Go 如何通过 Kafka 客户端库 生产与消费消息
文章目录
- 0.前置说明
- 1. confluent-kafka-go
- 2. sarama
- 3. segmentio/kafka-go
- 4. franz-go
- 选择建议
- 1.启动 kafka 集群
- 2.安装 confluent-kafka-go 库
- 3.创建生产者
- 特殊文件说明
- 如何查看.log文件内容
- 4.创建消费者
0.前置说明
Go 语言中有一些流行的 Kafka 客户端库。以下是几个常用的库及其优劣与区别:
1. confluent-kafka-go
-
优点:
- 高性能:基于
librdkafka,性能非常高。 - 功能全面:支持 Kafka 的所有高级功能,如事务、压缩、认证等。
- 社区支持:由 Confluent 维护,社区活跃,文档丰富。
- 稳定性:广泛使用于生产环境,经过大量测试和验证。
- 高性能:基于
-
缺点:
- 依赖性:依赖于
librdkafka,需要额外安装该库。 - 复杂性:配置和使用相对复杂,特别是对于新手。
- 依赖性:依赖于
2. sarama
-
优点:
- 纯 Go 实现:不依赖于任何 C 库,安装和使用非常方便。
- 社区活跃:由 Shopify 维护,社区支持良好,文档齐全。
- 灵活性:提供了丰富的配置选项,适用于各种使用场景。
-
缺点:
- 性能:相对于
confluent-kafka-go,性能稍逊一筹。 - 功能:不支持 Kafka 的一些高级功能,如事务。
- 性能:相对于
3. segmentio/kafka-go
-
优点:
- 纯 Go 实现:不依赖于任何 C 库,安装和使用非常方便。
- 简洁易用:API 设计简洁,易于上手。
- 灵活性:支持多种配置选项,适用于各种使用场景。
-
缺点:
- 性能:相对于
confluent-kafka-go,性能稍逊一筹。 - 功能:不支持 Kafka 的一些高级功能,如事务。
- 性能:相对于
4. franz-go
-
优点:
- 纯 Go 实现:不依赖于任何 C 库,安装和使用非常方便。
- 高性能:在纯 Go 实现中性能较为优越。
- 功能全面:支持 Kafka 的大部分功能,包括事务。
-
缺点:
- 社区支持:相对于
sarama和confluent-kafka-go,社区支持稍弱。 - 文档:文档相对较少,需要更多的社区贡献。
- 社区支持:相对于
选择建议
- 高性能和高级功能需求:如果你需要高性能和 Kafka 的高级功能(如事务、压缩、认证等),
confluent-kafka-go是一个不错的选择。 - 纯 Go 实现和易用性:如果你更倾向于使用纯 Go 实现的库,并且希望安装和使用更加简便,可以选择
sarama或segmentio/kafka-go。 - 平衡性能和功能:如果你希望在纯 Go 实现中获得较好的性能和功能支持,可以考虑
franz-go。
本文我们就以confluent-kafka-go库为例来编写代码。
1.启动 kafka 集群
不知道如何搭建集群请点击这里 ----》Kafka 集群部署(CentOS 单机模拟版)
如果你懒得启动集群,那么直接跳过。
- 在
cluster目录下运行集群启动脚本cluster.sh;
cd cluster
./cluster.sh
- 检查是否启动成功;
ll zookeeper-data/
total 4
drwxr-xr-x 3 root root 4096 May 27 10:20 zookeeperll broker-data/
total 12
drwxr-xr-x 2 root root 4096 May 27 10:21 broker-1
drwxr-xr-x 2 root root 4096 May 27 10:21 broker-2
drwxr-xr-x 2 root root 4096 May 27 10:21 broker-3
2.安装 confluent-kafka-go 库
- 查看你的
go工作目录
echo $GOPATH
- 在
GOPATH目录下的src目录下新建produce项目
mkdir src/produce
cd src/produce
- 在你的项目目录中运行
go mod init命令来初始化一个新的Go 模块
go mod init produce
- 安装
confluent-kafka-go库
go get github.com/confluentinc/confluent-kafka-go/kafka
3.创建生产者
- 新建文件
producer.go
touch producer.go
- 编写代码
package mainimport ("fmt""log""github.com/confluentinc/confluent-kafka-go/kafka"
)func main() {// 创建生产者实例broker := "localhost:9091" // 集群地址topic := "test" // 主题名称producer, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": broker}) // 创建生产者实例// 检查错误if err != nil {log.Fatalf("Failed to create producer: %s", err)}defer producer.Close()fmt.Printf("Created Producer %v\n", producer)// 生产消息message := "hello kafka"for i := 0; i < 10; i++ {producer.Produce(&kafka.Message{TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny}, // 任题名称Value: []byte(message + fmt.Sprintf("%d", i)), // 消息内容}, nil)}if err != nil {log.Fatalf("Failed to produce message: %v", err)}// 等待消息发送完成e := <-producer.Events() // 阻塞直到消息发送完成switch ev := e.(type) {case *kafka.Message:if ev.TopicPartition.Error != nil {log.Printf("Failed to deliver message: %v", ev.TopicPartition)} else {fmt.Printf("Delivered message: %s to %v\n", string(ev.Value), ev.TopicPartition)}}// 冲刷缓冲区消息producer.Flush(15 * 1000)
}
代码说明
- 创建生产者时需要指定
集群地址以及主题信息,如果没有该主题则自动创建。 - 生产者会
异步地将消息发送到 Kafka,因此你需要处理交付报告以确保消息成功发送。
我们需要了解一下Go语言和Kafka之间的关系:Go是一种静态类型、编译型的编程语言,由Google开发并开源。它适用于构建高性能服务器端应用程序和网络服务。而Apache Kafka是一个分布式流处理平台,主要面向大规模数据传输和存储。
在这个例子中,我们有一个生产者程序,它使用Kafka的客户端库来连接到Kafka集群,然后通过创建一个生产者实例来开始发送消息。当生产者准备好要发送的消息时,它就会调用Send()方法将其添加到缓冲区中。一旦缓冲区满了或者用户主动触发了Flush()方法,生产者就会把缓冲区里的所有消息一起发送给Kafka集群。
- 编译运行,生产者发送消息
go build producer.go
./producer
Created Producer rdkafka#producer-1
Delivered message: hello kafka0 to test[0]@0
- 查看消息
ll cluster/broker-data/broker-1
total 20
-rw-r--r-- 1 root root 0 May 27 10:20 cleaner-offset-checkpoint
-rw-r--r-- 1 root root 4 May 27 11:36 log-start-offset-checkpoint
-rw-r--r-- 1 root root 88 May 27 10:20 meta.properties
-rw-r--r-- 1 root root 13 May 27 11:36 recovery-point-offset-checkpoint
