机器学习模型调试学习总结
1.学习内容
模型调试方法:冻结部分层,训练剩余层
实践:在一个预训练的 BERT 模型上冻结部分层,并训练剩余的层
模型调试方法:线性探测(Linear Probe)
实践:在一个预训练的 BERT 模型上冻结全部层,只训练最后一层
模型调试方法:适配模块
实践:在BERT模型中添加适配模块
模型调试方法: 软提示
实践:使用软提示来指导生成对话文本
2.总结
冻结部分层,只训练其他层。这有助于降低训练过程中的显存消耗,并能专注于某些特定层的优化。
以这次的实践项目为例,全程只用到了6g多的内存,完全在可以接受的范围内。
具体的实践部分代码,首先我们加载了预训练的模型,之后我们需要进行冻结某些层的操作,调用model.named_parameters()获取模型中的所有参数(weights)及其名称。这个函数返回一个迭代器,它会遍历模型的所有参数及其名称。
对于BERT模型,它有很多层,每一层都有自己的参数(比如权重和偏差)。想要冻结前n层,也就是不更新这些层的参数。通过遍历所有参数,并且通过检查参数的名称来判断它们属于哪一层,可以实现这个目的。最后将模型移动到可用的计算设备上,通常是 GPU,当然我们目前并没有,所以用的还是cpu。
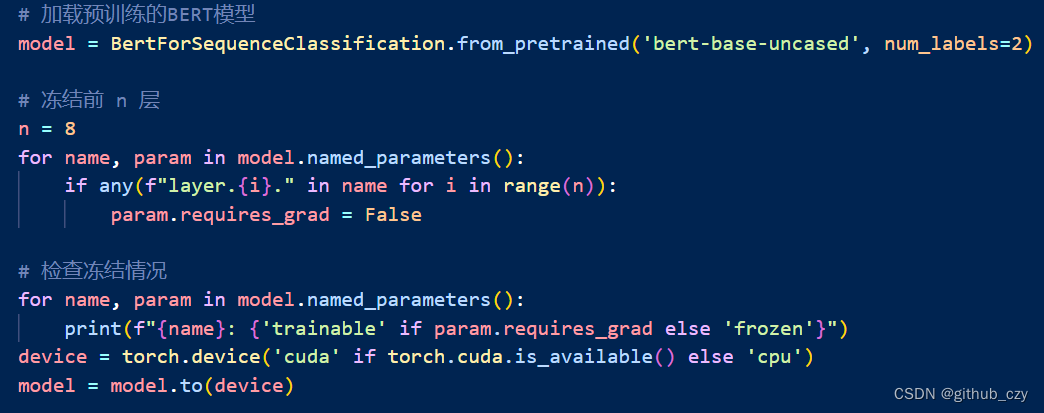
这段代码的作用是在加载预训练的 BERT 模型之后,通过冻结部分参数,只训练模型的后几层,以加速微调过程并提高效果。
下面是模型的其他部分

这段代码是用于设置优化器和计算总步数的。
optimizer = AdamW(model.parameters(), lr=2e-5)
这一行代码创建了一个AdamW优化器对象,用于更新神经网络模型中的参数。在这里,model.parameters() 返回模型中的所有可学习参数,然后将其传递给AdamW优化器。lr=2e-5 指定了学习率(learning rate)为2e-5,这是优化器在更新参数时使用的步长(即每一步更新时参数变化的程度)。这里也可以进行微调。
优化器是一种算法,它根据定义的损失函数和一些超参数(如学习率),来调整网络中每个参数的值,使得损失函数达到最小值,从而让网络的预测结果尽可能接近真实的标签。
AdamW优化器是一种常用的优化器之一。它结合了两个重要的思想:梯度下降和动量。在每一步更新中,AdamW根据当前参数的梯度(即损失函数对参数的变化率)来调整参数的值。同时,它也考虑了之前步骤中参数的移动情况,以便更加高效地更新参数。
学习率是优化器中的一个重要超参数,它决定了每次参数更新的步长。如果学习率设置得太大,可能会导致参数在更新时跳过最优解;而如果学习率设置得太小,收敛速度可能会很慢。

