lucene 9.10向量检索基本用法
Lucene 9.10 中的 KnnFloatVectorQuery 是用来执行最近邻(k-Nearest Neighbors,kNN)搜索的查询类,它可以在一个字段中搜索与目标向量最相似的k个向量。以下是 KnnFloatVectorQuery 的基本用法和代码示例。
1. 索引向量字段
首先,你需要一个包含向量字段的索引。你可以使用 KnnFloatVectorField 来添加向量到文档中。
import org.apache.lucene.document.Document;
import org.apache.lucene.document.KnnFloatVectorField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;import java.io.IOException;
import java.util.ArrayList;
import java.util.List;public class VectorIndexing {public static void main(String[] args) throws IOException {List<Document> docs = new ArrayList<>();String fieldName = "knnFloatField";IndexWriter writer = new IndexWriter(FSDirectory.open(/* ... */), new IndexWriterConfig());for (float[] vector : /* ... */) {Document doc = new Document();doc.add(new KnnFloatVectorField(fieldName, vector, VectorSimilarityFunction.EUCLIDEAN));docs.add(doc);// ... 其他字段的添加 ...writer.addDocument(doc);}writer.close();}
}
2. 执行 kNN 查询
接下来,使用 KnnFloatVectorQuery 来执行查询。你需要指定查询的字段、目标向量以及想要检索的最近邻个数 k。
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.KnnFloatVectorQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.DirectoryReader;public class VectorSearch {public static void main(String[] args) throws IOException {try (DirectoryReader reader = DirectoryReader.open(/* ... */)) {IndexSearcher searcher = new IndexSearcher(reader);float[] targetVector = { /* ... */ }; // 目标向量int k = 3; // 想要检索的最近邻个数KnnFloatVectorQuery knnQuery = new KnnFloatVectorQuery("knnFloatField", targetVector, k);TopDocs topDocs = searcher.search(knnQuery, 10);for (ScoreDoc scoreDoc : topDocs.scoreDocs) {// 处理检索到的文档}}}
}
3. 结果处理
TopDocs 对象包含了按分数排序的文档列表,其中分数是基于向量相似度计算的。你可以根据需要遍历这些文档。
请注意,KnnFloatVectorQuery 是基于 KnnVectorsReader 的,它使用特定的算法(如 HNSW)来执行高效的向量最近邻搜索。查询时,相似度的计算由字段定义的 VectorSimilarityFunction 决定,例如欧几里得距离(Euclidean distance)。
在实际应用中,你可能还需要考虑如何存储和检索其他相关的文档信息,以及如何处理查询结果以满足你的业务需求。此外,向量字段的索引和搜索可能需要特定的索引配置和优化,以确保性能和准确性。
以上示例代码提供了在 Lucene 9.10 中使用 KnnFloatVectorQuery 进行向量检索的基本框架。具体的实现细节(如索引的创建、字段的配置等)需要根据你的具体应用场景进行调整。
VectorSimilarityFunction 下枚举值解释:
VectorSimilarityFunction 是 Lucene 中用于定义向量相似度计算方法的枚举类型。它提供了几种不同的函数,用于在执行向量搜索时比较向量的相似度。以下是 VectorSimilarityFunction 的一些枚举值及其解释:
-
EUCLIDEAN: 使用欧几里得距离来衡量向量之间的相似度。这是一种常见的距离度量,用于计算两点之间的直线距离。在 Lucene 中,它用于计算查询向量与索引中向量之间的距离。
-
COSINE: 使用余弦相似度来衡量向量之间的相似度。余弦相似度测量的是两个向量在方向上的相似性,而不是大小。它通过计算两个向量的点积与它们模的乘积的比值来得到。
-
DOT_PRODUCT: 点积相似度,与余弦相似度类似,它计算两个向量的点积,但不需要归一化向量。点积相似度对向量的长度敏感,因此在比较之前通常需要将向量标准化到单位长度。
-
MANHATTAN: 使用曼哈顿距离(也称为城市街区距离)来衡量向量之间的相似度。这种距离度量是各个维度上差的绝对值之和。
-
HAMMING: 汉明相似度,通常用于二进制向量,它计算两个向量中不同位置的个数。
-
JACCARD: 杰卡德相似度,用于衡量集合之间的相似度,它定义为两个集合交集大小与并集大小之比。
-
CHEBYCHEV: 切比雪夫距离,它是向量中对应元素差的绝对值的最大值。
-
CANBERRA: 坎培拉距离,是一种加权的曼哈顿距离,它考虑了两个元素值的差的绝对值与它们值的和的比率。
-
BRAY_CURTIS: 布雷-柯蒂斯相似度,它是基于两个向量交集和并集的大小,类似于杰卡德相似度,但权重不同。
-
ROGERSTANIMOTO: 罗杰斯-谭马托相似度,它是一种基于向量元素差的绝对值的相似度度量。
-
RUSSELLRAO: 罗素-劳相似度,它是基于两个集合交集大小与各自独有元素大小之和的度量。
-
SOKALSNEATH: 索卡尔-斯内思相似度,它结合了汉明距离和杰卡德相似度的特点。
这些相似度函数可以用于不同的场景,选择哪一种取决于你的具体需求以及数据的特性。例如,如果你关心的是向量的方向而不是大小,那么余弦相似度可能是一个好选择;如果你关心的是向量间的实际距离,欧几里得距离可能更合适。
相关文章:

lucene 9.10向量检索基本用法
Lucene 9.10 中的 KnnFloatVectorQuery 是用来执行最近邻(k-Nearest Neighbors,kNN)搜索的查询类,它可以在一个字段中搜索与目标向量最相似的k个向量。以下是 KnnFloatVectorQuery 的基本用法和代码示例。 1. 索引向量字段 首先…...

【2023百度之星初赛】跑步,夏日漫步,糖果促销,第五维度,公园,新材料,星际航行,蛋糕划分
目录 题目:跑步 思路: 题目:夏日漫步 思路: 题目:糖果促销 思路: 题目:第五维度 思路: 题目:公园 思路: 新材料 思路: 星际航行 思路…...
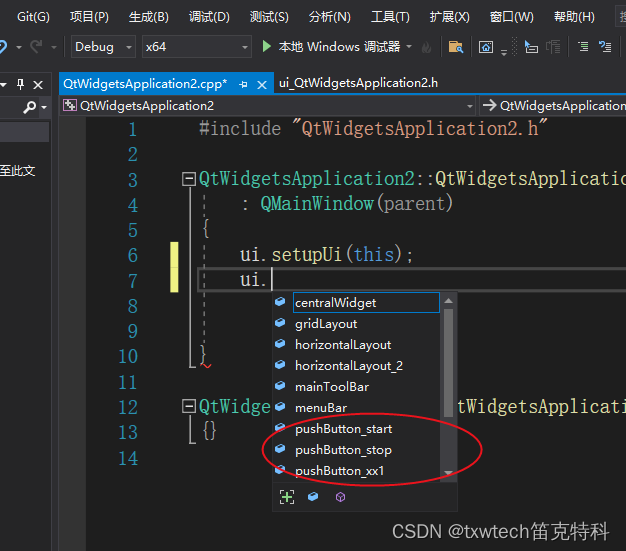
vs2019 QT UI 添加新成员或者控件代码不提示问题解决方法
右键点击头文件,添加ui的头文件 添加现有项 找到uic目录的头文件 打开ui,QtWidgetsApplication2.ui,进行测试 修改一个名字: 重点: 设置一个布局: 点击生成解决方案: 以后每次添加控件后,记得点击保存 这样…...

【面试八股总结】MySQL事务:事务特性、事务并行、事务的隔离级别
参考资料:小林coding 一、事务的特性ACID 原子性(Atomicity) 一个事务是一个不可分割的工作单位,事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。原子性是通过 undo …...

