SpringBoot整合Kafka的快速使用教程
目录
一、引入Kafka的依赖
二、配置Kafka
三、创建主题
1、自动创建(不推荐)
2、手动动创建
四、生产者代码
五、消费者代码
六、常用的KafKa的命令
Kafka是一个高性能、分布式的消息发布-订阅系统,被广泛应用于大数据处理、实时日志分析等场景。Spring Boot作为目前最流行的Java开发框架之一,其简洁的配置和丰富的工具使得与Kafka的集成变得更加容易。本文将介绍如何使用Spring Boot整合Kafka,实现高效的数据处理和消息传递。
一、引入Kafka的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-kafka</artifactId>
</dependency>
二、配置Kafka
spring:kafka:bootstrap-servers: 156.65.20.76:9092,156.65.20.77:9092,156.65.20.78:9092 #指定Kafka集群的地址,这里有三个地址,用逗号分隔。listener:ack-mode: manual_immediate #设置消费者的确认模式为manual_immediate,表示消费者在接收到消息后立即手动确认。concurrency: 3 #设置消费者的并发数为3missing-topics-fatal: false #设置为false,表示如果消费者订阅的主题不存在,不会抛出异常。producer:key-serializer: org.apache.kafka.common.serialization.StringSerializer # 设置消息键的序列化器value-serializer: org.apache.kafka.common.serialization.StringSerializer #设置消息值的序列化器acks: 1 #一般就是选择1,兼顾可靠性和吞吐量 ,如果想要更高的吞吐量设置为0,如果要求更高的可靠性就设置为-1consumer:auto-offset-reset: earliest #设置为"earliest"表示将从最早的可用消息开始消费,即从分区的起始位置开始读取消息。enable-auto-commit: false #禁用了自动提交偏移量的功能,为了避免出现重复数据和数据丢失,一般都是手动提交key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 设置消息键的反序列化器value-deserializer: org.apache.kafka.common.serialization.StringDeserializer #设置消息值的反序列化器注:kafka的acks有三个值,可以根据实际情况和需求平衡消息系统的吞吐量和数据安全性,来选择对应的值。
acks=0:这是最不可靠的模式。当设置为acks=0时,生产者在发送消息后不会等待任何服务器端的确认响应。这种模式下,生产者可以迅速继续发送下一批消息,效率最高,但风险也最大。如果在此模式下发生网络问题或broker故障,发送的消息可能会永久丢失,生产者无法得知消息是否成功到达Kafka broker。因此,这种配置适合于能够容忍少量数据丢失的场景,例如实时数据分析或生成非关键的实时报表。acks=1:这是默认的配置模式,也是一种折衷方案。在这种模式下,生产者会等待分区的领导者节点(leader)确认消息已经成功写入磁盘,才会发送确认信息给生产者。这提高了数据的安全性,因为只要领导者节点保存了消息,即使跟随者(replicas)没有及时同步,消息也不会丢失。然而,如果领导者在同步给所有追随者之前崩溃,那么尚未同步的副本将无法获取该消息,仍然存在消息丢失的风险。acks=all或-1:这是最可靠的模式。在这个模式下,生产者不仅需要领导者节点确认,还会等待所有同步副本(In-sync replicas, ISR)都确认写入消息后才会收到确认。这极大地增强了数据的持久性保证,确保了即使在多个节点故障的情况下,消息也不会丢失。此模式适用于数据可靠性要求非常高的场景,如金融交易系统或重要的日志记录
三、创建主题
1、自动创建(不推荐)
不存在的主题,会自动创建,分区数和副本数均为默认值。而默认值可能会不符合某些场景的要求。
在kafka的安装目录conf目录下找到该配置文件server.properties,添加如下配置:
num.partitions=3 #默认3个分区
auto.create.topics.enable=true #开启自动创建主题
default.replication.factor=3 #默认3个副本
2、手动动创建
在kafka的安装目录bin目录下,执行如下命令:
//创建一个有三个分区和三个副本,名为zhuoye的主题
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic zhuoye
四、生产者代码
@Slf4j
@Component
public class ALiYunServiceImpl implents IALiYunService {@Autowiredprivate KafkaTemplate kafkaTemplate;@Autowiredprivate ExecutorService executorService;String topicName = "zhuoye";@Overridepublic void queryECSMetricInfo() {//发送到kafka的消息集合,因为使用了多线程,并且在多线程中往该集合进行添加操作,所以需要线程安全的List<Message> messages = Collections.synchronizedList(new ArrayList<>());boolean flag = true;//获取上次查询时间Long startTime = Long.valueOf(queryTimeRecordMapper.selectTimeByBelongId(3)) * 1000;Long endTime = System.currentTimeMillis();try {//查询出所有的运行中的实例List<CloudInstanceAssetDto> cloudInstances = cloudInstanceAssetMapper.queryAllRunningInstance(1, "Running");if (CollectionUtils.isEmpty(cloudInstances)) {return;}//定义计数器CountDownLatch latch = new CountDownLatch(cloudInstances.size());//遍历查询for (CloudInstanceAssetDto instance : cloudInstances) {executorService.submit(() -> {try {//获取内网流出带宽,并将结果封装到消息集合中dealMetricDataToMessage(ALiYunConstant.ECS_INTRANET_OUT_RATE, ALiYunConstant.INTRANET_OUT_RATE_NAME, ALiYunConstant.LW_INTRANET_OUT_RATE_CODE,startTime, endTime, instance, messages);} catch (Exception e) {log.error("获取ECS的指标数据-多线程处理任务异常!", e);} finally {latch.countDown();}});}//等待任务执行完毕latch.await();//将最终的消息集合发送到kafkaif (CollectionUtils.isNotEmpty(messages)) {for (int i = 0; i < messages.size(); i++) {if (StringUtils.isNotBlank(messages.get(i).getValue())&& "noSuchInstance".equals(messages.get(i).getValue())) {continue;}kafkaTemplate.send(topicName, messages.get(i));}}} catch (Exception e) {flag = false;log.error("获取ECS的指标数据失败", e);}//更新记录上次查询时间if (flag) {QueryTimeRecord queryTimeRecord = new QueryTimeRecord();queryTimeRecord.setBelongId(3).setLastQueryTime(String.valueOf((endTime - 1000 * 60 * 1) / 1000)); //开始时间往前推1分钟queryTimeRecordMapper.updateByBelongId(queryTimeRecord);}}这个时候,如果你想看有没有把消息发送到kafka的指定主题可以使用如下命令:
kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic zhuoye
五、消费者代码
@Slf4j
@Component
public class KafkaConsumer {// 消费监听@KafkaListener(topics = "zhuoye",groupId ="zhuoye-aliyunmetric")public void consumeExtractorChangeMessage(ConsumerRecord<String, String> record, Acknowledgment ack){try {String value = record.value();//处理数据,存入openTsDb.................................ack.acknowledge();//手动提交}catch (Exception e){log.error("kafa-topic【zhuoye】消费阿里云指标源消息【失败】");log.error(e.getMessage());}}
}六、常用的KafKa的命令
//创建主题
./kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 3 --topic zhuoye
//查看kafka是否接收对应的消息
kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic zhuoye
// 修改kafka-topic分区数
./kafka-topics.sh --zookeeper localhost:2181 -alter --partitions 6 --topic zhuoye
// 查看topic分区数
./kafka-topics.sh --zookeeper localhost:2181 --describe --topic zhuoye
// 查看用户组消费情况
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group zhuoye-aliyunmetric --describe
相关文章:

SpringBoot整合Kafka的快速使用教程
目录 一、引入Kafka的依赖 二、配置Kafka 三、创建主题 1、自动创建(不推荐) 2、手动动创建 四、生产者代码 五、消费者代码 六、常用的KafKa的命令 Kafka是一个高性能、分布式的消息发布-订阅系统,被广泛应用于大数据处理、实时日志分析等场景。Spring B…...
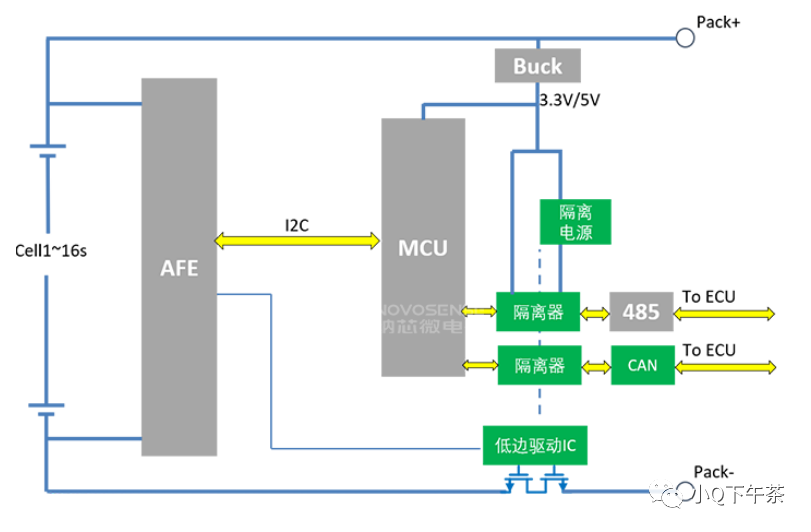
低边驱动与高边驱动
一.高边驱动和低边驱动 低边驱动(LSD): 在电路的接地端加了一个可控开关,低边驱动就是通过闭合地线来控制这个开关的开关。容易实现(电路也比较简单,一般由MOS管加几个电阻、电容)、适用电路简化和成本控制的情况。 高边驱动&am…...
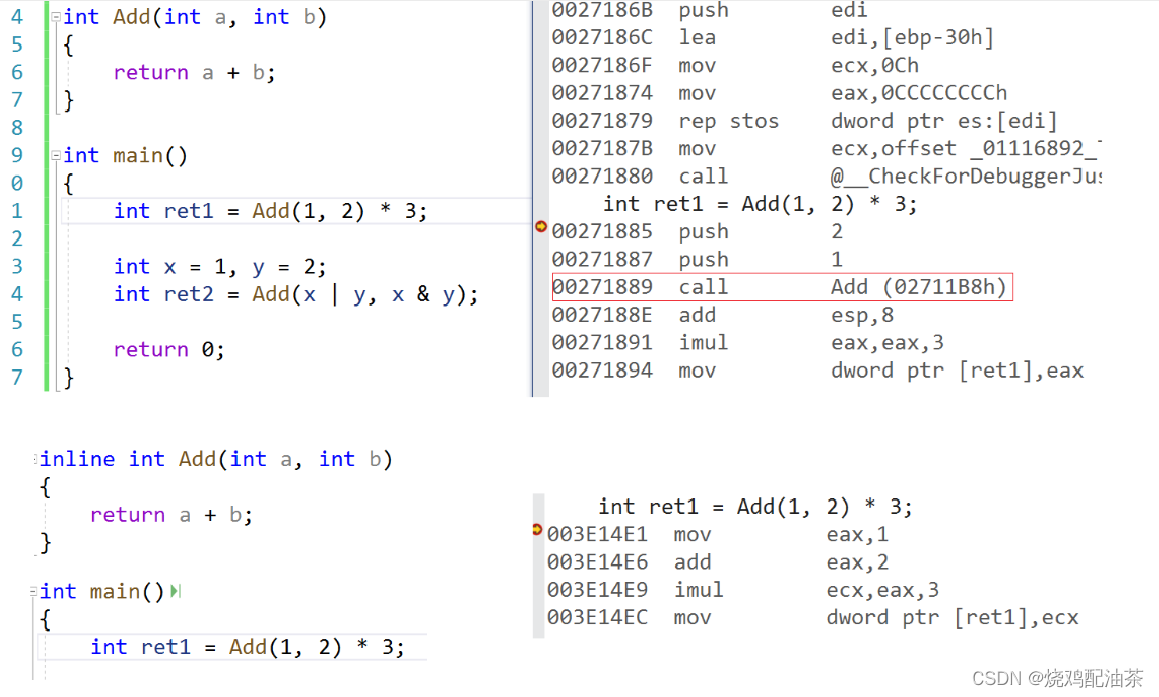
【C++】入门(二):引用、内联、auto
书接上回:【C】入门(一):命名空间、缺省参数、函数重载 文章目录 六、引用引用的概念引用的使用场景1. 引用做参数作用1:输出型参数作用2:对象比较大,减少拷贝,提高效率 2. 引用作为…...
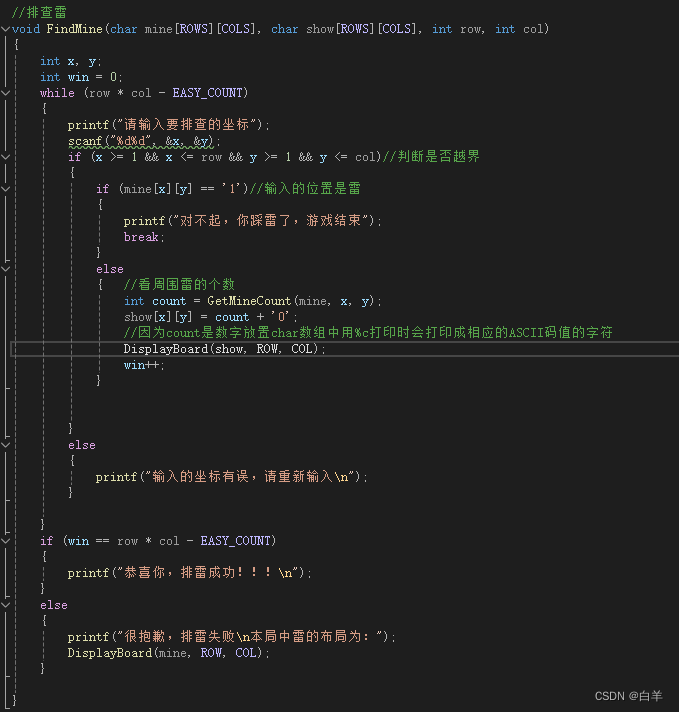
编程学习 (C规划) 6 {24_4_18} 七 ( 简单扫雷游戏)
首先我们要清楚扫雷大概是如何实现的: 1.布置雷 2.扫雷(排查雷) (1)如果这个位置是雷就炸了,游戏结束 (2)如果不是雷,就告诉周围有几个雷 3.把所有不是雷的位置都找…...
【AI】llama-fs的 安装与运行
pip install -r .\requirements.txt Windows PowerShell Copyright (C) Microsoft Corporation. All rights reserved.Install the latest PowerShell for new features and improvements! https://aka.ms/PSWindows(venv) PS D:\XTRANS\pythonProject>...
内存监控)
Android NDK系列(五)内存监控
在日常的开发中,内存泄漏是一种比较比较棘手的问题,这是由于其具有隐蔽性,即使发生了泄漏,很难检测到并且不好定位到哪里导致的泄漏。如果程序在运行的过程中不断出现内存泄漏,那么越来越多的内存得不到释放࿰…...

