Pytorch入门需要达到的效果
会搭建深度学习环境和依赖包安装
使用Anaconda创建环境、在pytorch官网安装pytorch、安装依赖包
会使用常见操作,例如matmul,sigmoid,softmax,relu,linear
matmul操作见文章torch.matmul()的用法
sigmoid,softmax,relu都是常用的激活函数,linear是线性层:
from torch import nnclass Network(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Sigmoid(),nn.Softmax(),nn.ReLU(),nn.Linear(1024, 64))
dataset,dataloader,损失函数,优化器的使用
dataset,dataloader
官方文档是这么写的:
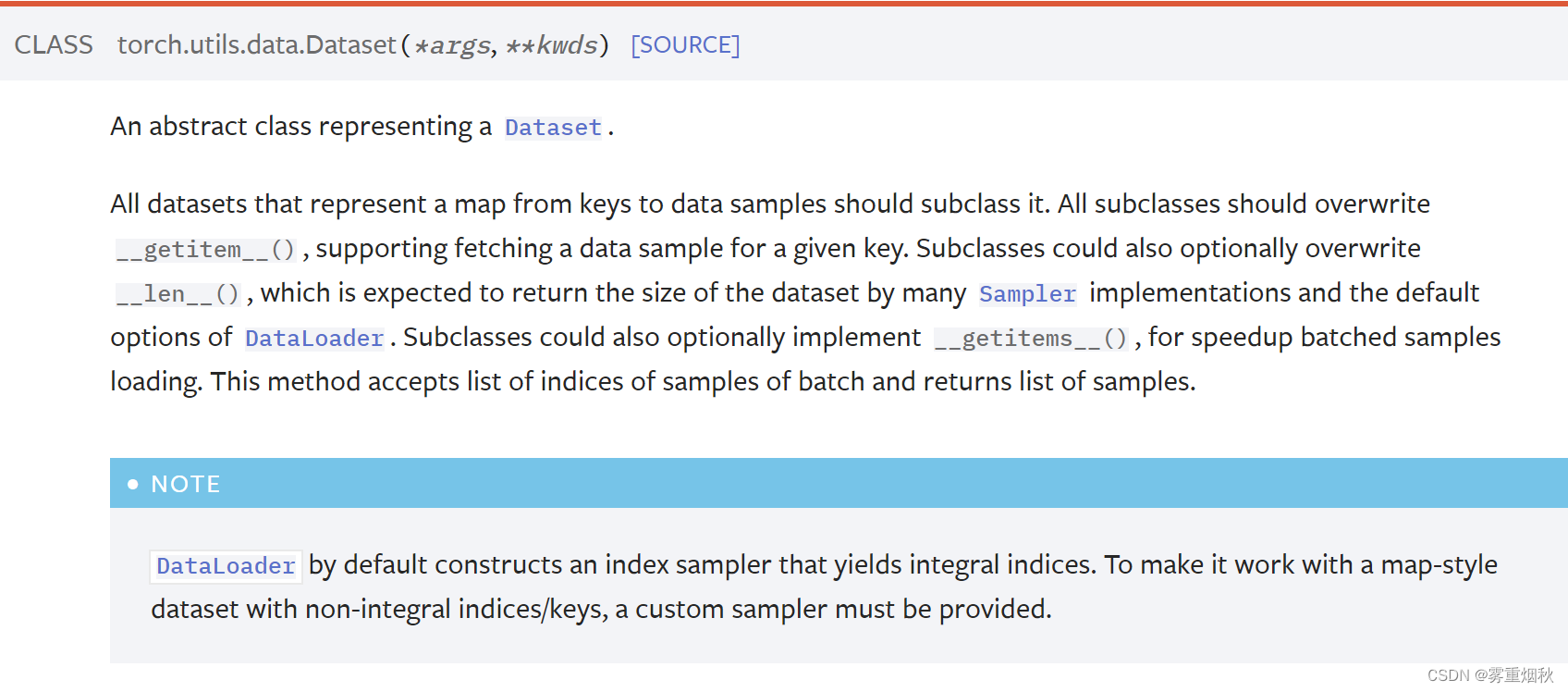
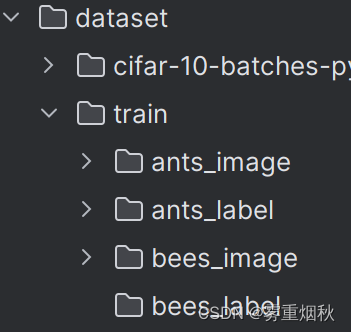
当我们自定义一个dataset的时候,需要继承Dataset,重写__getitem__()方法,也可以重写__len__()方法,下面是一个例子,我们的数据集存放成这种形式,每一个image图片都对应一个相同名称的label文件,如0013035.jpg和0013035.txt就分别是一个图片和它的label:
import torchvision.transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoaderclass MyData(Dataset):def __init__(self, root_dir, image_dir, label_dir):self.root_dir = root_dirself.image_dir = image_dirself.label_dir = label_dirself.image_path = os.path.join(self.root_dir, self.image_dir)self.label_path = os.path.join(self.root_dir, self.label_dir)self.imgs = os.listdir(self.image_path)self.labels = os.listdir(self.label_path)def __getitem__(self, item):img_name = self.imgs[item]img_item_path = os.path.join(self.image_path, img_name)label_item_path = os.path.join(self.label_path, self.convert_to_txt_path(img_name))img = Image.open(img_item_path)with open(label_item_path, 'r') as f:label = f.read().strip()return img, labeldef convert_to_txt_path(self, image_path):# 使用正则表达式匹配文件名中的点和扩展名,并替换为'.txt'label_path = re.sub(r'\.[^.]+?$', '.txt', image_path)return label_pathdef __len__(self):return len(self.imgs)root_dir = "dataset/train"
ants_image_dir = "ants_image"
bees_image_dir = "bees_image"
ants_label_dir = "ants_label"
bees_label_dir = "bees_label"
ants_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_image_dir, bees_label_dir)train_dataset = ants_dataset + bees_datasetimg, target = train_dataset[0]
transform = torchvision.transforms.ToTensor()
print(transform(img).shape)
print(target)
我们使用dataloader来读取这个数据集,我们需要对jpg格式的dataset进行处理,将其转换为相同大小的tensor,再读取:
import torchvision.transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoaderclass MyData(Dataset):def __init__(self, root_dir, image_dir, label_dir):self.root_dir = root_dirself.image_dir = image_dirself.label_dir = label_dirself.image_path = os.path.join(self.root_dir, self.image_dir)self.label_path = os.path.join(self.root_dir, self.label_dir)self.imgs = os.listdir(self.image_path)self.labels = os.listdir(self.label_path)def __getitem__(self, item):img_name = self.imgs[item]img_item_path = os.path.join(self.image_path, img_name)label_item_path = os.path.join(self.label_path, self.convert_to_txt_path(img_name))img = Image.open(img_item_path)transcompose = torchvision.transforms.Compose([torchvision.transforms.Resize((300, 300)), torchvision.transforms.ToTensor()])img = transcompose(img)with open(label_item_path, 'r') as f:label = f.read().strip()return img, labeldef convert_to_txt_path(self, image_path):# 使用正则表达式匹配文件名中的点和扩展名,并替换为'.txt'label_path = re.sub(r'\.[^.]+?$', '.txt', image_path)return label_pathdef __len__(self):return len(self.imgs)root_dir = "dataset/train"
