集成算法实验与分析(软投票与硬投票)
概述
目的:让机器学习效果更好,单个不行,集成多个
集成算法
Bagging:训练多个分类器取平均
f ( x ) = 1 / M ∑ m = 1 M f m ( x ) f(x)=1/M\sum^M_{m=1}{f_m(x)} f(x)=1/M∑m=1Mfm(x)
Boosting:从弱学习器开始加强,通过加权来进行训练
F m ( x ) = F m − 1 ( x ) + a r g m i n h ∑ i = 1 n L ( y i , F m − 1 ( x i ) + h ( x i ) ) F_m(x)=F_{m-1}(x)+argmin_h\sum^n_{i=1}L(y_i,F_{m-1}(x_i)+h(x_i)) Fm(x)=Fm−1(x)+argminh∑i=1nL(yi,Fm−1(xi)+h(xi))
(加入一棵树,新的树更关注之前错误的例子)
Stacking:聚合多个分类或回归模型(可以分阶段来做)
Bagging模型(随机森林)
全称: bootstrap aggregation(说白了就是并行训练一堆分类器)
最典型的代表就是随机森林,现在Bagging模型基本上也是随机森林。
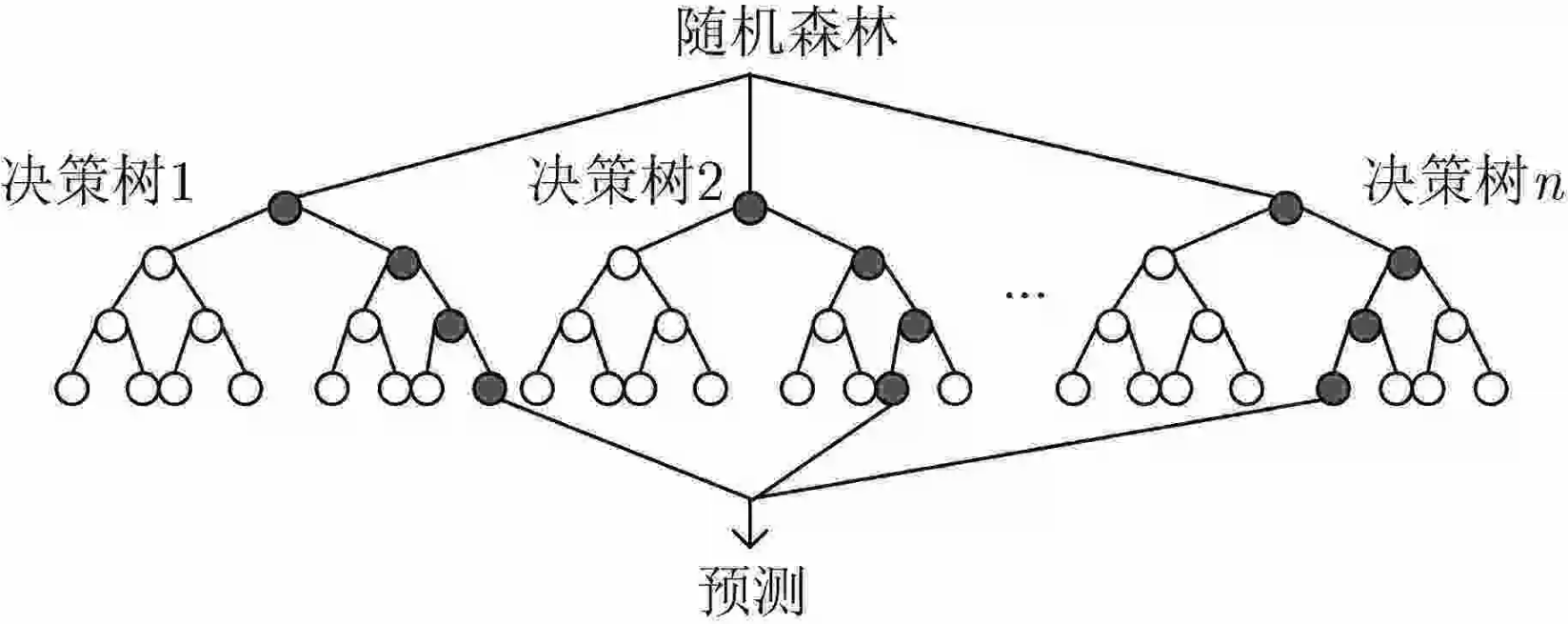
随机:数据采样随机,每棵树只用部分数据;数据有多个特征(属性)组成,每棵树随机选择部分特征。随机是为了使得每个分类器拥有明显差异性。
森林:很多个决策树并行放在一起
如何对所有树选择最终结果?分类的话可以采取少数服从多数,回归的话可以采用取平均值。
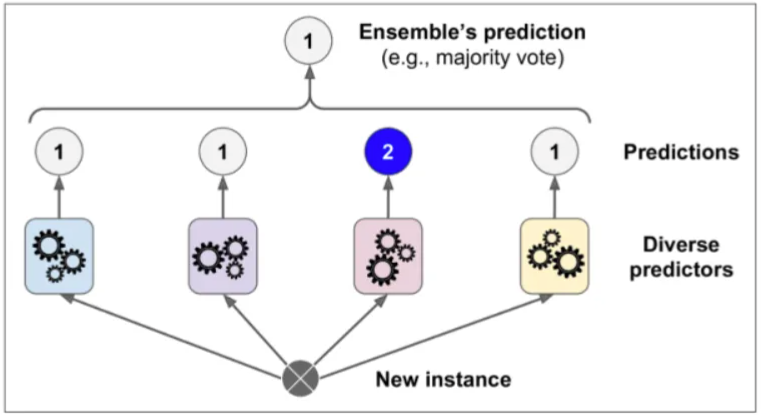
集成基本思想
训练时用多种分类器一起完成同一份任务
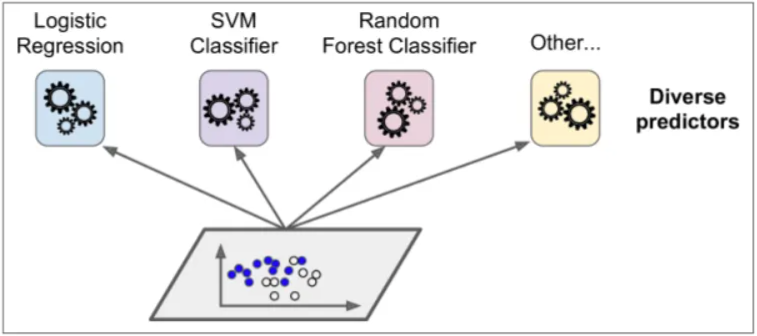
测试时对待测试样本分别通过不同的分类器,汇总最后的结果
import numpy as np
import os
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
import warnings
warnings.filterwarnings('ignore')
np.random.seed(42)
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moonsX,y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha = 0.6)
plt.plot(X[:,0][y==0],X[:,1][y==1],'bs',alpha = 0.6)
投票策略:软投票与硬投票
- 硬投票:直接用类别值,少数服从多数
- 软投票:各自分类器的概率值进行加权平均,或者自己就去概率值最大的作为结果
硬投票实验
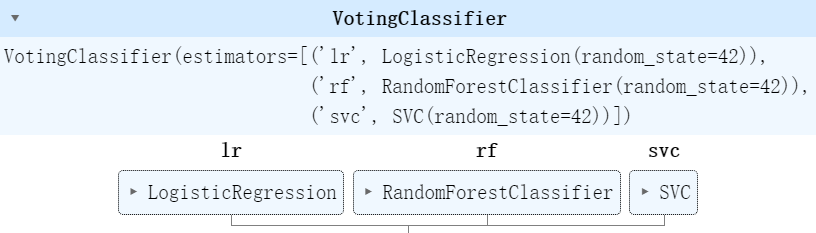
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC# 三种分类器,逻辑回归,随机森林,支持向量机
log_clf = LogisticRegression(random_state=42)
rnd_clf = RandomForestClassifier(random_state=42)
svm_clf = SVC(random_state=42)voting_clf = VotingClassifier(estimators =[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='hard')
