留给“端侧大模型”的时间不多了
端侧大模型(Edge AI models),也就是只在设备本地(如智能手机、IoT设备、嵌入式系统等)运行的大模型,过去一两年来非常流行。
具体表现在,终端设备厂商,如苹果、荣耀、小米、OV等,AI公司如商汤科技,都推出了自研的纯端侧大模型。
端侧大模型存在的意义,就是“以小博大”。
简单来说,和云侧大模型相比,端侧大模型要在本地部署,所以参数规模都不大,不用担心私密数据在推理时被泄露;不需要网络传输,因此响应速度更快;设备原生搭载,不需要租用云资源,用起来更省……
听起来,端侧大模型简直是AI设备不可或缺的标配啊。但实际情况,可能出乎很多人的意料。

我们在调研和使用多个终端厂商的大模型时发现,端云协同、云端大模型,才是大模型在端侧的主流形式。
比如目前很流行的“手机拍照一键擦除背景人物”,仅靠端侧大模型的计算能力是无法实现的,需要端云协同来完成。
再比如公文写作、长文要点总结、PDF要点摘要等,端侧大模型要么无法完成,比如荣耀、OPPO端侧大模型都不支持PDF文本摘要,小米MiLM的支持度和生成效果也不够好。
最终,用户还是要访问GPT-4、文心一言、智谱清言、讯飞星火、KIMI等云端大模型的网页/APP,来满足一些复杂AIGC任务需求。
不难看到,端侧大模型听起来很美,但真正用起来却有点鸡肋。
而随着云端大模型“变大”(走向统一多模态)又“变小”(压缩技术),留给“端侧大模型”的时间,真的不多了。
端侧大模型不是万能的
但没有云侧大模型是万万不能的
目前来看,“端侧大模型”收益和损失这笔账,根本算不平。
先说收益,云端大模型比端侧大模型对用户的价值更大。
端侧AI首先要保障用户体验,先有价值,再说其他。只能在设备本地运行,意味着“端侧大模型”注定不会太大,必然限制了模型本身的性能表现,无法媲美云端大模型。
所以,用户在使用端侧大模型时,要牺牲一部分体验,那么所获得的收益是否更大呢?并不是。
云端大模型的能力变得越来越强大,与不得不“因小失大”的端侧大模型,拉开了更大的体验差距。比如近期OpenAI和谷歌斗得火热的多模态大模型,GPT-4o和Gemini带来令人惊艳的语音交互、多种模态一次生成等能力,处理图片、视频、音频等数据和复杂逻辑,都要在云端运行。

一位国内PC行业的资深从业者曾告诉脑极体,大模型出来之后我们硬件企业就在研究,怎么将大模型跟PC结合,究竟什么是真正的AI PC?结论就是,搭载了GPT-4(代指当下最先进大模型)的硬件,确实可以叫“AI xx”,模型能力才是最核心的。
所以,想做好端侧AI,端侧大模型不是万能的,但没有云侧大模型是万万不能的。
云端大模型不得不用,那端侧大模型也一样非用不可吗?这就要来说说损失了。
不用端侧大模型,并不会给用户带来更大的麻烦。
此前,终端追求搭载“端侧大模型”,主要受限于两点:计算瓶颈、安全顾虑。大模型推理对实时性的要求,云端相比本地的时延更高。此外,手机、PC涉及大量隐私数据,传输到云端进行推理,让很多人有顾虑。上述两点“损失”正在被积极地解决。
比如前不久谷歌I/O大会上,就发布了响应速度快、成本低的轻量化模型Gemini 1.5 Flash。谷歌采用了“蒸馏”方法,将较大Gemini 模型的核心知识和技能迁移到了更小、更高效的模型中,Gemini 1.5 Flash在摘要、聊天应用、图像和视频字幕等多种任务中,有很好的表现,可以在不同平台运行。
此外,本地计算硬件针对AI任务进行优化,也可以提升云端推理服务的流畅度。目前x86、Arm阵营都在积极提升端侧计算单元对AI专项任务的适配度,已经有旗舰和高端手机支持实时运行大规模参数量的大模型。
数据安全层面,终端厂商和大模型企业都推出了相应的隐私安全保护机制,通过“数据可用不可见”、脱敏、联邦学习等多种手段,防范泄露风险。

