CSAPP Lab07——Malloc Lab完成思路
等不到天黑
烟火不会太完美
回忆烧成灰
还是等不到结尾
——她说
完整代码见:CSAPP/malloclab-handout at main · SnowLegend-star/CSAPP (github.com)
Malloc Lab
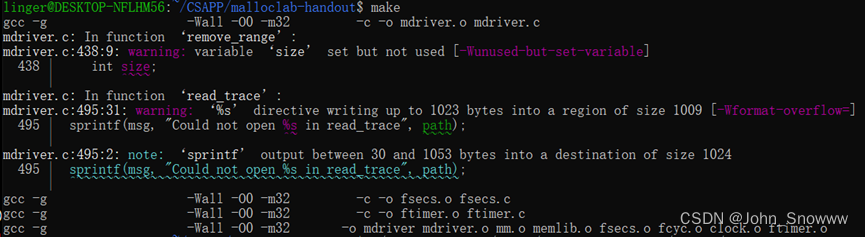
按照惯例,我先是上来就把mm.c编译了一番,结果产生如下报错。搜索过后看样子应该是编译器的版本不匹配,得建立条软链接。

经过多番尝试,最后得到正确的链接形式是
“ln -s /usr/include/x86_64-linux-gnu/asm /usr/include/asm”
隐式空闲链表
这方法就是把书上的那几个函数搬过来就行,唯一需要自己动手的是realloc()函数。但是书上的那一大块宏定义属实是看得我两眼发昏。特别是NEXT_BLKP(bp)和PREV_BLKP(bp)这两个定义,直接把我绕晕了。
后来仔细分析了一番,发现最根本的原因是我把隐式空闲链表的头/尾块和内存块的头/尾部弄混了,导致每次分析堆内块的4byte头/尾部分的时候就会不自觉想到链表的头/尾部分。明白两者的不同之后,接下来分析宏定义等就显得直观明了了。
 在排查bug的时候,没有实现把指针ptr定位到堆块的头部再进行指针操作确实是害苦了我。刚才就是一个困扰我很久的问题。
在排查bug的时候,没有实现把指针ptr定位到堆块的头部再进行指针操作确实是害苦了我。刚才就是一个困扰我很久的问题。

