PyTorch、显卡、CUDA 和 cuDNN 之间的关系
概述
PyTorch、显卡、CUDA 和 cuDNN 之间的关系及其工作原理可以这样理解:
显卡 (GPU)
显卡,特别是 NVIDIA 的 GPU,具有大量的并行处理单元,这些单元可以同时执行大量相似的操作,非常适合进行大规模矩阵运算,如深度学习中的卷积神经网络(CNNs)和循环神经网络(RNNs)的计算。
CUDA
CUDA(Compute Unified Device Architecture)是 NVIDIA 开发的一种并行计算架构,它允许开发者使用 C、C++、Fortran、Python 等语言编写程序直接访问 NVIDIA GPU 的并行计算能力。CUDA 提供了一个软件平台和一组工具,使得 GPU 能够作为通用处理器使用,执行复杂的并行计算任务。
cuDNN
cuDNN(CUDA Deep Neural Network library)是 NVIDIA 提供的一个高性能的 GPU 加速库,专门针对深度神经网络进行了优化。cuDNN 实现了常见的深度学习操作,如卷积、池化、归一化等,通过高度优化的内核提供了快速的执行速度。它简化了深度学习框架的实现,并提高了计算效率。
PyTorch
PyTorch 是一个开源机器学习库,主要用于深度学习模型的构建和训练。PyTorch 支持动态计算图,这使得它非常灵活,适合研究和原型设计。PyTorch 内置了对 CUDA 和 cuDNN 的支持,可以自动将计算卸载到 GPU 上,从而极大地加速深度学习模型的训练过程。
工作原理
当使用 PyTorch 进行深度学习模型的训练时,数据和计算会在以下组件间流动:
- CPU:模型定义、数据加载和预处理通常在 CPU 上完成。
- PyTorch:模型定义和训练逻辑由 PyTorch 处理。PyTorch 自动检测是否启用了 GPU 加速,并根据可用资源决定在 CPU 或 GPU 上执行计算。
- CUDA:当 PyTorch 需要执行 GPU 上的计算时,它会通过 CUDA API 将数据传输到 GPU 的显存中,并调用 CUDA 内核来执行计算。
- cuDNN:对于特定的深度学习操作,PyTorch 会调用 cuDNN 库,该库提供了优化过的 GPU 实现,进一步加速计算过程。
- GPU:GPU 执行由 CUDA 和 cuDNN 提供的计算任务,然后将结果返回给 PyTorch。
总之,PyTorch 利用 CUDA 和 cuDNN 来高效地使用 GPU 的计算资源,从而加快深度学习模型的训练速度。这种集成使得开发者可以专注于模型的设计和实验,而无需深入了解底层硬件细节。
举例讲解
让我们用更通俗的方式来解释 PyTorch、显卡(GPU)、CUDA 和 cuDNN 之间的关系,以及它们是如何一起工作的。
想象一下你在厨房准备一顿大餐。你有各种食材(数据),一些基本的烹饪工具(CPU),以及一个超级烤箱(GPU)。
显卡 (GPU) - 超级烤箱
显卡(GPU)就像是你的厨房里的超级烤箱。这个烤箱有很多加热元件(计算单元),可以同时烤很多食物(处理大量数据)。在深度学习中,GPU 的强大并行处理能力能够快速执行矩阵运算,这正是神经网络所需要的。
CUDA - 烤箱使用手册
CUDA 就像是超级烤箱的使用手册,它告诉烤箱如何更有效地工作。CUDA 是 NVIDIA 的一套工具和指令集,让程序员可以直接控制 GPU 的计算能力,就像是你按照食谱操作烤箱一样。没有 CUDA,GPU 就不会知道如何高效地处理深度学习的任务。
cuDNN - 烤箱的预设菜谱
cuDNN 类似于烤箱内置的一些预设菜谱,比如一键制作披萨或面包。cuDNN 是一个优化过的深度学习算法库,它包含了深度学习中最常用的算法,如卷积和池化。使用 cuDNN 就像选择烤箱上的预设模式,让 GPU 快速准确地完成任务。
PyTorch - 厨师和菜单
PyTorch 就像是一个聪明的厨师加上一个菜单。厨师(PyTorch)知道如何将食材(数据)变成美味的菜肴(模型预测),菜单(PyTorch 的 API)提供了各种各样的菜品选择。PyTorch 能够自动判断哪些任务可以在超级烤箱(GPU)上更快完成,哪些则在基础厨具(CPU)上更合适。
当你在 PyTorch 中训练模型时,它会检查是否连接了超级烤箱(GPU)。如果有,PyTorch 会调用 CUDA 和 cuDNN 来加速计算。它会把数据发送到 GPU,使用 CUDA 来控制 GPU 如何执行计算,同时使用 cuDNN 来执行那些预设好的深度学习算法,以达到最快的烹饪速度(计算速度)。
总的来说,PyTorch 是一个高级的工具,它让深度学习的专家和新手都能轻松使用 GPU 的强大计算力,就像一位经验丰富的厨师使用先进的厨房设备一样。通过这些工具,深度学习模型的训练和测试变得既快又容易。
相关文章:

PyTorch、显卡、CUDA 和 cuDNN 之间的关系
概述 PyTorch、显卡、CUDA 和 cuDNN 之间的关系及其工作原理可以这样理解: 显卡 (GPU) 显卡,特别是 NVIDIA 的 GPU,具有大量的并行处理单元,这些单元可以同时执行大量相似的操作,非常适合进行大规模矩阵运算&#x…...

Lambda 表达式练习
目录 sorted() 四种排序 List 转 Map map 映射 对象中 String 类型属性为空的字段赋值为 null BiConsumer,> T reduce(T identity, BinaryOperator accumulator) allMatch(Predicate p) groupingBy(Function f) flatMap(Function f) Optional.ofNullable(T t) 和 …...

JavaScript第七讲:数组,及练习题
目录 今天话不多说直接进入正题! 1. 创建数组对象 2. 数组长度 3. 遍历一个数组 4. 连接数组 5. 通过指定分隔符,返回一个数组的字符串表达 6. 分别在最后的位置插入数据和获取数据(获取后删除) 7. 分别在最开始的位置插入数据和获取数据(获取后删…...

从docker镜像反推Dockerfile
在项目运维的过程中,偶尔会遇到某个docker image打包时候的Dockerfile版本管理不善无法与image对应的问题,抑或需要分析某个三方docker image的构建过程,这时,就希望能够通过image反推构建时的instruction. 想实现这个过程可以使…...

车载软件架构 - AUTOSAR 的信息安全框架
车载软件架构 - AUTOSAR 的信息安全架构 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗…...

欧洲版“OpenAI”——Mistral 举办的 AI 大模型马拉松
近期,法国的 Mistral AI 举办了一场别开生面的 AI 大模型马拉松。要知道,Mistral 可是法国对 OpenAI 的有力回应,而且其技术还是完全开源的呢!这场在巴黎举行的黑客马拉松,规模空前盛大,竟然有超过 1000 名…...

Java | Leetcode Java题解之第128题最长连续序列
题目: 题解: class Solution {public int longestConsecutive(int[] nums) {Set<Integer> num_set new HashSet<Integer>();for (int num : nums) {num_set.add(num);}int longestStreak 0;for (int num : num_set) {if (!num_set.contai…...

C++的List
List的使用 构造 与vector的区别 与vector的区别在于不支持 [ ] 由于链表的物理结构不连续,所以只能用迭代器访问 vector可以排序,list不能排序(因为快排的底层需要随机迭代器,而链表是双向迭代器) (算法库里的排序不支持)(需要单独的排序) list存在vector不支持的功能 链…...

