Flink的简单学习二
一 Flink的核心组件
1.1 client
1.将数据流程图DataFlow发送给JobManager。
1.2 JobManager
1.收集client的DataFlow图,将图分解成一个个的task任务,并返回状态更新数据给client
2.JobManager负责作业调度,收集TaskManager的Heartbeat和统计信息。
1.3 TaskManager
1.将每一个task任务放到一个TaskSlot槽中
2.TaskManager 之间以流的形式进行数据的传输。
二 Flink的集群搭建
2.1 独立集群
2.1.1 上传解压配置环境变量
1.解压 tar -zxvf flink-1.15.2-bin-scala_2.12.tgz -C ../
2.配置环境变量
# 配置环境变量
vim /etc/profileexport FLINK_HOME=/usr/local/soft/flink-1.15.2
export PATH=$PATH:$FLINK_HOME/binsource /etc/profile2.1.2 修改配置文件
1.修改flink-conf.yaml
jobmanager.rpc.address: master
jobmanager.bind-host: 0.0.0.0
taskmanager.bind-host: 0.0.0.0
taskmanager.host: localhost # noe1和node2需要单独修改
taskmanager.numberOfTaskSlots: 4
rest.address: master
rest.bind-address: 0.0.0.02.修改masters
master:80813.修改workers
node1
node22.1.3 同步到所有节点
1.同步
scp -r flink-1.15.2 node1:`pwd`
scp -r flink-1.15.2 node2:`pwd`2.修改子节点的flink-conf.yaml文件中的taskmanager.host
taskmanager.host: node1
taskmanager.host: node22.1.4 启动与关闭集群
1.启动
start-cluster.sh
2.看是否成功,打开web ui界面
http://master:8081
3.关闭集群
stop-cluster.sh
2.1.5 提交任务
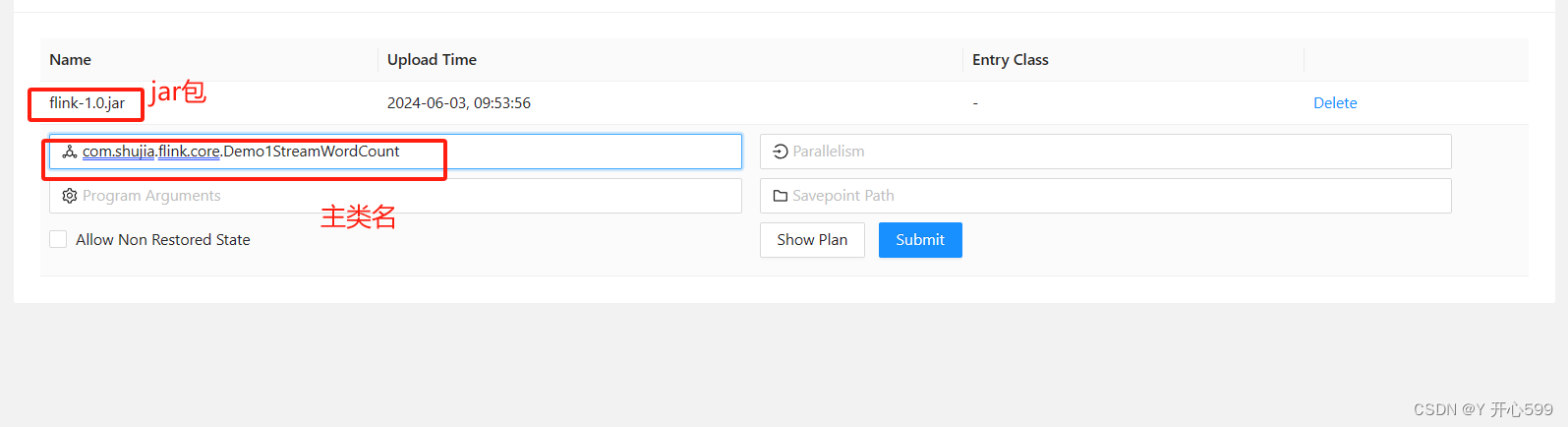
1.将代码打包到服务器中提交
