【算法】在?复习一下快速排序?
基本概念
快速排序是一种基于交换的排序算法,该算法利用了分治的思想。
整个算法分为若干轮次进行。在当前轮次中,对于选定的数组范围[left, right],首先选取一个标志元素pivot,将所有小于pivot的元素移至其左侧,大于pivot的则移动至其右侧,记录下最终pivot所处的位置pivot_pos。然后再利用递归,分别对左侧区间[left, pivot_pos - 1]和右侧区间[pivot_pos + 1, left]执行相同操作,依次类推,最终对整个数组完成排序。

以数组[16, 1, 2, 25, 9, 2, 5]为例,在递归实现中,其排序过程中交换策略如下图所示。当pivot_pos与i相等时,不需要交换,之所以先将pivot_pos++再交换的原因是,此时i指向的是小于pivot的元素,而pivot_pos是小于标志元素范围的右边界(如图),如果pivot_pos + 1 = i,则直接将这个右边界扩大1即可,而无需交换。如果不是,则将pivot_pos += 1以指向这个大于pivot的元素,并将其与小于pivot的array[i]进行交换,从而扩大右边界。下面给出了递归实现的示例代码。
int partition(int *array, int left, int right) {// * 默认选定首个元素为划分元素int pivot_pos = left, pivot_val = array[left];// * 遍历,将小于划分元素的值交换至其左侧for (int i = left + 1; i <= right; ++i) {if (array[i] < pivot_val) {pivot_pos += 1;if (pivot_pos != i) {swap(array[i], array[pivot_pos]);}}}array[left] = array[pivot_pos];array[pivot_pos] = pivot_val;return pivot_pos;
}// * 递归版快速排序 O(nlogn)
void quickSort(int *array, int left, int right) {if (left < right) {int pivotpos = partition(array, left, right);quickSort(array, left, pivotpos - 1);quickSort(array, pivotpos + 1, right);}
}
算法分析
时间复杂度:
- 最好情况:每次划分均得到等长的两个子序列, O ( n l o g n ) O(nlogn) O(nlogn);
- 最坏情况:每次划分得到的子序列只比上一层长度少1, O ( n 2 ) O(n^2) O(n2);
- 平均情况: O ( n l o g n ) O(n log_n) O(nlogn)
此外,快速排序是一种不稳定的排序算法。
技巧应用
面试题 17.14. 最小K个数 - 力扣(LeetCode)
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4
输出: [1,2,3,4]
提示:
0 <= len(arr) <= 100000
0 <= k <= min(100000, len(arr))
请注意,上面这个题不要求返回的顺序。我们可以用快速排序对该数组进行排序操作。考虑一下快速排序的流程,是先对整体数组进行划分,然后再依次对划分元素的左侧和右侧进行划分,逐层递归。当划分元素的位置等于k或k + 1时,[0, k - 1]实际上已经是数组前k小的数了,没有必要继续对数组做完全排序,因此可以将pivotpos == k || pivotpos == k + 1作为递归出口。
示例代码如下:
class Solution {
// 采用STL迭代器组合表示待排序的范围range
private:using Iter = vector<int>::iterator;Iter partition(Iter left, Iter right) {Iter pivot_pos = left;int pivot_val = *left;for (Iter i = left + 1; i < right; ++i) {if (*i < pivot_val) {pivot_pos += 1;if (pivot_pos != i) {iter_swap(pivot_pos, i);}}}iter_swap(left, pivot_pos);return pivot_pos;}void quicksort(Iter left, Iter right, Iter tar) {if (left < right) {Iter pivot_pos = partition(left, right);if (pivot_pos > tar + 1) {quicksort(left, pivot_pos, tar);}if (pivot_pos < tar) {quicksort(pivot_pos + 1, right, tar);}// 仅当等于tar或者tar+1时,// 才可判定pivot_pos的左侧范围为前k小或前k+1小}}public:vector<int> smallestK(vector<int>& arr, int k) {if (arr.empty() || k == 0) return {};quicksort(arr.begin(), arr.end(), arr.begin() + k - 1);vector<int> rtn(arr.begin(), arr.begin() + k);return rtn;}
};
拓展
在快速排序算法中,一个关键操作就是选择基准点(Pivot):元素将被此基准点分开成两部分。
最经常使用的就是选择一个区间的首元素或者尾元素,如本文所给出的示例。但是当数组部分有序时,这样做通常会使算法陷入坏情况,从 O ( n l o g n ) O(nlog_n) O(nlogn) 劣化到 O ( n 2 ) O(n^2) O(n2)。
研究人员为此设计了一个快速排序的变体,选择首、尾、中间元素之中的中位数作为基准,依次避免特殊情况下算法劣化到 O ( n 2 ) O(n^2) O(n2)。但是即便性能有所提升,但是仍然有机会针对这种算法设计出一些特殊构造数组,以延长排序时间。这可能会造成服务器计算时间过程,进而为拒绝服务攻击提供可乘之机。
大卫·穆塞尔在1997年提出了内省排序算法introsort。旨在改善上述情况。introsort的主要步骤如下:
- 快速排序:最初使用快速排序对数组进行排序。
- 递归深度检查:在递归过程中,检查当前的递归深度。如果深度超过 2 l o g n 2 logn 2logn,则切换到堆排序。
- 堆排序:当递归深度过深时,使用堆排序对当前子数组进行排序。
- 插入排序:在数组小于一定阈值(通常是16或更小)时,使用插入排序进行排序,以提高小数组排序的效率。
使用这种组合算法,可以在正常快速排序算法的平均和最坏情况下,将时间复杂度均保持为 n l o g n nlogn nlogn。
C++ STL算法库中的sort函数,在早期版本(LWG713之前)未对最坏情况的时间复杂度做要求,那个时候的标准库使用普通qsort实现就符合要求。在此之后,标准对最坏情况的时间复杂度进行了修正,后面的标准库实现版本使用的就是introsort算法。
LWG-xxx : 由 ISO C++ 标准委员会的图书馆工作组(LWG)跟踪的某个特定问题编号。