网易有道QAnything使用CPU模式和openAI接口安装部署
网易有道QAnything可以使用本地部署大模型(官网例子为qwen)也可以使用大模型接口(OPENAI或者其他大模型AI接口 )的方式,使用在线大模型API接口好处就是不需要太高的硬件配置。 本机环境windows11 首先安装WSL环境, 安装方法参考https://zhuan…...

量子加速超级计算简介
本文转载自:量子加速超级计算简介(2024年 3月 13日) By Mark Wolf https://developer.nvidia.cn/zh-cn/blog/an-introduction-to-quantum-accelerated-supercomputing/ 文章目录 一、概述二、量子计算机的构建块:QPU 和量子位三、量子计算硬件和算法四、…...

Unity3D 基于YooAssets的资源管理详解
前言 Unity3D 是一款非常流行的游戏开发引擎,它提供了丰富的功能和工具来帮助开发者快速创建高质量的游戏和应用程序。其中,资源管理是游戏开发中非常重要的一部分,它涉及到如何有效地加载、管理和释放游戏中的各种资源,如模型、…...

Linux 自动化升级Jar程序,指定Jar程序版本进行部署脚本
文章目录 一、环境准备二、脚本1. 自动化升级Jar程序2. 指定Jar程序版本进行部署总结一、环境准备 本文在 CentOS 7.9 环境演示,以springboot为例,打包后生成文件名加上版本号,如下打包之后为strategy-api-0.3.2.jar: pom.xml<?xml version="1.0" encoding=&…...

python练习五
Title1:请实现一个装饰器,每次调用函数时,将函数名字以及调用此函数的时间点写入文件中 代码: import time time time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 获取当前的时间戳 # 定义一个有参装饰器来实…...
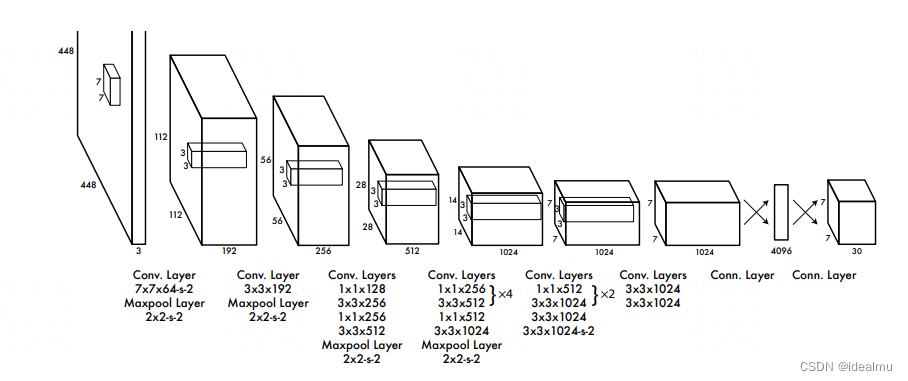
YOLOv1深入解析与实战:目标检测算法原理
参考: https://zhuanlan.zhihu.com/p/667046384 https://blog.csdn.net/weixin_41424926/article/details/105383064 https://arxiv.org/pdf/1506.02640 1. 算法介绍 学习目标检测算法,yolov1是必看内容,不同于生成模型,没有特别…...

Apache Calcite - 自定义标量函数
前言 上一篇文章中我们介绍了calcite中内置函数的使用。实际需求中会遇到一些场景标准内置函数无法满足需求,这时候就需要用到自定义函数。在 Apache Calcite 中添加自定义函数,以便在 SQL 查询中使用自定义的逻辑。这对于执行特定的数据处理或分析任务…...
STM32作业实现(四)光敏传感器
目录 STM32作业设计 STM32作业实现(一)串口通信 STM32作业实现(二)串口控制led STM32作业实现(三)串口控制有源蜂鸣器 STM32作业实现(四)光敏传感器 STM32作业实现(五)温湿度传感器dht11 STM32作业实现(六)闪存保存数据 STM32作业实现(七)OLED显示数据 STM32作业实现(八)触摸按…...

