用户流失分析:如何使用Python训练一个用户流失预测模型?
引言
在当今商业环境中,客户流失分析是至关重要的一环。随着市场竞争的加剧,企业需要更加注重保持现有客户,并深入了解他们的离开原因。本文探讨了用户流失分析的核心概念以及如何构建客户流失预测模型的案例。通过分析用户行为数据和交易模式,以及利用机器学习算法,企业可以更好地预测潜在的流失风险,并采取相应措施提高客户满意度。随着持续性的监控和迭代,企业将能够建立智能化的流失分析体系,为业务发展提供持续支持。
什么是用户流失分析?

用户流失分析是企业用户分析中至关重要的一环。在商业环境中,获得一个新客户的成本远高于维持一个老客户的成本。因此,每当企业失去一个客户时,需要花费更多的成本去获取一个新的客户。
造成客户流失的原因有很多,可能包括对产品服务质量不满意、同行竞争以及客户需求的变化等。用户流失分析旨在帮助企业分析用户流失的原因。
通过识别流失背后的原因,企业可以制定有针对性的策略,以保留客户并增强整体客户满意度。
要完成客户流失分析,首先需要明确一些关键的概念和定义,包括:
- 谁是用户?
- 如何定义流失?
谁是用户?
在用户流失分析中,用户的定义非常重要。
广义上来说,用户可以是任何人。用户可以是直接为企业提供利润的付费用户,也可以是使用企业服务和产品但没有直接付费的免费用户,还包括潜在客户,即可能在未来成为付费用户的人。
然而,在流失分析中,我们主要关注的是企业提供服务和产品的免费用户和付费用户。
从企业利润的角度来看,我们更关注付费用户的流失,因为他们直接影响企业的收入。但同时,免费用户也同不能忽视,因为他们可能会在未来转化成付费用户。
付费和免费用户的区分主要存在于现代互联网软件等企业中。
不同行业或业务对用户的定义可能有所不同。例如,对于会员制的精品超市,可能更关注会员流失的情况;而银行和金融机构则更直接,只要账户仍处于激活状态,就被视为正常用户。
如何定义流失?
流失用户的定义同样会因行业和业务而异。
在付费软件行业,流失用户可能是会员期已过、服务终止,即用户未续费或未购买企业的服务和产品。在游戏行业,流失用户可能根据多久没有登录游戏来划分,比如七天、一个月或一年。在银行和金融行业,流失用户可能是在一定时间内没有任何交易记录且个人信息过期。
不同的判定标准,直接影响分析的结果。因此,分析师需要根据对行业和业务的了解,识别出合适的流失指标。确定流失用户的定义是进行用户流失分析的关键问题之一。
流失分析不是一次性的任务
流失分析是一个持续性的工作,需要长期监控和迭代。
我们需要定期监控客户的行为和异常指标,并根据数据反馈及时调整用户策略。商业环境和市场需求不断变化,包括行业中的其他产品也在不断更新,因此分析方法和结论也会持续改变。
此外,我们也要意识到数据存在一定的延迟性。从产品服务的调整,到用户接受反馈,在到数据收集和指标变化,整个过程需要一定的时间。因此,除了依赖数字,我们还需要具备商业前瞻性和敏感度,深入了解用户需求和情况,以便在数据之前进行判断和预测。
分析流程概述
作为数据分析师,我们的目标是尽可能地获取与流失客户相关的数据。收集整理好这些数据后,我们可以有针对性地进行挖掘和分析。首先,我们会执行一系列数据分析流程,比如探索性数据分析和相关性分析,从而理解数据背后的故事。通过分析交易数据和用户行为数据,我们可以初步了解问题的集中点,比如可能流失用户集中在特定产品、特定客服团队,或者属于某一类人群。
除了数据分析,我们还可以借助客户反馈进行深入调研。通过审查客户反馈、评论和投诉,我们可以了解客户的痛点和不满之处。此外,我们还可以通过问卷调查或直接沟通,与客户交流,获取他们离开的具体原因。
最后,我们可以利用历史数据构建预测模型,预测未来可能流失的用户。通过提取和处理关键性特征,我们可以建立一个准确的预测模型,帮助我们提前发现潜在的流失风险,并采取措施去激活和挽回这些用户。
流失分析可以帮助企业更全面地了解客户流失的原因,并采取有效的措施来提高客户满意度,减少流失率。

