多线程和多进程的快速入门
多线程和多进程的快速入门
学习自:莫烦Python www.mofanpy.com
Threading - 多线程运算python程序
多线程的简单理解:把数据分成很多段,将每一段数据放入一个线程,将所有的线程同时开始,大大的节省了运算时间。相当于:请一个人来工作一件事和请很多人来工作一件事
Threading 可以分配python分批量在同一时间做事情,但是Threading只能是在一个py脚本中
添加一个线程的案例
import threading#def main():
# print(threading.active_count()) # 查看现在激活线程的数量
# print(threading.enumerate()) # 查看当前的threading都是什么
# print(threading.current_thread()) # 查看我运行这个函数程序的时候 对应的threading是什么def thread_job():print('This is a thread of %s' % threading.current_thread()) # 查看我运行这个函数程序的时候 对应的threading是什么def main():thread = threading.Thread(target=thread_job,) # 添加线程 这个线程做什么由target指定thread.start() # 添加一个线程后,要启动线程,才能让这个线程开始工作if __name__ == '__main__':main()
程序运行的结果为:
This is a thread of <Thread(Thread-1, started 6300)>
threading中的join的功能
由于多线程是同石进行运行的线程任务,如果某些时刻你想等待所有的线程都运行完,然后开始某些操作,这个时候需要在这个操作前对每个线程使用join操作
join操作是等待threading线程运行完
import threading
import time
def thread_job():print('T1 start\n')for i in range(10): time.sleep(0.1) # 睡一秒 print('T1 finish\n')def T2_job():print('T2 start\n')print('T2 finish\n')def main():added_thread = threading.Thread(target=thread_job, name='T1') # name为给线程命名thread2 = threading.Thread(target=T2_job, name='T2')added_thread.start()thread2.start()thread2.join()added_thread.join()print('all done\n')if __name__ == '__main__':main()
不加join的结果如下:
T1 startT2 start
all doneT2 finishT1 finish
加join的结果如下:
T1 startT2 startT2 finishT1 finishall done
多线程搭配Queue功能
多线程无返回值,所以要把运算出来的结果放在一个长的队列中,对每一个线程的队列到主线程中拿出来,以便做继续的运算。
import threading
import time
from queue import Queuedef job(l,q):# 对每一个列表中的值做平方运算for i in range(len(l)):l[i] = l[i]**2q.put(l)def multithreading():q = Queue() # 定义队列threads = [] # 用来存储所有的线程data = [[1,2,3],[3,4,5],[4,4,4],[5,5,5]]for i in range(4): # 定义四个线程 计算大列表中的四个小列表t = threading.Thread(target=job, args=(data[i], q)) # args用来给线程 传递参数t.start() # 启动线程threads.append(t) # 将每个小列表的计算线程 存储到线程列表中for thread in threads: thread.join() # 等到所有的线程运行完 再继续操作results = []for _ in range(4): results.append(q.get()) # 将每个线程运算的结果 保存print(results)if __name__ == '__main__':multithreading()
该程序的结果如下:
[[1, 4, 9], [9, 16, 25], [16, 16, 16], [25, 25, 25]]
多线程的效率分析
多线程的全局控制并不是把任务平均的分配个每一个线程 ,python只能让一个线程在某一时刻运算一个东西,然后不停的切换线程,让你误以为这些线程是在相同时刻在运算。 (学过操作系统应该会很容易理解多线程的并发运算)
下面实力代码中:
normal方法:对四倍的l列表执行累加运算
multithreading多线程方法:将四倍的l列表分为四份,用四个多线程同时处理
import threading
from queue import Queue
import copy
import timedef job(l, q):res = sum(l)q.put(res)def multithreading(l):q = Queue()threads = []for i in range(4):t = threading.Thread(target=job, args=(copy.copy(l), q), name='T%i' % i)t.start()threads.append(t)[t.join() for t in threads]total = 0for _ in range(4):total += q.get()print(total)def normal(l):total = sum(l)print(total)if __name__ == '__main__':l = list(range(1000000))s_t = time.time()normal(l*4)print('normal: ',time.time()-s_t)s_t = time.time()multithreading(l)print('multithreading: ', time.time()-s_t)
程序的执行结果:
1999998000000
normal: 0.08538269996643066
1999998000000
multithreading: 0.08719158172607422
用了多线程比未用多线程的耗时反而多了
多线程与lock锁
锁的用法:当第一个线程处理完这一批数据得到一个初步的结果,然后再把这个结果拿去给第二个线程处理,这个时候就需要锁住第一个线程,等他处理完,再开始第二个线程
在要进行上锁的程序的前后设置锁
import threadingdef job1():global A, locklock.acquire() # 在要进行上锁的程序前 设置锁for i in range(10): # 对A进行10次累加1A += 1print('job1', A)lock.release() # 在要进行上锁的程序后 设置锁def job2():global A, locklock.acquire()for i in range(10): # 对A进行10次累加10A += 10print('job2', A)lock.release()if __name__ == '__main__':lock = threading.Lock() # 定义锁A = 0 # 定义一个全局变量 模拟共享内存t1 = threading.Thread(target=job1)t2 = threading.Thread(target=job2)t1.start()t2.start()t1.join()t2.join()
不加锁的程序结果: 两个线程同时运行,结果上为交替对A进行操作
job1 1
job1 2
job1 13
job2 12
job1 14
job2 24
