【SVG 生成系列论文(九)】如何通过文本生成 svg logo?IconShop 模型推理代码详解
- SVG 生成系列论文(一) 和 SVG 生成系列论文(二) 分别介绍了 StarVector 的大致背景和详细的模型细节。
- SVG 生成系列论文(三)和 SVG 生成系列论文(四)则分别介绍实验、数据集和数据增强细节。
- SVG 生成系列论文(五)介绍了从光栅图像(如 PNG、JPG 格式)转换为矢量图形(如 SVG、EPS 格式)的关键技术-像素预过滤(pixel prefiltering), Diffvg 这篇论文也是 SVG 生成与编辑领域中 “基于优化”方法的开创性研究。
- SVG 生成系列论文(六) 和 SVG 生成系列论文(七) 简要介绍了 IconShop 的背景、应用和部分细节。
- SVG 生成系列论文(八)则介绍了模型架构和具体的训练技巧。
本文将详细拆解 IconShop(论文原文以及代码🔗)的模型结构和对应开源代码。上篇有提到过模型架构如下所示,本篇则从代码的逻辑进行解释,主要是 /path/to/IconShop/model/decoder.py 中的 sample 以及 forward 两个函数。
模型架构
架构整体分为 4 个部分:SVG 图标嵌入(SVG Icon Embedding),文本嵌入(Text Embedding),输入准备和输出生成。
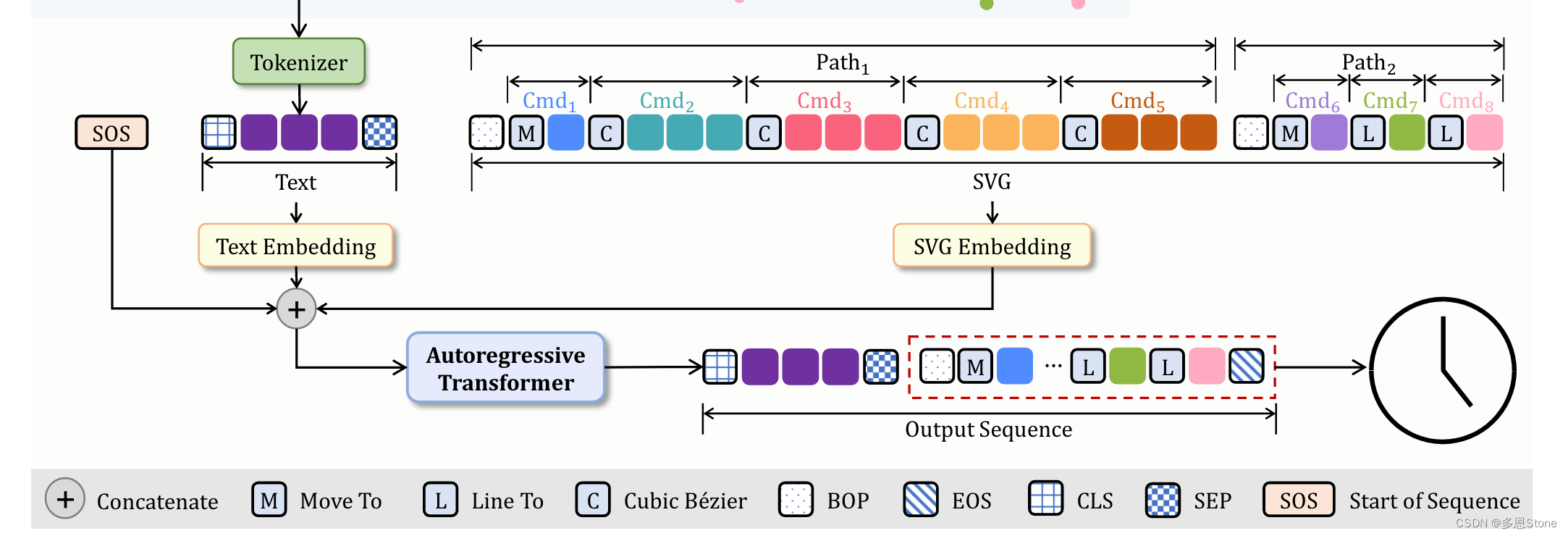
sample 函数
在原项目中,调用模型推理是从 sample_pixels = sketch_decoder.sample(n_samples=BS, text=tokenized_text) 中进行的,因此重点解读这部分代码。
- 输入部分:
self: 指代调用该方法的对象,意味着可以访问类的属性和方法。
n_samples: 要生成的样本数量,这里是 batchsize。
text: 输入的文本数据,用于条件生成。形状为[batch_size, text_len],其中text_len是文本序列的长度,默认是 50。
pixel_seq: 已有的像素序列,初始化为None,形状为[batch_size, max_len]。
xy_seq: 已有的坐标序列,初始化为None,形状为[batch_size, max_len, 2]。
def sample(self, n_samples, text, pixel_seq=None, xy_seq=None):""" sample from distribution (top-k, top-p) """pix_samples = []xy_samples = []# latent_ext_samples = []top_k = 0top_p = 0.5
- 初始化:
定义了空列表pix_samples和xy_samples以存储采样的像素和坐标序列。
同时定义了 top_k 和 top_p 作为采样策略的参数,默认使用“Top-P”策略(top_p=0.5),不使用“Top-K”。了解更多,可参见大模型推理常见采样策略(Top-k, Top-p)
# Mapping from pixel index to xy coordiantepixel2xy = {}x=np.linspace(0, BBOX-1, BBOX)y=np.linspace(0, BBOX-1, BBOX)xx,yy=np.meshgrid(x,y)xy_grid = (np.array((xx.ravel(), yy.ravel())).T).astype(int)for pixel, xy in enumerate(xy_grid):pixel2xy[pixel] = xy+COORD_PAD+SVG_END
-
像素到坐标映射:
创建一个从像素索引到坐标(x, y)的映射。这里假设有一个固定大小的边界框(BBOX=200),通过网格生成所有可能的坐标组合,并将这些坐标与像素索引关联起来。其中,COORD_PAD= NUM_END_TOKEN + NUM_MASK_AND_EOM(NUM_END_TOKEN = 3,NUM_MASK_AND_EOM = 2),SVG_END= 1 -
处理文本输入: 确保文本序列的长度不超过预设的最大长度
self.text_len -
循环采样:
- for k in range(
text.shape[1] + pixlen, self.total_seq_len): 是开始对文本之后的 SVG 序列进行采样(预测)。 - 初始化或更新像素
pixel_seq和坐标序列xy_seq的长度。 - 使用模型的
forward方法计算当前状态下下一个token的概率分布。 - 应用“Top-K”和“Top-P”过滤策略(
top_k_top_p_filtering)到概率分布上,仅保留最可能的token。 - 从过滤后的分布中多分类采样得到下一个像素值。
- 将采样的像素索引转换为实际的坐标。其中
PIX_PAD= NUM_END_TOKEN + NUM_MASK_AND_EOM,SVG_END= 1
- 序列更新和早停条件:
- 将生成的像素和坐标序列加入现有序列中。
- 检查生成是否完成(例如生成到结束符),如果有完成的样本则记录并移除。
- 如果所有样本都生成完毕,提前停止循环。
- 返回结果:
返回生成的坐标序列xy_samples。