以一贯注重隐私安全的苹果为例,也自研了端侧模型OpenELM,可在手机和笔记本电脑等设备上运行,但在真正上线AIGC等能力时,据说也将选择与大模型企业合作(国外据传是OpenAI,国内据传是文心一言)。
综上,使用“云端大模型”的收益正显著增大,不用“端侧大模型”的损失却越来越小。这让“以小博大”端侧大模型,显得越来越不划算了。
接下来的故事也不难预测,随着越来越多的终端企业,纷纷把云端大模型塞进设备,纯端侧大模型的存在会越来越尴尬,进入到“不好用-不爱用-更不好用”的循环中。
这端侧大模型
终端厂商是非做不可吗?
你可能会问了,既然端侧大模型不如云端大模型好用,为什么终端厂商还都在下大力气做呢?
客观情况是,大模型必须得有,但终端厂商并不适合做云端大模型,所以端侧、端云协同就成了必选项。
一位国内某终端企业的负责人曾直言:即使我的研发费用再翻一倍,也没法做像ChatGPT、Sora这样的通用大模型,还是会选择跟百度、腾讯、阿里巴巴等伙伴合作。
比如荣耀正在引导百模千态,在手机中接入文心一言等通用大模型,以及高德地图、航旅纵横等行业大模型;华为在PC中接入了文心一言、讯飞星火、智谱AI的通用大模型,同时上线了基于自研盘古大模型的AI纪要功能……
从主观角度猜测,终端厂商做端侧大模型,既有品牌方面的考量,彰显大模型技术的自研能力,也有“将灵魂握在自己手里”的考虑,类似于银行、金融机构、车企希望将数据这一核心优势,掌握在自己手里,打造行业大模型,而非交给大模型厂商。

终端厂商,既希望通过合作云端大模型,拔高AI设备的体验优势,增强产品对消费者的吸引力,又希望通过自研抓住端侧大模型,守住数据护城河,是进可攻、退可守的大模型策略。
我们预计,随着云端大模型的性能、能力在非线性增长,终端厂商的纯端侧大模型,会被拉开越来越大的差距,无法成为消费者的购买决策依据。
不远的将来,能否在设备侧整合优质云端大模型生态,会成为AI终端设备的赛点。
总结一下就是,端侧大模型,终端厂商可以做,但没必要。云侧大模型,终端厂商必须有,且得比人强。
深度协作的不只大模型
还有两类厂商
在一次与华为终端的交流中,对方提到:华为是唯一一个云侧通用大模型、端侧大模型全自研的终端厂商(指盘古大模型),这给AI硬件奠定了很好的基础。比如要完成一个复杂的AIGC任务,可以拆分为云、端、边缘等并行训练,兼顾推理效果、运行速度、数据安全等。
需要说明的是,上述思路仍处于概念验证阶段,目前我们还未能在华为终端设备上体验到盘古大模型从云到端的深度整合。但这一理念,在逻辑上确实是说得通的——通过端云高效协同,可以建立起无短板的大模型产品力,打动AI硬件的潜在消费者,而这离不开终端厂商和通用大模型厂商的深度合作。
端侧大模型和云侧通用大模型全自有的终端企业,确实具备紧密融合的先天优势,不过,其他厂商也可以通过开放生态补足,形成一个更全面的模型生态。
这对双方来说,是一件互利共赢的事情:

通用大模型厂商,需要借助终端厂商的庞大设备生态,作为大模型落地的土壤,回收基座模型的庞大投入。借助端侧的设备数据,更好地解决大模型的幻觉问题,推动模型进化。
而终端厂商,需要通用大模型(尤其是尖端版本的云端大模型)作为体验支撑,为用户提供最先进的AIGC应用和体验,避免在基座模型上投入太高的研发成本,也避免在AI体验上被其他终端厂商拉大。
在此基础上,终端厂商和云端通用大模型厂商还要抓紧解决的重点问题:
安全问题。如何在保证隐私数据的基础上,学习设备数据,明确数据权益与责任归属,对数据产生的商业收益建立合理的分配机制。
开发者分利政策。无论是手机的AI应用,还是云端大模型的AI应用,都需要开发者来完成。终端开发者生态和大模型开发者生态的进一步打通,也会增加对开发者的吸引力,加速AI应用的孵化。那么,如何共同赋能并分利给开发者,将成为两类厂商合作与博弈的关键。
今年上半年,我们见证了通用大模型的诸多突破,留给端侧大模型的时间已经不多了,留给终端厂商构建大模型共同体生态的机会窗口期,也并不会太久。
下半年,我们或将见证一场“终端厂商+大模型厂商”携手的“阵营战”。
相关文章:
留给“端侧大模型”的时间不多了
端侧大模型(Edge AI models),也就是只在设备本地(如智能手机、IoT设备、嵌入式系统等)运行的大模型,过去一两年来非常流行。 具体表现在,终端设备厂商,如苹果、荣耀、小米、OV等&…...
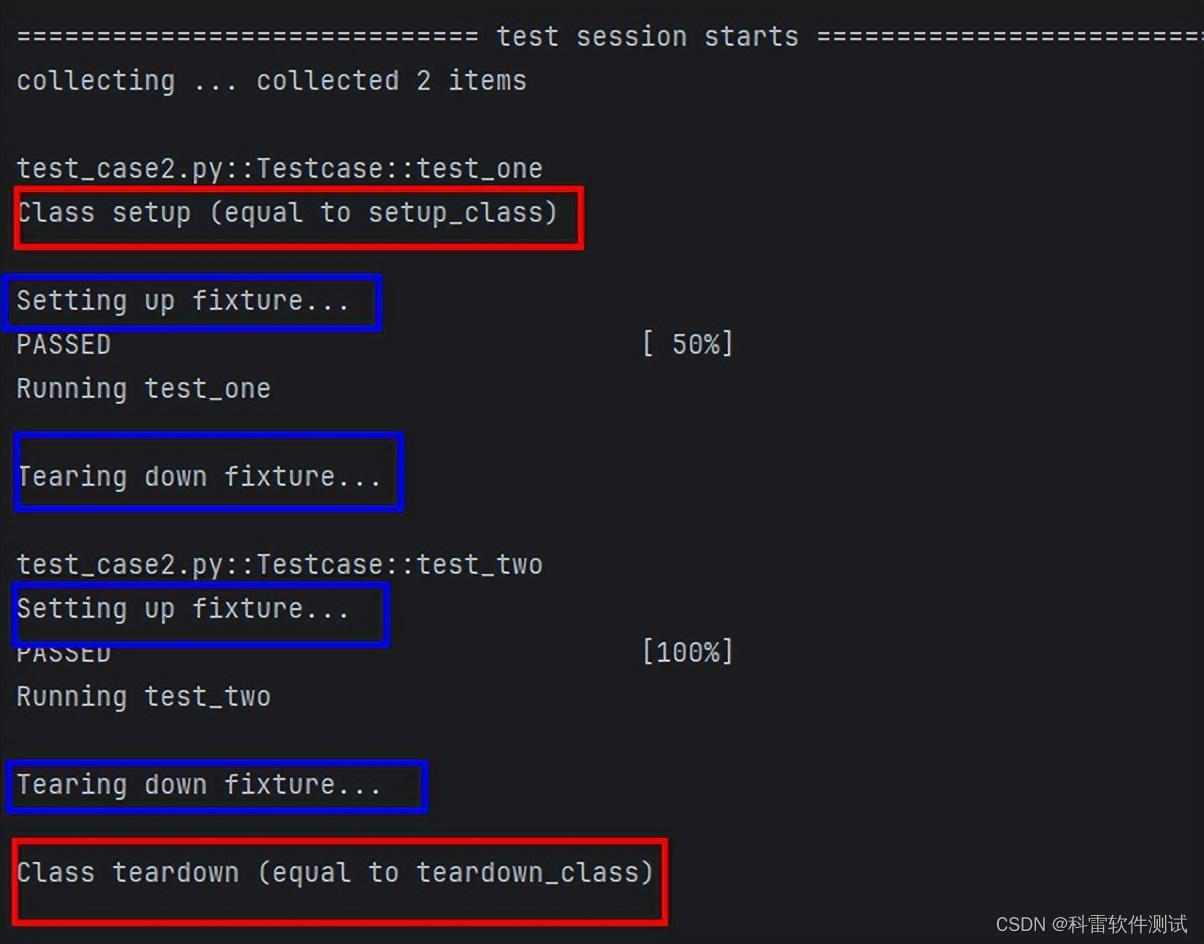
Pytest框架中的Setup和Teardown功能
在 pytest 测试框架中,setup 和 teardown是用于在每个测试函数之前和之后执行设置和清理的动作,而pytest 实际上并没有内置的 setup 和 teardown 函数,而是使用了一些装饰器或钩子函数来实现类似的功能。 学习目录 钩子函数(Hook…...