这部分代码主要是设置了学习率调度器(scheduler)和损失函数(loss function)。
scheduler = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0, num_training_steps=total_steps)这行代码创建了一个学习率调度器,采用了线性学习率调度和预热(warm-up)策略。optimizer 是之前创建的优化器,num_warmup_steps=0 表示预热步数为 0,num_training_steps=total_steps 表示总的训练步数。这个调度器会在训练过程中线性地增加学习率,并在一开始的一部分步数进行预热,有助于训练的稳定和收敛。(这里也可以进行微调。)
loss_fn = torch.nn.CrossEntropyLoss().to(device)这行代码创建了一个交叉熵损失函数,用于计算模型预测值和真实标签之间的损失。.to(device) 将损失函数移动到可用的计算设备上。交叉熵损失函数是多分类任务常用的损失函数,适用于我们的文本分类任务。
预热是指在训练初期逐渐增加学习率的过程,有助于训练的稳定和加快收敛速度。
学习率调度器就像是告诉小狗在学习过程中什么时候应该跑得快一点,什么时候应该慢下来。这样可以让它更好地掌握技能,就像你的神奇机器在学习时能够以合适的速度更新它的“知识”。
而预热就像是在小狗开始学习前先稍微热身一下,这样它就能更好地适应学习的环境。在训练开始时给模型一个小小的“预热”,能够让它更快地开始学习。
总的训练步数就像是告诉小狗要学习多久一样。就像告诉小狗学习新技能需要多长时间一样,我们告诉神奇的机器,它需要经过多少次“学习步骤”才能变得更聪明。
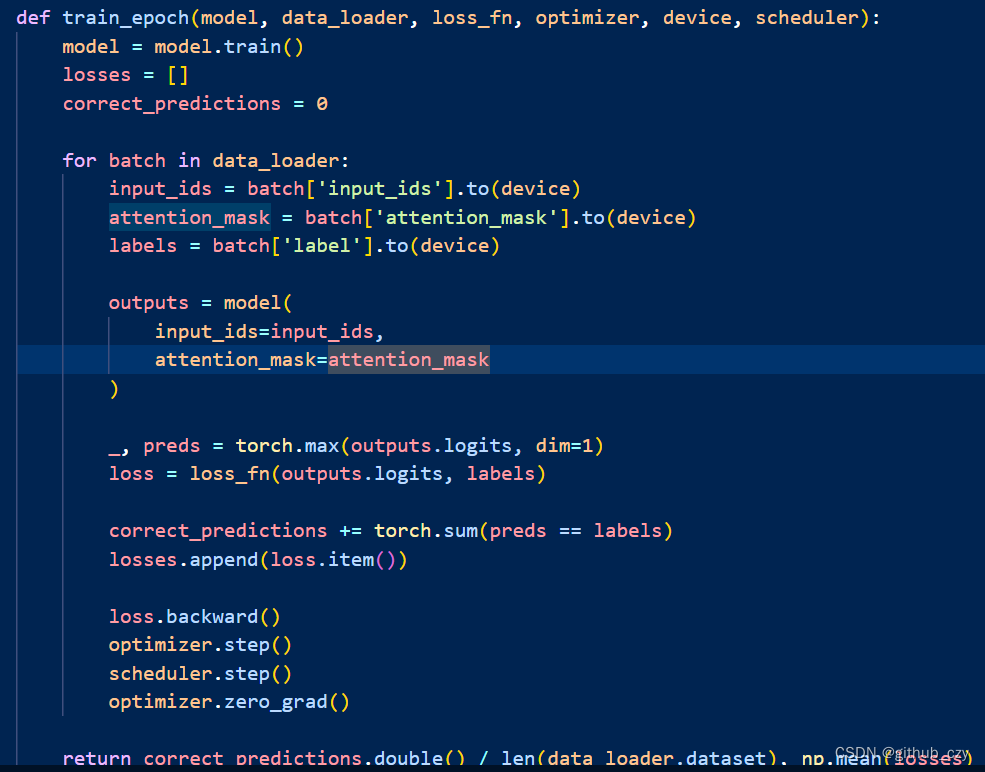
这一部分则是训练模型的代码,model = model.train(): 将模型设置为训练模式。这会启用训练模式下的特定功能,例如启用 Dropout 层。
losses = []: 用于存储每个批次的损失值。
correct_predictions = 0: 记录预测正确的样本数量。
for batch in data_loader:: 遍历数据加载器中的每个批次。
input_ids = batch['input_ids'].to(device): 将输入张量移动到指定的设备(例如 GPU)上。
attention_mask = batch['attention_mask'].to(device): 将注意力掩码张量移动到指定的设备上。
labels = batch['label'].to(device): 将标签张量移动到指定的设备上。
outputs = model(input_ids=input_ids, attention_mask=attention_mask): 使用模型进行前向传播,得到预测结果。
_, preds = torch.max(outputs.logits, dim=1): 根据模型的输出,选择概率最大的类别作为预测结果。
loss = loss_fn(outputs.logits, labels): 计算模型预测结果与真实标签之间的损失值。
correct_predictions += torch.sum(preds == labels): 统计预测正确的样本数量。
losses.append(loss.item()): 将本批次的损失值添加到列表中。
loss.backward(): 反向传播计算梯度。
optimizer.step(): 更新模型参数。
scheduler.step(): 更新学习率。
optimizer.zero_grad(): 清空梯度。
return correct_predictions.double() / len(data_loader.dataset), np.mean(losses): 返回每个样本的平均损失和准确率。损失值的平均值表示整个 epoch 的平均损失,准确率表示模型在整个 epoch 中预测正确的样本比例。
前向传播:就像是告诉模型“看这些数据,试着预测一下”。在前向传播过程中,你将数据输入到模型中,让模型通过它的网络结构进行计算,得到预测结果。
反向传播:当模型做出了预测后,我们需要知道它做得有多好,以及如何更新模型的参数来改进预测结果。这就是反向传播的作用。在反向传播中,我们计算模型预测值与真实标签之间的差距(损失值),然后沿着网络逆向传播这个差距,以便调整每个参数,使得损失值最小化。
optimizer.step():更新模型参数:一旦我们通过反向传播计算出了每个参数的梯度(即参数变化的方向),我们就可以使用优化器来更新模型的参数。优化器根据梯度的方向和设定的学习率来更新参数,使得损失值逐渐减小,模型性能逐渐提高。
scheduler.step():更新学习率:学习率是决定模型参数更新步长的重要因素。在训练过程中,我们可能希望随着训练的进行逐渐降低学习率,以便更加精细地调整参数。调度器的作用就是根据预先设定的调度策略来更新学习率。
optimizer.zero_grad():清空梯度:在每次参数更新之前,我们需要清空之前计算的梯度值,以免梯度累积导致更新不准确。这个步骤就是清空模型参数的梯度,以便进行下一轮的梯度计算和更新。
什么是线性探测?
