AI智能体研发之路-模型篇(四):一文入门pytorch开发
博客导读:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
目录
一、引言
二、pytorch介绍
2.1 pytorch历史
2.2 pytorch特点
2.2.1 支持GPU加速的张量计算库
2.2.2 包含自动求导系统的动态图机制
2.3 pytorch安装
三、pytorch实战
3.1 引入依赖的python库
3.2 定义三层神经网络
3.3 训练数据准备
3.4 实例化模型、定义损失函数与优化器
3.5 启动训练,迭代收敛
3.6 模型评估
3.7 可以直接跑的代码
四、总结
一、引言
要深入了解大模型底层原理,先要能手撸transformer模型结构,在这之前,pytorch、tensorflow等深度学习框架必须掌握,之前做深度学习时用的tensorflow,做aigc之后接触pytorch多一些,今天写一篇pytorch的入门文章吧,感兴趣的可以一起聊聊。
二、pytorch介绍
2.1 pytorch历史
PyTorch由facebook人工智能研究院研发,2017年1月被提出,是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序。PyTorch既可以看作加入了GPU支持的numpy,同时也可以看成一个拥有自动求导功能的强大的深度神经网络。
PyTorch的前身是Torch,其底层和Torch框架一样,但是使用Python重新写了很多内容,不仅更加灵活,支持动态图,而且提供了Python接口。它是由Torch7团队开发,是一个以Python优先的深度学习框架,不仅能够实现强大的GPU加速,同时还支持动态神经网络。
2.2 pytorch特点
Pytorch是一个python包,提供两个高级功能:
2.2.1 支持GPU加速的张量计算库
张量(tensor):可以理解为多位数组,是Pytorch的基本计算单元,Pytorch的特性就是可以基于GPU快速完成张量的计算,包括求导、切片、索引、数学运算、线性代数、归约等

