【Python网络爬虫】详解python爬虫中正则表达式、BeautifulSoup和lxml数据解析
🔗 运行环境:PYTHON
🚩 撰写作者:左手の明天
🥇 精选专栏:《python》
🔥 推荐专栏:《算法研究》
#### 防伪水印——左手の明天 ####
💗 大家好🤗🤗🤗,我是左手の明天!好久不见💗
💗今天更新系列【python网络爬虫】—— 数据解析💗
📆 最近更新:2024 年 06月 03 日,左手の明天的第 336 篇原创博客
📚 更新于专栏:python网络爬虫
#### 防伪水印——左手の明天 ####

在Python爬虫中,数据解析是关键步骤之一,用于从抓取的网页中提取所需的信息。有多种方法可以进行数据解析,其中最常用的包括正则表达式、BeautifulSoup和lxml库。以下是使用这些方法进行数据解析的简要说明:
1、正则表达式(Regular Expressions)
正则表达式是一个强大的文本处理工具,可以用于匹配和提取字符串中的特定模式。然而,正则表达式对于复杂的HTML结构来说可能变得非常繁琐和难以维护。因此,尽管它可以用于数据解析,但在处理HTML时通常不是首选方法。
import re# 假设你已经从网页中获取了HTML内容并存储在变量html中
html = "<p>This is a <b>sample</b> text.</p>"# 使用正则表达式提取<b>标签之间的文本
bold_text = re.search(r'<b>(.*?)</b>', html)
if bold_text:print(bold_text.group(1)) # 输出: sample2、BeautifulSoup数据解析
BeautifulSoup是一个Python库,用于从HTML或XML文件中提取数据。它创建了一个解析树,可以方便地导航、搜索和修改树中的标签。它提供了一种简单、灵活且高效的方式来从网页中提取数据。
以下是如何使用BeautifulSoup进行数据解析的基本步骤:
2.1 安装BeautifulSoup和解析器
首先,需要安装BeautifulSoup库以及一个HTML或XML解析器。常用的解析器有html.parser(Python内置)、lxml和html5lib。其中lxml解析速度最快,而html5lib能最好的解析不规范的HTML。
pip install beautifulsoup4 lxml2.2 导入所需的库
在你的Python脚本中,导入BeautifulSoup和解析器。
from bs4 import BeautifulSoup2.3 获取HTML内容
使用如requests库从网页抓取HTML内容,或者如果你有本地的HTML文件,直接读取文件内容。
import requestsurl = 'http://example.com'
response = requests.get(url)
html_content = response.text2.4 创建BeautifulSoup对象
使用获取的HTML内容创建一个BeautifulSoup对象,并指定解析器。
soup = BeautifulSoup(html_content, 'lxml')2.5 查找和提取数据
BeautifulSoup提供了多种方法来查找和提取HTML中的数据,包括基于标签名、类名、ID、属性等。
- find() 和 find_all()
find()方法返回文档中匹配到的第一个元素,find_all()方法返回所有匹配的元素,结果是一个列表。
# 查找第一个<title>标签的内容
title_tag = soup.find('title')
title_text = title_tag.get_text()
print(title_text)# 查找所有<a>标签
links = soup.find_all('a')
for link in links:print(link.get('href')) # 打印所有链接的href属性
- select() 使用CSS选择器来查找元素,类似于在浏览器开发者工具中使用的方式。
# 使用CSS选择器查找所有类名为'my-class'的元素
elements = soup.select('.my-class')
for element in elements:print(element.get_text())- get_text() 提取标签内部的文本内容。
text = soup.get_text()
print(text)- get() 提取标签的属性值。
img = soup.find('img')
src = img.get('src')
print(src)2.6 注意事项
- 网页内容可能随着时间变化,解析代码可能需要更新以适应新的结构。