voting_clf.fit(X_train,y_train)
from sklearn.metrics import accuracy_score
print('三种分类器的结果')
for clf in (log_clf,rnd_clf,svm_clf):clf.fit(X_train,y_train)y_pred = clf.predict(X_test)print (clf.__class__.__name__,accuracy_score(y_test,y_pred))
print('集成分类的硬投票结果(一般会在效果上有微量提升,但不会太大)')
voting_clf.fit(X_train,y_train)
y_pred = voting_clf.predict(X_test)
print (voting_clf.__class__.__name__,accuracy_score(y_test,y_pred))
结果输出:
三种分类器的结果
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896
集成分类的结果(一般会在效果上有微量提升,但不会太大)
VotingClassifier 0.912
软投票实验
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVClog_clf = LogisticRegression(random_state=42)
rnd_clf = RandomForestClassifier(random_state=42)
svm_clf = SVC(probability = True,random_state=42)voting_clf = VotingClassifier(estimators =[('lr',log_clf),('rf',rnd_clf),('svc',svm_clf)],voting='soft')
from sklearn.metrics import accuracy_score
print('三种分类器的结果')
for clf in (log_clf,rnd_clf,svm_clf):clf.fit(X_train,y_train)y_pred = clf.predict(X_test)print (clf.__class__.__name__,accuracy_score(y_test,y_pred))
print('集成分类的软投票结果(一般会在效果上有微量提升,但不会太大)')
voting_clf.fit(X_train,y_train)
y_pred = voting_clf.predict(X_test)
print (voting_clf.__class__.__name__,accuracy_score(y_test,y_pred))
结果输出:
三种分类器的结果
LogisticRegression 0.864
RandomForestClassifier 0.896
SVC 0.896
集成分类的硬投票结果(一般会在效果上有微量提升,但不会太大)
VotingClassifier 0.92
总结:软投票要求必须各个分别器都能得出概率值,一般来说软投票效果更好一些
相关文章:
集成算法实验与分析(软投票与硬投票)
概述 目的:让机器学习效果更好,单个不行,集成多个 集成算法 Bagging:训练多个分类器取平均 f ( x ) 1 / M ∑ m 1 M f m ( x ) f(x)1/M\sum^M_{m1}{f_m(x)} f(x)1/M∑m1Mfm(x) Boosting:从弱学习器开始加强&am…...