HTML+CSS 文本动画卡片
效果演示 实现了一个图片叠加文本动画效果的卡片(Card)布局。当鼠标悬停在卡片上时,卡片上的图片会变为半透明,同时显示隐藏在图片上的文本内容,并且文本内容有一个从左到右的渐显动画效果,伴随着一个白色渐…...

MongoDB CRUD操作: 在本地实例进行文本搜索查询
MongoDB CRUD操作: 在本地实例进行文本搜索查询 文章目录 MongoDB CRUD操作: 在本地实例进行文本搜索查询举例创建集合创建文本索引精准搜索排除短语结果排序 在本地实例运行文本搜索查询前,必须先在集合上建立文本索引。MongoDB提供文本索引…...

文档智能开源软件
文档智能介绍: 文档智能通常指的是利用人工智能技术来处理和分析文档内容,以实现自动化、智能化的文档管理。文档智能的应用领域非常广泛,包括但不限于: 1. **文档识别**:使用OCR(光学字符识别࿰…...
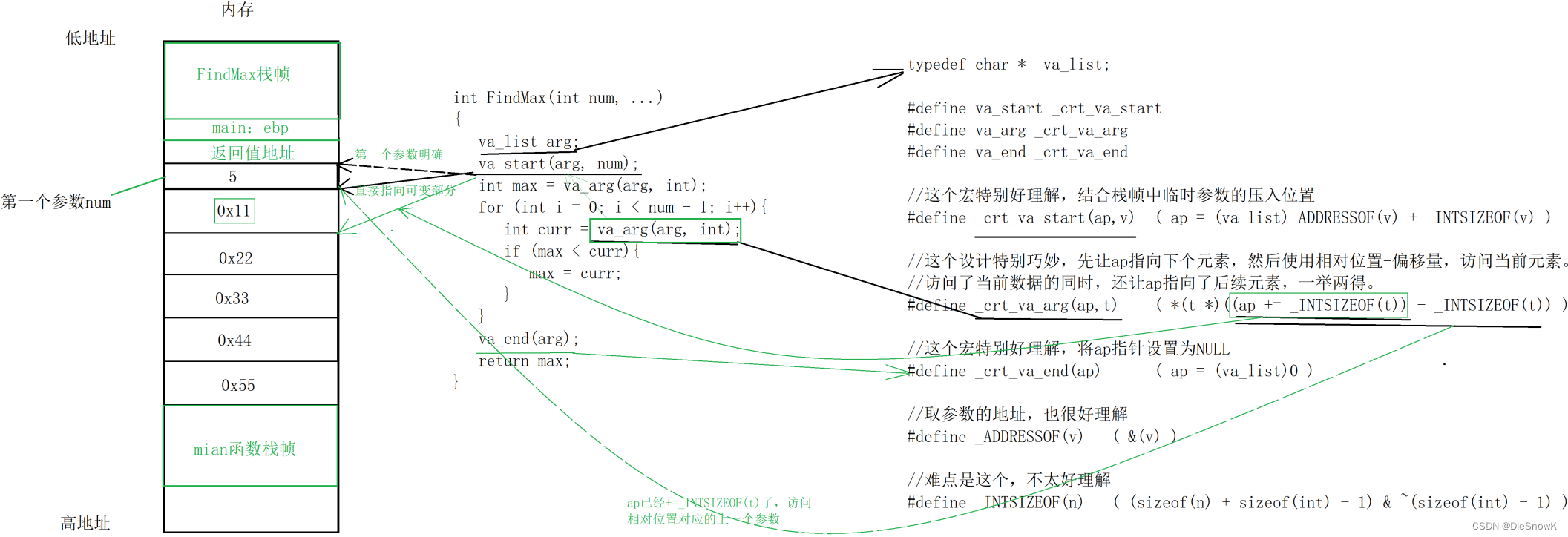
[C][可变参数列表]详细讲解
目录 1.宏含义及使用2.宏原理分析1.原理2.宏理解 1.宏含义及使用 依赖库stdarg.hva_list 其实就是char*类型,方便后续按照字节进行指针移动 va_start(arg, num) 使arg指向可变参数部分(num后面) va_arg(arg, int) 先让arg指向下个元素,然后使用相对位置…...