# Sample per tokentext = text[:, :self.text_len]pixlen = 0 if pixel_seq is None else pixel_seq.shape[1]for k in range(text.shape[1] + pixlen, self.total_seq_len):if k == text.shape[1]:pixel_seq = [None] * n_samplesxy_seq = [None, None] * n_samples# pass through modelwith torch.no_grad():p_pred = self.forward(pixel_seq, xy_seq, None, text)p_logits = p_pred[:, -1, :]next_pixels = []# Top-p sampling of next pixelfor logit in p_logits: filtered_logits = top_k_top_p_filtering(logit, top_k=top_k, top_p=top_p)next_pixel = torch.multinomial(F.softmax(filtered_logits, dim=-1), 1)next_pixel -= self.num_text_tokennext_pixels.append(next_pixel.item())# Convert pixel index to xy coordinatenext_xys = []for pixel in next_pixels:if pixel >= PIX_PAD+SVG_END:xy = pixel2xy[pixel-PIX_PAD-SVG_END]else:xy = np.array([pixel, pixel]).astype(int)next_xys.append(xy)next_xys = np.vstack(next_xys) # [BS, 2]next_pixels = np.vstack(next_pixels) # [BS, 1]# Add next tokensnextp_seq = torch.LongTensor(next_pixels).view(len(next_pixels), 1).cuda()nextxy_seq = torch.LongTensor(next_xys).unsqueeze(1).cuda()if pixel_seq[0] is None:pixel_seq = nextp_seqxy_seq = nextxy_seqelse:pixel_seq = torch.cat([pixel_seq, nextp_seq], 1)xy_seq = torch.cat([xy_seq, nextxy_seq], 1)# Early stoppingdone_idx = np.where(next_pixels==0)[0]if len(done_idx) > 0:done_pixs = pixel_seq[done_idx] done_xys = xy_seq[done_idx]# done_ext = latent_ext[done_idx]# for pix, xy, ext in zip(done_pixs, done_xys, done_ext):for pix, xy in zip(done_pixs, done_xys):pix = pix.detach().cpu().numpy()xy = xy.detach().cpu().numpy()pix_samples.append(pix)xy_samples.append(xy)# latent_ext_samples.append(ext.unsqueeze(0))left_idx = np.where(next_pixels!=0)[0]if len(left_idx) == 0:break # no more jobs to doelse:pixel_seq = pixel_seq[left_idx]xy_seq = xy_seq[left_idx]text = text[left_idx]# return pix_samples, latent_ext_samplesreturn xy_samplesforward
这个函数的主要作用是前向传播(或称推理),根据输入的像素序列、坐标序列、掩码和文本,计算模型的输出。具体过程如下:
- 准备输入:
- 如果需要计算损失
return_loss,则去掉最后一个时间步的数据。 - 计算上下文序列的长度
c_seqlen,包括文本和像素序列的长度。
def forward(self, pix, xy, mask, text, return_loss=False):'''pix.shape [batch_size, max_len]xy.shape [batch_size, max_len, 2]mask.shape [batch_size, max_len]text.shape [batch_size, text_len]'''pixel_v = pix[:, :-1] if return_loss else pixxy_v = xy[:, :-1] if return_loss else xypixel_mask = mask[:, :-1] if return_loss else maskc_bs, c_seqlen, device = text.shape[0], text.shape[1], text.deviceif pixel_v[0] is not None:c_seqlen += pixel_v.shape[1]
- 嵌入计算:
对输入的文本进行嵌入计算text_emb。
