R语言数据分析-xgboost模型预测
XGBoost模型预测的主要大致思路:
1. 数据准备
首先,需要准备数据。这包括数据的读取、预处理和分割。数据应该包括特征和目标变量。
步骤:
- 读取数据:从CSV文件或其他数据源读取数据。
- 数据清理:处理缺失值、异常值等。
- 数据转换:将因变量转换为因子类型,特征变量转换为适合模型输入的格式。
- 数据分割:将数据分为训练集和测试集,一般按照8:2的比例分割。
2. 特征工程
特征工程是提升模型性能的关键步骤。包括:
- 特征选择:选择对预测目标最重要的特征。
- 特征转换:将分类变量转换为数值变量(如独热编码)。
- 特征缩放:标准化或归一化特征值。
3. 转换数据格式
XGBoost需要输入数据为矩阵格式。因此,需要将数据转换为稀疏矩阵格式。
4. 训练模型
训练模型是整个过程的核心步骤。需要设置模型的参数,并使用训练数据进行训练。
关键点:
- 设置参数:包括树的深度、学习率、采样率等。
- 交叉验证:使用交叉验证找到最佳的迭代次数。
- 模型训练:使用最佳参数训练模型。
5. 模型调参
为了获得最佳模型性能,需要进行参数调优。常用的方法有网格搜索、随机搜索和贝叶斯优化。
6. 模型评估
使用测试集评估模型性能。常用的评估指标有准确率、精确率、召回率、F1分数等。
步骤:
- 生成预测值:使用测试集生成预测值。
- 计算评估指标:根据预测值和实际值计算模型性能指标。
7. 模型预测
使用训练好的模型对新数据进行预测。将新数据转换为与训练数据相同的格式,然后进行预测。
8. 模型保存和加载
训练好的模型可以保存到文件中,以便后续加载和使用。
步骤:
- 保存模型:将模型保存到文件中。
- 加载模型:从文件中加载模型,以便进行预测。
本文数据和代码案例
library(xgboost)
library(Metrics)
library(ggplot2)
library(readxl)
library(dplyr)# 读取数据
data <- read_excel("分析数据.xlsx")# 用每列的后一个值填充缺失值
data1 <- data %>%mutate(across(everything(), ~ ifelse(is.na(.), lead(.), .)))# 查看填充后的数据
head(data1)
# 分离特征和响应变量
X <- data1 %>% select(-ILI) # 移除ILI列
y <- data1$ILI# 划分训练集和测试集
set.seed(123) # 确保可重复性
train_indices <- sample(1:nrow(data1), size = 0.7 * nrow(data1))
train_data <- X[train_indices, ]
train_label <- y[train_indices]
test_data <- X[-train_indices, ]
test_label <- y[-train_indices]# 设置XGBoost参数
params <- list(booster = "gbtree",objective = "reg:squarederror",eta = 0.1# 训练模型
model <- xgb.train(params, dtrain, nrounds = 150)# 预测
predictions <- predict(model, dtest)# 输出评价指标
cat("R2:", R2, "\n")
cat("Adjusted R2:", adj_R2, "\n")
cat("RMSE:", RMSE, "\n")
cat("MSE:", MSE, "\n")最终可视化评价指标
# 可视化
# 创建散点图和回归线
scatter_plot <- data.frame(Actual = test_label, Predicted = predictions) %>%ggplot(aes(x = Actual, y = Predicted)) +geom_point() +geom_smooth(method = "lm", col = "blue") +xlab("Actual ILI1") +ylab("Predicted ILI1") +ggtitle("Actual vs Predicted")# 设置标题居中
scatter_plot +theme(plot.title = element_text(hjust = 0.5))思路主要是使用R语言进行XGBoost模型预测的流程包括数据准备、模型训练、参数调优、模型评估和预测。首先,加载数据并进行预处理,然后使用 xgb.cv 和 xgb.train 函数进行模型训练和交叉验证。接着,通过调整参数优化模型性能,最后使用测试集评估模型,并使用训练好的模型进行预测新数据。
数据和完整代码
创作不易,希望大家多多点赞收藏和评论!
相关文章:

R语言数据分析-xgboost模型预测
XGBoost模型预测的主要大致思路: 1. 数据准备 首先,需要准备数据。这包括数据的读取、预处理和分割。数据应该包括特征和目标变量。 步骤: 读取数据:从CSV文件或其他数据源读取数据。数据清理:处理缺失值、异常值等…...

使用redis的setnx实现分布式锁
在Redis中,SETNX 是 “Set If Not Exists”(如果不存在,则设置)的缩写。这是一个原子操作,用于设置一个键的值,前提是这个键不存在。如果键已经存在,.则不会执行任何操作。 封装方法trylock,用…...

