德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第四周) - 语言建模
语言建模
- 1. 统计语言模型
- 2. N-gram语言建模
- 2.1. N-gram语言模型中的平滑处理
- 3. 语言模型评估
- 4. 神经语言模型
- 5. 循环神经网络
- 5.1. Vanilla RNN
- 5.2. LSTM
1. 统计语言模型
统计语言模型旨在量化自然语言文本中序列的概率分布,即计算一个词序列(如一个句子或文档)出现的可能性。这类模型基于统计方法,利用大量文本数据学习语言的统计规律,进而预测未知文本的概率,或者为给定的文本序列生成最可能的后续词汇。
统计语言模型的核心思想是将语言视为一个随机过程,每一个词的选择都受到其上下文的影响。模型通常定义为一个概率函数,比如假设一个句子由 T T T个单词顺序组成:
W = w T : = ( w 1 , w 2 , ⋯ , w T ) W = w^{T} := (w_{1}, w_{2}, \cdots, w_{T}) W=wT:=(w1,w2,⋯,wT)
那么该句子的联合概率如下:
p ( w T ) = p ( w 1 ) ⋅ p ( w 2 ∣ w 1 ) ⋅ p ( w 3 ∣ w 1 2 ) ⋯ p ( w T ∣ x 1 T − 1 ) p(w^{T}) = p(w_{1}) \cdot p(w_{2}|w_{1}) \cdot p(w_{3}|w_{1}^{2}) \cdots p(w_{T}|x_{1}^{T-1}) p(wT)=p(w1)⋅p(w2∣w1)⋅p(w3∣w12)⋯p(wT∣x1T−1)
其中,模型参数为:
p ( w 1 ) , p ( w 2 ∣ w 1 ) , p ( w 3 ∣ w 1 2 ) , ⋯ , p ( w T ∣ w 1 T − 1 ) p(w_{1}), p(w_{2}|w_{1}) , p(w_{3}|w_{1}^{2}), \cdots, p(w_{T}|w_{1}^{T-1}) p(w1),p(w2∣w1),p(w3∣w12),⋯,p(wT∣w1T−1)
根据贝叶斯公式可得:
p ( w k ∣ w 1 k − 1 ) = p ( w 1 k ) p ( w 1 k − 1 ) p(w_{k}|w_{1}^{k-1}) = \frac{p(w_{1}^{k})}{p(w_{1}^{k-1})} p(wk∣w1k−1)=p(w1k−1)p(w1k)
根据大数定理可得:
p ( w k ∣ w 1 k − 1 ) ≈ c o u n t ( w 1 k ) c o u n t ( w 1 k − 1 ) p(w_{k}|w_{1}^{k-1}) \approx \frac{count(w_{1}^{k})}{count(w_{1}^{k-1})} p(wk∣w1k−1)≈count(w1k−1)count(w1k)
其中count表示统计词串在语料中的出现次数,当k比较大时,上述计算比较耗时。
2. N-gram 语言建模
N-gram模型是一种统计语言模型,用于预测给定文本中下一个词(或字符)的概率。该模型基于一个简化的假设:一个词(或字符)的出现概率只依赖于它前面的N-1个词(或字符),也就是n-1阶的马尔科夫假设。这里的N代表了模型考虑的上下文窗口大小,因此模型被称为N-gram。
p ( w k ∣ w 1 k − 1 ) ≈ p ( w k ∣ w k − n + 1 k − 1 ) ≈ count ( w k − n + 1 k ) count ( w k − n + 1 k − 1 ) \begin{aligned} p(w_{k}|w_{1}^{k-1}) &\approx p(w_{k}|w_{k-n+1}^{k-1}) \\ &\approx \frac{\text{count}(w_{k-n+1}^{k})}{\text{count}(w_{k-n+1}^{k-1})} \end{aligned} p(wk∣w1k−1)≈p(wk∣wk−n+1k−1)≈count(wk−n+1k−1)count(wk−n+1k)
N-gram模型中的概率通常通过从大型文本语料库中计算词序列的频次来估计。具体来说,使用最大似然估计(Maximum Likelihood Estimation, MLE)计算每个N-gram的概率,这些概率可以通过简单地统计每个N-gram在语料库中出现的频次来估计。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到,然后可以使用这些概率来计算给定上下文情况下下一个词或字符的概率。常用的是二元(Bi-gram)建模和三元(Tri-gram)建模。
例如,在一个句子"ChatGPT is a powerful language model"中,如果我们使用2-gram,那么句子可以被分成以下2-gram序列:[“ChatGPT is”, “is a”, “a powerful”, “powerful language”, “language model”]。假设我们有一个足够大的文本语料库,其中包含很多句子。我们可以使用2-gram语言模型来计算给定一个词的前提下,下一个词出现的概率。如果我们想要预测句子中的下一个词,我们可以使用前面的一个词作为上下文,并计算每个可能的下一个词的概率。例如,在句子"ChatGPT is a"中,我们可以计算出给定上下文"ChatGPT is"下一个词"powerful"的概率。通过统计语料库中"ChatGPT is"后面是"powerful"的次数,并将其除以"ChatGPT is"出现的次数,我们可以得到这个概率。