STL用法总结
文章目录 vector构造常用函数遍历适用情形注意事项使用迭代器删除可能会出现的错误 Set & MultiSet(不能用sort,会自动排序)构造常用函数删除,查找遍历 unordered_set(不排序集合),unordered_multiset Map & M…...
他人项目二次开发——慎接
接了一个朋友的项目——开发及运营迭代差不多2年多了,整体样子移动端和PC都能正常使用,但后期的扩展性及新功能添加出现瓶颈。 因此给了一部分钱,让我接手来开发——重构架构。 背景说明 朋友公司的技术人员是我帮忙招聘的,相关技…...

k8s之PV、PVC
文章目录 k8s之PV、PVC一、存储卷1、存储卷定义2、存储卷的作用2.1 数据持久化2.2 数据共享2.3 解耦2.4 灵活性 3、存储卷的分类3.1 emptyDir存储卷3.1.1 定义3.1.2 特点3.1.3 用途3.1.4 示例 3.2 hostPath存储卷3.2.1 定义3.2.2 特点3.2.3 用途3.2.4 示例 3.3 NFS存储卷3.3.1 …...
)
新人学习笔记之(JavaScript作用域)
一、作用域 1.通常来说,一段程序代码中所用的名字并不总是有效和可用的,而限定这个名字的可用性的代码范围就是这个名字的作用域。作用域的使用提高了程序逻辑的局部性,增强了程序的可靠性,减少了名字冲突 二、变量的作用域 1.变…...

图论第一天
在单位摸鱼,地铁上看了个开始,图论开了个头,后面也希望能往这个方向上转,努努力吧。 一周没做题啦,后面坚持继续做题+二刷,接着记录每一天!!!加油࿰…...

革新风暴来袭:报事报修系统小程序如何重塑报事报修体验?
随着数字化、智能化的发展,已经应用在我们日常生活和工作的方方面面。那么,你还在为物业报修而头疼吗?想象一下,家里的水管突然爆裂,你急忙联系物业,时常面临物业电话忙音、接听后才进行登记繁琐的报修单、…...

linux各个日志的含义 以及使用方法
在Linux系统上,系统日志文件通常存储在/var/log/目录下。可以通过查看这些日志文件来了解系统的操作记录、错误信息和其他相关信息。以下是一些常见的系统日志文件以及它们包含的信息: /var/log/messages:这是一个常见的系统日志文件…...

