emp
where entrydate <= '2015-01-01'
group by job
having count(*) >= 2;★where与having的区别
1.执行时机不同:where是分组前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
2.判断条件不同:where不能对聚合函数进行判断,而having可以。
排序查询:

排序方式:

注意事项:

代码演示:
-- 根据入职时间,对员工进行升序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate;-- 根据入职时间,对员工进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate DESC;-- 根据入职时间对公司的员工进行升序排序,入职时间相同,再按照更新时间进行降序排序
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
order by entrydate, update_time DESC;
分页查询:

注意事项:

代码演示:
-- 从起始索引0开始查询员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 0,5;-- 查询第一页员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 0,5;-- 查询第二页员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 5,5;-- 查询第三页员工数据,每页展示5条记录
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
limit 10,5;案例:
下面给出三个案例,案例中还用到了这两个函数
if函数和case函数

代码演示:
-- 查找 名字里有张,性别男,入职日期在2000-01-01到2015-12-31之间的员工
select id, username, password, name, gender, image, job, entrydate, create_time, update_time
from tb_emp
where name like '%张%'and gender = 1and entrydate between '2000-01-01' and '2015-12-31'
order by update_time DESC
limit 10,10;-- 员工性别统计
select if(gender = 1, '男性员工', '女性员工') as 性别,count(*)
from tb_emp
group by gender;-- 员工职位统计
select(case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管'when 4 then '教研主管' else '未分配职位' end) 职位,count(*)
from tb_emp
group by job;多表设计:
一对多:
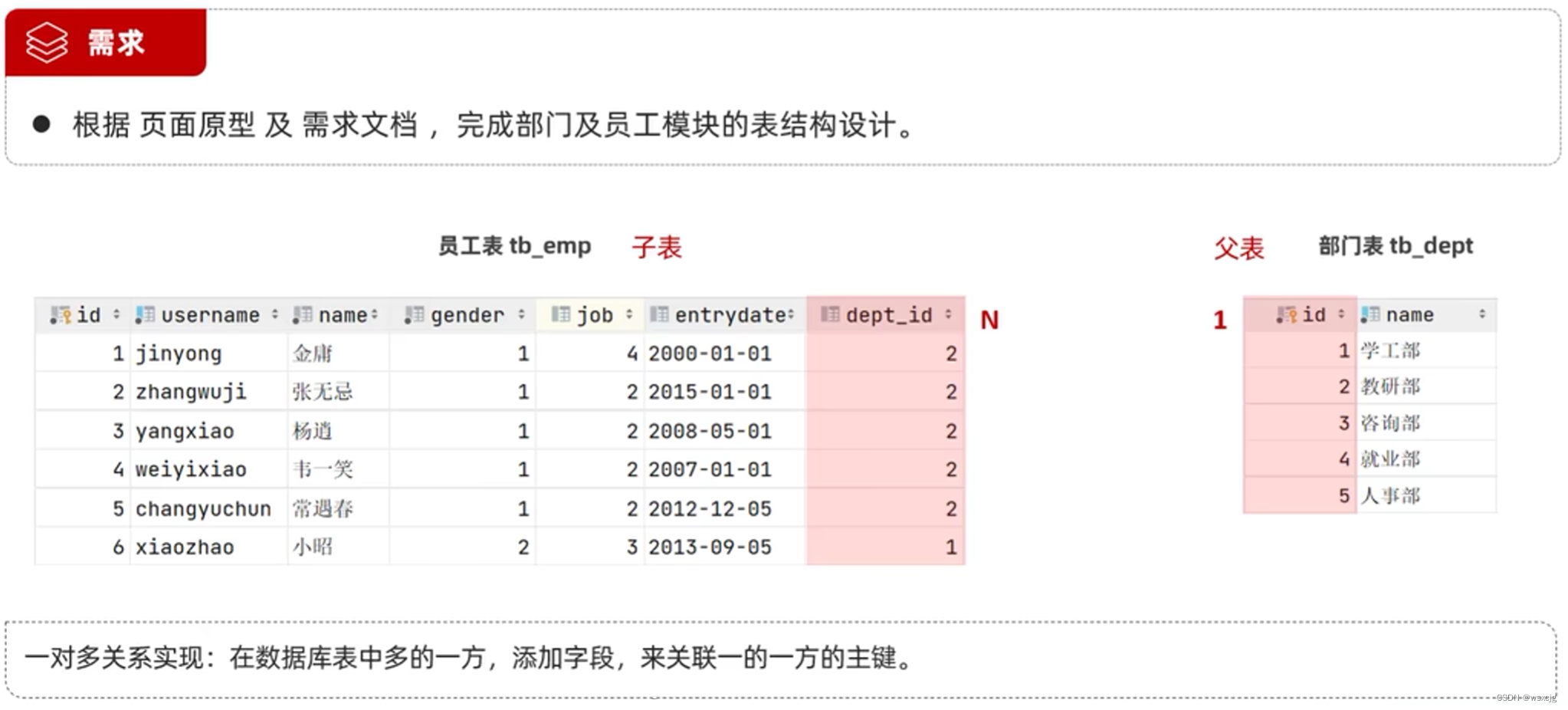
多表问题分析:


外键约束:


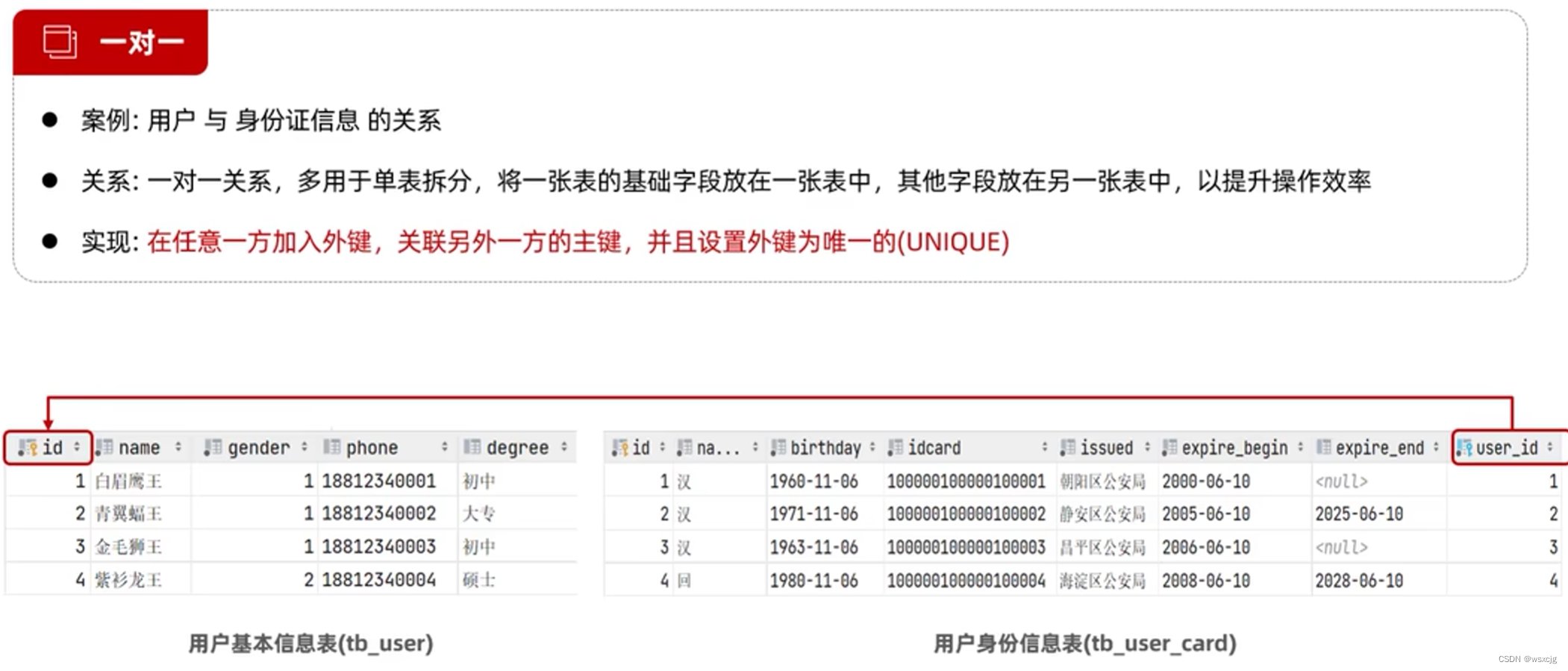
一对一:
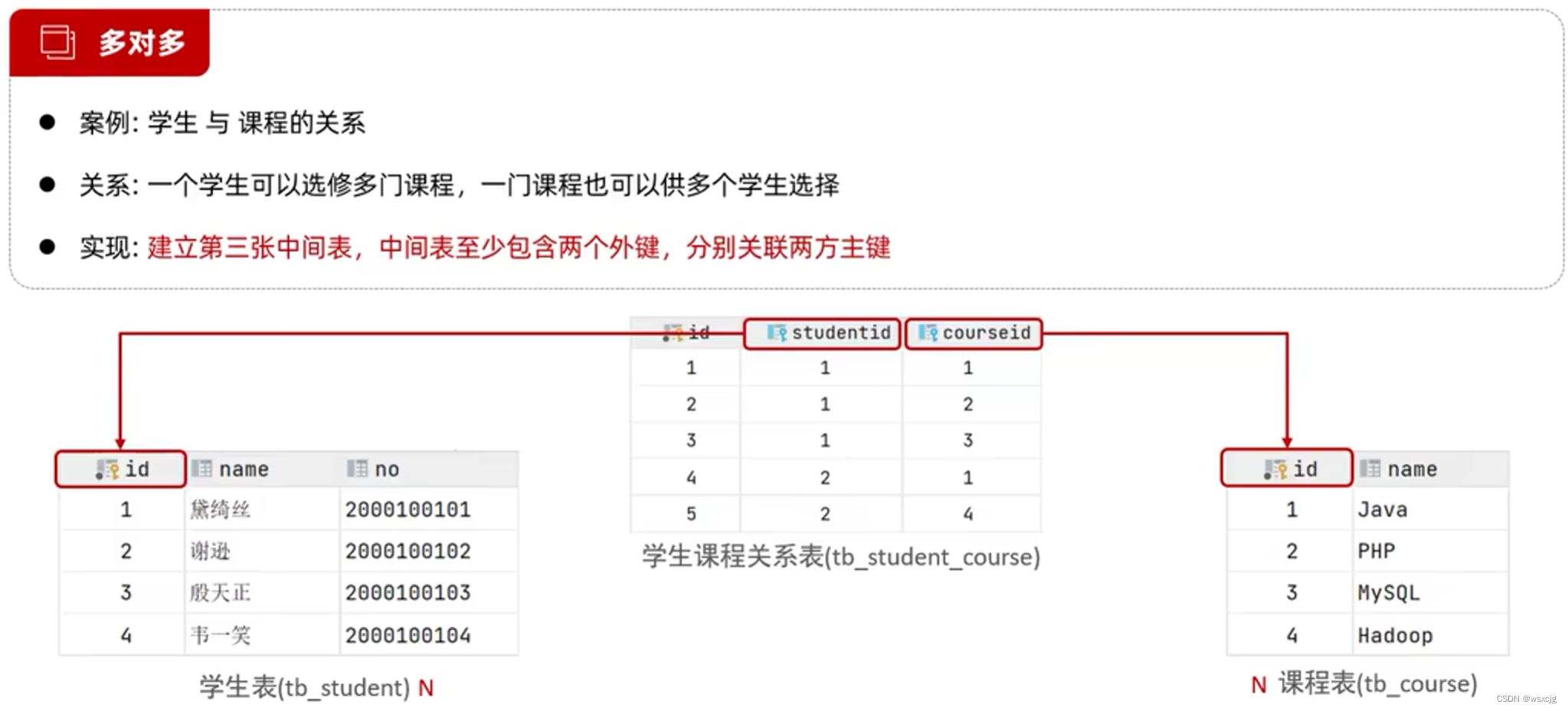
多对多:
小结:

多表查询:
从多张表中查询数据
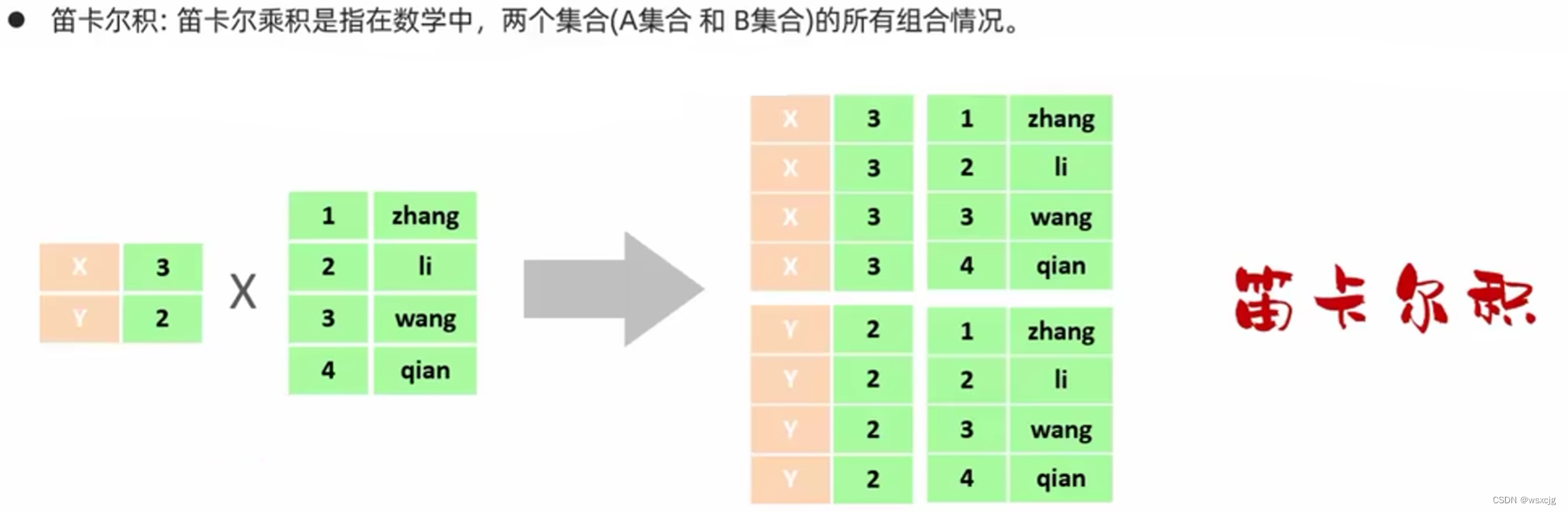
笛卡尔积:
直接在from后加入多个表会出现这多个表的笛卡尔积个数据,在多表查询时,需要消除无效的笛卡尔积。
连接方式:

内连接:

代码演示:
-- 查询员工的姓名,及所属的部门名称(隐式内连接实现)
select tb_emp.name, tb_dept.name
from tb_emp,tb_dept
where tb_emp.dept_id = tb_dept.id;
-- 起别名 --简洁
select e.name,d.name
from tb_dept d,tb_emp e
where d.id = e.dept_id;-- 查询员工的姓名,及所属的部门名称(显式内连接实现)
select tb_emp.name, tb_dept.name
from tb_empjoin tb_depton tb_emp.dept_id = tb_dept.id;外连接:

代码演示:
-- 查询员工表所有员工的姓名和对应的部门名称(左外连接)
select e.name,d.name
from tb_emp eleft join tb_dept don e.dept_id = d.id;-- 查询部门表所有部门名称和对应的员工的姓名(右外连接)
select e.name,d.name
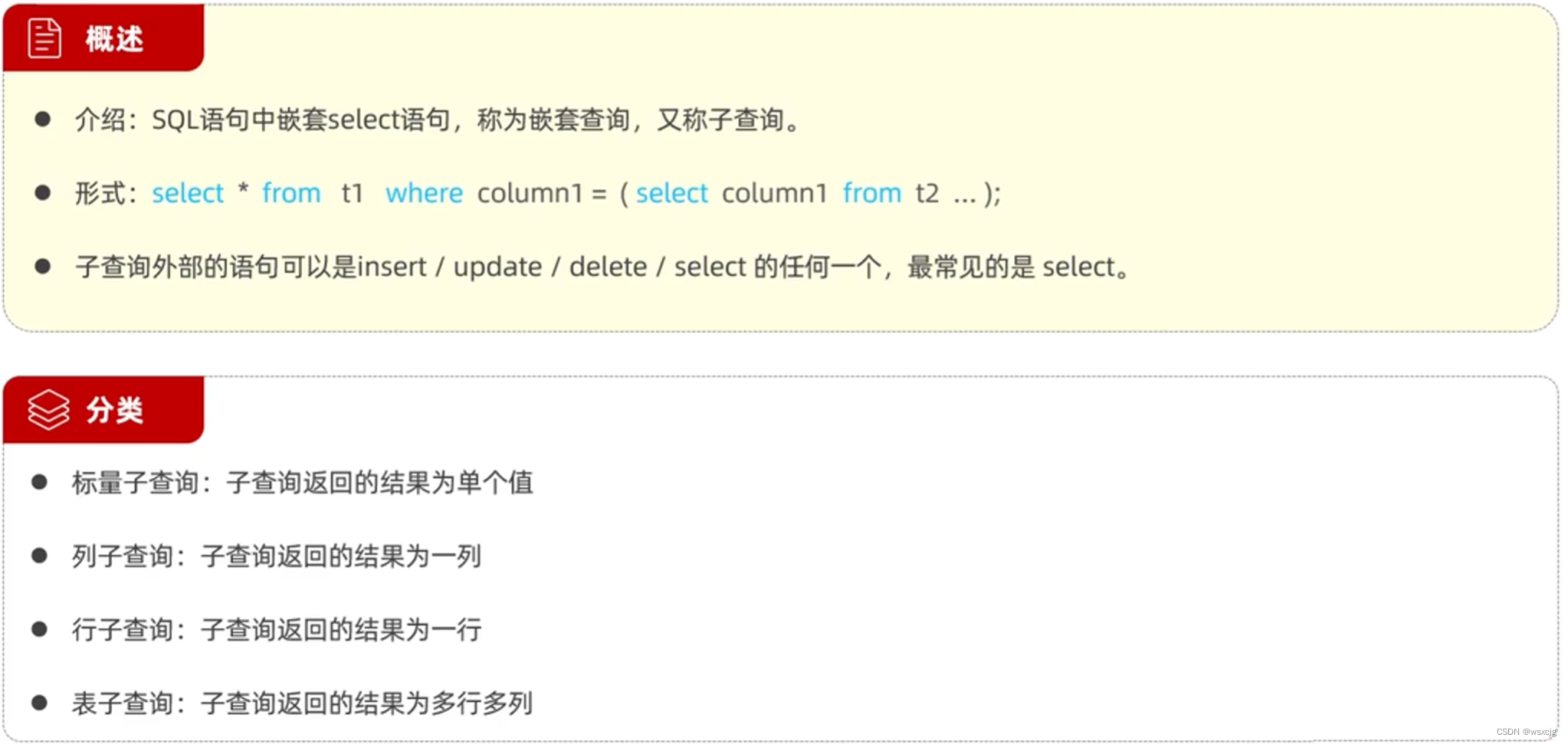
from tb_emp eright join tb_dept don e.dept_id = d.id;子查询:
标量子查询:

代码演示:
-- 查询教研部的所有员工信息
select *
from tb_emp
where dept_id = (select idfrom tb_deptwhere name = '教研部');-- 查询在方东白入职之后的员工信息
select *
from tb_emp
where entrydate > (select entrydatefrom tb_empwhere name = '方东白');列子查询

代码演示:
-- 查询教研部和咨询部的所有员工信息
select *
from tb_emp
where dept_id in (select idfrom tb_deptwhere name in ('教研部', '咨询部'));行子查询:

代码演示:
-- 查询与韦一笑的入职日期及职位都相同的员工信息
select *
from tb_emp
where (entrydate, job) = (select entrydate, jobfrom tb_empwhere name = '韦一笑');表子查询:

代码演示:
-- 查询入职日期是2006-01-01之后的员工信息,及其部门名称
select e.*, d.name
from (select *from tb_empwhere entrydate > '2006-01-01') e,tb_dept d
where e.dept_id = d.id;案例:
-- 1. 查询价格低于 10元 的菜品的名称 、价格 及其 菜品的分类名称 .
select d.name,d.price,c.name
from dish d,category c
where d.category_id = c.idand d.price < 10;-- 2. 查询所有价格在 10元(含)到50元(含)之间 且 状态为'起售'的菜品名称、价格 及其 菜品的分类名称 (即使菜品没有分类 , 也需要将菜品查询出来).
select d.name,d.price,c.name
from dish dleft join category con d.category_id = c.id
where d.price between 10 and 50and d.status = 1;-- 3. 查询每个分类下最贵的菜品, 展示出分类的名称、最贵的菜品的价格 .
select c.name, max(d.price)
from category c,dish d
where c.id = d.category_id
group by c.id;-- 4. 查询各个分类下 状态为 '起售' , 并且 该分类下菜品总数量大于等于3 的 分类名称 .
select c.name
from category c,dish d
where c.id = d.category_idand d.status = 1
group by c.name
having count(*) >= 3;-- 5. 查询出 "商务套餐A" 中包含了哪些菜品 (展示出套餐名称、价格, 包含的菜品名称、价格、份数).
select s.name, s.price, d.name, d.price, sd.copies
from dish d,setmeal_dish sd,setmeal s
where d.id = sd.dish_idand sd.setmeal_id = s.idand s.name = '商务套餐A';-- 6. 查询出低于菜品平均价格的菜品信息 (展示出菜品名称、菜品价格).
select d.name, d.price
from dish d
where d.price < (select avg(d.price)from dish d);事务:
使用场景:
介绍:

操作:

★事物的四大特性(ACID):

索引:

优缺点:

索引的缺点到目前影响已经很小,因为第一点企业的磁盘空间很大,索引占用的空间与之相比很小,第二点数据查询业务基本占总体业务的百分之九十,所以降低增删改效率影响也不大。
结构:

思考:为什么索引结构不采用二叉搜索树和红黑树?
答:因为在大数据情况下,树的层次深,检索速度慢
B+Tree(多路平衡搜索树):
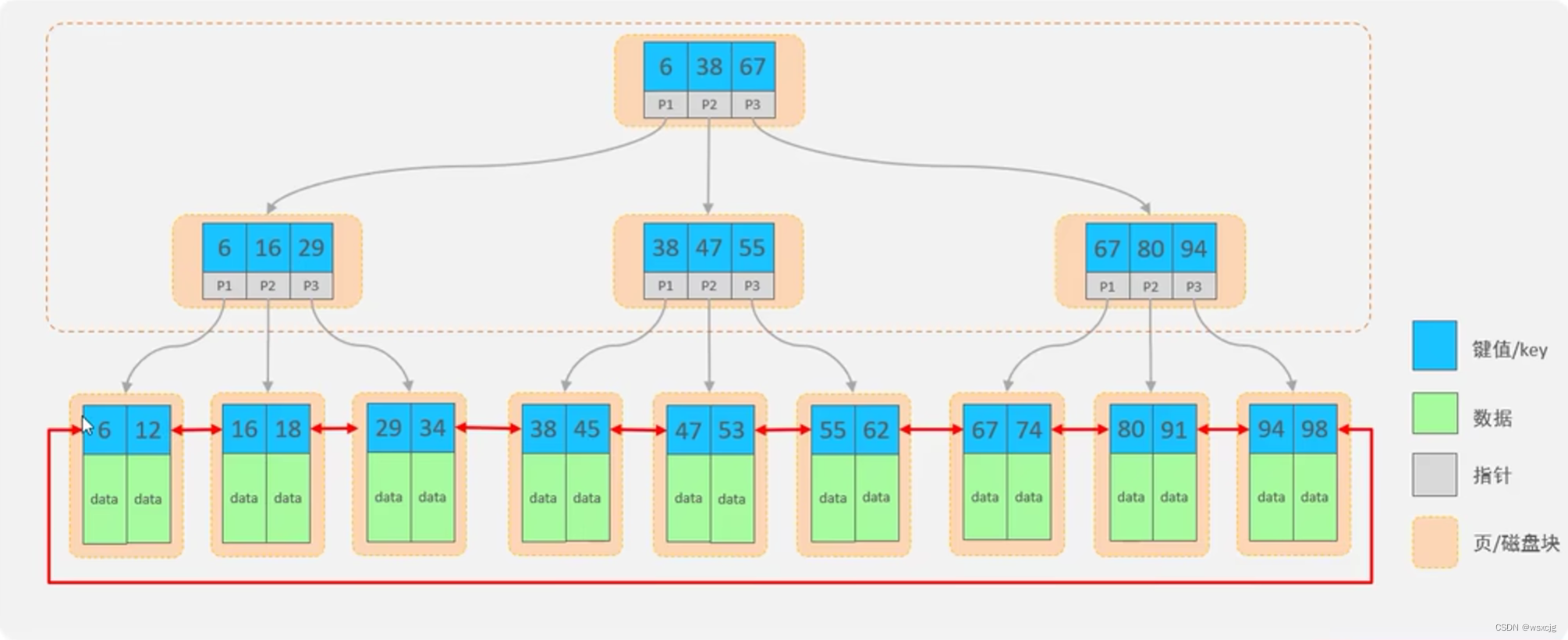
特点:

代码演示:
-- 创建:为tb_emp表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);-- 查询:查询tb_emp表的索引信息
show index from tb_emp;-- 删除:删除tb_emp表中的name字段的索引
drop index idx_emp_name on tb_emp;注意事项:

主键索引性能最高
相关文章:
JavaWeb_MySQL数据库
数据库: MySQL数据模型: MySQL是关系型数据库。 SQL: 简介 分类: 数据库设计-DDL 对数据库操作: 表操作: 小练习: 创建下表 SQL代码: create table tb_user (id int primar…...

