数据结构:详解二叉树(树,二叉树顺序结构,堆的实现与应用,二叉树链式结构,链式二叉树的4种遍历方式)
目录
1.树的概念和结构
1.1树的概念
1.2树的相关概念
1.3树的代码表示
2.二叉树的概念及结构
2.1二叉树的概念
2.2特殊的二叉树
2.3二叉树的存储结构
2.3.1顺序存储
2.3.2链式存储
3.二叉树的顺序结构和实现
3.1二叉树的顺序结构
3.2堆的概念和结构
3.3堆的特点
3.4堆的代码实现
3.4.1堆代码实现中的算法问题
3.4.1.1向上调整算法
3.4.1.2向下调整算法
3.4.2堆代码 Heap.h
3.4.3堆代码Heap.c
3.4.4堆代码test.c
3.5堆的应用(TOP K问题)
3.5.1举例
3.5.2解决问题代码
4.二叉树的链式结构和实现
4.1手搓链式二叉树
4.2遍历链式二叉树
4.2.1前序遍历
4.2.2中序遍历
4.2.3后序遍历
4.2.4层序遍历
编辑
4.3链式二叉树的其他函数
4.3.1二叉树节点个数,叶子节点个数,高度函数
4.3.2二叉树第K层节点个数
4.3.3销毁二叉树
1.树的概念和结构
1.1树的概念
树与我们之前学过的数据结构都不相同,因为其具有一个重要特征:非线性。
树是一种非线性的数据结构,由一组节点(node)和一组连接节点的边(edge)组成。树的基本定义如下:
- 每个树都有一个称为根(root)的节点,根节点是树的顶层节点,没有父节点。
- 除了根节点外,每个节点可以有零个或多个子节点,子节点与父节点之间通过边连接。
- 树中的每个节点都有一个称为父节点(parent)的节点,除了根节点。
- 树中的节点可以拥有一个或多个子节点,每个子节点都有一个称为子树(subtree)的树,由该子节点及其子节点构成。
- 没有子节点的节点称为叶节点(leaf),叶节点位于树的底层。
- 从根节点到任意节点的路径都唯一确定一条边,该边称为该节点的父边。
用图来表示就是:
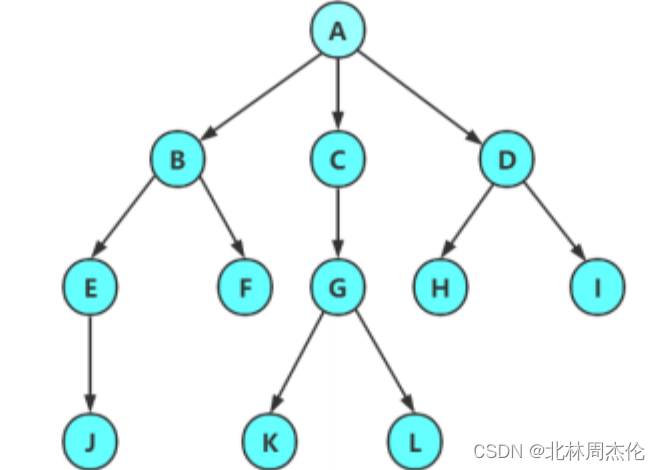
简单来说,数据结构中树就是一种发散性的结构,与我们之前学过的单链表,顺序表,栈和队列这类的线性事物完全不同。计算机中和树有关系的就是文件夹,文件夹一般采用多层次结构( 树状结构 )。在这种结构中每一个磁盘有一个根文件夹 ,它包含若干文件和文件夹。
需要注意的一点是: 在树这种结构,子树之间不能有交集,要不然就不能构成树了。
1.2树的相关概念
在树这种数据结构中包含了很多概念,这些概念基于树的结构,利用人类亲缘关系和树木的概念名称命名。
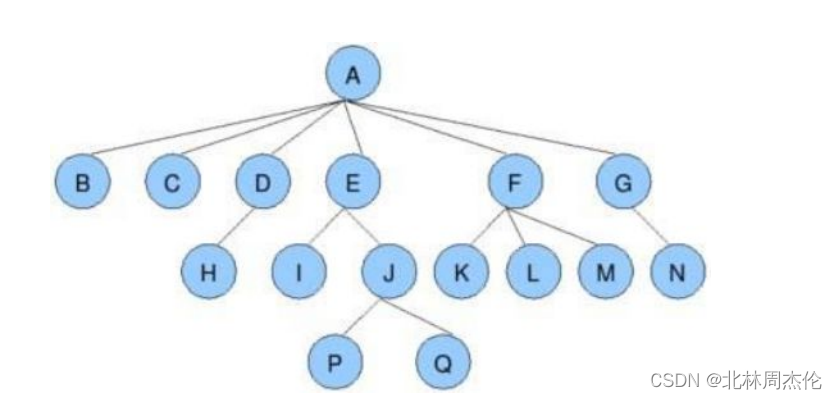
结点的度:一个结点含有的子树的个数称为该结点的度;如上图:A的为6叶结点或终端结点:度为0的结点称为叶结点;如上图:B、C、H、I...等结点为叶结点非终端结点或分支结点:度不为0的结点;如上图:D、E、F、G...等结点为分支结点双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点;如上图:A是B的父结点孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点;如上图:B是A的孩子结点兄弟结点:具有相同父结点的结点互称为兄弟结点;如上图:B、C是兄弟结点树的度:一棵树中,最大的结点的度称为树的度;如上图:树的度为6结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推;树的高度或深度:树中结点的最大层次;如上图:树的高度为4堂兄弟结点:双亲在同一层的结点互为堂兄弟;如上图:H、I互为兄弟结点结点的祖先:从根到该结点所经分支上的所有结点;如上图:A是所有结点的祖先子孙:以某结点为根的子树中任一结点都称为该结点的子孙。如上图:所有结点都是A的子孙森林:由m(m>0)棵互不相交的树的集合称为森林;
1.3树的代码表示
树的代码表示和一些其他数据结构类似,都是利用指针联系不同的数据。而树这个数据结构特殊之处在于是由一个根数据慢慢扩展至很多其他数据。从前面的介绍我们也得知了不同数据之间大体上可以分为两种:父子(祖先)关系和兄弟关系,聪明的发明者就是利用这一点设计出了树的代码表示:
typedef int DataType;
typedef struct Node
{struct Node* firstChild1; // 第一个孩子结点struct Node* pNextBrother; // 指向其下一个兄弟结点DataType data; // 结点中的数据域
}Node;注意:第一个孩子默认是父亲向下最左边的子树。
无论父亲有多少孩子节点,child指向左边第一个孩子。

