Spark RDD案例
Apache Spark中的RDD(Resilient Distributed Dataset)是一个不可变、分布式对象集合,它允许用户在大型集群上执行并行操作。虽然RDD在Spark的早期版本中非常核心,但随着DataFrame和Dataset的引入,RDD的使用在某些场景下有所减少,因为DataFrame和Dataset提供了更高级别和类型安全的API。然而,RDD在某些特定的计算任务中仍然非常有用。
以下是一个Spark RDD的典型案例,它展示了如何使用RDD进行词频统计(Word Count):
import org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {// 创建SparkConf对象并设置应用信息val conf = new SparkConf().setAppName("Word Count").setMaster("local[*]")// 创建SparkContext对象,它是所有功能的入口点val sc = new SparkContext(conf)// 读取输入文件并转换为RDDval inputRDD = sc.textFile("path/to/input/file.txt")// 将每一行文本分割成单词,并扁平化成一个单词RDDval wordsRDD = inputRDD.flatMap(line => line.split(" "))// 将单词转换为小写(可选)val lowerCaseWordsRDD = wordsRDD.map(word => word.toLowerCase())// 计算每个单词的频率(使用map和reduceByKey操作)val wordCountsRDD = lowerCaseWordsRDD.map(word => (word, 1)).reduceByKey(_ + _)// 将结果RDD中的数据收集到驱动程序并打印wordCountsRDD.collect().foreach(println)// 停止SparkContextsc.stop()}
}
这个案例做了以下几件事:
- 创建一个
SparkConf对象来配置Spark应用。 - 使用
SparkConf对象创建一个SparkContext对象,这是所有功能的入口点。 - 使用
textFile方法从文件系统中读取文本文件,并将其转换为一个RDD。 - 使用
flatMap操作将每一行文本分割成单词,并扁平化为一个包含所有单词的RDD。 - 使用
map操作将单词转换为小写(这是一个可选步骤,但它可以确保单词计数时不区分大小写)。 - 使用
map和reduceByKey操作计算每个单词的频率。map操作将每个单词映射到一个键值对(单词,1),然后reduceByKey操作将具有相同键的值相加,以计算每个单词的总数。 - 使用
collect操作将结果RDD中的数据收集到驱动程序中,并使用foreach打印每个键值对(单词和它的计数)。 - 调用
stop方法停止SparkContext。
请注意,这个案例是Spark RDD编程模型的一个基本示例,用于演示RDD的基本操作和转换。在实际应用中,您可能会处理更大的数据集,并使用更复杂的转换和操作。此外,随着Spark的不断发展,DataFrame和Dataset API通常提供了更简洁、类型安全且性能优化的方式来处理数据。
以下是使用Scala编写的完整Spark RDD代码示例,用于进行词频统计(Word Count):
import org.apache.spark.{SparkConf, SparkContext}object WordCount {def main(args: Array[String]): Unit = {// 创建SparkConf对象并设置应用信息val conf = new SparkConf().setAppName("Word Count").setMaster("local[*]")// 创建SparkContext对象,它是所有功能的入口点val sc = new SparkContext(conf)// 读取输入文件(假设args[0]是文件路径)val inputRDD = sc.textFile(if (args.length > 0) args(0) else "path/to/input/file.txt")// 将每一行文本分割成单词,并扁平化成一个单词RDDval wordsRDD = inputRDD.flatMap(line => line.split(" "))// 将单词转换为小写(可选)val lowerCaseWordsRDD = wordsRDD.map(word => word.toLowerCase())// 过滤掉空字符串val filteredWordsRDD = lowerCaseWordsRDD.filter(_.nonEmpty)// 计算每个单词的频率(使用map和reduceByKey操作)val wordCountsRDD = filteredWordsRDD.map(word => (word, 1)).reduceByKey(_ + _)// 输出结果(可以保存到文件,也可以只是打印出来)wordCountsRDD.collect().foreach(println)// 停止SparkContextsc.stop()}
}
在这段代码中,我们增加了一些改进:
-
检查命令行参数,以确定输入文件的路径(
args(0))。如果没有提供参数,它将默认使用"path/to/input/file.txt"作为文件路径。 -
在将单词转换为小写之后,我们增加了一个
filter操作来移除空字符串(这可能在分割文本行时产生)。 -
我们使用
collect操作将最终的RDD(wordCountsRDD)中的所有元素收集到驱动程序,并使用foreach遍历和打印它们。
请注意,在实际生产环境中,您可能希望将结果保存到文件或数据库中,而不是仅仅打印它们。您可以使用saveAsTextFile、saveAsParquetFile、saveAsTable等方法来保存结果。
此外,如果您正在使用Spark的集群模式,您应该使用集群管理器(如YARN、Mesos或Standalone)来设置setMaster的值,而不是使用"local[*]"(这是在本地机器上运行的单机模式)。
在编译和运行Scala程序时,您需要使用sbt(简单构建工具)或Maven等构建工具来管理依赖和构建过程。您还需要将Spark的相关库添加到项目的依赖中。
相关文章:

