基于Django的博客系统之用HayStack连接elasticsearch增加搜索功能(五)
上一篇:搭建基于Django的博客系统数据库迁移从Sqlite3到MySQL(四)
下一篇:基于Django的博客系统之增加类别导航栏(六)
功能概述
- 添加搜索框用于搜索博客。
需求详细描述
1. 添加搜索框用于搜索博客
- 描述: 在博客首页添加搜索框,用户可以通过关键词搜索博客文章。
- 功能要求:
- 搜索框位置:导航栏或页面顶部。
- 支持根据标题和内容进行搜索。
- 搜索结果显示匹配的博客列表。
- 用户故事:
- 作为用户,我希望能够通过搜索框快速找到感兴趣的博客文章。
技术结构
实现一个博客搜索功能,可以同时使用 Elasticsearch 和 MySQL 各自的优势。以下是如何区分和结合使用这两种技术的方法:
使用 MySQL 的部分
- 数据存储:
- 存储博客文章的基本信息,如标题、作者、发布时间、分类等。
- 存储用户信息、评论、标签等结构化数据。
- 基础查询和管理:
- 进行常规的 CRUD 操作,如创建、读取、更新、删除博客文章。
- 进行简单的过滤和排序,如按发布时间、作者、分类等查询文章。
使用 Elasticsearch 的部分
- 全文搜索:
- 存储和索引博客文章的全文内容,以支持全文搜索功能。
- 对用户搜索的关键词进行快速匹配,返回相关的文章列表。
- 复杂查询:
- 支持复杂的查询需求,如模糊搜索、布尔搜索、按相关性排序等。
- 支持自动补全、拼写纠错等高级搜索功能。
集成 MySQL 和 Elasticsearch
- 数据同步:
- 需要将 MySQL 中的博客文章数据同步到 Elasticsearch 中,以确保搜索功能能够使用最新的数据。
- 可以使用定时任务或实时数据同步机制来保持两者数据的一致性。例如,使用工具如 Logstash、Beats 或自定义的同步程序。
- 搜索接口设计:
- 提供一个统一的搜索接口,前端用户提交搜索请求时,后台从 Elasticsearch 中查询搜索结果。
- 查询到的搜索结果中包含文章的基本信息,从 Elasticsearch 返回文章的 ID,然后从 MySQL 中获取详细信息(如作者、评论等)。
实现步骤
要在 Django 博客应用中添加搜索框,以便用户可以搜索博客内容,可以按照以下步骤进行:
1. 安装 Django 搜索库
首先,确保你已经安装了 Django 搜索库。一个常用的选择是 django-haystack 库,它提供了与多个搜索引擎(如 Elasticsearch、Solr 和 Whoosh 等)集成的功能。
pip install django-haystack
2. 配置搜索引擎
选择并配置你想要使用的搜索引擎。例如,如果选择使用 Whoosh 搜索引擎,需要在 settings.py 文件中配置 Haystack 设置:
# settings.pyINSTALLED_APPS = [# 其他应用...'haystack',
]HAYSTACK_CONNECTIONS = {'default': {'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine','URL': 'http://localhost:9200/', # Elasticsearch 服务器的 URL'INDEX_NAME': 'haystack', # Elasticsearch 索引的名称},
}HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
3. 创建搜索索引类
为你的博客模型创建一个搜索索引类,告诉 Haystack 如何索引你的数据。假设你有一个名为 Post 的博客模型:
# search_indexes.pyfrom haystack import indexes
from .models import Postclass PostIndex(indexes.SearchIndex, indexes.Indexable):text = indexes.CharField(document=True, use_template=True)def get_model(self):return Post
在这个示例中,我们使用 text 字段来索引博客内容。你可以根据需要添加更多的字段。
4. 创建搜索模板
在你的博客模板文件夹中创建一个模板文件,用于显示搜索结果。这个模板将根据搜索结果显示匹配的博客文章。
<!-- templates/search/post_text.txt -->{{ object.title }}
{{ object.content }}
同步索引:运行 Django 的管理命令来创建或更新搜索索引。
python manage.py rebuild_index
5. 更新 URL 配置
将搜索视图添加到你的 URL 配置中,以便用户可以访问搜索页面并执行搜索。
# urls.pyfrom django.urls import path
from . import viewsurlpatterns = [# 其他 URL 配置...path('search/', views.SearchView.as_view(), name='search'),
]
6. 创建搜索视图
创建一个视图类来处理搜索请求,并将搜索结果呈现给用户。
from haystack.query import SearchQuerySetdef search_view(request):query = request.GET.get('q', '')results = SearchQuerySet().filter(content=query)return render(request, 'search_results.html', {'results': results})
7. 创建搜索模板
创建一个模板文件,用于显示搜索结果。在这个模板中,你可以根据需要定制搜索结果的展示方式。
<!-- templates/search.html -->{% for result in page.object_list %}<h3><a href="{{ result.object.get_absolute_url }}">{{ result.object.title }}</a></h3><p>{{ result.object.content }}</p>
{% empty %}<p>No results found.</p>
{% endfor %}{% if is_paginated %}<div class="pagination"><span class="step-links">{% if page.has_previous %}<a href="?q={{ query }}&page=1">« first</a><a href="?q={{ query }}&page={{ page.previous_page_number }}">previous</a>{% endif %}<span class="current">Page {{ page.number }} of {{ page.paginator.num_pages }}.</span>{% if page.has_next %}<a href="?q={{ query }}&page={{ page.next_page_number }}">next</a><a href="?q={{ query }}&page={{ page.paginator.num_pages }}">last »</a>{% endif %}</span></div>
{% endif %}
8. 创建搜索表单
最后,创建一个搜索表单,让用户输入搜索关键字并提交搜索请求。
<!-- templates/search_form.html --><form action="{% url 'search' %}" method="get"><input type="text" name="q" placeholder="Search..."><button type="submit">Search</button>
</form>
将搜索表单包含在你的博客页面中的适当位置,用户就可以使用它来搜索博客内容了。
这就是在 Django 博客应用中添加搜索框的基本步骤。根据你的需求,你可以进一步定制搜索功能,例如添加搜索结果的高亮显示、自定义搜索表单字段等。
连接elasticsearch
具体参看这篇Windows安装ElasticSearch版本7.17.0
要连接 Elasticsearch,你需要配置 Django Haystack 的后端为 Elasticsearch 后端。下面是一些步骤:
- 安装 Elasticsearch:首先确保你已经安装了 Elasticsearch 并且它正在运行。你可以从 Elasticsearch 的官方网站上下载并安装它。
- 安装 Haystack:确保你已经安装了 Django Haystack。你可以使用 pip 进行安装:
pip install django-haystack。 - 安装 Elasticsearch 后端:你需要安装与 Elasticsearch 兼容的 Haystack 后端。通常情况下,你需要安装
elasticsearch-dsl,它是 Elasticsearch 的 Python 客户端库。你可以使用 pip 进行安装:pip install elasticsearch-dsl。 - 配置 Haystack 设置:在 Django 项目的
settings.py文件中,配置 Haystack 设置以使用 Elasticsearch 后端。这包括指定 Elasticsearch 的主机和端口等信息。
HAYSTACK_CONNECTIONS = {'default': {'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine','URL': 'http://localhost:9200/', # Elasticsearch 服务器的 URL'INDEX_NAME': 'haystack', # Elasticsearch 索引的名称},
}
- 建立索引:运行
python manage.py rebuild_index命令来建立你的模型的搜索索引。这将会在 Elasticsearch 中创建对应的索引。 - 运行你的应用程序:现在你的 Django 应用程序应该能够连接到 Elasticsearch 并使用它来进行全文搜索了。
问题和解决
报错 from django.utils.datetime_safe import date, datetime ModuleNotFoundError: No module named 'django.utils.datetime_safe'
分析解决:
在 Django 3.2 中,django.utils.datetime_safe 模块已被移除。这个模块提供了在处理日期和时间时的安全操作,以防止由于 datetime 和 date 对象的类型不同而导致的一些问题。
如果你的代码中依赖了 django.utils.datetime_safe 模块,你可以尝试以下替代方法:
- 直接使用 datetime 和 date:在绝大多数情况下,直接使用内置的
datetime和date类应该没有问题。只要确保在处理日期和时间时,类型的转换和比较是正确的即可。 - 在需要的地方进行转换:如果你的代码在某些情况下需要确保
datetime和date对象的类型一致,你可以手动进行转换。比如,使用timezone.now()获取当前时间,使用datetime.strptime()将字符串转换为datetime对象等。 - 更新依赖:如果你使用的是第三方库,可以尝试更新这些库的版本,看看是否有与 Django 3.2 兼容的版本。
确保你的代码不再依赖于 django.utils.datetime_safe 模块后,就可以解决这个错误了。切换为elasticsearch连接。报错如下 raise MissingDependency( haystack.exceptions.MissingDependency: The 'elasticsearch5' backend requires the installation of 'elasticsearch>=5.0.0,<6.0.0'. Please refer to the documentation.