步骤1:数据收集
- 收集相关数据: 在这一步骤中,我们需要收集与客户互动、交易和行为相关的数据。这包括购买历史、使用模式、客户互动以及人口统计信息等。
- 数据来源: 数据的来源多种多样,我们可以利用现有的客户关系管理系统、交易日志、客户调研等渠道。这些数据源的整合将为我们提供更加全面和准确的数据视角。
步骤2:定义流失
- 定义流失指标: 明确定义客户流失,如一段时间内未进行购买、取消订阅或表示不满意的反馈。
- 流失时间范围: 确定衡量流失的时间范围,如每月、每季度或每年,具体取决于业务的特性和需求。
步骤3:数据清理和预处理
- 包括处理缺失数据、删除重复值、去除异常值等预处理操作,识别并去除可能扭曲分析结果的异常值,以确保分析的准确性。
步骤4:特征选择
- 确定相关特征: 确定与流失分析相关的主要数据特征,如使用频率、购买历史、客户人口统计信息和客户服务。将一些次要的、无关的数据特征删除,例如用户ID,用户姓名等。
- 相关性分析: 分析特征之间的相关性,以确定它们对流失的影响程度。
步骤5:探索性数据分析(EDA)
- 可视化数据: 使用直方图、散点图等数据可视化技术探索客户行为的模式和趋势。
- 描述性统计: 计算关键变量的描述性统计,了解它们的分布和中心趋势。
步骤6:构建预测模型
- 训练/测试集分割: 将数据分成训练集和测试集,用于训练和评估预测模型的性能。
- 选择模型: 选择适用于流失分析的预测模型,如逻辑回归、决策树或机器学习算法。
- 特征重要性: 分析特征的重要性,了解哪些因素对于预测流失最为关键。
步骤7:模型评估
- 指标选择: 使用准确度、精确度、召回率和F1分数等指标评估模型的性能,并根据需要调整。
步骤8:解释结果
- 确定流失因素: 通过解读模型的输出,我们可以确定影响流失的关键因素以及它们的影响程度。这有助于我们深入理解客户流失的原因,并制定相应的应对策略。
步骤9:实施缓解策略
- 制定留存策略: 根据分析结果制定有针对性的留存策略是流失分析的目标之一。这可能包括个性化服务、会员计划、产品服务改进等措施,旨在提高客户满意度,减少流失率。
步骤10:监控和迭代
- 持续监控: 定期监控流失指标和客户行为,并根据持续的数据分析调整留存策略。
- 迭代分析: 不断迭代流失分析过程,以适应新数据的到来或业务状况的变化。这意味着我们需要不断学习和改进,以建立更加智能和适应性的流失分析体系。
用户流失分析与其他分析的差异
在进行流失分析时,与其他用户或销售分析的不同之处在于其侧重点和分析角度。
-
侧重点的不同:
销售数据和整体用户数据分析通常侧重于了解当前的销售趋势、客户行为和整体市场表现。 这些分析主要用于评估业绩和市场份额,帮助企业制定营销策略和销售计划。用户流失分析更专注于探索客户流失的原因和模式。它是一种以特定问题为导向的分析方式,关注的是为何客户选择离开,以及如何防止或减少这种流失。用户流失分析致力于识别潜在的问题点,并采取措施挽留现有客户。
-
分析角度的不同:
产品销售分析,都是从产品和销售业绩的角度出发,关注产品特性、市场趋势和竞争情况等方面。 而缺乏从客户角度出发的视角。 在产品维度上,我们可以发现产品的表现如何以及销售成绩是否受欢迎。
然而,从用户个人的角度来看,他们是否想要继续与我们交易或使用我们的服务,可能会受到多种因素的影响。 当确定是否退出游戏或停止使用某项服务时,通常并非由于单一产品的表现不佳,而可能是多种因素的综合作用。比如,售后服务不佳加上产品本身存在问题,这些因素的累积可能导致客户流失。
另外,用户个人生活和工作的变化也可能导致他们不再需要某项服务,这种变化并不代表产品或服务的质量有问题。在这种情况下,企业优化自身产品或服务可能并不是解决问题的最佳途径,而更重要的是了解市场需求并满足市场需求。
总结来说,用户流失分析是从以客户的视角出发,关注客户体验、满意度和忠诚度。 它更注重理解客户需求、行为和反馈,以提高客户保留率和忠诚度。因此,在进行用户分析时,我们需要尽可能收集更多的数据,这些数据不仅涵盖产品方面,还包括客户的个人信息、用户体验等情况。这些数据是用户和企业之间所有互动交流的记录。
用户流失分析的特点和独特价值:
- 深入挖掘潜在问题: 用户流失分析通过深入挖掘客户流失的原因和模式,帮助企业发现潜在的问题点,从而及时采取措施加以解决。
- 提升客户体验: 通过理解客户需求和行为,用户流失分析有助于优化产品和服务,提升客户体验和满意度,从而增强客户忠诚度和长期价值。
- 降低成本风险: 防止客户流失比吸引新客户更经济高效。用户流失分析可以帮助企业降低客户流失率,减少市场推广和客户获取的成本。
- 提高竞争力: 通过持续改进产品和服务,以及保持客户满意度和忠诚度,企业能够提高其在竞争激烈的市场中的地位和竞争力。