Spark RDD案例
Apache Spark中的RDD(Resilient Distributed Dataset)是一个不可变、分布式对象集合,它允许用户在大型集群上执行并行操作。虽然RDD在Spark的早期版本中非常核心,但随着DataFrame和Dataset的引入,RDD的使用在某些场景下…...

【线性表 - 数组和矩阵】
数组是一种连续存储线性结构,元素类型相同,大小相等,数组是多维的,通过使用整型索引值来访问他们的元素,数组尺寸不能改变。 知识点数组与矩阵相关题目 # 知识点 数组的优点: 存取速度快 数组的缺点: 事先必须知道…...

Springboot 开发 -- 跨域问题技术详解
一、跨域的概念 跨域访问问题指的是在客户端浏览器中,由于安全策略的限制,不允许从一个源(域名、协议、端口)直接访问另一个源的资源。当浏览器发起一个跨域请求时,会被浏览器拦截,并阻止数据的传输。 这…...
)
【Qt】之【项目】整理可参考学习的git项目链接(持续更新)
Tcp 通信相关 IM即时通讯设计 高并发聊天服务:服务器 qt客户端(附源码) - DeRoy - 博客园 未使用protobuf通讯协议格式 github:GitHub - ADeRoy/chat_room: IM即时通讯设计 高并发聊天服务:服务器 qt客户端 QT编…...

2024年5月个人工作生活总结
本文为 2024年5月工作生活总结。 研发编码 golang 多个defer函数执行顺序 golang 函数中如有多个defer,倒序执行。示例代码: func foo() {defer func() {fmt.Println("111")}()defer func() {fmt.Println("2222")}()defer func()…...
Kafka Java API
1、增加依赖 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>1.0.0</version> </dependency>2、三个案例 案例1:生产数据 import org.apache.kafka.clients.p…...