LangChain进行文本摘要 总结
利用LangChain进行文本摘要的详细总结 LangChain是一个强大的工具,可以帮助您使用大型语言模型(LLM)来总结多个文档的内容。以下是一个详细指南,介绍如何使用LangChain进行文本摘要,包括使用文档加载器、三种常见的摘…...
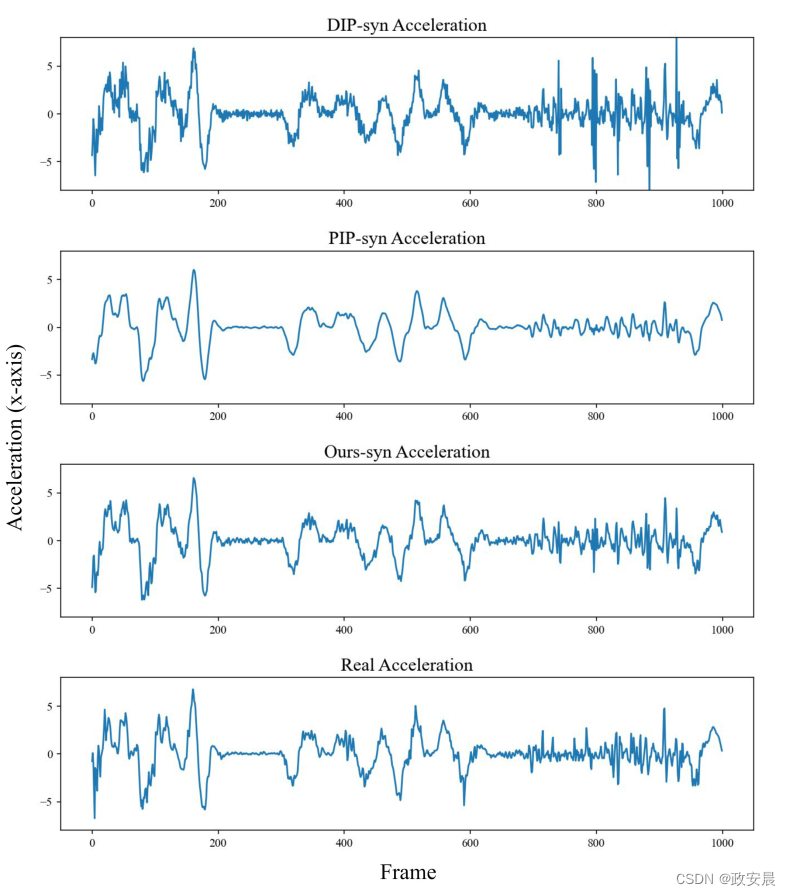
政安晨【零基础玩转各类开源AI项目】:解析开源项目的论文:Physical Non-inertial Poser (PNP)
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 零基础玩转各类开源AI项目 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本文解析的原始论文为:https://arxiv.org/…...
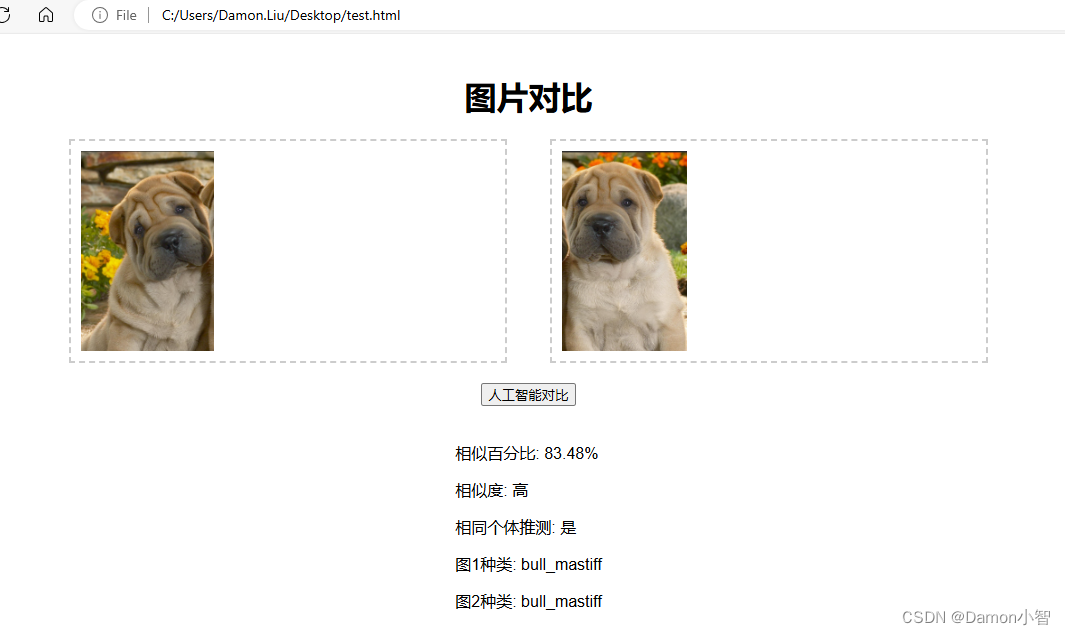
【机器学习】基于OpenCV和TensorFlow的MobileNetV2模型的物种识别与个体相似度分析
在计算机视觉领域,物种识别和图像相似度比较是两个重要的研究方向。本文通过结合深度学习和图像处理技术,基于OpenCV和TensorFlow的MobileNetV2的预训练模型模,实现物种识别和个体相似度分析。本文详细介绍该实验过程并提供相关代码。 一、名…...
建模杂谈系列244 TimeTraveller
说明 所有的基于时间处理和运行的程序将以同样的节奏同步和执行 TT(TimeTraveller)是一个新的设计,它最初会服务与量化过程的大量任务管理:分散开发、协同运行。但是很显然,TT的功能将远不止于此,它将服务大量的,基于时…...
基于MingGW64 GCC编译Windows平台上的 libuvc
安装cmake 打开cmake官网 https://cmake.org/download/,下载安装包: 安装时选择将cmake加到系统环境变量里。安装完成后在新的CMD命令窗口执行cmake --version可看到输出: D:\>cmake --version cmake version 3.29.3 CMake suite mainta…...