网络数据库后端框架相关面试题
面试是工作的第一步,面试中面试官所提出的问题千奇百怪,其中关于网络数据库后端框架面试题汇总如下: 1,关系型数据库和非关系型数据库的区别 关系型数据库主要有 MYsql Iracle SQLSever等 相对于非关系型数据库的优势为查询效率…...
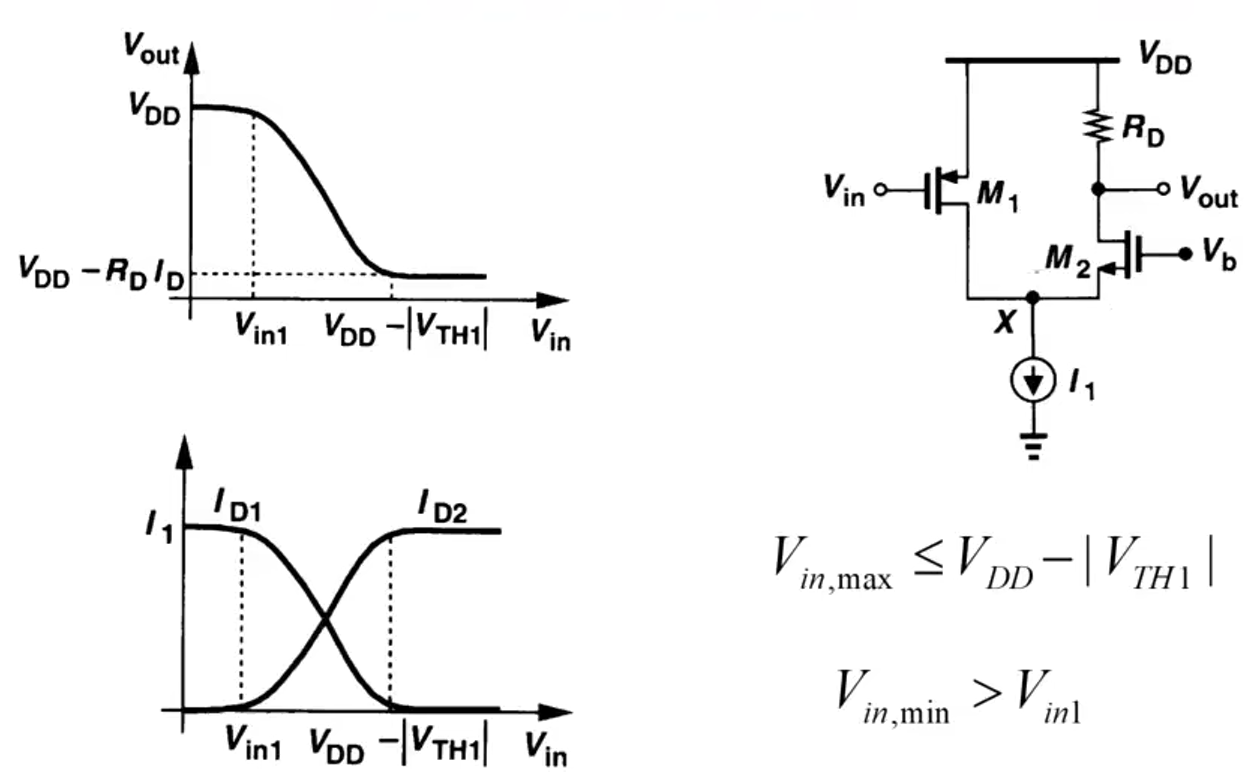
模拟集成电路(6)----单级放大器(共源共栅级 Cascode Stage)
模拟集成电路(6)----单级放大器(共源共栅级 Cascode Stage) 大信号分析 对M1 V x ≥ V i n − V T H 1 V x V B − V G S 2 V B ≥ V i n − V T H 1 V G S 2 V_{x}\geq V_{in}-V_{TH1}\quad V_{x}V_{B}-V_{GS2}\\V_{B}\geq V_{in}-V_{TH1}V_{GS2} Vx…...
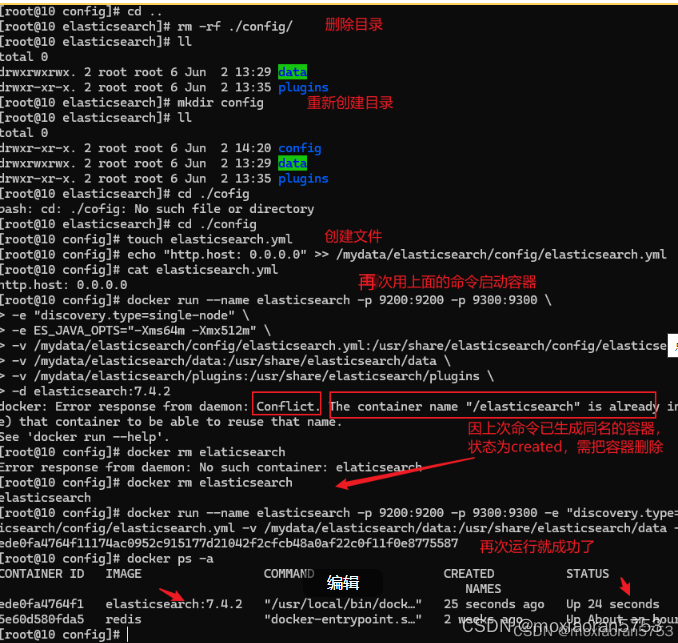
docker以挂载目录启动容器报错问题的解决