想象一下,你有一个装满了很多层积木的积木塔。每一层积木都有点不同,有的积木是红色的,有的是蓝色的,还有的上面有不同的图案。这个积木塔就像一个训练好的模型,每一层积木就像这个模型的一层。
为什么要用线性探测?
现在,我们想知道这个积木塔的每一层对我们玩一个特别的游戏有多大的帮助。这个游戏可以是猜动物、颜色,或者其他有趣的事情。我们用一种叫做线性探测的方法来看看哪些层对这个游戏最有帮助。
怎么做线性探测?
保持积木塔不变:我们不动积木塔,只是看它的每一层。
提取每一层的信息:我们从积木塔的每一层拿一点信息出来。
用这些信息玩游戏:我们用每一层的信息来玩游戏,看看我们能不能用这些信息做出正确的猜测。
评估效果:我们看看每一层的信息能不能帮助我们在游戏中表现得更好。
一个小例子
假设我们有一个关于动物的游戏,我们的积木塔可以帮我们识别动物。
保持积木塔不变:积木塔已经建好了,我们不动它。
提取信息:我们从积木塔的第一层拿信息出来,看看它能告诉我们什么。然后从第二层拿信息出来,依此类推。
用信息玩游戏:我们用这些信息来猜图片上的动物是什么,比如一只猫或一只狗。
评估效果:我们看看每一层的信息能不能帮助我们正确地猜出动物是什么。
通过这种方法,我们可以知道积木塔的哪一层最聪明,能帮我们最准确地猜出动物。这样,我们就能了解积木塔的每一层对我们玩游戏的帮助有多大。
所以,线性探测就像我们通过每一层积木的信息来玩游戏,看看哪一层的信息最有用。这帮助我们更好地了解积木塔,也就是我们的模型,知道它的每一层都能做些什么。
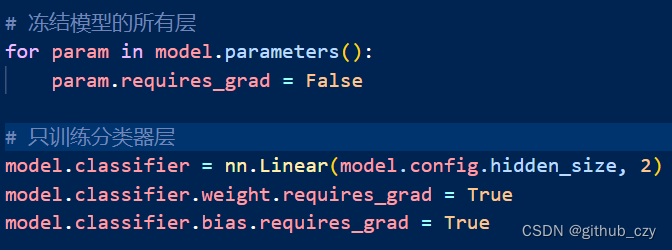
首先是冻结模型的所有层,
for param in model.parameters():
param.requires_grad = False
这部分代码将模型中的所有参数设置为不可训练状态。param.requires_grad = False 表示在反向传播时不会计算这些参数的梯度,因此这些参数在训练过程中保持不变。冻结模型的所有层有助于保持预训练模型学到的知识。由于预训练模型已经在大规模数据集上进行了训练,它已经具备了丰富的语言学特征。冻结这些层可以防止在训练过程中丢失这些有用的特征。
model.classifier = nn.Linear(model.config.hidden_size, 2)
model.classifier.weight.requires_grad = True
model.classifier.bias.requires_grad = True
这部分代码将模型的分类器层重新定义为一个新的线性层,并设置为可训练状态。nn.Linear(model.config.hidden_size, 2) 创建一个线性层,输入大小为 model.config.hidden_size(BERT模型的隐藏层大小),输出大小为2(表示二分类任务)。这个线性层将作为模型的新的分类器层,用于预测输入文本的分类标签。通过设置 model.classifier.weight.requires_grad = True 和 model.classifier.bias.requires_grad = True,确保分类器层的权重和偏置参数在训练过程中是可训练的。仅训练分类器层的策略使得模型能够在保持预训练特征的同时,专注于目标任务的特定特征。
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.classifier.parameters(), lr=1e-3)
nn.CrossEntropyLoss() 是 PyTorch 提供的交叉熵损失函数,通常用于分类任务,特别是多类分类任务。交叉熵损失函数结合了 softmax 激活函数和负对数似然损失,适用于模型的输出是非归一化的对数几率(logits)。在二分类或多分类任务中,交叉熵损失函数会计算预测的概率分布与真实标签分布之间的差异。
假设有三个类别,模型的输出 logits 为 [2.0, 1.0, 0.1],对应的真实标签为 0(即第一个类别),则交叉熵损失函数会先将 logits 通过 softmax 转换为概率分布 [0.71, 0.26, 0.03],然后计算损失值。
optim.AdamW 是 PyTorch 提供的 AdamW 优化器,这是一种基于 Adam 优化器的变体,具有权重衰减(weight decay)正则化的特点,有助于防止过拟合。
model.classifier.parameters() 表示仅对模型的分类器层的参数进行优化。
lr=1e-3 设置优化器的学习率为 0.001。
权重衰减(Weight Decay):
权重衰减是一种正则化技术,通过在每次参数更新时对权重施加 L2 惩罚,从而防止模型过拟合。AdamW 优化器相比于传统的 Adam 优化器,能够更好地控制权重衰减,从而提高模型的泛化能力。
假设分类器层的参数为 [w1, w2, ..., wn],AdamW 优化器会在每次更新这些
参数时,根据损失函数的梯度和权重衰减项调整参数值,以最小化损失函数。
适配模块是什么?
当你在玩积木,拼图或者搭建模型的时候,你可能会发现有些部分不太合适,需要进行调整,这就像在调试模型一样。适配模块就像是一个特殊的积木块,它可以帮助你把不同的部分连接在一起,使它们更好地适应并协同工作。就像在搭积木时一样,调试模型时的适配模块可以帮助我们解决各种问题,确保整个模型能够正常运行。