说完指针定位到头部的问题后,再来谈谈void *mm_realloc(void *ptr, size_t size)的实现框架。
1、ptr=NULL,size≠0:调用malloc()
2、ptr≠NULL,size=0:调用free()
3、ptr≠NULL,size≠0:调整size为asize
3.1、asize=blocksize_Cur:直接分配
3.2、asize<blocksize_Cur:调用place()把当前块进行分割
3.3、asize>blocksize_Cur:当前块的大小不足以分配
3.3.1、next block空闲,且两个块的大小和blocksize_Sum>aszie:对下一块使用place()
3.3.2、next block已分配,或者两块大小和blocksize_Sum<aszie:调用find_fit()来寻找一个全新的块进行分配,而不考虑当前块和next block
3.3.2.1、find_fit()找到了合适的块:调用place()进行分配
3.3.2.2、find_fit()未找到合适的块:先用extend_heap()来申请新的堆空间,再调用place(),最后把原来块的内容拷贝到新块里面,释放原来块的空间。
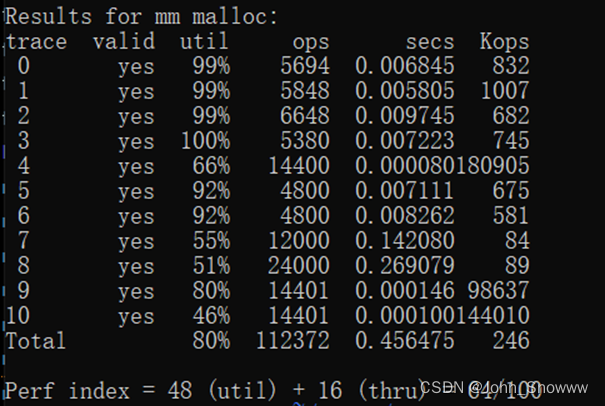
最后得到的测试结果如图。
//define function
static void *extend_heap(size_t words);
static void *coalesce(void *bp);
static void *find_fit(size_t asize);
static void place(void *bp,size_t asize);/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT-1)) & ~0x7)#define SIZE_T_SIZE (ALIGN(sizeof(size_t)))//basic constants and macros
#define WSIZE 4 //字的大小和首部/脚部的大小
#define DSIZE 8 //双字的大小
#define CHUNKSIZE (1<<12) //扩展堆时的默认大小#define MAX(x,y) ((x)>(y)?(x):(y))//pack a size and allocated bit into a word in header/footer 很绕啊
#define PACK(size ,alloc) ((size)|(alloc))//read and write a word at address p
#define GET(p) (*(unsigned int *)(p))
#define PUT(p,val) (*(unsigned int *)(p)=(val))//read the size and allocated filds from address p
#define GET_SIZE(p) (GET(p)&~0x7)
#define GET_ALLOC(p) (GET(p)&0x1 )//given block ptr bp,compute address of its header and footer
#define HDRP(bp) ((char *)(bp)-WSIZE)
#define FTRP(bp) ((char*)(bp)+GET_SIZE(HDRP(bp))-DSIZE) //没把bp定位到头部坏大事//given block ptr bp,computer address of next and previous blocks
#define NEXT_BLKP(bp) ((char*)(bp)+GET_SIZE( (char*)(bp) - WSIZE) )
#define PREV_BLKP(bp) ((char*)(bp)-GET_SIZE( (char*)(bp) - DSIZE) )static void *heap_listp;static void *extend_heap(size_t words){char *bp;size_t size;//分配偶数字或者进行填充size=(words%2)?(words+1)*WSIZE:words*WSIZE;if((long)(bp=mem_sbrk(size))==-1)return NULL;//初始化头部/脚部块和结束块PUT(HDRP(bp),PACK(size,0));PUT(FTRP(bp),PACK(size,0));PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1)); //有点没看懂//如果前一个块空闲则合并return coalesce(bp);
}static void *find_fit(size_t asize){//h第一次适应算法void *bp;for(bp=heap_listp;GET_SIZE(HDRP(bp))>0;bp=NEXT_BLKP(bp)){if(!GET_ALLOC(HDRP(bp))&&(asize<=GET_SIZE(HDRP(bp)))) //这个块没被分配且容量合适return bp;}return NULL;
}static void place(void *bp,size_t asize){size_t cur_size=GET_SIZE(HDRP(bp));if((cur_size-asize)>=(2*WSIZE)){ //给16字节的头部、序言、结尾块腾位置PUT(HDRP(bp),PACK(asize,1));PUT(FTRP(bp),PACK(asize,1));bp=NEXT_BLKP(bp); //移动到下一个块,就是分割完剩下的部分PUT(HDRP(bp),PACK(cur_size-asize,0));PUT(FTRP(bp),PACK(cur_size-asize,0));}else{ //能用到place说明cur_size-asize>0 直接把这个给分配掉PUT(HDRP(bp),PACK(cur_size,1)); //因为剩下的空间也就0、1这两种,但是一个可用块最小为2WSIZEPUT(FTRP(bp),PACK(cur_size,1));}