- 对于大型网站或频繁的抓取请求,请确保遵守网站的robots.txt规则和使用条款,避免造成不必要的麻烦。
- 使用
lxml解析器时,确保已经正确安装了C语言库,否则可能会遇到安装或运行时错误。
以上只是BeautifulSoup的基本用法。根据你的具体需求,你可能还需要深入了解BeautifulSoup提供的更多高级功能和方法。
from bs4 import BeautifulSoup# 假设你已经从网页中获取了HTML内容并存储在变量html中
html = "<p>This is a <b>sample</b> text.</p>"# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html, 'html.parser')# 提取<b>标签之间的文本
bold_text = soup.find('b').text
print(bold_text) # 输出: sample
3、lxml数据解析
lxml是一个高效、易于使用的Python库,用于处理XML和HTML。它基于libxml2和libxslt库,提供了XPath和CSS选择器的支持,使得数据解析变得更加简单。
以下是如何使用lxml进行数据解析的基本步骤:
3.1 安装lxml
如果你还没有安装lxml,你可以使用pip来安装:
pip install lxml3.2 导入lxml库
在你的Python脚本中,你需要导入lxml的相关模块。通常我们会使用etree模块。
from lxml import etree3.3 获取HTML或XML内容
你可以使用如requests库从网页抓取内容,或者从本地文件读取内容。
import requestsurl = 'http://example.com'
response = requests.get(url)
html_content = response.text
3.4 解析HTML或XML
使用etree模块的HTML或XML解析器将字符串内容解析成DOM树。
# 解析HTML内容
tree = etree.HTML(html_content)# 或者,如果你正在处理XML内容
# tree = etree.XML(xml_content)3.5 查找和提取数据
lxml提供了多种查找元素的方法,其中最常用的是XPath表达式。
# 使用XPath查找元素
# 查找所有<a>标签
links = tree.xpath('//a')
for link in links:href = link.get('href') # 获取链接的href属性text = link.text # 获取链接的文本内容print(href, text)# 查找具有特定类的元素
elements_with_class = tree.xpath('//div[@class="my-class"]')
for element in elements_with_class:print(element.text)XPath表达式非常强大,允许你基于标签名、属性、位置等选择元素。你可以查阅XPath的文档来学习如何构建更复杂的表达式。
3.6 注意事项
- 当处理从网页抓取的内容时,请确保遵守网站的robots.txt规则和使用条款。
- XPath表达式可能因HTML或XML文档的结构变化而需要调整。
- 如果你在处理大型文档或进行频繁的解析操作,请注意性能问题,并考虑优化你的XPath表达式或使用其他技术来提高效率。
lxml是一个非常强大的库,提供了比BeautifulSoup更多的功能和更高的性能。然而,它的API可能比BeautifulSoup略难一些,特别是对于XPath表达式的编写。因此,在选择使用哪个库时,你需要根据你的具体需求和项目规模来决定。
from lxml import etree# 假设你已经从网页中获取了HTML内容并存储在变量html中
html = "<p>This is a <b>sample</b> text.</p>"# 使用lxml解析HTML
tree = etree.HTML(html)# 使用XPath提取<b>标签之间的文本
bold_text = tree.xpath('//b/text()')[0]
print(bold_text) # 输出: sample在选择数据解析方法时,请考虑网页的复杂性、解析需求以及个人偏好。对于简单的网页,正则表达式可能足够。然而,对于复杂的网页结构和大量的解析需求,建议使用BeautifulSoup或lxml。
相关文章:
【Python网络爬虫】详解python爬虫中正则表达式、BeautifulSoup和lxml数据解析
🔗 运行环境:PYTHON 🚩 撰写作者:左手の明天 🥇 精选专栏:《python》 🔥 推荐专栏:《算法研究》 #### 防伪水印——左手の明天 #### 💗 大家好🤗ᾑ…...