软件设计师,下午题 ——试题六
模型图 简单工厂模式 工厂方法模式抽象工厂模式生成器模式原型模式适配器模式桥接模式组合模式装饰(器)模式亨元模式命令模式观察者模式状态模式策略模式访问者模式中介者模式 简单工厂模式 工厂方法模式 抽象工厂模式 生成器模式 原型模式 适配器模式 桥…...

《Kubernetes部署篇:基于麒麟V10+ARM64架构部署harbor v2.4.0镜像仓库》
总结:整理不易,如果对你有帮助,可否点赞关注一下? 更多详细内容请参考:企业级K8s集群运维实战 一、环境信息 K8S版本 操作系统 CPU架构 服务版本 1.26.15 Kylin Linux Advanced Server V10 ARM64 harbor v2.4.0 二、部…...
远程工作/线上兼职网站整理(数字游民友好)
文章目录 国外线上兼职网站fiverrupwork 国内线上兼职网站甜薪工场猪八戒网云队友 国外线上兼职网站 fiverr https://www.fiverr.com/start_selling?sourcetop_nav upwork https://www.upwork.com/ 国内线上兼职网站 甜薪工场 https://www.txgc.com/ 猪八戒网 云队友 …...
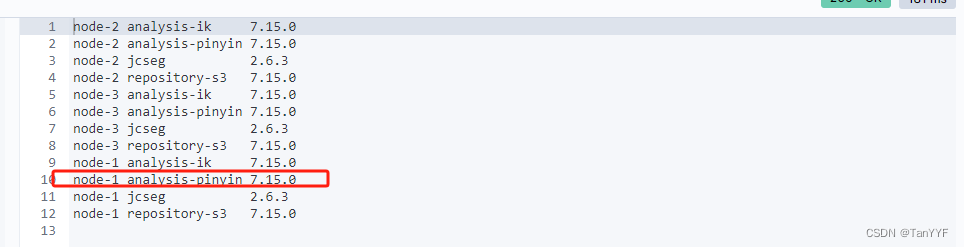
elasticsearch7.15实现用户输入自动补全
Elasticsearch Completion Suggester(补全建议) Elasticsearch7.15安装 官方文档 补全建议器提供了根据输入自动补全/搜索的功能。这是一个导航功能,引导用户在输入时找到相关结果,提高搜索精度。 理想情况下,自动补…...