中国BI步入增长大周期,腾讯云ChatBI加速AI+BI融合
过去十年,大数据技术的快速发展,让数据消费前进一大步,数据价值得到一定程度的挖掘与释放,真正开启了“用数”的大时代。但数据分析繁杂的技术栈、复杂的处理过程以及程式化的交互方式,让“数据消费”的门槛始终降不下…...
揭秘Python:下划线的特殊用法,你绝对想不到!
在Python编程中,下划线(underscore)是一个常见而又强大的工具。它不仅仅是一个普通的字符,而是具有特殊含义和用法的符号。今天,我们就来揭开Python下划线的神秘面纱,探索它的各种妙用。 下划线的基本用法…...

深入探索Java世界中的Jackson魔法:玩转JsonNode
哈喽,大家好,我是木头左! 揭秘Jackson库:JSON处理的瑞士军刀 在Java的世界里,处理JSON数据就像是一场探险。幸运的是,Jackson库就像一把多功能的瑞士军刀,为提供了强大而灵活的工具来解析和操作…...

为什么要使用动态代理IP?
一、什么是动态代理IP? 动态代理IP是指利用代理服务器来转发网络请求,并通过不断更新IP地址来保护访问者的原始IP,从而达到匿名访问、保护隐私和提高访问安全性的目的。动态代理IP在多个领域中都有广泛的应用,能够帮助用户…...
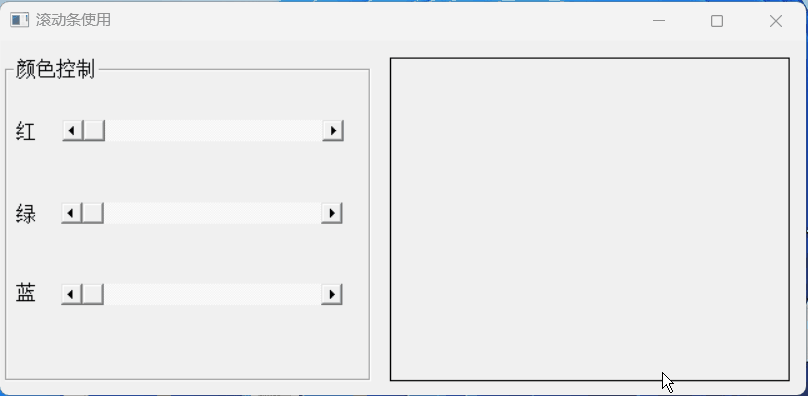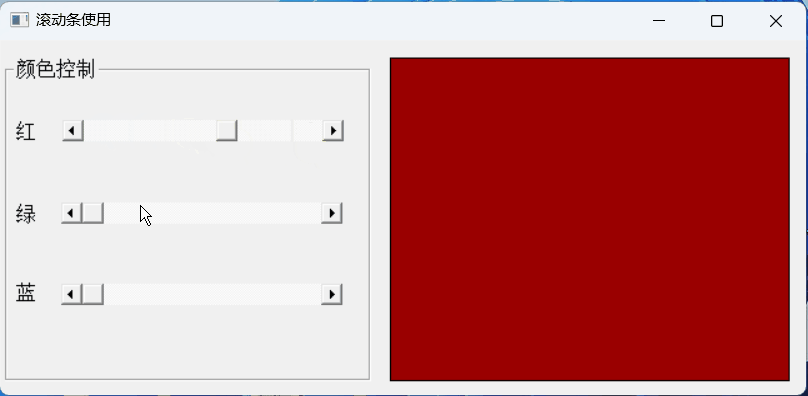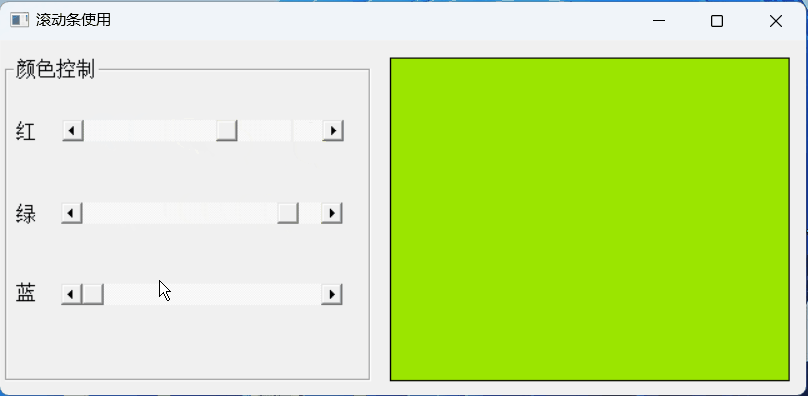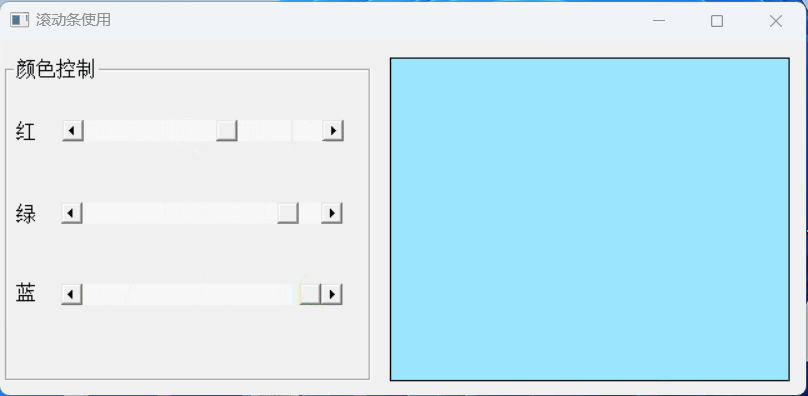
【PB案例学习笔记】-09滚动条使用
写在前面 这是PB案例学习笔记系列文章的第8篇,该系列文章适合具有一定PB基础的读者。 通过一个个由浅入深的编程实战案例学习,提高编程技巧,以保证小伙伴们能应付公司的各种开发需求。 文章中设计到的源码,小凡都上传到了gitee…...