import torch
import torch.nn.functional as F# 1. 张量的创建
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
y = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(x) #tensor([[1, 2, 3],[4, 5, 6]])
print(y) #tensor([[1, 2, 3],[4, 5, 6]])# 2. 张量的运算
z=x+y
print(z) #tensor([[2, 4, 6],[8, 10, 12]])# 3. 张量的自动求导
x = torch.tensor(3.0, requires_grad=True)
print(x.grad) #Noney = x**2
y.backward()
print(x.grad) #tensor(6.)2.2.2 包含自动求导系统的动态图机制
Pytorch提供了一种独一无二的构建神经网络的方式:动态图机制
不同于TensorFlow、Caffe、CNTK等静态神经网络:网络构建一次反复使用,如果修改了网络不得不重头开始。
在Pytorch中,使用了一种“反向模式自动微分的技术(reverse-mode auto-differentiation)”,允许在零延时或开销的情况下任意更改网络。
2.3 pytorch安装
这里建议大家采用conda创建环境,采用pip管理pytorch包
1.建立名为pytrain,python版本为3.11的conda环境
conda create -n pytrain python=3.11
conda activate pytrain
2.采用pip下载torch和torchvision包
pip install torch torchvision torchmetrics -i https://mirrors.cloud.tencent.com/pypi/simple
这里未指定版本,默认下载最新版本torch-2.3.0、torchvision-0.18.0以及其他一堆依赖。
三、pytorch实战
动手实现一个三层DNN网络:
3.1 引入依赖的python库
这里主要是torch、torch.nn网络、torch.optim优化器、torch.utils.data数据处理等
import torch # 导入pytorch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.utils.data import DataLoader, TensorDataset # 数据集模块3.2 定义三层神经网络
引入nn.Module类,编写构造函数定义网络结构,编写前向传播过程定义激活函数。
- 通过继承torch.nn.Module类,对神经网络层进行构造,Module类在pytorch中非常重要,他是所有神经网络层和模型的基类。
- 定义模型构造函数__init__:在这里定义网络结构,输入为每一层的节点数,采用torch.nn.Linear这个类,定义全连接线性层,进行线性变换,通过第一层节点输入数据*权重矩阵(n * [n,k] = k),加偏置项,再配以激活函数得到下一层的输入。
- 定义前向传播forward过程:采用relu、sigmod、tanh等激活函数,对每一层计算得到的原始值归一化输出。一般建议采用relu。sigmod的导数在0、1极值附近会接近于0,产生“梯度消失”的问题,较长的精度会导致训练非常缓慢,甚至无法收敛。relu导数一直为1,更好的解决了梯度消失问题。
# 定义三层神经网络模型
class ThreeLayerDNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(ThreeLayerDNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size) # 第一层全连接层self.fc2 = nn.Linear(hidden_size, hidden_size) # 第二层全连接层self.fc3 = nn.Linear(hidden_size, output_size) # 输出层self.sigmoid = nn.Sigmoid() # 二分类输出层使用Sigmoid激活函数def forward(self, x):x = torch.relu(self.fc1(x)) # 使用ReLU激活函数x = torch.relu(self.fc2(x)) # 中间层也使用ReLU激活函数x = torch.sigmoid(self.fc3(x)) # 二分类输出层使用Sigmoid激活函数return x3.3 训练数据准备
- 定义输入的特征数、隐层节点数、输出类别数,样本数,
- 采用torch.randn、torch.randint函数构造训练数据,
- 采用TensorDataset、DataLoader类分别进行张量数据集构建以及数据导入
# 数据准备
input_size = 1000 # 输入特征数
hidden_size = 512 # 隐藏层节点数
output_size = 2 # 输出类别数
num_samples = 1000 # 样本数
# 示例数据,实际应用中应替换为真实数据
X_train = torch.randn(num_samples, input_size)
y_train = torch.randint(0, output_size, (num_samples,))# 数据加载
dataset = TensorDataset(X_train, y_train)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)3.4 实例化模型、定义损失函数与优化器
损失函数与优化器是机器学习的重要概念,先看代码,nn来自于torch.nn,optim来自于torch.optim,均为torch封装的工具类
# 实例化模型
model = ThreeLayerDNN(input_size, hidden_size, output_size)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 适合分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001)损失函数:用于衡量模型预测值与真实值的差距,是模型优化的目标。常见损失函数为
- 均方误差损失(MSE):用于回归问题,衡量预测值与真实值之间的平方差的平均值。
- 交叉熵损失(Cross Entropy Loss):用于分类问题,衡量预测概率分布与真实分布之间的差距。
- 二进制交叉熵损失(Binary Cross-Entropy Loss):是一种用于二分类任务的损失函数,通常用于测量模型的二分类输出与实际标签之间的差距,不仅仅应用于0/1两个数,0-1之间也都能学习
优化器:优化算法用于调整模型参数,以最小化损失函数。常见的优化算法为
- 随机梯度下降(SGD):通过对每个训练样本计算梯度并更新参数,计算简单,但可能会陷入局部最优值。
- Adam:结合了动量和自适应学习率调整的方法,能够快速收敛且稳定性高,广泛应用于各种深度学习任务。
3.5 启动训练,迭代收敛
模型训练可以简单理解为一个“双层for循环”
第一层for循环:迭代的轮数,这里是10轮
第二层for循环:针对每一条样本,前、后向传播迭代一遍网络,1000条样本就迭代1000次。
所以针对10轮迭代,每轮1000条样本,要迭代网络10*1000=10000次。
# 训练循环
num_epochs = 10
for epoch in range(num_epochs):model.train() # 设置为训练模式running_loss = 0.0for i, (inputs, labels) in enumerate(data_loader, 0):optimizer.zero_grad() # 清零梯度outputs = model(inputs)loss = criterion(outputs, labels)loss.backward() # 反向传播optimizer.step() # 更新权重running_loss += loss.item()print(f'Epoch {epoch + 1}, Loss: {running_loss / (i + 1)}')print('Training finished.')运行后可以看到loss逐步收敛:
3.6 模型评估
通过引入torchmetrics库对模型效果进行评估,主要分为以下几步
- 构造测试集数据;
- 测试集数据加载;
- 将模型切至评估模式;
- 初始化模型准确率与召回率的计算器;
- 循环测试样本,更新准确率与召回率计算器;
- 打印输出
import torchmetrics # 导入torchmetricstest_num_samples = 200 # 测试样本数
test_X_train = torch.randn(test_num_samples, input_size)
test_y_train = torch.randint(0, output_size, (test_num_samples,))# 数据加载
test_dataset = TensorDataset(test_X_train,test_y_train)
test_data_loader = DataLoader(test_dataset, batch_size=32, shuffle=True)# 在模型训练完成后进行评估
# 首先,我们需要确保模型在评估模式下
model.eval()# 初始化准确率和召回率的计算器
accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=output_size)
recall = torchmetrics.Recall(task="multiclass", num_classes=output_size)with torch.no_grad(): # 确保在评估时不进行梯度计算for inputs, labels in test_data_loader:outputs = model(inputs)preds = torch.softmax(outputs, dim=1)# 更新指标计算器accuracy.update(preds, labels)recall.update(preds, labels)# 打印准确率和召回率
print(f'Accuracy: {accuracy.compute():.4f}')
print(f'Recall: {recall.compute():.4f}')print('Evaluation finished.')运行后,可以输出模型的准确率与召回率,由于采用随机生成的测试数据且迭代轮数较少,具体数值不错参考,可以根据自己需要丰富数据。