树莓派串口无法使用(排除硬件错误后)
1、串口 进入/boot文件夹下,打开cmdline.txt文件 cd /boot/sudo vi cmdline.txt 删除下方红框内字段...

JavaEE IO流(1)
1.什么是IO流 (1)input输入 Output输出 这两个的首字母就是IO的组成 (2)比如你的电脑可以通过网络上传文件和下载文件 这个上传文件就是Output 这个下载翁建就是input (3)这个输入和输出的标准是以CPU为参照物为基准的 其中通…...

Prisma是什么:现代数据库工具和ORM
Prisma是什么:现代数据库工具和ORM 引言 Prisma 是一个流行的开源数据库工具和对象关系映射(ORM)系统,用于帮助开发者以类型安全的方式与数据库进行交互。它提供了一套丰富的功能,包括数据库建模、迁移管理、数据访问…...

SpringBootWeb登录认证
JWT令牌 JSON Web Token JSON Web Tokens - jwt.ioJSON Web Token (JWT) is a compact URL-safe means of representing claims to be transferred between two parties. The claims in a JWT are encoded as a JSON object that is digitally signed using JSON Web Signatur…...

vim编辑器的使用
删除当前行及以后的行 使用vim编辑器打开文件 vim xxx.txt删除指定行及后面所有行,光标定位到要删除的第一行,比如:删除第10行以后的数据,光标定位到11行,然后在命令模式下按dG...

深入理解Linux网络总结
1、内核如何接收网络包 1.1 RingBuffer到底是什么,RingBuffer为什么会丢包? 问:RingBuffer到底存在那一块,是如何被使用到的,真的就只是一个环形队列吗?RingBuffer内存是预先分配好的,还是随着…...

Python冷知识
Python作为一种广泛使用的编程语言,有许多功能和特性可能不为初学者或普通用户所熟知。以下是一些相对冷门但有趣的Python知识: 魔术方法:Python中有一些特殊的方法,通常以双下划线__开头和结尾,被称为魔术方法(或特殊方法)。例如,__init__用于初始化对象,__str__返回…...
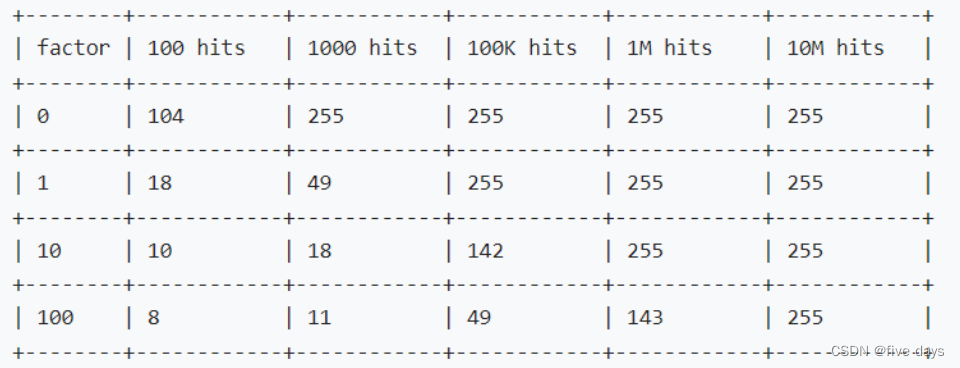
Redis之内存管理过期、淘汰机制
1.Redis内存管理 我们的redis是一个内存型数据库,我们的数据也都是放在内存中的,内存是有限的空间,当数据满了之后,我们要怎么样继续保证redis的可用性呢?我们就需要采取点管理措施和机制来保证我们redis的可用性。 在redis.co…...