job1 25
job2 35
job1 36
job2 46
job1 47
job2 57
job1 58
job2 68
job1 69
job2 79
job1 80
job2 90
job2 100
job2 110
加锁的程序结果: job1先上锁 待程序运行完后 解锁。此时job2再上锁 待程序运行完后 解锁
job1 1
job1 2
job1 3
job1 4
job1 5
job1 6
job1 7
job1 8
job1 9
job1 10
job2 20
job2 30
job2 40
job2 50
job2 60
job2 70
job2 80
job2 90
job2 100
job2 110
Multiprocessing - 多进程运算python程序
运用多核CPU处理器CPU运算python程序,一般只会用一个核来处理程序,但是现代计算器的处理器一般都是多核,如果不用白白的浪费,可以将其运用起来加速程序的处理。
多线程实际上还是同一个时间处理一个线程(并发轮转调度),而多核完全避免了这种情况,它会把任务平均分配给每一个核,每一个核都有单独的运算空间和运算能力,多核从一定程度上避免了多线程劣势。
创建进程
import multiprocessing as mpdef job(q):print("进程创建", q)if __name__ == '__main__':p1 = mp.Process(target=job, args=(q,))p1.start()
进程与Queue输出
将每一个核运算出来的结果放入到队列Queue中,等到所有的核运算完成后,再将结果从队列中取出,以便后续操作
import multiprocessing as mpdef job(q):res = 0for i in range(1000):res += i+i**2+i**3q.put(res) # 将运算后的值操作放入到队列if __name__ == '__main__':q = mp.Queue() # 定义队列p1 = mp.Process(target=job, args=(q,)) # 注意args 即使只有一个参数 也要写成(q,) 不然会报错 p2 = mp.Process(target=job, args=(q,))p1.start()p2.start()p1.join()p2.join()res1 = q.get() # 从队列中获取值res2 = q.get()print(res1+res2)
运行结果为:499667166000
进程池
进程池就是把所有要运行的东西放到一个池子里,python自己解决如何分配这些进程,如何分配运行出来的结果。
import multiprocessing as mpdef job(x): # 平方操作return x*xdef multicore():pool = mp.Pool(processes=2) # 默认的是你所有的核心, processes是指定想用的核的数量res = pool.map(job, range(10)) # map 将range(10) 交给job,并将结果返回print(res)res = pool.apply_async(job, (2,)) # 只传入一个值给job 如果输入的是(2,3,4,5)会报错,因为只能传入一个值print(res.get()) # 使用get获取multi_res =[pool.apply_async(job, (i,)) for i in range(10)] # 利用迭代器 获取对多个值操作的结果print([res.get() for res in multi_res]) # 利用列表迭代获取if __name__ == '__main__':multicore()
程序运行的结果:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
4
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
多进程使用shared memory共享内存
为什么使用共享内存,不用全局变量?
因为多进程中传入全局变量给每个cpu,多进程对全局变量进行操作后传给其它进程是行不通的
import multiprocessing as mpvalue = mp.Value('i', 1) # i是整数 d是double小数 f是float小数等等
array = mp.Array('i', [1, 2, 3, 4]) # 只能是一维列表,不能是多维
value和array可以被每一个核读取,加载到内存
多进程与lock锁
锁的应用:
import multiprocessing as mp
import timedef job(v, num, l):l.acquire()for _ in range(10):time.sleep(0.1)v.value += numprint(v.value)l.release()def multicore(): l = mp.Lock() # 实例化锁v = mp.Value('i', 0) # 设立共享内存变量p1 = mp.Process(target=job, args=(v, 1, l)) p2 = mp.Process(target=job, args=(v, 3, l))p1.start()p2.start()p1.join()p2.join()if __name__ == '__main__':multicore()
加锁的结果为:
前面程序依次+1 后面程序依次+3
不加锁的结果为:
3 4 7 8 11 12这样两个多进程交替打印结果
多线程、多进程以及函数的效率对比
import multiprocessing as mp
import threading as td
import timedef job(q):res = 0for i in range(1000000):res += i+i**2+i**3q.put(res) # queuedef multicore():q = mp.Queue()p1 = mp.Process(target=job, args=(q,))p2 = mp.Process(target=job, args=(q,))p1.start()p2.start()p1.join()p2.join()res1 = q.get()res2 = q.get()print('multicore:' , res1+res2)def normal():res = 0for _ in range(2):for i in range(1000000):res += i+i**2+i**3print('normal:', res)def multithread():q = mp.Queue()t1 = td.Thread(target=job, args=(q,))t2 = td.Thread(target=job, args=(q,))t1.start()t2.start()t1.join()t2.join()res1 = q.get()res2 = q.get()print('multithread:', res1+res2)if __name__ == '__main__':st = time.time()normal()st1= time.time()print('normal time:', st1 - st)multithread()st2 = time.time()print('multithread time:', st2 - st1)multicore()print('multicore time:', time.time()-st2)
运行的结果:
# 不用进程和线程
normal: 499999666667166666000000
normal time: 0.75795578956604
# 多线程
multithread: 499999666667166666000000
multithread time: 0.7419922351837158
# 多进程
multicore: 499999666667166666000000
multicore time: 0.4487142562866211
多进程运算的时间明显由于另外两个,多线程的运算与什么都不做时间差不多,说明多线程对于某些运算还是存在明显的短板
相关文章:

多线程和多进程的快速入门
多线程和多进程的快速入门 学习自:莫烦Python www.mofanpy.com Threading - 多线程运算python程序 多线程的简单理解:把数据分成很多段,将每一段数据放入一个线程,将所有的线程同时开始,大大的节省了运算时间。相…...

【TensorFlow深度学习】经典卷积网络架构回顾与分析
经典卷积网络架构回顾与分析 经典卷积网络架构回顾与分析:从AlexNet到ResNet、VGGLeNet、ResNet、DenseNet的深度探索AlexNet ——深度学习的破冰点火VGGNet — 简洁的美ResNet — 深持续深度的秘钥DenseNet — 密集大成塔实战代码示例:ResNet-50模型结语…...
Salesforce推出Einstein 1 Studio:用于自定义Einstein Copilot并将人工智能嵌入任何CRM应用程序的低代码人工智能工具
一、关键要点 1. Salesforce管理员和开发人员现在可以在每个Salesforce应用程序和工作流程中构建、定制和嵌入人工智能,包括Einstein Copilot。 2. Einstein 1 Studio与数据云深度集成,通过对客户数据和元数据的全面理解,解锁并统一被捕获的…...

点赋科技:建设智能饮品高地,打造数字化产业先锋
在当今数字化时代的浪潮中,点赋科技以其敏锐的洞察力和卓越的创新能力,致力于建设智能饮品高地,打造数字化产业先锋。 点赋深知智能饮品机对于推动社会进步和满足人们日益增长的需求的重要性。因此,他们投入大量资源和精力&#x…...