3.7 可以直接跑的代码
附可以直接运行的代码,先跑起来,再一行行研究!
import torch # 导入pytorch
import torch.nn as nn # 神经网络模块
import torch.optim as optim # 优化器模块
from torch.utils.data import DataLoader, TensorDataset # 数据集模块# 定义三层神经网络模型
class ThreeLayerDNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(ThreeLayerDNN, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size) # 第一层全连接层self.fc2 = nn.Linear(hidden_size, hidden_size) # 第二层全连接层self.fc3 = nn.Linear(hidden_size, output_size) # 输出层self.sigmoid = nn.Sigmoid() # 二分类输出层使用Sigmoid激活函数def forward(self, x):x = torch.relu(self.fc1(x)) # 使用ReLU激活函数x = torch.relu(self.fc2(x)) # 中间层也使用ReLU激活函数x = torch.sigmoid(self.fc3(x)) # 二分类输出层使用Sigmoid激活函数return x# 数据准备
input_size = 1000 # 输入特征数
hidden_size = 512 # 隐藏层节点数
output_size = 2 # 输出类别数
num_samples = 1000 # 样本数
# 示例数据,实际应用中应替换为真实数据
X_train = torch.randn(num_samples, input_size)
y_train = torch.randint(0, output_size, (num_samples,))# 数据加载
dataset = TensorDataset(X_train, y_train)
data_loader = DataLoader(dataset, batch_size=32, shuffle=True)# 实例化模型
model = ThreeLayerDNN(input_size, hidden_size, output_size)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 适合分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001)# 训练循环
num_epochs = 10
for epoch in range(num_epochs):model.train() # 设置为训练模式running_loss = 0.0for i, (inputs, labels) in enumerate(data_loader, 0):optimizer.zero_grad() # 清零梯度outputs = model(inputs)loss = criterion(outputs, labels)loss.backward() # 反向传播optimizer.step() # 更新权重running_loss += loss.item()print(f'Epoch {epoch + 1}, Loss: {running_loss / len(data_loader)}')print('Training finished.')#for param in model.parameters():
# print(param.data)import torchmetrics # 导入torchmetricstest_num_samples = 200 # 测试样本数
test_X_train = torch.randn(test_num_samples, input_size)
test_y_train = torch.randint(0, output_size, (test_num_samples,))# 数据加载
test_dataset = TensorDataset(test_X_train,test_y_train)
test_data_loader = DataLoader(test_dataset, batch_size=32, shuffle=True)# 在模型训练完成后进行评估
# 首先,我们需要确保模型在评估模式下
model.eval()# 初始化准确率和召回率的计算器
accuracy = torchmetrics.Accuracy(task="multiclass", num_classes=output_size)
recall = torchmetrics.Recall(task="multiclass", num_classes=output_size)with torch.no_grad(): # 确保在评估时不进行梯度计算for inputs, labels in test_data_loader:outputs = model(inputs)# 将输出通过softmax转换为概率分布(虽然CrossEntropyLoss内部做了,但这里为了计算指标明确显示)preds = torch.softmax(outputs, dim=1)# 更新指标计算器accuracy.update(preds, labels)recall.update(preds, labels)# 打印准确率和召回率
print(f'Accuracy: {accuracy.compute():.4f}')
print(f'Recall: {recall.compute():.4f}')print('Evaluation finished.')四、总结
本文先对pytorch深度学习框架历史、特点及安装方法进行介绍,接下来基于pytorch带读者一步步开发一个简单的三层神经网络程序,最后附可执行的代码供读者进行测试学习。个人感觉网络结构部分比tensorflow稍微抽象一点点,不过各有优劣吧,初学者最好对比着学习。下一篇写tensorflow吧,一起讲了大家可以对比着看。喜欢的话期待您的关注、点赞、收藏,您的互动是对我最大的鼓励!
如果还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
相关文章:
AI智能体研发之路-模型篇(四):一文入门pytorch开发
博客导读: 《AI—工程篇》 AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效 AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署 AI智能体研发之路-工程篇(三&am…...
)
英语口语中though的用法(even though、as though)
文章目录 英语口语中 "though" 的用法详解1. "Though" 作为转折连词的用法1.1 基本用法示例句子: 1.2 位置灵活性示例句子: 2. "Though" 作为副词的用法2.1 表示对比或转折示例句子: 2.2 强调前述观点示例句子…...
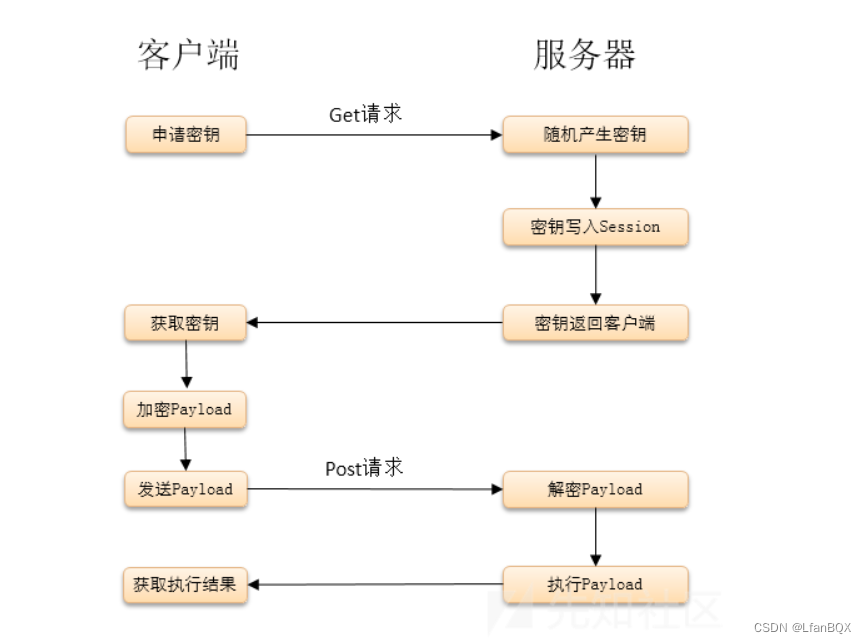
菜刀冰蝎哥斯拉流量通讯特征绕过检测反制感知
1.加密流程 工具名称requestsresponseAntSwordbase64等方式明文冰蝎2.0开启Openssl扩展-动态密钥aes加密aes加密base64未开启Openssl扩展-异或异或base64冰蝎3.0开启Openssl扩展-静态密钥aes加密aes加密base64未开启Openssl扩展-异或异或base64哥斯拉php的为base64异或base64异…...