pushd: not found
解决方法: pushd 比 cd 命令更高效的切换命令,非默认,可在脚本开头添加: #! /bin/bash ubuntu 编译时出现/bin/sh: 1: pushd: not found的问题-CSDN博客...
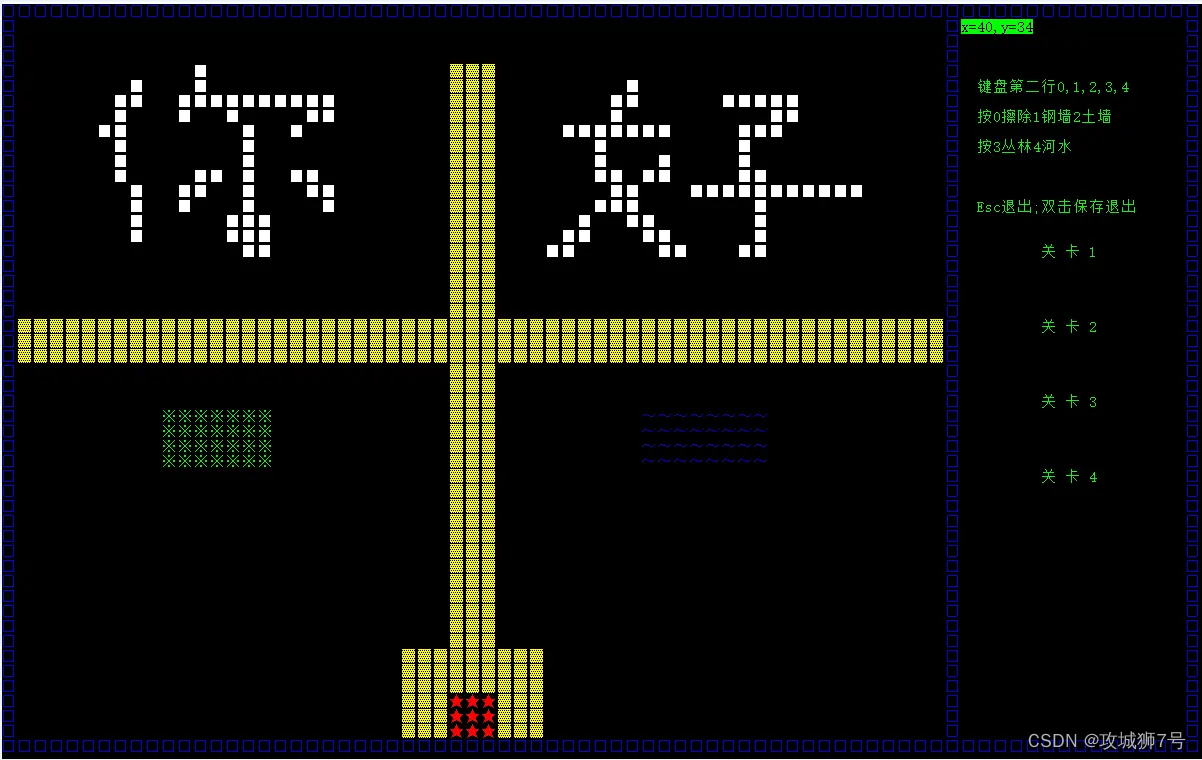
【第十三节】C++控制台版本坦克大战小游戏
目录 一、游戏简介 1.1 游戏概述 1.2 知识点应用 1.3 实现功能 1.4 开发环境 二、项目设计 2.1 类的设计 2.2 各类功能 三、程序运行截图 3.1 游戏主菜单 3.2 游戏进行中 3.3 双人作战 3.4 编辑地图 一、游戏简介 1.1 游戏概述 本项目是一款基于C语言开发的控制台…...
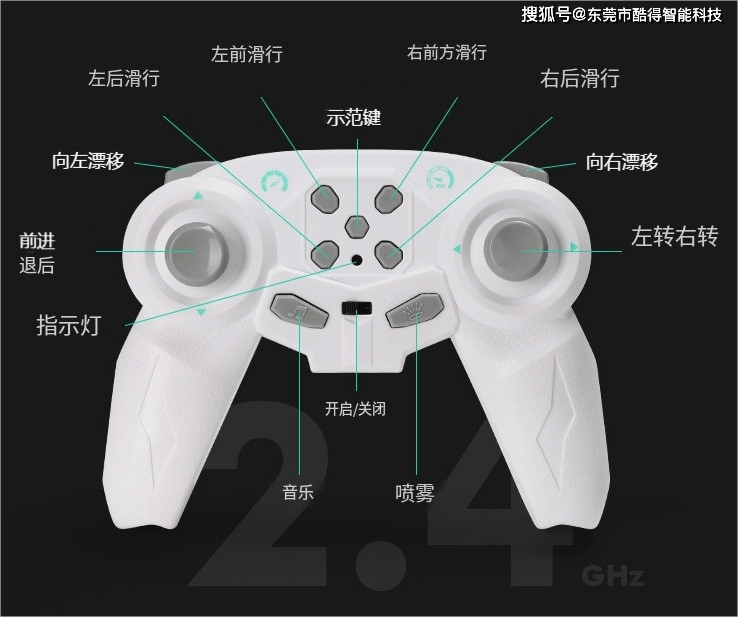
酷得单片机方案 2.4G儿童遥控漂移车
电子方案开发定制,我们是专业的 东莞酷得智能单片机方案之2.4G遥控玩具童车具有以下比较有特色的特点: 1、内置充电电池:这款小车配备了可充电的电池,无需频繁更换电池,既环保又方便。充电方式可能为USB充电或者专用…...

【为什么 Google Chrome 打开网页有时极慢?尤其是国内网站,如知网等】
要通过知网搜一点资料,发现怎么都打不开。而且B站,知乎这些速度也变慢了!已经检查过确定不是网络的问题。 清空了记录,清空了已接受Cookie,清空了缓存内容……没用!!! 不断搜索&am…...

FastAPI - 数据库操作5
先安装mysql驱动程序 pipenv install pymysql安装数据库ORM库SQLAlchemy pipenv install SQLAlchemy修改文件main.py文件内容 设置数据库连接 # -*- coding:utf-8 –*- from fastapi import FastAPIfrom sqlalchemy import create_engineHOST 192.168.123.228 PORT 3306 …...

