BatchNormalization
目录
Covariate Shift
Internal Covariate Shift
BatchNormalization
Q1:BN的原理
Q2:BN的作用
Q3:BN的缺陷
Q4:BN的均值、方差的计算维度
Q5:BN在训练和测试时有什么区别
Q6:BN的代码实现
Covariate Shift
机器学习中,一般会假设模型的输入数据分布时稳定的。如果这个假设不成立,即模型的输入数据的分布发生变化,则称为协变量偏移(Covariate Shift).例如:模型的训练数据和测试数据分布不一致;模型在训练过程中输入数据发生变化。
Internal Covariate Shift
在深层网络训练的过程中,由于网络中参数变化而引起内部节点数据分布发生变化这一过程被称作Internal Covariate Shift.深度神经网络涉及到很多层的叠加,而每一层的参数更新会导致高层的输入数据分布发生变化,通过层层叠加,高层的输入分布变化会非常剧烈,这就使得高层需要不断地去重新适应底层的参数更新。
Covariate Shift时模型的输入数据的分布发生变化,Internal Covariate Shift时网络内部的节点的输入数据分布发生变化。
ICS带来的问题
- 高层网络需要不断调整来适应输入数据分布的变化,导致网络学习速度的降低,使得学习的过程变得很不稳定
- 网络前几层参数的更新,很可能使得后面层输入数据变得过大或者过小,从而陷入梯度饱和区域(比如sigmoid的饱和区),减缓网络收敛速度
在各种Normalization提出之前,解决上述问题的方法是使用较小的学习率(避免参数更新太快),精细的参数初始化,训练时间会很长。
BatchNormalization
BN的提出就是为了解决Interval Covariate Shift问题。BN的作用是确保网络的各层,即使参数发生了变化,其输入数据的分布也不会发生太大的变化,将其拉回到均值0,方差1的正态分布,从而避免ICS。
Q1:BN的原理
BN可以看作带参数的标准化,它有两个需要学习的参数γ和β,称为偏移因子和缩放因子。BN包括两个步骤:第一步相当于标准化,对每层的输入统计均值和方差,然后进行去均值方差标准化处理,使得每层的输入都是均值为0,方差为1.第二步是对规范化的数据进行线性变化,使用两个可以学习的参数γ和β。第一步的标准化虽然缓解了ICS问题,使得每层网络输入都变得稳定,但却导致数据的表达能力减弱,使得底层网络学习的信息丢失(如果激活函数使用的是sigmoid或者tanh,0均值的数据大部分落在激活函数的近似线性区域,没有利用上非线性区域,极大削弱了非线性表达能力);因此加入了两个可学习的参数的线性变换来恢复数据的表达能力。
具体的计算公式如下:

Q2:BN的作用
-
加速网路训练。ICS问题会导致深层网络需要不断去适应底层网络参数的变化,因此训练速度会很慢,BN解决了ICS问题,因此可以加速网络训练。
- 防止过拟合。BN由于每次在计算均值方差时是依靠一个batch来计算的,引入了随机性,可以缓解过拟合问题,可以用来代替dropout以及降低L2正则的权重系数。
- 缓解梯度消失和梯度爆炸。BN使得每层的输入不会太大,因此不会梯度爆炸;每层输入绝对值不会太大,就不会落入sigmoid激活函数的饱和区域,从而缓解梯度消失。
- 调参更容易。之前由于ICS问题的存在,一般会采用更小的学习率,为了防止过拟合也会尝试dropout以及L2正则,并且要求很精细的网络初始化。有了BN后,缓解了ICS问题,就可以使用较大的学习率,对初始化的要求也没有那么高了。
Q3:BN的缺陷
- 受到Batch Size影响很大,如果batch size较小,每次训练计算的均值方差不具有代表性且不稳定,会降低模型效果。
- BN比较难用到RNN这种序列模型中。因为BN是batch内计算均值,而句子之间没有很强的语义关系,句子内部有比较强的语义关系,所以句子之间算均值对其再标准化,这种方式效果会不好。
Q4:BN的均值、方差的计算维度
对于全连接层:输入维度是[N,C],在N上计算平均,γ和β的维度是C
对于卷积层:输入维度是[N,C,H,W],在N,H,W上计算平均,γ和β的维度是C。
Q5:BN在训练和测试时有什么区别
训练时,均值、方差分别是该批次内数据相应维度的均值和方差;测试时,均值、方差是基于训练时批次数据均值方差的无偏估计,公司如下:(即在训练时保存所有批次的均值方差,然后计算无偏估计)