前端 JS 经典:判断数组的准确方法
前言:判断数组的方法有很多,但是最完美的只有一个。 1. Object.prototype.toString.call 通过 toString.call 方法来判断是否数组。 function isArray(obj) {return Object.prototype.toString.call(obj) "[object Array]"; } 缺点&#…...

【仓库设置问题】
问题: 某公司在高速公路一些服务站内开设了百货超市,为了能及时给这些百货超市提供足够的商品,他们需要在一些百货超市旁修建仓库。一个仓库可以同时为多家百货超市提供服务,以满足各个超市对商品的需求。现已知这些百货超市在高…...
深度学习知识与心得
目录 深度学习简介 传统机器学习 深度学习发展 感知机 前馈神经网络 前馈神经网络(BP网络) 深度学习框架讲解 深度学习框架 TensorFlow 一个简单的线性函数拟合过程 卷积神经网络CNN(计算机视觉) 自然语言处理NLP Wo…...

Qt for Android
文章 USB Qt for android 获取USB设备列表(一)Java方式 获取 Qt for android 获取USB设备列表(二)JNI方式 获取 Qt for android 串口库使用 Qt for android : libusb在android中使用 Qt for Android : 使用libusb做CH340x串口传…...

HTTP 的三次握手
HTTP 的三次握手是指在建立 TCP 连接时,客户端和服务器之间进行的三步握手过程。这个过程确保了双方都能够互相通信,并且同步了彼此的序列号和确认号。 概念: 第一次握手:客户端发送一个 SYN(同步…...

【Text2SQL 论文】T5-SR:使用 T5 生成中间表示来得到 SQL
论文:T5-SR: A Unified Seq-to-Seq Decoding Strategy for Semantic Parsing ⭐⭐⭐ 北大 & 中科大,arXiv:2306.08368 文章目录 一、论文速读二、中间表示:SSQL三、Score Re-estimator四、总结 一、论文速读 本文设计了一个 NL 和 SQL 的…...

【HarmonyOS】应用屏蔽截屏和录屏
【HarmonyOS】应用屏蔽截屏和录屏 一、问题背景: 金融类或者高密性质的应用APP,对于截屏和录屏场景,某些业务下是禁止不允许。 目前这种场景的需求也是非常有必要的,很多电诈都是通过远程录屏软件,获取到账户密码或者…...

[BUG历险记] ERROR: [SIM 211-100] CSim failed with errors
问题重现 在开发HLS过程中,我碰到一个奇怪的现象,同样的工程,在我重装完系统后,不能进行C仿真了,但是综合实现都是可以正常运作的。 vitis的报错也非常奇怪,单单一行: ERROR: [SIM 211-100] C…...
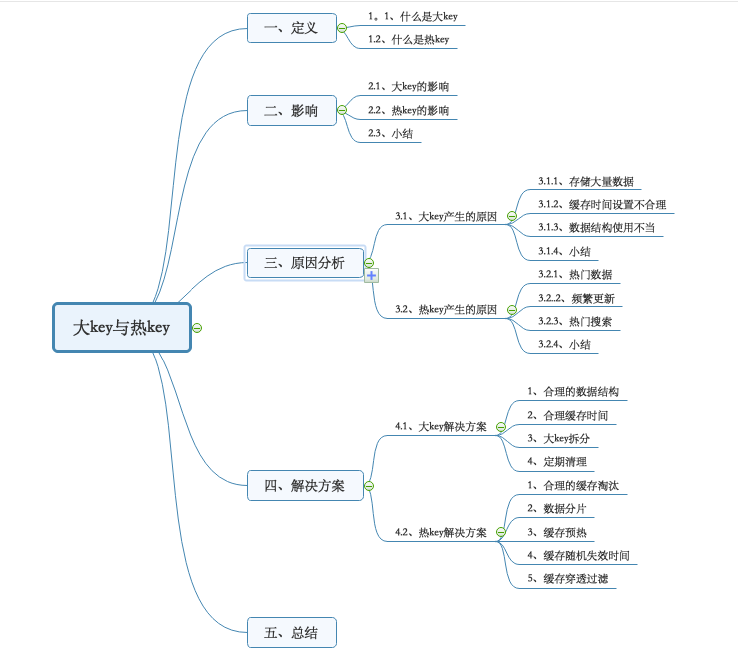
Redis中大Key与热Key的解决方案
原文地址:https://mp.weixin.qq.com/s/13p2VCmqC4oc85h37YoBcg 在工作中Redis已经成为必备的一款高性能的缓存数据库,但是在实际的使用过程中,我们常常会遇到两个常见的问题,也就是文章标题所说的大 key与热 key。 一、定义 1.1…...
)
MySQL 视图(2)
上一篇:MySQL视图(1) 基于其他视图 案例对 WITH [CASCADED | LOCAL] CHECK OPTION 进行释义 创建视图时,可以基于表 / 多个表,也可以使用 其他视图表 / 其他视图 其他视图 的方式进行组合。 总结 更新视图&#x…...