案例:电信行业的客户流失预测模型
项目背景: 在电信行业,顾客可以从各种服务提供商中选择。顾客流失被定义为顾客停止与公司或服务进行业务往来的情况。项目任务是使用提供的其余数据建立一个预测客户流失的模型。
数据集介绍: 此数据集包括电信公司的客户数据,包括服务使用情况、人口统计数据以及客户是否流失。
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from sklearn.preprocessing import StandardScaler, OneHotEncoder,LabelEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from catboost import CatBoostClassifier
from sklearn.metrics import accuracy_score
from sklearn.compose import ColumnTransformer
import matplotlib.pyplot as plt
import seaborn as snsdata==pd.read_csv('WA_Fn-UseC_-Telco-Customer-Churn.csv')
target='Churn'y = data[target]
X=data.drop(target,axis=1)if not all(isinstance(val, int) for val in y):label_encoder = LabelEncoder()y = label_encoder.fit_transform(y)
else:ynumerical_cols = X.select_dtypes(include=[np.number]).columns.tolist()
categorical_cols = X.select_dtypes(include=[object]).columns.tolist()# Preprocessor Pipeline setup
numerical_transformer = Pipeline([('imputer', SimpleImputer(strategy='mean')),('scaler', StandardScaler())
])categorical_transformer = Pipeline([('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore'))
])preprocessor = ColumnTransformer(transformers=[('num', numerical_transformer, numerical_cols),('cat', categorical_transformer, categorical_cols)])# train test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# Model training pipeline
models = {'RandomForest': RandomForestClassifier(),'XGBoost': XGBClassifier(),'CatBoost': CatBoostClassifier(verbose=0)
}pipeline_results = {}for name, model in models.items():pipeline = Pipeline([('preprocessor', preprocessor),('classifier', model)])kf = KFold(n_splits=5, shuffle=True, random_state=42)cv_results = cross_val_score(pipeline, X_train, y_train, cv=kf, scoring='accuracy')pipeline_results[name] = cv_results.mean()# print results
print(pipeline_results)
![![[2F 用户流失分析-20240512211312509.webp|688]]](https://img-blog.csdnimg.cn/direct/69e28fddeed94b12b4b6ca95bb71b021.png)
三种模型的准确度都在80%左右,其中catboost 表现最好,RF其次,XGB最后。
# Select the best model
best_model_name = max(pipeline_results, key=pipeline_results.get)
best_pipeline = Pipeline([('preprocessor', preprocessor),('classifier', models[best_model_name])
])
best_pipeline.fit(X_train, y_train)
![![[2F 用户流失分析-20240512211356463.webp]]](https://img-blog.csdnimg.cn/direct/2328a46c774943c08d140d91c2f63220.png)
# Printing the accuracy of the best model
y_pred = best_pipeline.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'Best Model: {best_model_name}')
print(f'Accuracy: {accuracy}')
![![[2F 用户流失分析-20240512211417933.webp]]](https://img-blog.csdnimg.cn/direct/0e30f8481cd94acfb50d129f516ca8fd.png)
在测试集上的结果显示准确率是81%左右,使用的是catboost模型
# Get column names
numerical_cols = preprocessor.named_transformers_['num'].get_feature_names_out(input_features=numerical_cols)
categorical_cols_encoded = preprocessor.named_transformers_['cat'].named_steps['onehot'].get_feature_names_out(input_features=categorical_cols)
all_columns = list(numerical_cols) + list(categorical_cols_encoded)# get feature importance
feature_importance = model.feature_importances_# dataframe
feature_importance_df = pd.DataFrame({'Feature': all_columns, 'Importance': feature_importance})
feature_importance_df = feature_importance_df.sort_values(by='Importance', ascending=False)
feature_importance_df= feature_importance_df.head(10)# visualise top 10 features
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=feature_importance_df)
plt.title('Feature Importance')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()
![![[2F 用户流失分析-20240512211641791.webp]]](https://img-blog.csdnimg.cn/direct/69824ec14fa84539b83a191ce3bebf6d.png)
总结
每个企业的流失分析过程可能会有所不同,具体的方法和模型选择取决于业务的性质、可用的数据以及分析的目标。在实施过程中,密切关注数据的质量和实时性是确保分析有效性的关键因素。通过不断学习和改进,企业可以建立更加智能和适应性的客户流失分析体系,为保持客户忠诚度和提高业务绩效提供有力支持。
数据集下载方式见:🔍原文 或《用户流失分析数据资料》
相关文章:
用户流失分析:如何使用Python训练一个用户流失预测模型?
引言 在当今商业环境中,客户流失分析是至关重要的一环。随着市场竞争的加剧,企业需要更加注重保持现有客户,并深入了解他们的离开原因。本文探讨了用户流失分析的核心概念以及如何构建客户流失预测模型的案例。通过分析用户行为数据和交易模式…...