HTML静态网页成品作业(HTML+CSS)—— 冶金工程专业展望与介绍介绍网页(2个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有2个页面。 二、作品演示 三、代…...
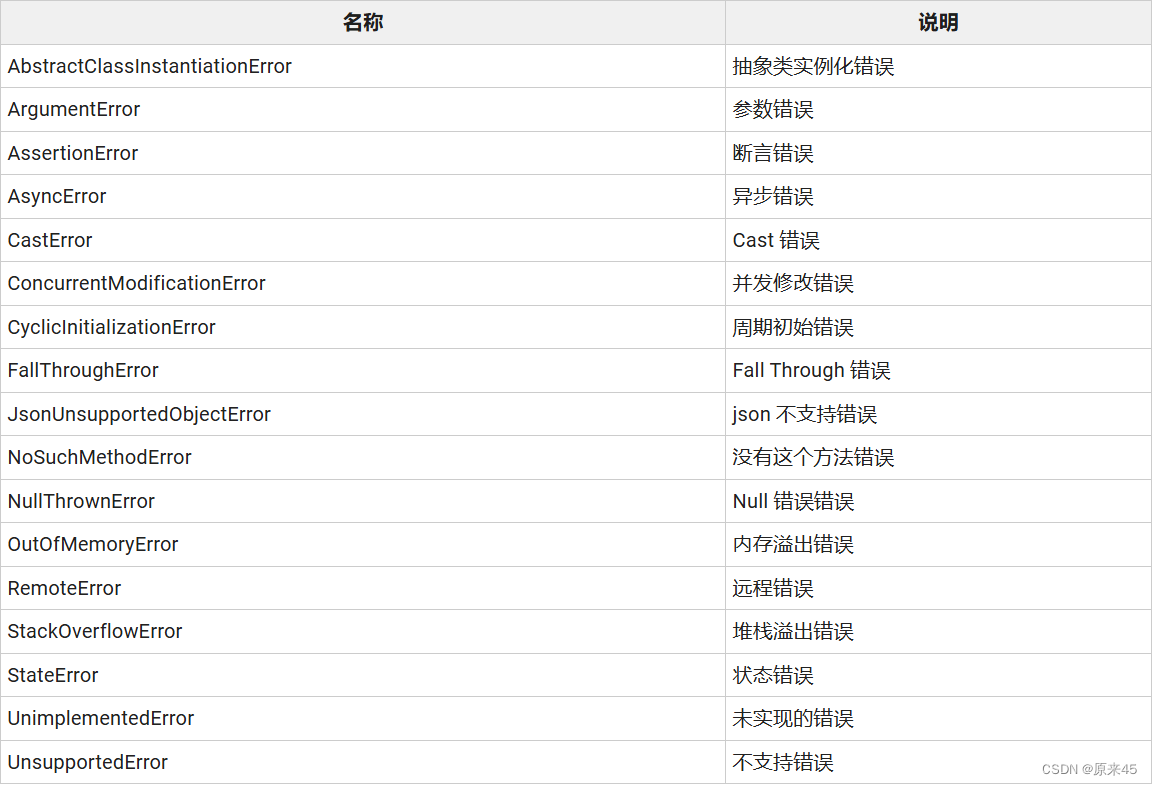
Flutter基础 -- Dart 语言 -- 注释函数表达式
目录 1. 注释 1.1 单行注释 1.2 多行注释 1.3 文档注释 2. 函数 2.1 定义 2.2 可选参数 2.3 可选参数 默认值 2.4 命名参数 默认值 2.5 函数内定义 2.6 Funcation 返回函数对象 2.7 匿名函数 2.8 作用域 3. 