-rw-r--r-- 1 root root 14 May 27 11:36 replication-offset-checkpoint
drwxr-xr-x 2 root root 4096 May 27 11:21 test-0 # 我们创建的主题 数字代表分区号ll cluster/broker-data/broker-1/test-0/
total 12
-rw-r--r-- 1 root root 10485760 May 27 11:21 00000000000000000000.index
-rw-r--r-- 1 root root 251 May 27 11:21 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 May 27 11:21 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 May 27 11:21 leader-epoch-checkpoint
-rw-r--r-- 1 root root 43 May 27 11:21 partition.metadata
特殊文件说明
Kafka 的数据文件存储在每个分区的目录中,这些文件包括 .index、.log、.timeindex、leader-epoch-checkpoint 和 partition.metadata 文件。每个文件都有其特定的用途,下面是对这些文件的详细解释:
-
.log文件:- 用途:存储实际的消息数据。
- 描述:这是 Kafka 中最重要的文件,包含了生产者发送到 Kafka 的消息。每个
.log文件代表一个日志段(log segment),文件名通常是该段的起始偏移量(offset)。
-
.index文件:- 用途:存储消息偏移量到物理文件位置的映射。
- 描述:这个文件是一个稀疏索引,允许 Kafka 快速查找特定偏移量的消息。通过这个索引,Kafka 可以避免从头开始扫描整个日志文件,从而提高查找效率。
-
.timeindex文件:- 用途:存储消息时间戳到物理文件位置的映射。
- 描述:这个文件允许 Kafka 根据时间戳快速查找消息。它是一个稀疏索引,类似于
.index文件,但索引的是时间戳而不是偏移量。
-
leader-epoch-checkpoint文件:- 用途:记录分区的领导者纪元(leader epoch)信息。
- 描述:这个文件包含了每个纪元的起始偏移量。领导者纪元是 Kafka 用来跟踪分区领导者变化的机制。每次分区领导者发生变化时,纪元号会增加。这个文件帮助 Kafka 在领导者变更时进行数据恢复和一致性检查。
-
partition.metadata文件:- 用途:存储分区的元数据信息。
- 描述:这个文件包含了分区的一些基本信息,如分区的版本号等。它帮助 Kafka 管理和维护分区的元数据。
这些文件共同作用,确保 Kafka 能够高效、可靠地存储和检索消息数据。
如何查看.log文件内容
- 执行指令
~/cluster/broker-1/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log --print-data-log
~/cluster/broker-1/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log --print-data-log
Dumping ./00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 9 count: 10 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1716780091840 size: 251 magic: 2 compresscodec: none crc: 997822510 isvalid: true
| offset: 0 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka0
| offset: 1 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka1
| offset: 2 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka2
| offset: 3 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka3
| offset: 4 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka4
| offset: 5 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka5
| offset: 6 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka6
| offset: 7 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka7
| offset: 8 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka8
| offset: 9 CreateTime: 1716780091840 keySize: -1 valueSize: 12 sequence: -1 headerKeys: [] payload: hello kafka9
如上我们可以看到消息已经成功的发送。
4.创建消费者
- 创建消费者项目
mkdir src/consume
cd src/consume
- 在你的项目目录中运行
go mod init命令来初始化一个新的Go 模块
go mod init consume
- 安装
confluent-kafka-go库
go get github.com/confluentinc/confluent-kafka-go/kafka
- 新建文件
touch consumer.go
- 编写代码
package mainimport ("fmt""log""github.com/confluentinc/confluent-kafka-go/kafka"
)func main() {// 创建消费者实例broker := "localhost:9091" // 集群地址topic := "test" // 主题名称c, err := kafka.NewConsumer(&kafka.ConfigMap{"bootstrap.servers": broker, // 集群地址"group.id": "my-group", // 消费者组"auto.offset.reset": "earliest", // 设置偏移量 从头开始消费})// 检查错误if err != nil {log.Printf("Failed to create consumer: %s\n", err)}defer c.Close()// 描述订阅主题c.SubscribeTopics([]string{topic}, nil)fmt.Printf("Consuming topic %s\n", topic)// 消费消息for {msg, err := c.ReadMessage(-1) // 阻塞直到消息到达if err == nil {fmt.Printf("Consumed message: %s\n", msg.Value)} else {// 消费者错误fmt.Printf("Consumer error: %v (%v)\n", err, msg)}}
}
- 编译并运行
go build consumer.go
./consumer
Consuming topic test
Consumed message: hello kafka0
Consumed message: hello kafka1
Consumed message: hello kafka2
Consumed message: hello kafka3
Consumed message: hello kafka4
Consumed message: hello kafka5
Consumed message: hello kafka6
Consumed message: hello kafka7
Consumed message: hello kafka8
Consumed message: hello kafka9可以看到已经成功的消费刚才生产的消息。
相关文章:

Go 如何通过 Kafka 客户端库 生产与消费消息
文章目录 0.前置说明1. confluent-kafka-go2. sarama3. segmentio/kafka-go4. franz-go选择建议 1.启动 kafka 集群2.安装 confluent-kafka-go 库3.创建生产者特殊文件说明如何查看.log文件内容 4.创建消费者 0.前置说明 Go 语言中有一些流行的 Kafka 客户端库。以下是几个常用…...
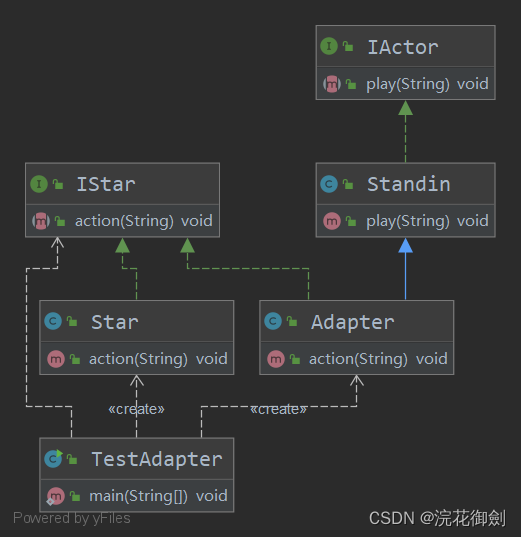
【设计模式深度剖析】【B】【结构型】【对比】| 主要区别包装的不同
👈️上一篇:享元模式 回 顾:结构型设计模式 1.代理模式👈️ 2.装饰器模式👈️ 3.适配器模式👈️ 4.组合模式👈️ 5.桥接模式👈️ 6.外观模式👈️ 7.享元模式&#x…...