详解 Spark 核心编程之 RDD 持久化
一、问题引出 /** 案例:对同一份数据文件分别做 WordCount 聚合操作和 Word 分组操作 期望:针对数据文件只进行一次分词、转换操作得到 RDD 对象,然后再对该对象分别进行聚合和分组,实现数据重用 */ object TestRDDPersist {def …...
创新融合,5G+工业操作系统引领未来工厂
为加速企业完成生产制造自动化和经营管理自动化,从而走向未来工厂,蓝卓不断探索supOS工业操作系统与前沿技术的的创新融合,而5G技术为工业操作系统提供了更多元化的赋能手段和想象空间。目前,supOS围绕生产、安全、质检、监控等领…...
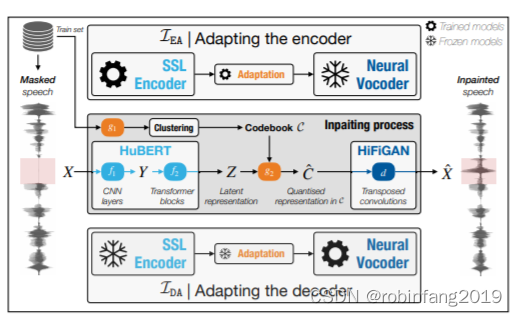
自监督表示学习和神经音频合成实现语音修复
关键词:语音修复、自监督模型、语音合成、语音增强、神经声码器 语音和/或音频修复的目标是增强局部受损的语音和/或音频信号。早期的工作基于信号处理技术,例如线性预测编码、正弦波建模或图模型。最近,语音/音频修复开始使用深度神经网络&a…...
【论文复现|智能算法改进】融合黑寡妇思想的蜣螂优化算法
目录 1.算法原理2.改进点3.结果展示4.参考文献5.代码获取 1.算法原理 【智能算法】蜣螂优化算法(DBO)原理及实现 2.改进点 ICMIC混沌映射 z n 1 sin ( α z n ) , α ∈ ( 0 , ∞ ) (1) z_{n1}\sin(\frac{\alpha}{z_n}),\alpha\in(0,\infty)\ta…...
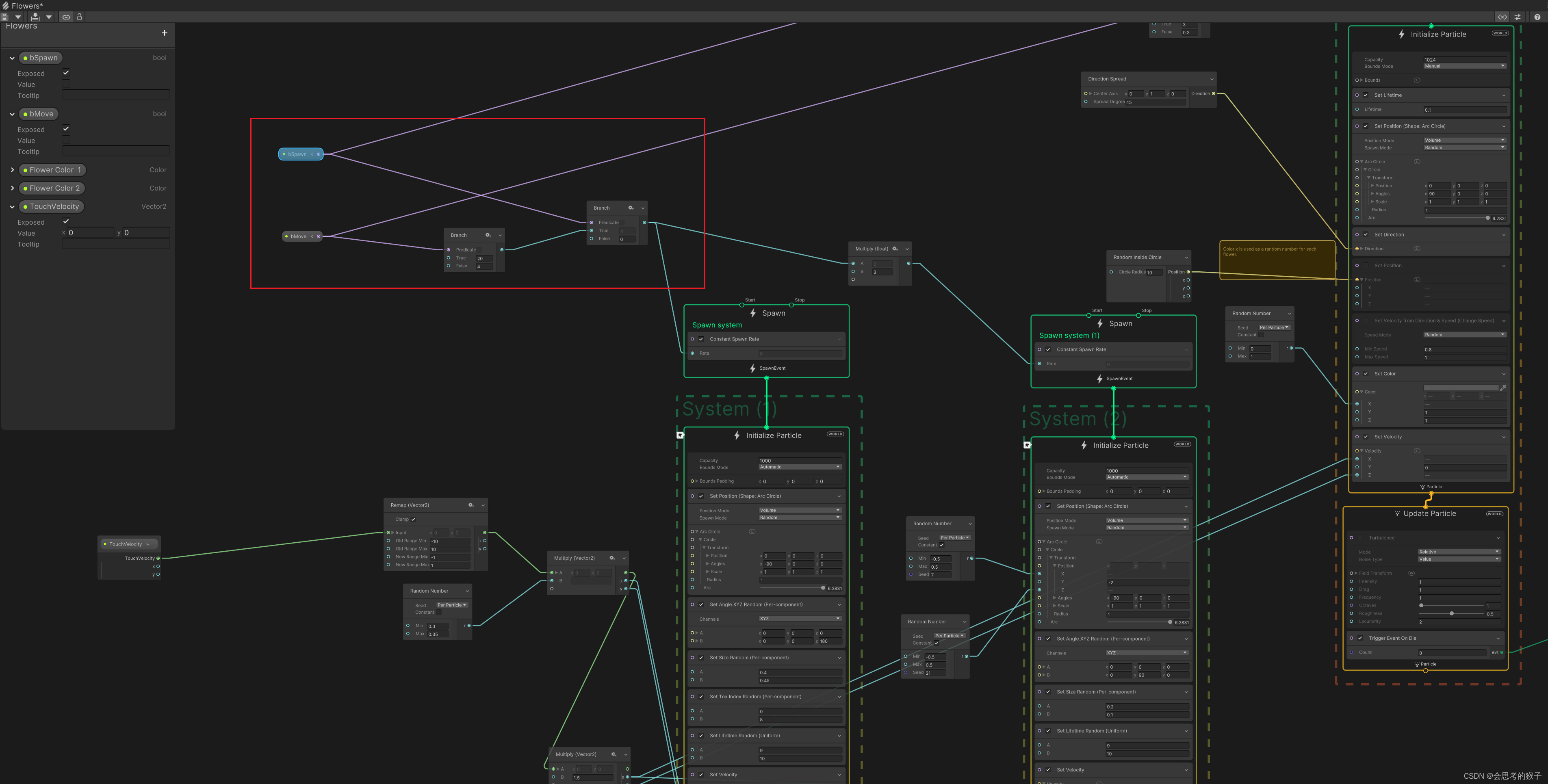
Unity + 雷达 粒子互动(待更新)
效果预览: 花海(带移动方向) VFX 实例 脚本示例 使用TouchScript,计算玩家是否移动,且计算移动方向 using System.Collections; using System.Collections.Generic; using TouchScript; using TouchScript.Pointers; using UnityEngine; using UnityEngine.VFX;public …...