yolov10/v8 loss详解
v10出了就想看看它的loss设计有什么不同,看下来由于v8和v10的loss部分基本一致就放一起了。 v10的论文笔记,还没看的可以看看,初步尝试耗时确实有提升 好记性不如烂笔头,还是得记录一下,以免忘了,废话结束…...

Typescript高级: 深入理解infer关键字
概述 在 TS 中,infer 是一个高级类型操作,特别是条件类型和映射类型中非常有用的关键字它在泛型中使用也会是一个强大工具,增强了类型推断的能力,让开发者更灵活地处理和操作类型它允许在泛型类型推导过程中捕获一个具体的类型&a…...

JQC-3FF-S-Z 继电器模块使用(arduino)
前言 继电器模块可以控制电流的接通和非接通状态,和开关一样。实际上是用小电流去控制大电流运作的一种“自动开关” 本文只是简单使用继电器模块做一个 led 点亮和熄灭的案例,结合案例可以和 nodemcu 等板子结合做出远程控制开关。 材料准备 杜邦线…...
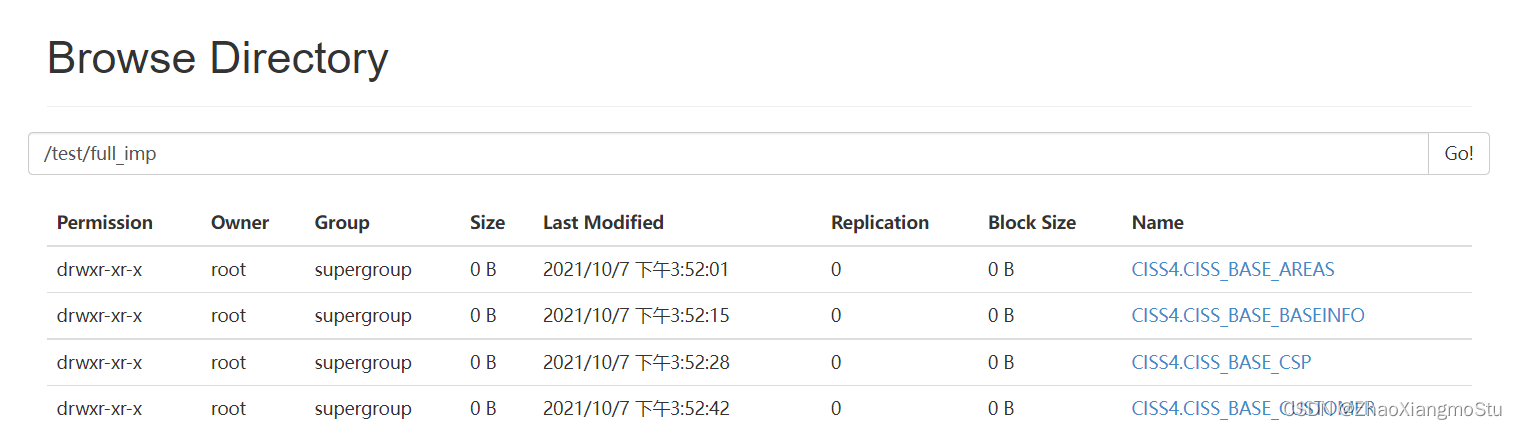
黑马一站制造数仓实战2