ants_image_dir = "ants_image"
bees_image_dir = "bees_image"
ants_label_dir = "ants_label"
bees_label_dir = "bees_label"
ants_dataset = MyData(root_dir, ants_image_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_image_dir, bees_label_dir)train_dataset = ants_dataset + bees_datasetimg, target = train_dataset[0]
print(img.shape)
print(target)train_dataloader = DataLoader(train_dataset, batch_size=64, drop_last=True)
for data in train_dataloader:try:imgs, target = dataexcept Exception as e:print(f"跳过异常文件: {e}")
使用公开数据集的示例如下:
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备的测试数据集
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())test_loader = DataLoader(test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)writer = SummaryWriter("dataloader")
for epoch in range(2):step = 0for data in test_loader:imgs, targets = data# print(imgs.shape)# print(targets)writer.add_images("Epoch: {}".format(epoch), imgs, step)step = step + 1writer.close()
损失函数
Loss的用法实际上就两行代码的事情,以下是示例:
import torch
from torch.nn import L1Loss, MSELoss
from torch import nninputs = torch.tensor([1, 2, 3], dtype=torch.float)
targets = torch.tensor([1, 2, 5], dtype=torch.float)inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))loss = L1Loss(reduction='sum')
result = loss(inputs, targets)loss_mse = MSELoss()
result_mse = loss_mse(inputs, targets)print(result)
print(result_mse)x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
优化器
优化器的使用也很简单,但要注意,在每一步训练之前都需要用optim.zero_grad()将梯度置零,避免梯度累加造成问题,用loss.backward()得到梯度以后用optim.step()更新参数
import torch
import torchvision.datasets
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=1)class Network(nn.Module):def __init__(self):super().__init__()self.model1 = Sequential(Conv2d(3, 32,5, padding=2),MaxPool2d(2),Conv2d(32, 32,5, padding=2),MaxPool2d(2),Conv2d(32, 64,5,padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64,10))def forward(self, x):x = self.model1(x)return xloss = nn.CrossEntropyLoss()
network = Network()
optim = torch.optim.SGD(network.parameters(), lr=0.01)for epoch in range(20):running_loss = 0.0for data in dataloader:imgs, targets = dataoutputs = network(imgs)result_loss = loss(outputs, targets)optim.zero_grad()result_loss.backward()optim.step()running_loss = running_loss + result_lossprint(running_loss)
gpu手写和预测一个模型
gpu写模型
这里采用to(device)的方式使用gpu,对模型、损失函数和读数据部分使用to(device)调用gpu,其他和cpu并无区别:
import torch
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# from model import *# 定义训练的设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 准备数据集
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为: {}".format(train_data_size))
print(f"测试数据集的长度为: {test_data_size}")# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 创建网络模型