}static void *coalesce(void *bp){size_t prev_alloc=GET_ALLOC(FTRP(PREV_BLKP(bp)));size_t next_alloc=GET_ALLOC(HDRP(NEXT_BLKP(bp)));size_t size=GET_SIZE(HDRP(bp));if(prev_alloc&&next_alloc){return bp;}else if(prev_alloc&&!next_alloc){size+=GET_SIZE(HDRP(NEXT_BLKP(bp)));PUT(HDRP(bp),PACK(size,0));PUT(FTRP(bp),PACK(size,0));}else if(!prev_alloc&&next_alloc){size+=GET_SIZE(HDRP(PREV_BLKP(bp)));PUT(FTRP(bp),PACK(size,0));PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));bp=PREV_BLKP(bp);}else{size+=GET_SIZE(HDRP(PREV_BLKP(bp)))+GET_SIZE(FTRP(NEXT_BLKP(bp)));PUT(HDRP(PREV_BLKP(bp)),PACK(size,0));PUT(FTRP(NEXT_BLKP(bp)),PACK(size,0));}return bp;
}/* * mm_init - initialize the malloc package.*/
int mm_init(void)
{//开始创建初始的空堆,大小为4字if((heap_listp=mem_sbrk(4*WSIZE))==(void *) -1)return -1;// return 0; //牛魔的,怎么这里有个returnPUT(heap_listp,0); //alignment paddingPUT(heap_listp+(1*WSIZE),PACK(DSIZE,1)); //prologue headerPUT(heap_listp+(2*WSIZE),PACK(DSIZE,1)); //prologue footerPUT(heap_listp+(3*WSIZE),PACK(0,1)); //epologue blockheap_listp+=(2*WSIZE);//增加堆的大小if(extend_heap(CHUNKSIZE/WSIZE)==NULL)return -1;return 0;
}/* * mm_malloc - Allocate a block by incrementing the brk pointer.* Always allocate a block whose size is a multiple of the alignment.*/
void *mm_malloc(size_t size)
{size_t asize; //adjusted block sizesize_t extendsize; //如果大小超过堆的大小应该增加的总数char* bp;if(size==0)return NULL;//双字对齐if(size<=DSIZE)asize=2*DSIZE;elseasize=DSIZE*((size+(DSIZE)+(DSIZE-1))/DSIZE); //加1向下舍入//从空闲链表里找合适的块进行分配if((bp=find_fit(asize))!=NULL){place(bp,asize);return bp;}//如果没有合适的空闲块,堆请求更大的空间extendsize=MAX(asize,CHUNKSIZE);if((bp=extend_heap(extendsize/WSIZE))==NULL)return NULL;place(bp,asize);return bp;}/** mm_free - Freeing a block does nothing.*/
void mm_free(void *ptr)
{size_t size=GET_SIZE(HDRP(ptr));PUT(HDRP(ptr),PACK(size,0));PUT(FTRP(ptr),PACK(size,0));coalesce(ptr);
}/** mm_realloc - Implemented simply in terms of mm_malloc and mm_free*/
void *mm_realloc(void *ptr, size_t size)
{void *old_ptr=ptr,*next_ptr,*new_ptr;size_t asize;size_t extendsize;size_t blocksize_Cur,blocksize_Next,blocksize_Sum; //当前块的大小,下一个块的大小if(ptr==NULL&&size!=0)return mm_malloc(size);if(ptr!=NULL&&size==0){mm_free(ptr); return NULL; }//接下来就是指针不为空,且分配大小非0的正常情况了//双字对齐if(size<=DSIZE)asize=2*DSIZE;elseasize=DSIZE*((size+(DSIZE)+(DSIZE-1))/DSIZE);// blocksize_Cur=GET_SIZE(ptr); //ptr得定位到头部☆☆☆blocksize_Cur=GET_SIZE(HDRP(ptr));if(asize==blocksize_Cur){return ptr; }else if(asize<blocksize_Cur){ //当前块的大小>要求分配的空间大小place(ptr,asize);return ptr;}else{ //当前块的大小<要求分配的空间大小next_ptr=NEXT_BLKP(ptr);blocksize_Next=GET_SIZE(HDRP(next_ptr));blocksize_Sum=blocksize_Cur+blocksize_Next;if(GET_ALLOC(HDRP(next_ptr))==0&&blocksize_Sum>=asize){ //当前块大小+下一块大小>asizePUT(HDRP(ptr),PACK(blocksize_Sum,0)); //把当前块和下一块合并place(ptr,asize);return ptr;}else{new_ptr=find_fit(asize);if(new_ptr==NULL){ //如果当前链表找不到合适的块,则申请额外的空间extendsize=MAX(CHUNKSIZE,asize);if((new_ptr=extend_heap(extendsize/WSIZE))==NULL)return NULL;}place(new_ptr,asize);memcpy(new_ptr,old_ptr,blocksize_Cur);mm_free(old_ptr);return new_ptr;}}
}显式空闲链表
按照书上思路来写就行
Tip:有char **p1和int **p2,那p1==p2吗?