1.启动命令
flink run -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
com.shujia.flink.core.Demo1StreamWordCount:主类名
flink-1.0.jar:jar包名
2.查看web界面
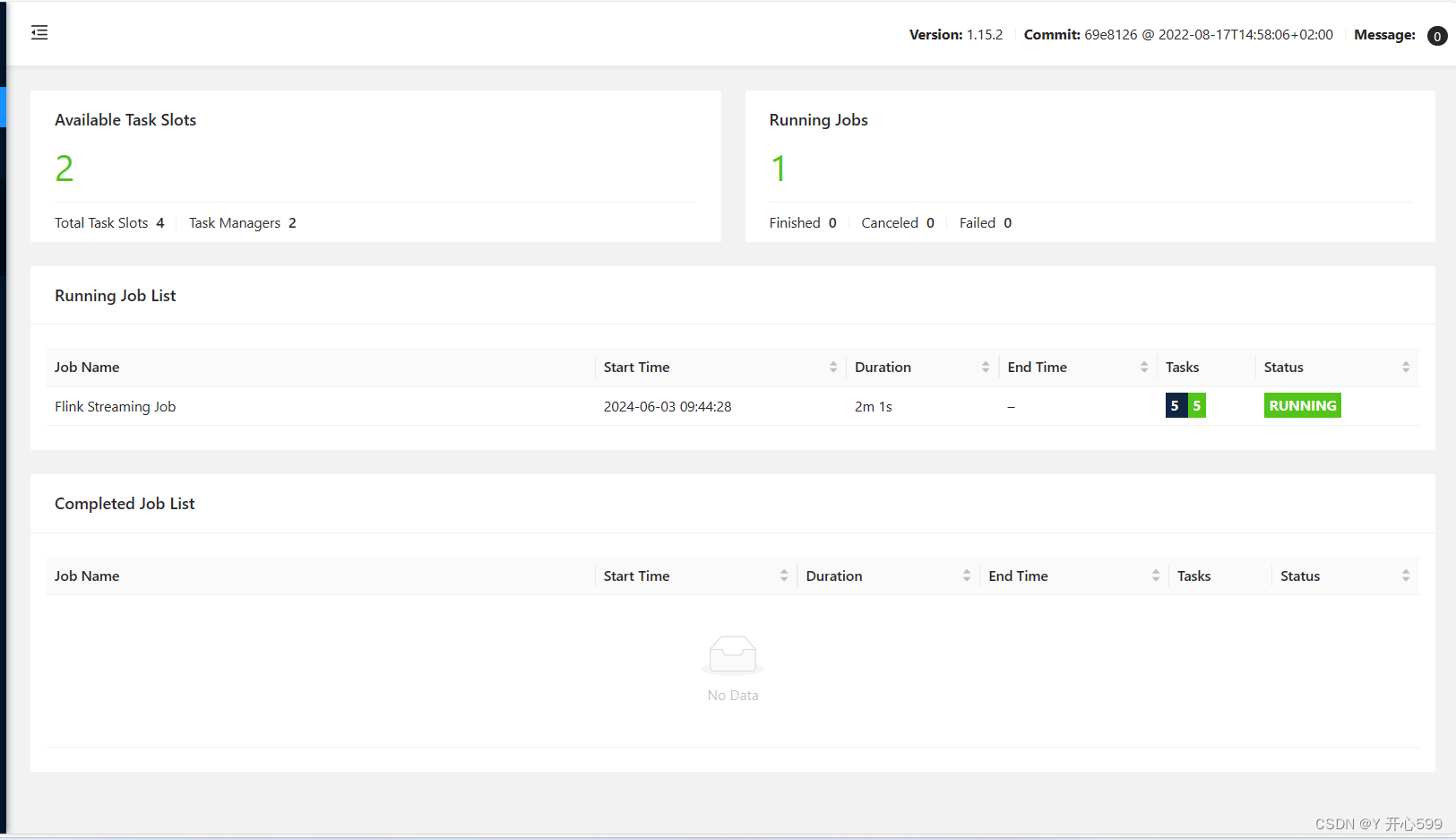
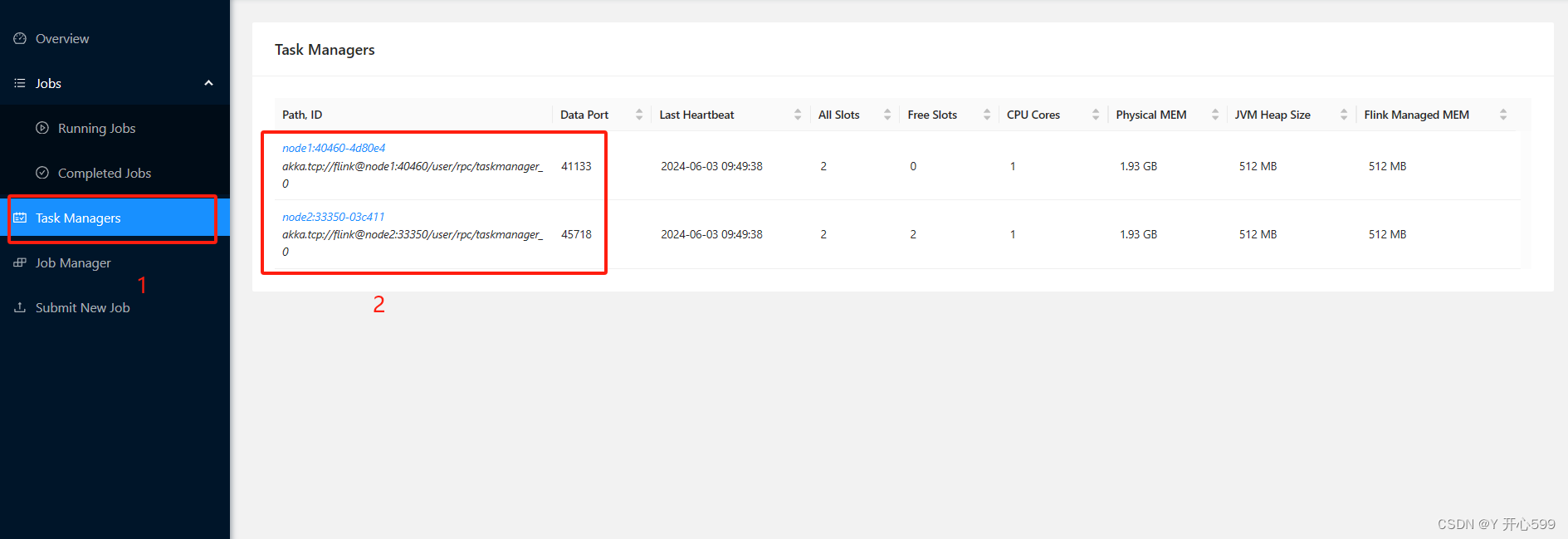
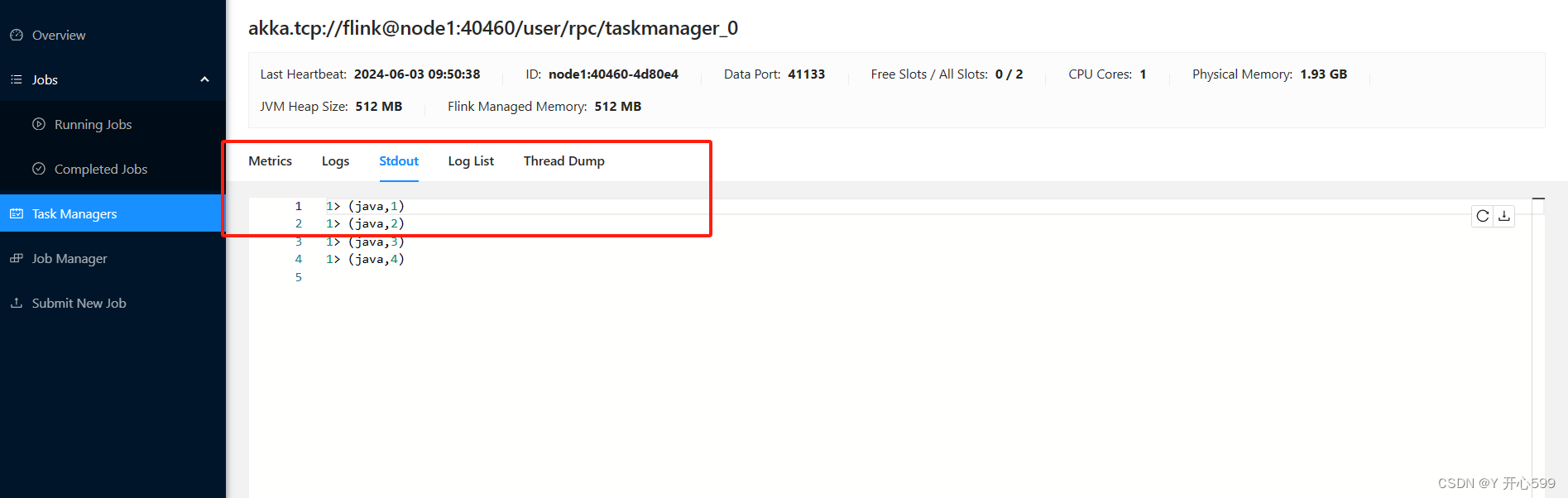
3.查看结果
4.关闭任务
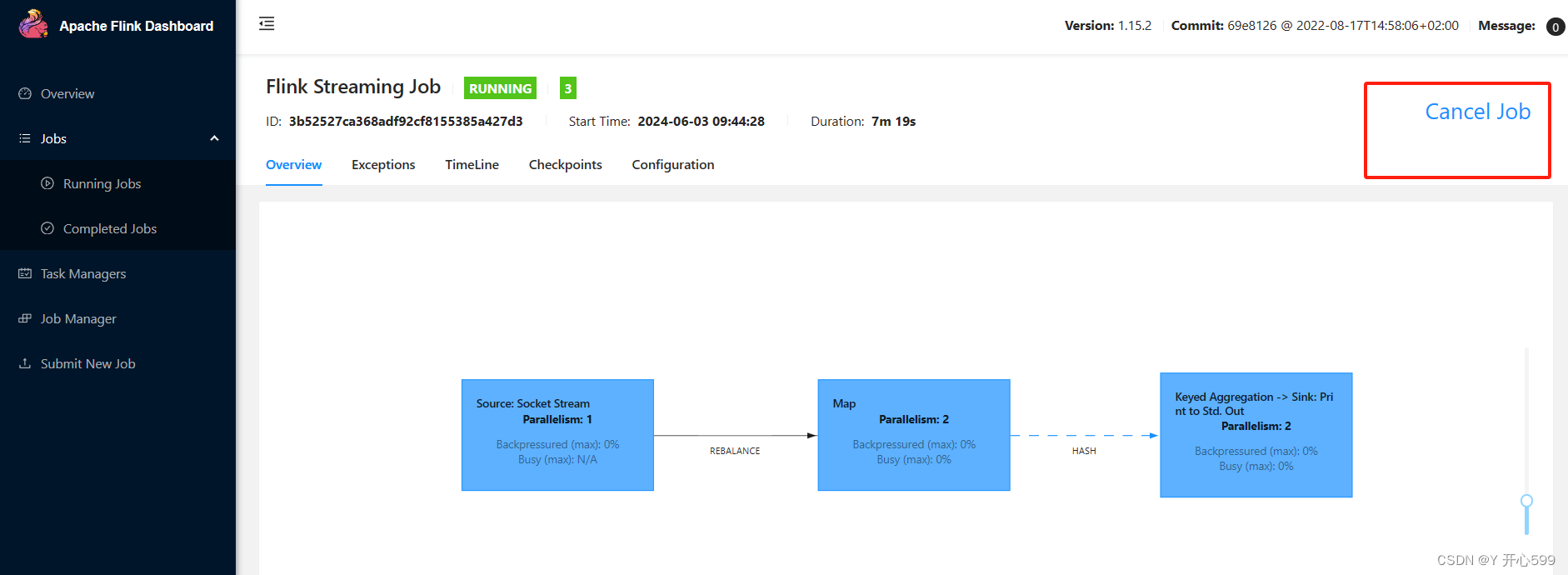
2.web界面提交任务
1.提交
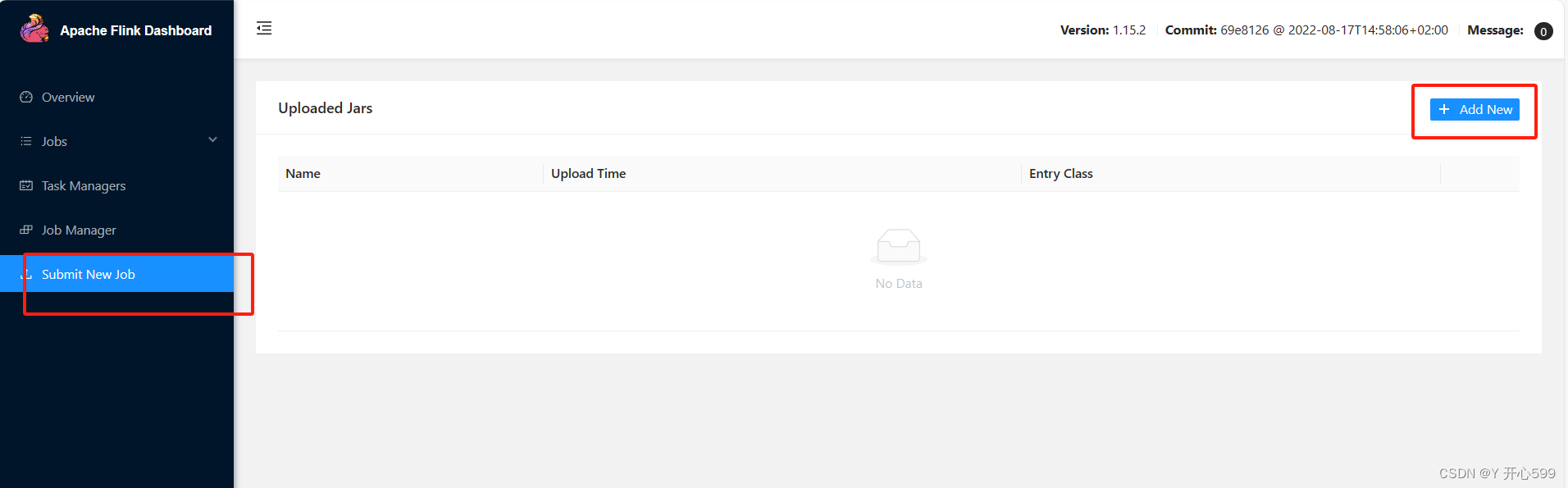
2.相关配置
2.2 Flink on Yarn
2.2.1 整合
1.在环境变量中配置HADOOP_CLASSSPATH
vim /etc/profileexport HADOOP_CLASSPATH=`hadoop classpath`source /etc/profile2.2.2 Application Mode
1、将任务提交到yarn上运行,yarn会为每一个flink地任务启动一个jobmanager和一个或者多个taskmanasger
2、代码main函数不再本地运行,dataFlow不再本地构建,如果代码报错在本地看不到详细地错误日志
1.启动命令
flink run-application -t yarn-application -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
flink run-application -t yarn-application -c:任务命令名
com.shujia.flink.core.Demo1StreamWordCount:主类名
flink-1.0.jar:jar包名
2.查看界面
点击这个,直接跳转到Flink的web界面
2.2.3 Per-Job Cluster Mode
1、将任务提交到yarn上运行,yarn会为每一个flink地任务启动一个jobmanager和一个或者多个taskmanasger
2、代码地main函数在本地启动,在本地构建dataflow,再将dataflow提交给jobmanager,如果代码报错再本地可以烂到部分错误日志
1.启动命令