信息学奥赛初赛天天练-17-阅读理解-浮点数精准输出与海伦公式的巧妙应用
PDF文档公众号回复关键字:20240531 1 2023 CSP-J 阅读程序1 阅读程序(程序输入不超过数组成字符串定义的范围:判断题正确填√,错误填;除特殊说明外,判断题1.5分,选择题3分,共计40分࿰…...

mysql - 为什么MySQL不建议使用NULL作为列默认值?
为什么MySQL不建议使用NULL作为列默认值? InnoDB有4中行格式: Redundant : 非紧凑格式,5.0 版本之前用的行格式,目前很少使用,Compact : 紧凑格式,5.1 版本之后默认行格式,可以存储更多的数据Dynamic , Compressed : 和Compact类似,5.7 版本之后默认使…...

数据分析案例-在线食品订单数据可视化分析与建模分类
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

构建LangChain应用程序的示例代码:2、使用LangChain库实现的AutoGPT示例:查找马拉松获胜成绩
AutoGPT 示例:查找马拉松获胜成绩 实现 https://github.com/Significant-Gravitas/Auto-GPT,使用LangChain基础组件(大型语言模型(LLMs)、提示模板(PromptTemplates)、向量存储(VectorStores)、嵌入(Embeddings)、工具(Tools))。…...

代码随想录算法训练营第三十四 |● 1005.K次取反后最大化的数组和 ● 134. 加油站 ● 135. 分发糖果
今天的解析写在了代码注释中 1005.K次取反后最大化的数组和 讲解链接:https://programmercarl.com/1005.K%E6%AC%A1%E5%8F%96%E5%8F%8D%E5%90%8E%E6%9C%80%E5%A4%A7%E5%8C%96%E7%9A%84%E6%95%B0%E7%BB%84%E5%92%8C.html class Solution { public:static bool cmp(i…...

GB-T 43206-2023 信息安全技术 信息系统密码应用测评要求
GB-T 43206-2023 信息安全技术 信息系统密码应用测评要求 编写背景 随着信息技术的飞速发展,信息系统在社会经济活动中扮演着越来越重要的角色。信息安全问题也随之成为社会关注的焦点。GB-T 43206-2023《信息安全技术 信息系统密码应用测评要求》是针对信息系统中…...