class Adapter(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(Adapter, self).__init__()
self.down_project = nn.Linear(input_dim, hidden_dim)
self.activation = nn.ReLU()
self.up_project = nn.Linear(hidden_dim, input_dim)
def forward(self, x):
x = self.down_project(x)
x = self.activation(x)
x = self.up_project(x)
return x
这段代码定义了一个名为 Adapter 的类,它继承自 nn.Module,这是 PyTorch 中定义神经网络模型的标准方式。Adapter 有两个主要组件:
下投影层 (down_project): 这是一个线性层 (nn.Linear),它将输入的特征维度从 input_dim 缩减到 hidden_dim。这一步可以看作是将输入特征映射到一个更低维度的空间。
激活函数 (activation): 这里使用的是 ReLU 激活函数 (nn.ReLU),它将线性变换后的特征进行非线性映射,增加模型的表达能力。
上投影层 (up_project): 这是另一个线性层,它将特征从 hidden_dim 恢复到 input_dim 的维度。这一步可以看作是对特征进行重建,将低维特征映射回原始特征空间。
在 forward 方法中,输入 x 首先通过下投影层,然后经过激活函数,最后再通过上投影层。最终输出的特征维度与输入相同,但经过了非线性变换。
这个 Adapter 类的作用是将输入的特征进行降维,然后通过非线性映射,最后再恢复到原始的特征空间。
class BertWithAdapters(nn.Module):
def __init__(self, model_name, adapter_hidden_dim):
super(BertWithAdapters, self).__init__()
self.bert = BertModel.from_pretrained(model_name)
self.adapters = nn.ModuleList([Adapter(self.bert.config.hidden_size, adapter_hidden_dim) for _ in range(self.bert.config.num_hidden_layers)])
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask, output_hidden_states=True)
hidden_states = outputs.hidden_states
for i, adapter in enumerate(self.adapters):
hidden_states[i] = hidden_states[i] + adapter(hidden_states[i])
return hidden_states[-1]
这个函数定义了一个新的神经网络模型 BertWithAdapters,它基于预训练的 BERT 模型,但添加了适配器模块。__init__ 方法:这是类的构造方法,在创建 BertWithAdapters 类的实例时调用。在这个方法中,首先调用了 super().__init__() 来初始化父类的构造方法。然后,通过 BertModel.from_pretrained(model_name) 创建了预训练的 BERT 模型,并将其保存在 self.bert 属性中。接着,使用 nn.ModuleList 创建了一个列表 self.adapters,其中包含了多个适配器模块,其数量等于 BERT 模型的隐藏层数量。
forward 方法:这是模型的前向传播方法,定义了数据从输入到输出的流程。在这个方法中,首先调用了 BERT 模型 (self.bert) 对输入数据进行处理,并将输出保存在 outputs 中。然后,从 outputs 中提取出所有隐藏状态,即 hidden_states。接下来,通过遍历所有隐藏状态并分别应用相应的适配器模块,对隐藏状态进行调整。具体地,对每一层的隐藏状态应用对应的适配器模块,得到调整后的隐藏状态。最后,返回调整后的最后一个隐藏状态,作为整个模型的输出。
这个函数的主要作用是创建一个基于预训练的 BERT 模型的新模型,该新模型在每一层都添加了一个适配器模块,用于对隐藏状态进行调整。
软提示是什么?
在模型调试中,软提示是指向模型提供的一种提示或指导,以帮助模型生成更加准确或符合预期的输出。软提示通常是一种文本形式,向模型提供了一些上下文或指示,以便模型在生成文本、回答问题或执行其他任务时更好地理解用户的意图或期望。
相关文章:
机器学习模型调试学习总结
1.学习内容 模型调试方法:冻结部分层,训练剩余层 实践:在一个预训练的 BERT 模型上冻结部分层,并训练剩余的层 模型调试方法:线性探测(Linear Probe) 实践:在一个预训练的 BERT …...