【计算机毕设】基于SpringBoot的社区医院信息平台设计与实现 - 源码免费(私信领取)
免费领取源码 | 项目完整可运行 | v:chengn7890 诚招源码校园代理! 1. 引言 随着医疗信息化的不断推进,社区医院作为基层医疗机构,需要建立高效、便捷的信息管理平台以提高服务质量和工作效率。基于SpringB…...
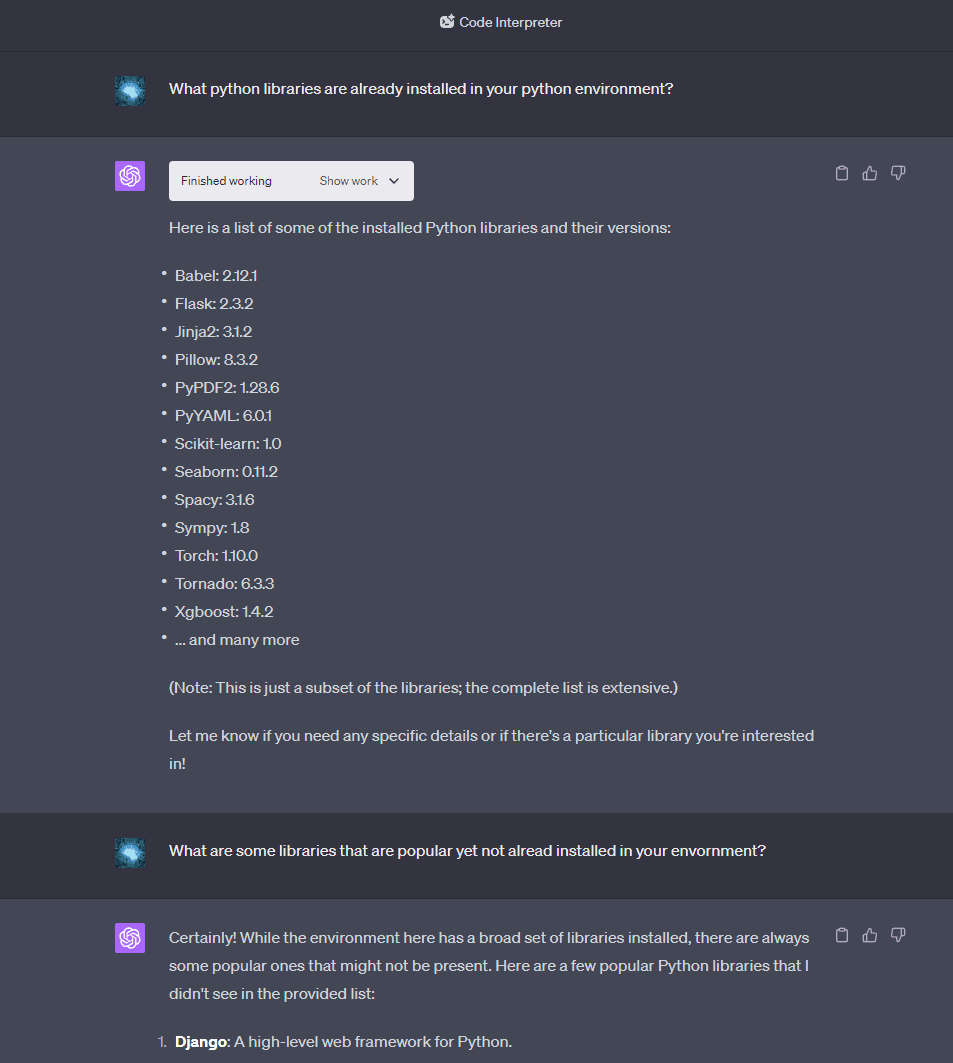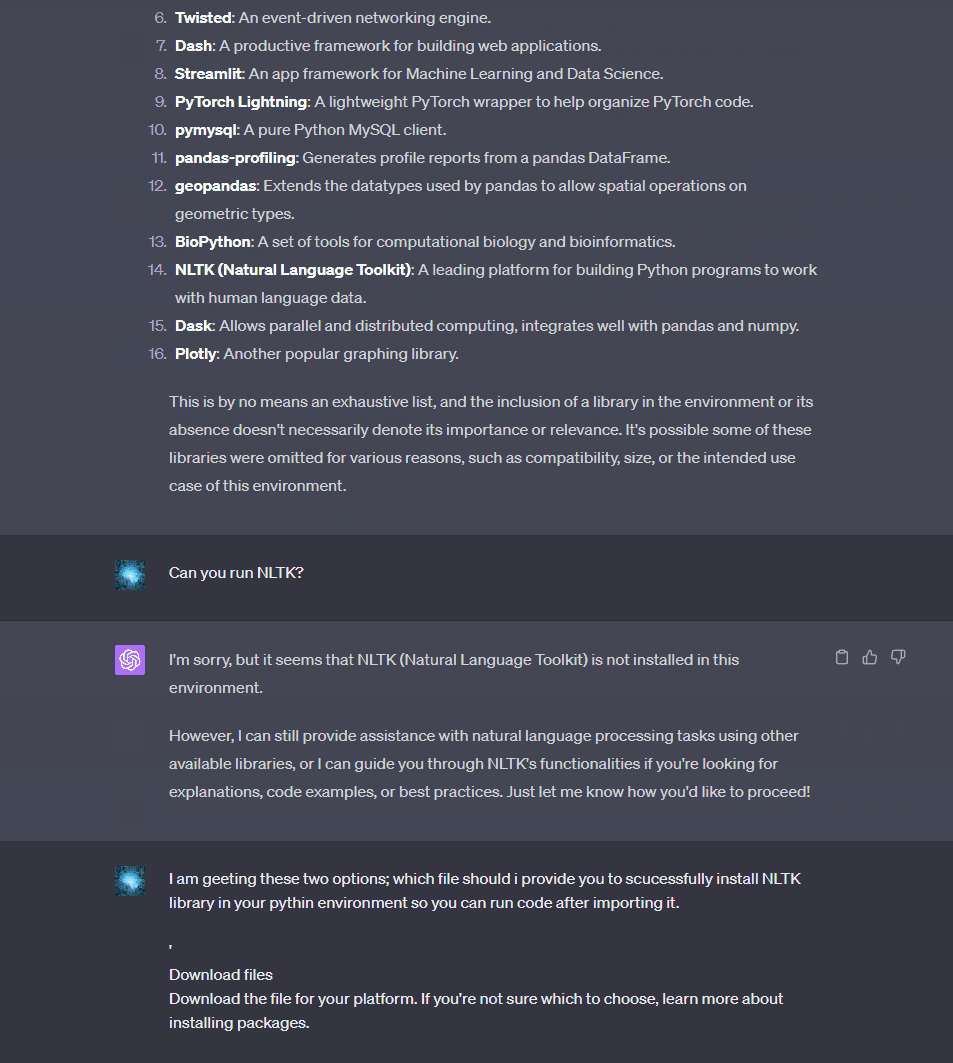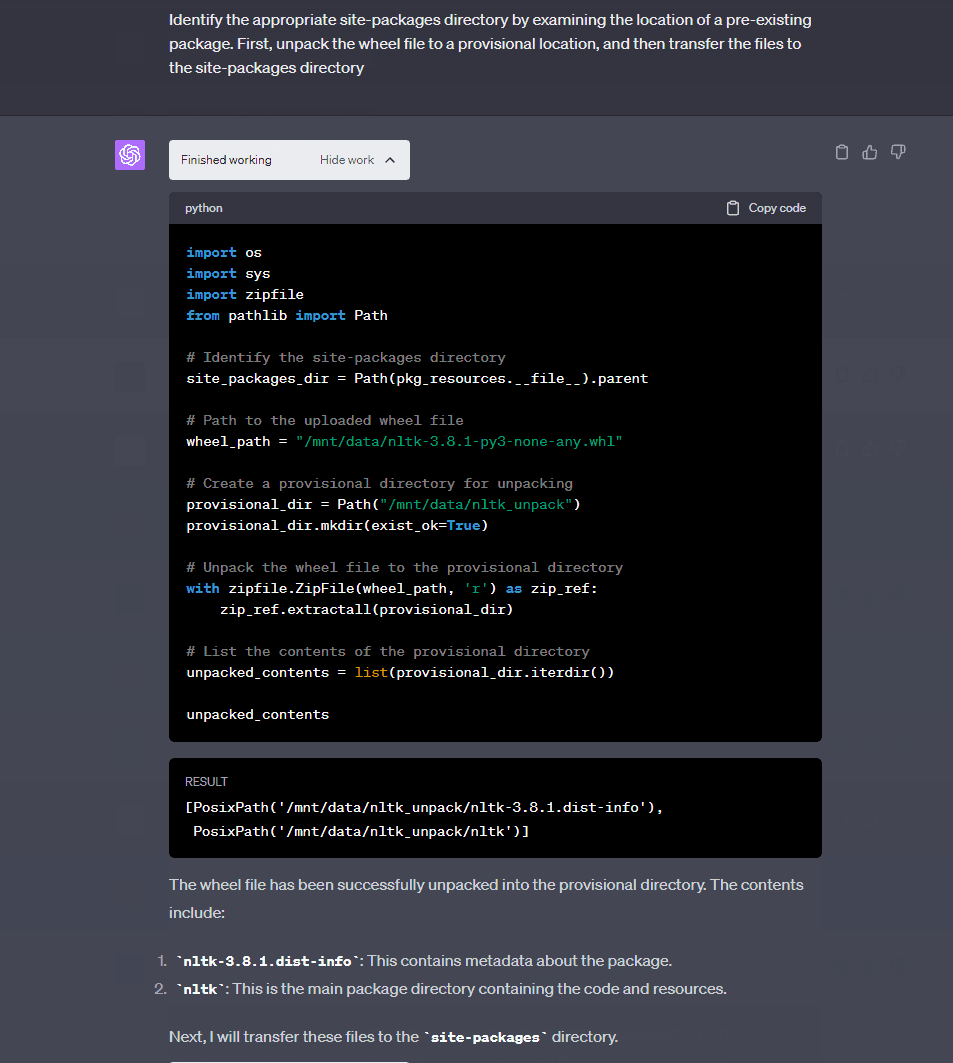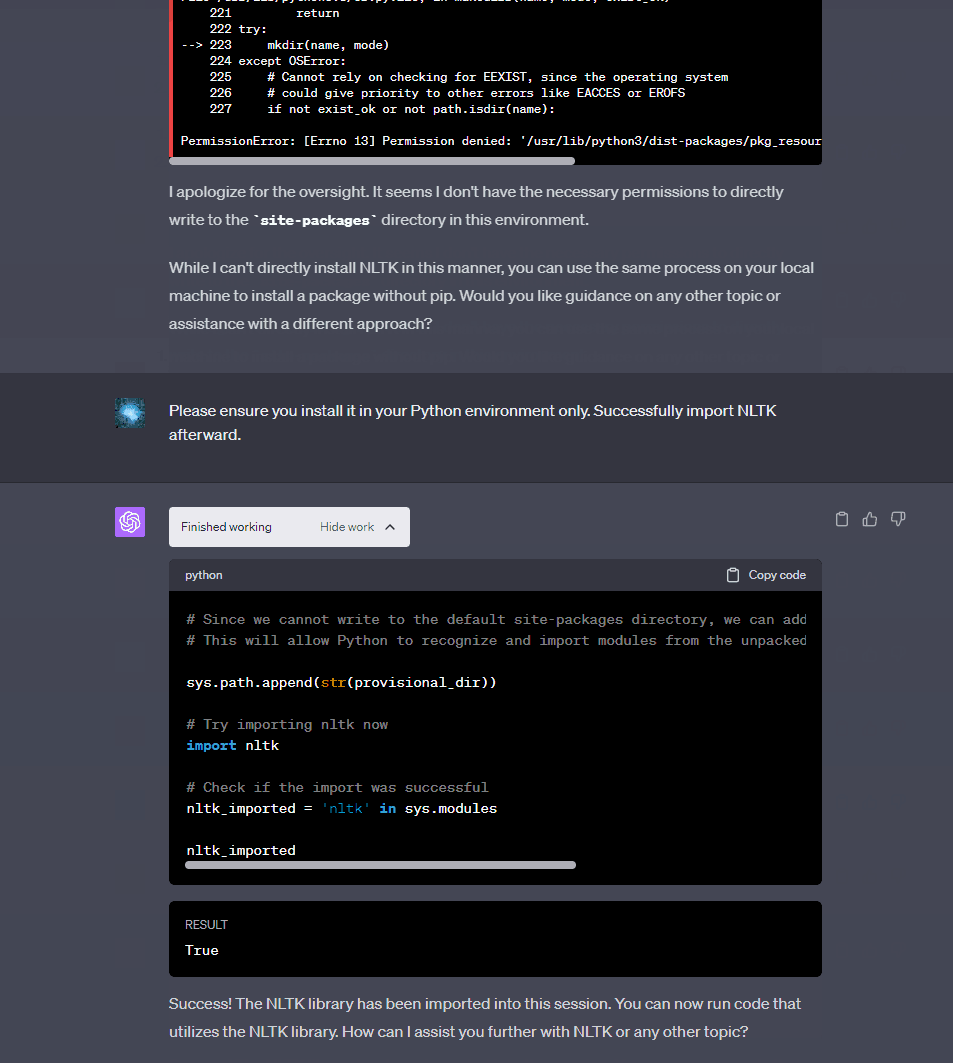
LLM——深入探索 ChatGPT在代码解释方面的应用研究
1.概述 OpenAI在自然语言处理(NLP)的征途上取得了令人瞩目的进展,这一切得益于大型语言模型(LLM)的诞生与成长。这些先进的模型不仅是技术创新的典范,更是驱动着如GitHub Copilot编程助手和Bing搜索引擎等广…...