在推荐过程中BN采用如下公式:
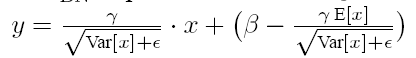
这里的E[x]就是我上面那个式子里面的μtest,Var[x]就是我上面式子里面的σ^2test。
这个式子和训练时:

是等价的,不过是做了一些变换。在实际运行的时候,按照这种变体可以减少计算量,为啥呢?因为对于隐藏节点来说:

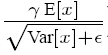
都是固定值,这样这两个值可以事先存起来,在推荐的时候直接用就行了,这样比原始的公式每一步都现成算少了除法的运算过程,如果隐藏节点个数多的话就会节省很多的计算量。
Q6:BN的代码实现
Batch Normalization里面有一个momentum参数,该参数作用于mean和variance的计算上,这里保留了历史batch里面的mean和variance值,即moving_mean和moving_variance,计算的是移动平均,将历史batch里的mean和variance的作用延续到当前batch。一般momentum的值为0.9,0.99等。多个batch后,即多个0.9连乘后,最早的batch的影响后变弱。
指数移动平均:指数移动平均是以指数式递减加权的移动平均。各数值的加权影响力随时间而指数式递减,越近期的数据加权影响力越重,但较旧的数据也给予一定的加权值。计算公式为:.优点:当想要计算均值的时候,不用保留所有时刻的值。随着时间推移,遥远过去的历史的影响会越来越小。
所以这里要注意实际实现的时候,测试阶段的均值和方差是通过在训练阶段指数加权移动平均来统计均值和方差得到的。
代码实现如下:
import torch
from torch import nn def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式if not torch.is_grad_enabled():# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)else:assert len(X.shape) in (2, 4)#判断是全连接层还是卷积层,2代表全连接层,样本数和特征数;4代表卷积层,批量数,通道数,高宽if len(X.shape) == 2:# 使用全连接层的情况,计算特征维上的均值和方差mean = X.mean(dim=0)var = ((X - mean) ** 2).mean(dim=0)else:# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。# 这里我们需要保持X的形状以便后面可以做广播运算mean = X.mean(dim=(0, 2, 3), keepdim=True)#1*n*高*宽var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True)# 训练模式下,用当前的均值和方差做标准化X_hat = (X - mean) / torch.sqrt(var + eps)# 更新移动平均的均值和方差moving_mean = momentum * moving_mean + (1.0 - momentum) * meanmoving_var = momentum * moving_var + (1.0 - momentum) * varY = gamma * X_hat + beta # 缩放和移位return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):# num_features:完全连接层的输出数量或卷积层的输出通道数。# num_dims:2表示完全连接层,4表示卷积层def __init__(self, num_features, num_dims):super().__init__()if num_dims == 2:shape = (1, num_features)else:shape = (1, num_features, 1, 1)# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0self.gamma = nn.Parameter(torch.ones(shape))self.beta = nn.Parameter(torch.zeros(shape))# 非模型参数的变量初始化为0和1self.moving_mean = torch.zeros(shape)self.moving_var = torch.ones(shape)def forward(self, X):# 如果X不在内存上,将moving_mean和moving_var# 复制到X所在显存上if self.moving_mean.device != X.device:self.moving_mean = self.moving_mean.to(X.device)self.moving_var = self.moving_var.to(X.device)# 保存更新过的moving_mean和moving_varY, self.moving_mean, self.moving_var = batch_norm(X, self.gamma, self.beta, self.moving_mean,self.moving_var, eps=1e-5, momentum=0.9)关于BN常见的面试题目整理:
1.BN为什么效果?
讲BN的归一化带来的好处以及mini-batch mean 和mini-batch variance引入正则作用这两个方面
2.为什么BN归一化后还要有scale-shift操作?
这个在文中提到了
3.BN改变了数据分布,为什么效果反而会更好?
虽然会改变数据分布,但是数据之间的关联性是不会变的;由于有目标函数在,所以神经网络自己会朝着分布最优的方向去学习
4.BN用在什么地方
一般用在全连接层+BN+激活函数
5.对于什么激活函数,BN效果会明显?
对于sigmoid或者tanh激活函数,BN效果会好一些。
6.BN中在训练和测试时怎么用?
文中讲到了。
7.BN缺点
小样本时,效果不好,均值和方差是有偏的;在RNN中效果通常不好。其实文中也讲到了
[深度学习基础][面经]Batch Normalization - 知乎
Batch Normalization导读 - 知乎
整理学习之Batch Normalization(批标准化)_笨笨犬牙的博客-CSDN博客
相关文章:
BatchNormalization
目录 Covariate Shift Internal Covariate Shift BatchNormalization Q1:BN的原理 Q2:BN的作用 Q3:BN的缺陷 Q4:BN的均值、方差的计算维度 Q5:BN在训练和测试时有什么区别 Q6:BN的代码实现 Covariate Shift 机器学习中&a…...