高校生最适用的AI论文网站是哪款?
国内高校学生在论文写作中越来越依赖AI工具,目前主流方案以本土化全流程工具为核心,结合通用大模型与专业辅助工具,覆盖选题构思、框架搭建、初稿撰写、内容降重、查重检测以及格式排版等关键环节,以下将深入解析并对比当前最适配…...
)
保姆级教程:在K8s集群上部署Triton Inference Server服务(含TensorRT加速配置)
生产级K8s集群部署Triton Inference Server全流程指南 在AI模型工业化落地的浪潮中,如何将训练好的模型高效、稳定地部署到生产环境,成为众多技术团队面临的共同挑战。本文将聚焦Kubernetes集群环境,详细拆解NVIDIA Triton Inference Server…...

从“佩戴感知”到“无感融入”:UWB vs 镜像视界——空间智能的代际跃迁
从“佩戴感知”到“无感融入”:UWB vs 镜像视界——空间智能的代际跃迁空间智能产业正迎来划时代理念革新,行业认知正式完成从主动佩戴式感知向全域无感化融入的核心转变。以UWB为代表的传统定位技术,始终停留在依托外接设备实现信息采集的初…...

5分钟快速上手:如何为Windows安装程序添加简体中文界面支持
5分钟快速上手:如何为Windows安装程序添加简体中文界面支持 【免费下载链接】Inno-Setup-Chinese-Simplified-Translation :earth_asia: Inno Setup Chinese Simplified Translation 项目地址: https://gitcode.com/gh_mirrors/in/Inno-Setup-Chinese-Simplified-…...

口腔诊所装修性价比提升指南
口腔诊所进行装修时,提升性价比的核心在于 “精准投入” ,即在确保医疗功能、患者体验和卫生合规的前提下,实现成本的最优化。1、 规划先行:奠定性价比基石 功能布局优先: 明确划分接待、候诊、诊疗、消毒等功能区&…...
)
ElevenLabs缅甸文语音准确率仅68.3%?实测对比5种预处理方案,第4种提升至92.7%(附Jupyter验证代码)
更多请点击: https://kaifayun.com 第一章:ElevenLabs缅甸文语音准确率实测基准与问题定位 为系统评估 ElevenLabs 对缅甸文(Burmese, my-MM)语音合成的准确性,我们在统一硬件环境(Intel i7-11800H 32GB …...

Windows RTMP流媒体服务器搭建完整指南:nginx-rtmp-win32终极教程
Windows RTMP流媒体服务器搭建完整指南:nginx-rtmp-win32终极教程 【免费下载链接】nginx-rtmp-win32 Nginx-rtmp-module Windows builds. 项目地址: https://gitcode.com/gh_mirrors/ng/nginx-rtmp-win32 想要在Windows系统上快速搭建自己的RTMP直播服务器…...

Windows音频设备切换神器:AudioSwitch让你的音频管理效率提升300%
Windows音频设备切换神器:AudioSwitch让你的音频管理效率提升300% 【免费下载链接】AudioSwitch Switch between default audio input or output change volume 项目地址: https://gitcode.com/gh_mirrors/au/AudioSwitch 还在为Windows系统下繁琐的音频设备…...

免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南
免费压缩包密码恢复工具:ArchivePasswordTestTool终极指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经因为忘记压…...

深入浅出ASoC:用一张图看懂Machine、Platform、Codec在Android音频驱动中的分工与协作
深入浅出ASoC:用一张图看懂Machine、Platform、Codec在Android音频驱动中的分工与协作 在Android音频系统的开发中,ASoC(ALSA System on Chip)框架扮演着至关重要的角色。对于刚接触这一领域的开发者来说,理解Machine、…...