如果有像素和坐标序列,则分别对它们进行嵌入计算(coord_embed_x, pixel_embed),并与文本嵌入拼接。
# Context embedding valuescontext_embedding = torch.zeros((1, c_bs, self.embed_dim)).to(device) # [1, bs, dim]# tokens.shape [batch_size, text_len, emb_dim]tokens = self.text_emb(text)# Data input embeddingif pixel_v[0] is not None:# coord_embed.shape [batch_size, max_len-1, emb_dim]# pixel_embed.shape [batch_size, max_len-1, emb_dim] coord_embed = self.coord_embed_x(xy_v[...,0]) + self.coord_embed_y(xy_v[...,1]) # [bs, vlen, dim]pixel_embed = self.pixel_embed(pixel_v)embed_inputs = pixel_embed + coord_embed# tokens.shape [batch_size, text_len+max_len-1, emb_dim]tokens = torch.cat((tokens, embed_inputs), dim=1)
- 位置编码和掩码计算:
计算位置编码,并与嵌入后的输入序列拼接。
生成用于Transformer的掩码nopeak_mask,确保模型不会看到未来的时间步。
如果有像素掩码pixel_mask,则将其扩展到与嵌入序列匹配的形状。
# nopeak_mask.shape [c_seqlen+1, c_seqlen+1]nopeak_mask = torch.nn.Transformer.generate_square_subsequent_mask(c_seqlen+1).to(device) # masked with -infif pixel_mask is not None:# pixel_mask.shape [batch_size, text_len+max_len]pixel_mask = torch.cat([(torch.zeros([c_bs, context_embedding.shape[0]+self.text_len])==1).to(device), pixel_mask], axis=1) - Transformer解码:
将处理后的输入序列送入Transformer解码器,得到输出序列。
decoder_out = self.decoder(tgt=decoder_inputs, memory=memory_encode, memory_key_padding_mask=None,tgt_mask=nopeak_mask, tgt_key_padding_mask=pixel_mask)
- 计算logits和损失:
通过全连接层logit_fc计算输出的logits。
如果需要计算损失,则分别计算文本和像素的损失cross_entropy,并返回总损失。
如果不需要计算损失,则直接返回logits。
# Logits fclogits = self.logit_fc(decoder_out) # [seqlen, bs, dim] logits = logits.transpose(1,0) # [bs, textlen+seqlen, total_token] logits_mask = self.logits_mask[:, :c_seqlen+1]max_neg_value = -torch.finfo(logits.dtype).maxlogits.masked_fill_(logits_mask, max_neg_value)if return_loss:logits = rearrange(logits, 'b n c -> b c n')text_logits = logits[:, :, :self.text_len]pix_logits = logits[:, :, self.text_len:]pix_logits = rearrange(pix_logits, 'b c n -> (b n) c')pix_mask = ~mask.reshape(-1)pix_target = pix.reshape(-1) + self.num_text_tokentext_loss = F.cross_entropy(text_logits, text)pix_loss = F.cross_entropy(pix_logits[pix_mask], pix_target[pix_mask], ignore_index=MASK+self.num_text_token)loss = (text_loss + self.loss_img_weight * pix_loss) / (self.loss_img_weight + 1)return loss, pix_loss, text_losselse:return logits相关文章:
【SVG 生成系列论文(九)】如何通过文本生成 svg logo?IconShop 模型推理代码详解
SVG 生成系列论文(一) 和 SVG 生成系列论文(二) 分别介绍了 StarVector 的大致背景和详细的模型细节。SVG 生成系列论文(三)和 SVG 生成系列论文(四)则分别介绍实验、数据集和数据增…...