ORACLE RAC的一些基本理论知识
一 . Oracle RAC 的发展历程 1. Oracle Parallel Server (OPS) 早期阶段:Oracle 6 和 7 Oracle Parallel Server(OPS)是 Oracle RAC 的前身。 通过多个实例并行访问同一个数据库来提高性能。 共享磁盘架构,利用分布式锁管理&am…...

CMake的作用域:public/private/interface
在 CMake 中,public、private和 interface是用来指定目标属性的作用域的关键字,这三个有什么区别呢?这些关键字用于控制属性的可见性和传递性,影响了目标之间的依赖关系和属性传递。 public 如果在一个目标上使用 public关键字时…...
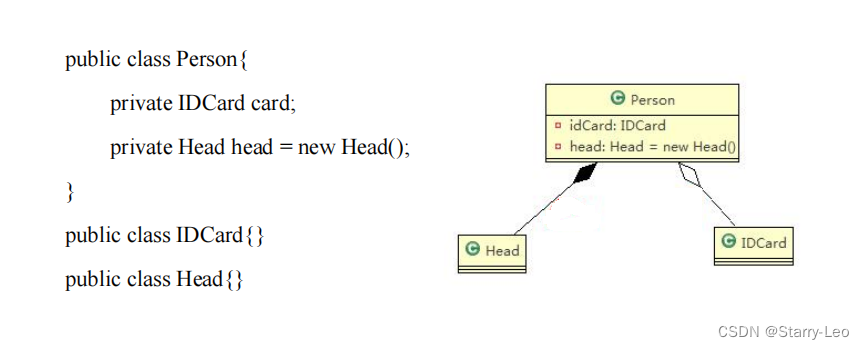
设计模式基础知识点(七大原则、UML类图)
Java设计模式(设计模式七大原则、UML类图) 设计模式的目的设计模式七大原则单一职能原则(SingleResponsibility)接口隔离原则(InterfaceSegreation)依赖倒转原则(DependenceInversion࿰…...

Android开机动画的结束过程BootAnimation(基于Android10.0.0-r41)
文章目录 Android 开机动画的结束过程BootAnimation(基于Android10.0.0-r41) Android 开机动画的结束过程BootAnimation(基于Android10.0.0-r41) 路径frameworks/base/cmds/bootanimation/bootanimation_main.cpp init进程把我们的BootAnimation的二进制文件拉起来了…...
微软远程连接工具:Microsoft Remote Desktop for Mac 中文版
Microsoft Remote Desktop 是一款由微软开发的远程桌面连接软件,它允许用户从远程地点连接到远程计算机或虚拟机,并在远程计算机上使用桌面应用程序和文件。 下载地址:https://www.macz.com/mac/5458.html?idOTI2NjQ5Jl8mMjcuMTg2LjEyNi4yMz…...
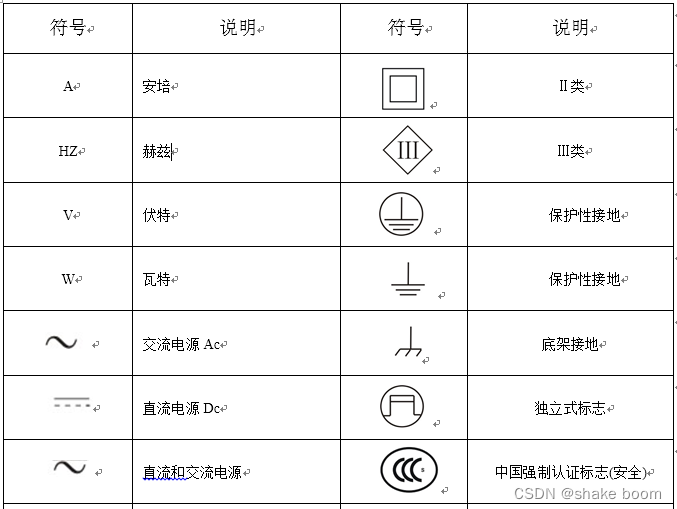
【安规介绍】
文章目录 一、基础知识安规上的六类危险的防护:安全电压漏电流接触电流能量问题:火灾问题:热问题结构问题阻燃等级绝缘等级:对接地系统的要求:结构要求:电气要求: 二、设计的关键电气绝缘距离电气爬电距离:…...
)
[sylar]后端学习:配置环境(一)
1.介绍 基于sylar大神的C高性能后端网络框架来进行环境配置和后续学习。网站链接:sylar的Linux环境配置 2.下载 按照视频进行下载,并进行下载,并最好还要下载一个vssh的软件。可以直接在网上搜索即可。 sylar_环境配置,vssh下…...