通过这个设计思路我们能从根出发找到任意一个子树,下面是举例:
(1)
要找到D首先利用(第一个孩子节点指针)找到B,再利用(指向下一个兄弟指针)两次找到D。
(2)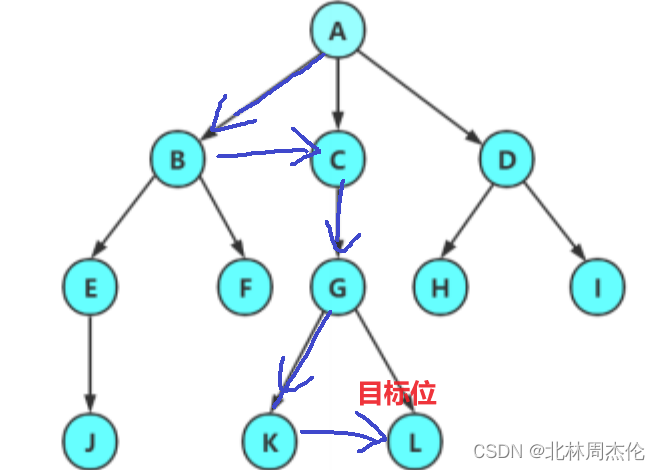
同理,找到L应该走下面这个路线。具体过程不再重复。
2.二叉树的概念及结构
2.1二叉树的概念
二叉树是一种常见的树状数据结构,它由一组称为节点的元素组成,每个节点最多有两个子节点,分别称为左子节点和右子节点。根节点是树的顶部节点,它没有父节点,而其他节点都有且只有一个父节点。
二叉树是树中比较特殊的一种,因为二叉树中每个父节点最多只能有两个子树(左子树和右子树)。

从这张图中我们知道:
1. 二叉树不存在度大于2的结点2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
2.2特殊的二叉树
实际应用中不是所有的二叉树我们都研究,主要有下面两种特殊的二叉树:

1. 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是 2^k-1 ,则它就是满二叉树。2. 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对 应时称之为完全二叉树。 要注意的是 满二叉树是一种特殊的完全二叉树.
2.3二叉树的存储结构
二叉树的储存结构有两种,正好对应之前我们学过的两种数据结构:顺序表(底层是数组)和链表(底层是结构体和指针)。所以,二叉树储存分为顺序存储和链式存储。
2.3.1顺序存储
顺序存储一般只适用于完全二叉树,因为使用顺序存储要利用到数组。而使用数组存储二叉树就必须要用到完全二叉树(因为这样会满足一定的规律,后续会详细讲),所以使用非完全二叉树时会造成数组空间的浪费(有时需要跳过数组中的一些元素)。如下图:
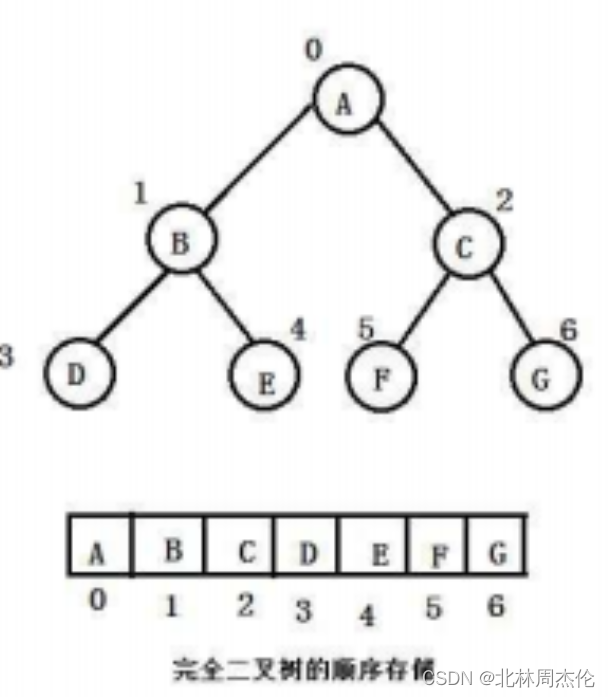
假设4位置是空的,数组中E位置就必须空出来,这样就造成了空间的浪费。
2.3.2链式存储
3.二叉树的顺序结构和实现
3.1二叉树的顺序结构
二叉树的顺序结构是指将二叉树的节点按照顺序存储在一个数组中,同时利用数组索引来表示节点之间的父子关系。
具体而言,假设二叉树的根节点存储在数组索引为0的位置,任意节点在数组中的索引为i,则它的左子节点存储在索引2i+1的位置,右子节点存储在索引2i+2的位置。这种方式可以有效地节省空间,但在插入和删除节点时可能需要进行数组的移动操作,因此不适用于经常需要插入和删除操作的情况。

在用数组存储的时候根部用0表示,每个子树都要-1.这样就满足前面所说的:
左子树=父亲*2+1;右子树=父亲*2+2.

3.2堆的概念和结构
在数据结构中,堆(Heap)是一种特殊的树形数据结构,它满足以下两个特性:
堆是一个完全二叉树(Complete Binary Tree)。这意味着除了最底层之外的所有层都被完全填满,并且最底层从左到右填充。
堆中的每个节点的值都必须满足堆属性(Heap Property):“对于大顶堆(或最大堆),父节点的值大于或等于其子节点的值;对于小顶堆(或最小堆),父节点的值小于或等于其子节点的值”。
基于上述属性,堆可以分为两种常见的类型:大堆和小堆。
下图就是大堆和小堆最直观的区别:
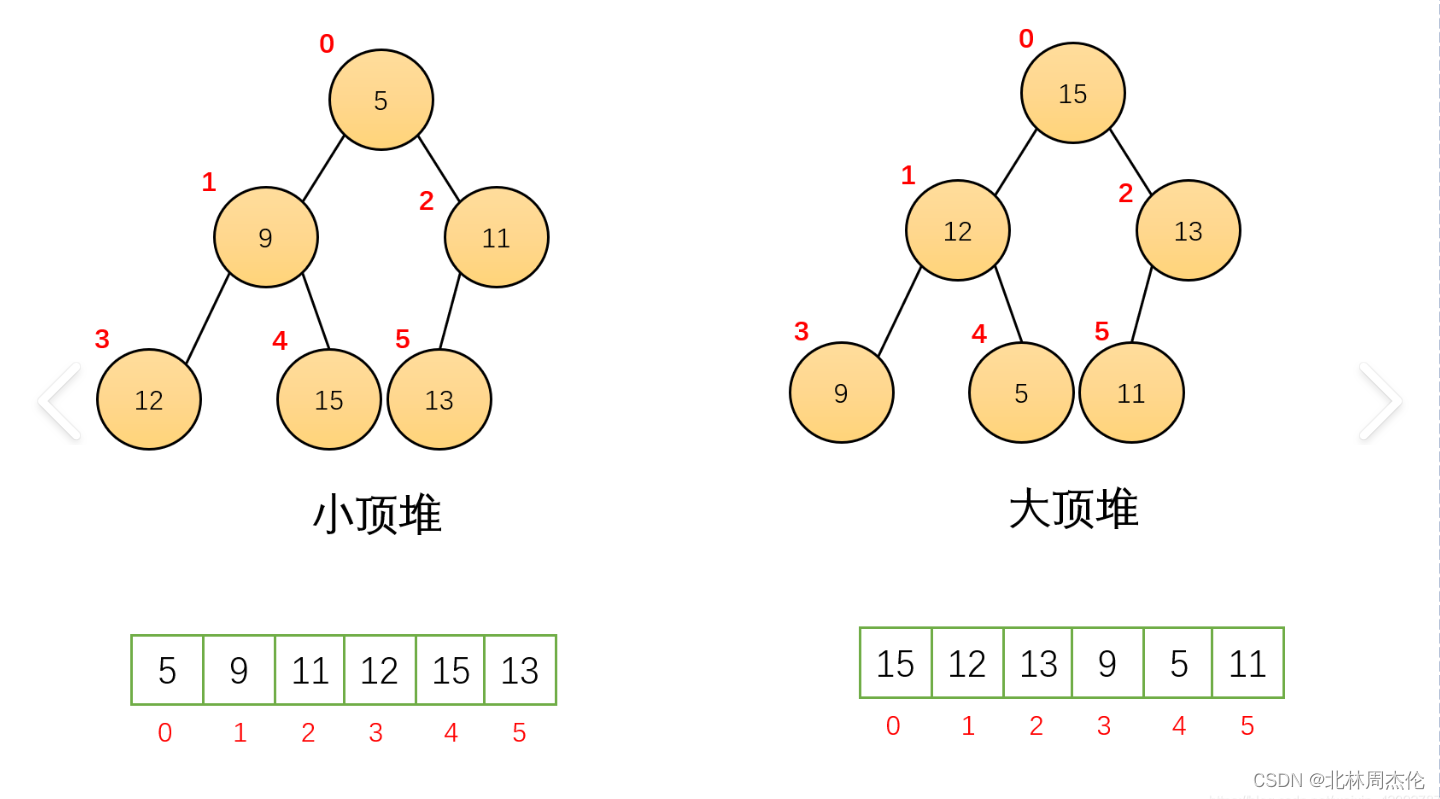
3.3堆的特点
无论是小堆还是大堆,祖先的位置和子树的位置之间都有一定的关系(这一特点对后面关于对的代码实现很有用处)。
特点如下:
1.堆是以数组作为底层的,存储数据的逻辑结构是一颗二叉树,存储数据的物理结构是数组。
2.想象中的二叉树上的每一个数据都是数组中的一个元素,都有自己的编号(就是作为数组元素的下标 )。
3.二叉树上的数据的编号有一定的规律:
(1)由父亲找儿子:左子树=父亲*2+1;右子树=父亲*2+2。
(2)由儿子找父亲:父亲=(儿子-1)/2.(这个公式容易记错先-1还是先/2的话可以自己画一个二叉树的图去判断)。
3.4堆的代码实现
3.4.1堆代码实现中的算法问题
堆代码中的算法问题主要解决一个有序的堆中突然插入或删除一个数据导致有序的堆变为无序的堆的问题,我们需要涉及到的算法有向上调整算法和向下调整算法。
下面我们先来讲向上调整算法:
3.4.1.1向上调整算法
这个算法主要解决的是当一个有序的堆插入新数据时怎样重新调整至有序的状态。
比如下面这个小堆:

它现在是一个有序的小堆存储,如果这个时候我们插入一个新的编号为9的数据14,就像下图:

此时它明显不符合小堆的概念,这个时候就需要向上调整。
小堆排序中向上调整的方法与思路是:
子树与父亲进行比较,如果子树比父亲小,则与父亲交换;若子树比父亲大,则不需要变动。
思路用图来表示就是:

最后,添加了一个数据的无序堆再次变成了有序的小堆。
向上调整算法用代码来表示就是:
//向上调整算法
void AdjustUp(DataType*a,int child)
{assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[child] <= a[parent]){int tmp = a[child];a[child] = a[parent];a[parent] = tmp;child = parent;parent = (child - 1) / 2;}else{break;}}
}3.4.1.2向下调整算法
向下调整算法比向上调整算法稍微复杂一点,用于接下来删除堆顶数据。
还是利用我们刚刚的图像,如果直接删除堆顶数据就像这样:
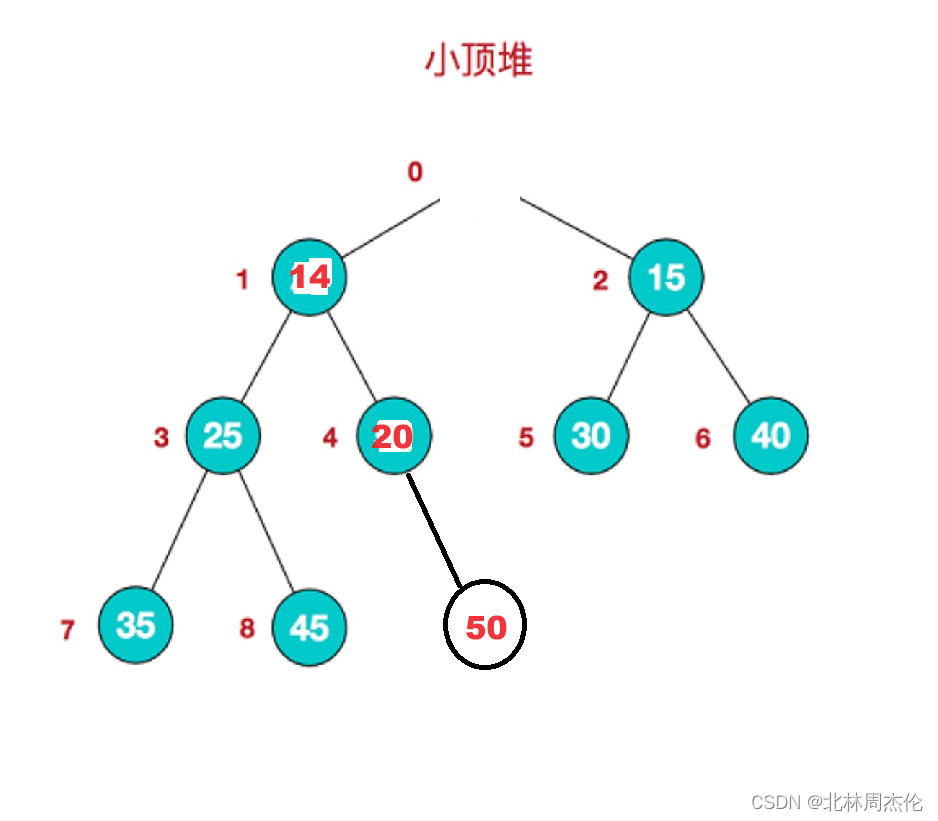
对于剩下数据的重排就比较麻烦,因为动的数据很多(不像向上调整算法一样只要动一列从子孙到祖先的疏忽),非常麻烦。
这个时候科学家想到一种很妙的方式,思路如下:
1.先将堆顶元素和堆的最后一个元素互换。
2.删除堆的最后一个元素(相当于删除了先前的堆顶)。
3.利用向下调整算法将堆重新恢复至小堆。
我们先来讲向下调整算法部分。
小堆排序中向下调整的方法与思路是(刚好与向上调整算法相反):
根数据与子树进行比较,如果根数据比子树大,则与子树交换;若根数据比子树大,则不需要变动。
代码实现如下:
//向下调整算法
void AdjustDown (Heap* hp,DataType parent)
{assert(hp);//假设左孩子比右孩子要小int child = parent * 2 + 1;while (child < hp->size){// 找出小的那个孩子if (child + 1 < hp->size && hp->a[child + 1] < hp->a[child]){++child;}if (hp->a[parent] >= hp->a[child]){int tmp =hp->a[parent];hp->a[parent] = hp->a[child];hp->a[child] = tmp;parent = child;child = parent * 2 + 1;}else{break;}}
}需要注意的是:这个代码与向上调整算法的不同之处在于使用了假设法,先假设左子树比右子树小,假设成功就不需要调整;若假设失败,在使数组的下标++即可。
3.4.2堆代码 Heap.h
堆底层还是数组,所以构成堆的结构体组成与顺序表相似。
#pragma once
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include<stdbool.h>typedef int DataType;typedef struct Heap
{DataType* a;int size;int Capacity;
}Heap;// 堆的构建
void HeapInit(Heap* hp);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, DataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
DataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
bool HeapEmpty(Heap* hp);
//展示堆的数据
void HeapPrint(Heap* hp);//向上调整算法
void AdjustUp(Heap*hp,DataType parent);//向下调整算法
void AdjustDown(Heap* hp, DataType parent);3.4.3堆代码Heap.c
答题的实现方式与顺序表比较类似,不同的地方主要有两个:
(1)堆数据的添加和堆数据的删除需要引入向上调整算法和向下调整算法。
(2)堆数据的删除需要三步:
1.堆顶堆底数据交换。(引入临时变量)
2.删除堆底数据。(size--即可)
3.向下调整算法。(调用写好的函数即可)
#include"Heap.h"//向上调整算法
void AdjustUp(DataType*a,int child)
{assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[child] <= a[parent]){int tmp = a[child];a[child] = a[parent];a[parent] = tmp;child = parent;parent = (child - 1) / 2;}else{break;}}
}//向下调整算法
void AdjustDown (Heap* hp,DataType parent)
{assert(hp);//假设左孩子比右孩子要小int child = parent * 2 + 1;while (child < hp->size){// 找出小的那个孩子if (child + 1 < hp->size && hp->a[child + 1] < hp->a[child]){++child;}if (hp->a[parent] >= hp->a[child]){int tmp =hp->a[parent];hp->a[parent] = hp->a[child];hp->a[child] = tmp;parent = child;child = parent * 2 + 1;}else{break;}}
}// 堆的构建
void HeapInit(Heap* hp)
{hp->Capacity = hp->size = 0;hp->a = NULL;
}// 堆的销毁
void HeapDestory(Heap* hp)
{assert(hp);free(hp->a);hp->a = NULL;hp->Capacity = hp->size = 0;
}// 堆的插入
void HeapPush(Heap* hp, DataType x)
{//扩容if (hp->Capacity == hp->size){int NewCapacity = hp->Capacity == 0 ? 4 : 2 * hp->Capacity;DataType* tmp = (DataType*)realloc(hp->a,NewCapacity*sizeof(DataType));hp->Capacity = NewCapacity;hp->a = tmp;}if (hp->size == 0){hp->a[0] = x;hp->size++;}else{hp->a[hp->size] = x;hp->size++;//数据添加AdjustUp(hp->a, hp->size - 1);}
}// 堆的删除(删除堆顶数据)
void HeapPop(Heap* hp)
{//1.交换int tmp = hp->a[0];hp->a[0] = hp->a[hp->size - 1];hp->a[hp->size-1]=tmp;//2.删除末尾数据hp->size--;//3.向下调整算法AdjustDown(hp,0);
}// 取堆顶的数据
DataType HeapTop(Heap* hp)
{assert(hp);return hp->a[0];
}// 堆的数据个数
int HeapSize(Heap* hp)
{return hp->size;
}// 堆的判空
bool HeapEmpty(Heap* hp)
{if (hp->size == 0){return false;}else{return true;}
}//展示堆的数据
void HeapPrint(Heap* hp)
{for (int i=0;i<hp->size;i++){printf("%d ",hp->a[i]);}
}3.4.4堆代码test.c
#include"Heap.h"int main()
{Heap hp;// 堆的构建HeapInit(&hp);// 堆的插入HeapPush(&hp,1);HeapPush(&hp, 6);HeapPush(&hp, 48);HeapPush(&hp, 45);HeapPush(&hp, 17);HeapPush(&hp, 172);HeapPush(&hp, 51);HeapPush(&hp, 5);//展示堆的数据HeapPrint(&hp);// 堆的删除HeapPop(&hp);printf("\n");HeapPrint(&hp);// 堆的销毁HeapDestory(&hp);return 0;
}效果如下:

3.5堆的应用(TOP K问题)
3.5.1举例
我们知道数据结构的学习就是为了处理数据,堆排序的一个重要应用就是可以解决TOP K问题,下面我们简单介绍一下TOP K问题。
TOP K问题可以举出下面的例子:
(1)(实例)假设王者荣耀有几亿个玩家,其中有一般的人都玩过亚瑟这个角色。现在系统要根据每位玩家亚瑟的数据排出全国前十的亚瑟。
(2)现在随机生成10000个数字,要把最大的5个数字筛选出来。
我们将上述王者荣耀的例子换成整型数字,一亿个数字=4亿字节≈4G。现在面试官问你能否用1G的内存找出最大的10个数字?解法如下:
将1亿个数字分为4堆,分4次堆排序,每次筛选出最大的10个数字,最后再对40个数字来一次堆排序,挑出最大的10个数字即可。
现在面试官改变问法:能否用1KB的内存完成上述的事情呢?方法如下:
先用前10个数字组成一个小堆,之后遍历1亿个数字,将这1亿个数字都与小堆顶的数字比较。如果比小堆顶的数字大,就交换,同时再利用向下调整算法重新恢复成小堆;如果比小堆顶的数字还小就不做变动。最后留在小堆的10个数字就是最大的10个数字。这样就可以利用最少的空间办最大的事。
3.5.2解决问题代码
现在我们写出一段代码,来证明我们的思路确实有效果。这段代码大致意思是:给一个长度为10000的数组,生成10000个随机数,利用代码筛选出最大的10个数。
Heap.h , Heap.c大体上与堆代码一致,需要修改的地方如下:
(1)新写了一个HeapAdd函数,当遍历数组时用这个函数来判断数组元素是否要与堆顶元素进行交换。代码如下:
void HeapAdd(Heap* hp, int x)
{if (x >= hp->a[0]){hp->a[0] = x;AdjustDown(hp, 0);}}(2)主函数需要改动
#include"Heap.h"int main()
{Heap hp;srand((unsigned)time(NULL));int arr[10000] = { 0 };//随机生成10000个数字for (int i = 0; i < 10000; i++){arr[i] = rand()%10000+ i;}HeapInit(&hp);//将前10个数组成一个小堆for (int j = 0; j < 10; j++){HeapPush(&hp, arr[j]);}for (int l = 10; l < 10000; l++){HeapAdd(&hp, arr[l]);}HeapPrint(&hp);return 0;
}效果如下:

但是我们不知道找到的这10个数是不是最大的,我们要再对代码进行小小的改动:
#include"Heap.h"int main()
{Heap hp;srand((unsigned)time(NULL));int arr[10000] = { 0 };//随机生成10000个数字for (int i = 0; i < 10000; i++){arr[i] = rand()%10000+ i;//改动位置if (i % 999 == 0){arr[i] += 1000000;}}HeapInit(&hp);//将前10个数组成一个小堆for (int j = 0; j < 10; j++){HeapPush(&hp, arr[j]);}for (int l = 10; l < 10000; l++){HeapAdd(&hp, arr[l]);}HeapPrint(&hp);return 0;
}我们看到留了很多空白的地方就是改动位置,主要是为了创造出最大的10个数(其他的数都在20000以内,而这10个数在100000以上)。效果如下:

证明我们的代码没有问题,TOP K问题被成功解决。
4.二叉树的链式结构和实现
二叉树链式结构的基础结构体代码是:
typedef struct BinaryNode
{int data;struct BinaryNode* LeftTree;struct BinaryNode* RightTree;
}BN;
每棵树都有左右两颗子树,使用两个指针分别指向他们即可。
4.1手搓链式二叉树
为了方便操作,我们手动创造一个二叉树,后续方便写有关二叉树的函数。
假设我们要实现下面这个链式二叉树:
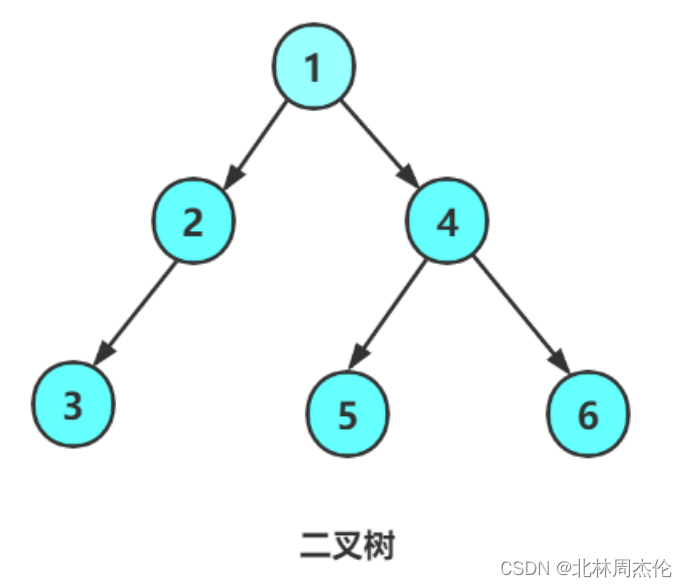
BN* BuyNode(int a)
{BN* NewCapacity = (BN*)malloc(sizeof(BN));if (NewCapacity == NULL){perror("malloc fail");}NewCapacity->data = a;NewCapacity->LeftTree = NULL;NewCapacity->RightTree = NULL;return NewCapacity;
}BN* CreatCapacity()
{BN* Node1 = BuyNode(1);BN* Node2 = BuyNode(2);BN* Node3 = BuyNode(3);BN* Node4 = BuyNode(4);BN* Node5 = BuyNode(5);BN* Node6 = BuyNode(6);Node1->LeftTree = Node2;Node1->RightTree = Node4;Node2->LeftTree = Node3;Node4->LeftTree = Node5;Node4->RightTree = Node6;return Node1;
}主函数内代码如下:
int main()
{BN *pret=CreatCapacity();PreOrder(pret);return 0;
}4.2遍历链式二叉树
二叉树有前序遍历,中序遍历,后序遍历和层序遍历。一般将前序,中序,后序放在一起讲。下面我们就利用上面的二叉树图完成下面几个遍历。
前序,中序,后序遍历代码简单且比较相似,但是理解起来有一定难度,需要用到递归的知识。
4.2.1前序遍历
void PreOrder(BN* root)
{if (root == NULL){printf("N ");return;}printf("%d ", root->data);PreOrder(root->LeftTree);PreOrder(root->RightTree);
}前序遍历是 根---->左边的子树----->右边的子树 这个顺序来遍历的。按照补全空子树的顺序(如下图)应该是:1 2 3 N N N 4 5 N N 6 N N


如右图:红色箭头代表的是指向节点,绿色的线代表指向节点为空时函数return 到上一层函数并且换向(从指向左子树换成指向右子树,即代码中PreOrder(root->LeftTree) 和 PreOrder(root->RightTree) 的变换)。
用递归的思路解释就是下面这张图:(红线表示跳入函数,绿线表示跳出函数)

当遇到NULL的时候函数会沿着绿线向上跳一层,当本函数的所有代码都走完了之后,该函数也会向上跳一层(这就是为什么出现了绿线连续的情况)。
4.2.2中序遍历
中序遍历在代码上的改变非常小,就是把printf和指向左子树的PreOrder调换了一下顺序。
void MiddleOrder(BN* root)
{if (root == NULL){printf("N ");return;}MiddleOrder(root->LeftTree);printf("%d ", root->data);MiddleOrder(root->RightTree);
}按照中序遍历的思路输出的内容应该是:N 3 N 2 N 1 N 5 N 4 N 6 N
递归的思路如下图:

4.2.3后序遍历
后序遍历代码如下:
void BackOrder(BN* root)
{if (root == NULL){printf("N ");return;}BackOrder(root->LeftTree);BackOrder(root->RightTree);printf("%d ", root->data);
}按照后序遍历的思路输出的内容应该是:N N 3 N 2 N N 5 N N 6 4 1
递归的思路如下图:

三种遍历方式最大的不同就在于执行printf的顺序不相同。
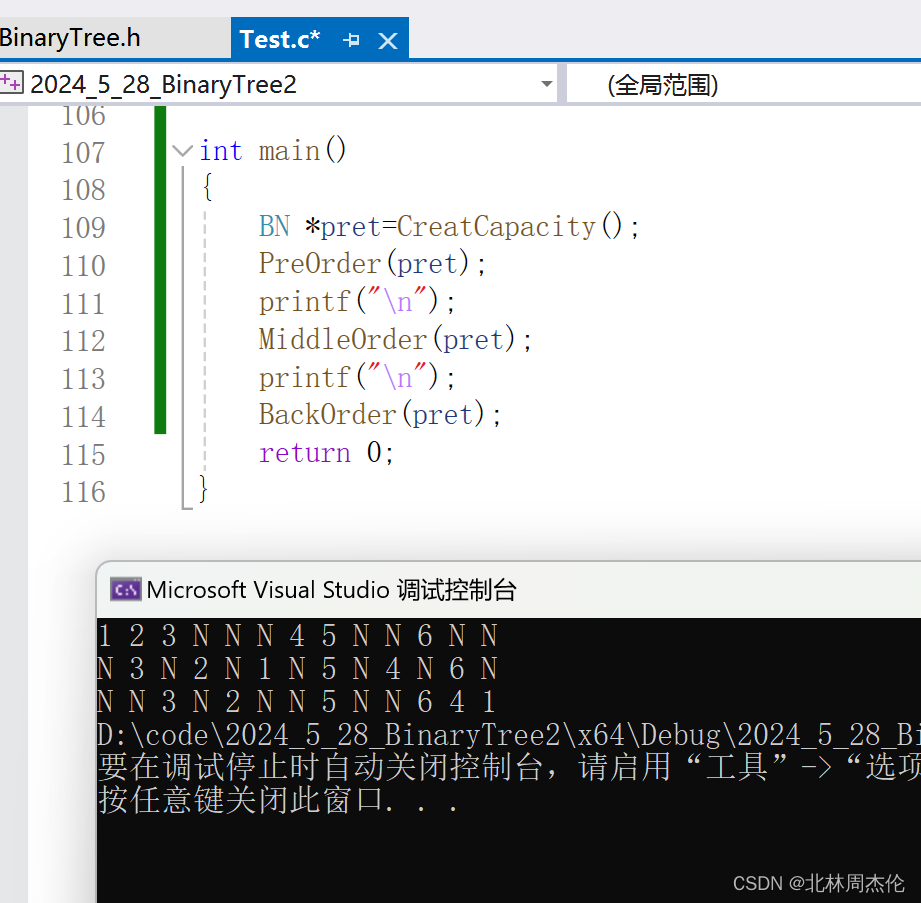
最后三种遍历的所有代码以及运行结果如下:
#include"BinaryTree.h"BN* BuyNode(int a)
{BN* NewCapacity = (BN*)malloc(sizeof(BN));if (NewCapacity == NULL){perror("malloc fail");}NewCapacity->data = a;NewCapacity->LeftTree = NULL;NewCapacity->RightTree = NULL;return NewCapacity;
}BN* CreatCapacity()
{BN* Node1 = BuyNode(1);BN* Node2 = BuyNode(2);BN* Node3 = BuyNode(3);BN* Node4 = BuyNode(4);BN* Node5 = BuyNode(5);BN* Node6 = BuyNode(6);Node1->LeftTree = Node2;Node1->RightTree = Node4;Node2->LeftTree = Node3;Node4->LeftTree = Node5;Node4->RightTree = Node6;return Node1;
}void PreOrder(BN* root)
{if (root == NULL){printf("N ");return;}printf("%d ", root->data);PreOrder(root->LeftTree);PreOrder(root->RightTree);
}void MiddleOrder(BN* root)
{if (root == NULL){printf("N ");return;}MiddleOrder(root->LeftTree);printf("%d ", root->data);MiddleOrder(root->RightTree);
}void BackOrder(BN* root)
{if (root == NULL){printf("N ");return;}BackOrder(root->LeftTree);BackOrder(root->RightTree);printf("%d ", root->data);
}int TreeSize(BN* root)
{return root == NULL ? 0 :TreeSize(root->LeftTree ) + TreeSize(root->RightTree) + 1;
}int TreeLeafSize(BN* root)
{if (root = NULL){return 0;}if (root->LeftTree == NULL && root->RightTree == NULL){return 1;}return TreeLeafSize(root->LeftTree) + TreeLeafSize(root->RightTree);}int TreeHeight()
{}int main()
{BN *pret=CreatCapacity();PreOrder(pret);printf("\n");MiddleOrder(pret);printf("\n");BackOrder(pret);return 0;
}
4.2.4层序遍历
层序遍历顾名思义就是一层一层地读取数据遍历二叉树。其概念如下:
层序遍历是二叉树遍历的一种方法,也称为广度优先遍历。它按照树的层级顺序逐层遍历树的节点。具体操作是从根节点开始,先将根节点加入队列,然后依次取出队列中的节点,访问该节点,并将其左右子节点加入队列。重复该过程,直到队列为空为止。这样可以保证按照从上到下,从左到右的顺序遍历整个二叉树。
像下面这种遍历顺序:

这种遍历方式不能再用递归的方式写出,聪明的科学家想到了用队列实现层序遍历。具体的操作流程如下:
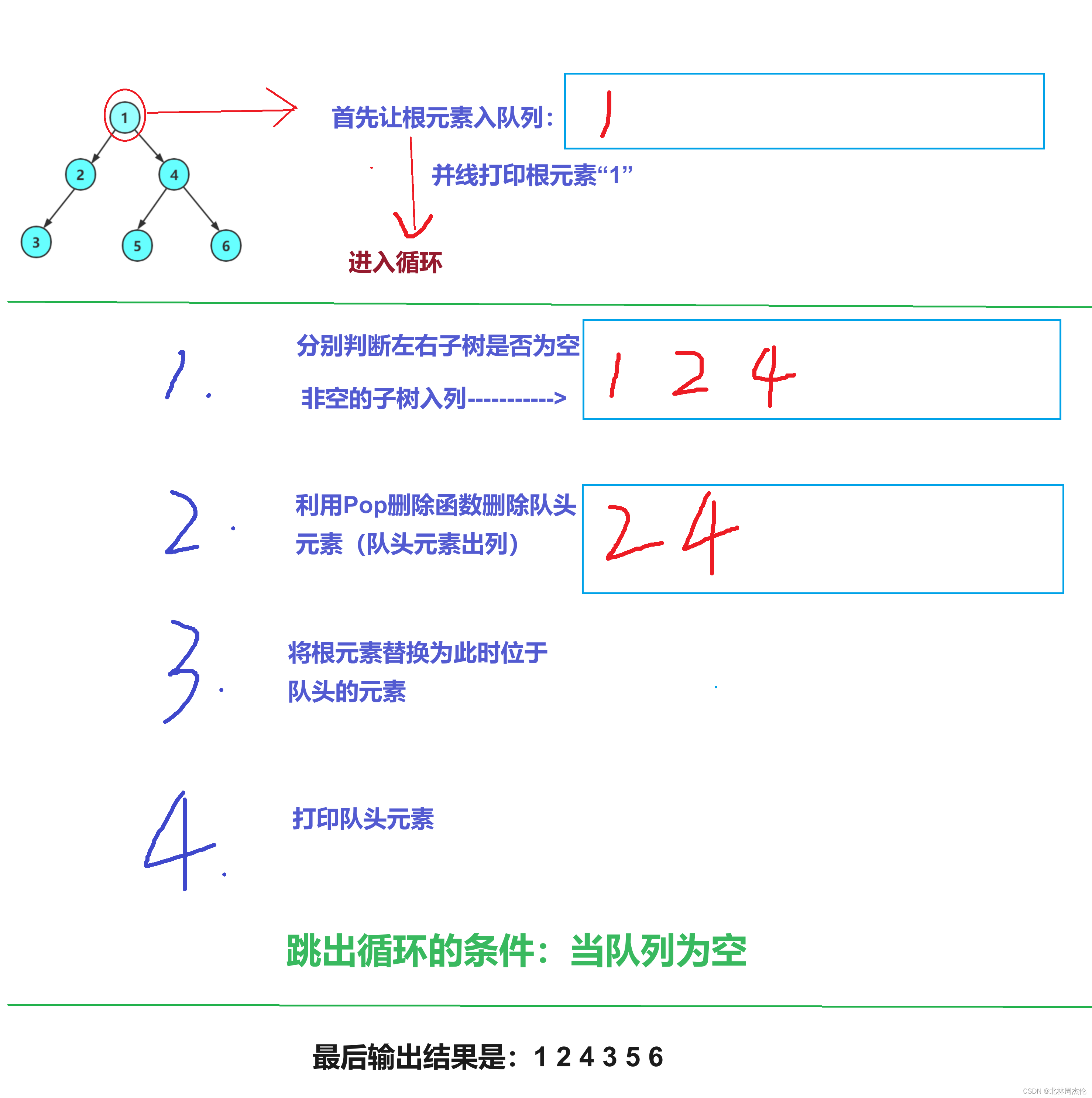
图上展示的只是一次循环,完整循环我们来用文字表示:
第1步: 1 (打印1)
第2步: 1 2 4 (1的左右子树入列)
第3步: 2 4 (打印并删除1)
第4步: 2 4 3 (2的非空子树入列)
第5步: 4 3 (打印并删除2)
第6步: 4 3 5 6 (4的左右子树入列)
第7步: 3 5 6 (打印并删除4)
第8步: 5 6 (打印并删除3)
第9步:6 (打印并删除5)
第10步:NULL (打印并删除6)
代码实现如下:
void LayerOrder(BN* root,Queue*q)
{QueueInit(q);if (root == 0){return ;}else{QueuePush(q,root);printf("%d ", root->data);}while (q->size){if (root->LeftTree != NULL){QueuePush(q, root->LeftTree);}if (root->RightTree!= NULL){QueuePush(q, root->RightTree);}QueuePop(q);if (q->Fir != NULL){root = q->Fir->root;}else{break;}printf("%d ", QueueFront(q));}printf("\n");}入列函数与我们之前写的函数有一些改动,一个参数改成了指针,修改之后的入列函数如下:
// 队尾入队列
void QueuePush(Queue* q, BN*Node)
{assert(q);QNode* Newnode = (QNode*)malloc(sizeof(QNode));Newnode->val = Node->data;Newnode->root = Node;//判断队列是否有元素if (q->Las == NULL){q->Fir = q->Las = Newnode;}else{q->Las->next = Newnode;q->Las = Newnode;//和下面的代码一个意思/*q->Las->next = Newnode;q->Las =q->Las->next;*/}q->size++;
}我们来对层序遍历进行检验:

现在再添加一个数据“7”(加在3的右子树上):
BN* CreatCapacity()
{BN* Node1 = BuyNode(1);BN* Node2 = BuyNode(2);BN* Node3 = BuyNode(3);BN* Node4 = BuyNode(4);BN* Node5 = BuyNode(5);BN* Node6 = BuyNode(6);BN* Node7 = BuyNode(7);Node1->LeftTree = Node2;Node1->RightTree = Node4;Node2->LeftTree = Node3;Node4->LeftTree = Node5;Node4->RightTree = Node6;Node3->RightTree = Node7;return Node1;
}结果如下:

4.3链式二叉树的其他函数
4.3.1二叉树节点个数,叶子节点个数,高度函数
除了遍历,链式二叉树还有其他函数。
二叉树节点个数,二叉树叶子节点个数,二叉树高度函数
代码如下:
int TreeSize(BN* root)
{return root == NULL ? 0 :TreeSize(root->LeftTree ) + TreeSize(root->RightTree) + 1;
}int TreeLeafSize(BN* root)
{if (root == NULL){return 0;}if (root->LeftTree == NULL && root->RightTree == NULL){return 1;}return TreeLeafSize(root->LeftTree) + TreeLeafSize(root->RightTree);}int count = 1; int max = 0;
int TreeHeight(BN*root)
{if (root == NULL){return 0;}if (root->LeftTree == NULL && root->RightTree == NULL){if (max <= count){max = count;}return 1;}count++;TreeHeight(root->LeftTree);TreeHeight(root->RightTree);return 1;}
这3个函数主要用的就是递归的方法,在判断条件和返回值上注意一下就能分析出来。
1.二叉树节点个数函数:当节点不为空时就重复调用函数(先是根节点的左子树再是右子树)并且每次+1,相当于把二叉树遍历一遍。
2.二叉树叶子节点函数。叶子就是外层两个子树都为空的节点。当根就是空的时候,直接返回0,根的左右子树均为0的时候代表已经到叶子处了,于是返回1.再运用递归的手法不断深入遍历二叉树直至找到所有叶子为止,并返回叶子的个数。
3.二叉树高度函数。二叉树的高度就是最深的节点的深度。要创建两个全局变量来记录每次最深节点的深度,最后筛选出最大的那个。深入方式就是每调用一次函数count++,当走到叶子时(到底的时候),就做判断,如果count比max大就赋值给max,最后就能取得最大值了。
测试效果如下:

再改动一下数据,将数据7挂在6的右子树,将8挂在7的左子树,测试结果如下:

4.3.2二叉树第K层节点个数
代码如下:
int TreeLevelKSize(BN* root, int k)
{assert(k > 0); //断言从根节点算起不存在第0层的节点if (root == NULL)return 0;if (k == 1)return 1;return TreeLevelKSize(root->LeftTree, k - 1)+ TreeLevelKSize(root->RightTree, k - 1);//从根节点开始,分别向左子树和右子树深入k-1层;//当二叉树的最深处都比所要查找的层数大则使用assert报错。
}4.3.3销毁二叉树
代码如下:
// 二叉树销毁
void BinaryTreeDestory(BN* root)
{if (root == NULL)return;BinaryTreeDestory(root->LeftTree);BinaryTreeDestory(root->RightTree);free(root);
}结语:二叉树一些基本内容几乎都在本篇文章中,谢谢阅读,如有错误请批评指正
相关文章:
数据结构:详解二叉树(树,二叉树顺序结构,堆的实现与应用,二叉树链式结构,链式二叉树的4种遍历方式)
目录 1.树的概念和结构 1.1树的概念 1.2树的相关概念 1.3树的代码表示 2.二叉树的概念及结构 2.1二叉树的概念 2.2特殊的二叉树 2.3二叉树的存储结构 2.3.1顺序存储 2.3.2链式存储 3.二叉树的顺序结构和实现 3.1二叉树的顺序结构 3.2堆的概念和结构 3.3堆的特点 3…...
HarmonyOS-9(stage模式)
配置文件 {"module": {"requestPermissions": [ //权限{"name": "ohos.permission.EXECUTE_INSIGHT_INTENT"}],"name": "entry", //模块的名称"type": "entry", //模块类型 :ability类型和…...

RestTemplate代码内部访问RESTful服务的客户端工具
1. 前言 在当今的互联网时代,RESTful服务已经成为了一种流行的服务架构风格,它提供了简单、轻量级、灵活、可扩展的方式来构建和访问Web服务。而在Java开发中,Spring框架提供了一个非常方便的工具——RestTemplate,用于访问和调用…...

Flutter 中的 SliverLayoutBuilder 小部件:全面指南
Flutter 中的 SliverLayoutBuilder 小部件:全面指南 Flutter 是一个功能强大的 UI 框架,它提供了丰富的组件来帮助开发者构建高性能、美观的跨平台应用。在 Flutter 的滚动视图系统中,SliverLayoutBuilder 是一个允许开发者根据当前滚动位置…...
家政预约小程序11新增预约
目录 1 创建数据源2 创建页面3 显示选中的服务信息4 设置表单容器5 配置地图6 配置预约成功页面7 从详情页到预约页总结 用户在浏览家政小程序的具体服务时,如果希望预约的,可以在详情页点击立即预约按钮,填写具体的信息,方便家政…...

AI雷达小程序个人名片系统源码 PHP+MYSQL组合开发 带完整的安装代码包以及搭建教程
系统概述 随着移动互联网的普及和社交媒体的兴起,人们获取信息和建立联系的方式发生了翻天覆地的变化。传统的纸质名片已经无法满足现代人的需求,而小程序作为一种轻量级应用,具有无需安装、即开即用、易于分享等特点,成为了个人…...

Kafka生产者消息异步发送并返回发送信息api编写教程
1.引入依赖(pox.xml文件) <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.6.2</version> </dependency> </depende…...
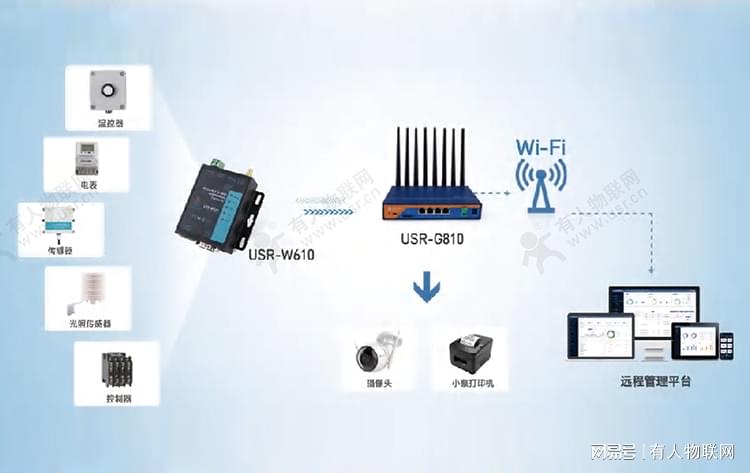
WiFi串口服务器与工业路由器:局域网应用的协同之力
在工业物联网(IIoT)迅猛发展的当下,局域网(LAN)作为连接工业设备与数据中心的桥梁,其重要性日益凸显。WiFi串口服务器与工业路由器作为局域网中的关键组件,以其独特的性能和功能,为传…...
)
Unity功能——通过按键设置物体朝左/右旋转(含C#转xlua版)
博文简介: 开发场景:unity的3d场景; 功能:当设定的键被按下时,进行物体朝左/右旋转; 适用范围:本文代码适用于设置3d物体朝左右旋转,也适用于设置UI对象朝左右旋转…...