【Linux】网络高级IO
欢迎来到Cefler的博客😁 🕌博客主页:折纸花满衣 🏠个人专栏:Linux 目录 👉🏻五种IO模型👉🏻消息通信的同步异步与进程线程的同步异步有什么不同?👉…...
【C++ ——— 继承】
文章目录 继承的概念即定义继承概念继承定义定义格式继承关系和访问限定符继承基类成员访问方式的变化 基类对象和派生类对象的赋值转换继承中的作用域派生类中的默认成员函数继承与友元继承与静态成员菱形继承虚继承解决数据冗余和二义性的原理继承的总结继承常见笔试面试题 继…...
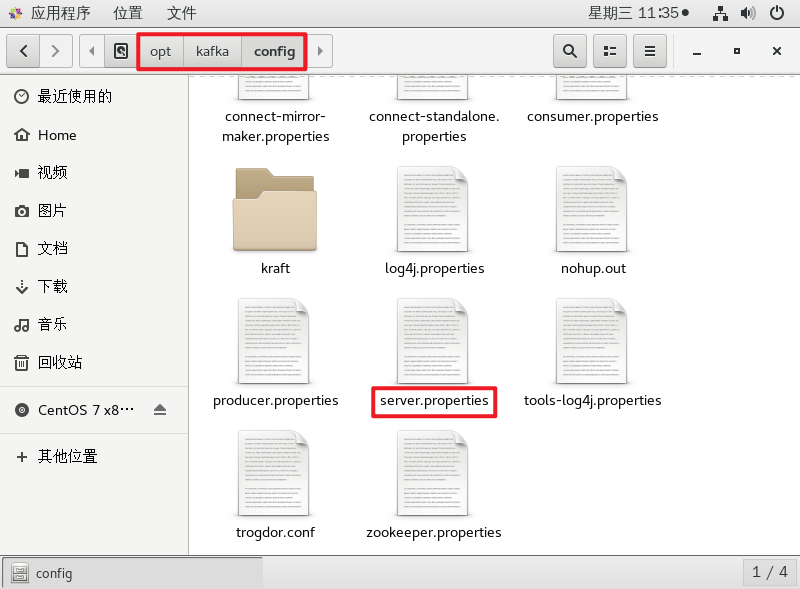
kafka-守护启动
文章目录 1、kafka守护启动1.1、先启动zookeeper1.1.1、查看 zookeeper-server-start.sh 的地址1.1.2、查看 zookeeper.properties 的地址 1.2、查看 jps -l1.3、再启动kafka1.3.1、查看 kafka-server-start.sh 地址1.3.2、查看 server.properties 地址 1.4、再次查看 jps -l 1…...

TypeScript 中的命名空间和模块化
1. 命名空间(Namespace) 命名空间提供了一种逻辑上的代码分组机制,用于避免命名冲突和将相关代码组织在一起。它使用 namespace 关键字来定义命名空间,并通过点运算符来访问其中的成员。例如: // 定义命名空间 names…...