/* single word (4) or double word (8) alignment */
#define ALIGNMENT 8 //对齐8个字节(2个字)/* rounds up to the nearest multiple of ALIGNMENT */
#define ALIGN(size) (((size) + (ALIGNMENT-1)) & ~0x7)
#define SIZE_T_SIZE (ALIGN(sizeof(size_t))) //头部、脚部、两指针、8字节数据//basic constants and macros
#define WSIZE 4 //字的大小和首部/脚部的大小
#define DSIZE 8 //双字的大小
#define CHUNKSIZE (1<<12) //扩展堆时的默认大小
#define MINBLOCK (DSIZE+2*WSIZE+2*WSIZE)#define MAX(x,y) ((x)>(y)?(x):(y))//pack a size and allocated bit into a word in header/footer 很绕啊
#define PACK(size ,alloc) ((size)|(alloc))//read and write a word at address p
#define GET(p) (*(unsigned int *)(p))
#define PUT(p,val) (*(unsigned int *)(p)=(val))
#define GETADDR(p) (*(unsigned int **)(p)) //读地址p处的一个指针
#define PUTADDR(p,addr) (*(unsigned int **)(p)=(unsigned int *)(addr)) //在地址p处写的指针//read the size and allocated filds from address p
#define GET_SIZE(p) (GET(p)&~0x7)
#define GET_ALLOC(p) (GET(p)&0x1 )//given block ptr bp,compute address of its header and footer
#define HDRP(bp) ((char *)(bp)-WSIZE)
#define FTRP(bp) ((char*)(bp)+GET_SIZE(HDRP(bp))-DSIZE) //没把bp定位到头部坏大事//given block ptr bp,computer address of next and previous blocks
#define NEXT_BLKP(bp) ((char*)(bp)+GET_SIZE( (char*)(bp) - WSIZE) )
#define PREV_BLKP(bp) ((char*)(bp)-GET_SIZE( (char*)(bp) - DSIZE) )//链表特有的指针
#define PRED_POINTER(bp) (bp) //指向父指针的指针
#define SUCC_POINTER(bp) ((char*)(bp)+WSIZE) //指向后继的指针static void *heap_listp;
static void *head_free;//define function
static void *extend_heap(size_t words);
static void *coalesce(void *bp);
static void *find_fit(size_t asize);
static void place(void *bp,size_t asize);//链表操作
static void insert_freelist(void *bp);
static void remove_freelist(void *bp);
static void place_freelist(void *bp);static void *extend_heap(size_t words){char *bp;size_t size;//分配偶数字或者进行填充size=(words%2)?(words+1)*WSIZE:words*WSIZE;if((long)(bp=mem_sbrk(size))==-1)return NULL;//初始化头部/脚部块和结束块PUT(HDRP(bp),PACK(size,0));PUT(FTRP(bp),PACK(size,0));PUT(HDRP(NEXT_BLKP(bp)),PACK(0,1)); //有点没看懂//如果前一个块空闲则合并return coalesce(bp);
}static void *find_fit(size_t asize){//h第一次适应算法void *bp;for(bp=GETADDR(head_free);bp!=NULL;bp=GETADDR(SUCC_POINTER(bp))){ //遍历空闲链表if((asize<=GET_SIZE(HDRP(bp)))) //这个块没被分配且容量合适return bp;}return NULL;
}static void place(void *bp,size_t asize){size_t cur_size=GET_SIZE(HDRP(bp));void *next_bp;if((cur_size-asize)>=(MINBLOCK)){ //最小块的大小为24B,这里包括了有效载荷的部分PUT(HDRP(bp),PACK(asize,1));PUT(FTRP(bp),PACK(asize,1));next_bp=NEXT_BLKP(bp); //移动到下一个块,就是分割完剩下的部分PUT(HDRP(next_bp),PACK(cur_size-asize,0));PUT(FTRP(next_bp),PACK(cur_size-asize,0));place_freelist(bp);}else{ //能用到place说明cur_size-asize>0 直接把这个给分配掉PUT(HDRP(bp),PACK(cur_size,1)); //因为剩下的空间也就0、1这两种,但是一个可用块最小为2WSIZEPUT(FTRP(bp),PACK(cur_size,1));remove_freelist(bp);}
}static void *coalesce(void *bp){//基本思路没变,加入对空闲链表的操作size_t prev_alloc=GET_ALLOC(FTRP(PREV_BLKP(bp)));size_t next_alloc=GET_ALLOC(HDRP(NEXT_BLKP(bp)));size_t size=GET_SIZE(HDRP(bp));char *pre_block,*next_block;if(prev_alloc&&next_alloc){insert_freelist(bp);return bp;}else if(prev_alloc&&!next_alloc){ //合并下一块size+=GET_SIZE(HDRP(NEXT_BLKP(bp)));next_block=NEXT_BLKP(bp); remove_freelist(next_block);insert_freelist(bp);}else if(!prev_alloc&&next_alloc){ //合并前一块size+=GET_SIZE(HDRP(PREV_BLKP(bp)));bp=PREV_BLKP(bp);remove_freelist(bp);insert_freelist(bp);}else{ //前后块都合并size+=GET_SIZE(HDRP(PREV_BLKP(bp)))+GET_SIZE(FTRP(NEXT_BLKP(bp)));pre_block=PREV_BLKP(bp);next_block=NEXT_BLKP(bp);bp=PREV_BLKP(bp);remove_freelist(pre_block);remove_freelist(next_block);insert_freelist(bp);}PUT(HDRP(bp),PACK(size,0));PUT(FTRP(bp),PACK(size,0));return bp;
}//使用头插法,将空闲块插入空闲链表中
static void insert_freelist(void *bp){ //LIFO,先进后出if(GETADDR(head_free)==NULL){PUTADDR(SUCC_POINTER(bp),NULL);PUTADDR(PRED_POINTER(bp),head_free);PUTADDR(head_free,bp);}else{void *tmp;tmp=GETADDR(head_free);PUTADDR(SUCC_POINTER(bp),tmp);PUTADDR(PRED_POINTER(bp),head_free);PUTADDR(head_free,bp);PUTADDR(PRED_POINTER(tmp),bp);tmp=NULL;}