# 搭建神经网络
class Network(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return xnetwork = Network()
network.to(device)# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)# 优化器
# learning_rate = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(network.parameters(), lr=learning_rate)# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 30# 添加tensorboard
writer = SummaryWriter("logs_train")
start_time = time.time()
for i in range(epoch):print("-----------第 {} 轮训练开始----------".format(i+1))# 训练步骤开始network.train()for data in train_dataloader:imgs, targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = network(imgs)loss = loss_fn(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:end_time = time.time()print(end_time - start_time)print("训练次数: {}, loss: {}".format(total_train_step, loss.item()))writer.add_scalar("train_loss", loss.item(), total_train_step)# 测试步骤开始network.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs, targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = network(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + lossaccuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整体测试集上的Loss: {}".format(total_test_loss))print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss", total_test_loss, total_test_step)writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)total_test_step = total_test_step + 1torch.save(network, "network_{}.pth".format(i))print("模型已保存")writer.close()
gpu预测模型
把读取到的模型和数据用to(device)设置成gpu运行
import torch
import torchvision.transforms
from PIL import Image
from torch import nn# 定义训练的设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
img_path = "dog.png"
image = Image.open(img_path)
print(image)transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)# 搭建神经网络
class Network(nn.Module):def __init__(self):super().__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, padding=2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64*4*4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return xmodel = torch.load("network_29.pth").to(device)
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
image = image.to(device)
model.eval()
with torch.no_grad():output = model(image)
print(output)print(output.argmax(1))
相关文章:
Pytorch入门需要达到的效果
会搭建深度学习环境和依赖包安装 使用Anaconda创建环境、在pytorch官网安装pytorch、安装依赖包 会使用常见操作,例如matmul,sigmoid,softmax,relu,linear matmul操作见文章torch.matmul()的用法 sigmoid࿰…...
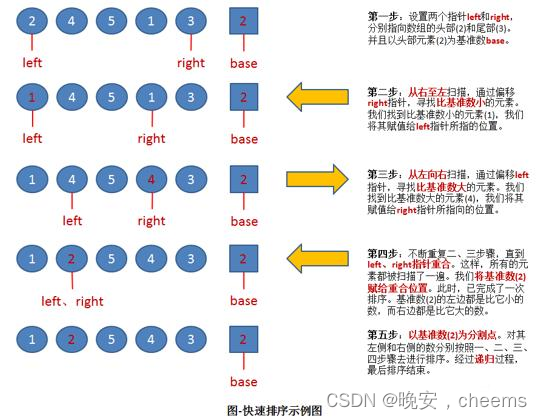
数据结构的快速排序(c语言版)
一.快速排序的概念 1.快排的基本概念 快速排序是一种常用的排序算法,它是基于分治策略的一种高效排序算法。它的基本思想如下: 从数列中挑出一个元素作为基准(pivot)。将所有小于基准值的元素放在基准前面,所有大于基准值的元素放在基准后面。这个过程称为分区(partition)操作…...
)
数据结构基础篇(4)
十六.循环链表 概念 循环链表是一种头尾相接的链表(最后一个结点的指针域指向头结点,整个链表形成一个环)优点 从表任一结点出发均可找到表中其他结点判断终止 由于循环链表中没有NULL指针,所以涉及遍历操作时,终止条…...
使用cad绘制一个螺旋输送机
1、第一步,绘制一个矩形 2、使用绘图中的样条线拟合曲线,绘制螺旋线。 绘制时使用上下辅助线、阵列工具绘制多个竖线保证样条线顶点在同一高度。 3、调整矩形右侧的两个顶点,使其变形。 矩形1和矩形2连接时,使用blend命令&#…...