拉取镜像: docker pull elasticsearch:7.4.2 docker pull kibana:7.4.2 创建实例: mkdir -p /mydata/elasticsearch/configmkdir -p /mydata/elasticsearch/dataecho "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasti…...
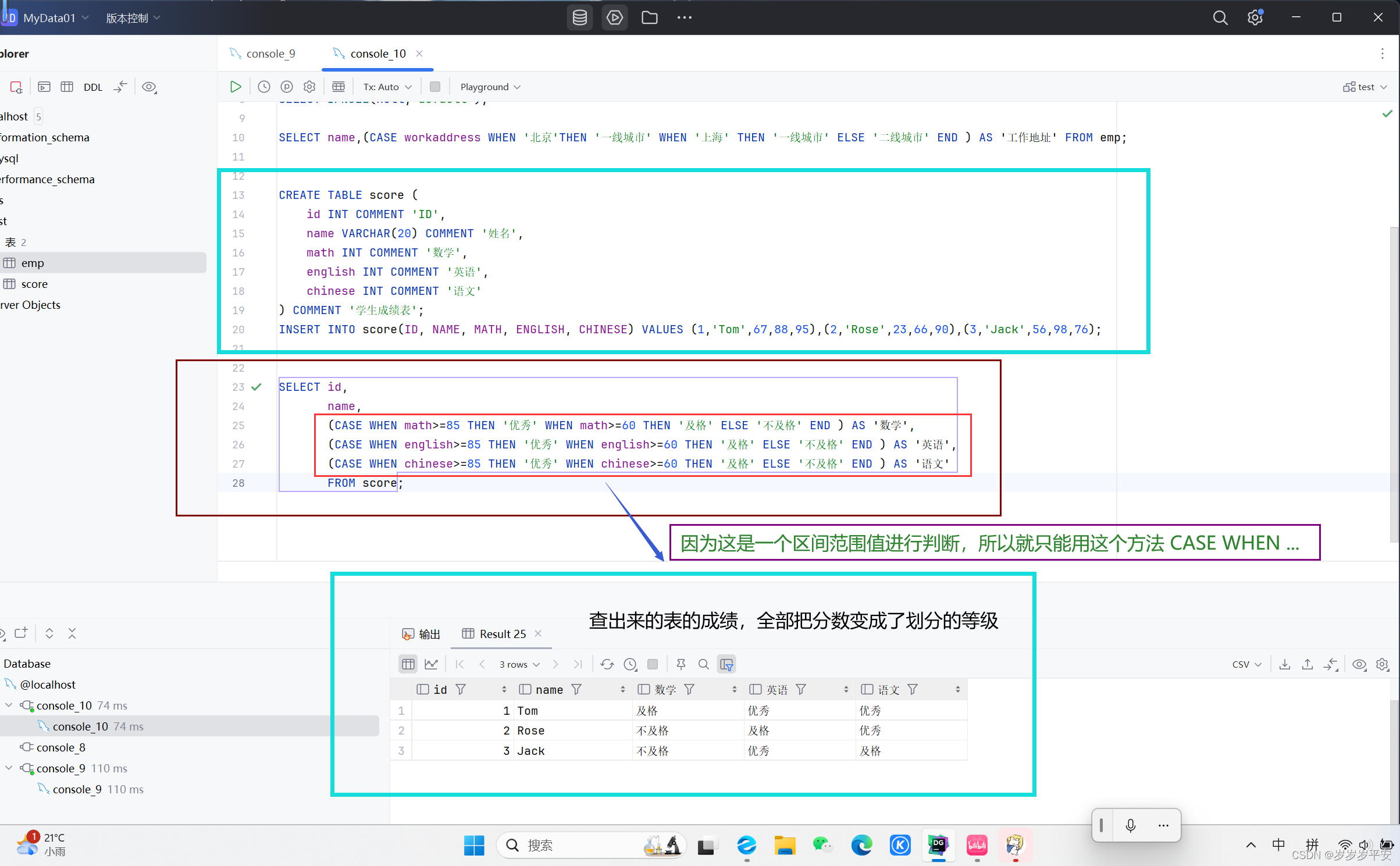
MySQL—函数—流程控制函数(基础)
一、引言 接下来,我们就进入函数的最后一个部分:流程函数。而流程控制函数在我们的日常开发过程是很有用的。 流程控制函数在我们 sql 语句当中,经常用来实现条件的筛选,从而提高语句的一个执行效率。 我们主要介绍以下4个流程控…...
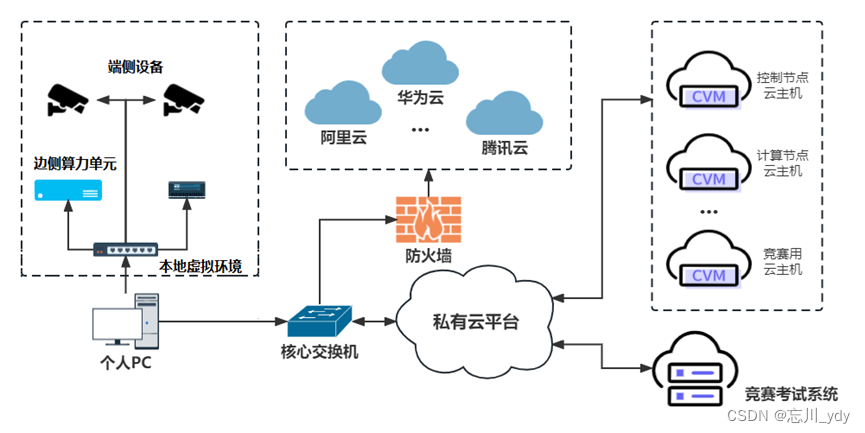
2023年全国职业院校技能大赛(高职组)“云计算应用”赛项赛卷7(私有云)
#需要资源(软件包及镜像)或有问题的,可私聊博主!!! #需要资源(软件包及镜像)或有问题的,可私聊博主!!! #需要资源(软件包…...