操作符 3.1 操作符表 3.2 算术操作符 3.3 相等相关的…...
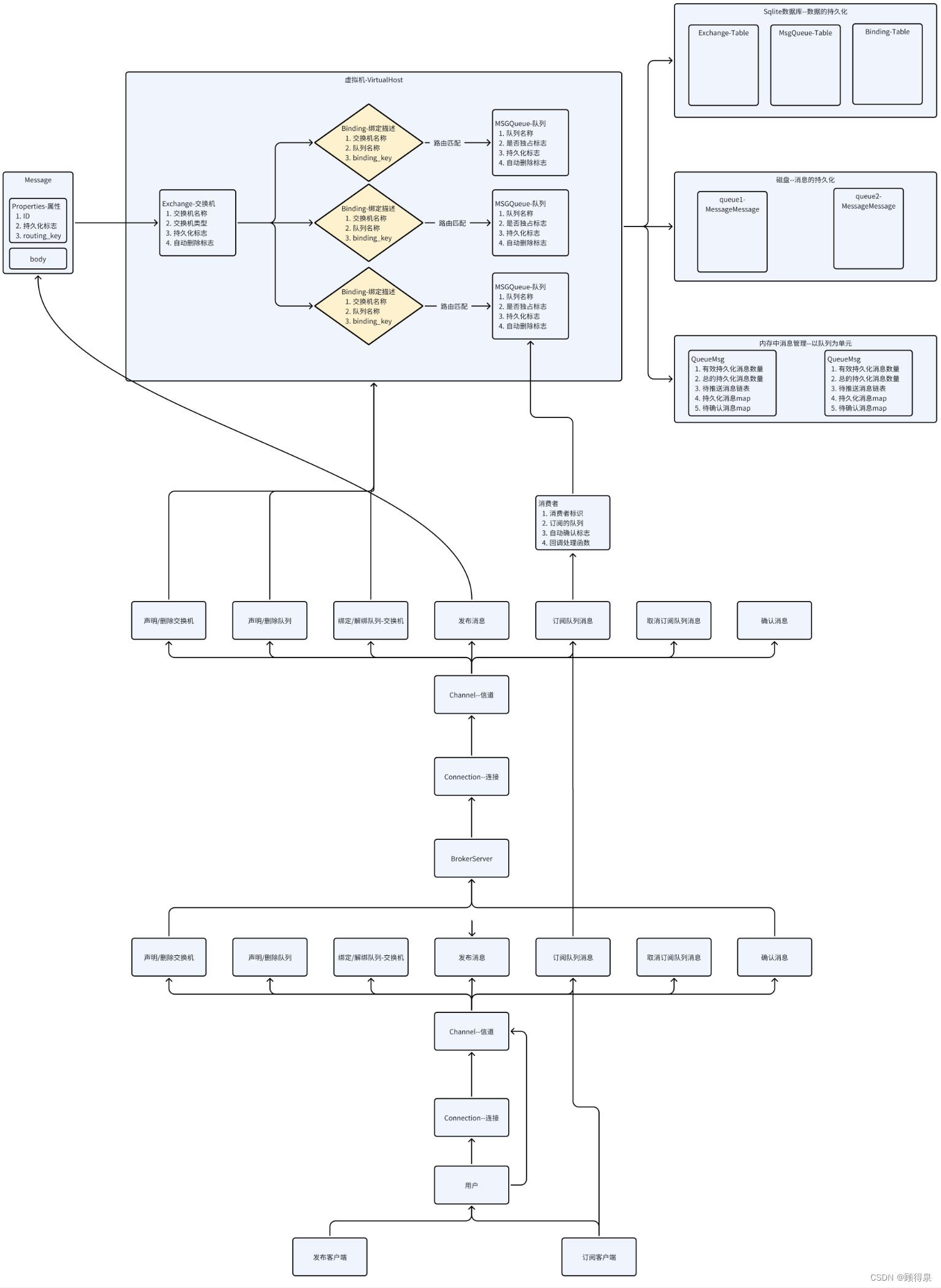
“仿RabbitMQ实现消息队列”---整体架构与模块说明
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C从入门到精通》 《LeedCode刷题》 键盘敲烂,年薪百万! 一、概念性框架理解 我们主要实现的内容: 1.Broker服务器:消息队列服务器(服务端&…...