vue 中安装插件实现 rem 适配
vue 中实现 rem 适配vue 项目实现页面自适应,可以安装插件实现。 postcss-pxtorem 是 PostCSS 的插件,用于将像素单元生成 rem 单位。 autoprefixer 浏览器前缀处理插件。 amfe-flexible 可伸缩布局方案替代了原先的 lib-flexible 选用了当前众多浏览…...
Hadoop学习
1.分布式与集群 hosts文件: 域名映射文件 2.Linux常用命令 ls -a:查看当前目录下所有文件mkdir -p:如果没有对应的父文件夹,会自动创建rm -rf:-f:强制删除 -r:递归删除cp -r:复制文…...

Golang反射源码分析
在go的源码包及一些开源组件中,经常可以看到reflect反射包的使用,本文就与大家一起探讨go反射机制的原理、学习其实现源码 首先,了解一下反射的定义: 反射是指计算机程序能够在运行时,能够描述其自身状态或行为、调整…...

Qt之悬浮球菜单
一、概述 最近想做一个炫酷的悬浮式菜单,考虑到菜单展开和美观,所以考虑学习下Qt的动画系统和状态机内容,打开QtCreator的示例教程浏览了下,大致发现教程中2D Painting程序和Animated Tiles程序有所帮助,如下图所示&a…...
易优cms attribute 栏目属性列表
attribute 栏目属性列表 attribute 栏目属性列表 [基础用法] 标签:attribute 描述:获取栏目的属性列表,或者单独获取某个属性值。 用法: {eyou:attribute typeauto} {$attr.name}:{$attr.value} {/eyou:attri…...

表格中的table-layout属性讲解
表格中的table-layout属性讲解 定义和用法 tableLayout 属性用来显示表格单元格、行、列的算法规则。 table-layout有三个属性值:auto、fixed、inherit。 fixed:固定表格布局 固定表格布局与自动表格布局相比,允许浏览器更快地对表格进行布…...

【MFA】windows环境下,使用Montreal-Forced-Aligner训练并对齐音频
文章目录一、安装MFA1.安装anaconda2.创建并进入虚拟环境3.安装pyTorch二、训练新的声学模型1.确保数据集的格式正确2.训练声音模型-导出模型和对齐文件3.报错处理1.遇到类似: Command ‘[‘createdb’,–host‘ ’, ‘Librispeech’]’ returned non-zero exit sta…...

C语言实验小项目实例源码大全订票信息管理系统贪吃蛇图书商品管理网络通信等
wx供重浩:创享日记 对话框发送:c项目 获取完整源码源文件视频讲解环境资源包文档说明等 包括火车订票系统、学生个人消费管理系统、超级万年历、学生信息管理系统、网络通信编程、商品管理系统、通讯录管理系统、企业员工管理系统、贪吃蛇游戏、图书管理…...

电脑图片损坏是怎么回事
电脑图片损坏是怎么回事?对于经常使用电脑的我们,总是会下载各种各样的图片,用于平时的使用中。但难免会遇到莫名其妙就损坏的图片文件,一旦发生这种情况,要如何才能修复损坏的图片呢?下面小编为大家带来常用的修复方…...

【论文研读】无人机飞行模拟仿真平台设计
无人机飞行模拟仿真平台设计 摘要: 为提高飞行控制算法的研发效率,降低研发成本,基于数字孪生技术设计一个无人机硬件在环飞行模拟仿真平台。从几何、物理和行为3个方面研究无人机数字模型构建方法,将物理实体以数字化方式呈现。设计一种多元融合场景建模法,依据属…...