}//将bp指向的空闲块从空闲链表中移除
static void remove_freelist(void *bp){void *pred_ptr,*succ_ptr;pred_ptr=GETADDR(PRED_POINTER(bp));succ_ptr=GETADDR(SUCC_POINTER(bp));//处理前驱节点if(pred_ptr==head_free){PUTADDR(head_free,succ_ptr);}else{PUTADDR(SUCC_POINTER(pred_ptr),succ_ptr);}//处理后继节点if(succ_ptr!=NULL){PUTADDR(PRED_POINTER(succ_ptr),pred_ptr);}
}//对空闲链表中的空闲块进行分割
static void place_freelist(void *bp){void *pred_ptr,*succ_ptr,*next_bp;//储存前后结点的地址pred_ptr=GETADDR(PRED_POINTER(bp));succ_ptr=GETADDR(SUCC_POINTER(bp));next_bp=NEXT_BLKP(bp);//处理新的bp,进行前后链接PUTADDR(PRED_POINTER(next_bp),pred_ptr);PUTADDR(SUCC_POINTER(next_bp),succ_ptr);//处理前序节点,针对head_free是前序节点的特殊处理if(pred_ptr==head_free){PUTADDR(head_free,next_bp);}else{PUTADDR(SUCC_POINTER(pred_ptr),next_bp);}//处理后序节点if(succ_ptr!=NULL){PUTADDR(PRED_POINTER(succ_ptr),next_bp);}
}
/* * mm_init - initialize the malloc package.*/
//设立序言块、结尾块,以及序言块前的对齐块(4B),总共需要4个4B的空间
int mm_init(void)
{//开始创建初始的空堆,大小为4字if((heap_listp=mem_sbrk(4*WSIZE))==(void *) -1)return -1;PUTADDR(heap_listp,NULL); //堆起始位置的对齐块,是bp对齐8字节// PUT(heap_listp,0); //alignment paddingPUT(heap_listp+(1*WSIZE),PACK(DSIZE,1)); //prologue headerPUT(heap_listp+(2*WSIZE),PACK(DSIZE,1)); //prologue footerPUT(heap_listp+(3*WSIZE),PACK(0,1)); //epologue block 存疑head_free=heap_listp;PUTADDR(head_free,NULL);heap_listp+=(2*WSIZE);//增加堆的大小if(extend_heap(CHUNKSIZE/WSIZE)==NULL)return -1;return 0;
}/* * mm_malloc - Allocate a block by incrementing the brk pointer.* Always allocate a block whose size is a multiple of the alignment.*/
void *mm_malloc(size_t size)
{size_t asize; //adjusted block sizesize_t extendsize; //如果大小超过堆的大小应该增加的总数char* bp;if(size==0)return NULL;//双字对齐if(size<=DSIZE)asize=2*DSIZE;elseasize=DSIZE*((size+(DSIZE)+(DSIZE-1))/DSIZE); //加1向下舍入//从空闲链表里找合适的块进行分配if((bp=find_fit(asize))!=NULL){place(bp,asize);return bp;}//如果没有合适的空闲块,堆请求更大的空间extendsize=MAX(asize,CHUNKSIZE);if((bp=extend_heap(extendsize/WSIZE))==NULL)return NULL;place(bp,asize);return bp;}/** mm_free - Freeing a block does nothing.*/
void mm_free(void *ptr)
{size_t size=GET_SIZE(HDRP(ptr));PUT(HDRP(ptr),PACK(size,0));PUT(FTRP(ptr),PACK(size,0));coalesce(ptr);
}/** mm_realloc - Implemented simply in terms of mm_malloc and mm_free*/
void *mm_realloc(void *ptr, size_t size)
{void *old_ptr=ptr,*new_ptr;size_t asize;size_t extendsize;size_t blocksize_Cur; //当前块的大小,下一个块的大小if(ptr==NULL&&size!=0)return mm_malloc(size);if(ptr!=NULL&&size==0){mm_free(ptr); return NULL; }//接下来就是指针不为空,且分配大小非0的正常情况了//双字对齐if(size<=DSIZE)asize=2*DSIZE;elseasize=DSIZE*((size+(DSIZE)+(DSIZE-1))/DSIZE);// blocksize_Cur=GET_SIZE(ptr); //ptr得定位到头部☆☆☆blocksize_Cur=GET_SIZE(HDRP(ptr));if(asize==blocksize_Cur){return ptr; }else if(asize<blocksize_Cur){ //当前块的大小>要求分配的空间大小if(blocksize_Cur-asize>=MINBLOCK)place(ptr,asize);return ptr;}else{ //当前块的大小<要求分配的空间大new_ptr=find_fit(asize);if(new_ptr==NULL){ //如果当前链表找不到合适的块,则申请额外的空间extendsize=MAX(CHUNKSIZE,asize);if((new_ptr=extend_heap(extendsize/WSIZE))==NULL)return NULL;}place(new_ptr,asize);memcpy(new_ptr,old_ptr,blocksize_Cur-2*WSIZE);mm_free(old_ptr);return new_ptr;}
}分离空闲链表
对于显式空闲链表,判断节点bp的前驱是否是头结点相当简单,如下
但是对于分离空闲链表来说,就显得比较繁琐了。按照上面的思路,我们得先用一个大循环来遍历24条链表的各个头结点,然后再用上述式子。不如把这个循环遍历做成一个单独的函数,以此来判断前驱是否头结点的问题。
if(isSegList(pred_ptr)){ //如果前驱是头结点汗流浃背了,代码出了个bug。
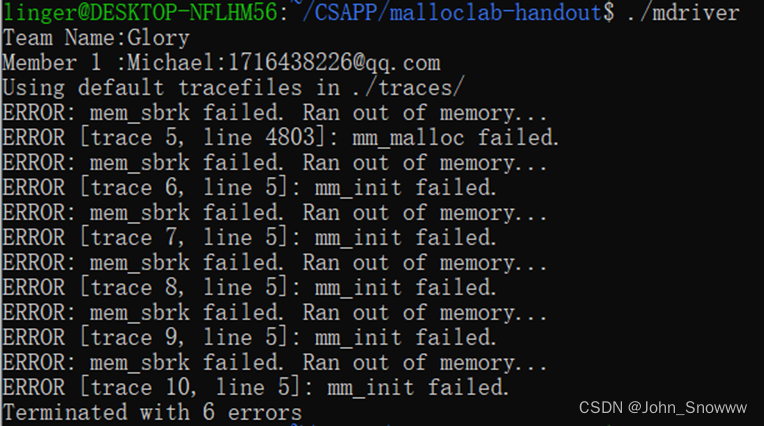
然后是调试环节。
我先是一直在那输入“gdb mm”,结果代码在gdb模式下run起来都有问题,让我心生怀疑可能是调试错了文件,最后才发现pdf上写着调试应该是“gdb mdriver”,白忙活一场。由于默认调试的执行文件是“short1-bal.rep”,想要调试其他文件就得改config.h,但是我发现无论怎么修改config.h,都会报下面的错误。这也是浪费最多时间的一部分。
相关文章:
CSAPP Lab07——Malloc Lab完成思路
等不到天黑 烟火不会太完美 回忆烧成灰 还是等不到结尾 ——她说 完整代码见:CSAPP/malloclab-handout at main SnowLegend-star/CSAPP (github.com) Malloc Lab 按照惯例,我先是上来就把mm.c编译了一番,结果产生如下报错。搜索过后看样子应…...