文明互鉴促发展——2024“国际山地旅游日”主题活动在法国启幕
5月29日,2024“国际山地旅游日”主题活动在法国尼斯市成功举办。中国驻法国使领馆、法国文化旅游部门、地方政府、国际组织、国际山地旅游联盟会员代表、旅游机构、企业、专家、媒体等围绕“文明互鉴的山地旅游”大会主题和“气候变化与山地旅游应对之策”论坛主题展…...

【C++进阶】深入STL之string:掌握高效字符串处理的关键
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:C模板入门 🌹🌹期待您的关注 🌹🌹 ❀STL之string 📒1. STL基本…...
一、初识Qt 之 Hello world
一、初识Qt 之 Hello world 提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 初识Qt 之 Hello world文章目录 一、Qt 简介二、Qt 获取安装三、Qt 初步使用四、Qt 之 Hello world1.新建一个项目 总结 一、Qt 简介 C …...
nginx搭建简单负载均衡demo(springboot)
目录 1 安装nignx 1.1 执行 brew install nginx 命令(如果没安装brew可百度搜索如何安装brew下载工具。类似linux的yum命令工具)。 1.2 安装完成会有如下提示:可以查看nginx的配置文件目录。 1.3 执行 brew services start nginx 命令启动…...
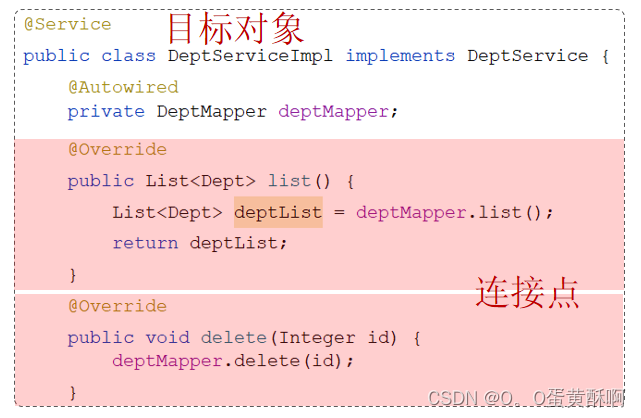
SpringBoot的第二大核心AOP系统梳理
目录 1 事务管理 1.1 事务 1.2 Transactional注解 1.2.1 rollbackFor 1.2.2 propagation 2 AOP 基础 2.1 AOP入门 2.2 AOP核心概念 3. AOP进阶 3.1 通知类型 3.2 通知顺序 3.3 切入点表达式 execution切入点表达式 annotion注解 3.4 连接点 1 事务管理 1.1 事务…...
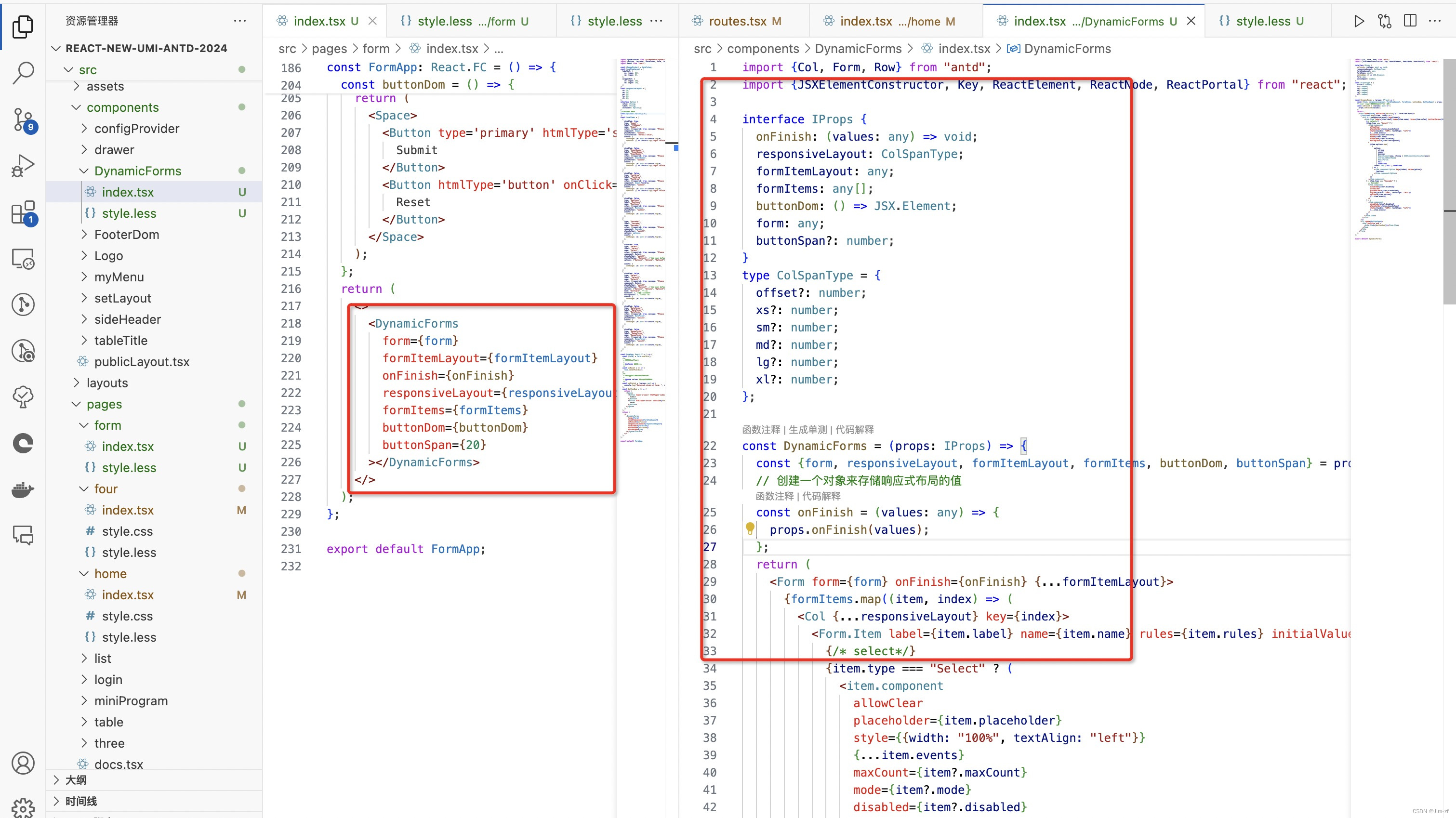
react、vue动态form表单
需求在日常开发中反复写form 是一种低效的开发效率,布局而且还不同这就需要我们对其封装 为了简单明了看懂代码,我这里没有组件,都放在一起,简单抽离相信作为大佬的你,可以自己完成, 一、首先我们做动态f…...
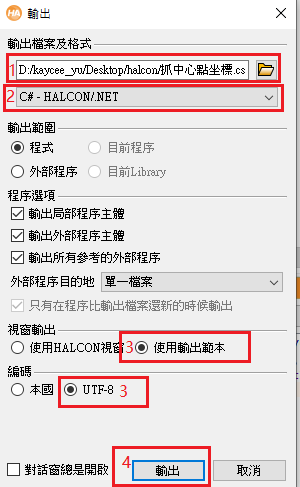
halcon程序如何导出C#文件
1.打开halcon文件; 2.写好需要生成C#文件的算子或函数; 3.找到档案-输出,如下图; 4.点击输出,弹出如下窗口 (1)可以修改导出文件的存储路径 (2)选择C#-HALCON/.NET &…...