金融科技赋能跨境支付:便捷与安全并驾齐驱
一、引言 在全球经济一体化的背景下,跨境支付作为国际贸易和金融活动的重要组成部分,正迎来金融科技浪潮的洗礼。金融科技以其独特的创新性和颠覆性,正在重塑跨境支付市场的格局,使其更加便捷、高效且安全。本文旨在探讨金融科技如何助力跨境支付,实现便捷与安全并存,并…...
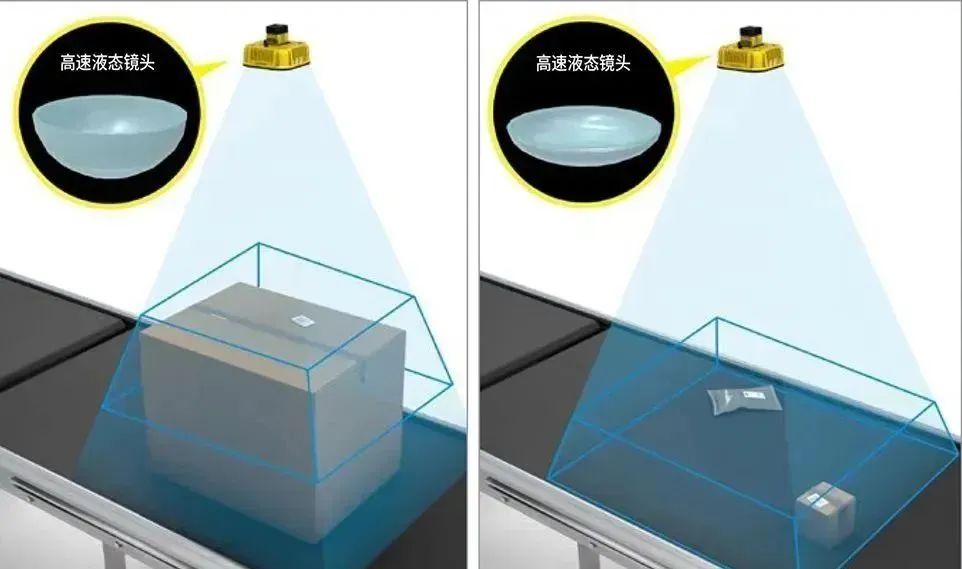
【康耐视国产案例】智能AI相机:深度解析DataMan 380大视野高速AI读码硬实力
随着读码器技术的不断更新迭代,大视野高速应用成为当前工业读码领域的关键发展方向。客户对大视野高速读码器的需求源于其能显著减少生产成本并提升工作效率。然而,大视野应用场景往往伴随着对多个条码的读取需求,这无疑增加了算法的处理负担…...
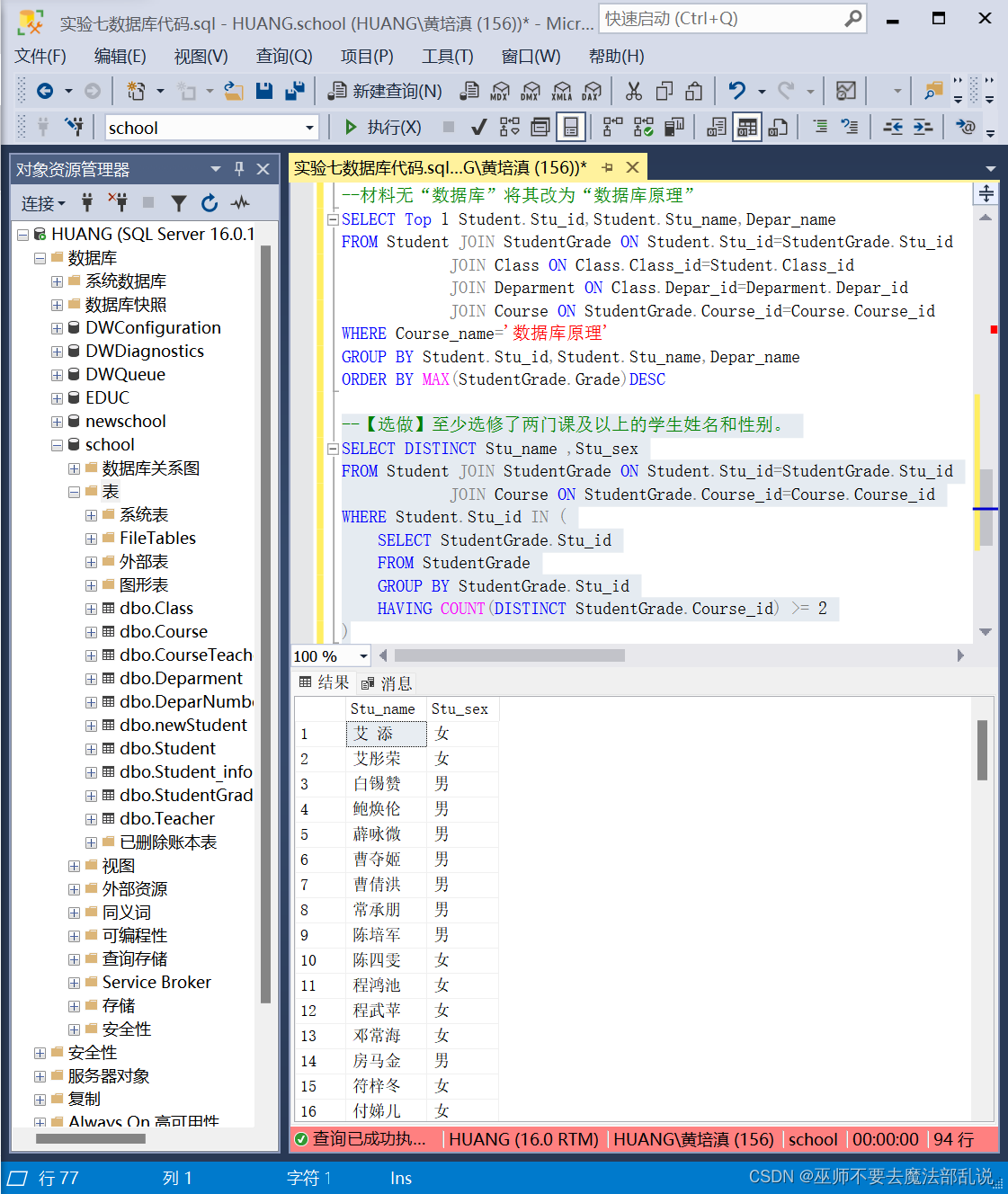
SQL实验 带函数查询和综合查询
一、实验目的 1.掌握Management Studio的使用。 2.掌握带函数查询和综合查询的使用。 二、实验内容及要求 1.统计年龄大于30岁的学生的人数。 --统计年龄大于30岁的学生的人数。SELECT COUNT(*) AS 人数FROM StudentWHERE (datepart(yea…...