迭代器模式(行为型)
目录 一、前言 二、迭代器模式 三、总结 一、前言 迭代器模式(Iterator Pattern)是一种行为型设计模式,提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示。总的来说就是分离了集合对象的遍历行为,抽象出…...
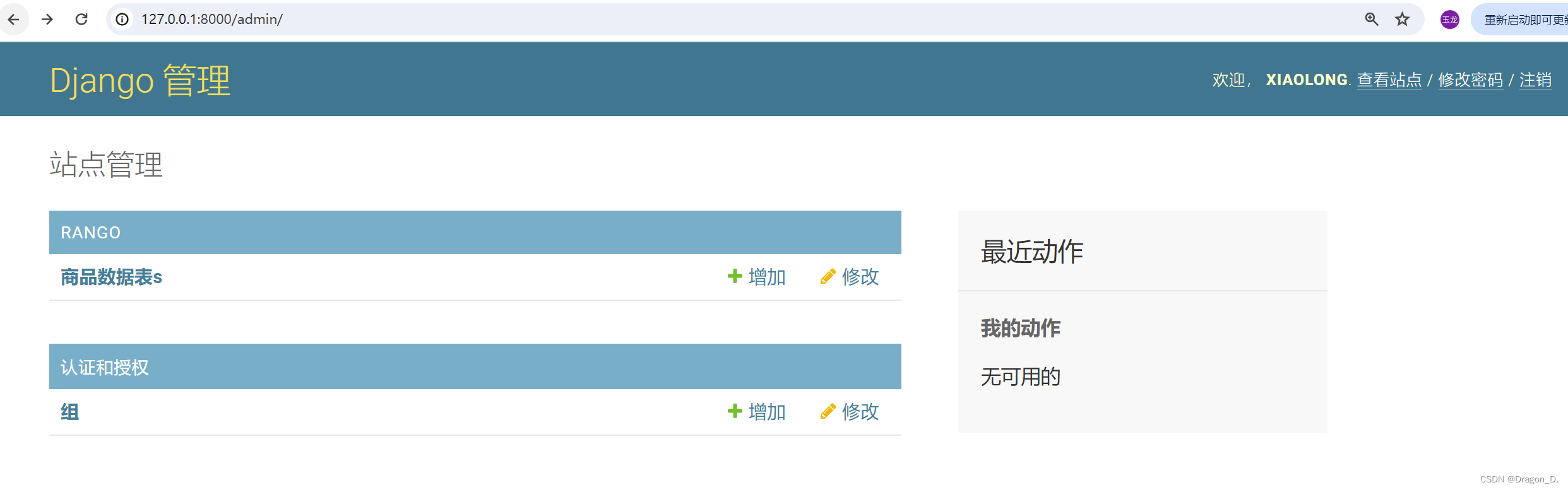
Django——Admin站点(Python)
#前言: 该博客为小编Django基础知识操作博客的最后一篇,主要讲解了关于Admin站点的一些基本操作,小编会继续尽力更新一些优质文章,同时欢迎大家点赞和收藏,也欢迎大家关注等待后续文章。 一、简介: Djan…...