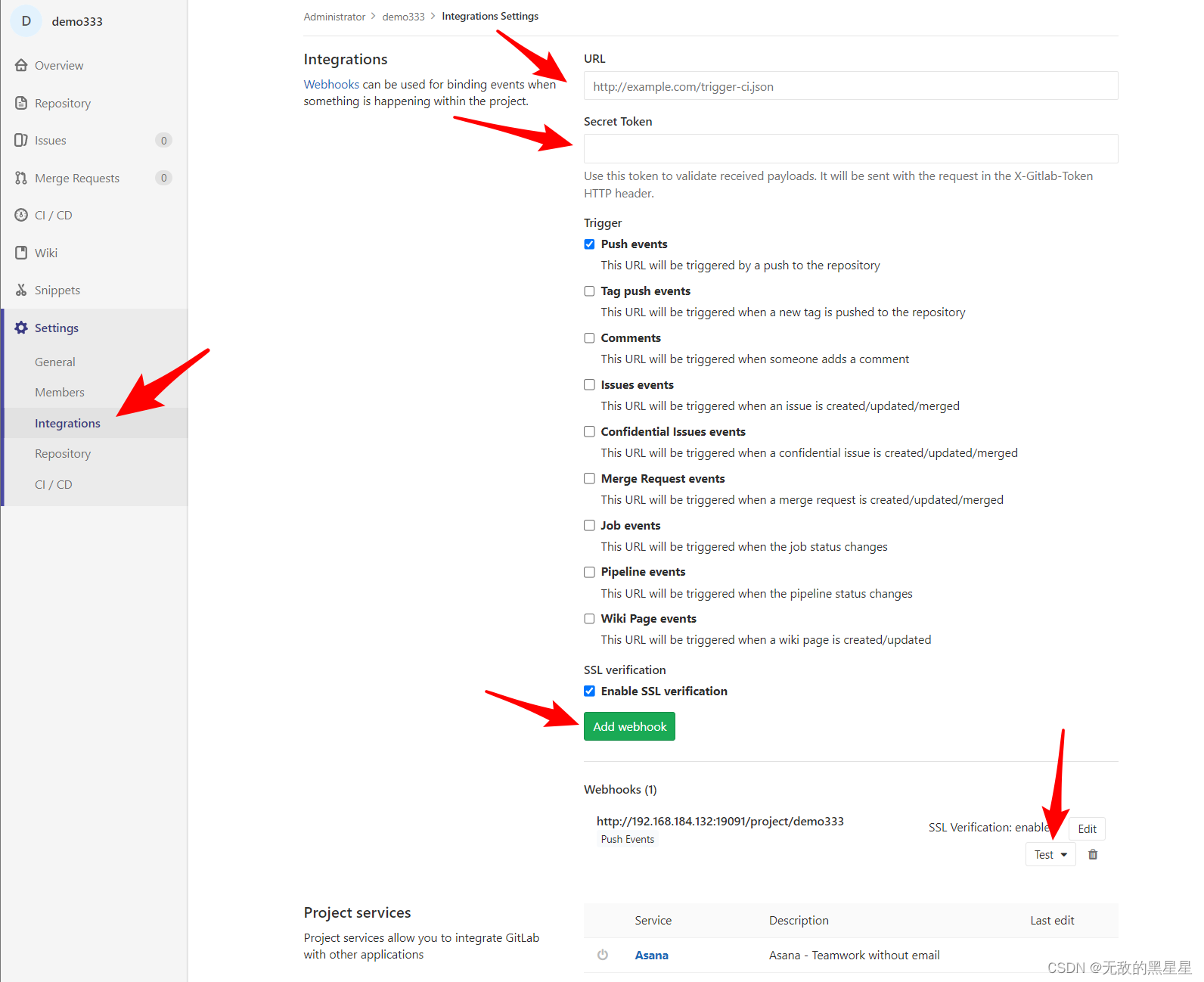
Jenkins、GitLab部署项目
1、安装JDK 1.1、下载openJdk11 yum -y install fontconfig java-11-openjdk1.2、查看安装的版本号 java -version1.3、配置环境变量 vim /etc/profile在最底部添加即可 export JAVA_HOME/usr/lib/jvm/java-11-openjdk-11.0.23.0.9-2.el7_9.x86_64 export PATH$JAVA_HOME/…...
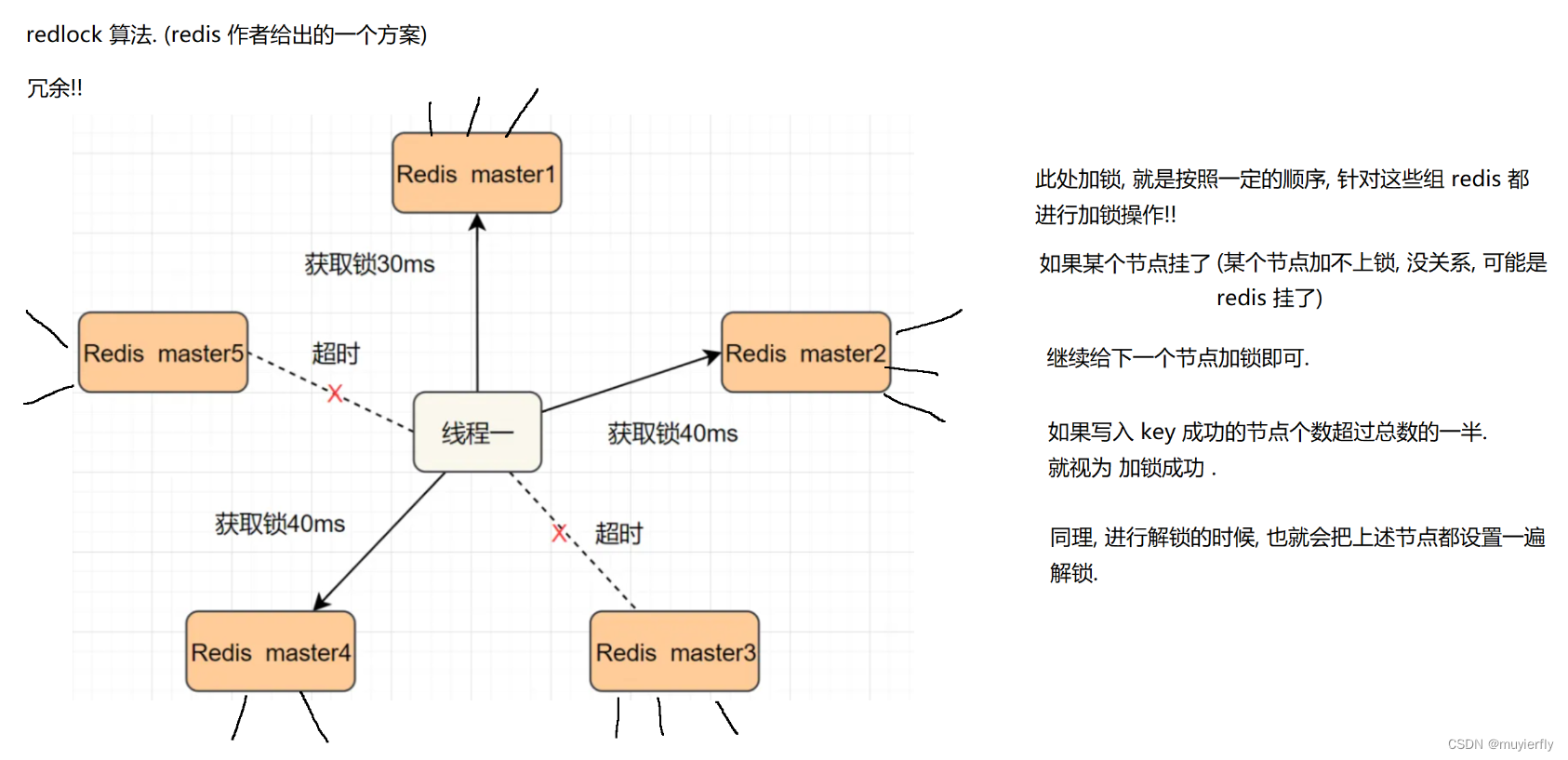
21.Redis之分布式锁
1.什么是分布式锁 在⼀个分布式的系统中, 也会涉及到多个节点访问同⼀个公共资源的情况. 此时就需要通过 锁 来做互斥控制, 避免出现类似于 "线程安全" 的问题. ⽽ java 的 synchronized 或者 C 的 std::mutex, 这样的锁都是只能在当前进程中⽣效, 在分布式的这种多…...