简单、免费、无广告的高性能多线程文件下载工具
一、简介 1、它是一款免费、无广告的高性能多线程文件下载工具。它界面简洁,简单好用,压缩包大小仅有 0.7MB,目前仅支持 Windows 平台。 2、使用方法:点击程序左上角的【】按钮,将需要的链接输入进去后点击【下载】即…...

【退役之重学 SQL】什么是笛卡尔积
一、初识笛卡尔积 概念: 笛卡尔积是指在关系型数据库中,两个表进行 join 操作时,没有指定任何条件,导致生成的结果集,是两个表中所有行的组合。 简单来说: 笛卡尔积是两个表的乘积,结果集中的每…...

Vue3禁止 H5 界面放大与缩小功能
Vue3禁止 H5 界面放大与缩小功能 一、前言1.第一步2.第二部3.总结 一、前言 当涉及到禁止 H5 界面的放大与缩小功能时,Vue 3 提供了一种方便的方式来处理。我们可以使用 <script setup> 语法,将相关代码添加到 App.vue 组件中,以确保在…...

上位机图像处理和嵌入式模块部署(f407 mcu中tf卡读写和fatfs挂载)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 很早之前,个人对tf卡并不是很重视,觉得它就是一个存储工具而已。后来在移植v3s芯片的时候,才发现很多的soc其实…...

汽车识别项目
窗口设计 这里的代码放在py文件最前面或者最后面都无所谓 # 创建主窗口 window tk.Tk() window.title("图像目标检测系统") window.geometry(1000x650) # 设置窗口大小# 创建背景画布并使用grid布局管理器 canvas_background tk.Canvas(window, width1000, height…...

【面试题-012】什么是Spring 它有哪些优势
文章目录 Spring有哪些优势有哪些优势Spring和Springboot区别在 Spring 框架中,什么是AOP核心概念应用场景 Spring有哪些通知类型 Spring 是一个开源的 Java 平台,由 Rod Johnson 创建,用于简化企业级 Java 应用程序的开发。它于 2003 年首次…...

ImageButton src图片会照成内存泄露吗 会使native内存增加吗?
在Android开发中,ImageButton 是用来显示按钮的视图组件,它通常用于显示图标或图片。对于ImageButton使用的src属性(即按钮上的图片)通常不会导致内存泄漏,但是有几种情况可能会导致内存问题: 1. **不正确…...
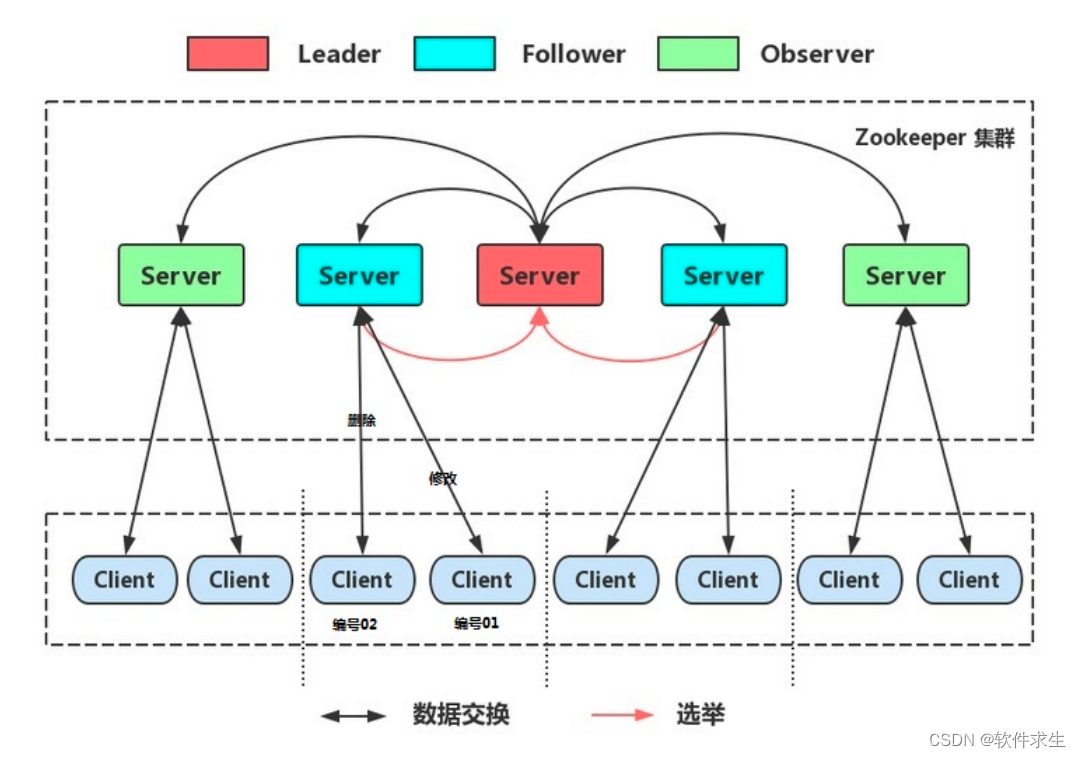
负载均衡与容错性:集群模式在分布式系统中的应用
本文作者:小米,一个热爱技术分享的29岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号“软件求生”,获取更多技术干货! 大家好,我是小米,一个热爱分享技术的29岁程序员。今天我们来聊一聊分布式系统中的一个重要概念:集群(Cluster)模式。相信很多朋友在日常开发…...