flink run -t yarn-per-job -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
flink run -t yarn-per-job -c:命令名
com.shujia.flink.core.Demo1StreamWordCount:主类名
flink-1.0.jar:jar包名
2.界面跟Application Mode一样
2.3.4 Session Mode
1、先再yarn中启动一个jobmanager, 不启动taskmanager
2、提交任务地时候再动态申请taskmanager
3、所有使用session模式提交的任务共享同一个jobmanager
4、类似独立集群,只是集群在yarn中启动了,可以动态申请资源
5、一般用于测试
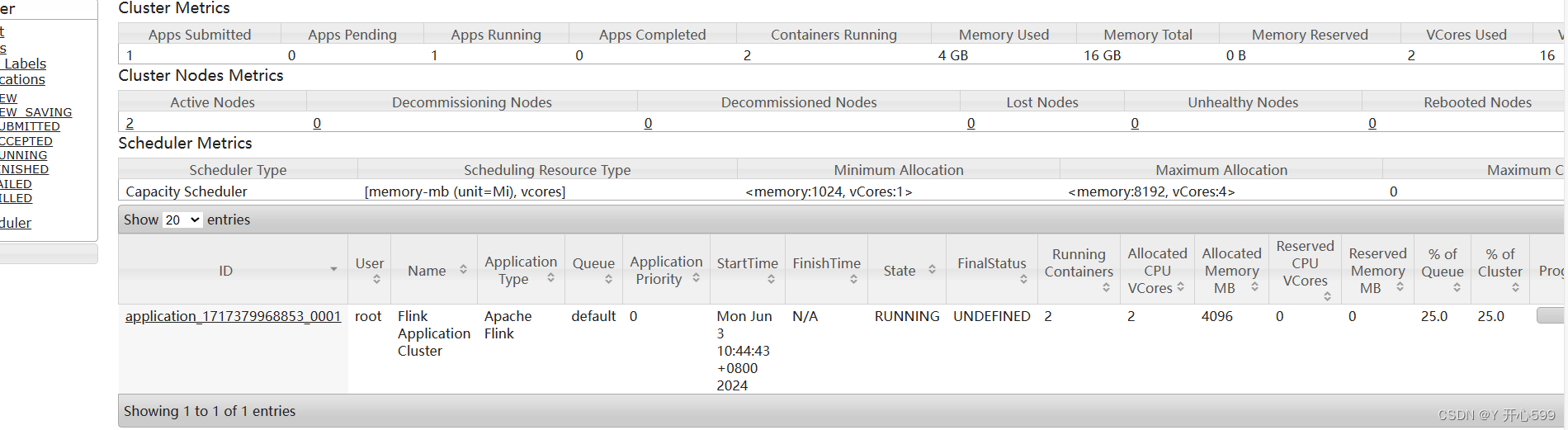
1.先启动会话集群
yarn-session.sh -d
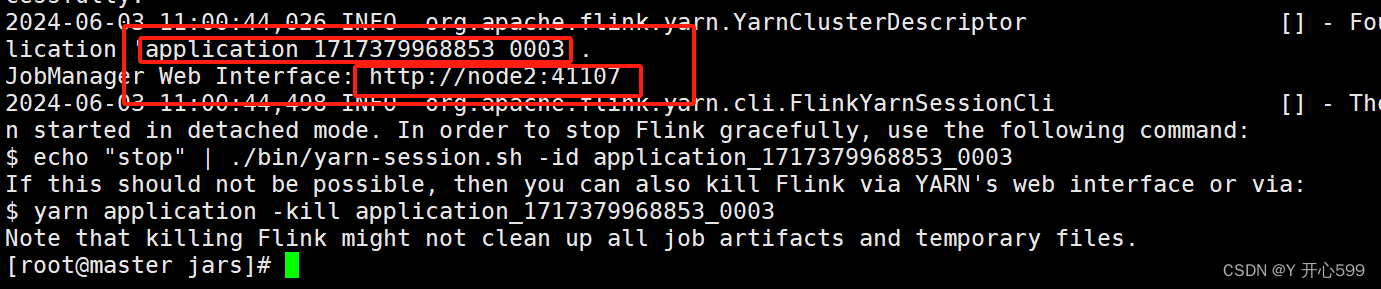
启动过后出现这个,一个是任务编码application_1717379968853_0003
另一个是web界面,复制可以打开
2.提交任务
命令提交:
flink run -t yarn-session -Dyarn.application.id=application_1717379968853_0003 -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
Dyarn.application.id=application_1717379968853_0003:这个是启动会话集群给的
com.shujia.flink.core.Demo1StreamWordCount:主类名
flink-1.0.jar:jar包名
web界面提交:跟Application Mode的web提交一模一样
三 并行度
3.1 设置并行度
3.1.1 代码中设置
1.代码中不设置,默认的并行度数量是配置文件里面的
2.代码中配置
env.setParallelism(2)3.1.2 提交任务中设置
1.加一个参数 -p 并行度数量
例如:
flink run -t yarn-session -p 3 -Dyarn.application.id=application_1717379968853_0003 -c com.shujia.flink.core.Demo1StreamWordCount flink-1.0.jar
2.或者在ui界面中设置