有哪些兼职软件一天能赚几十元?盘点十个能长期做下去的挣钱软件
在当今这个信息泛滥的时代,众人纷纷寻求迅速致富的捷径。许多人在从事兼职或副业时,并不期望取得巨大的成就,只要每天能额外收入数十元,便已心满意足。 今天,我将带领大家深入探究,揭开那些隐藏在日常生活…...

ubuntu 22.04配置静态ip
ubuntu 22.04配置静态ip vim /etc/netplan/01-network-manager-all.yaml# Let NetworkManager manage all devices on this system network:renderer: NetworkManagerethernets:enp4s0f1:addresses:- 192.168.1.18/24dhcp4: falseroutes:- to: defaultvia: 192.168.1.1nameser…...

C++ 使用 nlohmann/json 库
C常用 json 库有: Jsoncpp boost ison Qt Json (不推荐使用) nlohman::json (推荐使用) 其中Qt中json解析的相关类只在qt中有用,为了避免以后不用qt无法解析json,建议使用nlohmann/json,适用于任何C框架。 1. 简介 nlohmann是一…...

【Java面试】六、Spring框架相关
文章目录 1、单例Bean不是线程安全的2、AOP3、Spring中事务的实现4、Spring事务失效的场景4.1 情况一:异常被捕获4.2 情况二:抛出检查异常4.3 注解加在非public方法上 5、Bean的生命周期6、Bean的循环引用7、Bean循环引用的解决:Spring三级缓…...