【UE5.1 角色练习】09-物体抬升、抛出技能 - part1
前言 在上一篇(【UE5.1 角色练习】08-传送技能)的基础上继续实现控制物体抬升、抛出的功能。 效果 步骤 一、准备技能动画 1. 在项目设置中新建一个操作映射,这里命名为“Skill_GravityControl”,用按键4触发 2. 通过IK重定向…...
最大的游戏交流社区Steam服务器意外宕机 玩家服务受影响
易采游戏网6月3日消息:众多Steam游戏玩家报告称,他们无法访问Steam平台上的个人资料、好友列表和社区市场等服务。同时,社区的讨论功能也无法正常使用。经过第三方网站SteamDB的确认,,这一现象是由于Steam社区服务器突…...
如何手动批准内核扩展 Tuxera NTFS for mac内核扩展需要批准 内核扩展怎么打开
在了解如何手动批准内核扩展之前,我们应该先了解什么叫做内核扩展。内核扩展又被称为KEXT,通过它可以实现macOS系统与软件组件之间的交互,例如磁盘管理、任务管理和内存管理等等。 kext 是内核扩展(Kernel Extension)…...

ffmpeg常用命令
推流 ffmpeg -re -stream_loop -1 -i in.flv -c copy -f flv outurl 推流追加时间戳 ffmpeg -stream_loop -1 -re -i move.flv -vf "settbAVTB,setptstrunc(PTS/1K)*1Kst(1,trunc(RTCTIME/1K))-1K*trunc(ld(1)/1K),drawtextfontfilearial.ttf:text%{localtime}.%{eif\:…...

在MongoDB中,您可以通过以下步骤来创建账号密码,并限制其在特定数据库上的访问权限
在MongoDB中,您可以通过以下步骤来创建账号密码,并限制其在特定数据库上的访问权限: 连接到MongoDB数据库: 使用MongoDB的客户端(如mongo shell或者MongoDB Compass)连接到MongoDB服务器。 切换到admin数…...
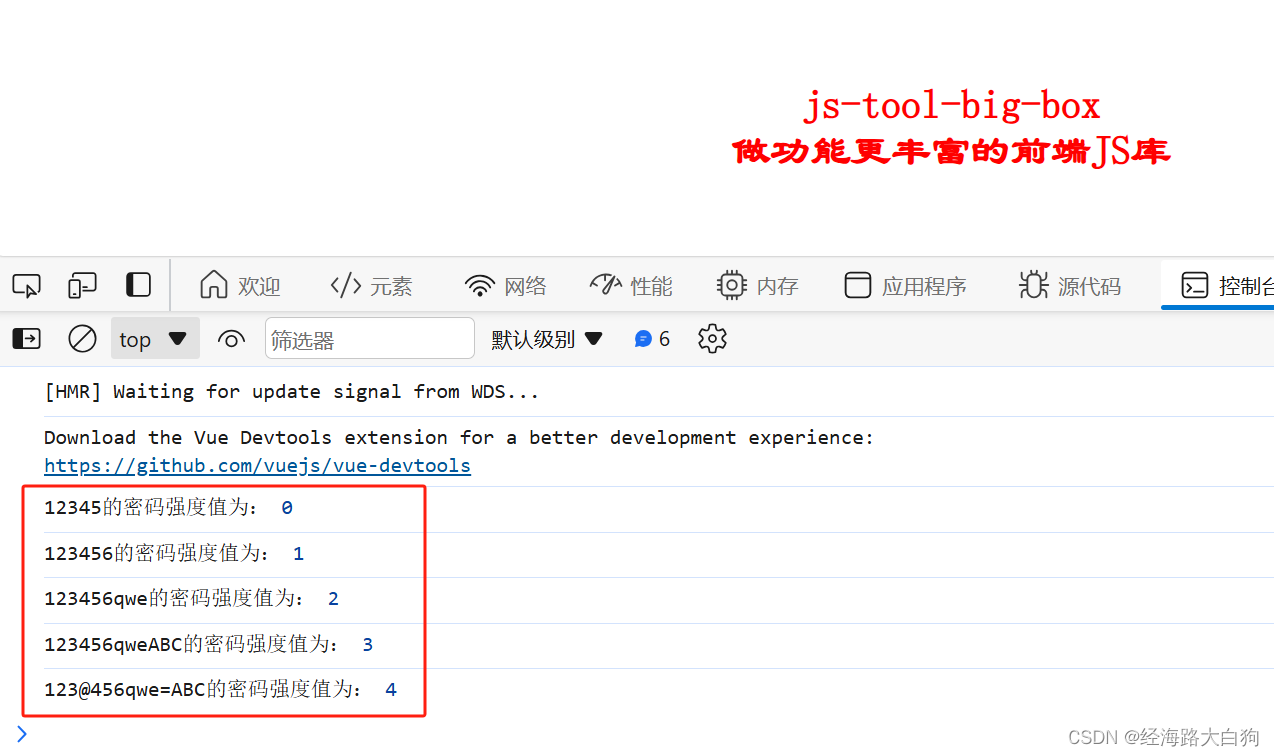
前端JS必用工具【js-tool-big-box】学习,检测密码强度
js-tool-big-box 前端工具库,实用的公共方法越来越多了,这一小节,我们带来的是检测密码强度。 我们在日常开发中,为了便于测试,自己总是想一个简单的密码,赶紧输入。但到了正式环境,我们都应该…...

PHP精度处理
一、问题缘由 PHP 服务接收前端传过来的单价(字符串形式)和数量,把单价转成分(单价*100),然后传给下游的 Golang 服务,不过最后从两个服务日志中发现金额相差 1。 以下为前端传的 {"amount": 4,"price": "9.2&qu…...