C++中常见的构造函数类别
目录 摘要 默认构造函数(Default Constructor): 带参数的构造函数(Parameterized Constructor): 拷贝构造函数(Copy Constructor): 移动构造函数(Move C…...
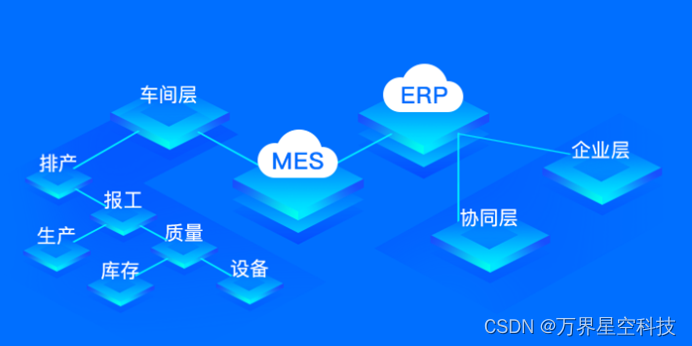
万界星空科技MES系统功能介绍
制造执行系统或MES 是一个全面的动态软件系统,用于监视、跟踪、记录和控制从原材料到成品的制造过程。MES在企业资源规划(ERP) 和过程控制系统之间提供了一个功能层,为决策者提供了提高车间效率和优化生产所需的数据。 万界星空科技MES 系统基础功能&am…...

炸裂的开源AI语音生成模型ChatTTS
今天看到GitHub上开源了一个非常厉害的AI语音生成模型ChatTTS,可以生成和人类声音非常接近的语音,而且有语气、语调、可以停顿和发出笑声,再也没有了以前的AI味道 体验地址:https://colab.research.google.com/drive/1MYep5f0-BJ…...
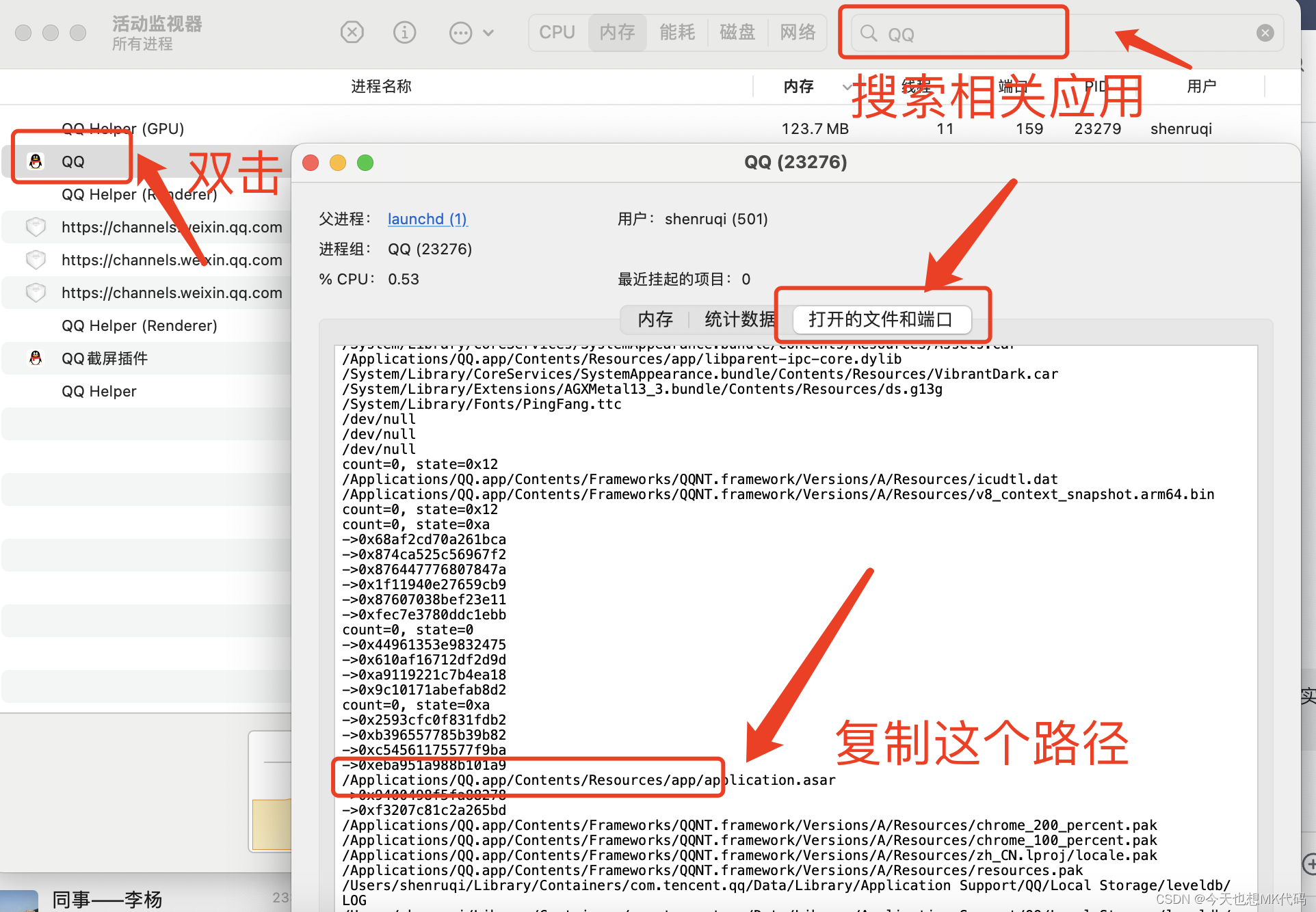
Mac逆向Electron应用