3.1.3 配置文件中设置
1.这个一般不用
在flink-conf.yaml修改配置
3.1.4 每一个算子单独设置
在代码中使用算子时候后面可以设置并行度,但是这种不用
3.1.4 优先级
代码>提交任务中配置>配置文件
3.2 共享资源
1、flink需要资源的数量和task数量无关
2、一个并行度对应一个资源(slot)
3、上游task的下游task共享同一个资源
3.3 并行度设置原则
1.实时计算的任务并行度取决于数据的吞吐量
2、聚合计算(有shuffle)的代码一个并行度大概一秒可以处理10000条数据左右
3、非聚合计算是,一个并行度大概一秒可以处理10万条左右
四 事件时间
4.1 event time
数据产生的时间,数据中有一个时间字段,使用数据的时间字段触发计算,代替真实的时间,可以反应数据真实发生的顺序,计算更有意义
4.1.1 数据时间无乱序
1.解析数据,分析哪个数据是数据时间
2.指定时间字段
forMonotonousTimestamps():单调递增。数据时间只能是往上增的
tsDS.assignTimestampsAndWatermarks(WatermarkStrategy
//指定水位线生产策略,水位线等于最新一条数据的时间戳,如果数据乱序可能会丢失数据
.<Tuple2<String, Long>>forMonotonousTimestamps()
//指定时间字段
.withTimestampAssigner((event, ts) -> event.f1));2.完整代码如下
package com.shujia.flink.core;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import java.time.Duration;public class Demo5EventTime {public static void main(String[] args)throws Exception {/** 事件时间:数据中有一个时间字段,使用数据的时间字段触发计算,代替真实的时间,可以反应数据真实发生的顺序,计算更有意义*//*java,1717395300000java,1717395301000java,1717395302000java,1717395303000java,1717395304000java,1717395305000*/StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> linesDS = env.socketTextStream("master", 8888);//解析数据DataStream<Tuple2<String, Long>> tsDS = linesDS.map(line -> {String[] split = line.split(",");String word = split[0];long ts = Long.parseLong(split[1]);return Tuple2.of(word, ts);}, Types.TUPLE(Types.STRING, Types.LONG));/** 指定时间字段和水位线生成策略*/DataStream<Tuple2<String, Long>> assDS = tsDS.assignTimestampsAndWatermarks(WatermarkStrategy//指定水位线生产策略,水位线等于最新一条数据的时间戳,如果数据乱序可能会丢失数据.<Tuple2<String, Long>>forMonotonousTimestamps()//指定时间字段.withTimestampAssigner((event, ts) -> event.f1));/**每隔5秒统计单词的数量*/DataStream<Tuple2<String, Integer>> kvDS = assDS.map(kv -> Tuple2.of(kv.f0, 1), Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);//TumblingEventTimeWindows:滚动的事件时间窗口WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowDS = keyByDS.window(TumblingEventTimeWindows.of(Time.seconds(5)));windowDS.sum(1).print();env.execute();}
}
3.结果分析
上面代码是以5秒作为一个滚动的事件时间窗口。不包括第五秒,左闭右开。
窗口的触发条件:水位线大于等于窗口的结束时间;窗口内有数据
水位线:等于最新一条数据的时间戳
比如说0-5-10-15-20.0-5是一个窗口,5-10是一个窗口,且窗口里面有数据才能被计算,如果这个窗口里面出现了不存在这个时间的事件,则不会被处理
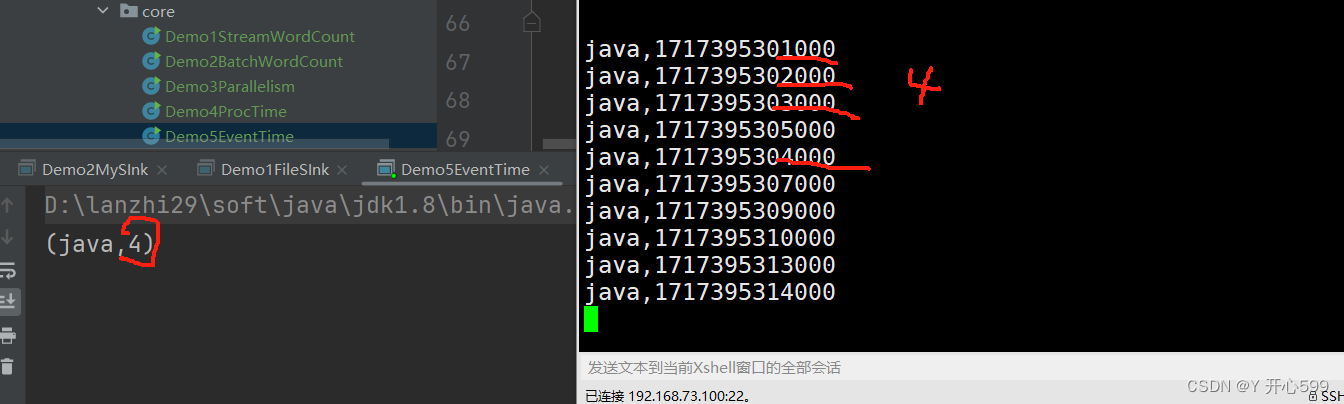
输入的事件时间是乱序的,他丢失第四次输出的。