【前端每日基础】day34——HTTP和HTTPS
HTTP(Hypertext Transfer Protocol)和HTTPS(Hypertext Transfer Protocol Secure)是互联网通信协议,用于在Web浏览器和Web服务器之间传输数据。以下是对HTTP和HTTPS的详细介绍: HTTP(Hypertext…...

go mongo 唯一索引创建
1. 登录mongo,创建数据库 mongosh -u $username -p $password use test 2. 查看集合索引 db.$collection_name.getIndexes() 为不存在的集合创建字段唯一索引 package mainimport ("context""fmt""log""time""go…...

微信小程序如何进行页面跳转
微信小程序中的页面跳转可以通过多种方式实现,以下是几种主要的跳转方式及其详细解释: wx.navigateTo 功能:保留当前页面,跳转到应用内的某个页面。特点: 可以在新页面使用wx.navigateBack返回原页面。每跳转一个新页…...

信息标记形式 (XML, JSON, YAML)
文章目录 🖥️介绍🖥️三种形式🏷️XML (Extensible Markup Language)🔖规范🔖注释🔖举例🔖其他 🏷️JSON (JavaScript Object Notation)🔖规范🔖注释&#x…...

C语言:学生成绩管理系统(含源代码)
一.功能 二.源代码 #include <stdio.h> #include <stdlib.h> #include <string.h> #define MAX_NUM 100 typedef struct {char no[30];char name[10];char sex[10];char phone[20];float cyuyan;float computer;float datastruct; } *student, student1;typ…...

MySQL 导出导入的101个坑
最近接到一个业务自行运维的MySQL库迁移至标准化环境的需求,库不大,迁移方式也很简单,由开发用myqldump导出数据、DBA导入,但迁移过程坎坷十足,记录一下遇到的各项报错及后续迁移注意事项。 一、 概要 空间问题源与目…...