修改settings.py中HAYSTACK_CONNECTIONS连接的Elasticsearch版本为8.x,如下:
HAYSTACK_CONNECTIONS = {'default': {'ENGINE': 'haystack.backends.elasticsearch8_backend.Elasticsearch8SearchEngine','URL': 'http://localhost:9200/','INDEX_NAME': 'myblog',},
}
报错ModuleNotFoundError: No module named 'haystack.backends.elasticsearch8_backend'
原因:Haystack中没有提供一个专门用于Elasticsearch 8.x 的后端引擎。使用 haystack.backends.elasticsearch7_backend.Elasticsearch7SearchEngine 就可以支持 Elasticsearch 7.x。
重新安装elasticsearch版本号为7.17。见这篇文章
卸载不需要的驱动
pip uninstall elasticsearch
pip uninstall elasticsearch-dsl
安装需要的驱动
pip install elasticsearch==7.17.0pip install elasticsearch-dsl==7.4.1
再次调用启动搜索index命令python manage.py rebuild_index
报错ImportError: cannot import name 'datetime_safe' from 'django.utils'
原因:Django 3.2 中移除了 django.utils.datetime_safe 模块引起的。Haystack 应该已经更新以适应 Django 3.2。
执行命令下载haystack支持django5.0.7
pip install git+https://github.com/django-haystack/django-haystack.git
再次调用启动搜索index命令
python manage.py rebuild_index
运行成功。效果如下:

调用http://localhost:8000/search/?q=%E6%AF%94%E4%BC%AF后,结果如下:

分析原因elasticsearch的index有问题。
用tree /F命令获取全文件夹下的文件格式表。
通过下面命令获取当前elasticsearch里面的index:
Invoke-WebRequest -Uri "http://localhost:9200/_cat/indices?v"
在post_text.txt里面添加一段index的指向
<!-- templates/search/indexes/blog/post_text.txt -->
执行index命令python manage.py rebuild_index
执行成功,如下:

postman调用apihttp://localhost:9200/myblog结果返回成功:
{"myblog": {"aliases": {},"mappings": {"properties": {"content": {"type": "text","analyzer": "snowball"},"django_ct": {"type": "keyword"},"django_id": {"type": "keyword"},"id": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"text": {"type": "text","analyzer": "snowball"},"title": {"type": "text","analyzer": "snowball"}}},"settings": {"index": {"max_ngram_diff": "2","routing": {"allocation": {"include": {"_tier_preference": "data_content"}}},"number_of_shards": "1","provided_name": "myblog","creation_date": "1716964128114","analysis": {"filter": {"haystack_ngram": {"type": "ngram","min_gram": "3","max_gram": "4"},"haystack_edgengram": {"type": "edge_ngram","min_gram": "2","max_gram": "15"}},"analyzer": {"edgengram_analyzer": {"filter": ["haystack_edgengram","lowercase"],"tokenizer": "standard"},"ngram_analyzer": {"filter": ["haystack_ngram","lowercase"],"tokenizer": "standard"}}},"number_of_replicas": "1","uuid": "1GzZNjZzSmOtmFdLuGWhvw","version": {"created": "7170099"}}}}
}
搜索index
修改搜索视图以获取匹配的博客文章 ID,并从 MySQL 中获取详细信息:
# blog/views.py
from django.shortcuts import render
from haystack.query import SearchQuerySet
from .models import BlogPost
from .forms import BlogSearchFormdef search(request):form = BlogSearchForm(request.GET)results = []if form.is_valid():# 从 Elasticsearch 获取匹配的博客文章 IDsqs = form.search()matched_ids = [result.pk for result in sqs]# 从 MySQL 数据库中获取详细信息results = BlogPost.objects.filter(id__in=matched_ids)return render(request, 'search_results.html', {'form': form, 'results': results})
访问’http://localhost:8000’输入搜索growing,访问’http://localhost:8000/search/?q=growing’,得到结果如下:

相关文章:
基于Django的博客系统之用HayStack连接elasticsearch增加搜索功能(五)
上一篇:搭建基于Django的博客系统数据库迁移从Sqlite3到MySQL(四) 下一篇:基于Django的博客系统之增加类别导航栏(六) 功能概述 添加搜索框用于搜索博客。 需求详细描述 1. 添加搜索框用于搜索博客 描…...