2.1. N-gram 语言模型中的平滑处理
在统计语言模型中,平滑操作是至关重要的一个步骤,主要目的是解决以下几个关键问题:
- 零概率问题(Zero Frequency Problem):在基于计数的统计语言模型中,如果某个词或词序列在训练数据中没有出现过,那么其概率会被直接估计为零,这显然不符合实际情况,因为未观测到并不意味着不可能发生。平滑通过分配一些概率质量给这些零频率事件,确保所有可能的事件都有非零的概率。
- 数据稀疏性:自然语言具有极大的词汇量和结构多样性,即使是大型语料库也难以覆盖所有可能的词序列组合,导致许多长尾或罕见事件的计数非常少。平滑帮助模型更好地泛化到未见过的数据,减少因数据不足引起的过拟合。
- 模型稳定性:极端的计数(如极高或极低频词)可能会导致模型对训练数据中的噪声过度敏感。平滑通过减少这种极端情况的影响,提高模型的稳定性和鲁棒性。
- 促进泛化能力:通过减少对高频项的过分信任,同时给予低频项一定的机会,平滑有助于模型学习到更普遍的语言规律,提高在新数据上的表现。
常见的平滑技术包括但不限于:
- 加一平滑(Additive Smoothing, 拉普拉斯平滑):对所有计数加1,包括未出现的事件。
- 古德-图灵估计(Good-Turing Smoothing):基于实际观察到的频率分布来估计未见事件的概率。
- 绝对减值平滑(Absolute Discounting):从高频率计数中减去一个固定值,再进行重新分配。
- Kneser-Ney Smoothing:特别处理尾随事件,改进对未登录词的处理。
- 插值平滑(Interpolation):结合不同N-gram模型的结果,如Jelinek-Mercer平滑。
平滑不仅是统计语言模型构建中的一个必要步骤,也是提升模型实用性和准确性的重要手段。
以2-gram为例,最大似然估计如下:
p ( w i ∣ w i − 1 ) = c ( w i − 1 w i ) c ( w i − 1 ) p(w_i|w_{i-1}) = \frac{c(w_{i-1} w_i)}{c(w_{i-1})} p(wi∣wi−1)=c(wi−1)c(wi−1wi)
以上其实就是简单的计数,然后我们就要在这里去做平滑,其实就是减少分母为0的出现。拉普拉斯平滑如下:
p add ( w i ∣ w i − 1 ) = c ( w i − 1 w i ) + δ c ( w i − 1 ) + δ ∣ V ∣ p_{\text{add}}(w_i|w_{i-1}) = \frac{c(w_{i-1} w_i) + \delta}{c(w_{i-1}) + \delta |V|} padd(wi∣wi−1)=c(wi−1)+δ∣V∣c(wi−1wi)+δ
一般地, δ \delta δ取1, ∣ V ∣ |V| ∣V∣表示词典库的大小。
- 2-gram 模型的 Python 实现
基于二元模型的简单示例,包括数据预处理、构建模型、平滑处理以及基于模型进行预测。
import collectionsclass BigramLanguageModel:def __init__(self, sentences: list):"""初始化Bigram模型:param sentences: 训练语料,类型为字符串列表"""self.sentences = sentencesself.word_counts = collections.Counter()self.bigram_counts = collections.defaultdict(int)self.unique_words = set()# 预处理数据:分词并合并所有句子words = ' '.join(sentences).split()for w1, w2 in zip(words[:-1], words[1:]):self.word_counts[w1] += 1self.word_counts[w2] += 1self.bigram_counts[(w1, w2)] += 1self.unique_words.update([w1, w2])def laplace_smooth(self, delta: float = 1.0):"""拉普拉斯平滑:param delta: 平滑因子,默认为1.0"""V = len(self.unique_words) # 词汇表大小self.model = {}for w1 in self.unique_words:total_count_w1 = self.word_counts[w1] + delta*Vself.model[w1] = {}for w2 in self.unique_words:count_w1w2 = self.bigram_counts.get((w1, w2), 0) + deltaself.model[w1][w2] = count_w1w2 / total_count_w1def generate_text(self, start_word: str, length: int = 10) -> str:"""生成文本:param start_word: 文本起始词:param length: 生成文本的长度:return: 生成的文本字符串"""if start_word not in self.model:raise ValueError(f"Start word '{start_word}' not found in the model.")sentence = [start_word]current_word = start_wordfor _ in range(length):next_word_probs = self.model[current_word]next_word = max(next_word_probs, key=next_word_probs.get)sentence.append(next_word)current_word = next_wordreturn ' '.join(sentence)# 示例使用