Leecode---技巧---颜色分类、下一个排列、寻找重复数
思路: 遍历一遍记录0,1,2的个数,然后再遍历一次,按照0,1,2的个数修改nums即可。 class Solution { public:void sortColors(vector<int>& nums){int n0 0, n1 0, n2 0;for(int x: nums){if(x0) n0;else if(x1) n1;else n2;}for…...

ERC-7401:嵌套 NFT 标准的全新篇章
在数字资产和区块链技术迅速发展的今天,非同质化代币(NFT)已经成为了一种重要的资产形式,广泛应用于艺术、游戏、收藏品等多个领域。随着市场需求的多样化,传统的 NFT 标准如 ERC-721 和 ERC-1155 已经不能完全满足用户…...

代码随想录算法训练营Day6| 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和
242.有效的字母异位词 知识点补充: 1.遍历HashMap中的值: HashMap<Integer,Integer> map new HashMap<Integer,Integer>(); for(Integer num:map.values()){ } 2.遍历HashMap的键: HashMap<Integer,Integer> map new Ha…...
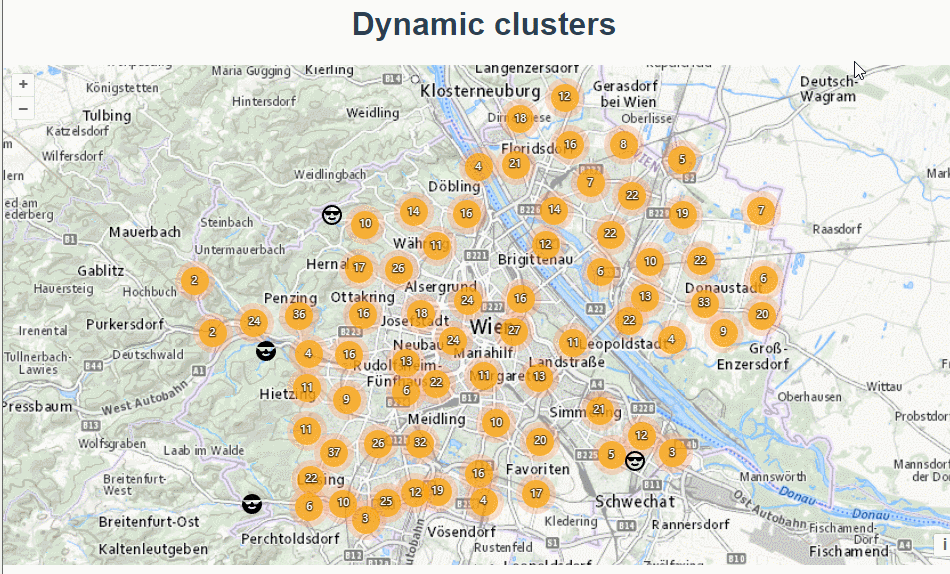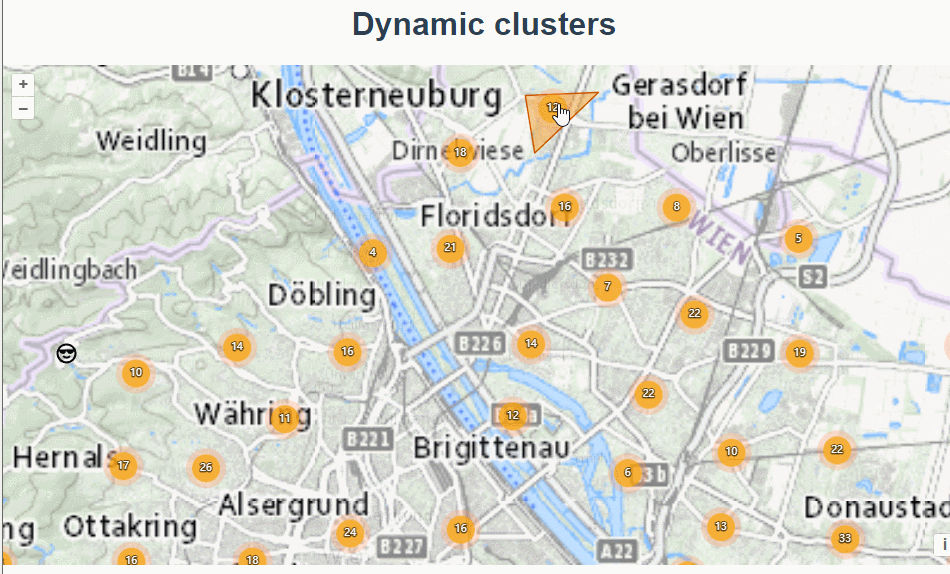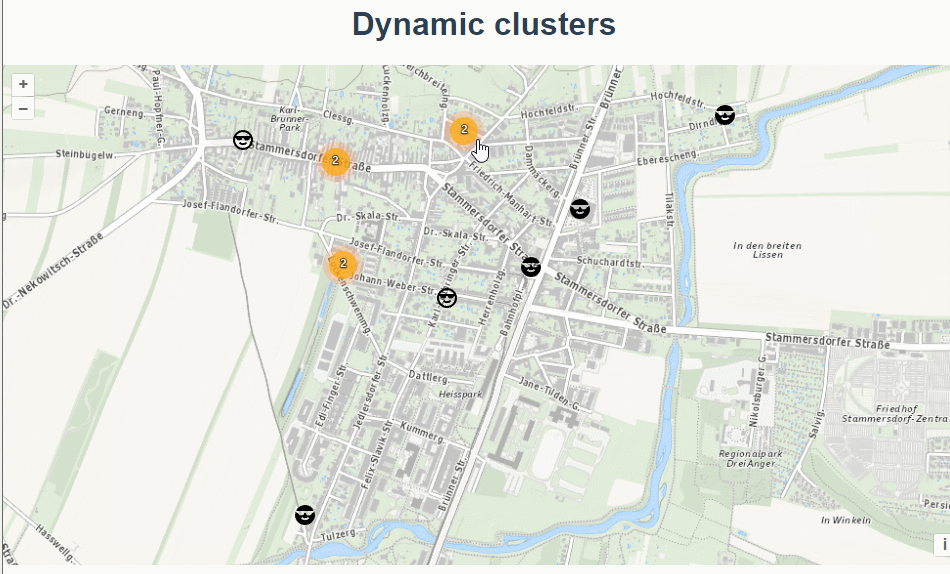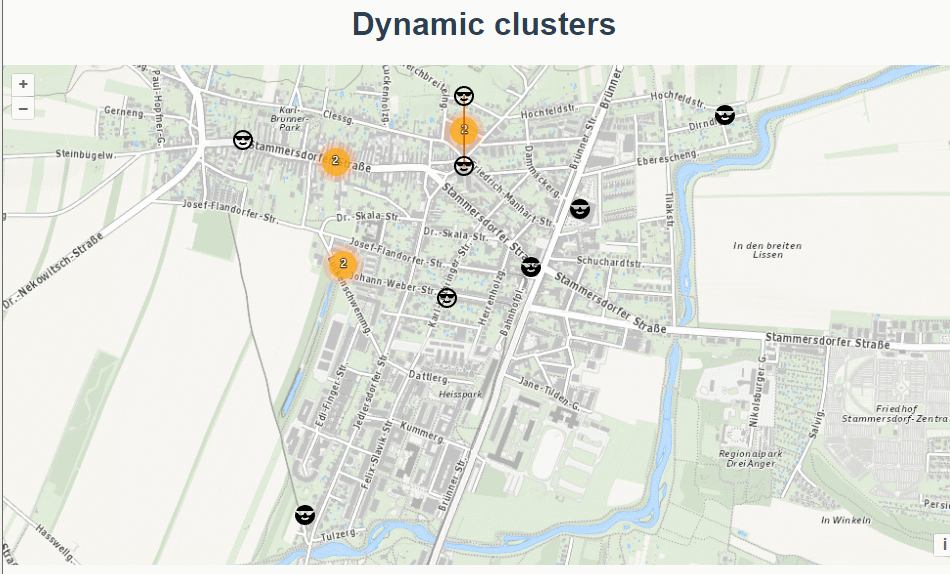
三十四、openlayers官网示例Dynamic clusters解析——动态的聚合图层
官网demo地址: https://openlayers.org/en/latest/examples/clusters-dynamic.html 这篇绘制了多个聚合图层。 先初始化地图 ,设置了地图视角的边界extent,限制了地图缩放的范围 initMap() {const raster new TileLayer({source: new XYZ…...