Mysql基础学习:mysql8 JSON字段查询操作
文章目录 一、查询JSON中某个属性值为XXX的数据量1、方式一2、方式二 二、查询的JSON中的value并去除双引号 一、查询JSON中某个属性值为XXX的数据量 1、方式一 select count(*)from table_namewhere JSON_CONTAINS(json-> $.filed1, "xxx")or JSON_CONTAINS(jso…...

搭建基于Django的博客系统数据库迁移从Sqlite3到MySQL(四)
上一篇:搭建基于Django的博客系统增加广告轮播图(三) 下一篇:基于Django的博客系统之用HayStack连接elasticsearch增加搜索功能(五) Sqlite3数据库迁移到MySQL 数据库 迁移原因 Django 的内置数据库 SQL…...

24年护网工具,今年想参加护网的同学要会用
24年护网工具集 吉祥学安全知识星球🔗http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247483727&idx1&sndb05d8c1115a4539716eddd9fde4e5c9&chksmc0e47813f793f105017fb8551c9b996dc7782987e19efb166ab665f44ca6d900210e6c4c0281&scene21…...
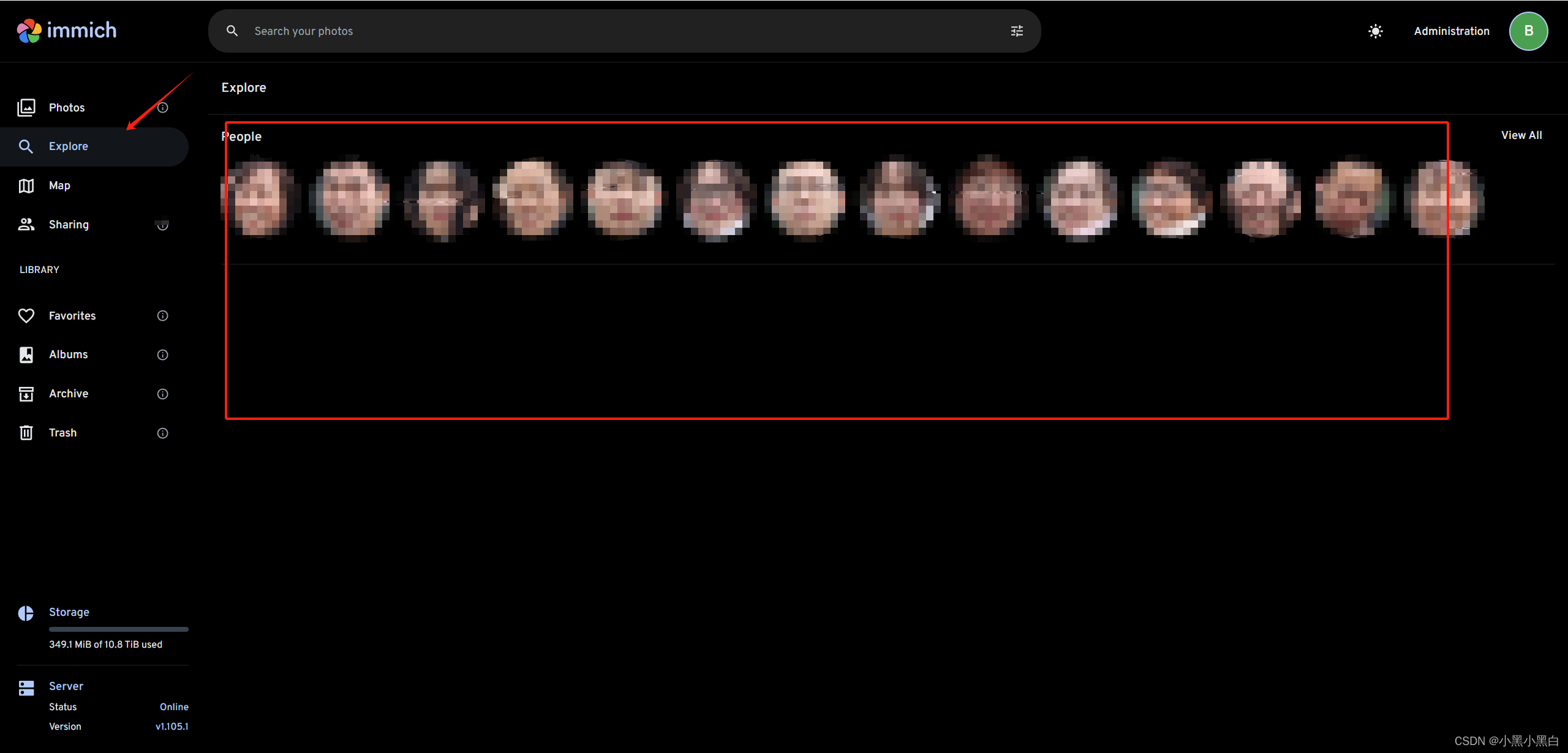
解决TrueNas Scale部署immich后人脸识别失败,后台模型下载异常,immich更换支持中文搜索的CLIP大模型
这个问题搞了我几天终于解决了,搜遍网上基本没有详细针对TrueNas Scale部署immich应用后,CLIP模型镜像下载超时导致人脸识别失败,以及更换支持中文识别的CLIP模型的博客。 分析 现象:TrueNas Scale安装immich官方镜像应用后&…...

