YOLOv8 segment介绍
1.YOLOv8图像分割支持的数据格式:
(1).用于训练YOLOv8分割模型的数据集标签格式如下:
1).每幅图像对应一个文本文件:数据集中的每幅图像都有一个与图像文件同名的对应文本文件,扩展名为".txt";
2).文本文件中每个目标(object)占一行:文本文件中的每一行对应图像中的一个目标实例;
3).每行目标信息:如下所示:之间用空格分隔
A.目标类别索引:整数,例如:0代表person,1代表car,等等;
B.目标边界坐标:mask区域周围的边界坐标,归一化为[0, 1];
<class-index> <x1> <y1> <x2> <y2> ... <xn> <yn>注:每行的长度不必相等;每个分隔label必须至少有3对xy点
(2).数据集YAML格式:Ultralytics框架使用YAML文件格式来定义用于训练分隔模型的数据集和模型配置,如下面测试数据集melon中melon_seg.yaml内容如下: 在网上下载了60多幅包含西瓜和冬瓜的图像组成melon数据集
path: ../datasets/melon_seg # dataset root dir
train: images/train # train images (relative to 'path')
val: images/val # val images (relative to 'path')
test: # test images (optional)# Classes
names:0: watermelon1: wintermelon2.使用半自动标注工具 EISeg 对数据集melon进行标注:
(1).从 PaddleSeg 中下载"通用场景的图像标注"高精度模型static_hrnet18_ocr64_cocolvis.zip;
(2).标注前先按照下面操作设置好:
1).选中JSON保存,取消COCO保存;
2).选中自动保存;
3).取消灰度保存.
3.编写Python脚本将EISeg生成的json文件转换成YOLOv8 segment支持的txt文件:
import os
import json
import argparse
import colorama
import random
import shutil
import cv2# supported image formats
img_formats = (".bmp", ".jpeg", ".jpg", ".png", ".webp")def parse_args():parser = argparse.ArgumentParser(description="json(EISeg) to txt(YOLOv8)")parser.add_argument("--dir", required=True, type=str, help="images directory, all json files are in the label directory, and generated txt files are also in the label directory")parser.add_argument("--labels", required=True, type=str, help="txt file that hold indexes and labels, one label per line, for example: face 0")parser.add_argument("--val_size", default=0.2, type=float, help="the proportion of the validation set to the overall dataset:[0., 0.5]")parser.add_argument("--name", required=True, type=str, help="the name of the dataset")args = parser.parse_args()return argsdef get_labels_index(name):labels = {} # key,valuewith open(name, "r") as file:for line in file:# print("line:", line)key_value = []for v in line.split(" "):# print("v:", v)key_value.append(v.replace("\n", "")) # remove line breaks(\n) at the end of the lineif len(key_value) != 2:print(colorama.Fore.RED + "Error: each line should have only two values(key value):", len(key_value))continuelabels[key_value[0]] = key_value[1]with open(name, "r") as file:line_num = len(file.readlines())if line_num != len(labels):print(colorama.Fore.RED + "Error: there may be duplicate lables:", line_num, len(labels))return labelsdef get_json_files(dir):jsons = []for x in os.listdir(dir+"/label"):if x.endswith(".json"):jsons.append(x)return jsonsdef parse_json(name_json, name_image):img = cv2.imread(name_image)if img is None:print(colorama.Fore.RED + "Error: unable to load image:", name_image)raiseheight, width = img.shape[:2]with open(name_json, "r") as