工具库 解压asar文件 第一步 找到应用文件夹位置 打开活动监视器: 搜索相关应用 用命令行打开刚才复制的路径即可 open Applications/XXX.app/Contents/Resources/app第二步 解压打包文件 解压asar文件...
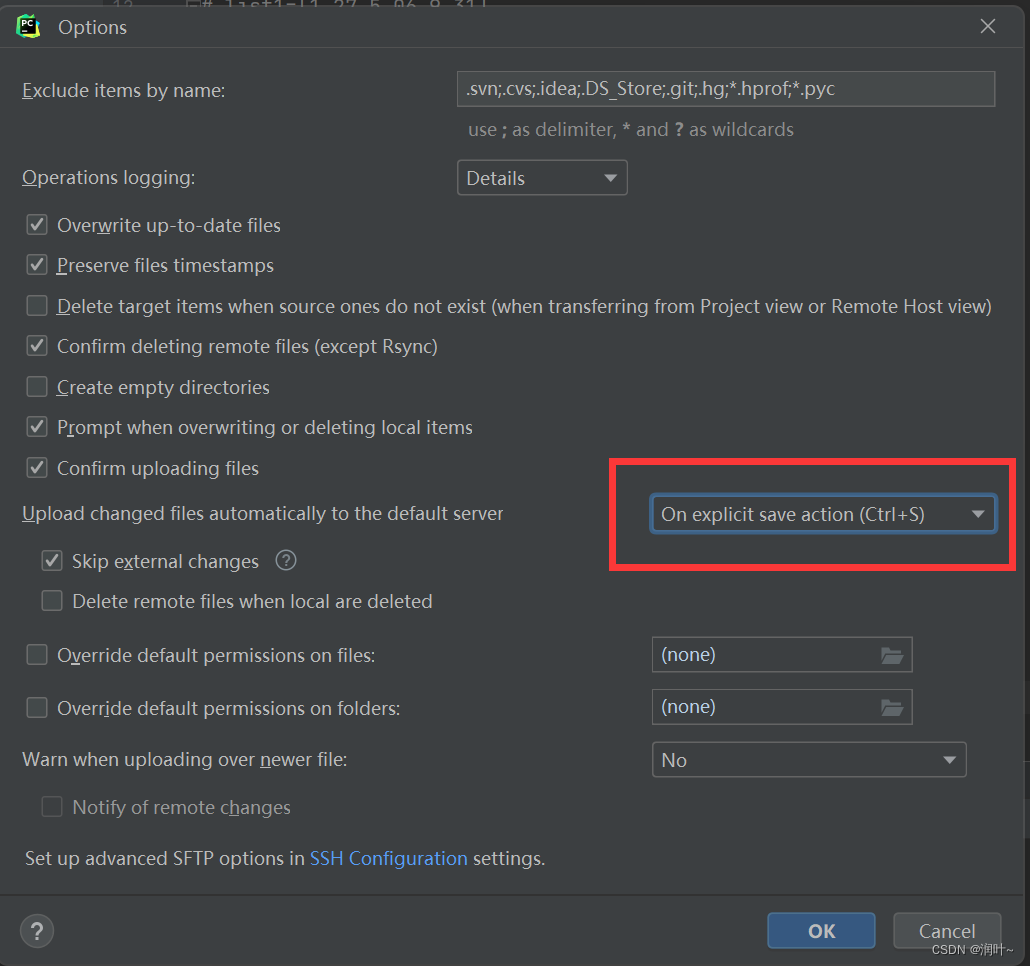
(三)MobaXterm、VSCode、Pycharm ssh连接服务器并使用
背景:根据前两篇文章操作完成后, 手把手教学,一站式安装ubuntu及配置服务器-CSDN博客 手把手教学,一站式教你实现服务器(Ubuntu)Anaconda多用户共享-CSDN博客 课题组成员每人都有自己的帐号了࿰…...
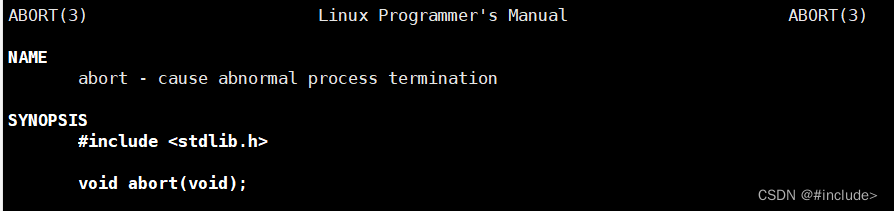
【Linux】初识信号及信号的产生
初始信号 初始信号什么是信号站在应用角度的信号查看Linux系统定义的信号列表 信号的常见处理方式信号的产生通过终端按键产生信号什么是core dump?如何开启core dump?core dump有什么用?为什么默认关闭core dump?设置了core文件大小但是没有产生core文…...