相关文章:
【算法】在?复习一下快速排序?
基本概念 快速排序是一种基于交换的排序算法,该算法利用了分治的思想。 整个算法分为若干轮次进行。在当前轮次中,对于选定的数组范围[left, right],首先选取一个标志元素pivot,将所有小于pivot的元素移至其左侧,大于…...
matlab安装及破解
一、如何下载 软件下载链接,密码:98ai 本来我想自己生成一个永久百度网盘链接的,但是: 等不住了,所以大家就用上面的链接吧。 二、下载花絮 百度网盘下载速度比上载速度还慢,我给充了个会员,…...
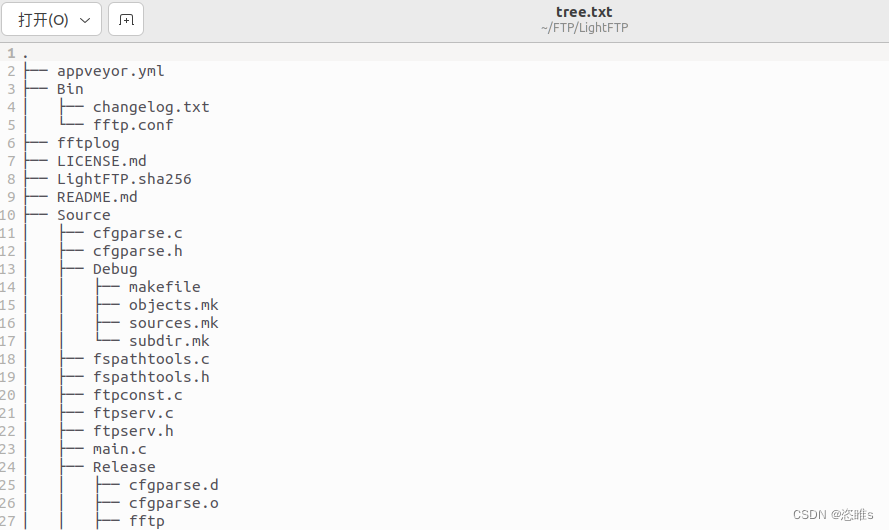
Tree——输出项目的文件结构(Linux)
输出项目中的文件结构可以使用tree命令。tree是一个用于以树状结构显示目录内容的命令行工具。它非常适合快速查看项目的文件结构。安装: sudo apt-get install tree 使用: 在命令行中导航到项目的根目录,输出文件结构。 tree 也可以将结构输…...

UE5 读取本地图片并转换为base64字符串
调试网址:在线图像转Base64 - 码工具 (matools.com) 注意要加(data:image/png;base64,) FString UBasicFuncLib::LoadImageToBase64(const FString& ImagePath) {TArray<uint8> ImageData;// Step 1: 读取图片文件到字节数组if (!…...