4.1.2 数据时间乱序
1.水位线前移,使用forBoundedOutOfOrderness里面传入前移的时间
tsDS.assignTimestampsAndWatermarks(WatermarkStrategy
//水位线前移时间(数据最大乱序时间)
.<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))
//指定时间字段
.withTimestampAssigner((event, ts) -> event.f1));2.完整代码
package com.shujia.flink.core;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import java.time.Duration;public class Demo5EventTime {public static void main(String[] args)throws Exception {/** 事件时间:数据中有一个时间字段,使用数据的时间字段触发计算,代替真实的时间,可以反应数据真实发生的顺序,计算更有意义*/StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();/*java,1717395301000java,1717395302000java,1717395303000java,1717395304000java,1717395305000java,1717395307000java,1717395308000java,1717395311000java,1717395313000java,1717395315000*/env.setParallelism(1);DataStream<String> linesDS = env.socketTextStream("master", 8888);//解析数据DataStream<Tuple2<String, Long>> tsDS = linesDS.map(line -> {String[] split = line.split(",");String word = split[0];long ts = Long.parseLong(split[1]);return Tuple2.of(word, ts);}, Types.TUPLE(Types.STRING, Types.LONG));/** 指定时间字段和水位线生成策略*/DataStream<Tuple2<String, Long>> assDS = tsDS.assignTimestampsAndWatermarks(WatermarkStrategy//指定水位线生产策略,水位线等于最新一条数据的时间戳,如果数据乱序可能会丢失数据
// .<Tuple2<String, Long>>forMonotonousTimestamps()//水位线前移时间(数据最大乱序时间).<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))//指定时间字段.withTimestampAssigner((event, ts) -> event.f1));/**每隔5秒统计单词的数量*/DataStream<Tuple2<String, Integer>> kvDS = assDS.map(kv -> Tuple2.of(kv.f0, 1), Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);//TumblingEventTimeWindows:滚动的事件时间窗口WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowDS = keyByDS.window(TumblingEventTimeWindows.of(Time.seconds(5)));windowDS.sum(1).print();env.execute();}
}
3.结果分析
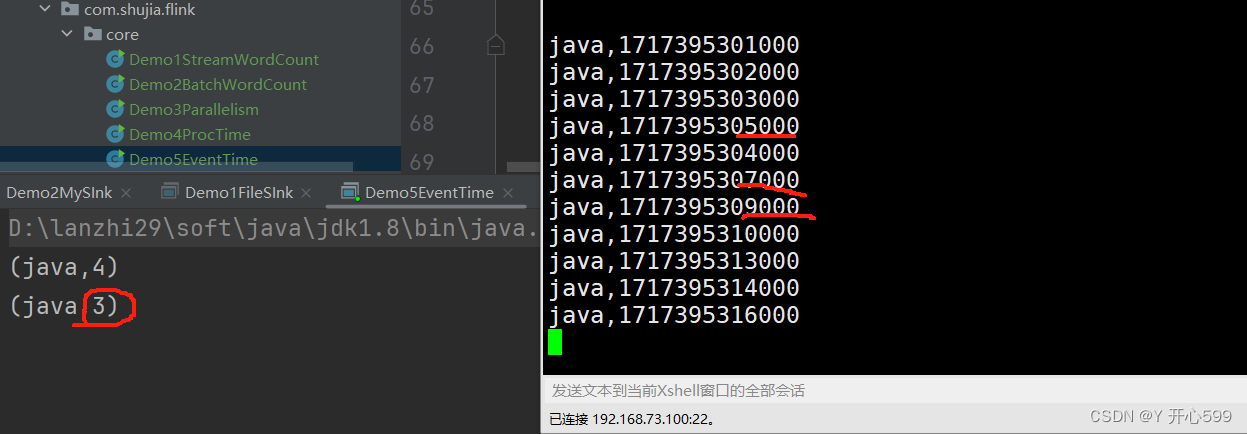
我输入的如图所示,我代码设置了水位线前移5秒中,所以触发时间是10秒才触发任务,0-10秒里有4个0-5里面的数据,所以输出了4.为什么14000没有输出,因为14-5=9,他还没有到下一阶段的水位线。我再输出了16秒的,他就有结果了。
4.1.3 水位线对齐
1.当上游有多个task时,下游task会取上游task水位线的最小值,如果数据量小。水位线就很难对齐,窗口就不会触发计算。故要设置并行度,提前把task设定好。
2.如果不设置并行度,可能要输出很多事件才能触发计算。
4.2 processing time
1.处理时间:真实时间
2.这个代码是设置了滚动的处理时间窗口吗,每现实时间5秒中处理一下数据
package com.shujia.flink.core;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;public class Demo4ProcTime {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> wordsDS = env.socketTextStream("master", 8888);//转换成kvDataStream<Tuple2<String, Integer>> kvDS = wordsDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));//按照单词分组KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);//划分窗口//TumblingProcessingTimeWindows:滚动的处理时间窗口WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowDS = keyByDS.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));//统计单词的数量DataStream<Tuple2<String, Integer>> countDS = windowDS.sum(1);countDS.print();env.execute();}
}
五 窗口
5.1 time window
1.时间窗口有四种:
SlidingEventTimeWindows:滑动的事件时间窗口
SlidingProcessingTimeWindows: 滑动的处理时间窗口
TumblingEventTimeWindows:滚动的事件时间窗口
TumblingProcessingTimeWindows:滚动的处理时间窗口
2.滑动事件需要设置2个时间,一个设置窗口的大小,另一个是滚动的时间
package com.shujia.flink.window;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import java.time.Duration;public class Demo1TimeWindow {public static void main(String[] args)throws Exception {/** 事件时间:数据中有一个时间字段,使用数据的时间字段触发计算,代替真实的时间,可以反应数据真实发生的顺序,计算更有意义*/StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();/*java,1717395301000java,1717395302000java,1717395303000java,1717395304000java,1717395305000java,1717395307000java,1717395308000java,1717395311000java,1717395313000java,1717395315000*//**水位线对齐* 1、当上游有多个task时,下游task会取上游task水位线的最小值,如果数据量小。水位线就很难对齐,窗口就不会触发计算*/env.setParallelism(1);DataStream<String> linesDS = env.socketTextStream("master", 8888);//解析数据DataStream<Tuple2<String, Long>> tsDS = linesDS.map(line -> {String[] split = line.split(",");String word = split[0];long ts = Long.parseLong(split[1]);return Tuple2.of(word, ts);}, Types.TUPLE(Types.STRING, Types.LONG));/** 指定时间字段和水位线生成策略*/DataStream<Tuple2<String, Long>> assDS = tsDS.assignTimestampsAndWatermarks(WatermarkStrategy//指定水位线生产策略,水位线等于最新一条数据的时间戳,如果数据乱序可能会丢失数据
// .<Tuple2<String, Long>>forMonotonousTimestamps()//水位线前移时间(数据最大乱序时间).<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))//指定时间字段.withTimestampAssigner((event, ts) -> event.f1));/**每隔5秒统计单词的数量*/DataStream<Tuple2<String, Integer>> kvDS = assDS.map(kv -> Tuple2.of(kv.f0, 1), Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);/** SlidingEventTimeWindows:滑动的事件时间窗口* SlidingProcessingTimeWindows: 滑动的处理时间窗口* TumblingEventTimeWindows:滚动的事件时间窗口* TumblingProcessingTimeWindows:滚动的处理时间窗口* 滑动的时间窗口需要设置两个时间,第一个是窗口的大小,第二个是记录的时间,* 比如说(15,5),这是每5秒计算最近15秒内的数据*/WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowDS = keyByDS.window(SlidingEventTimeWindows.of(Time.seconds(15),Time.seconds(5)));windowDS.sum(1).print();env.execute();}
}
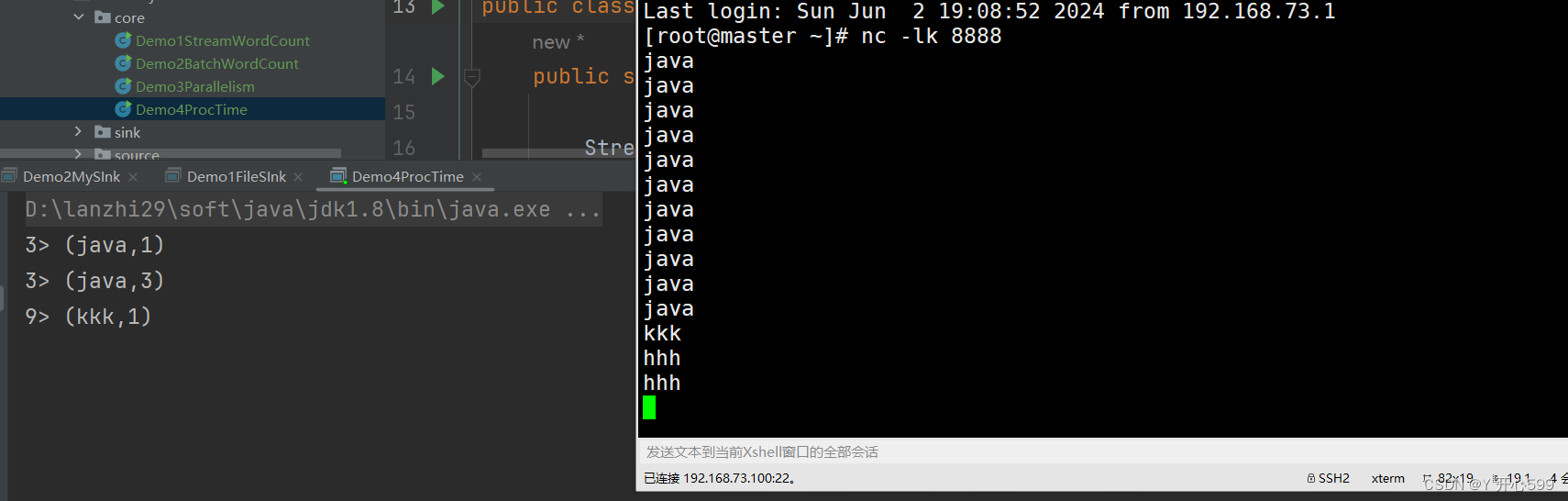
这个代码用的是滑动的事件时间窗口,我设置了每5秒钟计算最近15秒内的数据
5.2 count time
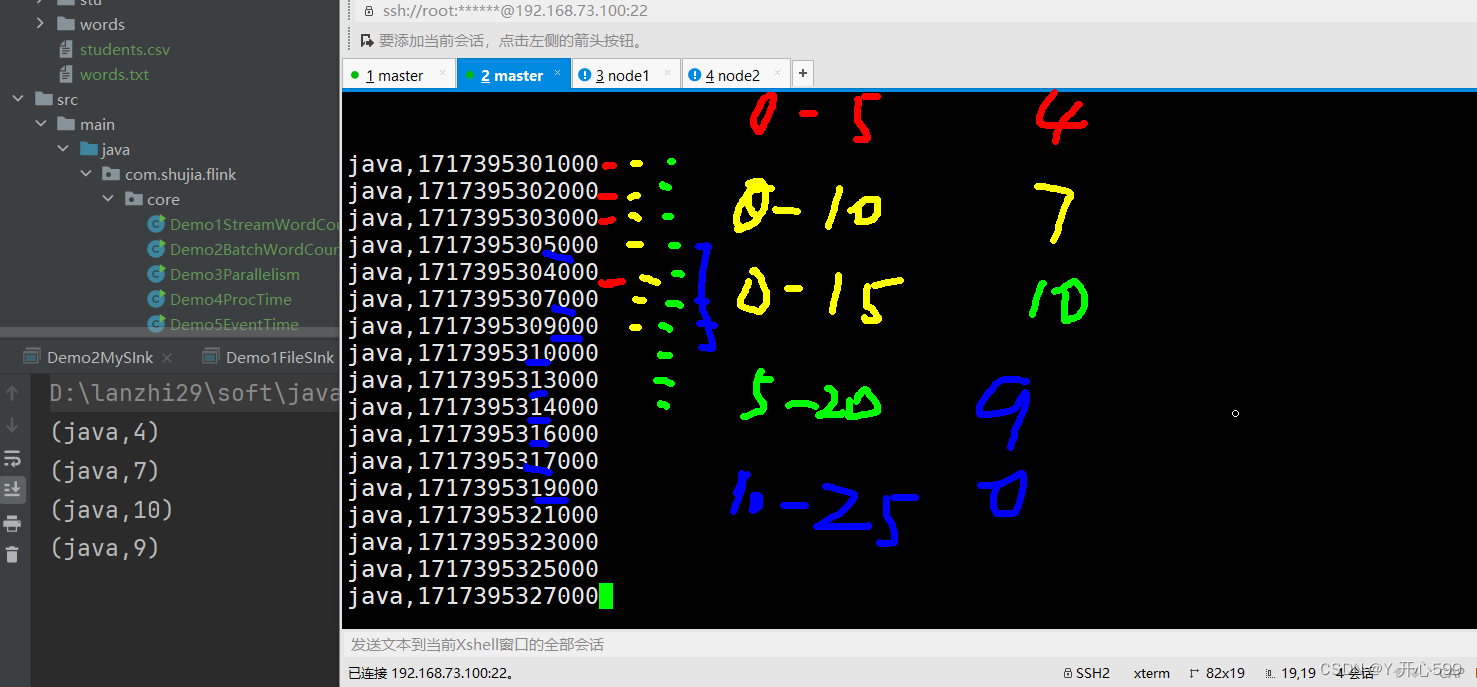
1.滚动的统计窗口:每个key隔多少数据计算一次
package com.shujia.flink.window;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;public class Demo2CountWindow {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> linesDS = env.socketTextStream("master", 8888);DataStream<Tuple2<String, Integer>> kvDS = linesDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);/** 统计窗口* countWindow(10):滚动的统计窗口, 每个key每隔10条数据计算一次* countWindow(10, 2): 滑动的统计窗口,每隔两条数据计算最近10条数据*/WindowedStream<Tuple2<String, Integer>, String, GlobalWindow> countWindowDS = keyByDS.countWindow(10, 2);countWindowDS.sum(1).print();env.execute();}
}