RabbitMQ三、springboot整合rabbitmq(消息可靠性、高级特性)
一、springboot整合RabbitMQ(jdk17)(创建两个项目,一个生产者项目,一个消费者项目) 上面使用原生JAVA操作RabbitMQ较为繁琐,很多的代码都是重复书写的,使用springboot可以简化代码的…...
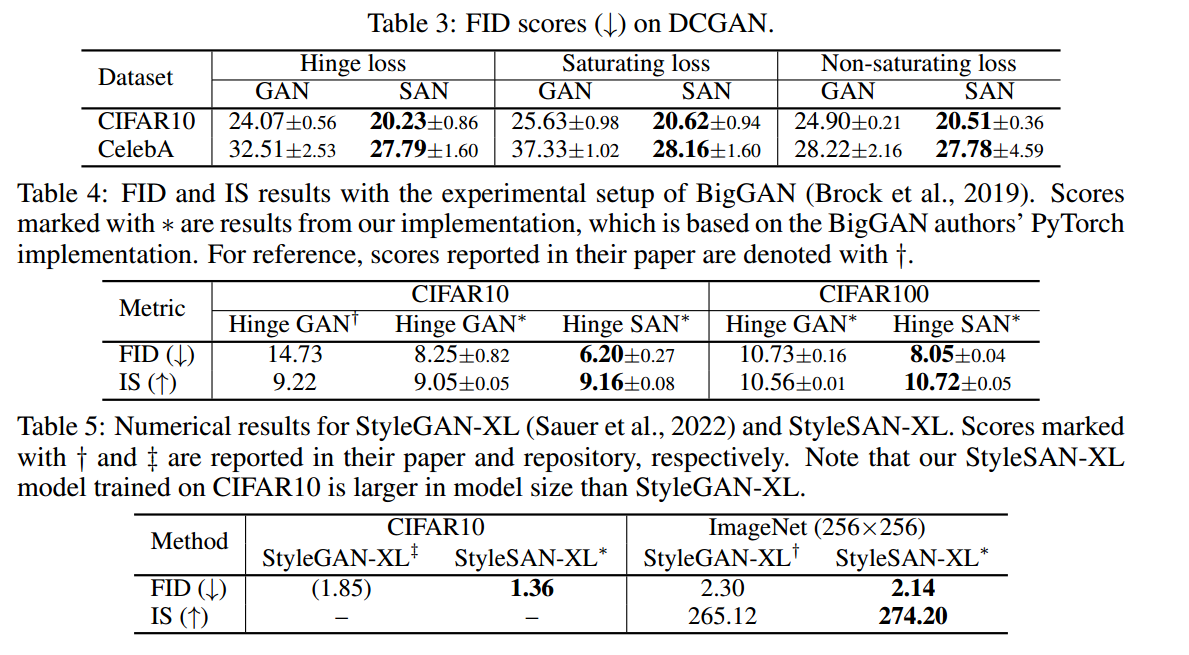
第八十九周周报
学习目标: 论文 学习时间: 2024.05.25-2024.05.31 学习产出: 一、论文 SAN: INDUCING METRIZABILITY OF GAN WITH DISCRIMINATIVE NORMALIZED LINEAR LAYER 将GAN与切片最优输运联系起来,提出满足方向最优性、可分离性和单射…...