线程进阶-1 线程池
一.说一下线程池的执行原理 1.线程池的七大核心参数 (1)int corePoolSize:核心线程数。默认情况下核心线程会一直存活,当设置allowCoreThreadTimeout为true时,核心线程也会被超时回收。 (2)i…...
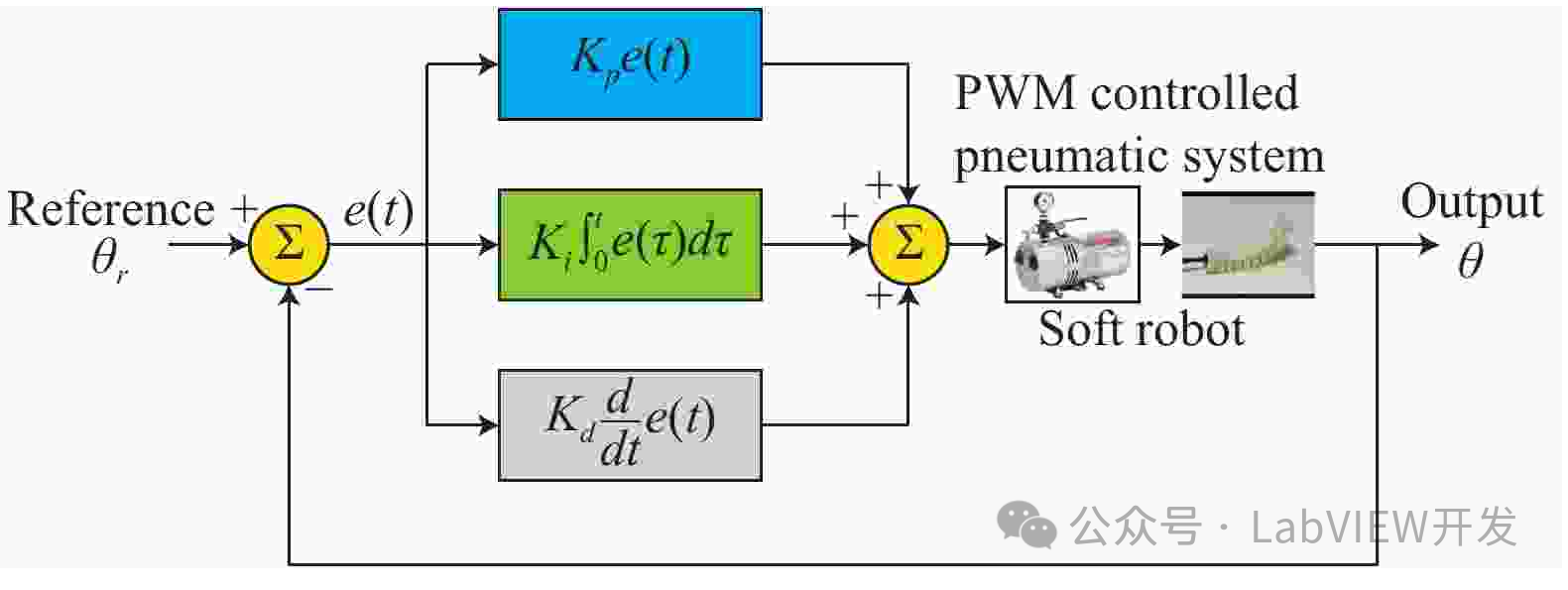
LabVIEW中PID控制器系统的噪声与扰动抑制策略
在LabVIEW中处理PID控制器系统中的噪声和外部扰动,需要从信号处理、控制算法优化、硬件滤波和系统设计四个角度入手。采用滤波技术、调节PID参数、增加前馈控制和实施硬件滤波器等方法,可以有效减少噪声和扰动对系统性能的影响,提高控制系统的…...
JavaWeb笔记整理+图解——Listener监听器
欢迎大家来到这一篇章——Listener监听器 监听器和过滤器都是JavaWeb服务器三大组件(Servlet、监听器、过滤器)之一,他们对于Web开发起到了不可缺少的作用。 ps:想要补充Java知识的同学们可以移步我已经完结的JavaSE笔记&#x…...
AIGC智能办公实战 课程,祝你事业新高度
在数字化时代,人工智能(AI)已经渗透到我们生活的方方面面,从智能家居到自动驾驶,从医疗诊断到金融分析,AI助手正在改变我们的工作方式和生活质量。那么,你是否想过自己也能从零开始,…...