开源VS闭源:大模型发展路径之争,你站哪一派?
文章目录 引言一、数据隐私1.1开源大模型的数据隐私1.2 闭源大模型的数据隐私1.3 综合考量 二、商业应用2.1 开源大模型的商业应用2.2 闭源大模型的商业应用2.3 商业应用的综合考量 三、社区参与3.1 开源大模型的社区参与3.2 闭源大模型的社区参与3.3 综合考量 结论 引言 在人…...

Python | Leetcode Python题解之第115题不同的子序列
题目: 题解: class Solution:def numDistinct(self, s: str, t: str) -> int:m, n len(s), len(t)if m < n:return 0dp [[0] * (n 1) for _ in range(m 1)]for i in range(m 1):dp[i][n] 1for i in range(m - 1, -1, -1):for j in range(n …...
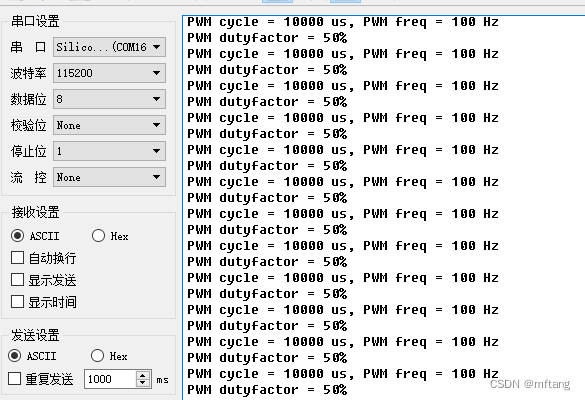
STM32高级控制定时器应用之检测输入PWM周期和占空比
目录 概述 1 PWM 输入模式 1.1 原理介绍 1.2 应用实例 1.3 示例时序图 2 使用STM32Cube配置工程 2.1 软件环境 2.2 配置参数 2.3 生成项目文件 3 功能实现 3.1 PWM占空比函数 3.2 输入捕捉回调函数 4 功能测试 4.1 测试软件框架结构 4.2 实验实现 4.2.1 测试实…...

[AI Google] 三种新方法利用 Gemini 提高 Google Workspace 的生产力
Workspace 侧边栏中的 Gemini 现在将使用 Gemini 1.5 Pro,新的 Gemini for Workspace 功能即将登陆 Gmail 移动应用,等等。 Gemini for Google Workspace 帮助个人和企业更好地利用 Google 应用——从在 Gmail 中撰写邮件到在 Sheets 中组织项目计划。过…...

【U-Net验证】逐元素乘积将特征投射到极高维隐式特征空间的能力
写在前面:本博客仅作记录学习之用,部分图片来自网络,如需使用请注明出处,同时如有侵犯您的权益,请联系删除! 文章目录 前言网络结构编码结构解码结构代码 实验实验设置w/o-ReLU的性能比较with-ReLU的性能比…...

快团团大团长帮卖如何导出单个团购的订单?免费教程教你怎么做!
一、小程序端如何导出单个团购的订单? 进入团购页面,在订单管理——订单导出中,点击订单数据表格,可导出到邮箱,或通过在浏览器中查看下载链接 二、电脑端如何导出单个团购的订单? 1、如何自定义选择订单信…...
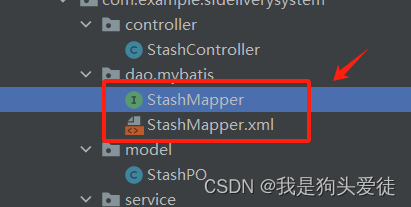
services层和controller层
services层 我的理解,services层是编写逻辑代码语句最多的一个层,非常重要,在实际的项目中,负责调用Dao层中的mybatis,在我的项目中它调用的是这两个文件 举例代码如下 package com.example.sfdeliverysystem.servic…...