Centos升级Openssh版本至openssh-9.3p2
一、启动Telnet服务 为防止升级Openssh失败导致无法连接ssh,所以先安装Telnet服务备用 1.安装telnet-server及telnet服务 yum install -y telnet-server* telnet 2.安装xinetd服务 yum install -y xinetd 3.启动xinetd及telnet并做开机自启动 systemctl enable…...

茉莉香飘,奶茶丝滑——周末悠闲时光的绝佳伴侣
周末的时光总是格外珍贵,忙碌了一周的我们,终于迎来了难得的闲暇。这时,打开喜欢的综艺,窝在舒适的沙发里,再冲泡一杯香飘飘茉莉味奶茶,一边沉浸在剧情的海洋中,一边品味着香浓丝滑的奶茶&#…...
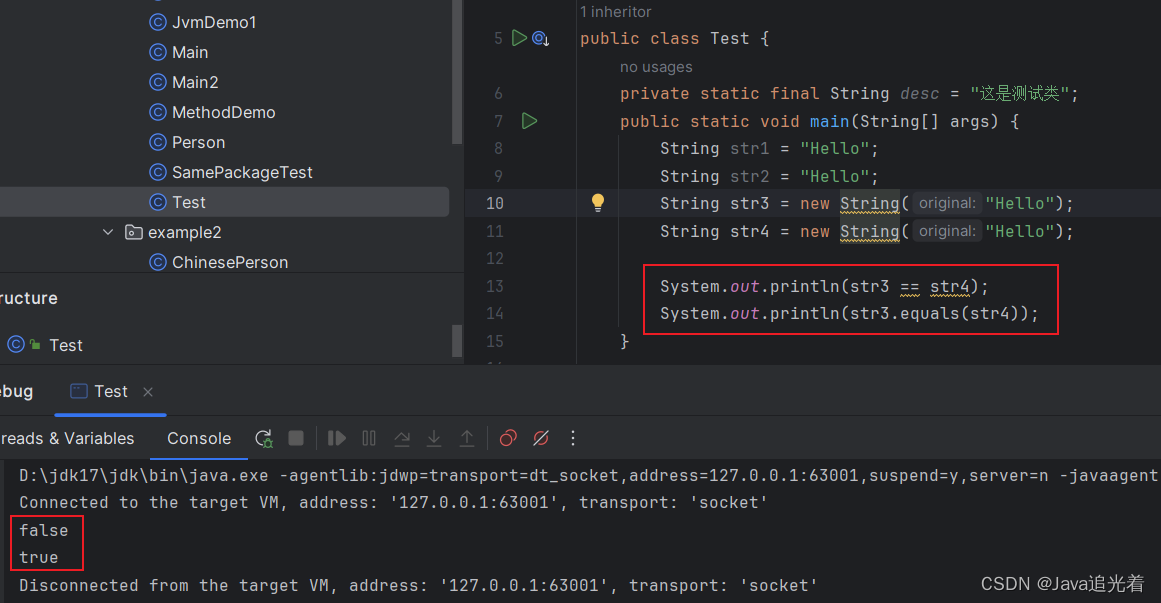
揭秘:Java字符串对象的内存分布原理
先来看看下面寄到关于String的真实面试题,看看你废不废? String str1 "Hello"; String str2 "Hello"; String str3 new String("Hello"); String str4 new String("Hello");System.out.println(str1 str2)…...

Vue.js - 生命周期与工程化开发【0基础向 Vue 基础学习】
文章目录 Vue 的生命周期Vue 生命周期的四个阶段Vue 生命周期函数(钩子函数 工程化开发 & 脚手架 Vue CLI**开发 Vue 的两种方式:**脚手架目录文件介绍项目运行流程组件化开发 & 根组件App.vue 文件(单文件组件)的三个组成…...

Element-UI 快速入门指南
Element-UI 快速入门指南 Element-UI 是一套基于 Vue.js 的桌面端组件库,由饿了么前端团队开发和维护。它提供了丰富的 UI 组件,帮助开发者快速构建美观、响应式的用户界面。本篇文章将详细介绍 Element-UI 的安装、配置和常用组件的使用方法,帮助你快速上手并应用于实际项…...
)
2024华为OD机试真题-整型数组按个位值排序-C++(C卷D卷)
题目描述 给定一个非空数组(列表),其元素数据类型为整型,请按照数组元素十进制最低位从小到大进行排序, 十进制最低位相同的元素,相对位置保持不变。 当数组元素为负值时,十进制最低位等同于去除符号位后对应十进制值最低位。 输入描述 给定一个非空数组,其元素数据类型…...