XDMA原理及其应用和发展
XDMA原理 XDMA的主要原理是通过直接访问主机内存,实现数据的快速传输。在传统的DMA(Direct Memory Access)技术中,数据传输需要经过CPU的干预,而XDMA可以绕过CPU,直接将数据从外设读取到主机内存或者从主机…...

携程梁建章:持续投资创新与AI,开启旅游行业未来增长
5月30至31日,携程集团在上海和张家界举办Envision 2024全球合作伙伴大会,邀请超50个国家和地区的1600余名外籍旅游业嘉宾与会,共同探讨中国跨境旅游市场发展机遇,讲好中国故事。 携程国际业务增速迅猛,创新与AI解锁未…...
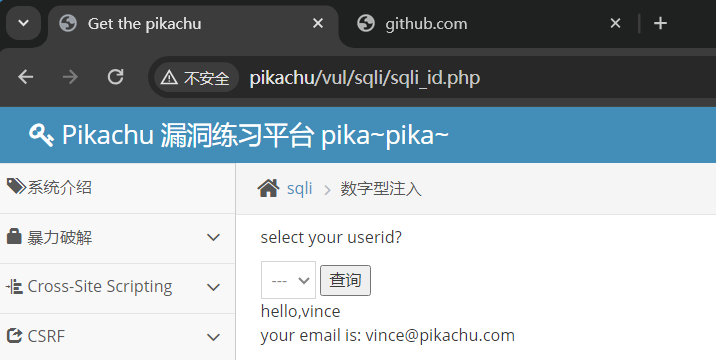
【网络安全的神秘世界】在win11搭建pikachu靶场
🌝博客主页:泥菩萨 💖专栏:Linux探索之旅 | 网络安全的神秘世界 | 专接本 下载pikachu压缩包 https://github.com/zhuifengshaonianhanlu/pikachu 下载好的pikachu放在phpstudy_pro/www目录下 创建pikachu数据库 打开phpstudy软件…...
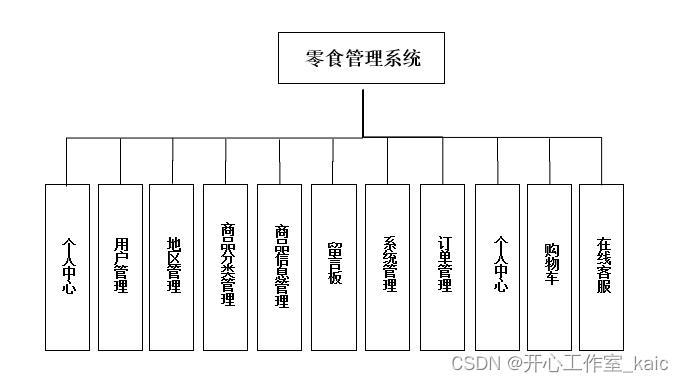
基于Java的零食管理系统的设计与实现(论文+源码)_kaic
摘 要 随着科技的进步,以及网络的普及,都为人们的生活提供了极大的方便。因此,在管理”三姆”宿舍在线零食商店时,与现代的网络联系起来是非常必要的,本次设计的系统在研发过程中应用到了Java技术,这在一定…...

【案例实操】银河麒麟桌面操作系统实例分享,V10SP1重启后网卡错乱解决方法
1.问题现象 8 个网口, 命名从 eth1 开始到 eth8。 目前在系统 grub 里面加了 net.ifnames0 biosdevname0 参数, 然后在 udev 规则中加了一条固定网卡和硬件 pci 设备号的规则文件。 最后在 rc.local 中加了两条重新安装网卡驱动的命令( rmmod…...