面试高频问题----2
一、进程、线程、协程有什么区别? 1.进程:进程是操作系统中独立运行的程序实例,每个进程都有自己的内存空间和系统资源;进程之间相互独立,每个进程有自己的内存地址空间,一个进程无法直接访问另一个进程的…...

Nginx的配置文件-详细使用说明
Nginx的配置文件是Nginx服务器运行的核心,它决定了Nginx如何响应和处理各种请求。以下是对Nginx配置文件(通常名为nginx.conf)的详细解析,按照常见的结构和配置项进行分类: 1. 全局块 user:指定Nginx运行的用户和用户组。例如:user nginx;worker_processes:指定工作进…...

YOLOv5改进 | 卷积模块 | 提高网络的灵活性和表征能力的动态卷积【附代码+小白可上手】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 轻量级卷积神经网络由于其低计算预算限制了CNNs的深度(卷积层数)和宽度(通道数),…...

23、linux系统文件和日志分析
linux文件系统与日志分析 文件时存储在硬盘上的,硬盘上的最小存储单位是扇区,每个扇区大大小是512字节。 inode:元信息(文件的属性 权限,创建者,创建日期等) block:块,…...
安装VS2017后,离线安装Debugging Tools for Windows(QT5.9.2使用MSVC2017 64bit编译器)
1、背景 安装VS2017后,Windows Software Development Kit - Windows 10.0.17763.132的Debugging Tools for Windows默认不会安装,如下图。这时在QT5.9.2无法使用MSVC2017 64bit编译器。 2、在线安装 如果在线安装参考之前的文章: Qt5.9.2初…...
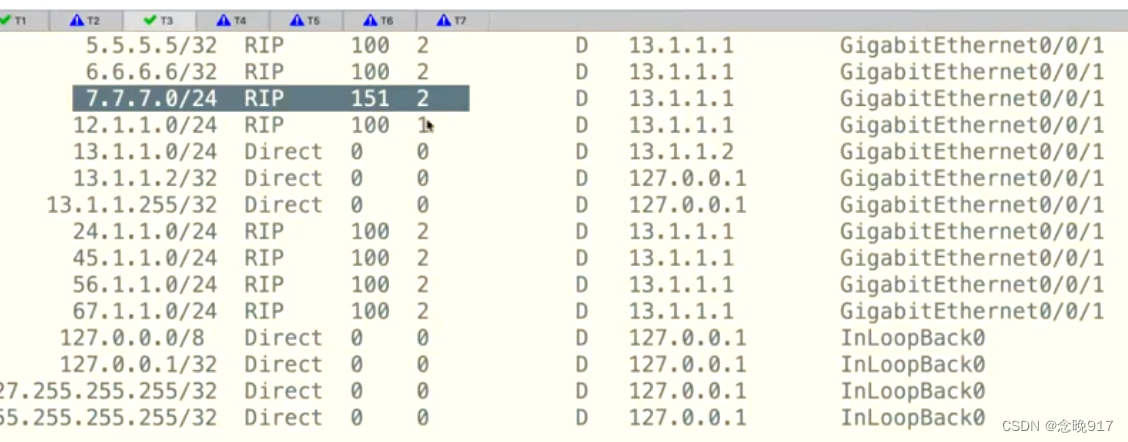
路由策略实验2
对R7,重发布直连路由 对R2,做双向 对R3同样 先不改优先级 查看,知道所有给R3的路由为151,全部为OSPF。 知道了是错误的,先把3,4之间的线路断掉 接着对R3,让优先级全部回到100(displa…...
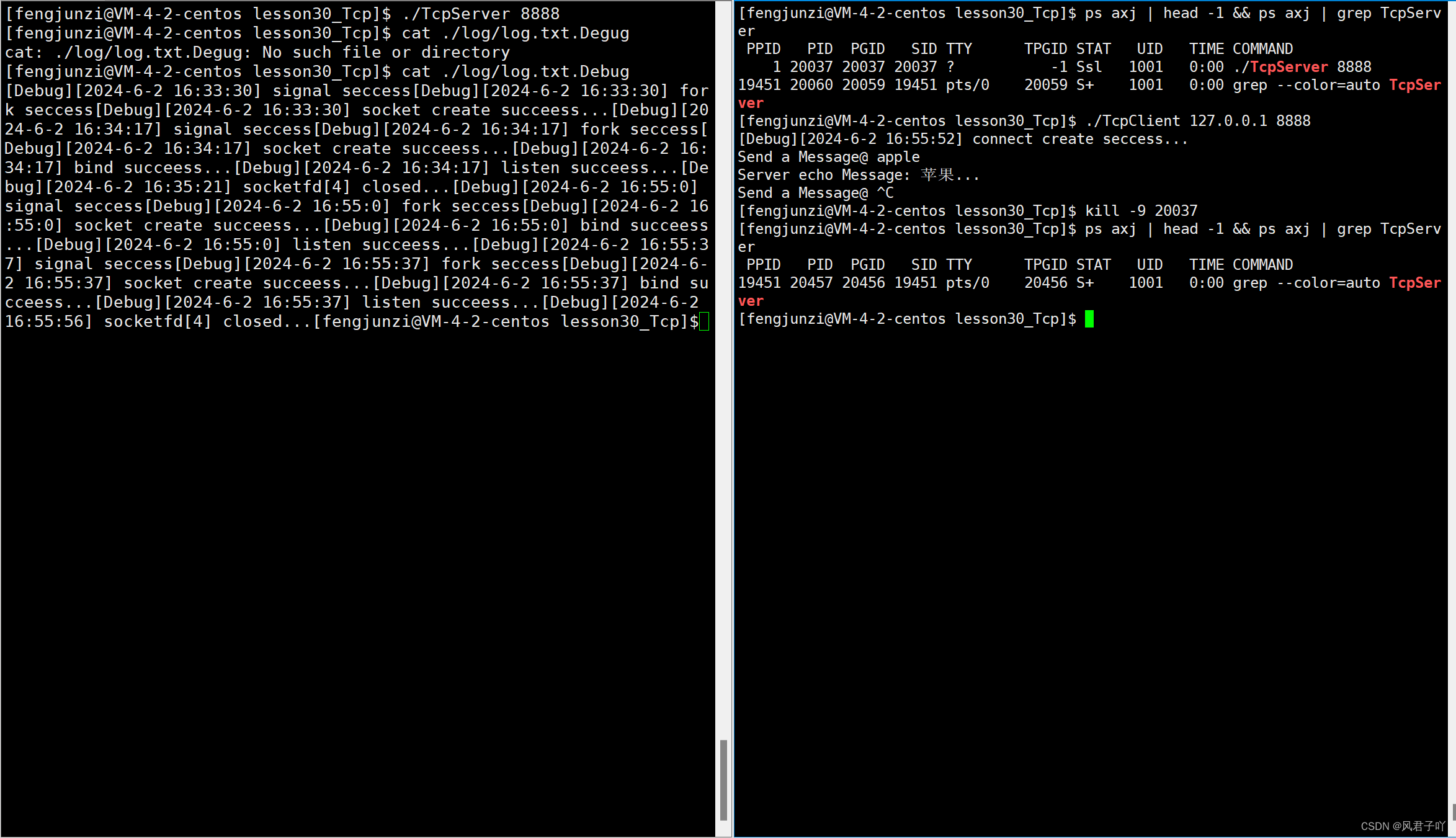
Linux网络-守护进程版字典翻译服务器
文章目录 前言一、pid_t setsid(void);二、守护进程翻译字典服务器(守护线程版)效果图 前言 根据上章所讲的后台进程组和session会话,我们知道如果可以将一个进程放入一个独立的session,可以一定程度上守护该进程。 一、pid_t se…...