corpus = ["ChatGPT is a powerful language model for multi task","ChatGPT is a powerful language model","ChatGPT can generate human-like text","ChatGPT is trained using deep learning",
]model = BigramLanguageModel(corpus)
model.laplace_smooth()
generated_text = model.generate_text('ChatGPT', 5)
print(generated_text) # ChatGPT is a powerful language model
3. 语言模型评估
准确率作为语言模型的评估指标没有太多意义,语言是开放的序列预测问题,给定前面的文本,下一个词的可能性是非常多的,因此准确率值会非常低。
作为替代,应该在模型保留数据(held-out data)上,计算其对应的似然性(取平均值以消除长度影响)来评估语言模型。对数似然(log likelihood,LL)计算如下:
LL ( W ) = 1 n ∑ i = 1 n log P ( w i ∣ w 1 , ⋯ , w i − 1 ) \text{LL}(W) = \frac{1}{n} \sum_{i=1}^n \log P(w_i|w_1, \cdots, w_{i-1}) LL(W)=n1i=1∑nlogP(wi∣w1,⋯,wi−1)
保留数据:指在训练语言模型时,专门保留一部分数据不参与训练,用作评估模型性能的数据集。这确保了评估数据独立于训练数据,能够真实反映模型在新数据上的泛化能力。
困惑度(Perplexity,PPL)是评价语言模型质量的一个重要指标,能够更好地体现语言模型对句子流畅性、语义连贯性的建模能力。困惑度是指数形式的平均负对数似然,计算如下:
PPL ( W ) = exp ( NLL ( W ) ) = exp ( − LL ( W ) ) \text{PPL}(W) = \exp (\text{NLL}(W) ) = \exp (- \text{LL}(W) ) PPL(W)=exp(NLL(W))=exp(−LL(W))
对数似然:给定语料库数据,对数似然衡量模型为这些数据赋予的概率的对数值。对数似然越高,模型对数据的建模能力越强。
负对数似然:由于对数似然值通常是个负值,取负号得到正值更利于分析比较。
平均负对数似然:将负对数似然值加总后除以数据长度(如词数),得到平均负对数似然。这样可以消除数据长度的影响,更公平地比较不同模型。
指数形式:将平均负对数似然值做指数运算,得到Perplexity值。由于似然本身很小,对数似然为负值,做指数能使结果值落在较合理的范围。
困惑度本质上反映了模型对数据的平均怀疑程度。值越低,说明模型对数据的建模质量越高、不确定性越小。通常优秀模型的困惑度值在10-100之间,值越接近1越好。
4. 神经语言模型
神经语言模型(Neural Language Model, NLM)是一种利用神经网络来建模和生成自然语言序列的模型。相比传统的统计语言模型(如n-gram模型),神经语言模型具有以下几个主要特点:
- 神经网络的强大建模能力:神经网络能够自动从大量数据中学习复杂的特征模式,克服了传统模型需要人工设计特征的缺陷,无需人工特征工程。
- 分布式词向量表示:将每个词映射为一个连续的向量表示,能够自然地捕捉词与词之间的语义和句法关联。
- 长距离依赖建模:传统n-gram模型只考虑有限历史窗口,神经网络可以更好地学习长程语境依赖关系。
- 泛化能力更强:神经网络内部分布式表示有助于更好的泛化,可以很好地应对未见数据。
常见神经语言模型有基于RNN、LSTM、Transformer等不同网络架构,并广泛应用于语言建模、机器翻译、对话系统等自然语言处理任务中。神经语言模型弥补了传统模型的不足,极大地推进了语言模型的发展,但也面临训练资源需求大、解释性较差等新的挑战。
5. 循环神经网络
前馈神经网络(Feedforward NNs)无法处理可变长度的输入,特征向量中的每个位置都有固定的语义。使用传统前馈神经网络作为语言模型时的主要缺陷和局限性如下:
- 前馈神经网络要求输入是固定长度的向量,输入向量中每个位置的元素都对应特定的语义含义。但在自然语言处理任务中,输入序列(如句子或文本)的长度是可变的,不同的输入会有不同的序列长度。
- 前馈神经网络位置语义固定,对于不同长度的输入序列,每个位置的语义无法自动对应和调整。为了将变长序列映射到固定向量,不可避免需要截断或填充,这会导致信息损失或人为噪声的引入。
为了解决这个问题,出现了诸如循环神经网络(RNN)、长短期记忆网络(LSTM)等能够更好地处理序列输入的神经网络架构。
5.1. Vanilla RNN
循环神经网络是一种可以接受变长输入和产生变长输出的网络架构类型,这与标准的前馈神经网络形成对比。我们也可以考虑变长的输入,比如视频帧序列,并希望在该视频的每一帧上都做出决策。