file:data = json.load(file)objects=[]for i in range(0, len(data)):object = []object.append(data[i]["name"])object.append(data[i]["points"])objects.append(object)return width, height, objectsdef write_to_txt(name_json, width, height, objects, labels):name_txt = name_json[:-len(".json")] + ".txt"# print("name txt:", name_txt)with open(name_txt, "w") as file:for obj in objects: # 0: name; 1: pointsif len(obj[1]) < 3:print(colorama.Fore.RED + "Error: must be at least 3 pairs:", len(obj[1]), name_json)raiseif obj[0] not in labels:print(colorama.Fore.RED + "Error: unsupported label:", obj[0], labels)raisestring = ""for pt in obj[1]:string = string + " " + str(round(pt[0] / width, 6)) + " " + str(round(pt[1] / height, 6))string = labels[obj[0]] + string + "\r"file.write(string)def json_to_txt(dir, jsons, labels):for json in jsons:name_json = dir + "/label/" + jsonname_image = ""for format in img_formats:file = dir + "/" + json[:-len(".json")] + formatif os.path.isfile(file):name_image = filebreakif not name_image:print(colorama.Fore.RED + "Error: required image does not exist:", json[:-len(".json")])raise# print("name image:", name_image)width, height, objects = parse_json(name_json, name_image)# print(f"width: {width}; height: {height}; objects: {objects}")write_to_txt(name_json, width, height, objects, labels)def get_random_sequence(length, val_size):numbers = list(range(0, length))val_sequence = random.sample(numbers, int(length*val_size))# print("val_sequence:", val_sequence)train_sequence = [x for x in numbers if x not in val_sequence]# print("train_sequence:", train_sequence)return train_sequence, val_sequencedef get_files_number(dir):count = 0for file in os.listdir(dir):if os.path.isfile(os.path.join(dir, file)):count += 1return countdef split_train_val(dir, jsons, name, val_size):if val_size > 0.5 or val_size < 0.01:print(colorama.Fore.RED + "Error: the interval for val_size should be:[0.01, 0.5]:", val_size)raisedst_dir_images_train = "datasets/" + name + "/images/train"dst_dir_images_val = "datasets/" + name + "/images/val"dst_dir_labels_train = "datasets/" + name + "/labels/train"dst_dir_labels_val = "datasets/" + name + "/labels/val"try:os.makedirs(dst_dir_images_train) #, exist_ok=Trueos.makedirs(dst_dir_images_val)os.makedirs(dst_dir_labels_train)os.makedirs(dst_dir_labels_val)except OSError as e:print(colorama.Fore.RED + "Error: cannot create directory:", e.strerror)raise# print("jsons:", jsons)train_sequence, val_sequence = get_random_sequence(len(jsons), val_size)for index in train_sequence:for format in img_formats:file = dir + "/" + jsons[index][:-len(".json")] + format# print("file:", file)if os.path.isfile(file):shutil.copy(file, dst_dir_images_train)breakfile = dir + "/label/" + jsons[index][:-len(".json")] + ".txt"if os.path.isfile(file):shutil.copy(file, dst_dir_labels_train)for index in val_sequence:for format in img_formats:file = dir + "/" + jsons[index][:-len(".json")] + formatif os.path.isfile(file):shutil.copy(file, dst_dir_images_val)breakfile = dir + "/label/" + jsons[index][:-len(".json")] + ".txt"if os.path.isfile(file):shutil.copy(file, dst_dir_labels_val)num_images_train = get_files_number(dst_dir_images_train)num_images_val = get_files_number(dst_dir_images_val)num_labels_train = get_files_number(dst_dir_labels_train)num_labels_val = get_files_number(dst_dir_labels_val)if num_images_train + num_images_val != len(jsons) or num_labels_train + num_labels_val != len(jsons):print(colorama.Fore.RED + "Error: the number of files is inconsistent:", num_images_train, num_images_val, num_labels_train, num_labels_val, len(jsons))raisedef generate_yaml_file(labels, name):path = os.path.join("datasets", name, name+".yaml")# print("path:", path)with open(path, "w") as file:file.write("path: ../datasets/%s # dataset root dir\n" % name)file.write("train: images/train # train images (relative to 'path')\n")file.write("val: images/val # val images (relative to 'path')\n")file.write("test: # test images (optional)\n\n")file.write("# Classes\n")file.write("names:\n")for key, value in labels.items():# print(f"key: {key}; value: {value}")file.write(" %d: %s\n" % (int(value), key))if __name__ == "__main__":colorama.init()args = parse_args()# 1. parse JSON file and write it to a TXT filelabels = get_labels_index(args.labels)# print("labels:", labels)jsons = get_json_files(args.dir)# print(f"jsons: {jsons}; number: {len(jsons)}")json_to_txt(args.dir, jsons, labels)# 2. split the datasetsplit_train_val(args.dir, jsons, args.name, args.val_size)# 3. generate a YAML filegenerate_yaml_file(labels, args.name)print(colorama.Fore.GREEN + "====== execution completed ======")以上脚本包含3个功能:
1).将json文件转换成txt文件;
2).将数据集随机拆分成训练集和测试集;
3).产生需要的yaml文件
4.编写Python脚本进行train:
import argparse
import colorama
from ultralytics import YOLOdef parse_args():parser = argparse.ArgumentParser(description="YOLOv8 train")parser.add_argument("--yaml", required=True, type=str, help="yaml file")parser.add_argument("--epochs", required=True, type=int, help="number of training")parser.add_argument("--task", required=True, type=str, choices=["detect", "segment"], help="specify what kind of task")args = parser.parse_args()return argsdef train(task, yaml, epochs):if task == "detect":model = YOLO("yolov8n.pt") # load a pretrained modelelif task == "segment":model = YOLO("yolov8n-seg.pt") # load a pretrained modelelse:print(colorama.Fore.RED + "Error: unsupported task:", task)raiseresults = model.train(data=yaml, epochs=epochs, imgsz=640) # train the modelmetrics = model.val() # It'll automatically evaluate the data you trained, no arguments needed, dataset and settings rememberedmodel.export(format="onnx") #, dynamic=True) # export the model, cannot specify dynamic=True, opencv does not support# model.export(format="onnx", opset=12, simplify=True, dynamic=False, imgsz=640)model.export(format="torchscript") # libtorchif __name__ == "__main__":colorama.init()args = parse_args()train(args.task, args.yaml, args.epochs)print(colorama.Fore.GREEN + "====== execution completed ======")执行结果如下图所示:会生成best.pt、best.onnx、best.torchscript
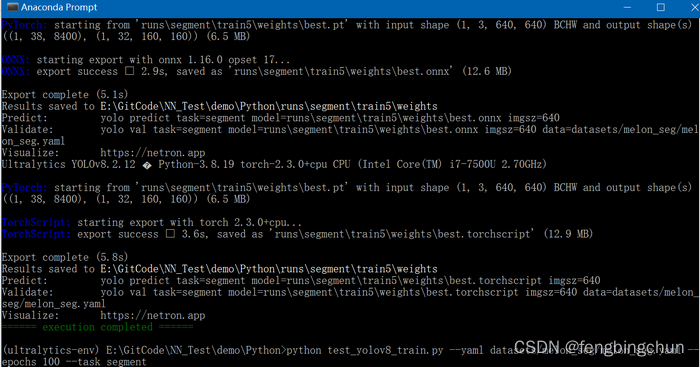
5.生成的best.onnx使用Netron进行可视化,结果如下图所示:
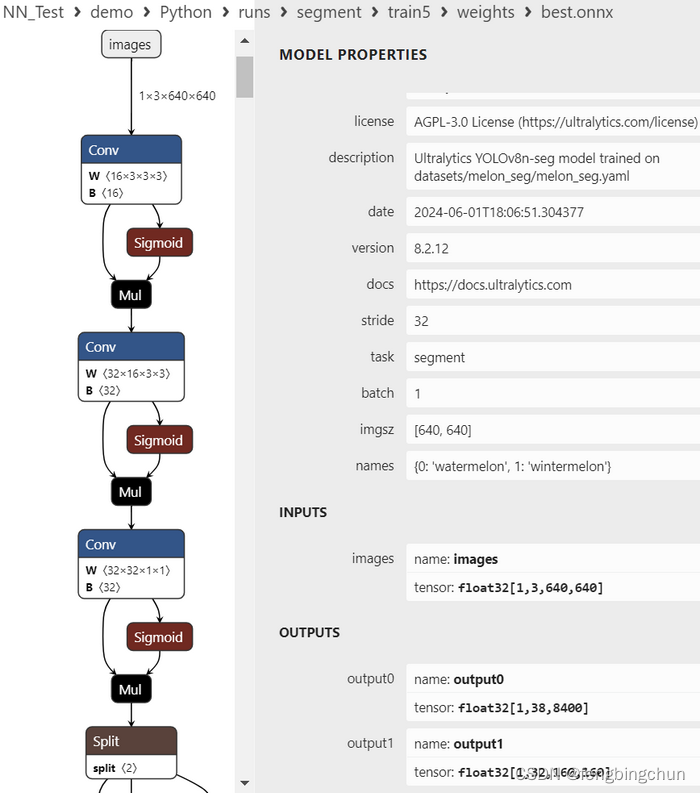
说明:
1).输入:images: float32[1,3,640,640] :与YOLOv8 detect一致,大小为3通道640*640
2).输出:包括2层,output0和output1
A.output0: float32[1,38,8400] :
a.8400:模型预测的所有box的数量,与YOLOv8 detect一致;
b.38: 每个框给出38个值:4:xc, yc, width, height;2:class, confidences;32:mask weights
B.output1: float32[1,32,160,160] :最终mask大小是160*160;output1中的masks实际上只是原型masks,并不代表最终masks。为了得到某个box的最终mask,你可以将每个mask与其对应的mask weight相乘,然后将所有这些乘积相加。此外,你可以在box上应用NMS,以获得具有特定置信度阈值的box子集
6.编写Python脚本实现predict:
import colorama
import argparse
from ultralytics import YOLO
import osdef parse_args():parser = argparse.ArgumentParser(description="YOLOv8 predict")parser.add_argument("--model", required=True, type=str, help="model file")parser.add_argument("--dir_images", required=True, type=str, help="directory of test images")parser.add_argument("--dir_result", required=True, type=str, help="directory where the image results are saved")args = parser.parse_args()return argsdef get_images(dir):# supported image formatsimg_formats = (".bmp", ".jpeg", ".jpg", ".png", ".webp")images = []for file in os.listdir(dir):if os.path.isfile(os.path.join(dir, file)):# print(file)_, extension = os.path.splitext(file)for format in img_formats:if format == extension.lower():images.append(file)breakreturn imagesdef predict(model, dir_images, dir_result):model = YOLO(model) # load an modelmodel.info() # display model informationimages = get_images(dir_images)# print("images:", images)os.makedirs(dir_result) #, exist_ok=True)for image in images:results = model.predict(dir_images+"/"+image)for result in results:# print(result)result.save(dir_result+"/"+image)if __name__ == "__main__":colorama.init()args = parse_args()predict(args.model, args.dir_images, args.dir_result)print(colorama.Fore.GREEN + "====== execution completed ======")执行结果如下图所示:
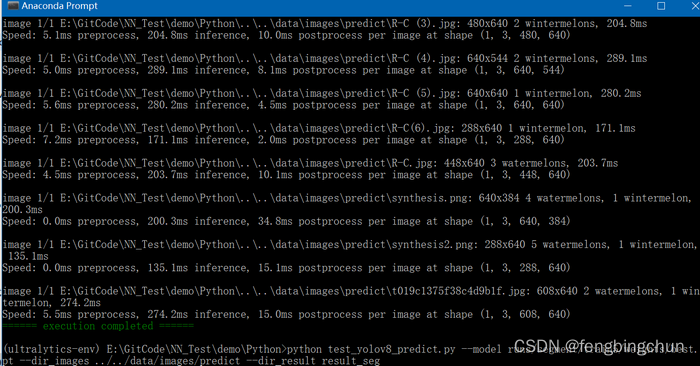
其中一幅图像的分割结果如下图所示:以下是epochs设置为100时生成的best.pt的结果