【NOIP普及组】税收与补贴问题
【NOIP普及组】税收与补贴问题 💖The Begin💖点点关注,收藏不迷路💖 每样商品的价格越低,其销量就会相应增大。现已知某种商品的成本及其在若干价位上的销量(产品不会低于成本销售),…...

Docker 部署 mysql 服务
linux用法 Container(容器)集合成 Services(服务) 交互集合成 Stack(堆栈)卸载可能存在的旧版本 sudo apt-get update使apt可以通过HTTPS使用存储库(repository) sudo apt-get ins…...

01- Redis 中的 String 数据类型和应用场景
1. 介绍 String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value 其实不仅是字符串,也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M。 2. 内部实现 Str…...

Android音频焦点
什么是音频焦点? 音频焦点是 API 8 中引入的一个概念。它用于传达这样一个事实:用户一次只能专注于一个音频流,例如收听音乐或播客,但不能同时关注两者。在某些情况下,多个音频流可以同时播放,但只有一个是…...

Docker安全配置
Docker安全及日志管理 文章目录 Docker安全及日志管理资源列表基础环境一、Docker安全相关介绍1.1、Docker容器与虚拟机的区别1.1.1、隔离与共享1.1.2、性能与损耗 1.2、Docker存在的安全问题1.2.1、Docker自身漏洞1.2.2、Docker源码问题 1.3、Docker架构缺陷与安全机制1.3.1、…...

文件上传之使用一个属性接收多个文件
在开发过程中,可能遇到这样的业务:文件上传时个数不定,这样我们不能枚举出所有的文件name,这种情况下我们可以使用一个name将所有的文件接收下来; html代码 <!DOCTYPE html> <html lang"en"> …...
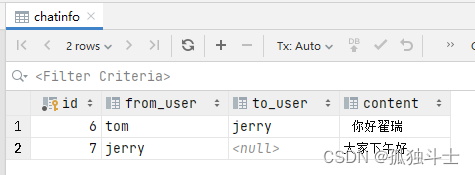
chat4-Server端保存聊天消息到mysql
本文档描述了Server端接收到Client的消息并转发给所有客户端或私发给某个客户端 同时将聊天消息保存到mysql 服务端为当前客户端创建一个线程,此线程接收当前客户端的消息并转发给所有客户端或私发给某个客户端同时将聊天消息保存到mysql 本文档主要总结了将聊天…...

vivo鄢楠:基于OceanBase 的降本增效实践
在3 月 20 日的2024 OceanBase 数据库城市行中,vivo的 体系与流程 IT 部 DBA 组总监鄢楠就“vivo 基于 OceanBase 的降本增效实践”进行了主题演讲。本文为该演讲的精彩回顾。 vivo 在1995年于中国东莞成立,作为一家全球领先的移动互联网智能终端公司&am…...
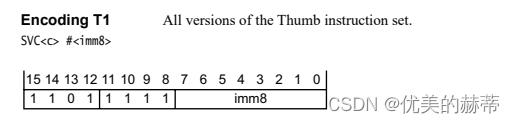
arm cortex-m架构 SVC指令详解以及其在freertos的应用
1. 前置知识 本文基于arm cortex-m架构描述, 关于arm cortex-m的一些基础知识可以参考我另外几篇文章: arm cortex-m 架构简述arm异常处理分析c语言函数调用规范-基于arm 分析 2 SVC指令 2.1 SVC指令位域表示 bit15 - bit12:条件码&#…...

k8s笔记——kubernetes中的三种IP
kubernetes概念 Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控 Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的docker负责容器的运行 Pod:kubernetes的…...

Golang | Leetcode Golang题解之第127题单词接龙
题目: 题解: func ladderLength(beginWord string, endWord string, wordList []string) int {wordId : map[string]int{}graph : [][]int{}addWord : func(word string) int {id, has : wordId[word]if !has {id len(wordId)wordId[word] idgraph a…...
微服务中feign远程调用相关的各种超时问题
1. 引言 在spring cloud微服中,feign远程调用可能是大家每天都接触到东西,但很多同学却没咋搞清楚这里边的各种超时问题,生产环境可能会蹦出各种奇怪的问题。 首先说下结论: 1)只使用feign组件,不使用ribbion组件&…...

springboot整合chatgpt,并且让其可以记录上下文
整合很简单,不过需要几个小条件 1.必须要有openai官方的key 2.国内需要有代理服务器或者国外的服务器把项目部署出去也没问题 我没有使用spring的springAI,听说很方便,日后有机会去体验体验,我今天用了两种方式整合了gpt 1.Ch…...