善听提醒遵循易经原则。世界大同只此一路。
如果说前路是一个大深坑,那必然是你之前做的事情做的不太好,当坏的时候,坏的结果来的时候,是因为你之前的行为,你也就不会再纠结了,会如何走出这个困境,是好的来了,不骄不躁…...

CrossOver有些软件安装不了 用CrossOver安装软件后如何运行
CrossOver为用户提供了三种下载软件的方式分别是:搜索、查找分类、导入。如果【搜索】和【查找分类】提供的安装资源不能成功安装软件,那么我们可以通过多种渠道下载安装包,并将安装包以导入的方式进行安装。这里我们以QQ游戏为例,…...

在vue中如何使用leaflet图层展示地图
在vue中如何使用leaflet <template><div id"map" class"map"></div> </template><script> export default {data () {return {};},mounted(){this.initMaps()},methods: {initMaps () {const map L.map(map, {zoomControl…...

mybatisplus 字段存的是json 在查询的时候怎么映射成对象
数据库交互对象 TableName(value "表名", autoResultMap true)TableField(typeHandler JacksonTypeHandler.class, value "user_info")private User user;autoResultMap 是一个 MyBatis-Plus 中的注解属性,用于控制是否自动生成结果映射。…...

微软UFO项目:基于视觉大模型的GUI自动化智能体实战解析
1. 项目概述:当“全能”AI助手遇见复杂任务编排 最近在AI应用开发圈里,一个来自微软研究院的项目“UFO”引起了我的注意。这名字听起来挺科幻,全称是“UI-Focused Agent”,直译过来是“专注于用户界面的智能体”。但别被这个直白的…...

避开这3个坑,你的HMC7044时钟输出才稳定:从VCO选择到奇数分频实战
HMC7044时钟系统设计避坑指南:从VCO选型到分频配置的工程实践 在高速数字系统设计中,时钟信号的稳定性往往决定着整个系统的性能上限。作为业界广泛使用的高性能时钟发生器,HMC7044凭借其出色的抖动性能和灵活的配置选项,成为众多…...

基于Hive的淘宝用户购物行为数据分析及可视化
第1章 绪论1.1 课题背景互联网技术迅猛发展,电子商务平台聚集了庞大的用户数据,其中包含着大量的用户行为信息以及消费习惯。淘宝是中国最大的电子商务平台之一,其用户购物行为数据具有很高的研究价值。在大数据的背景下,怎样对数…...

容器化应用分发平台seait:简化部署流程,实现一键运行
1. 项目概述:一个面向开发者的容器化应用分发平台最近在折腾个人项目部署和团队协作时,我一直在思考一个问题:如何能像分发一个可执行文件一样,轻松地分享和运行一个完整的、包含所有依赖的应用程序?尤其是在跨平台、跨…...

基于CircuitPython与BLE构建多探头无线温度监测系统
1. 项目概述:一个无线温度监控的“瑞士军刀” 如果你和我一样,喜欢在周末慢烤一块牛排,或者沉迷于培养天然酵母做面包,那你一定理解同时盯着好几个温度计的烦恼。厨房里烟雾缭绕,烤箱里正烤着东西,发酵箱里…...
与步进(step)函数的生成逻辑)
从Simulink的Vector信号到C代码数组:手把手拆解初始化(initialize)与步进(step)函数的生成逻辑
从Simulink的Vector信号到C代码数组:手把手拆解初始化与步进函数的生成逻辑 在嵌入式系统开发中,Simulink模型到C代码的转换过程往往被视为一个"黑箱"——工程师们习惯性地点击生成按钮,然后接受输出的代码文件。然而,当…...

5个颠覆性文本处理技巧:让notepad--成为你的跨平台效率倍增器
5个颠覆性文本处理技巧:让notepad--成为你的跨平台效率倍增器 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

扣图操作方法完全指南:2026年最实用的AI一键抠图工具推荐
说起扣图,我相信很多人都有过这样的经历——花半天时间用PS的钢笔工具精心描绘边界,最后还是差强人意。或者为了给证件照换个背景,反复调整参数却效果一般。今天我就来分享一下2026年最实用的扣图操作方法,以及那些真正能救命的工…...

车载网络测试演进:从CAN总线到TSN与SOA的实战解析
1. 项目概述:一场关于“神经”与“体检”的进化史几年前,我和几个同行在路边摊就着麻小和扎啤,聊起车载以太网测试,那时它还是个新鲜玩意儿,大家讨论的焦点更多是“要不要做”和“怎么做”。几年过去,再回头…...
)
告别PX4的玄学Bug:手把手教你用Mission Planner给ArduPilot飞控做全套硬件校准(附电调校准避坑指南)
告别PX4的玄学Bug:手把手教你用Mission Planner给ArduPilot飞控做全套硬件校准(附电调校准避坑指南) 作为一名长期与无人机打交道的开发者,我深知飞控系统稳定性对飞行安全的重要性。在尝试过PX4和ArduPilot两大主流固件后&#x…...