掌握正则表达式的力量:全方位解析PCRE的基础与进阶技能
Perl 兼容正则表达式(PCRE)是 Perl scripting language 中所使用的正则表达式语法标准。这些正则表达式在 Linux 命令行工具(如 grep -P)及其他编程语言和工具中也有广泛应用。以下是一些基础和进阶特性,帮你掌握和使用…...

FastFM库,一款强大神奇的Python系统分析预测的工具
FastFM库概述 在机器学习领域,Factorization Machines(FM)是处理稀疏数据集中特征间交互的重要工具.Python的fastFM库提供了高效的实现,特别适合用于推荐系统、评分预测等任务.本文将全面介绍fastFM的安装、特性、基本和高级功能,并结合实际应用场景展示…...

R语言绘图 --- 饼状图(Biorplot 开发日志 --- 2)
「写在前面」 在科研数据分析中我们会重复地绘制一些图形,如果代码管理不当经常就会忘记之前绘图的代码。于是我计划开发一个 R 包(Biorplot),用来管理自己 R 语言绘图的代码。本系列文章用于记录 Biorplot 包开发日志。 相关链接…...

用于日常任务的实用 Python 脚本
Python 是一种多功能编程语言,以其简单易读而闻名。它广泛应用于从 Web 开发到数据分析等各个领域。Python 脚本,它们可以通过自动执行常见任务来使您的生活更轻松。 用于日常任务的实用 Python 脚本 1. 使用 Pandas 进行数据分析2. 使用 BeautifulSoup …...

7-Zip是什么呢
1. 简介 7-Zip 是一个功能强大、免费开源的文件压缩和解压缩工具,适用于个人用户和企业用户,可以在多种操作系统上进行使用,并且支持广泛的压缩格式和高级功能。 2. 特点与优势 开源免费:7-Zip 是免费的开源软件,可…...

Satellite Stereo Pipeline学习
1.在Anaconda某个环境中安装s2p pip install s2p 2.在Ubuntu系统中安装s2p源代码 git clone https://github.com/centreborelli/s2p.git --recursive cd s2p pip install -e ".[test]" 3.在s2p中进行make all处理 中间会有很多情况,基本上哪个包出问题…...

linux-gpio
在Linux shell中测试GPIO通信,通常需要使用GPIO的设备文件,这些文件通常位于/sys/class/gpio目录下。要使用特定的GPIO引脚,比如GPIO92,你需要执行以下步骤: 导出GPIO引脚:首先,需要确保GPIO92已…...

C# 代码配置的艺术
文章目录 1、代码配置的定义及其在软件工程中的作用2、C# 代码配置的基本概念和工具3、代码配置的实践步骤4、实现代码配置使用属性(Properties)使用配置文件(Config Files)使用依赖注入(Dependency Injection…...

268 基于matlab的模拟双滑块连杆机构运动
基于matlab的模拟双滑块连杆机构运动,并绘制运动动画,连杆轨迹可视化输出,并输出杆件质心轨迹、角速度、速度变化曲线。可定义杆长、滑块速度,滑块初始位置等参数。程序已调通,可直接运行。 268 双滑块连杆机构运动 连…...