- 一对一:经典的前馈神经网络架构,其中有一个输入并期望一个输出。
- 一对多:可以将其视为图像描述生成。有一个固定大小的图像作为输入,输出可以是长度可变的单词或句子。
- 多对一:用于情感分类。输入预期为一系列单词或甚至是段落。输出可以是具有连续值的回归输出,表示具有积极情感的可能性。
- 多对多:该模型非常适合机器翻译。输入可以是变长的英语句子,输出将是相同句子的另一种语言版本,其长度也可变。最后一个多对多模型可以用于基于词级别的机器翻译。将英语句子的每一个词输入神经网络,并期望立即得到输出。然而,由于词通常彼此相关,因此需要将网络的隐藏状态从上一个词传递到下一个词。因此,我们需要循环神经网络来处理这种任务。
对于循环神经网络,我们可以在每个时间步应用递推公式来处理向量序列:
h t = f W ( h t − 1 , x t ) h_t = f_W(h_{t-1}, x_t) ht=fW(ht−1,xt)
对于简单的 Vanilla 循环神经网络来说,计算公式如下:
h t = tanh ( W h h h t − 1 + W x h x t + b h ) y t = W h y h t + b y \begin{aligned} h_t &= \tanh (W_{hh} h_{t-1} + W_{xh} x_t + b_h) \\ y_t &= W_{hy} h_t + b_y \end{aligned} htyt=tanh(Whhht−1+Wxhxt+bh)=Whyht+by
- Vanilla RNN 的 Python 实现
import numpy as npnp.random.seed(0)class RecurrentNetwork(object):"""When we say W_hh, it means a weight matrix that accepts a hidden state and produce a new hidden state.Similarly, W_xh represents a weight matrix that accepts an input vector and produce a new hidden state. Thisnotation can get messy as we get more variables later on with LSTM and I simplify the notation a little bit inLSTM notes."""def __init__(self):self.hidden_state = np.zeros((3, 3))self.W_hh = np.random.randn(3, 3)self.W_xh = np.random.randn(3, 3)self.W_hy = np.random.randn(3, 3)self.Bh = np.random.randn(3,)self.By = np.random.rand(3,)def forward_prop(self, x):# The order of which you do dot product is entirely up to you. The gradient updates will take care itself# as long as the matrix dimension matches up.self.hidden_state = np.tanh(np.dot(self.hidden_state, self.W_hh) + np.dot(x, self.W_xh) + self.Bh)return self.W_hy.dot(self.hidden_state) + self.Byinput_vector = np.ones((3, 3))
rnn = RecurrentNetwork()# Notice that same input, but leads to different ouptut at every single time step.
print(rnn.forward_prop(input_vector))
print(rnn.forward_prop(input_vector))
print(rnn.forward_prop(input_vector))
5.2. LSTM
虽然 Vanilla RNN 在处理序列数据方面具有一定的能力,但它在长期依赖性建模方面存在一些挑战。长短期记忆网络(Long Short Term Memory, LSTM )是一种特殊类型的 RNN,通过引入细胞状态(cell state)和门控机制来解决长期依赖性问题。以下是 LSTM 相对于 Vanilla RNN 的一些优点和特点:
- 处理长期依赖性问题:Vanilla RNN 在处理长序列时容易发生梯度消失或梯度爆炸的问题,导致无法有效地捕捉长期依赖关系。LSTM 通过细胞状态和门控机制,能够更好地捕捉和传递长期依赖性信息,使得网络能够更好地学习并记住与序列任务相关的远距离依赖关系。
- 门控机制:LSTM 引入了三个门控单元:输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。这些门控单元通过使用适当的权重来控制信息的流动,决定哪些信息应该被保留、遗忘或输出。这种门控机制使得 LSTM 能够自适应地选择性地记住或遗忘相关信息,增强了网络的记忆和泛化能力。
- 细胞状态:LSTM 引入了细胞状态(cell state),作为网络的记忆单元。细胞状态在时间步长中一直传递,并且可以选择性地更新或清除信息。这种机制使得 LSTM 能够更好地处理长期依赖性,同时减少了梯度传播中的问题。
- 灵活性和建模能力:LSTM 具有更强大的建模能力,能够处理更复杂和多样化的序列任务。通过适当的设计和调整,LSTM 可以学习到不同时间尺度上的模式,对输入序列中的关键事件和特征进行建模。
LSTM 相对于 Vanilla RNN 具有更强的记忆和建模能力,能够更好地处理长期依赖性和序列任务。它通过引入细胞状态和门控机制,解决了 Vanilla RNN 在处理长序列时出现的梯度消失和梯度爆炸问题。