springboot如何快速接入minio对象存储
1.在项目中添加 Minio 的依赖,在使用 Minio 之前,需要在项目中添加 Minio 的依赖。可以在 Maven 的 pom.xml 文件中添加以下依赖: <dependency><groupId>io.minio</groupId><artifactId>minio</artifactId>&l…...

第六届“智能设计+运维”国产工业软件研讨会暨2024年天洑软件用户大会圆满召开
2024年5月23-24日,第六届“智能设计运维”国产工业软件研讨会暨2024年天洑软件用户大会在南京举办。来自国产工业软件研发企业、制造业企业、高校、科研院所的业内大咖,能源动力、船舶海事、车辆运载、航空航天、新能源汽车、动力电池、消费电子、石油石…...
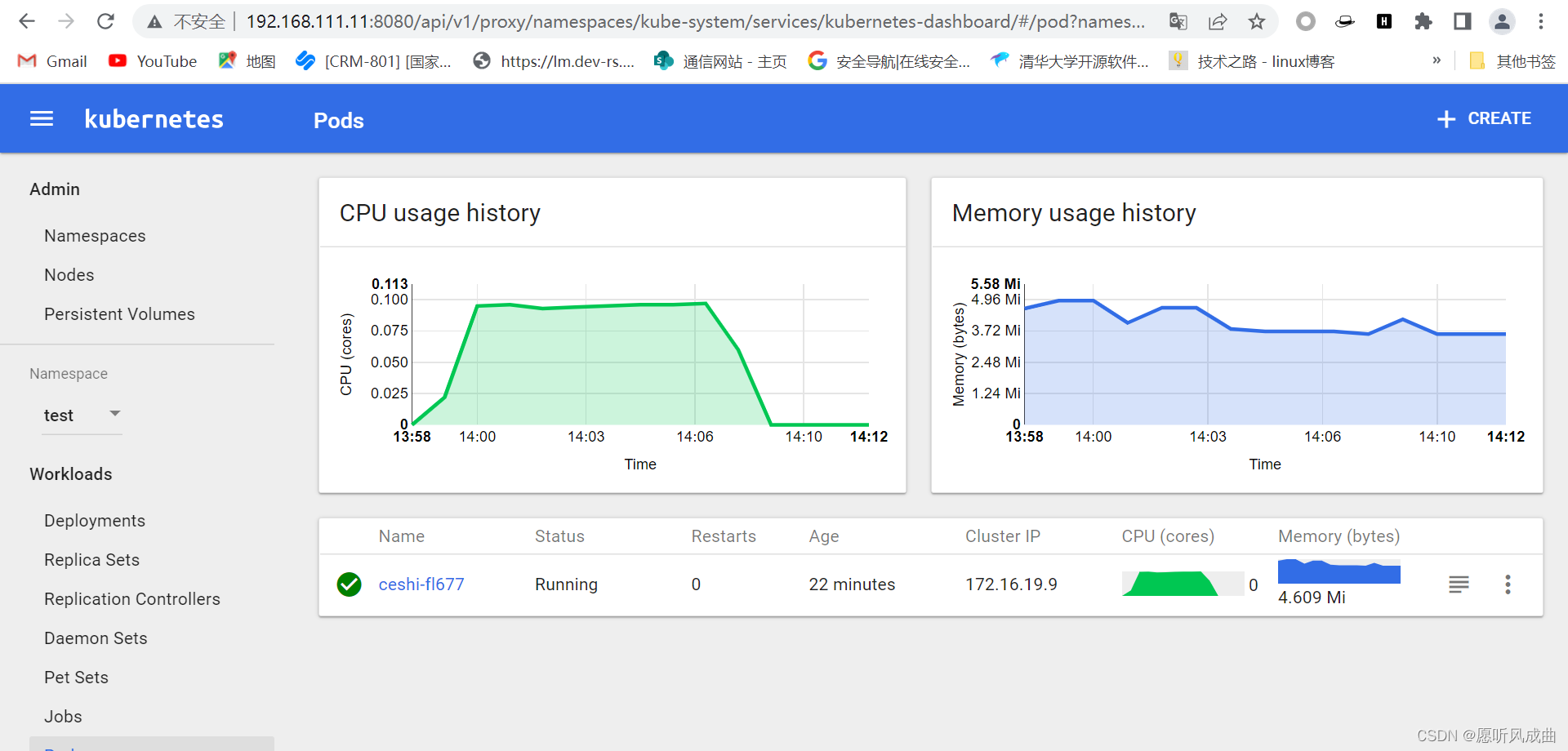
05.k8s弹性伸缩
5.k8s弹性伸缩 k8s弹性伸缩,需要附加插件heapster监控 弹性伸缩:随着业务访问量的大小,k8s系统中的pod比较弹性,会自动增加或者减少pod数量; 5.1 安装heapster监控 1:上传并导入镜像,打标签 ls *.tar.gz for n in ls *.tar.gz…...
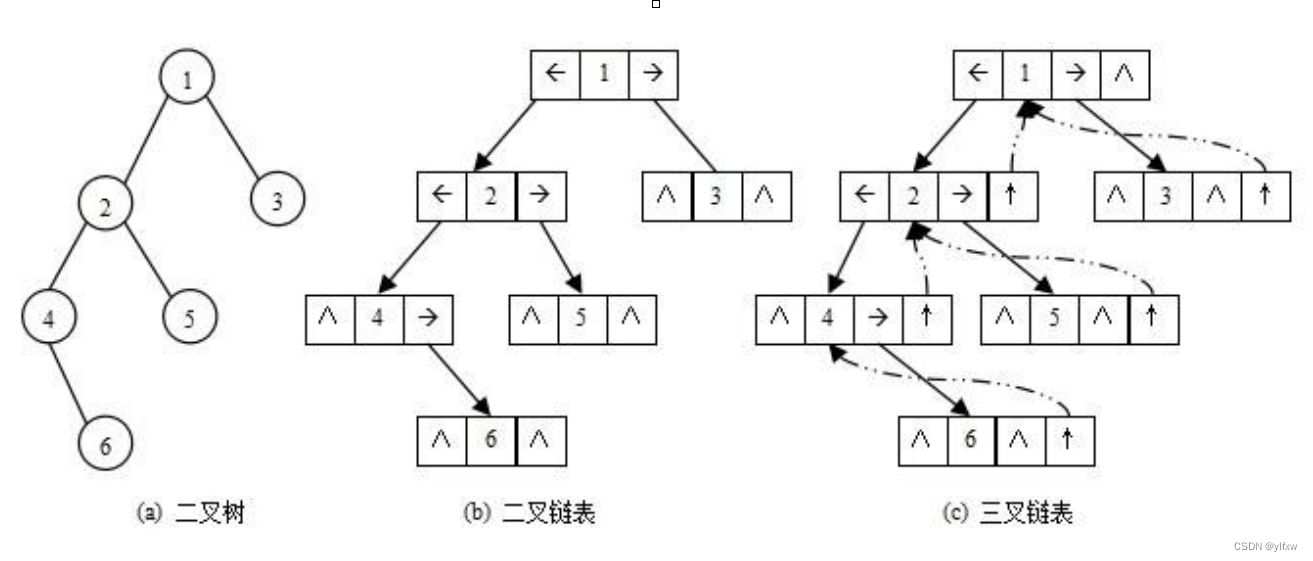
【数据结构】详解二叉树
文章目录 1.树的结构及概念1.1树的概念1.2树的相关结构概念1.3树的表示1.4树在实际中的应用 2.二叉树的结构及概念2.1二叉树的概念2.2特殊的二叉树2.2.1满二叉树2.2.2完全二叉树 2.3 二叉树的性质2.4二叉树的存储结构2.4.1顺序结构2.4.2链表结构 1.树的结构及概念 1.1树的概念…...