2.滑动的统计窗口:每隔多少数据计算最近的多少条数据
package com.shujia.flink.window;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;public class Demo2CountWindow {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> linesDS = env.socketTextStream("master", 8888);DataStream<Tuple2<String, Integer>> mapDS = linesDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyBy = mapDS.keyBy(kv -> kv.f0);WindowedStream<Tuple2<String, Integer>, String, GlobalWindow> countWindow = keyBy.countWindow(10,2);countWindow.sum(1).print();env.execute();}
}
5.3 session time
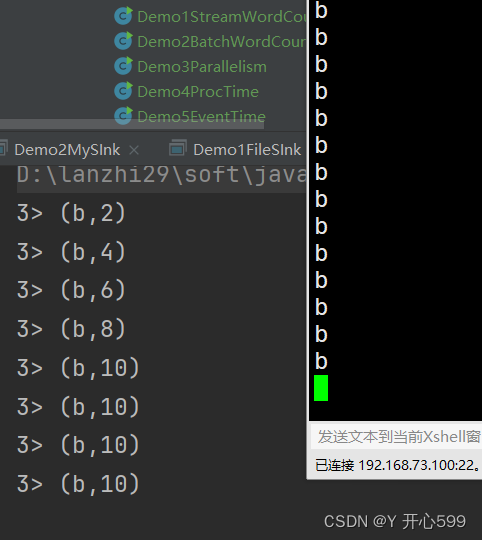
1.处理时间的会话窗口ProcessingTimeSessionWindows:对一个key,10秒内没有下一步数据开始计算。比如说我输入了 a*7次,然后等10秒输出结果是(a,7)。我再输入a*6次加一个aa,那么输出结果是(aa,1)与(a,6).
package com.shujia.flink.window;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;public class Demo3SessionWindow {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> linesDS = env.socketTextStream("master", 8888);DataStream<Tuple2<String, Integer>> mapDS = linesDS.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyBy = mapDS.keyBy(kv -> kv.f0);WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window = keyBy.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)));window.sum(1).print();env.execute();}
}
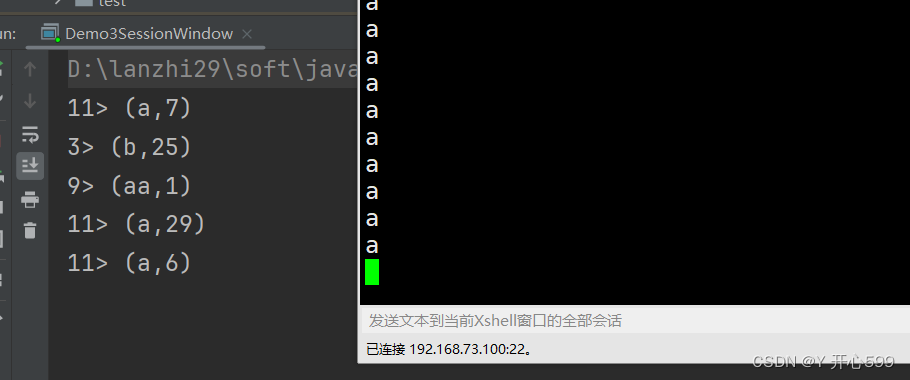
2.事件时间的会话窗口EventTimeSessionWindows:根据数据的时间,对应同一个key,10秒内没有下一步数据开始计算
这个不常用
package com.shujia.flink.window;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.WindowedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;import java.time.Duration;public class Demo4EventTimeSessionWindow {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();/*
java,1685433130000
java,1685433131000
java,1685433132000
java,1685433134000
java,1685433135000
java,1685433137000
java,1685433139000
java,1685433149000
java,1685433155000
java,1685433170000*/env.setParallelism(1);DataStream<String> linesDS = env.socketTextStream("master", 8888);//解析数据DataStream<Tuple2<String, Long>> tsDS = linesDS.map(line -> {String[] split = line.split(",");String word = split[0];long ts = Long.parseLong(split[1]);return Tuple2.of(word, ts);}, Types.TUPLE(Types.STRING, Types.LONG));/** 指定时间字段和水位线生成策略*/DataStream<Tuple2<String, Long>> assDS = tsDS.assignTimestampsAndWatermarks(WatermarkStrategy//水位线前移时间(数据最大乱序时间).<Tuple2<String, Long>>forBoundedOutOfOrderness(Duration.ofSeconds(5))//指定时间字段.withTimestampAssigner((event, ts) -> event.f1));/**每隔5秒统计单词的数量*/DataStream<Tuple2<String, Integer>> kvDS = assDS.map(kv -> Tuple2.of(kv.f0, 1), Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyByDS = kvDS.keyBy(kv -> kv.f0);/** EventTimeSessionWindows:事件时间的会话窗口*/WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowDS = keyByDS.window(EventTimeSessionWindows.withGap(Time.seconds(10)));windowDS.sum(1).print();env.execute(); }
}
5.4 process与窗口结合
1.设置了窗口过后的DS后面用process算子,他里面传入的是实现ProcessWindowFunction中的抽象方法process的对象,这个抽象类里面传的是4个参数(IN, OUT, KEY, W),输入的类型,输出的类型,key的类型,以及窗口类型。窗口类型是三大窗口的其中之一。
2.process方法里面,第一个参数是key,第二个参数是flink的环境连接对象。第三个参数是kv的键值对,第四个参数是发送的对象
代码如下
package com.shujia.flink.window;import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;public class Demo5WindowProcess {public static void main(String[] args) throws Exception{StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<String> linesDS = env.socketTextStream("master", 8888);SingleOutputStreamOperator<Tuple2<String, Integer>> kvDS = linesDS.map(line -> {String[] lines = line.split(",");String clazz = lines[4];int age = Integer.parseInt(lines[2]);return Tuple2.of(clazz, age);}, Types.TUPLE(Types.STRING, Types.INT));KeyedStream<Tuple2<String, Integer>, String> keyBy = kvDS.keyBy(kv -> kv.f0);WindowedStream<Tuple2<String, Integer>, String, TimeWindow> window = keyBy.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));DataStream<Tuple2<String, Double>> process = window.process(new ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Double>, String, TimeWindow>() {@Overridepublic void process(String clazz,ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Double>, String, TimeWindow>.Context context,Iterable<Tuple2<String, Integer>> elements,Collector<Tuple2<String, Double>> out) throws Exception {double sum_age = 0;int num = 0;for (Tuple2<String, Integer> element : elements) {sum_age += element.f1;num++;}double avg_age = sum_age / num;out.collect(Tuple2.of(clazz, avg_age));}});process.print();env.execute();}
}
相关文章:
Flink的简单学习二
一 Flink的核心组件 1.1 client 1.将数据流程图DataFlow发送给JobManager。 1.2 JobManager 1.收集client的DataFlow图,将图分解成一个个的task任务,并返回状态更新数据给client 2.JobManager负责作业调度,收集TaskManager的Heartbeat和…...