专科生听劝 这种情况你就不要专转本了
罗翔老师说过,读书学习主要作用是提高人的下限 我们能掌握的只有学习,以确保学历不会太差再去等机遇让自己活得更好 大部分情况来说,专科生努力去专转本挺好的提升自己准没错,我当年也是一心这样想的,但今天不得不说点…...

MySQL增删查改初阶
目录 一,数据库操作 1.关键字 show 显示当前数据库有哪些:show databases; 2.创建数据库 3.选中数据库 4.删除数据库 二,表的操作,在选中数据库的基础之上 1.查看表的结构 2.创建表 3.查看当前选中的数据库中…...

IService 接口中定义的常用方法
文心一言生成 以下是一些 IService 接口中定义的常用方法(以你提供的 UserSQL 类为例,该类继承自 ServiceImpl,因此也会拥有这些方法): 插入(新增) boolean save(T entity): 插入一条记录&…...
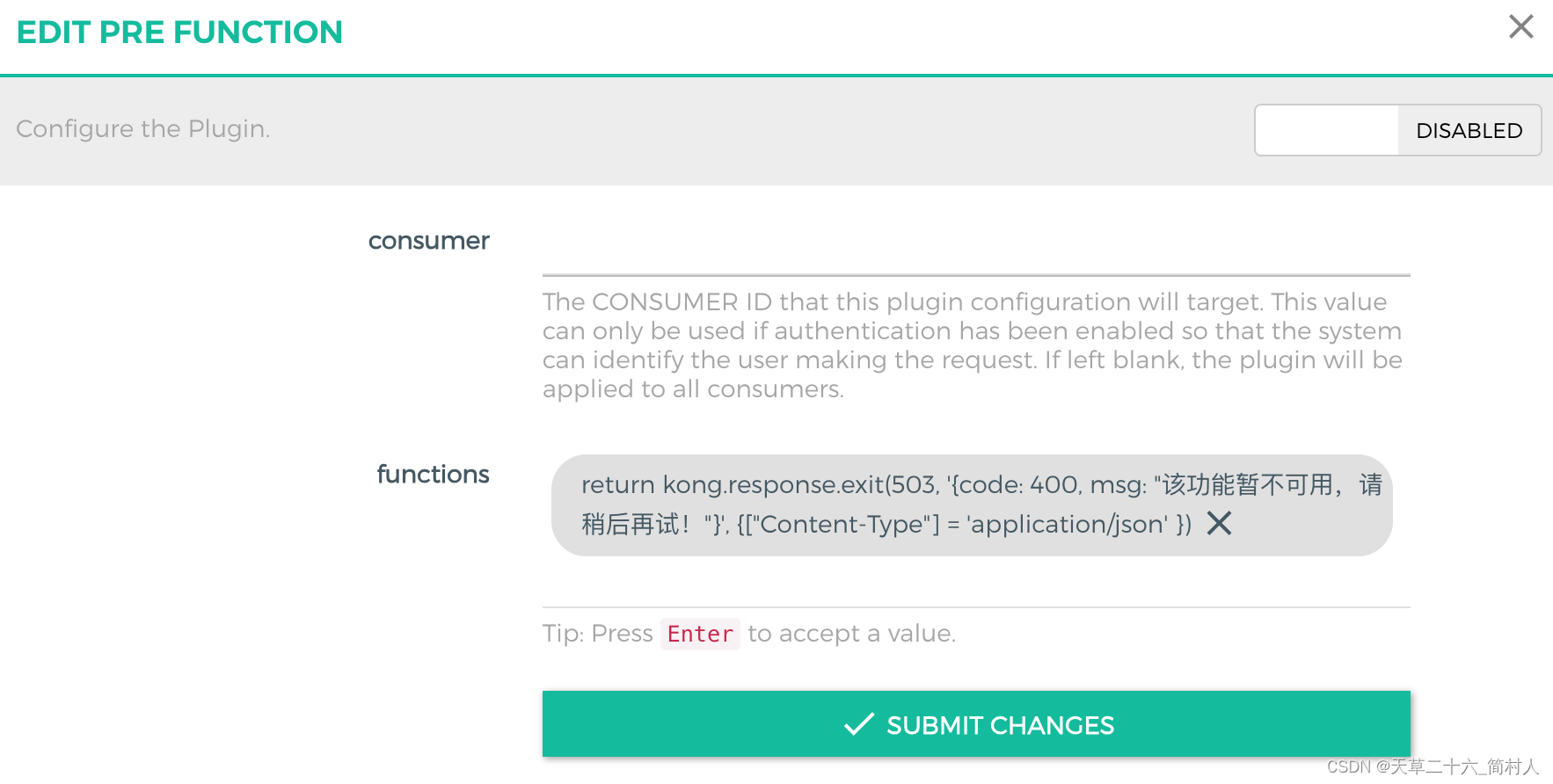
api网关kong对高频的慢接口进行熔断
一、背景 在生产环境,后端服务的接口响应非常慢,是因为数据库未创建索引导致。 如果QPS低的时候,因为后端服务有6个高配置的节点,虽然接口慢,还未影响到服务的正常运行。 但是,当QPS很高的时候,…...