9 html综合案例-注册界面
9 综合案例-注册界面 一个只有html骨架的注册页面 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>…...
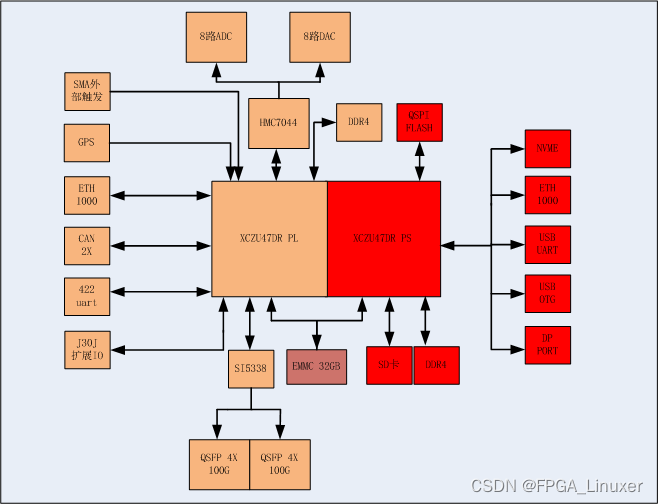
Xilinx RFSOC 47DR 8收8发 信号处理板卡
系统资源如图所示: FPGA采用XCZU47DR 1156芯片,PS端搭载一组64Bit DDR4,容量为4GB,最高支持速率:2400MT/s; PS端挂载两片QSPI X4 FLASH; PS支持一路NVME存储; PS端挂载SD接口,用于存储程序&…...

ros2 launch 用法以及一些基础功能函数的示例
文章目录 launch启动一个节点的launch示例launch文件中添加节点的namespacelaunch文件中的话题名称映射launch文件中向节点内传入命令行参数launch文件中向节点内传入rosparam使用方法多节点启动命令行参数配置资源重映射ROS参数设置加载参数文件在launch文件中使用条件变量act…...

如何使用Python获取图片中的文字信息
如下有三中方法: 方法1. 使用Tesseract OCR(pytesseract) 安装依赖 首先,确保你已经安装了Tesseract OCR引擎(例如,通过你的操作系统的包管理器)。然后,你可以通过pip安装pytesse…...

C++知识点
1. 构造函数:当没有写任何构造函数(含拷贝构造),系统会生成默认的无参构造,并且访问属性是共有。 默认拷贝构造:当没有写任何的拷贝构造,系统会生成默认的拷贝构造->是一个浅拷贝 写了拷贝构造函数,这…...

反转字符串中的单词-力扣
此题将问题分为三步进行解决: 第一步,删除字符串中多余的空格,removeSpaces函数中删除所有的空格,并手动在每个单词后添加一个空格,最后重构字符串s第二步,将整个字符串反转第三步,对反转后的字…...

Kotlin 重写与重载
文章目录 重写(Override)重载(Overload) 重写(Override) 重写通常是指子类覆盖父类的属性或方法,通常会标记为override: open class Base {open val name "Base"open f…...
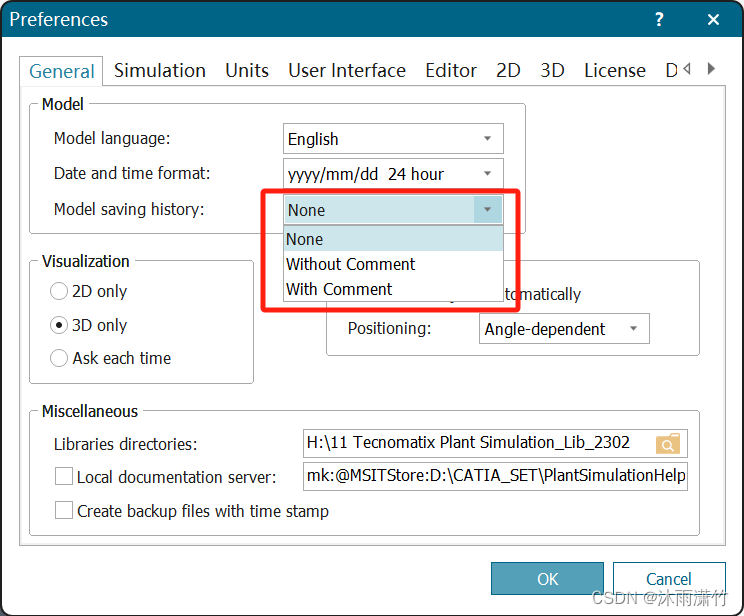
关于高版本 Plant Simulation 每次保存是 提示提交comm对话框的处理方法
关于高版本 Plant Simulation 每次保存是 提示提交comm对话框的处理方法 如下图 将model saving history 修改为None即可 关于AutoCAD 2022 丢失模板库的问题 从新从以下地址打开即可: D:\Program Files\Autodesk\AutoCAD 2022\UserDataCache\zh-cn\Template...