MapDB:轻量级、高性能的Java嵌入式数据库引擎
MapDB:轻量级、高性能的Java嵌入式数据库引擎 在今天的软件开发中,嵌入式数据库因其轻便、高效和易于集成而备受欢迎。对于Java开发者来说,MapDB无疑是一个值得关注的选项。MapDB是一个纯Java编写的嵌入式数据库引擎,它提供了高性…...

Rye: 一个革新的Python包管理工具
文章目录 Rye: 一个革新的Python包管理工具Rye的诞生背景Rye的核心特性Rye的安装与使用Rye的优势与挑战Rye的未来展望结语 Rye: 一个革新的Python包管理工具 在Python生态系统中,包管理一直是一个复杂且令人头疼的问题。随着Python社区的不断发展,出现了…...

3步学会使用Tinke:免费NDS游戏资源提取与修改终极指南
3步学会使用Tinke:免费NDS游戏资源提取与修改终极指南 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾经想过提取NDS游戏中的精美图片、动听音乐,或者修改游戏文本…...

深入TEA5767数据手册:51单片机I²C驱动FM收音模块的避坑指南与调试心得
深入解析TEA5767:51单片机驱动FM收音模块的实战技巧 在嵌入式开发领域,能够独立解读芯片手册并实现功能驱动是工程师的核心能力之一。TEA5767作为一款经典的FM收音芯片,因其低功耗、高集成度和简单的IC接口而广受欢迎。本文将从一个实际开发者…...

SDEP协议与SPI-BLE数据传输:从理论到实战的深度解析
1. SDEP协议与SPI-BLE数据传输:从理论到实战的深度解析在物联网和嵌入式开发领域,如何让一个资源受限的微控制器(MCU)与一个复杂的无线模块稳定、高效地“对话”,一直是个既基础又关键的挑战。你可能遇到过这样的场景&…...

如何构建智能的多显示器窗口布局持久化解决方案
如何构建智能的多显示器窗口布局持久化解决方案 【免费下载链接】PersistentWindows fork of http://www.ninjacrab.com/persistent-windows/ with windows 10 update 项目地址: https://gitcode.com/gh_mirrors/pe/PersistentWindows PersistentWindows 是一个开源工具…...

突破Cursor AI试用限制:技术实现与实战指南
突破Cursor AI试用限制:技术实现与实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial request…...