【GIC400】——PLIC,NVIC 和 GIC 中断对比
文章目录 PLIC,NVIC 和 GIC 中断对比中断向量表PLIC中断向量表中断使能中断服务函数NVIC中断向量表中断使能中断服务函数GIC中断向量表系列文章 【ARMv7-A】——异常与中断 【ARMv7-A】——异常中断处理概述...
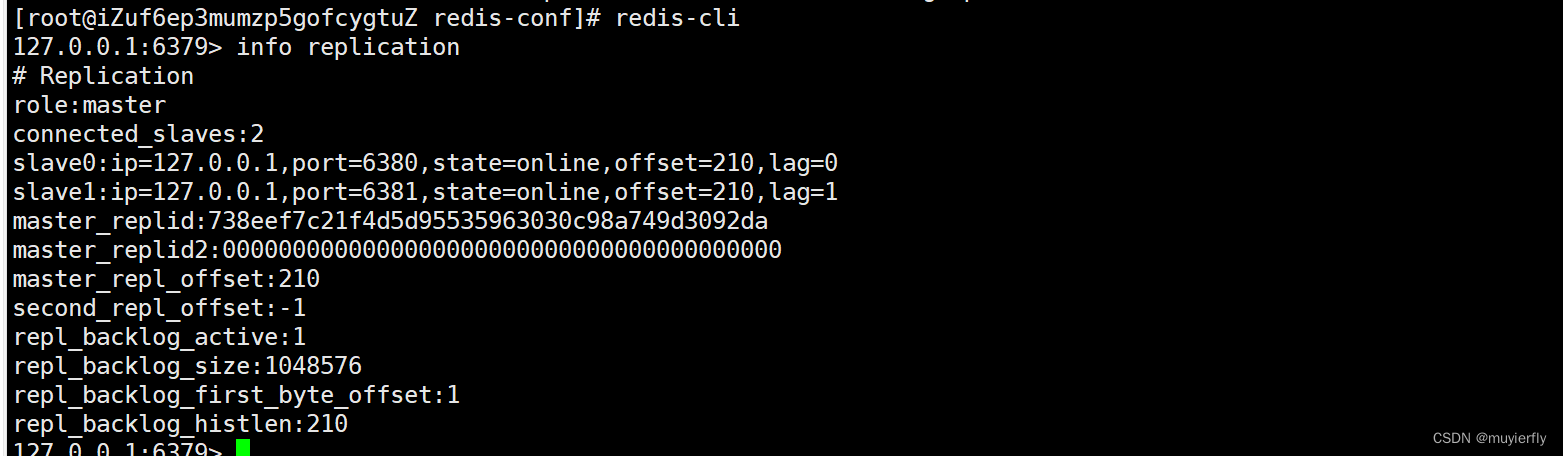
17.Redis之主从复制
1.主从复制是怎么回事? 分布式系统, 涉及到一个非常关键的问题: 单点问题 单点问题:如果某个服务器程序, 只有一个节点(只搞一个物理服务器, 来部署这个服务器程序) 1.可用性问题,如果这个机器挂了,意味着服务就中断了~ 2.性能/支持的并发量也是比较有限…...

计算机类专业应该怎么选学校和方向?优先选这些!
👆点击关注 获取更多编程干货👆 高考季临近,不少有意向报考计算机专业的同学在为院校和细分专业的选择而苦恼,以下是一些建议,希望能帮到大家! 01 选校建议 在选择计算机科学(CS)…...

Amazon云计算AWS(二)
目录 三、简单存储服务S3(一)S3的基本概念和操作(二)S3的数据一致性模型(三)S3的安全措施 四、非关系型数据库服务SimpleDB和DynamoDB(一)非关系型数据库与传统关系数据库的比较&…...

实战
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 实战一:大乐透号码生成器 使用Random模块模拟大乐透号码生成器。选号规则为:前区在1~35的范围内随机产生不重复的…...