python作业:实现一个任务列表管理系统,使用到python类、对象、循环等知识
实现一个简单的任务列表管理系统,可以用于python学习的作业或者练习。系统的功能包括: 用户可以添加任务、查看任务列表、标记任务为已完成,以及删除任务。 代码如下: class Task: def __init__(self, name, completedFalse):…...
如何开展电子商品渠道价格监测)
大宋咨询(深圳产品价格调查)如何开展电子商品渠道价格监测
开展电子商品渠道价格监测是当今电商时代的重要任务之一。随着电子商务的迅猛发展,电子商品的价格波动日益频繁,市场竞争也愈发激烈。为了解优化渠道管理策略,提升品牌竞争力,大宋咨询(深圳市场调查)受客户…...
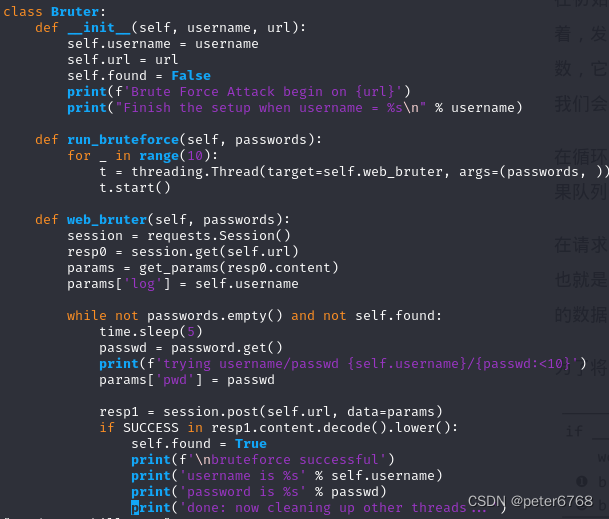
py黑帽子学习笔记_web攻击
python网络库 py2的urllib2 py3好像把urllib2继承到了标准库urllib,直接用urllib就行,urllib2在urllib里都有对应的接口 py3的urllib get请求 post请求,和get不同的是,先把post请求数据和请求封装到request对象,再…...
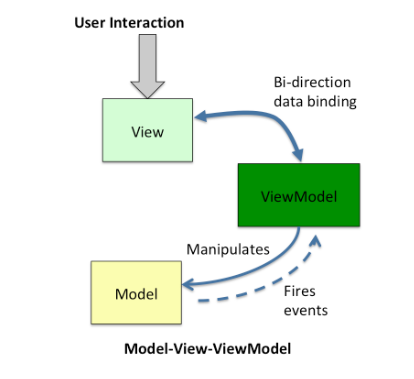
MVC、MVP 和 MVVM 架构总结
MVC、MVP 和 MVVM 是常见的软件架构模式,主要用于组织应用程序的结构,特别是在用户界面和业务逻辑之间进行分离。以下是对它们的详细解释,包括它们的差异、优缺点。 MVC(Model-View-Controller) 结构 Model…...