LSTM 计算过程如下:
f t = σ ( W h f h t − 1 + W x f x + b f ) i t = σ ( W h i h t − 1 + W x i x + b i ) o t = σ ( W h o h t − 1 + W x o x + b o ) c t = f t ⊙ c t 1 + i t ⊙ tanh ( W g x x + W g h h t − 1 + b g ) h t = o t ⊙ tanh ( c t ) \begin{aligned} f_t &= \sigma(W_{hf} h_{t-1} + W_{xf} x + b_f) \\ i_t &= \sigma(W_{hi} h_{t-1} + W_{xi} x + b_i) \\ o_t &= \sigma(W_{ho} h_{t-1} + W_{xo} x + b_o) \\ c_t &= f_t \odot c_{t_1} + i_t \odot \tanh(W_{gx} x + W_{gh} h_{t-1} + b_g) \\ h_t &= o_t \odot \tanh(c_t) \end{aligned} ftitotctht=σ(Whfht−1+Wxfx+bf)=σ(Whiht−1+Wxix+bi)=σ(Whoht−1+Wxox+bo)=ft⊙ct1+it⊙tanh(Wgxx+Wghht−1+bg)=ot⊙tanh(ct)
其中, f t f_t ft表示遗忘门,控制记忆的遗忘程度; i t i_t it表示输入门,控制信息写入状态单元的程度; o t o_t ot表示输出门,控制状态单元的暴露程度; c t c_t ct表示状态单元,负责内部记忆; h t h_t ht表示隐藏单元,负责对外暴露信息。
- LSTM 的 Python 实现
import numpy as npnp.random.seed(0)class LSTMNetwork(object):def __init__(self):self.hidden_state = np.zeros((3, 3))self.cell_state = np.zeros((3, 3))self.W_hh = np.random.randn(3, 3)self.W_xh = np.random.randn(3, 3)self.W_ch = np.random.randn(3, 3)self.W_fh = np.random.randn(3, 3)self.W_ih = np.random.randn(3, 3)self.W_oh = np.random.randn(3, 3)self.W_hy = np.random.randn(3, 3)self.Bh = np.random.randn(3,)self.By = np.random.randn(3,)def forward_prop(self, x):# Input gatei = sigmoid(np.dot(x, self.W_xh) + np.dot(self.hidden_state, self.W_hh) + np.dot(self.cell_state, self.W_ch))# Forget gatef = sigmoid(np.dot(x, self.W_xh) + np.dot(self.hidden_state, self.W_hh) + np.dot(self.cell_state, self.W_fh))# Output gateo = sigmoid(np.dot(x, self.W_xh) + np.dot(self.hidden_state, self.W_hh) + np.dot(self.cell_state, self.W_oh))# New cell statec_new = np.tanh(np.dot(x, self.W_xh) + np.dot(self.hidden_state, self.W_hh))self.cell_state = f * self.cell_state + i * c_newself.hidden_state = o * np.tanh(self.cell_state)return np.dot(self.hidden_state, self.W_hy) + self.Bydef sigmoid(x):return 1 / (1 + np.exp(-x))input_vector = np.ones((3, 3))
lstm = LSTMNetwork()# Notice that the same input will lead to different outputs at each time step.
print(lstm.forward_prop(input_vector))
print(lstm.forward_prop(input_vector))
print(lstm.forward_prop(input_vector))
- LSTM 的缺陷
LSTM 可以一定程度上缓解梯度消失问题,但对于非常长的序列或复杂的任务,仍然存在一定的限制。除了梯度消失问题,LSTM 在处理序列时也存在性能上的限制。由于它们是逐步处理序列的,无法充分利用并行计算的优势。对于长度为 n 的序列,LSTM 需要执行 O(n) 的非并行操作来进行编码,导致速度较慢。
为了克服这些限制,提出了 Transformer 模型作为解决方案。Transformer 可以扩展到处理数千个单词的序列,并且能够并行计算。它引入了自注意力机制和位置编码,使得模型能够同时关注序列中不同位置的信息,并且能够以高效的方式对输入进行编码。这使得 Transformer 在处理长序列和大规模数据时具有优势,并且在机器翻译和自然语言处理等领域取得了显著的成功。
- 相关阅读
Understanding LSTM Networks
Vanilla Recurrent Neural Network
LSTM Recurrent Neural Network
相关文章:
德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第四周) - 语言建模
语言建模 1. 统计语言模型2. N-gram语言建模 2.1. N-gram语言模型中的平滑处理 3. 语言模型评估4. 神经语言模型5. 循环神经网络 5.1. Vanilla RNN5.2. LSTM 1. 统计语言模型 统计语言模型旨在量化自然语言文本中序列的概率分布,即计算一个词序列(如一…...