【C++】vector模拟实现
🔥个人主页: Forcible Bug Maker 🔥专栏: STL || C 目录 前言🔥vector需要实现的接口函数🔥vector的模拟实现swap交换默认成员函数迭代器接口reserve和resizesize和capacityoperator[ ]下标获取push_back和…...
生成随机图片
package com.zhuguohui.app.lib.tools;/*** Created by zhuguohui* Date: 2024/6/1* Time: 13:39* Desc:获取随机图片*/ public class RandomImage {// static final String url "https://picsum.photos/%d/%d?random%d";static final String url "https://…...
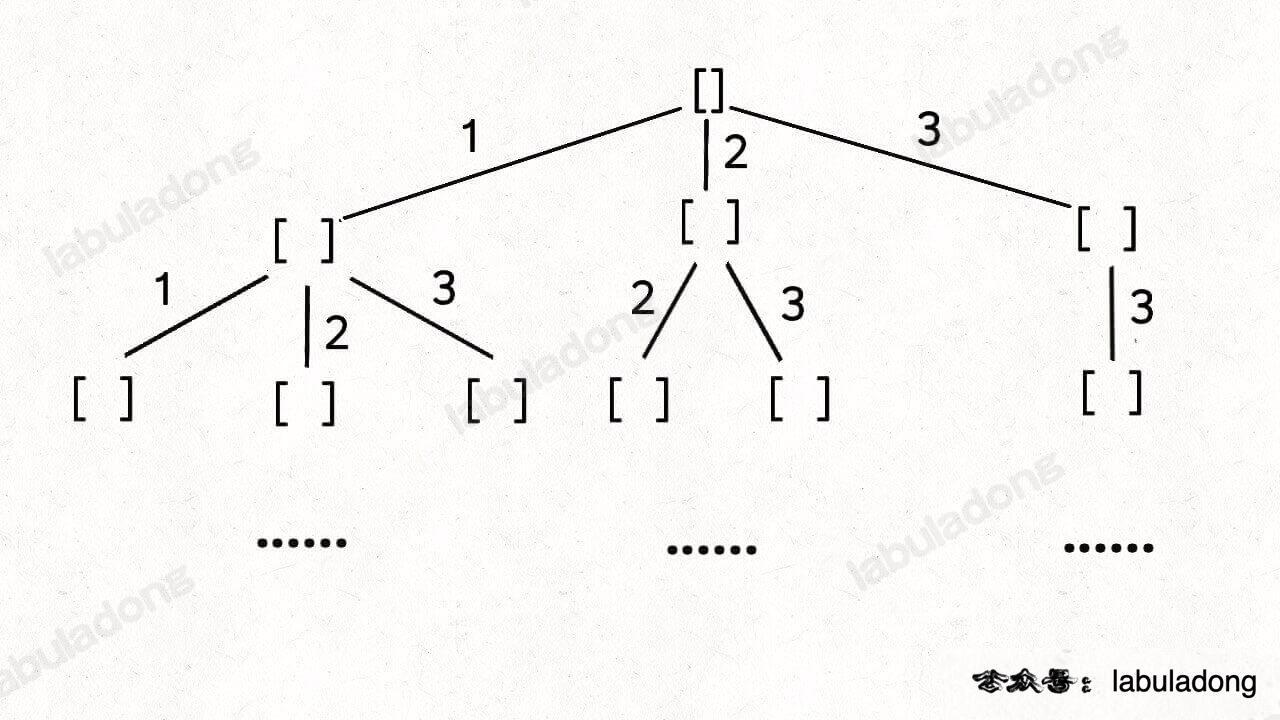
回溯算法常见思路
回溯问题 回溯法,一般可以解决如下几种问题: 组合问题:N个数里面按一定规则找出k个数的集合切割问题:一个字符串按一定规则有几种切割方式子集问题:一个N个数的集合里有多少符合条件的子集排列问题:N个数…...
AR眼镜定制开发_在AR眼镜中实现ChatGPT功能
AR眼镜定制方案中,需要考虑到强大的算力、轻巧的设计和更长的续航时间等基本要求。然而,AR眼镜的设计方案不仅仅需要在硬件和显示技术方面取得突破,还要在用户体验方面有所进展。 过去,由于造价较高,AR眼镜的普及和商业…...

手写防抖debounce
手写防抖debounce 应用场景 当需要在事件频繁触发时,只执行最后一次操作,可以使用防抖函数来控制函数的执行频率,比如窗口resize事件和输入框input事件; 这段代码定义了一个名为 debounce 的函数,它接收两个参数:fn…...