Midjourney v7艺术风格跃迁路径:从基础写实到超现实叙事的5阶能力模型,含GPT-4o协同提示链模板
更多请点击: https://intelliparadigm.com 第一章:Midjourney v7艺术风格跃迁路径总览 Midjourney v7 并非简单迭代,而是以扩散模型架构重构与多模态风格理解为内核的范式跃迁。其核心突破在于引入「语义风格锚点(Semantic Style…...
)
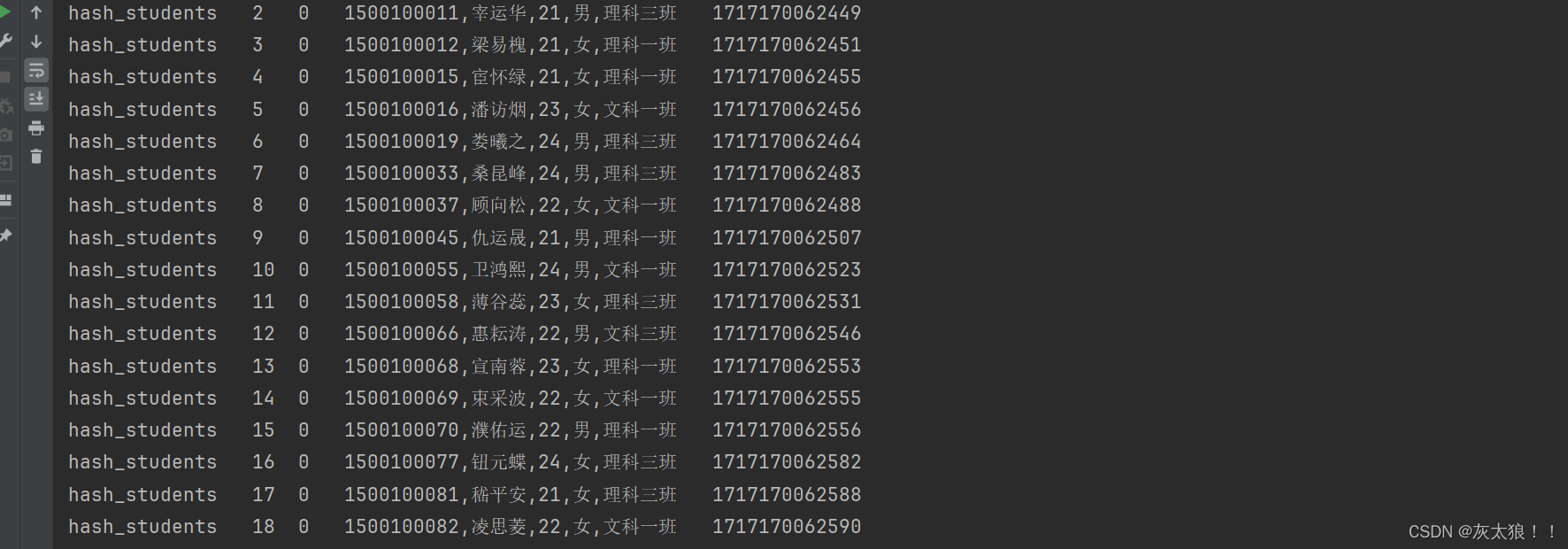
别再死记硬背排序了!‘原地哈希’如何用交换搞定特定数组排序(保姆级图解)
别再死记硬背排序了!‘原地哈希’如何用交换搞定特定数组排序(保姆级图解) 每次提到排序算法,你的第一反应是不是快速排序、归并排序这些经典方法?但面对特定场景的数组排序,这些"大炮打蚊子"式的…...

macOS微信防撤回终极指南:3分钟轻松安装WeChatIntercept插件
macOS微信防撤回终极指南:3分钟轻松安装WeChatIntercept插件 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微…...

AI 的能源账单:训练一次模型够一个城市用一年、$440 亿投资涌入、核能成为新基建 — 算力背后的环境代价
Stanford HAI 2026 年 AI Index 报告用一组数字泼了盆冷水:AI 模型正在取得突破性的科学和推理成果,但环境代价高到令人不安。报告披露:一个前沿大模型的单次训练,能耗相当于一个小型城市一天的全部用电量。而 2024-2026 年间&…...

开发者技能图谱实战指南:从结构化知识到可执行代码的进阶之路
1. 项目概述:一个面向开发者的技能图谱与实战仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫GuDaStudio/skills。乍一看名字,你可能会觉得这又是一个普通的“技能清单”或者“学习路线图”项目。但点进去仔细研究后…...