别再只怪USB线了!i.MX6Q用Mfgtools烧录rootfs.tar.bz2报错的深层硬件排查指南
i.MX6Q烧录故障的硬件级诊断:从USB OTG冲突到电源完整性排查 当Mfgtools在rootfs.tar.bz2传输阶段突然报错"Push error"或"No Device Connected"时,多数开发者会本能地检查USB线缆或驱动配置。但真正棘手的故障往往潜伏在硬件交互层…...

【ElevenLabs阿拉伯文语音实战指南】:20年AI语音工程师亲授7大本地化陷阱与3步高保真合成法
更多请点击: https://intelliparadigm.com 第一章:阿拉伯语语音合成的独特挑战与ElevenLabs能力边界 阿拉伯语语音合成(TTS)面临多重语言学与技术层面的固有挑战,远超拉丁语系语言的常规处理范畴。其核心难点在于右向…...

Termux安装Linux总失败?可能是你的安卓版本太老了!手把手解决apt update报错
Termux在老旧安卓设备上的终极解决方案:从原理到实践 你是否也曾在抽屉深处翻出一台尘封多年的安卓设备,满心欢喜地想要通过Termux让它重获新生,却在apt update的报错信息前铩羽而归?这并非个例——据统计,全球仍有超过…...

ISG系统三大电机结构深度解析:永磁同步、感应与开关磁阻电机对比
1. 项目概述:从“电机”到“ISG系统”的深度关联在混合动力与新能源车领域,ISG(Integrated Starter Generator,集成式启动发电一体机)系统是一个核心的动力单元。它不像传统汽车那样,启动电机和发电机是分开…...
)
出租车计价器控制电路的设计(有完整资料)
编号:CJ-32-2022-046设计简介:本设计是出租车计价器控制电路的设计,主要实现以下功能:1、出租车计价器系统以Km 为单位统计里程,以元为单位统计总金额; 2、通过霍尔传感器和电机获取速度和路程;…...

从零构建高性能内存键值存储:Memvault架构设计与实现详解
1. 项目概述:一个为内存数据打造的“保险箱”最近在折腾一些需要处理大量临时数据的项目,比如实时计算、缓存中间层,还有那种对延迟极其敏感的游戏服务器。这类场景下,Redis这类内存数据库是首选,但总感觉有点“杀鸡用…...

5分钟学会无损视频修复:untrunc让损坏MP4/MOV文件瞬间复活
5分钟学会无损视频修复:untrunc让损坏MP4/MOV文件瞬间复活 【免费下载链接】untrunc Restore a truncated mp4/mov. Improved version of ponchio/untrunc 项目地址: https://gitcode.com/gh_mirrors/un/untrunc 你是否经历过重要视频突然无法播放的绝望时刻…...

如何高效配置Cool Request插件:Spring Boot接口调试的终极实践指南
如何高效配置Cool Request插件:Spring Boot接口调试的终极实践指南 【免费下载链接】cool-request IDEA API、Java Method debug tools 项目地址: https://gitcode.com/gh_mirrors/co/cool-request Cool Request是一款专为IntelliJ IDEA设计的强大HTTP接口调…...

免费LLM API资源全解析:从选型接入到避坑实战指南
1. 项目概述:一个免费LLM API的“藏宝图”如果你最近在捣鼓一些AI小应用,或者想低成本地体验一下大语言模型的能力,大概率会和我一样,被一个问题卡住:去哪里找免费、稳定、还能用的LLM API?市面上各种模型服…...

完全掌握Adobe软件激活:5个实用技巧深度解析
完全掌握Adobe软件激活:5个实用技巧深度解析 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经为Adobe Creative Cloud的订阅费用感到困扰&…...