进口铝合金电动隔膜泵
进口铝合金电动隔膜泵是一种高效、可靠的工业泵,其特点、性能与应用广泛,以下是对其的详细分析: 特点 材质与结构: 采用铝合金材料制造,具有良好的耐腐蚀性和轻量化特点。铝合金材质使得泵体结构紧凑、轻便ÿ…...

5分钟免费制作专业AI翻唱:AICoverGen完整指南
5分钟免费制作专业AI翻唱:AICoverGen完整指南 【免费下载链接】AICoverGen A WebUI to create song covers with any RVC v2 trained AI voice from YouTube videos or audio files. 项目地址: https://gitcode.com/gh_mirrors/ai/AICoverGen 想让AI帮你翻唱…...

STM32F407通过SPI接口高效读写SD卡:CubeMX配置与底层驱动实战
1. SD卡基础与SPI通信原理 SD卡作为嵌入式系统中最常用的存储介质之一,其SPI模式因其接线简单、协议清晰而广受欢迎。先说说我实际项目中遇到的坑:曾经因为没理解清楚SPI模式下SD卡的初始化时序,导致整整两天卡在设备无法识别的困境里。 SD卡…...

用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧
用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧 当面对成百上千维的数据时,我们常会陷入"维度灾难"的困境——计算资源吃紧、模型训练缓慢,更糟的是噪声干扰导致分析结果失真。主成分…...

荣品RV1126 SDK编译避坑指南:从环境配置到分区调整,手把手解决常见编译错误
RV1126 SDK编译实战:从环境搭建到分区优化的全流程解决方案 1. 开发环境配置与初始化 RV1126开发环境的搭建是整个开发流程的第一步,也是后续所有工作的基础。一个稳定、高效的开发环境能够显著提升开发效率,减少不必要的错误。 首先需要确保…...

Thorium浏览器深度解析:5个核心优势与进阶配置实战
Thorium浏览器深度解析:5个核心优势与进阶配置实战 【免费下载链接】thorium Chromium fork named after radioactive element No. 90. Source code and Linux releases. Windows/MacOS/ARM builds served in different repos, links are towards the top of the RE…...

CircuitPython嵌入式游戏开发:基于TileGrid的迷宫寻蛋与JSON数据持久化实践
1. 项目概述与核心价值如果你和我一样,对嵌入式开发充满热情,同时又对游戏开发抱有好奇心,那么将两者结合——在微控制器上编写一个完整的2D游戏——绝对是一次令人兴奋的挑战。这不仅仅是让LED闪烁或读取传感器数据,而是要在资源…...

MATLAB/Simulink模型化设计驱动树莓派:从LED闪烁到快速原型开发
1. 项目概述:当MATLAB/Simulink遇见树莓派 如果你是一名算法工程师、控制工程师,或者正在学习嵌入式系统,那么“模型化设计”和“快速原型开发”这两个词对你来说一定不陌生。它们听起来很高大上,但核心目标其实很朴素࿱…...

龙芯3A6000平台Loongnix系统部署实战:从固件更新到驱动配置全解析
1. 项目概述:一次国产平台上的系统部署实战最近,我拿到了一台基于龙芯3A6000处理器和7A2000桥片的国产台式机。对于长期在x86/ARM生态里打转的开发者来说,这无疑是一个充满新鲜感和挑战的“新玩具”。它的核心使命,就是运行龙芯社…...

本地大模型Web API桥梁:llm-web-api部署与OpenAI兼容实践
1. 项目概述:一个为本地大语言模型提供Web API的轻量级桥梁如果你和我一样,热衷于在本地部署各种开源大语言模型(LLM),比如Llama、Qwen、Mistral,那么你一定遇到过这样的痛点:模型本身跑起来了&…...

Arm Neoverse CMN-700缓存一致性互连网络架构解析
1. Arm Neoverse CMN-700架构概述Arm Neoverse CMN-700是Arm公司推出的新一代缓存一致性互连网络(Coherent Mesh Network)解决方案,专为高性能计算、云计算和基础设施应用设计。作为多核处理器系统中实现高效数据共享的关键基础设施ÿ…...