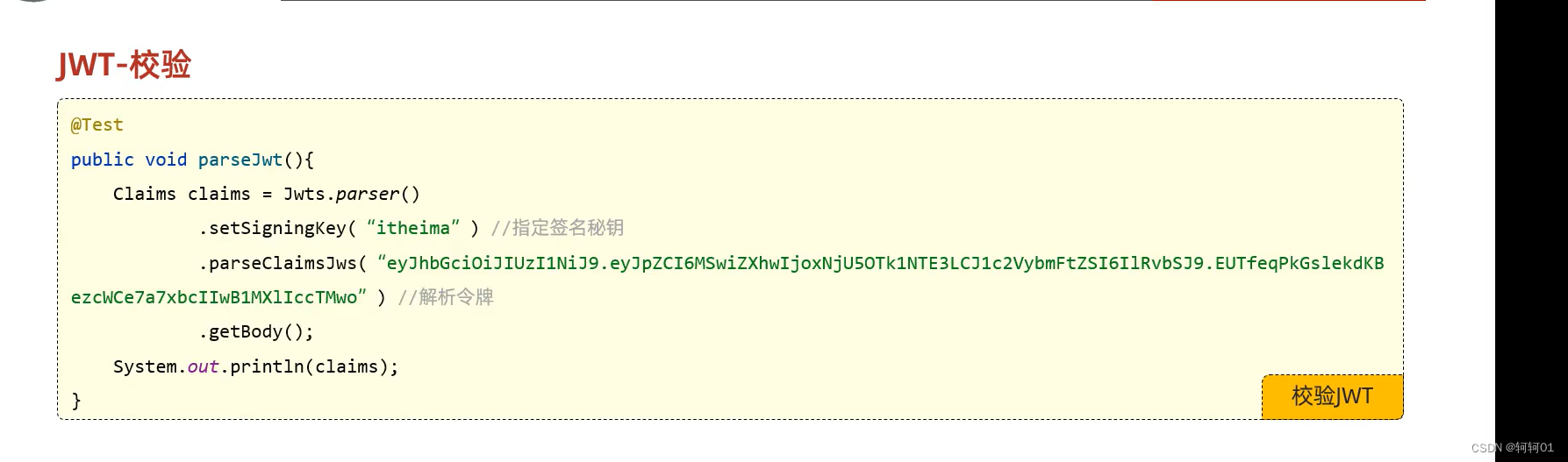
SpringBoot登录认证--衔接SpringBoot案例通关版
文章目录 登录认证登录校验-概述登录校验 会话技术什么是会话呢?cookie Session令牌技术登录认证-登录校验-JWT令牌-介绍JWT SpringBoot案例通关版,上接这篇 登录认证 先讲解基本的登录功能 登录功能本质就是查询操作 那么查询完毕后返回一个Emp对象 如果Emp对象不为空,那…...
vue3状态管理,pinia的使用
状态管理 我们知道组件与组件之间可以传递信息,那么我们就可以将一个信息作为组件的独立状态(例如,单个组件的颜色)或者共有状态(例如,多个组件是否显示)在组件之传递,…...
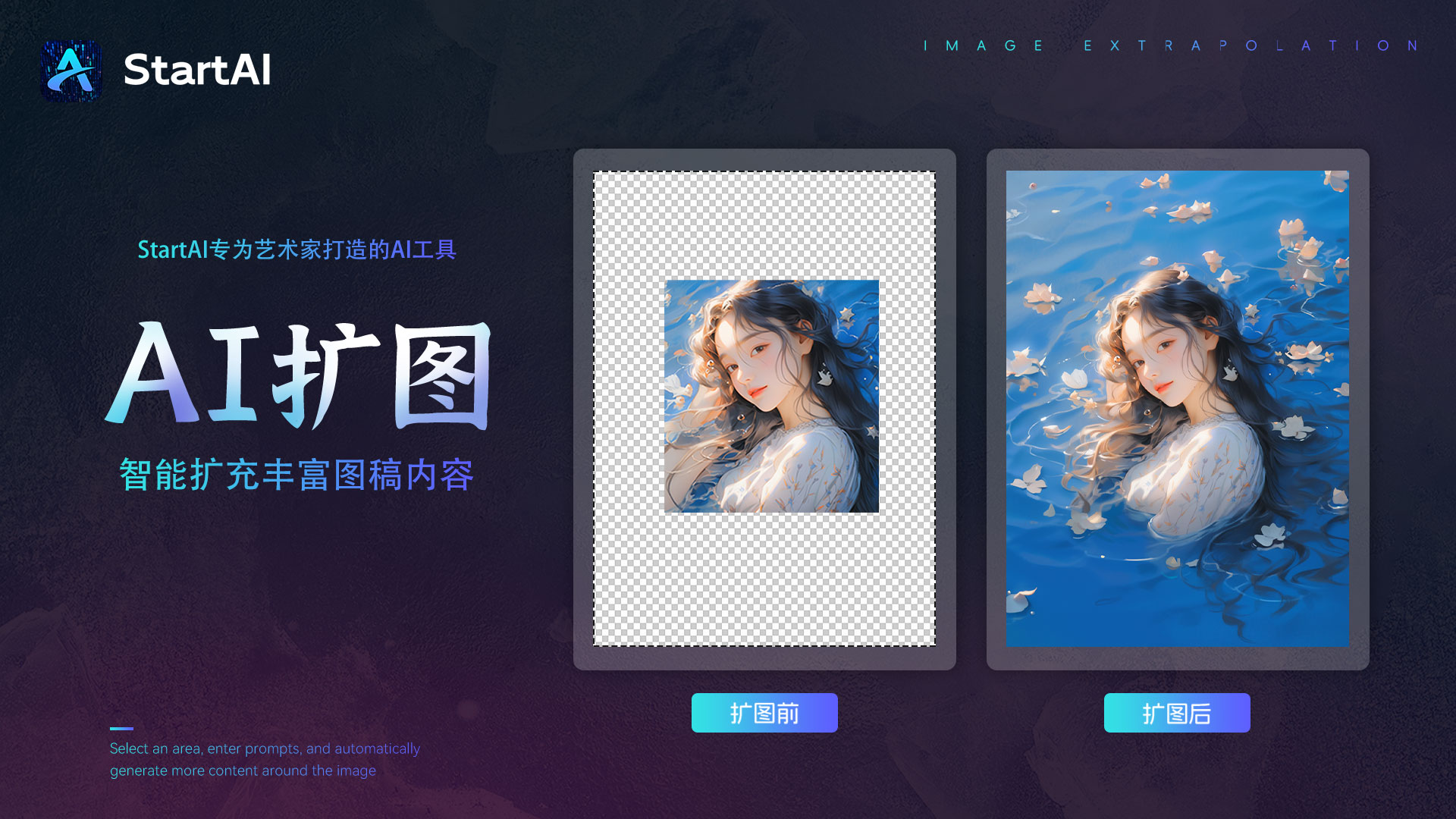
入门到实践,手把手教你用AI绘画!
前言 一款无需魔法的PS插件!下载即用,自带提示词插件,无论你是小白还是大神都能轻松上手,无配置要求,win/mac通通能用! AI绘画工具——StartAI 官网:StartAI官网 (istarry.com.cn) 近段时间…...