初级前端开发岗
定位: 日常任务的辅助执行者,前端基础建设的参与者。 素质要求: 是否遵循部门敏捷流程、规范、P0制度;具备良好的沟通和协作能力;负责日常迭代任务的落地执行;拥有较强的执行力,能够灵活解决问题; 职责:…...

颠仆流离学二叉树2 (Java篇)
本篇会加入个人的所谓鱼式疯言 ❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言 而是理解过并总结出来通俗易懂的大白话, 小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的. 🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人…...

柏林自由大学研究团队《Ecology Letters 》揭示AMF在植物对全球变化响应的作用
全球环境变化正在影响陆生植物生长。植物已经进化出各种策略来应对这些挑战,其中之一是与丛枝菌根真菌(AMF)形成共生关系(高达80%的陆生植物物种)。AMF为寄主植物提供各种益处,例如营养吸收、耐受性、食草动物防御和抗病能力,以换取糖和脂质(…...

libevent源码跨平台编译(windows/macos/linux)
1.windows编译: 克隆: git clone https://github.com/libevent/libevent.git 克隆成功 生成makefile 生成成功 默认不支持OpenSSL,MbedTLS,ZLIB这三个库 编译: cmake --build . --config release...

GA/T 1400视图库实战:从零部署Easy1400平台到设备级联全流程解析
1. 初识GA/T 1400与Easy1400平台 第一次接触GA/T 1400标准时,我完全被各种专业术语绕晕了。简单来说,这是一套专门针对视频监控领域的行业标准,规定了视频图像信息在采集、传输、存储等环节的技术要求。而Easy1400就是基于这个标准开发的一套…...

西门子PLC通信必备:手把手教你用SCL编写Modbus RTU CRC校验功能块
西门子PLC通信实战:SCL实现Modbus RTU CRC校验的工程化解决方案 在工业自动化领域,可靠的数据通信如同设备的神经系统。当两台PLC需要通过RS485接口交换温度传感器读数时,Modbus RTU协议因其简洁高效成为首选。但许多工程师在调试阶段都会遇到…...

Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案
Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费…...

UEFITool解析指南:三步骤掌握固件逆向分析的核心技术
UEFITool解析指南:三步骤掌握固件逆向分析的核心技术 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款功能强大的UEFI固件分析工具,能够帮助你深入探索计…...

Shell脚本加固实战:用shellguard提升脚本健壮性与安全性
1. 项目概述:一个为Shell脚本穿上“防弹衣”的守护者 在运维开发、自动化部署乃至日常的系统管理工作中,Shell脚本是我们最忠实、最高效的伙伴。从简单的日志清理到复杂的CI/CD流水线,Shell脚本无处不在。然而,脚本的安全性、健壮…...

3个技巧让SD-PPP插件提升Photoshop设计效率300%
3个技巧让SD-PPP插件提升Photoshop设计效率300% 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 还在为Photoshop和AI工具之间的频繁切换而烦恼吗?每次都要导出PSD、上传到AI平台、等待生成、再导回Phot…...

韩国市场合规语音交付迫在眉睫!ElevenLabs韩文生成必须配置的4项GDPR+KCC隐私开关
更多请点击: https://intelliparadigm.com 第一章:韩国市场语音AI合规落地的紧迫性与战略意义 韩国《个人信息保护法》(PIPA)于2023年修订后,明确将语音生物特征数据列为“敏感信息”,要求语音AI系统在采集…...

湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告 为何“wet plate collodion”提示词突然失灵? 在 Midjourney v6.1 及 N…...

开源项目仪表盘开发指南:基于React、Next.js与GitHub API的实践
1. 项目概述:一个为开源项目量身定制的现代化仪表盘 最近在折腾一个开源项目,想把它的状态、数据和一些关键指标更直观地展示出来,于是找到了 tugcantopaloglu/openclaw-dashboard 这个仓库。简单来说,这是一个专门为开源项目设…...

ubantu安装vscode
在火狐浏览器中搜索vscode官网,找到.deb文件下载,下载完成后文件所在的位置为 主文件夹/下载 文件夹内。...