Jitsi meet 退出房间后,用户还在房间内
前言 Jitsi Meet 如果客户端非正常退出会议,会产生用户还在房间内,实际用户已经退出的情况,需要一段时间内,才会在UI离开房间,虽然影响不大,但是也容易导致体验不好。 保活 Jitsi Meet 会和前端做一个保…...

Java 18 新特性
Java 作为一门广泛应用于企业级开发和系统编程的编程语言,一直以来都在不断进化和改进。2022 年发布的 Java 18 版本为开发者带来了一些新的特性和改进,这些特性不仅提升了开发效率,还进一步增强了 Java 语言的功能和灵活性。本文将深入探讨 …...

c++基础创建对象
在C中,test a; 和 test a new test(); 是两种不同的初始化或创建对象的方式,而且它们之间存在根本的区别。 test a; 这是对象a的栈上分配。在声明test a;时,编译器会在栈上为a分配内存,并调用test类的默认构造函数(…...
- docker)
WHAT - 容器化系列(二)- docker
目录 一、前言二、Docker镜像:可运行软件包三、Docker容器:可执行环境四、容器和镜像的关系五、创建镜像的过程5.1 编写Dockerfile5.2 构建Docker镜像5.3 查看构建的镜像5.4 运行Docker容器5.5 验证容器运行状态5.6 推送镜像到镜像仓库(可选&…...

力扣 19题 删除链表的倒数第 N 个结点 记录
题目描述 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: 输入:head [1], n 1 输出:[]示例 3&am…...
)
渗透测试之Web安全系列教程(二)
今天,我们来讲一下Web安全! 本文章仅提供学习,切勿将其用于不法手段! 目前,在渗透测试领域,主要分为了两个发展方向,分别为Web攻防领域和PWN(二进制安全)攻防领域。Web…...