泛微ecology开发修炼之旅
我将多年泛微ecology开发经验,进行了总结,然后分享给大家。 泛微开发修炼之旅 泛微开发修炼之旅--01搭建开发环境 泛微开发修炼之旅--02开发接口demo 泛微开发修炼之旅--03常用数据表结构讲解 泛微开发修炼之旅--04常用数据库操作工具类封装 。。。。 我…...

PostgreSQL的视图pg_locks
PostgreSQL的视图pg_locks pg_locks 是 PostgreSQL 提供的系统视图,用于显示当前数据库中的锁信息。通过查询这个视图,数据库管理员可以监控锁的使用情况,识别潜在的锁争用和死锁问题,并优化数据库性能。 pg_locks 视图字段说明…...

元宇宙NFG结合IPO线上营销模型合理降税
在当今快速演进的互联网和区块链技术背景下,我们见证了从移动端购物到区块链热潮,再到如今市场竞争日趋激烈的变革。尤其是在2024年这个关键节点,许多平台为了吸引用户,推出了各种创新的商业模式。然而,如何在这样的环…...
Python打印当前目录下,所有文件名的首字母
代码如下: #!/usr/bin/env python3 """ 按顺序打印当前目录下,所有文件名的首字母(忽略大小写) """ import sys from pathlib import Pathdef main() -> None:ps Path(__file__).parent.glob(…...

程序员应该有什么职业素养?
程序员的六大职业素养:构建成功职业生涯的基石 在不断变化的技术世界中,程序员不单要保持技术的锋利,也需要培养相应的职业素养,这些素养在很大程度上决定了一个程序员的职业生涯能否走得长远。以下是我认为最为重要的六大职业素…...

【PostgreSQL17新特性之-冗余IS [NOT] NULL限定符的处理优化】
在执行一个带有IS NOT NULL或者NOT NULL的SQL的时候,通常会对表的每一行,都会进行检查以确保列为空/不为空,这是符合常理的。 但是如果本身这个列上有非空(NOT NULL)约束,再次检查就会浪费资源。甚至有时候…...
Flink的简单学习二
一 Flink的核心组件 1.1 client 1.将数据流程图DataFlow发送给JobManager。 1.2 JobManager 1.收集client的DataFlow图,将图分解成一个个的task任务,并返回状态更新数据给client 2.JobManager负责作业调度,收集TaskManager的Heartbeat和…...

如何提高员工的工作主动性?
在现代竞争激烈的商业环境中,拥有高度主动性的员工是每个组织所追求的目标。主动性不仅能够促进员工的个人成长,还可以提升团队的效率和创新力。因此,如何提高员工的工作主动性成为了企业管理者需要关注的重要问题。那么如何培养和激发员工的…...

FFmpeg PCM编码为AAC
使用FFmpeg库把PCM文件编码为AAC文件,FFmpeg版本为4.4.2-0 代码如下: #include <stdio.h> #include <stdlib.h> #include <string.h> #include <libavcodec/avcodec.h> #include <libavformat/avformat.h> #include <…...
Render Props)
React@16.x(16)Render Props
目录 1,问题描述2,解决方式2.1,Render Props2.2,HOC 3,使用场景 1,问题描述 当使用组件时,标签中的内容,会被当做 props.children 来渲染: 子组件: import…...

STM32 定时器问题
stm32通用定时器中断问题 STM32 定时器有时一开启就进中断的问题 /// STM32 TIM1高级定时器RCR重复计数器的理解 /// /// /// /// /// /// /// ///...

使用 Python 和 Taotoken 官方风格 SDK 实现你的第一个 AI 对话应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Python 和 Taotoken 官方风格 SDK 实现你的第一个 AI 对话应用 对于刚开始接触大模型应用开发的 Python 程序员来说ÿ…...

基于YOLOv10的低延迟AI瞄准系统:多平台硬件加速与实时检测架构设计
基于YOLOv10的低延迟AI瞄准系统:多平台硬件加速与实时检测架构设计 【免费下载链接】yolov8_aimbot Aim-bot based on AI for all FPS games 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8_aimbot Sunone Aimbot是一个基于YOLOv10深度学习模型的FPS游…...

探索OneMore:解锁OneNote高效笔记的完整指南
探索OneMore:解锁OneNote高效笔记的完整指南 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore OneMore是一款专为OneNote设计的强大插件,通过160…...

可靠度理论导向的海床稳定性分析及评价方法【附仿真】
✨ 长期致力于可靠度、海床稳定性、随机场、响应面法、概率框架、随机有限元法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)Karhunen-Love展开三维…...

从AB类到C类:拆解Doherty功放里载波与峰值支路的相位“打架”问题及宽带补偿方案
从AB类到C类:拆解Doherty功放里载波与峰值支路的相位“打架”问题及宽带补偿方案 在射频功率放大器设计中,Doherty架构因其高效率特性而备受青睐。然而,当工程师们试图将这种架构扩展到更宽频带时,往往会遇到一个令人头疼的问题—…...

工业内窥镜哪家好用?
经常有不同行业的朋友问我,工业内窥镜品牌这么多,到底该怎么选?其实对于大多数企业来说,选择一款适用性广、能满足多种检测场景的设备,才是最划算的。我用了这么多年韦林工业内窥镜,最大的感受就是它几乎能…...

电力市场再调度成本飙升:高比例可再生能源与简化市场设计的结构性矛盾
1. 项目概述:当低净需求成为常态,电力市场再调度成本为何飙升?作为一名长期关注电力市场与能源转型的从业者,我一直在思考一个问题:当风电和光伏成为电力系统的主力军,我们的市场机制真的准备好了吗&#x…...

JMeter精准控制1 QPS的底层原理与三种实战方案
1. 这不是“设个线程数”就能搞定的事很多人第一次用Jmeter做压测,看到“我要每秒发1个请求”,第一反应是:开1个线程,Ramp-up时间设为1秒,循环次数设无限——结果一跑起来,发现TPS忽高忽低,有时…...

别再怕时序违例了!聊聊数字IC设计里那个‘偷时间’的Timing Borrow技巧
数字IC设计中的时序魔术:Timing Borrow实战解析 时钟信号如同城市交通的指挥灯,而数据信号则是川流不息的车辆。当某个路口(关键路径)出现拥堵时,传统做法是拓宽道路(优化逻辑)或降低车速&#…...

3步彻底告别重复GUI操作:零代码AI助手如何让你每天节省2小时
3步彻底告别重复GUI操作:零代码AI助手如何让你每天节省2小时 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-desk…...