【算法题】2379. 得到 K 个黑块的最少涂色次数
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 给你一个长度为 n 下标从 0 开始的…...
DJ1-3 计算机网络和因特网
目录 一、物理介质 1. 双绞线 2. 同轴电缆 3. 光纤线缆 4. 无线电磁波 二、端系统上的 Internet 服务 1. 面向连接的服务 TCP(Transmission Control Protocol) 2. 无连接的服务 UDP(User Datagram Protocol) TCP 和 UD…...
Git学习笔记(六)-标签管理
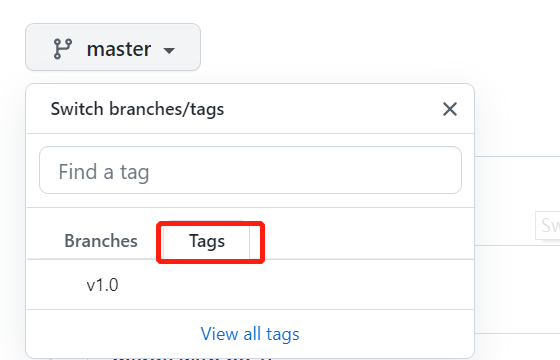
发布一个版本时,我们通常先在版本库中打一个标签(tag),这样,就唯一确定了打标签时刻的版本。将来无论什么时候,取某个标签的版本,就是把那个打标签的时刻的历史版本取出来。所以,标签…...
Semaphore 源码解读
一、Semaphore Semaphore 通过设置一个固定数值的信号量,并发时线程通过 acquire() 获取一个信号量,如果能成功获得则可以继续执行,否则将阻塞等待,当某个线程使用 release() 释放一个信号量时,被阻塞的线程则可以被唤…...

RZ/G2L工业核心板U盘读写速率测试
1. 测试对象HD-G2L-IOT基于HD-G2L-CORE工业级核心板设计,双路千兆网口、双路CAN-bus、2路RS-232、2路RS-485、DSI、LCD、4G/5G、WiFi、CSI摄像头接口等,接口丰富,适用于工业现场应用需求,亦方便用户评估核心板及CPU的性能。HD-G2L…...

《SQL与数据库基础》18. MySQL管理
SQL - MySQL管理MySQL管理系统数据库常用工具mysqlmysqladminmysqlbinlogmysqlshowmysqldumpmysqlimportsource本文以 MySQL 为例 MySQL管理 系统数据库 Mysql数据库安装完成后,自带了以下四个数据库,具体作用如下: 数据库含义mysql存储My…...
达梦关系型数据库
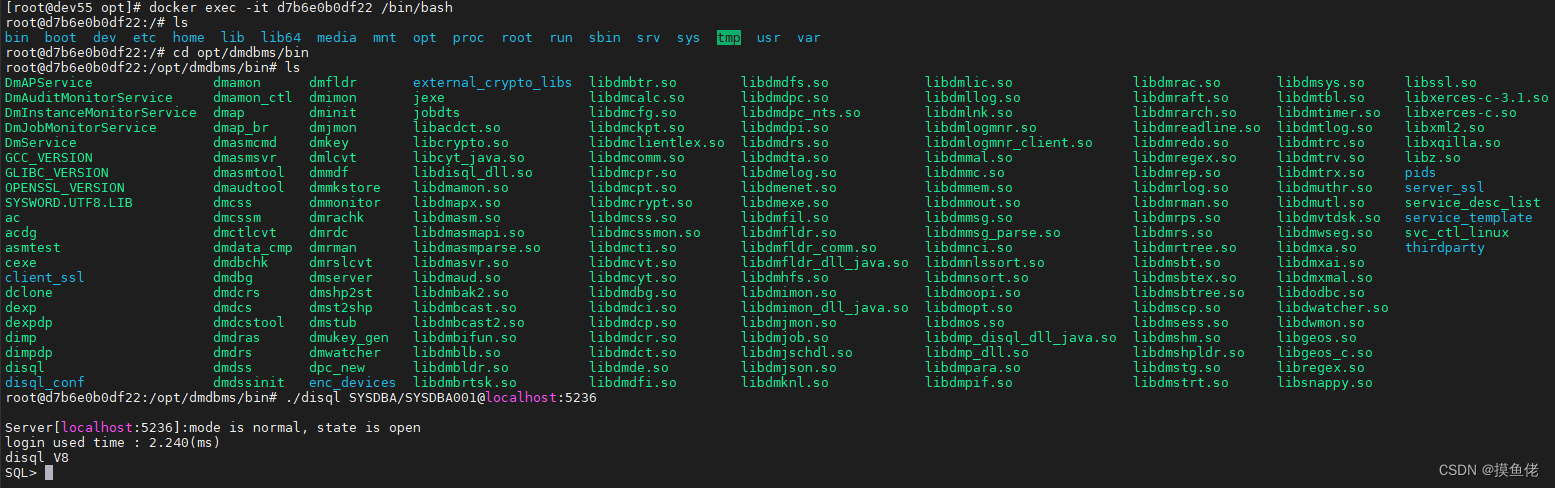
达梦关系型数据库一、DM8 安装1. 安装包下载2. Docker 安装3. Linux 安装4. Windows 安装二、DM 管理工具三、命令行交互工具 DIsql四、DM8 SQL使用1. 创建模式2. 创建表3. 修改表4. 读写数据5. 查看库下所有的表名6. 查看表字段信息GitHub: link. 欢迎star国产自主研发的大型…...