故障诊断 | 基于 KAN、KAN卷积的轴承故障诊断模型
研究背景: 轴承是机械设备中常见的关键部件之一,其工作状态直接影响设备的性能和可靠性。因此,轴承故障的早期诊断对于设备的正常运行和维护具有重要意义。近年来,基于振动信号的轴承故障诊断成为了研究的热点之一。KAN: Kolmogorov-Arnold Network 是一种有效的处理方法。…...

【设计模式】JAVA Design Patterns——Factory Method(虚拟构造器模式)
🔍目的 为创建一个对象定义一个接口,但是让子类决定实例化哪个类。工厂方法允许类将实例化延迟到子类 🔍解释 真实世界例子 铁匠生产武器。精灵需要精灵武器,而兽人需要兽人武器。根据客户来召唤正确类型的铁匠。 通俗描述 它为类…...

Spring——依赖项
文章目录 依赖注入基于构造函数的依赖注入基于 Setter 的依赖注入依赖解析过程依赖注入的示例 依赖关系和配置详细信息直接值(原语、字符串等)idref标签References to Other Beans (对其他 Bean的引用)Inner Beans(内部…...
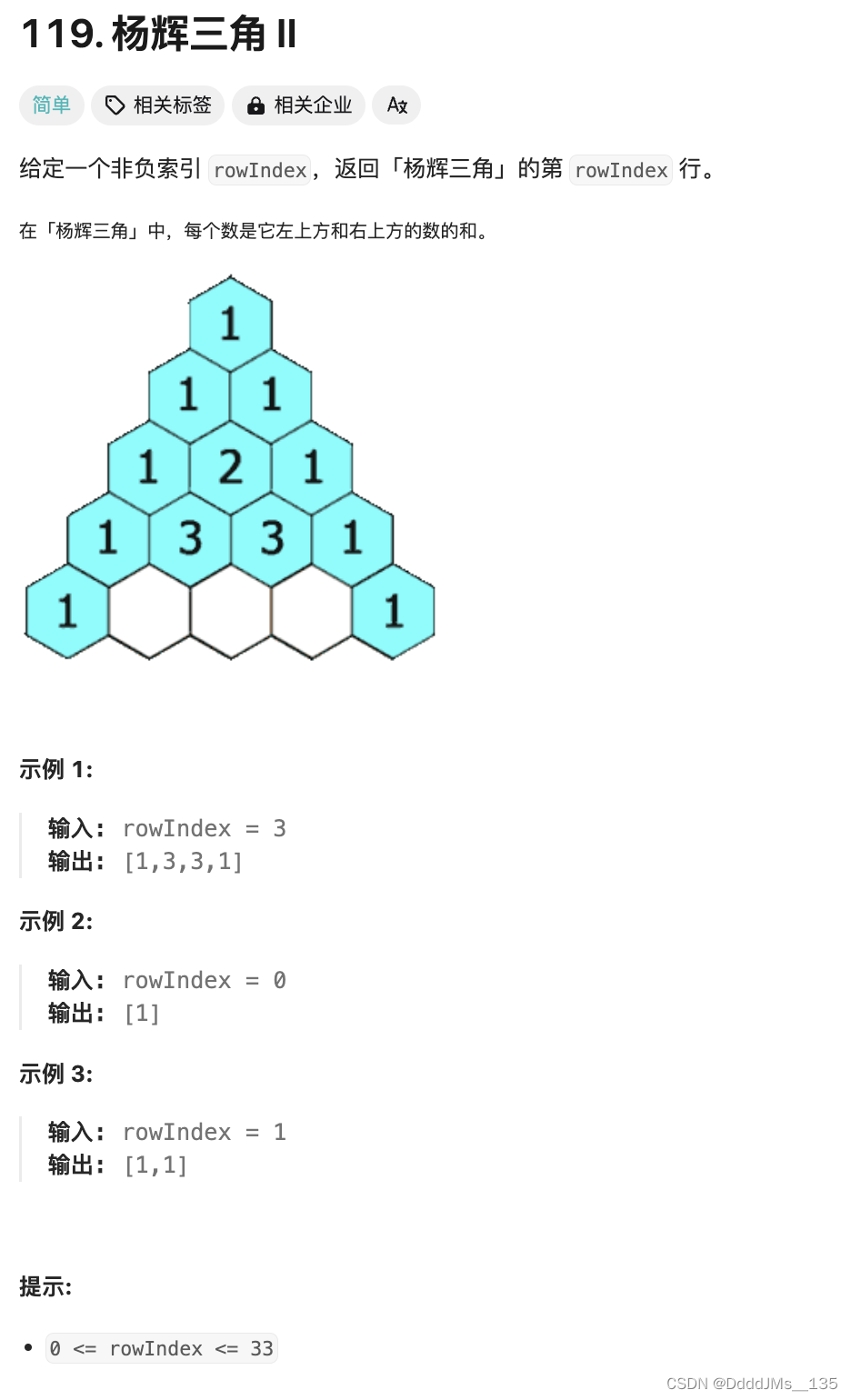
C语言 | Leetcode C语言题解之第119题杨辉三角II
题目: 题解: int* getRow(int rowIndex, int* returnSize) {*returnSize rowIndex 1;int* row malloc(sizeof(int) * (*returnSize));row[0] 1;for (int i 1; i < rowIndex; i) {row[i] 1LL * row[i - 1] * (rowIndex - i 1) / i;}return row…...

深入分析 Android Service (一)
文章目录 深入分析 Android Service (一)1. Android Service 设计说明1.1. Service 的类型1.2. Service 的生命周期1.3. 创建和启动 Service1.4. 绑定 Service1.5. ServiceConnection1.6. 前台 Service1.7. IntentService示例:创建和使用 IntentService 2. Service …...

英飞凌24GHz毫米波雷达-BGT24LTR11N16家用机器人应用
BGT24LTR11N16基础描述: 关于BGT24LTR11N16,它是一款用于信号生成和接收的硅锗雷达MMlC,工作频率为24.00GHz至24.25GHz ISM频段。它基于24GHz基本电压控制振荡器(VCO)。 这颗芯片是属于1T1R,也就是一发一收…...

17.js字符串
字符串创建 1.字面量创建 var 字符串名字符串 2.内部构造函数创建 var 字符串名new String(字符串) length属性 只能读取不能设置 var strabcdfegfglconsole.log(str.length) //10str.length5 console.log(str) //不能写 abcdfegfgl index属性 只能读不能设置 var strab…...
JS-51-Node.js10-yarn
一、yarn的简介 Yarn 是一款 JavaScript 的包管理工具(npm的代替方案),是 Facebook, Google, Exponent 和 Tilde 开发的一款新的 JavaScript 包管理工具。 正如 Yarn 官网的介绍,Yarn 的具有速度快 、安全 、可靠 的优点&#x…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...
)
手把手教你给STM32MP157开发板接上HDMI显示器(基于Sii9022A芯片与设备树配置)
STM32MP157开发板HDMI显示实战:从硬件连接到设备树配置全解析 引言 当你第一次拿到STM32MP157开发板时,最令人兴奋的莫过于看到图形界面在屏幕上亮起的那一刻。但现实往往很骨感——手头可能没有配套的LCD屏幕,而HDMI显示器却是大多数开发者桌…...

终极跨平台漫画阅读方案:nhentai-cross全平台使用指南
终极跨平台漫画阅读方案:nhentai-cross全平台使用指南 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 你是否厌倦了在不同设备间切换漫画阅读应用?nhentai-cross正是为你量身定制…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南
如何3秒破解百度网盘提取码难题:开源工具baidupankey的技术解析与实战指南 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否曾在寻找百度网盘资源时,被一个小小的提取码卡住,不得不花费…...

CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题
CompressO:终极跨平台视频图片压缩神器,轻松解决存储难题 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirrors/…...

轻量级工作流引擎pro-workflow:Go语言实现与实战解析
1. 项目概述:一个为专业开发者量身打造的工作流引擎如果你是一名开发者,尤其是经常需要处理复杂业务逻辑、数据流转或自动化任务的后端或全栈工程师,那么你一定对“工作流”这个概念不陌生。从简单的审批流到复杂的微服务编排,工作…...

Claude-Code-KnowCraft:轻量级代码知识库构建与智能问答实践
1. 项目概述与核心价值最近在跟几个做AI应用开发的朋友聊天,大家普遍有个痛点:想把Claude这类大语言模型(LLM)的能力深度集成到自己的代码库分析工具里,但发现现有的方案要么太重,要么太浅。太重的是指那些…...
从零构建大语言模型:Transformer架构、训练技巧与实战指南
1. 项目概述:从零构建你自己的大语言模型最近几年,大语言模型(LLM)的热度居高不下,从ChatGPT到Claude,再到国内外的各种开源模型,它们展现出的理解和生成能力让人惊叹。但你是否也和我一样&…...
)
【2026年阿里巴巴集团暑期实习- 5月16日-算法岗-第二题- 坏掉的键盘】(题目+思路+JavaC++Python解析+在线测试)
题目内容 小明准备输入一个仅由小写英文字母组成的字符串,但他的键盘在一开始就有且仅有一个按键失灵,导致该字母在原串中的所有出现都没有被输入,最终得到的字符串为 sss。小明还告诉你:原本要输入的完整字符串中任意相邻两个字符都不相同。 请你计算,对于每一个可能的…...