618电商大战开启!2024淘宝京东618满减规则与优惠力度大比拼
2024年淘宝和京东的618电商大战即将打响。作为一年一度的购物狂欢节日,今年618的满减规则和优惠力度再次成为消费者关注的焦点。在这场激烈的电商角逐中,究竟哪家平台能更胜一筹?让我们一起来揭晓答案! 淘宝京东满减规则大揭秘 淘…...
【全开源】种草分享|动态朋友圈|瀑布流|uniapp
一款基于FastadminThinkPHP和Uniapp开发的种草分享评论点赞消息提醒系统,发布动态,分享种草生活,可以收藏关注点赞,消息提醒,同时支持H5/小程序/app多端。 让每一次互动都不再错过🔔 🌱 种草…...

HDTune和CrystalDiskInfo硬盘检测S.M.A.R.T.参数当前值最差值阈值
高亮颜色说明:突出重点 个人觉得,:待核准个人观点是否有误 高亮颜色超链接 文章目录 S.M.A.R.T.监控技术磁盘健康状态监测,硬盘检测硬盘检测工具 HD Tune硬盘检测工具 CrystalDiskInfo 当前值最差值阈值原始值的含义二级标题待补充待补充 开头…...

Homebrew、RVM、ruby、cocoapods
安装Homebrewe 方式1:公司源安装 方式2:国内源安装 /bin/ssh -c “$(curl -fsSL https://gitee.com/cunkai/HomebrewCN/raw/master/Homebrev.sh)” 方式3:官网源安装(有可能443): ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)…...

Windows右键菜单终极清理教程:ContextMenuManager免费工具帮你告别臃肿与卡顿
Windows右键菜单终极清理教程:ContextMenuManager免费工具帮你告别臃肿与卡顿 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你的Windows右键菜单是…...

终极指南:如何用PowerShell一键安装Windows包管理器Winget [特殊字符]
终极指南:如何用PowerShell一键安装Windows包管理器Winget 🚀 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.…...

告别手动摆放!UE5.2+PCG插件:程序化实现枯木生蘑菇、岩石长苔藓的生态细节
UE5.2程序化生态细节:用PCG插件实现枯木生蘑菇的魔法 当游戏场景中的枯木自动长出蘑菇,岩石表面自然覆盖苔藓时,这种生态细节的呈现往往能让虚拟世界瞬间"活"起来。传统手动摆放的方式不仅耗时耗力,更难以实现自然生长的…...
)
别再硬编码了!ABAP Text Elements 三分钟搞定报表字段中文显示(附图标添加技巧)
ABAP文本元素实战:告别硬编码的报表开发艺术 每次看到报表界面上那些冷冰冰的字段名——MATNR、WERKS、VBELN——你是不是也感到一丝尴尬?业务用户可不懂这些技术缩写,他们需要的是直观的"物料编号"、"工厂"和"销售…...

433MHz无线模块解码避坑指南:从示波器抓波形到STM32代码实现的完整流程
433MHz无线模块解码实战:从波形分析到STM32代码优化的全流程解析 1. 解码前的硬件准备与信号捕获 当你第一次拿到433MHz无线模块时,最令人困惑的往往是"为什么我的代码无法正确解码?"要解决这个问题,我们需要从最基础的…...

别再只盯着IoU了!深入浅出聊聊边界框回归:从IoU到Shape-IoU的演进与选择
边界框回归的进化论:从IoU到Shape-IoU的技术跃迁与实战选型 当我们在计算机视觉领域谈论目标检测时,边界框回归就像是一场永不停歇的进化竞赛。从最初的IoU开始,这场竞赛已经经历了GIoU、DIoU、CIoU、SIoU等多个技术迭代,而最新登…...
)
手把手教你用STM32F103C8T6驱动NRF24L01模块(附完整代码与避坑指南)
STM32F103C8T6与NRF24L01无线通信实战:从硬件对接到代码调试全解析 在物联网和智能硬件快速发展的今天,无线通信技术已成为嵌入式系统设计中不可或缺的一环。NRF24L01作为一款性价比极高的2.4GHz无线收发模块,配合STM32F103C8T6这类主流微控制…...
)
告别枯燥例程:用STM32F4的CAN总线做个简易‘聊天室’(附代码)
用STM32F4的CAN总线打造趣味聊天室:从零实现双向文本通信 当两块STM32开发板通过CAN总线互相发送"Hello World"时,LED灯闪烁的瞬间往往比教科书上的协议框图更让人记忆深刻。这个项目将带您用两片价值不到百元的STM32F4开发板(或一…...

2026年238个好发CCF-A的强化学习idea全面汇总!
最近强化学习领域迎来重磅进展!强化学习之父R.S.Sutton 提出了一种全新的范式:Intentional Updates机制!其不再盲目预设步长,而是先设定一个预期的输出改变目标,实现了内存消耗降低10-100倍的同时,性能依然…...
)
手把手教你用BES AUDIO_DUMP抓取蓝牙耳机通话AEC前后音频(附AU播放教程)
蓝牙耳机AEC算法调试实战:从数据抓取到效果验证全流程 在嵌入式音频开发领域,通话降噪(AEC)算法的效果验证一直是工程师面临的痛点。传统调试方法往往依赖主观听感或简单波形对比,难以精准定位问题。本文将基于BES2500…...