React 组件通信
1.从父组件向子组件传递参数: 父组件可以通过props将数据传递给子组件。子组件通过接收props来获取这些数据。 // 父组件 const ParentComponent () > {const data Hello, Child!;return <ChildComponent childData{data} />; }; // 子组件 const ChildCompone…...
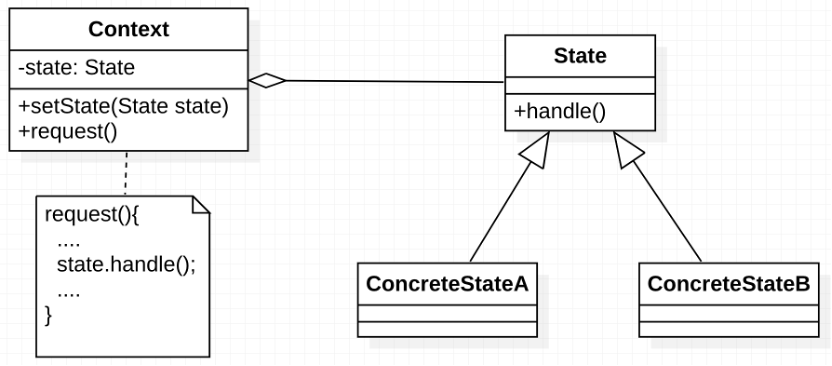
【再探】设计模式—访问者模式、策略模式及状态模式
访问者模式是用于访问复杂数据结构的元素,对不同的元素执行不同的操作。策略模式是对于具有多种实现的算法,在运行过程中可动态选择使用哪种具体的实现。状态模式是用于具有不同状态的对象,状态之间可以转换,且不同状态下对象的行…...