【算法】在?复习一下快速排序?
基本概念 快速排序是一种基于交换的排序算法,该算法利用了分治的思想。 整个算法分为若干轮次进行。在当前轮次中,对于选定的数组范围[left, right],首先选取一个标志元素pivot,将所有小于pivot的元素移至其左侧,大于…...
matlab安装及破解
一、如何下载 软件下载链接,密码:98ai 本来我想自己生成一个永久百度网盘链接的,但是: 等不住了,所以大家就用上面的链接吧。 二、下载花絮 百度网盘下载速度比上载速度还慢,我给充了个会员,…...
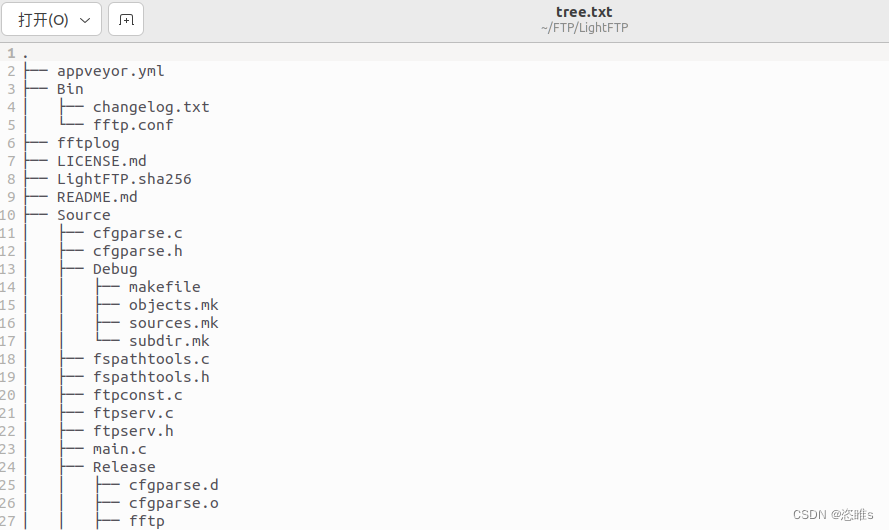
Tree——输出项目的文件结构(Linux)
输出项目中的文件结构可以使用tree命令。tree是一个用于以树状结构显示目录内容的命令行工具。它非常适合快速查看项目的文件结构。安装: sudo apt-get install tree 使用: 在命令行中导航到项目的根目录,输出文件结构。 tree 也可以将结构输…...

UE5 读取本地图片并转换为base64字符串
调试网址:在线图像转Base64 - 码工具 (matools.com) 注意要加(data:image/png;base64,) FString UBasicFuncLib::LoadImageToBase64(const FString& ImagePath) {TArray<uint8> ImageData;// Step 1: 读取图片文件到字节数组if (!…...

【NOIP普及组】税收与补贴问题
【NOIP普及组】税收与补贴问题 💖The Begin💖点点关注,收藏不迷路💖 每样商品的价格越低,其销量就会相应增大。现已知某种商品的成本及其在若干价位上的销量(产品不会低于成本销售),…...

Docker 部署 mysql 服务
linux用法 Container(容器)集合成 Services(服务) 交互集合成 Stack(堆栈)卸载可能存在的旧版本 sudo apt-get update使apt可以通过HTTPS使用存储库(repository) sudo apt-get ins…...

01- Redis 中的 String 数据类型和应用场景
1. 介绍 String 是最基本的 key-value 结构,key 是唯一标识,value 是具体的值,value 其实不仅是字符串,也可以是数字(整数或浮点数),value 最多可以容纳的数据长度是 512M。 2. 内部实现 Str…...

Android音频焦点
什么是音频焦点? 音频焦点是 API 8 中引入的一个概念。它用于传达这样一个事实:用户一次只能专注于一个音频流,例如收听音乐或播客,但不能同时关注两者。在某些情况下,多个音频流可以同时播放,但只有一个是…...

Docker安全配置
Docker安全及日志管理 文章目录 Docker安全及日志管理资源列表基础环境一、Docker安全相关介绍1.1、Docker容器与虚拟机的区别1.1.1、隔离与共享1.1.2、性能与损耗 1.2、Docker存在的安全问题1.2.1、Docker自身漏洞1.2.2、Docker源码问题 1.3、Docker架构缺陷与安全机制1.3.1、…...

文件上传之使用一个属性接收多个文件
在开发过程中,可能遇到这样的业务:文件上传时个数不定,这样我们不能枚举出所有的文件name,这种情况下我们可以使用一个name将所有的文件接收下来; html代码 <!DOCTYPE html> <html lang"en"> …...
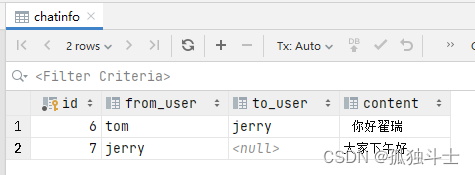
chat4-Server端保存聊天消息到mysql
本文档描述了Server端接收到Client的消息并转发给所有客户端或私发给某个客户端 同时将聊天消息保存到mysql 服务端为当前客户端创建一个线程,此线程接收当前客户端的消息并转发给所有客户端或私发给某个客户端同时将聊天消息保存到mysql 本文档主要总结了将聊天…...