问题 DG连接问题 原理:JDBC:用Java代码连接数据库 Hive/SparkSQL:端口有区别 可以为同一个端口,只要不在同一台机器 项目:一台机器 HiveServer:10000 hiveserver.port 10000 SparkSQL:10001…...
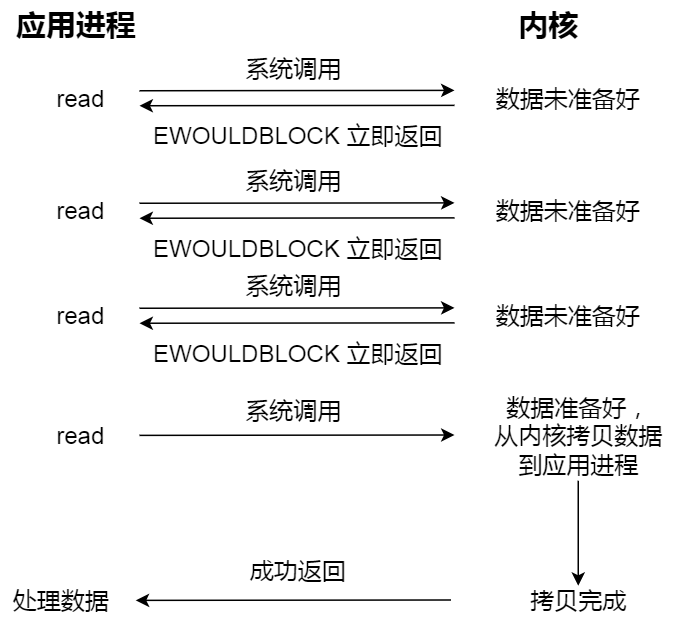
网络I/O模型
网络I/O模型 同步I/O阻塞I/O非阻塞I/OI/O多路复用select函数接口示例 poll函数接口示例 poll 和 select 的区别epoll原理:示例 异步I/O 同步I/O 阻塞I/O 一个基本的C/S模型如下图所图:其中 listen()、connect()、write()、read() 都是阻塞I/O࿰…...
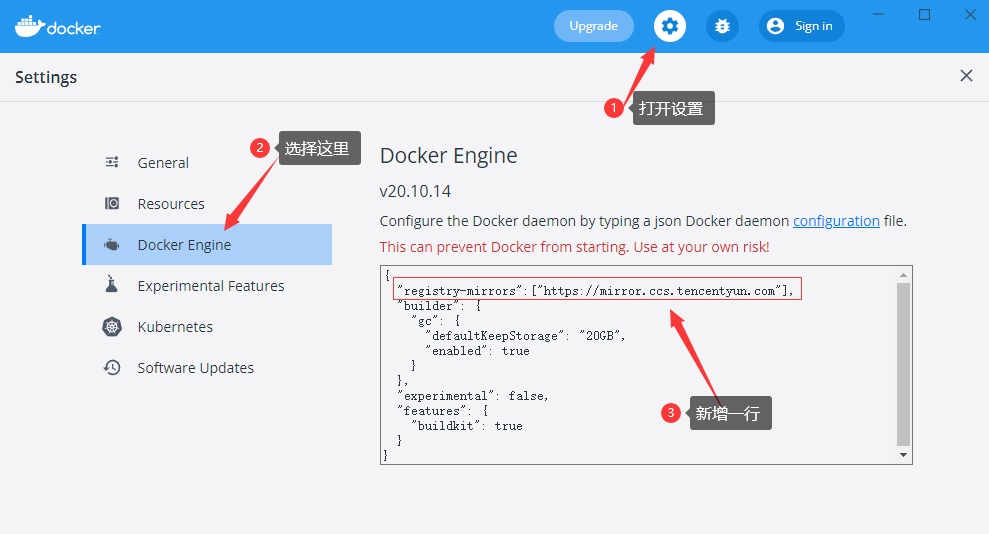
Docker 简介和安装
目录 Docker 是什么 跟普通虚拟机的对比 打包、分发、部署 Docker 部署的优势 Docker 通常用来做什么 重要概念:镜像、容器 安装 镜像加速源 Docker 是什么 Docker 是一个应用打包、分发、部署的工具 你也可以把它理解为一个轻量的虚拟机,它只虚…...