英语翻译程序,可以对用户自己建立的词汇表进行增删查改
⑴ 自行建立一个包含若干英文单词的词汇表文件,系统初始化时导入内存,用于进行句子翻译。 ⑵ 用户可以输入单词或者句子,在屏幕上显示对应翻译结果。 ⑶ 用户可对词汇表进行添加和删除,并能将更新的词汇表存储到文件中。 #defi…...

Django ORM魔法:用Python代码召唤数据库之灵!
探索Django ORM的神奇世界,学习如何用Python代码代替复杂的SQL语句,召唤数据库之灵,让数据管理变得轻松又有趣。从基础概念到高级技巧,阿佑带你一步步成为Django ORM的魔法师,让你的应用开发速度飞起来! 文…...

JetBrains Mono字体下载及安装
百度云字体下载 提取码:zida 1.mac 安装 选择文件夹中的所有字体文件,然后双击它们。点击“安装字体”按钮。 2.windows 安装 选择文件夹中的字体文件,右键单击其中任何一个,然后从菜单中选择“安装”。 3.linux 安装 将字体…...

【OS】AUTOSAR OS系统调用产生Trap的过程详解
目录 前言 正文 1.Os_Hal_Trap使用示例 2. Os_Hal_Trap的定义 3. syscall详解详解...

3小时从零掌握yuzu:在PC上畅玩任天堂Switch游戏的完整指南
3小时从零掌握yuzu:在PC上畅玩任天堂Switch游戏的完整指南 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想在Windows、Linux或Android设备上免费体验任天堂Switch游戏吗?yuzu模拟器正是你…...

3大核心功能深度解析:茉莉花插件如何彻底解决中文文献管理难题
3大核心功能深度解析:茉莉花插件如何彻底解决中文文献管理难题 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 您是否…...
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频
Pixelle-Video完整指南:如何用AI在3分钟内创建专业短视频 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video 在当今内容爆炸的时…...
)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南)
从原理到实战:拆解LCR表如何实现0.1%精度的电容测量(附寄生效应消除指南) 在电子工程领域,精确测量电容值是一项基础却极具挑战性的任务。无论是研发高频电路的设计师,还是调试精密仪表的工程师,亦或是研究…...

2026年同一机器两服务偶发`ECONNRESET`错误:实验室复现、场景分析与后续解决思路
突发!偶发 ECONNRESET 错误背后:实验室复现、场景分析与后续解决思路2026年5月5日,同一台机器上运行的两个服务出现问题,发起连接的服务读取数据时偶发 ECONNRESET 错误,且日志无其他错误信息、无崩溃情况。下面我们来…...

中小团队如何利用Taotoken统一管理多个AI模型的API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小团队如何利用Taotoken统一管理多个AI模型的API调用 对于需要协调使用多个大模型的中小开发团队而言,一个常见的工程…...

从混乱到掌控:FastbootEnhance如何重塑安卓设备管理体验
从混乱到掌控:FastbootEnhance如何重塑安卓设备管理体验 【免费下载链接】FastbootEnhance A user-friendly Fastboot ToolBox & Payload Dumper for Windows 项目地址: https://gitcode.com/gh_mirrors/fa/FastbootEnhance 你是否曾面对黑底白字的Fastb…...
)
从原理到批量利用:深入剖析Apache Superset默认密钥漏洞(CVE-2023-27524)
1. Apache Superset安全漏洞背景 Apache Superset作为一款流行的开源数据可视化工具,在企业数据分析领域有着广泛应用。但正是这样一个看似无害的工具,却因为开发者的一个常见疏忽——使用默认密钥,导致了严重的身份验证绕过漏洞。这个编号为…...

终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程
终极指南:10分钟掌握SPT-AKI存档编辑器完整使用教程 【免费下载链接】SPT-AKI-Profile-Editor Программа для редактирования профиля игрока на сервере SPT-AKI 项目地址: https://gitcode.com/gh_mirrors/sp/…...

Kubernetes部署Valheim游戏服务器:云原生架构实践指南
1. 项目概述:当维京英灵殿遇上Kubernetes如果你和我一样,既沉迷于《英灵神殿》(Valheim)里那种与三五好友一起伐木、采矿、建造长屋,然后被巨魔追得满地图跑的原始乐趣,又恰好是一名整天和容器、编排系统打…...