新人硬件工程师,工作中遇到的问题list
新人硬件工程师能够通过面试,已经证明是能够胜任硬件工程师职责,当然胜任的时间会延迟,而不是当下,为什么呢?因为学校学习和公司做产品,两者之间有差异,会需要适应期。今天来看看新人硬件工程师…...

如何在Linux系统中搭建Zookeeper集群
一、概述 ZooKeeper是一个开源的且支持分布式部署的应用程序,是Google的Chubby一个开源的实现;它为分布式应用提供了一致性服务支持,包括:配置维护、域名服务、分布式同步、组服务等。 官网:https://zookeeper.apach…...

C++:vector的模拟实现
hello,各位小伙伴,本篇文章跟大家一起学习《C:vector的模拟实现》,感谢大家对我上一篇的支持,如有什么问题,还请多多指教 ! 如果本篇文章对你有帮助,还请各位点点赞!&…...
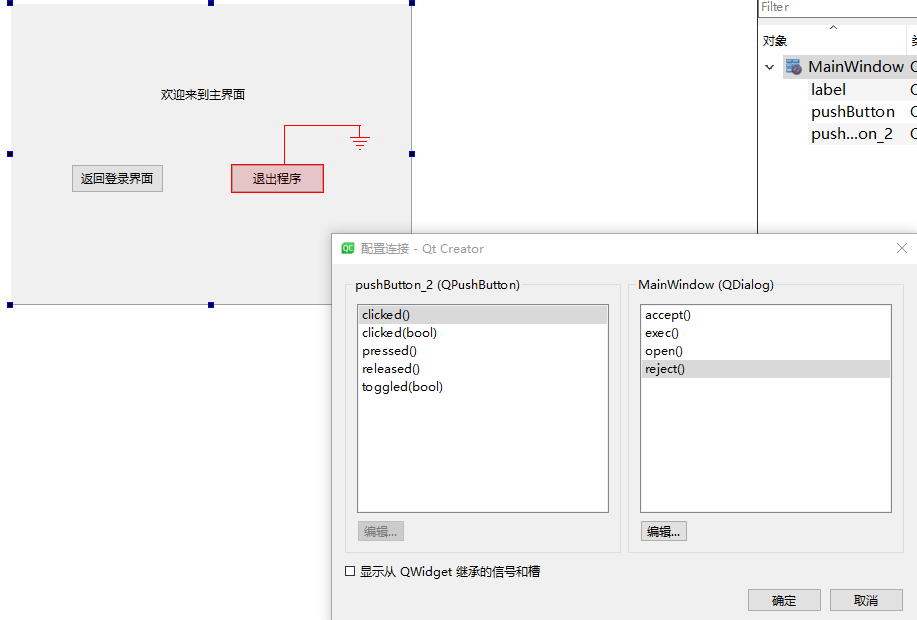
QT系列教程(5) 模态对话框消息传递
模态对话框接受和拒绝消息 我们创建一个模态对话框,调用exec函数后可以根据其返回值进行不同的处理,exec的返回值有两种,Qt的官方文档记录的为 QDialog::Accepted QDialog::RejectedAccepted 表示接受消息, Rejected表示拒绝消息…...
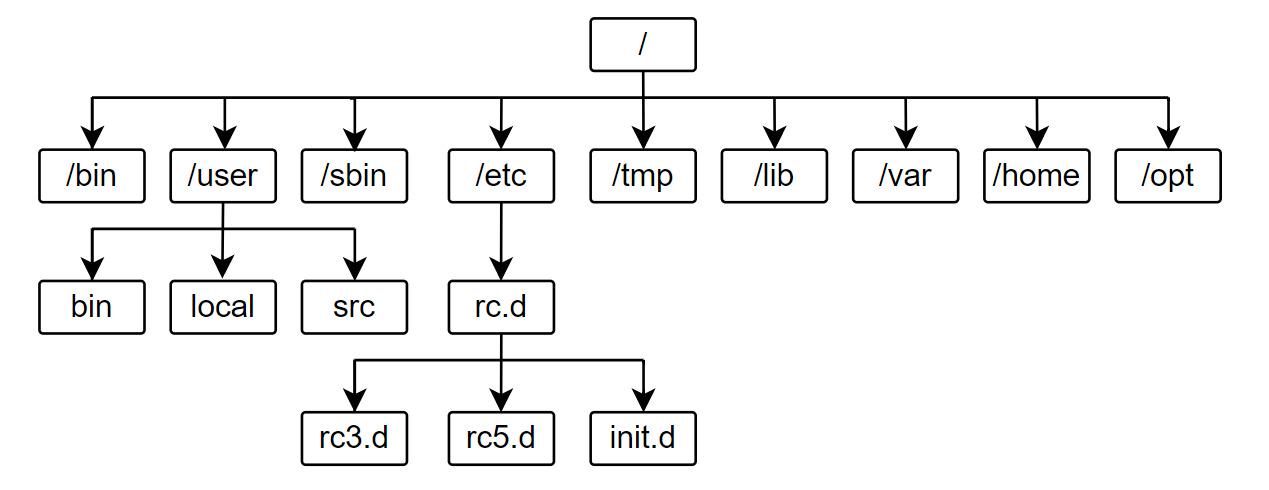
Linux学习笔记(清晰且清爽)
本文首次发布于个人博客 想要获得最佳的阅读体验(无广告且清爽),请访问本篇笔记 Linux安装 关于安装这里就不过多介绍了,安装版本是CentOS 7,详情安装步骤见下述博客在VMware中安装CentOS7(超详细的图文教…...
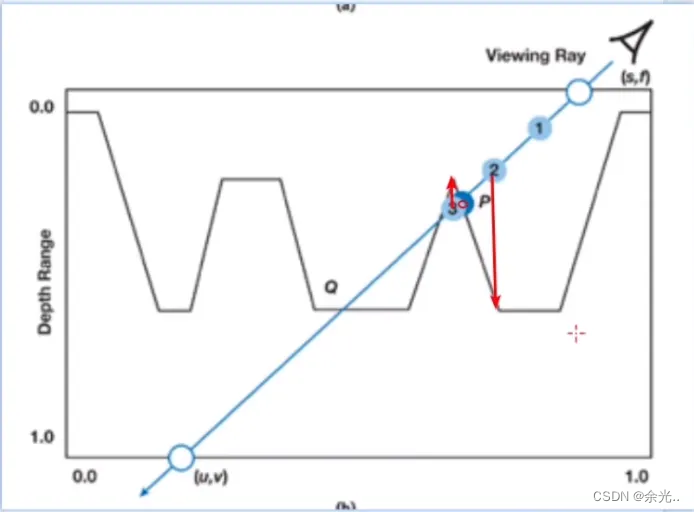
2.5Bump Mapping 凹凸映射
一、Bump Mapping 介绍 我们想要在屏幕上绘制物体的细节,从尺度上讲,一个物体的细节分为:宏观、中观、微观宏观尺度中其特征会覆盖多个像素,中观尺度只覆盖几个像素,微观尺度的特征就会小于一个像素宏观尺度是由顶点或…...