如何提高员工的工作主动性?
在现代竞争激烈的商业环境中,拥有高度主动性的员工是每个组织所追求的目标。主动性不仅能够促进员工的个人成长,还可以提升团队的效率和创新力。因此,如何提高员工的工作主动性成为了企业管理者需要关注的重要问题。那么如何培养和激发员工的…...

FFmpeg PCM编码为AAC
使用FFmpeg库把PCM文件编码为AAC文件,FFmpeg版本为4.4.2-0 代码如下: #include <stdio.h> #include <stdlib.h> #include <string.h> #include <libavcodec/avcodec.h> #include <libavformat/avformat.h> #include <…...
Render Props)
React@16.x(16)Render Props
目录 1,问题描述2,解决方式2.1,Render Props2.2,HOC 3,使用场景 1,问题描述 当使用组件时,标签中的内容,会被当做 props.children 来渲染: 子组件: import…...

STM32 定时器问题
stm32通用定时器中断问题 STM32 定时器有时一开启就进中断的问题 /// STM32 TIM1高级定时器RCR重复计数器的理解 /// /// /// /// /// /// /// ///...

CSS学习笔记目录
CSS学习笔记之基础教程(一) CSS学习笔记之基础教程(二) CSS学习笔记之中级教程(一) CSS学习笔记之中级教程(二) CSS学习笔记之中级教程(三) CSS学习笔记之高级…...

随笔-我在武汉一周了
做梦一样,已经来武汉一周了,回顾一下这几天,还真是有意思。 周一坐了四个小时的高铁到了武汉站,照着指示牌打了个出租车。司机大姐开得很快,瞅了眼,最快速度到了110,差点把我晃晕。一下车就感觉…...

Python 爬虫零基础:探索网络数据的神秘世界
Python 爬虫零基础:探索网络数据的神秘世界 在数字化时代,网络数据如同无尽的宝藏,等待着我们去发掘。Python爬虫,作为获取这些数据的重要工具,正逐渐走进越来越多人的视野。对于零基础的学习者来说,如何入…...

微信小程序的view的属性值和用法
在微信小程序中,view 是一个基础的视图组件,用于承载其他视图组件或者展示文本、图片等内容。view 组件具有多种属性,用于控制其行为和样式。以下是一些常用的 view 属性及其用法: class / style: 控制视图的样式,可以…...

Python优化、异常处理与性能提升技巧
Python作为一种高效的编程语言,其灵活性和强大的功能使得它成为了许多开发者的首选。在日常的编程实践中,掌握一些高效的Python技巧可以极大地提升开发效率和代码质量。本文将介绍五个关于Python使用技巧,帮助你更加熟练地运用Python解决问题…...

Flink状态State | 大数据技术
⭐简单说两句⭐ ✨ 正在努力的小叮当~ 💖 超级爱分享,分享各种有趣干货! 👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板 🌈 感谢关注,关注了你就是我的超级粉丝啦! &a…...

go语言方法之方法值和方法表达式
我们经常选择一个方法,并且在同一个表达式里执行,比如常见的p.Distance()形式,实际上 将其分成两步来执行也是可能的。p.Distance叫作“选择器”,选择器会返回一个方法"值"->一 个将方法(Point.Distance)绑定到特定接…...
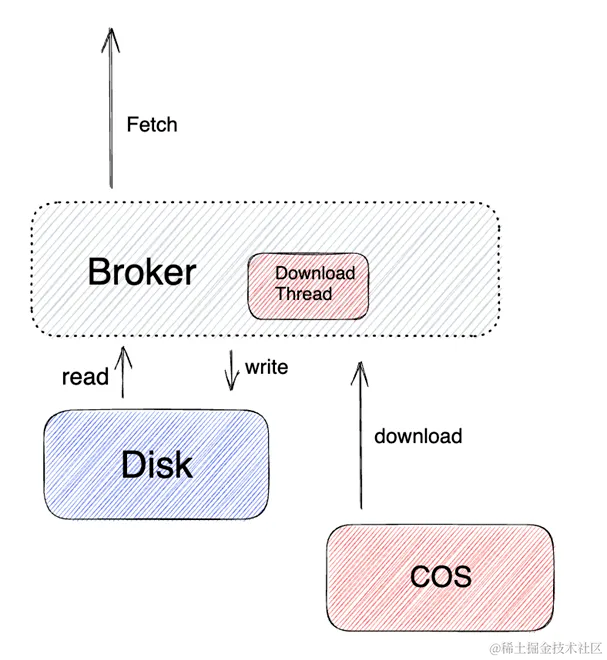
TDMQ CKafka 版弹性存储能力重磅上线!
导语 自 2024年5月起,TDMQ CKafka 专业版支持弹性存储能力,这种产品形态下,存储可按需使用、按量付费,一方面降低消费即删除、存储使用波动大场景下的存储成本,另一方面存储空间理论上无穷大。 TDMQ CKafka 版产品能…...

24、Linux网络端口
Linux网络端口 1、查看网络接口信息ifconfig ens33 eth0 文件 ifconfig 当前设备正在工作的网卡,启动的设备。 ifconfig -a 查看所有的网络设备。 ifconfig ens33 查看指定网卡设备。 ifconfig ens33 up/down 对指定网卡设备进行开关 基于物理网卡设备虚拟的…...