Python 推导式详解:高效简洁的数据处理技巧
推导式是 Python 提供的一种简洁而强大的语法,用于创建列表、集合和字典。它可以让代码更简洁、更易读,同时提高运行效率。 基本语法 列表推导式 基本语法: [expression for item in iterable if condition]示例: # 生成平方…...

3步掌握Jellyfin智能字幕插件:新手快速上手指南
3步掌握Jellyfin智能字幕插件:新手快速上手指南 【免费下载链接】jellyfin-plugin-maxsubtitle 一个 Jellyfin 中文字幕插件(未来可以不局限中文) 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-maxsubtitle MaxSubti…...
,限免领取仅剩200份)
ElevenLabs海南话语音部署避坑清单(含IPA音标对齐表+海口话声调模板),限免领取仅剩200份
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs海南话语音部署避坑清单(含IPA音标对齐表海口话声调模板),限免领取仅剩200份 部署ElevenLabs模型支持海口话(海南闽语)语音合成时&…...
)
git常用使用命令(亲测,可以,自己的笔记)
一本 官方中文版 书分享给大家(说明:本人多次阅读,体会是容易入门,读起来很顺手,但是讲的不深入) https://git-scm.com/book/zh/v2 一、git官方使用命令: usage: git [--version] [--help] [-C…...

会计学论文降AI工具怎么选?财务审计方向高效降重指南
又到了毕业答辩的关键期,不少会计专业的同学都在发愁论文AI率不达标:财务分析部分的数据解读、审计研究的案例推导用AI辅助写完,一检测全是高风险,改了好几遍还是过不了学校的审核。我身边不少师弟师妹踩过工具的坑,要…...

快速上手Notepad2-mod:5个步骤打造你的专属轻量级代码编辑器
快速上手Notepad2-mod:5个步骤打造你的专属轻量级代码编辑器 【免费下载链接】notepad2-mod LOOKING FOR DEVELOPERS - Notepad2-mod, a Notepad2 fork, a fast and light-weight Notepad-like text editor with syntax highlighting 项目地址: https://gitcode.c…...

如何快速掌握小程序UI组件库:Vant Weapp的5大优势与完整指南
如何快速掌握小程序UI组件库:Vant Weapp的5大优势与完整指南 【免费下载链接】vant-weapp 轻量、可靠的小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/va/vant-weapp Vant Weapp是一款轻量、可靠的小程序UI组件库,专为微信小程序开…...

AI应用哪家性价比高
在当前数字化转型浪潮中,企业纷纷寻求AI应用来降本增效,但面对市场上琳琅满目的产品,“AI应用哪家性价比高”成为决策者最纠结的问题。性价比并非单纯的价格对比,而是功能、效率、易用性与实际价值的综合考量。本文将从行业痛点出…...

酷安UWP桌面客户端:在Windows电脑上高效刷酷安的完整指南
酷安UWP桌面客户端:在Windows电脑上高效刷酷安的完整指南 【免费下载链接】Coolapk-UWP 一个基于 UWP 平台的第三方酷安客户端 项目地址: https://gitcode.com/gh_mirrors/co/Coolapk-UWP 还在为手机小屏幕刷酷安而感到眼睛酸痛吗?想在27寸大屏幕…...

Files.md:打造私密思考空间,兼具简洁实用与多样同步功能!
Files.md:专注思考的私密空间Files.md 是一款简洁的 .md 文件应用,为用户打造一个私密、安静的思考空间。用户可以用它存储生活中的一切,如笔记、文档、项目、日记、习惯记录、待办清单和任务等,所有内容都以纯 .md 文件形式保存&…...
)
别再用理想模型了!手把手教你用Multisim仿真LM741反相放大电路(含电源、电容、失真全避坑)
从理想模型到实战避坑:Multisim仿真LM741反相放大电路全流程解析 1. 为什么你的仿真结果总与教科书不符? 许多电子工程初学者在课本上学完"虚短虚断"原理后,第一次用Multisim搭建LM741反相放大电路时都会遇到这样的困惑:…...