OpenCv之简单的人脸识别项目(人脸提取页面)
人脸识别 准备五、人脸提取页面1.导入所需的包2.设置窗口2.1定义窗口外观和大小2.2设置窗口背景2.2.1设置背景图片2.2.2创建label控件 3.定义单人脸提取脚本4.定义多人脸提取脚本5.创建一个退出对话框6.按钮设计6.1单人脸提取按钮6.2多人脸提取按钮6.3返回按钮 7.定义关键函数8…...
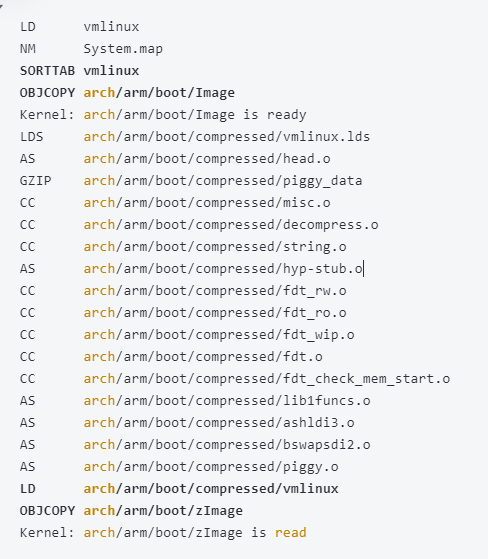
linux 内核映像差异介绍:vmlinux、zImage、zbImage、image、uImage等
一、背景 Linux内核是整个Linux操作系统的核心部分,它是一个负责与硬件直接交互的软件层,并且提供多种服务和接口,让用户程序能够方便地使用硬件资源。 当我们编译自定义内核时,可以将其生成为以下内核映像之一:vmli…...

Triton Ascend 代码生成 Skill
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: triton-op-coding description: > Triton Ascend 算子代码生…...

手把手教你用J-Link调试STM32:从20针接口定义到SWD最小系统连接实战
嵌入式开发实战:J-Link与STM32的SWD高效调试指南 第一次接触J-Link调试器时,面对20针接口上密密麻麻的引脚,不少开发者都会感到无从下手。实际上,现代ARM Cortex-M系列芯片的调试已经变得异常简单——只需要SWD协议下的三根线&am…...

5分钟极速上手:B站视频转文字工具bili2text完整指南
5分钟极速上手:B站视频转文字工具bili2text完整指南 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为整理B站视频内容而烦恼吗?每…...
)
告别实车测试!手把手教你用Vector VT平台搭建OBC/DCDC的HIL测试环境(附避坑指南)
新能源汽车OBC/DCDC控制器HIL测试环境搭建实战指南 在新能源汽车三电系统开发中,车载充电机(OBC)和DC/DC变换器的功能验证一直是工程师面临的挑战。传统实车测试不仅成本高昂,而且难以覆盖所有边界条件。硬件在环(HIL)测试技术通过将真实控制器接入虚拟车…...

BEP-20代币全解析:从原理到实战,赋能Web3开发
BEP-20代币全解析:从原理到实战,赋能Web3开发 引言 在百花齐放的区块链世界中,币安智能链(BNB Chain) 凭借其低廉的手续费与闪电般的交易速度,迅速成为众多开发者和项目方的热土。而这一切繁荣生态的基石…...
)
Cadence ADE保姆级教程:手把手教你用S参数文件提取变压器QLk指标(附完整公式)
Cadence ADE实战指南:从S参数文件到变压器QLk指标的全流程解析 在射频集成电路设计中,变压器作为关键无源器件,其性能直接影响整个系统的效率与稳定性。QLk指标(品质因数Q、电感值L和耦合系数k)的准确提取,…...

Phillips SDM01 0940860010091 003149电子控制单元
Phillips SDM01 0940860010091 003149 是一款飞利浦出品的电子控制单元,专用于工业设备或医疗系统的逻辑控制与信号处理。中间:15条产品特点SDM01 采用飞利浦高品质元器件,稳定性好。具备多路数字量输入输出通道,扩展性强。处理速…...

别再只问哪个大模型更强了,2026年真正决定AI Agent上限的,是向量引擎
别再只问哪个大模型更强了,2026年真正决定AI Agent上限的,是向量引擎 这两年做AI的人,最容易掉进一个坑。 每天盯着模型榜单看。 今天这个模型会写代码了。 明天那个模型会看视频了。 后天又有一个模型说自己推理能力更强了。 看久了以后&…...

2026年六大主流AI变声器软件排名推荐!
随着AI语音技术持续迭代升级,AI变声器不再是单一的娱乐工具,广泛应用于游戏开黑、直播互动、短视频配音、音频创作、隐私语音沟通等多个场景。目前市面上变声软件品类繁杂,涵盖移动端、PC端、免费开源、专业付费等不同类型,普通用…...

小米手表表盘设计革命:无需编程,5分钟打造个性化智能表盘
小米手表表盘设计革命:无需编程,5分钟打造个性化智能表盘 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 关键词: Mi-Creat…...