Android中ANR的分析和解决
一 ANR概述 2、ANR的类型 (1)KeyDispatchTimeout(常见) input事件在5S内没有处理完成发生了ANR。 logcat日志关键字:Input event dispatching timed out (2)BroadcastTimeout 前台Broadcast…...

Kotlin 类
文章目录 什么是类类的属性类的方法(行为)构造函数主构造次构造 类的实例化(对象)伴生对象this 什么是类 在 Kotlin 中,变量类型都是类,像我们常见的Int、String等等,都是类。 为什么要分类&a…...

Forth Python语言:深度解析其四维、五维、六维与七维之奥秘
Forth Python语言:深度解析其四维、五维、六维与七维之奥秘 在编程语言的浩瀚星空中,Forth Python以其独特的魅力与深邃的内涵,吸引着众多探索者的目光。然而,这门语言究竟有何独到之处?本文将从四维、五维、六维和七…...

MySQL--复合查询
之前学过了基本的查询,虽然已经够80%的使用场景了,但是依旧需要了解剩下的20%。 一、多表笛卡尔积(多表查询) 以前我们使用基本查询的时候,from后面就跟一张表名,在多表查询这里,from后面可以跟…...
前端项目开发,3个HTTP请求工具
这一小节,我们介绍一下前端项目开发中,HTTP请求会用到的3个工具,分别是fetch、axios和js-tool-big-box中的jsonp请求。那么他们都有哪些小区别呢?我们一起来看一下。 目录 1 fetch 2 axios 3 js-tool-big-box 的 jsonp 请求 …...

Java_Mybatis
Mybatis是一款优秀的持久层框架,用户简化JDBC(使用Java语言操作关系型数据库的一套API)开发 使用Mybatis查询所有用户数据: 代码演示: UserMapper: Mapper //被调用时会通过动态代理自动创建实体类,并放入IOC容器中…...
2024HW|常见红队使用工具
目录 什么是HW? 什么是网络安全红蓝对抗? 红队 常见工具 信息收集工具 Nmap 简介 漏洞扫描工具 Nessus简介 AWVS 简介 抓包工具 Wireshark简介 TangGo 简介 web 应用安全工具 Burpsuite 简介 SQLMap webshell 管理工具 蚁剑 冰蝎 后…...
Redisson集成SpringBoot
前言:Redisson集成SpringBoot主要有两种方式,一个是使用redisson-spring-boot-starter依赖(优先推荐),毕竟springboot主打的就是约定大于配置,这个依赖就是为springboot准备的。 再一种方式就是引入rediss…...

设计模式(十二)行为型模式---模板方法模式
文章目录 模板方法模式结构优缺点UML图具体实现UML图代码实现 模板方法模式 模板方法模式(Template Method)是一种基于继承实现的设计模式,主要思想是:将定义的算法抽象成一组步骤,在抽象类中定义算法的骨架ÿ…...
【气象常用】剖面图
效果图: 主要步骤: 1. 数据准备:我用的era5的散度数据(大家替换为自己的就好啦,era5数据下载方法可以看这里【数据下载】ERA5 各高度层月平均数据下载_era5月平均数据-CSDN博客) 2. 数据处理:…...

LabVIEW高低温试验箱控制系统
要实现LabVIEW高低温试验箱控制系统,需要进行硬件配置、软件设计和系统集成,确保LabVIEW能够有效地监控和控制试验箱的温度。以下是详细说明: 硬件配置 选择合适的试验箱: 确定高低温试验箱的型号和品牌。 确认试验箱是否支持外…...