CTP前端:解码数字世界的魔法师
CTP前端:解码数字世界的魔法师 CTP前端,一个充满神秘与魅力的职业,他们在数字世界中挥舞着魔法棒,创造着令人惊叹的奇迹。那么,CTP前端究竟是做什么的呢?让我们从四个方面、五个方面、六个方面和七个方面&…...

rabbitmq的交换机类型以及他们的区别
RabbitMQ中有四种主要的交换机类型,它们是:Direct,Topic,Fanout,Headers。 Direct(直连交换机):接收到消息后,会将消息发送到与消息的routing key完全匹配的队列上。Dire…...
)
理解不同层的表示(layer representations)
在机器学习和深度学习领域,特别是在处理音频和自然语言处理(NLP)任务时,"层的表示"(layer representations)通常是指神经网络不同层在处理输入数据时生成的特征或嵌入。这些表示捕获了输入数据的…...

多角色对话配音方案:顶伯 一键生成有声剧,支持角色区分
多角色对话配音方案:顶伯 一键生成有声剧,支持角色区分在制作有声剧、播客或短视频时,多角色对话配音往往是最耗时的一环。传统方法需要为每个角色分别录制、剪辑、混音,不仅效率低下,还容易因音色不统一而影响沉浸感。…...

Bilibili旧版界面恢复指南:3步重回经典简洁体验
Bilibili旧版界面恢复指南:3步重回经典简洁体验 【免费下载链接】Bilibili-Old 恢复旧版Bilibili页面,为了那些念旧的人。 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Old 你是否厌倦了B站新版界面的复杂布局?是否怀念那个…...
)
RWKV vs Llama2:在论文审稿任务上,我们为什么第一版选了它?(附长上下文模型选型避坑指南)
RWKV与Llama2在论文审稿任务中的技术选型思考 当面对论文审稿这一知识密集型任务时,模型选型往往成为项目成败的关键。2023年第三季度,我们在构建首个论文审稿GPT系统时,曾在RWKV与Llama2之间面临艰难抉择。本文将深入剖析两种架构的核心差异…...

如何高效实现STL到STEP格式转换?专业工具stltostp实战指南
如何高效实现STL到STEP格式转换?专业工具stltostp实战指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾遇到这样的困境:精心设计的3D模型在STL格式下无法导入…...

58_《智能体微服务架构企业级实战教程》授权与认证之认证方案设计
前言 配套视频教程: 在 Bilibili课堂、CSDN课程、51CTO学堂 同步发售,提供:源码+部署脚本+文档。 bilibili课堂视频教程:智能体微服务架构企业级实战教程_哔哩哔哩_bilibili CSDN课程视频教程:智能体微服务架构企业级实战教程_在线视频教程-CSDN程序员研修院 51CTO学堂…...

Diablo Edit2:暗黑破坏神2存档编辑器终极指南,5分钟掌握角色修改神器
Diablo Edit2:暗黑破坏神2存档编辑器终极指南,5分钟掌握角色修改神器 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾在暗黑破坏神2中花费数小时刷装备却一无所获&…...
)
千问 LeetCode 2478.完美分割的方案数 public int beautifulPartitions(String s, int k, int minLength)
好的,这是 LeetCode 2478 "完美分割的方案数" 的 Java 实现。 解题思路 核心是动态规划 + 前缀和优化: 1. 定义状态:dp[i][j] 表示前 i 个字符分成 j 段的方案数 2. 状态转移:对于每个可能的分割点,需要满足: - 当前段长度 ≥ minLength - 当前段首字…...
)
直线模组选型别再“先选电机“了!导程才是起点(附正向推导五步法)
引言:一个高频"翻车"现场在直线模组(丝杆模组)选型中,有个环节经常出现逆向翻车——工程师先选好了电机,再去配丝杆导程,结果发现:❌ 速度上不去❌ 推力不够大❌ 电机严重发热问题的根…...

5分钟快速上手Mermaid Live Editor:免费在线图表编辑器完全指南
5分钟快速上手Mermaid Live Editor:免费在线图表编辑器完全指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-li…...

百度网盘直链解析工具:三步实现全速下载的终极方案
百度网盘直链解析工具:三步实现全速下载的终极方案 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 百度网盘作为国内主流云存储平台,其下载限速问题一直…...