Pycharm编辑器下自定义模块导入报错:no module named问题
相信很多使用pycharm 社区版编写python 程序的初学者都会遇到这样一个看似简单但是一时半刻找不到解决头绪的问题: 在同个目录下导入自己编写的模块到主程序的过程中,直接import的时候会报错:ModuleNotFoundError。 通过各种方法尝试以后还是…...
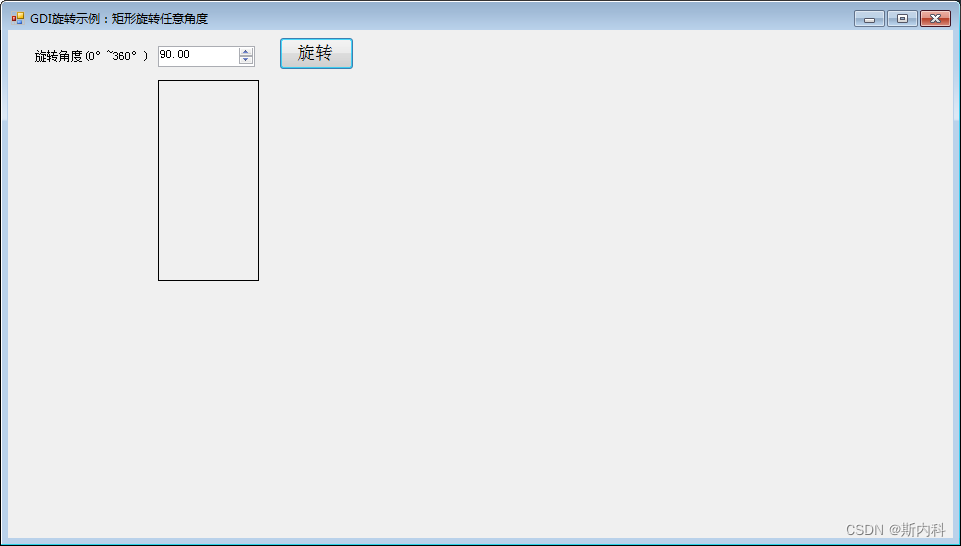
C#使用GDI对一个矩形进行任意角度旋转
C#对一个矩形进行旋转GDI绘图,可以指定任意角度进行旋转 我们可以认为一张图片Image,本质就是一个矩形Rectangle,旋转矩形也就是旋转图片 在画图密封类 System.Drawing.Graphics中, 矩形旋转的两个关键方法 //设置旋转的中心点 public v…...

打印机的ip不同且连不上
打印机的ip不同且连不上 1.问题分析2.修改网段3.验证网络 1.问题分析 主要是打印机的网段和电脑不在同一个网段 2.修改网段 3.验证网络...
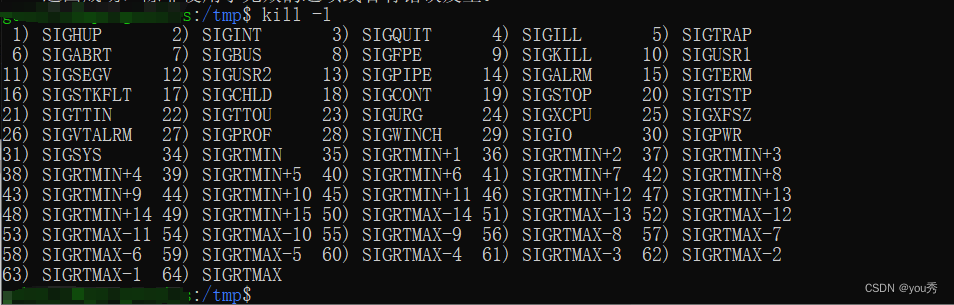
关于linux程序的查看、前台运行、后台运行、杀死的管理操作。
前言 在Linux中, 程序(program)是放在磁盘上的程序,是不会执行的。 进程(process)是程序被触发,从而加载到内存中的,会被CPU随机执行。 Linux中,有非常多的进程在实时运…...

STM32作业设计
目录 STM32作业设计 STM32作业实现(一)串口通信 STM32作业实现(二)串口控制led STM32作业实现(三)串口控制有源蜂鸣器 STM32作业实现(四)光敏传感器 STM32作业实现(五)温湿度传感器dht11 STM32作业实现(六)闪存保存数据 STM32作业实现(七)OLED显示数据 STM32作业实现(八)触摸按…...
PHPSTOM配置Laradock,xdebug,phpunit
原理图: 片面理解: phpstorm启用一个9000端口,这个端口用来接收到信息后,启用xdebug功能。服务器端(docker), 当客户端访问laravel项目域名后, 并读取xdebug.ini的配置, 把调试的请求数据, 向配置里面的端口发送消息, 配置里面的端…...