【源码】Spring Data JPA原理解析之Repository自定义方法命名规则执行原理(二)
Spring Data JPA系列 1、SpringBoot集成JPA及基本使用 2、Spring Data JPA Criteria查询、部分字段查询 3、Spring Data JPA数据批量插入、批量更新真的用对了吗 4、Spring Data JPA的一对一、LazyInitializationException异常、一对多、多对多操作 5、Spring Data JPA自定…...

Vue前端中从后端获取图片验证码
前端发送请求 <template><el-form :model"user" :rules"rules" ref"userForm" class"login" label-width"auto" style"max-width: 600px"><el-form-item label"用户名" prop"name…...
【源码】多语言H5聊天室/thinkphp多国语言即时通讯/H5聊天室源码/在线聊天/全开源
多语言聊天室系统,可当即时通讯用,系统默认无需注册即可进入群聊天,全开源 【海外聊天室】多语言H5聊天室/thinkphp多国语言即时通讯/H5聊天室源码/在线聊天/全开源 - 吾爱资源网...

gitlab 创建 ssh 和 token
文章目录 一、创建ssh key二、将密钥内容复制到gitlab三、创建token 一、创建ssh key 打开控制台cmd,执行命令 ssh-keygen -t rsa -C xxxxx xxxxx是你自己的邮箱 C:\Users\xx\.ssh 目录下会创建一个名为id_rsa.pub的文件,用记事本打开,并…...

Docker - Kafka
博文目录 文章目录 说明命令 说明 Docker Hub - bitnami/kafka Docker Hub - apache/kafka Kafka QuickStart Kafka 目前没有 Docker 官方镜像, 目前拉取次数最多的是 bitnami/kafka, Apache 提供的是 apache/kafka (更新最及时), 本文使用 bitnami/kafka bitnami/kafka 镜像…...
一键实现文件夹批量高效重命名:轻松运用随机一个字母命名,让文件管理焕然一新!
在数字化时代,文件夹管理是我们日常生活和工作中不可或缺的一部分。然而,随着文件数量的不断增加,文件夹命名的繁琐和重复成为了一个让人头疼的问题。你是否曾因为手动一个个重命名文件夹而感到枯燥乏味?你是否曾渴望有一种方法能…...

Vue3项目练习详细步骤(第二部分:主页面搭建)
主页面搭建 页面主体结构 路由 子路由 主页面搭建 页面主体结构 在vuews目录下新建Layout.vue文件 主页面内容主体代码 <script setup> import {Management,Promotion,UserFilled,User,Crop,EditPen,SwitchButton,CaretBottom } from element-plus/icons-vue imp…...
[个人总结]-java常用方法
1.获取项目根路径 user.dir是一个系统属性,表示用户当前的工作目录,大多数情况下,用户的当前工作目录就是java项目的根目录(src文件的同级路径) System.getProperty("user.dir") 结果:D:\code…...