vivo鄢楠:基于OceanBase 的降本增效实践
在3 月 20 日的2024 OceanBase 数据库城市行中,vivo的 体系与流程 IT 部 DBA 组总监鄢楠就“vivo 基于 OceanBase 的降本增效实践”进行了主题演讲。本文为该演讲的精彩回顾。 vivo 在1995年于中国东莞成立,作为一家全球领先的移动互联网智能终端公司&am…...
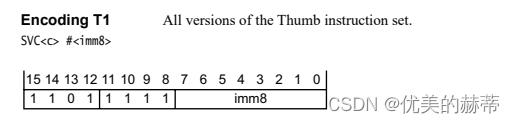
arm cortex-m架构 SVC指令详解以及其在freertos的应用
1. 前置知识 本文基于arm cortex-m架构描述, 关于arm cortex-m的一些基础知识可以参考我另外几篇文章: arm cortex-m 架构简述arm异常处理分析c语言函数调用规范-基于arm 分析 2 SVC指令 2.1 SVC指令位域表示 bit15 - bit12:条件码&#…...

硬件开发、智能硬件与硬件系统:三层架构解析与实践指南
1. 项目概述:从零开始理解硬件世界的三层架构干了十几年硬件,从画第一块单片机最小系统板,到参与设计复杂的智能穿戴设备,我越来越觉得,很多刚入行的朋友,甚至一些软件背景的同事,对“硬件”这个…...

从硬件小白到Ryzen调优专家:SMUDebugTool实战进阶指南
从硬件小白到Ryzen调优专家:SMUDebugTool实战进阶指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gi…...

Downkyi完全指南:三步掌握B站视频下载的10个高效技巧
Downkyi完全指南:三步掌握B站视频下载的10个高效技巧 【免费下载链接】downkyi 哔哩下载姬downkyi,哔哩哔哩网站视频下载工具,支持批量下载,支持8K、HDR、杜比视界,提供工具箱(音视频提取、去水印等&#x…...

SkyWalking UI 保姆级使用指南:从仪表盘到告警,手把手教你排查线上问题
SkyWalking UI 实战指南:从异常告警到代码级优化的全链路排查 当凌晨三点的告警短信突然亮起屏幕,作为值班工程师的你该如何快速定位线上服务的性能瓶颈?SkyWalking UI 提供的不仅是数据看板,更是一套完整的分布式系统诊断工具箱。…...

BEP-20代币全解析:从原理到实战,赋能Web3开发
BEP-20代币全解析:从原理到实战,赋能Web3开发 引言 在百花齐放的区块链世界中,币安智能链(BNB Chain) 凭借其低廉的手续费与闪电般的交易速度,迅速成为众多开发者和项目方的热土。而这一切繁荣生态的基石…...

魔百盒CM311-1s刷机后体验:安卓9.0固件到底香不香?附5621DS无线实测
魔百盒CM311-1s刷机实战:安卓9.0系统深度评测与无线性能揭秘 当手中的魔百盒CM311-1s遇上安卓9.0系统,这场硬件与软件的碰撞会擦出怎样的火花?作为一款搭载S905L3B芯片的电视盒子,其原生系统往往受限于运营商定制化限制࿰…...

传奇3手游网站下载 元素搭配攻略 新手快速上手复古服
官方出版资质:传奇3光通版手游由传奇3G原班人马打造,出版单位华东师范大学电子音像出版社有限公司,审批文号新广出审〔2016〕2183号,出版物号ISBN978-7-7979-0843-6,运营主体安徽游昕网络科技有限公司,官网…...

一文搞懂 MySQL:一条 SQL 语句的完整执行之旅
你是否每天都在写 SQL,却从未想过它在 MySQL 内部是如何一步步执行的?今天我们就通过这张经典的 MySQL 执行流程图,带你拆解一条 SQL 从客户端发送到结果返回的完整过程,搞懂这个过程,你就能轻松理解 SQL 优化、事务原…...

3步打造高效macOS菜单栏:Hidden Bar深度使用指南
3步打造高效macOS菜单栏:Hidden Bar深度使用指南 【免费下载链接】hidden An ultra-light MacOS utility that helps hide menu bar icons 项目地址: https://gitcode.com/gh_mirrors/hi/hidden 作为macOS用户,你是否曾为菜单栏图标拥挤不堪而烦恼…...

FPGA设计避坑指南:Vivado里那些红色和橙色的时钟交互框到底意味着什么?
FPGA设计避坑指南:Vivado里那些红色和橙色的时钟交互框到底意味着什么? 在FPGA设计的世界里,时钟信号就像城市交通系统中的红绿灯,协调着数据流的行进节奏。而当多个时钟域交汇时,就如同多个交通系统试图相互对接——如…...