如何让模拟人生1实现宽屏显示?3步打造经典游戏现代体验
如何让模拟人生1实现宽屏显示?3步打造经典游戏现代体验 【免费下载链接】Sims-1-Complete-Collection-Widescreen-Patcher Patches The Sims 1 to a custom resolution. 项目地址: https://gitcode.com/gh_mirrors/si/Sims-1-Complete-Collection-Widescreen-Patc…...

下一代神经机器翻译质量评估框架:COMET的革命性架构与智能评估范式
下一代神经机器翻译质量评估框架:COMET的革命性架构与智能评估范式 【免费下载链接】COMET A Neural Framework for MT Evaluation 项目地址: https://gitcode.com/gh_mirrors/com/COMET COMET(A Neural Framework for MT Evaluation)…...
)
STM32C8T6新手入门:用定时器中断和外部中断做一个99秒倒计时器(附完整代码)
STM32C8T6实战:构建高精度99秒倒计时器的5个关键步骤 第一次拿到STM32开发板时,我盯着那些密密麻麻的引脚发呆——这玩意儿真能做出实用的倒计时器?直到成功完成这个项目后才发现,原来从零开始构建一个稳定可靠的倒计时系统&#…...

基于Spring Boot+Vue3的烹饪交流学习系统 设计与实现
基于 Spring Boot Vue3 的烹饪交流学习系统 设计与实现 一、项目概述 随着人们对烹饪学习与交流需求的增加,传统线下学习模式在菜谱管理、内容发现、交流共享与个性化推荐等方面存在明显不足。为此,本项目基于 Spring Boot Vue3 技术栈,构建…...

Cucumber.js数据表格完全指南:如何优雅处理复杂测试数据
Cucumber.js数据表格完全指南:如何优雅处理复杂测试数据 【免费下载链接】cucumber-js Cucumber for JavaScript 项目地址: https://gitcode.com/gh_mirrors/cu/cucumber-js Cucumber.js是JavaScript生态中最流行的行为驱动开发(BDD)测…...

STEP3-VL-10B效果对比实测:10B参数碾压GLM-4.6V/Qwen3-VL-Thinking
STEP3-VL-10B效果对比实测:10B参数碾压GLM-4.6V/Qwen3-VL-Thinking 最近多模态大模型圈子里有个消息挺火的:阶跃星辰开源了一个只有10B参数的视觉语言模型STEP3-VL-10B,据说在好几个评测基准上把那些参数量大它10倍甚至20倍的模型都给比下去…...

万象视界灵坛惊艳效果:CLIP-ViT-L/14在低分辨率图像上的鲁棒性语义解析
万象视界灵坛惊艳效果:CLIP-ViT-L/14在低分辨率图像上的鲁棒性语义解析 1. 平台概览与核心价值 万象视界灵坛是一款基于OpenAI CLIP-ViT-L/14模型构建的多模态智能感知平台。不同于传统视觉识别系统的单调界面,这个平台将复杂的语义对齐过程转化为直观…...

Qwen3-Reranker-0.6B效果实测:轻量级模型重排序能力展示
Qwen3-Reranker-0.6B效果实测:轻量级模型重排序能力展示 1. 引言:为什么需要重排序模型? 在信息检索和问答系统中,我们经常会遇到这样的场景:用户输入一个问题,系统返回多个相关文档。但如何判断哪些文档…...

SEO 优化人员如何编写优化报告并向上级汇报_SEO 优化人员如何制定长期的 SEO 优化计划
SEO 优化人员如何编写优化报告并向上级汇报 在当前数字化经济的快速发展中,SEO(搜索引擎优化)已成为企业提升网站流量和品牌知名度的重要手段。作为SEO优化人员,我们不仅需要制定有效的SEO优化策略,还要能够精准地编写…...

终极GRUB配置指南:让build-linux系统成功启动的7个关键步骤
终极GRUB配置指南:让build-linux系统成功启动的7个关键步骤 【免费下载链接】build-linux A short tutorial about building Linux based operating systems. 项目地址: https://gitcode.com/gh_mirrors/bu/build-linux build-linux项目是一个构建Linux操作系…...