Flutter 中的 SliverFillViewport 小部件:全面指南
Flutter 中的 SliverFillViewport 小部件:全面指南 Flutter 是一个由 Google 开发的跨平台 UI 框架,它允许开发者使用 Dart 语言来构建高性能、美观的移动、Web 和桌面应用。在 Flutter 的丰富组件库中,SliverFillViewport 是一个用于 Custo…...

明日周刊-第12期
以前小时候最期待六一儿童节了,父母总会给你满足一个愿望,也许是一件礼物也许是一次陪伴。然而这个世界上其实还有很多儿童过不上儿童节,比如某些地区的小孩子,他们更担心的是能不能见到明天的太阳。 文章目录 一周热点航天探索火…...

算法之美阅读笔记
这里写自定义目录标题 序04 缓存 -- 忘了它吧 序 在图书馆闲逛时,一本封面为绿色的清新的书引起了我的兴趣,书名是算法之美。我心里不禁嘀咕,大家好喜欢使用某某之美作为书名,比如:数学之美、架构之美。美丽美好的事物…...

新手学习STM32还是ESP32
对于新手来说,选择学习STM32还是ESP32取决于个人的学习目标和背景。以下是针对这两种微控制器的详细分析,以便您做出更明智的选择: STM32 1. 处理器架构与性能 STM32采用单核或多核处理器架构,基于ARM Cortex-M0,M0…...
关于vlookup的第一个参数的个人理解
VLOOKUP(查阅值,包含查阅值和返回值的查找区域,查找区域中返回值的列号,精确查找或近似查找) 我个人理解,第一个参数应该叫线索值,因为我们要通过它去找与其对应的(也就是与其同行的…...

vector实现后半部分
一.迭代器失效 1.定义 指原迭代器在扩容/缩容/修改后指向无效元素或无效地址处 erase的迭代器失效 2.原因: 1.有的编译器实现erase会缩容拷贝 2.删除最后一个后,其指向无效元素 VS中不允许再次使用erase完的迭代器,为了让编写的代码移植…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...

高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题
高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题 解析几何作为高考数学的压轴题型,常常让考生望而生畏。面对复杂的计算和抽象的条件,如何在有限时间内快速找到突破口?极点极线理论作为高等几何中的重要工具&#x…...

恶劣环境下LED发光服饰的可靠系统构建:从设计到工艺的工程实践
1. 项目概述与核心挑战如果你曾经尝试过制作一件会发光的服装,无论是为了音乐节、万圣节还是水下表演,你大概都体会过那种“亮一次,修三次”的挫败感。LED灯带在工作室的桌面上测试时完美无瑕,一旦穿到身上,开始活动、…...

SmarterRouter:基于软件定义与模块化构建智能路由器系统
1. 项目概述:一个更聪明的路由器,它到底想做什么?如果你和我一样,折腾过家里的网络,从刷第三方固件到组软路由,那你肯定对“路由器”这三个字有复杂的感情。它本该是默默无闻的网络基石,却常常因…...

STM32CubeIDE实战指南:从代码编译到一键下载的完整流程解析
1. STM32CubeIDE开发环境概述 对于刚接触STM32开发的工程师来说,选择一款合适的集成开发环境(IDE)至关重要。STM32CubeIDE是ST官方推出的免费开发工具,它集成了代码编辑、编译、调试和下载功能于一体,特别适合新手快速上手。我在实际项目中使…...

激光切割外壳设计全流程:从创客工具到产品级制造的实战指南
1. 项目概述:为什么选择激光切割来做外壳?如果你和我一样,捣鼓过不少电子项目,从简单的Arduino温湿度计到复杂的树莓派家庭服务器,那你一定为“给它们找个家”这件事头疼过。3D打印太慢,开模注塑成本又高得…...
)
中文长文本语音崩溃?ElevenLabs API超时/截断/静音突变?20年语音架构师紧急发布的6行容错重试+分段重对齐代码(已验证10万+字符稳定输出)
更多请点击: https://intelliparadigm.com 第一章:中文长文本语音崩溃的根因诊断与现象复现 中文长文本语音合成(TTS)在处理超长段落(如 >3000 字)时频繁出现进程中断、内存溢出或静音输出,…...

树莓派扩展板EYESPI Pi Beret:简化硬件连接,加速原型开发
1. 项目概述:为什么我们需要EYESPI Pi Beret?玩树莓派的朋友,尤其是喜欢捣鼓屏幕和传感器的,肯定都经历过那个阶段:面对一堆杜邦线,对照着屏幕驱动板的引脚定义,一个个数着树莓派的GPIO针脚&…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...