使用Java进行数据分析和处理:应用在实际业务场景中的技术
在当今数据驱动的时代,数据分析和处理已经成为各行各业中不可或缺的一部分。Java作为一种广泛应用于企业级开发的编程语言,也在数据领域展现出了强大的能力。本文将探讨如何使用Java进行数据分析和处理,以及在实际业务场景中应用的技术。 ##…...

C++中的List
摘要 C 标准库中的 std::list 是一种双向链表容器,它允许在常数时间内进行插入和删除操作,每个元素包含一个指向前一个和后一个元素的指针。这给我们开发提供了高效的插入和删除操作。 引入头文件 要使用 std::list,需要包含头文件 <li…...

go map 如何比较两个 map 相等
go map 如何比较两个 map 相等 都为 nil非空、长度相等,指向同一个 map 实体对象相应的 key 指向的 value 相等 直接将使用 map1 map2 是错误的。这种写法只能比较 map 是否为 nil。因此只能是遍历map 的每个元素,比较元素是否都是深度相等。...

牛客网刷题 | BC108 反斜线形图案
目前主要分为三个专栏,后续还会添加: 专栏如下: C语言刷题解析 C语言系列文章 我的成长经历 感谢阅读! 初来乍到,如有错误请指出,感谢! 描述 KiKi学习了循环&am…...

数据的表示和运算
目录 一.各进制间的相互转换 1.各进制转化为10进制 2.二进制和八进制,十六进制之间地相互转化 3.十进制转换为其他进制 二.BCD码(Binary-Coded Decimal,用二进制编码的十进制) 1.8421码 2.余3码 3.2421码 三.无符号整数 …...
【爬虫工具】油管视频批量采集软件
一、背景介绍 1.1 爬取目标 我用Python独立开发了一款爬虫软件,作用是:通过搜索关键词采集ytb的搜索结果,包含14个关键字段:关键词,页码,视频标题,视频id,视频链接,发布时间,视频时长,频道名称,频道id,频道链接,播放数,点赞数,评…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

JVM调优实战:让你的服务性能提升50%
一、背景 线上一个核心订单服务,QPS 3000左右,经常出现接口超时告警。监控显示: 平均RT: 180ms(要求<100ms)Full GC频率: 每天20次,每次STW 1.5sCPU使用率: 峰值85%服务规格: 8C16G,堆内存…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

利用OCI免费套餐构建高可用Kubernetes集群实战指南
1. 项目概述:在免费云上构建企业级K8s集群最近在技术社区里,一个名为“nce/oci-free-cloud-k8s”的项目引起了我的注意。这个标题乍一看有点“黑话”的味道,但拆解开来,它指向了一个非常具体且极具吸引力的场景:利用Or…...
)
中文长文本语音崩溃?ElevenLabs API超时/截断/静音突变?20年语音架构师紧急发布的6行容错重试+分段重对齐代码(已验证10万+字符稳定输出)
更多请点击: https://intelliparadigm.com 第一章:中文长文本语音崩溃的根因诊断与现象复现 中文长文本语音合成(TTS)在处理超长段落(如 >3000 字)时频繁出现进程中断、内存溢出或静音输出,…...

Biomni项目解析:大语言模型与生物医学知识图谱融合实践
1. 项目概述:当大语言模型遇见生物医学知识图谱最近在探索如何让大语言模型(LLM)在专业领域,特别是生物医学这种信息密集、关系复杂的领域,变得更“靠谱”一点。相信很多同行都遇到过类似的问题:直接问Chat…...

揭秘Midjourney“树胶重铬酸盐”风格指令:3步精准触发古典印相质感,92%用户从未用对的隐藏参数组合
更多请点击: https://intelliparadigm.com 第一章:树胶重铬酸盐工艺的光学原理与数字映射本质 树胶重铬酸盐(Gum Bichromate)工艺是19世纪末发展起来的经典光敏印相技术,其核心光学原理基于重铬酸盐在紫外光照射下发生…...

如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南
如何永久保存你的微信聊天记录?WeChatExporter开源工具完整指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机丢失、微信重装后珍贵聊天…...

大语言模型长上下文建模:从注意力优化到Mamba架构的工程实践
1. 项目概述:为什么长上下文建模是LLM的“圣杯”?如果你在过去一年里深度使用过任何主流的大语言模型,无论是ChatGPT、Claude还是开源的Llama、Qwen,一个共同的痛点一定让你印象深刻:“它好像不记得我们之前聊了什么”…...