Mysql全文搜索和LIKE搜索有什么区别
全文搜索和LIKE的区别 性能:在大数据集上,全文搜索通常比LIKE查询更快,因为它使用了专门的索引结构。 功能:全文搜索提供了更丰富的查询功能,如多个关键词的搜索、自然语言搜索、布尔搜索等。而LIKE通常只支持简单的…...

elementplu父级页面怎么使用封装子组件原组件的方法
一、使用原因: 封装了el-table,表格中有多选,父级要根据指定状态,让其选择不上,需要用到elementplus中table原方法toggleRowSelection 附加小知识点:(el-tree刷新树后之前选中的保持高亮setCurr…...
el-date-picker选择开始日期的近半年
<el-date-pickerv-model"form[val.key]":type"val.datePickerType || daterange":clearable"val.clearable && true"range-separator"~"start-placeholder"开始日期"end-placeholder"结束日期"style&q…...
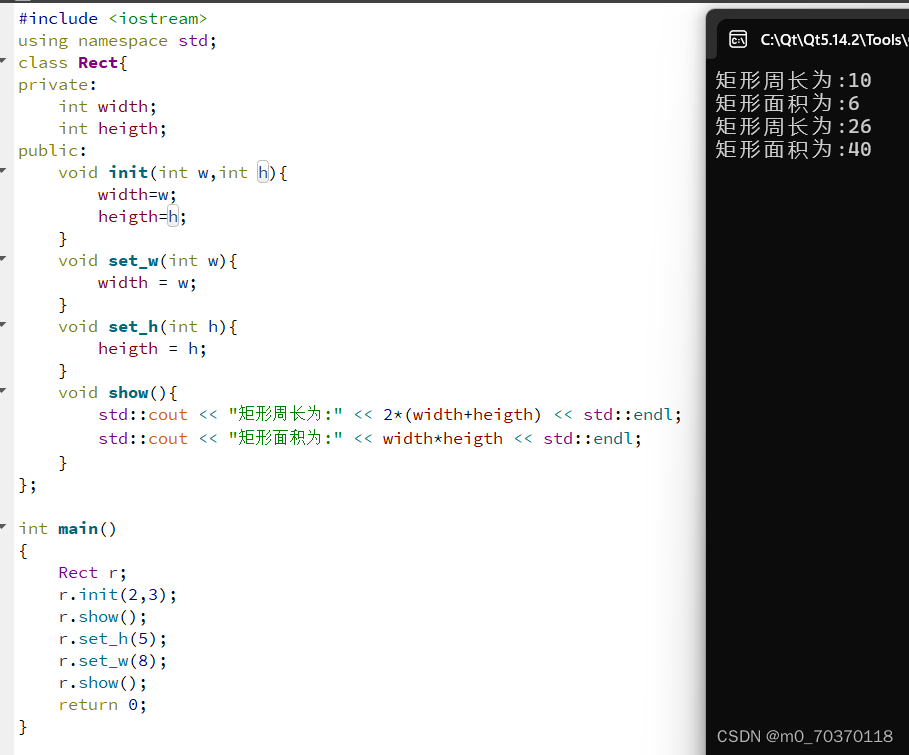
C++
封装一个矩形类(Rect),拥有私有属性:宽度(width)、高度(height), 定义公有成员函数: 初始化函数:void init(int w, int h) 更改宽度的函数:set_w(int w) 更改高度的函数:set_h(int h) 输出该矩形的周长和面积函数:void show()...
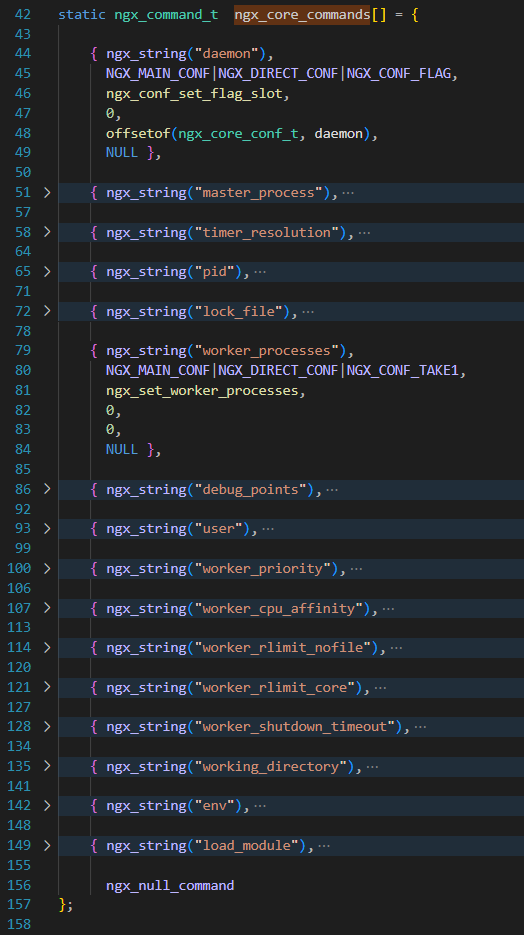
nginx源码阅读理解 [持续更新,建议关注]
文章目录 前述一、nginx 进程模型基本流程二、源码里的小点1.对字符串操作都进行了原生实现2.配置文件解析也是原生实现待续 前述 通过对 nginx 的了解和代码简单阅读,发现这个C代码的中间件确实存在过人之处,使用场景特别多,插件模块很丰富…...
笔试训练2
牛客.单词搜索 刚开始我就想是搜索,但是不清楚bfs还是dfs更好,我尝试了bfs但是队列存东西,没有我想象的那么好写,所以我决定试试dfs import java.util.*;public class Solution {static int m 0;static int n 0;static int […...

5个步骤掌握ScriptHookV:GTA V脚本开发终极指南
5个步骤掌握ScriptHookV:GTA V脚本开发终极指南 【免费下载链接】ScriptHookV An open source hook into GTAV for loading offline mods 项目地址: https://gitcode.com/gh_mirrors/sc/ScriptHookV 你是否曾梦想过为GTA V创造属于自己的游戏模组?…...

回归模型评估实战指南:从指标选择到业务决策
1. 这不是“背公式”手册,而是回归模型评估的实战决策地图 你训练完一个房价预测模型,R0.87,MAE2.3万,RMSE3.8万——然后呢?是立刻上线?还是再调参?还是换数据?还是干脆换算法&#…...

医疗可穿戴跨界创新:从连续监测到专业检测的硬件设计实践
1. 项目概述:当可穿戴设备“走出”身体这几年,医疗可穿戴设备已经不是什么新鲜词了。从最初只能计步的手环,到如今能监测心率、血氧、心电图甚至血糖趋势的智能手表,它们正变得越来越“贴身”,也越来越“懂”我们的身体…...

5分钟掌握跨平台音乐格式转换:Unlock-Music浏览器端音频解密终极指南
5分钟掌握跨平台音乐格式转换:Unlock-Music浏览器端音频解密终极指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项…...

2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解
2025睿抗机器人大赛智能侦查赛道省赛全流程——基础了解 智能侦查赛道概述 2025 睿抗机器人大赛智能侦察赛道是 CAIR 工程竞技赛道下的专业国防装备赛项,以无人侦察车为载体、模拟巷战环境开展军事侦察任务,核心培养学生国防意识与科技创新能力且核心硬件…...

pprint,一个漂亮打印的 Python 库!
在日常编程中,我们经常需要打印复杂的数据结构——嵌套的字典、列表、JSON 响应、配置对象等。使用普通的 print() 会将整个结构挤在一行或简单换行,导致可读性极差,尤其是在调试多层嵌套的 API 返回数据时,简直是一场灾难。pprin…...

Unlock Music Electron:终极开源音乐解密解决方案,打破平台枷锁
Unlock Music Electron:终极开源音乐解密解决方案,打破平台枷锁 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirrors/un/u…...

如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk
如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk 【免费下载链接】ppInk Fork from Gink 项目地址: https://gitcode.com/gh_mirrors/pp/ppInk 你是否曾在演示、教学或远程协作中,需要在屏幕上快速标注重点,却发现工具要么太复杂࿰…...

探索OneMore:解锁OneNote高效笔记的完整指南
探索OneMore:解锁OneNote高效笔记的完整指南 【免费下载链接】OneMore A OneNote add-in with simple, yet powerful and useful features 项目地址: https://gitcode.com/gh_mirrors/on/OneMore OneMore是一款专为OneNote设计的强大插件,通过160…...

工业边缘计算实战:基于Wind River Helix与App Cloud的云原生应用部署与管理
1. 项目概述:当工业边缘计算遇上云原生应用最近在跟几个做工业物联网和智能网关项目的朋友聊天,发现一个挺有意思的现象:大家手里的硬件平台越来越强,但软件开发和部署的效率却成了新的瓶颈。一个典型的场景是,你有一台…...