GitHub:https://github.com/fengbingchun/NN_Test
相关文章:
YOLOv8 segment介绍
1.YOLOv8图像分割支持的数据格式: (1).用于训练YOLOv8分割模型的数据集标签格式如下: 1).每幅图像对应一个文本文件:数据集中的每幅图像都有一个与图像文件同名的对应文本文件,扩展名为".txt"; 2).文本文件中每个目标(object)占一行…...

PMBOK® 第六版 项目整合管理概念
目录 读后感—PMBOK第六版 目录 项目往往会牵涉到众多专业的知识以及来自不同专业、具有不同性格且可能处在不同地理位置的人员,存在着诸多不同分工的状况。要是没有统一的目标,相互之间也没有有效的沟通机制,并且不存在计划、监控以及平衡等…...

【Qt】【模型视图架构】代理模型
文章目录 代理模型简单介绍QSortFilterProxyModel类简单介绍排序过滤子类化 代理模型简单介绍 代理模型的作用是可以将一个模型中的数据进行排序或者过滤,然后提供给视图进行显示。 如下所示,创建一个源模型、一个代理模型,界面上创建一个列…...

Flutter 中的 IconTheme 小部件:全面指南
Flutter 中的 IconTheme 小部件:全面指南 Flutter 是一个功能丰富的 UI 开发框架,它允许开发者使用 Dart 语言来构建跨平台的移动、Web 和桌面应用。在 Flutter 的丰富组件库中,IconTheme 是一个用于设置应用中图标主题的小部件,…...

virtualbox虚拟机、centos7安装增强工具
文章目录 1. virtualBox语言设置2. 设置终端启动快捷键3. 添加virtualbox 增强工具4. 设置共享文件夹 1. virtualBox语言设置 virtualbox -> file -> perferences -> language ->选择对应的语言 -> OK virtualbox -> 管理 -> 全局设定 -> 语言 -> …...

Kotlin 泛型
文章目录 定义泛型属性泛型函数泛型类或接口 where 声明多个约束泛型具体化in、out 限制泛型输入输出 定义 有时候我们会有这样的需求:一个类可以操作某一类型的对象,并且限定只有该类型的参数才能执行相关的操作。 如果我们直接指定该类型Intÿ…...
)
Tomcat 面试题(一)
1. 简述什么是Tomcat ? Tomcat是一个开源的Java Servlet容器,它实现了Java Servlet和JavaServer Pages (JSP)技术,提供了一个运行Java Web应用程序的平台。Tomcat由Apache软件基金会维护,并广泛用于开发和部署Web应用程序。 Tom…...

跟踪一个Pytorch Module在训练过程中的内存分配情况
跟踪一个Pytorch Module在训练过程中的内存分配情况 代码输出 目的:跟踪一个Pytorch Module在训练过程中的内存分配情况 方法: 1.通过pre_hook module的来区分module的边界 2.通过__torch_dispatch__拦截所有的aten算子,计算在该算子中新创建tensor的总内存占用量 3.通过tensor…...
空间方法×3))
LeetCode 2965.找出缺失和重复的数字:小数据?我选择暴力(附优化方法清单:O(1)空间方法×3)
【LetMeFly】2965.找出缺失和重复的数字:小数据?我选择暴力(附优化方法清单:O(1)空间方法3) 力扣题目链接:https://leetcode.cn/problems/find-missing-and-repeated-values/ 给你一个下标从 0 开始的二维…...
)
【运维】VMware Workstation 虚拟机内无网络的解决办法(或许可行)
【使用桥接模式】 【重置网络】 这个过程涉及管理Linux系统中的网络驱动程序和网络管理工具。以下是每个步骤的详细解释: 卸载网络驱动模块: sudo rmmod e1000 sudo rmmod e1000e sudo rmmod igb这些命令使用 rmmod(remove moduleÿ…...
如何使用Dora SDK完成Fragment流式切换和非流式切换
我想大家对Fragment都不陌生,它作为界面碎片被使用在Activity中,如果只是更换Activity中的一小部分界面,是没有必要再重新打开一个新的Activity的。有时,即使要更换完整的UI布局,也可以使用Fragment来切换界面。 何…...
低代码开发平台(Low-code Development Platform)的模块组成部分
低代码开发平台(Low-code Development Platform)的模块组成部分主要包括以下几个方面: 低代码开发平台的模块组成部分可以按照包含系统、模块、菜单组织操作行为等维度进行详细阐述。以下是从这些方面对平台模块组成部分的说明: …...

Java网络编程(上)
White graces:个人主页 🙉专栏推荐:Java入门知识🙉 🙉 内容推荐:Java文件IO🙉 🐹今日诗词:来如春梦几多时?去似朝云无觅处🐹 ⛳️点赞 ☀️收藏⭐️关注💬卑微小博主&a…...

Spring Kafka 之 @KafkaListener 注解详解
我们在开发的过程中当使用到kafka监听消费的时候会使用到KafkaListener注解,下面我们就介绍下它的常见属性和使用。 一、介绍 KafkaListener 是 Spring Kafka 提供的一个注解,用于声明一个方法作为 Kafka 消息的监听器 二、主要参数 1、topic 描述&…...
【量算分析工具-贴地距离】GeoServer改造Springboot番外系列九
【量算分析工具-概述】GeoServer改造Springboot番外系列三-CSDN博客 【量算分析工具-水平距离】GeoServer改造Springboot番外系列四-CSDN博客 【量算分析工具-水平面积】GeoServer改造Springboot番外系列五-CSDN博客 【量算分析工具-方位角】GeoServer改造Springboot番外系列…...
文件操作及vi)
【linux】(1)文件操作及vi
文件和目录的创建 创建文件 touch 命令:创建一个新的空文件。 touch filename.txtecho 命令:创建一个文件并写入内容。 echo "Hello, World!" > filename.txtcat 命令:将内容写入文件。 cat > filename.txt然后输入内容&…...
【5】MySQL数据库备份-XtraBackup - 全量备份
MySQL数据库备份-XtraBackup-全量备份 前言环境版本 安装部署下载RPM 包二进制包 安装卸载 场景分析全量备份 | 恢复备份恢复综合 增量备份 | 恢复部分备份 | 恢复 前言 关于数据库备份的一些常见术语、工具等,可见《MySQL数据库-备份》章节,当前不再重…...