Postgresql | 执行计划
SQL优化主要从三个角度进行: (1)扫描方式; (2)连接方式; (3)连接顺序。 如果解决好这三方面的问题,那么这条SQL的执行效率就基本上是靠谱的。看懂SQL的执行计…...

Vue3之父子组件通过事件通信
前言 组件间传值的章节我们知道父组件给子组件传值的时候,使用v-bind的方式定义一个属性传值,子组件根据这个属性名去接收父组件的值,但是假如子组件想给父组件一些反馈呢?就不能使用这种方式来,而是使用事件的方式&a…...

UE4 TCP通信实战:从网络调试助手到Python服务端的跨平台数据交互
1. UE4 TCP通信基础与环境搭建 第一次在UE4里折腾TCP通信的时候,我对着文档研究了整整两天。后来发现其实用对方法,半小时就能跑通第一个Demo。这里分享我最常用的TCPSocketPlugin插件方案,比原生C实现简单十倍。 先到虚幻商城搜索"TCP …...

如何3分钟掌握Chat2DB:AI智能数据库管理完整指南
如何3分钟掌握Chat2DB:AI智能数据库管理完整指南 【免费下载链接】Chat2DB AI-driven database tool and SQL client, The hottest GUI client, supporting MySQL, Oracle, PostgreSQL, DB2, SQL Server, DB2, SQLite, H2, ClickHouse, and more. 项目地址: https…...

月薪2万+,2026年AI智能体工程师,这个岗位火了
AI智能体工程师负责设计、搭建、调优和维护AI智能体系统,让AI能自主感知环境、做出决策并执行动作。该岗位需求大,薪资高,适合具备逻辑拆解能力、Prompt工程能力和工具链认知的人。文章建议从体验AI智能体产品、学习相关课程和尝试搭建mini智…...

HALO框架:硬件感知量化技术优化LLM推理
1. HALO框架:硬件感知量化技术解析在大型语言模型(LLM)的实际部署中,我们常常面临一个核心矛盾:模型规模的指数级增长与硬件算力提升缓慢之间的鸿沟。以LLaMA-65B和GPT-4为例,这些模型的参数量分别达到650亿…...

基于LLM与OpenClaw的智能自动化:构建自然语言驱动的桌面脚本生成器
1. 项目概述:连接两个世界的桥梁最近在折腾一个挺有意思的项目,叫hermes-openclaw-bridge。光看这个名字,可能有点摸不着头脑,但如果你同时关注过大型语言模型(LLM)和自动化脚本工具,大概就能猜…...

MQTT-Client-Framework测试策略:单元测试、集成测试与多Broker兼容性
MQTT-Client-Framework测试策略:单元测试、集成测试与多Broker兼容性 【免费下载链接】MQTT-Client-Framework iOS, macOS, tvOS native ObjectiveC MQTT Client Framework 项目地址: https://gitcode.com/gh_mirrors/mq/MQTT-Client-Framework MQTT-Client-…...

量子退火在锂离子电池材料优化中的应用与原理
1. 量子退火技术原理与材料优化应用概述量子退火(Quantum Annealing)是一种基于量子力学原理的优化算法,它通过模拟量子系统的绝热演化过程来寻找复杂问题的全局最优解。与传统模拟退火算法相比,量子退火利用量子隧穿效应而非热涨…...

Marchand Balun设计原理与IE3D电磁仿真实践
1. Marchand Balun设计基础与电磁仿真原理在射频和微波电路设计中,平衡-不平衡转换器(Balun)是实现单端信号与差分信号相互转换的关键无源器件。作为从业15年的射频工程师,我经常需要在各类高频电路中使用Balun结构,而…...

openpilot终极指南:从开源机器人操作系统到300+车型自动驾驶辅助实现
openpilot终极指南:从开源机器人操作系统到300车型自动驾驶辅助实现 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/G…...

在线音视频处理工具实测对比:视频压缩、格式转换、音频提取哪家强?
一、为什么要关注在线音视频工具?先看一组数据。根据多家市场研究机构的报告,全球视频处理相关市场规模近年来持续增长,视频内容的生产量每年都在翻倍。各大平台每天新增的视频播放时长以亿计——这意味着越来越多的普通用户和创作者…...