什么是Java泛型?它有什么作用
Java泛型(Generics)是一种允许在定义类、接口和方法时使用类型参数的机制。泛型提供了一种机制,使得代码可以对多种类型的对象进行操作,而无需进行类型转换。 Java泛型的作用 类型安全:通过在编译时进行类型检查&…...

[机缘参悟-197] - 《道家-水木然人间清醒1》读书笔记 -21-看问题从现象到本质的层次
目录 1. 现象层: 2. 关联层: 3. 原因层: 4. 本质层: 5. 解决方案层: 6. 设计实现层: 7. 泛化: 8. 创新与发现: 看问题从现象到本质的层次是一个逐步深入、由表及里的过程。这…...

AIGC商业案例实操课,发觉其创造和商业的无限可能,Ai技术在行业应用新的商机
课程下载:https://download.csdn.net/download/m0_66047725/89307523 更多资源下载:关注我。 课程内容 1 AI为什么火 。写在课程前面的寄语 。AIGC标志性事件:太空歌剧院 。AI人工智能为什么这么火 ,AI人工智能发展历程 。聊天AI会取…...

Java学习路径图
1.学习路径 JAVA架构师学习路径 2.路径拆解 2.1 Spring 2.1.1 SpringBoot原理 SpringBoot2学习视频 SpringBoot2笔记 SpringBoo2代码 2.2.2 SpringBoot项目 《谷粒商城》学习视频...

ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch + CUDA环境配置与避坑
ONNXRuntime GPU推理想用BFloat16加速?手把手教你搞定PyTorch CUDA环境配置与避坑 在深度学习模型部署领域,BFloat16数据类型正逐渐成为提升推理性能的新宠。这种16位浮点格式保留了与32位浮点相同的指数位,在保持数值范围的同时减少了内存占…...

从零构建现代化Web控制面板:安全架构与实时监控实践
1. 项目概述:一个为开发者设计的现代化控制面板最近在GitHub上看到一个挺有意思的项目,叫clawpanel,作者是kweephyo-pmt。光看名字,你可能会联想到“爪子”和“面板”,感觉像是个带点攻击性或工具属性的管理界面。实际…...

轻量级爬虫框架slacrawl:基于规则驱动的模块化数据采集实践
1. 项目概述:一个轻量级、模块化的网页爬虫框架最近在做一个需要从多个网站定时抓取结构化数据的小项目,找了一圈现成的工具,要么太重(像Scrapy,学起来成本高),要么太死板(很多脚本只…...

Arm Cortex-X2/X3架构解析与性能优化实践
1. Arm Cortex-X2/X3集群架构概述在Armv9架构的高性能计算领域,Cortex-X2和X3代表了当前最先进的CPU设计理念。作为DynamIQ共享单元(DSU)的核心组件,它们通过可配置的缓存层次结构和智能一致性协议,为现代异构计算提供了灵活的解决方案。1.1 …...

JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯
JetBrains IDE试用期重置终极指南:简单三步实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否曾经在项目开发的关键时刻,突然看到JetBrains IDE弹出"评估期已结束…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

ElevenLabs匈牙利语音API响应延迟飙升300%?内网穿透+CDN缓存+匈牙利语音素预加载三阶优化方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs匈牙利文语音API响应延迟飙升300%的现象复现与根因定位 近期多位开发者反馈,ElevenLabs API 在处理匈牙利语(hu-HU)文本转语音请求时,平均端到…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

开源技能安全仪表盘:从架构解析到CI/CD集成的DevSecOps实践
1. 项目概述:一个面向技能开发者的安全仪表盘最近在折腾一些智能设备上的技能开发,发现一个挺普遍但容易被忽视的问题:我们花大量时间在功能实现和用户体验上,但技能本身的安全性评估,往往只能等到上线后,通…...

开源婚礼技能库:用项目管理思维破解备婚焦虑,打造个性化高性价比婚礼
1. 项目概述:婚礼技能库的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“awesome-wedding-skills”。光看名字,你可能会觉得这又是一个普通的“awesome”系列资源列表,无非是收集一些婚礼策划、摄影、化妆的链接。但当我点…...