C语言之旅:探索单链表
目录 一、前言 二、实现链表的功能: 打印 创建节点 尾插 尾删 头插 头删 查找 在指定位置之前插入数据 指定位置删除 在指定位置之后插入数据 打印 销毁 三、全部源码: 四、结语 一、前言 链表是一个强大且基础的数据结构。对于很多初…...

Selenium Cookie复用登录态实战指南
1. 这不是“绕过”,而是“复用登录态”——先厘清一个关键认知误区很多人看到“Selenium通过cookie绕过验证码”这个标题,第一反应是:又一个黑灰产技巧?能省事就上?但我在电商、金融、SaaS类项目里带团队做自动化测试近…...

多图像查看器:告别繁琐切换,高效管理海量图片的专业解决方案
多图像查看器:告别繁琐切换,高效管理海量图片的专业解决方案 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. …...

AI人工智能行业的现状:为什么说AI从业者的需求越来越大
一、AI产业爆发式增长:需求激增的时代底色2026年,人工智能产业已步入爆发式增长的黄金期,成为驱动全球经济复苏与产业变革的核心引擎。从全球市场来看,2025年AI市场规模达7575.8亿美元,同比增长18.7%,预计2…...
)
仅限本周开放|Lovable高阶工程化实践内部培训课件(含模块化架构图、依赖注入容器源码注释版)
更多请点击: https://codechina.net 第一章:Lovable应用开发完整教程 Lovable 是一个面向现代 Web 应用的轻量级响应式框架,专为构建高交互性、可访问性强且易于维护的单页应用(SPA)而设计。它采用声明式组件模型与响…...
:从sref灰度映射到氯化银颗粒模拟全链路拆解)
Midjourney范戴克印相实战手册(2024唯一认证工作流):从sref灰度映射到氯化银颗粒模拟全链路拆解
更多请点击: https://intelliparadigm.com 第一章:范戴克印相的历史溯源与数字再生哲学 范戴克印相(Van Dyke Brown printing)诞生于19世纪末,是铁银盐印相工艺的重要分支,以荷兰画家安东尼范戴克命名&am…...

不止于指路,智慧导览如何重构公共空间价值
在过去很长一段时间里,公共空间的价值被简单地等同于功能性。一个公园只要有绿化和座椅,一个商场只要有商铺和电梯,一个政务大厅只要有窗口和座位,就被认为是合格的公共空间。然而,随着人们生活水平的提高和消费观念的…...
v1.0,集成 Matt Pocock 全套技能,实现零幻觉开发)
构建企业级 AI 编程助手(AI-OS)v1.0,集成 Matt Pocock 全套技能,实现零幻觉开发
告别单文件 Prompt:构建企业级 AI 编程助手(AI-OS)v1.0,集成 Matt Pocock 全套技能,实现零幻觉开发 引言:为什么你的 AI 编程总是“翻车”? 在使用 OpenCode、Cursor、Cline 等 AI 编程工具时&a…...

SSH密钥不能直接访问phpMyAdmin:正确使用隧道方案
1. 这个标题里藏着三个根本性误解,先说清楚再动手 “如何安全的使用ssh秘钥访问phpmyadmin”——这句话本身就是一个典型的认知错位组合。我第一次在客户现场看到这个需求时,花了一整个下午才把技术逻辑理顺。 phpMyAdmin 本质上是一个运行在 Web 服务器…...

YOLO26 ONNX Runtime 部署实战:告别NMS后处理,边缘推理新标杆
🚀 YOLO26 ONNX Runtime 部署实战:告别NMS后处理,边缘推理新标杆 摘要: Ultralytics 重磅推出的 YOLO26 不仅在精度上实现了代际飞跃,更在架构层面进行了颠覆性革新——彻底移除了传统的 NMS(非极大值抑制)后处理环节。本文将带你深入了解 YOLO26 的核心优势,并基于 …...

GBase 8c存储过程调试接口使用指南
本文针对南大通用 GBase 8c 数据库,围绕存储过程的使用与问题定位,基于 DBE_PLDEBUGGER 调试接口,详细说明存储过程调试的核心接口、标准流程、常用命令与完整实战操作步骤,帮助用户快速掌握调试方法,高效定位与解决存…...