数字化前沿:Web3如何引领未来技术演进
在当今数字化时代,随着技术的不断发展和创新,Web3作为一种新兴的互联网范式,正逐渐成为数字化前沿的代表。Web3以其去中心化、加密安全的特性,正在引领着未来技术的演进,为全球范围内的科技创新带来了新的可能性和机遇…...
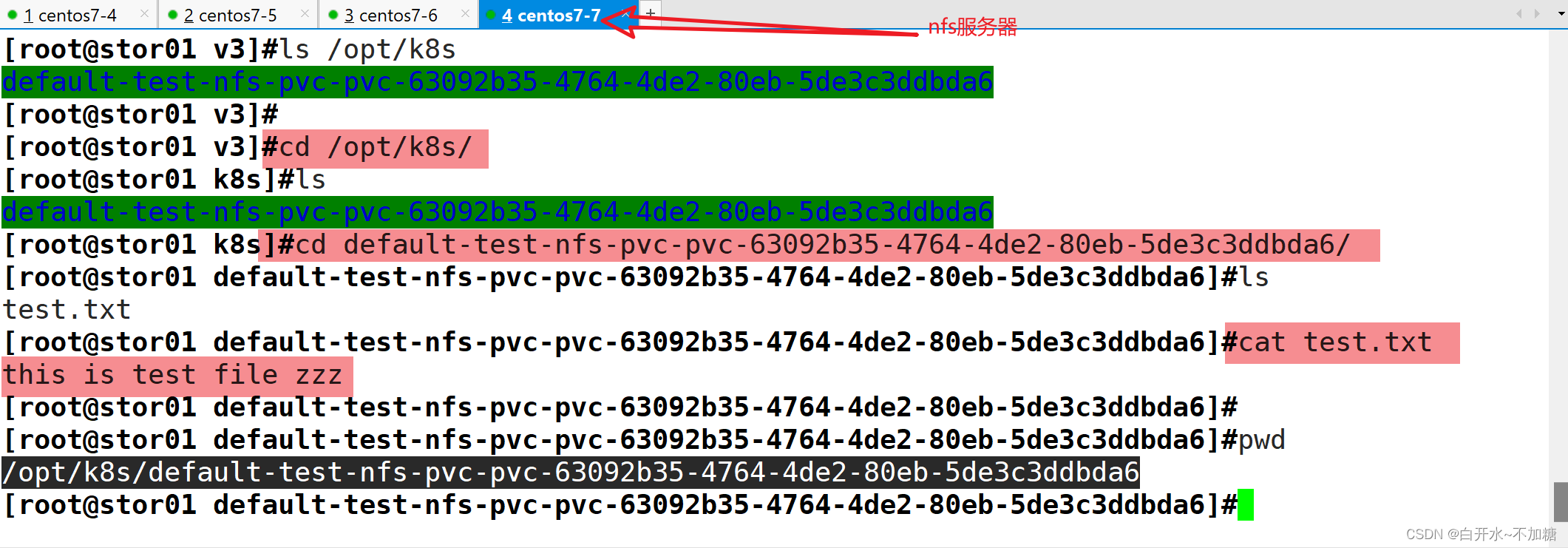
【kubernetes】探索k8s集群的存储卷、pvc和pv
目录 一、emptyDir存储卷 1.1 特点 1.2 用途 1.3部署 二、hostPath存储卷 2.1部署 2.1.1在 node01 节点上创建挂载目录 2.1.2在 node02 节点上创建挂载目录 2.1.3创建 Pod 资源 2.1.4访问测试 2.2 特点 2.3 用途 三、nfs共享存储卷 3.1特点 3.2用途 3.3部署 …...
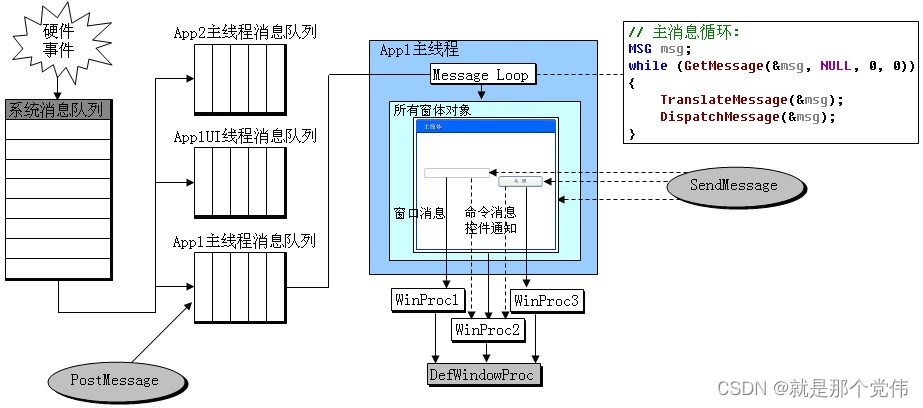
UI线程和工作线程
引用:windows程序员面试指南 工作线程 只处理逻辑的线程,例如:启动一个线程,用来做一个复杂的计算,计算完成之后,此线程就自动退出,这种线程称为工作线程 UI线程 Windows应用程序一般由窗口…...