数据治理-数据标准演示
数据字典 数据标准-数据字典 词根 数据标准-词根 业务字典映射 数据标准-业务字典映射 标准文档 数据标准-标准文档...
基于Chisel的FPGA流水灯设计
Chisel流水灯 一、Chisel(一)什么是Chisel(二)Chisel能做什么(三)Chisel的使用(四)Chisel的优缺点1.优点2.缺点 二、流水灯设计 一、Chisel (一)什么是Chise…...

LabVIEW齿轮调制故障检测系统
LabVIEW齿轮调制故障检测系统 概述 开发了一种基于LabVIEW平台的齿轮调制故障检测系统,实现齿轮在恶劣工作条件下的故障振动信号的实时在线检测。系统利用LabVIEW的强大图形编程能力,结合Hilbert包络解调技术,对齿轮的振动信号进行精确分析…...

Unity游戏接入TapTap登录,从后台配置到打包上线的完整避坑指南
Unity游戏接入TapTap登录的全流程避坑指南:从配置到上线的实战经验 在独立游戏开发领域,TapTap平台凭借其庞大的用户基础和便捷的登录系统,已成为许多开发者的首选接入方案。然而,从后台配置到最终打包上线的完整流程中࿰…...
)
告别串口线!用STM32CubeMX配置USB-CDC虚拟串口,实现与电脑免驱动通信(附Win7驱动安装指南)
STM32虚拟串口革命:USB-CDC免驱动通信全实战指南 嵌入式开发调试过程中,最令人头疼的莫过于频繁插拔串口线导致的接口松动、接触不良问题。传统串口调试不仅占用宝贵的UART资源,还常常因为物理连接问题浪费大量调试时间。本文将彻底改变这一局…...

如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案
如何5分钟掌握N_m3u8DL-RE:流媒体下载终极解决方案 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE …...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...

抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播
抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

技术视角:Sketchfab数据提取工具深度解析3D模型下载机制
技术视角:Sketchfab数据提取工具深度解析3D模型下载机制 【免费下载链接】sketchfab sketchfab download userscipt for Tampermonkey by firefox only 项目地址: https://gitcode.com/gh_mirrors/sk/sketchfab 在WebGL技术日益成熟的今天,Sketch…...

Mantic.sh:Bash脚本实现的终端命令自动化与效率提升工具
1. 项目概述:一个为开发者打造的终端效率工具如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那你肯定对效率工具有着近乎偏执的追求。从cd到ls,从grep到awk,我们依赖这些…...

TPU柔性材料3D打印GoPro车载支架:从减震原理到实战拍摄全指南
1. 项目概述与设计思路我一直对第一人称视角(FPV)拍摄很着迷,尤其是那种能贴着地面、模拟小车视角疾驰的画面,动态感和沉浸感是手持拍摄无法比拟的。市面上的运动相机车载支架要么是硬连接,颠簸起来画面抖动得厉害&…...

I2C地址冲突全解析:从原理到实战的嵌入式系统设计指南
1. I2C地址:嵌入式系统设计的“门牌号”与“交通规则”如果你玩过单片机或者树莓派,肯定对I2C不陌生。两根线,SDA和SCL,就能挂上一堆传感器、显示屏、扩展芯片,听起来简直是嵌入式开发的“万金油”。但真正上手后&…...
TransPrompt:结构化提示词工程,提升LLM应用开发效率
1. 项目概述:当提示词工程遇上结构化工具最近在折腾大语言模型应用开发的朋友,估计都绕不开一个核心痛点:如何高效、稳定地管理那些越来越复杂、越来越长的提示词(Prompt)。直接写在代码里?改起来麻烦&…...