RandLA-Net 训练自定义数据集
https://arxiv.org/abs/1911.11236 搭建训练环境 git clone https://github.com/QingyongHu/RandLA-Net.git搭建 python 环境 , 这里我用的 3.9conda create -n randlanet python3.9 source activate randlanet pip install tensorflow2.15.0 -i https://pypi.tuna.tsinghua.e…...

洛谷 B3642:二叉树的遍历 ← 结构体方法 链式前向星方法
【题目来源】https://www.luogu.com.cn/problem/B3642【题目描述】 有一个 n(n≤10^6) 个结点的二叉树。给出每个结点的两个子结点编号(均不超过 n),建立一棵二叉树(根结点的编号为 1),如果是叶子结点&…...

飞腾+FPGA多U多串全国产工控主机
飞腾多U多串工控主机基于国产化飞腾高性能8核D2000处理器平台的国产自主可控解决方案,搭载国产化固件,支持UOS、银河麒麟等国产操作系统,满足金融系统安全运算需求,实现从硬件、操作系统到应用的完全国产、自主、可控,是国产金融信…...

使用mcp-maker快速构建AI工具调用服务器:从协议原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给大语言模型(LLM)装上更强大的“手脚”,让它能直接操作我电脑上的各种软件和工具。这听起来很酷,对吧?但实际操作起来,你会发现一个核心痛…...

VectorDBBench:向量数据库性能基准测试工具详解与实战
1. 项目概述:向量数据库性能测试的“瑞士军刀”如果你正在评估或使用向量数据库,那么你一定遇到过这个灵魂拷问:“这么多产品,到底哪个最适合我的场景?”是选名声在外的老牌劲旅,还是选后起之秀的专精选手&…...

开源技能库构建指南:Git+Markdown+Docsify打造个人技术知识体系
1. 项目概述:一个开源技能库的诞生与价值在技术领域,尤其是软件开发、运维和数据分析等方向,我们每天都在与海量的工具、框架和命令打交道。时间一长,一个很现实的问题就摆在了面前:那些曾经花了好几个小时才调通的复杂…...

阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程
阴阳师自动化脚本OAS终极指南:轻松解放双手的完整教程 【免费下载链接】OnmyojiAutoScript Onmyoji Auto Script | 阴阳师脚本 项目地址: https://gitcode.com/gh_mirrors/on/OnmyojiAutoScript 阴阳师自动化脚本OAS是一款专门为《阴阳师》游戏设计的智能自动…...

终极免费换肤方案:R3nzSkin国服版完整使用教程
终极免费换肤方案:R3nzSkin国服版完整使用教程 【免费下载链接】R3nzSkin-For-China-Server Skin changer for League of Legends (LOL) 项目地址: https://gitcode.com/gh_mirrors/r3/R3nzSkin-For-China-Server 想要在英雄联盟国服免费体验所有皮肤&#x…...

开源AI图像生成工具Dream-Creator:本地部署与Stable Diffusion实战指南
1. 项目概述:一个开源的AI图像生成与创作工具 最近在GitHub上闲逛,发现了一个挺有意思的项目叫“Dream-Creator”。光看名字,你可能会联想到一些AI绘画或者创意生成工具。没错,这确实是一个围绕AI图像生成的开源项目。作为一个在…...

基于Taotoken统一API开发支持多模型切换的智能对话应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 基于Taotoken统一API开发支持多模型切换的智能对话应用 应用场景类,场景是开发一个需要支持用户自由选择或系统自动切换…...

开源大模型推理引擎Takeoff部署指南:从原理到生产实践
1. 项目概述:一个让大模型推理“起飞”的开源引擎 如果你正在为如何将那些动辄几十GB、几百亿参数的大语言模型(LLM)部署到生产环境而头疼,或者厌倦了为每一次API调用支付高昂的费用,那么今天聊的这个项目,…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...

DOM 浏览器
DOM 浏览器 引言 DOM(文档对象模型)是浏览器中处理HTML和XML文档的标准方式。它允许开发人员通过编程方式访问和操作网页内容。本文将详细介绍DOM的概念、其在浏览器中的运用以及相关的编程技巧。 DOM简介 什么是DOM? DOM(Document Object Model)是一种跨平台和语言独…...