anaconda pycharm jupter分别是
Anaconda Anaconda是一个面向数据科学的Python发行版,它包含了Python解释器、conda包管理器、以及大量的科学计算和数据分析库。Anaconda的主要功能是提供一个易于管理的环境,用于安装、运行和更新Python包,同时支持创建和切换不同的Python环…...
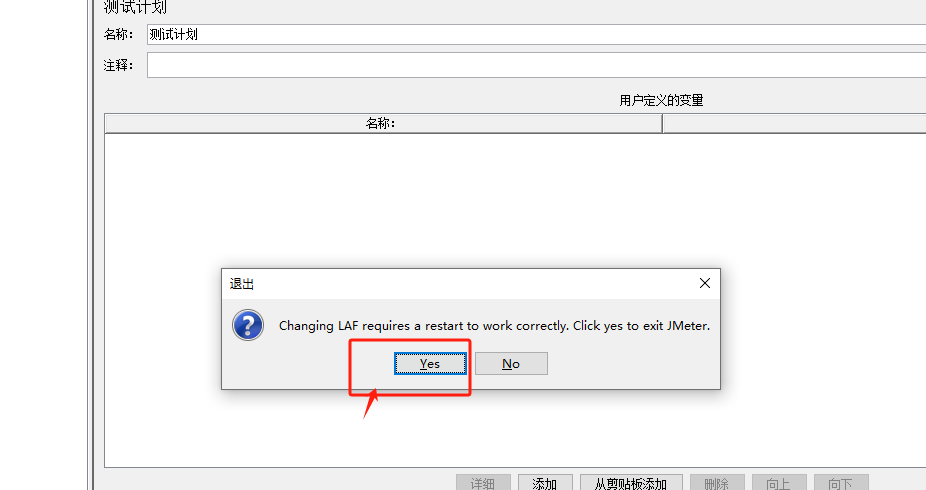
【JMeter接口自动化】第3讲 Jmeter语言及外观配置
Jmeter语言配置 方法一:暂时生效,下次打开JMeter还会恢复默认配置 Jmeter安装后,默认语言是英文,可以在“选项”——“选择语音”中更改 方法二,修改配置文件,永久生效 修改jmeter.properties文件 Jmete…...

浅谈云原生安全
一、云原生安全的层级概念 "4C" Code-Container-Cluster-Cloud 二、云原生各个层级的安全实践有哪些? 1、针对于Cloud针对的是公有云层面,其实就一点 1、使用主账号子角色,赋予最小权限原则进行资源管理。 2、对于Cluster 1、从C…...
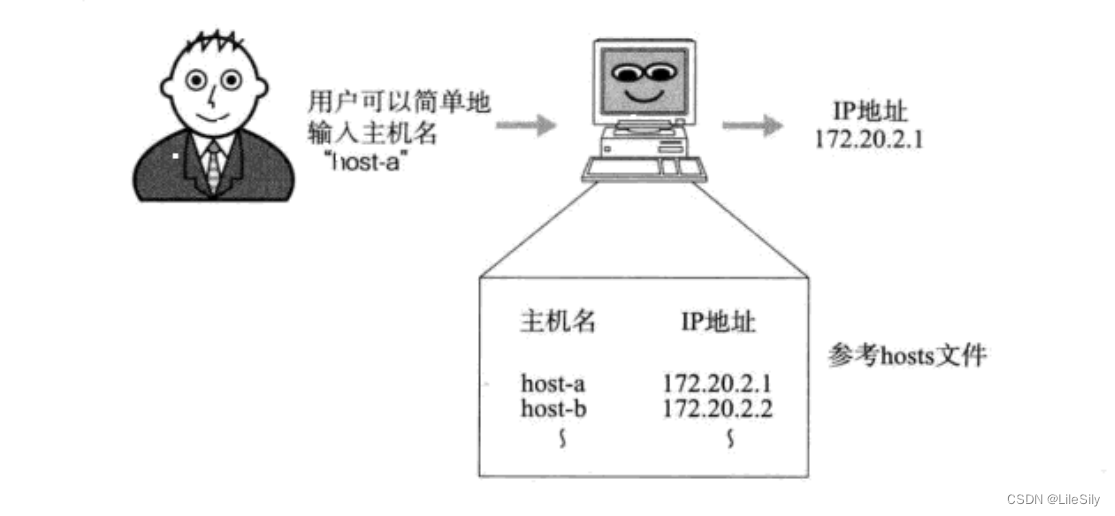
[线程与网络] 网络编程与通信原理(五): 深入理解网络层IP协议与数据链路层以太网协议
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏:🍕 Collection与数据结构 (92平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm1001.2014.3001.5482 🧀Java …...

【Python】超时请求或计算的处理
超时机制 一般应用于处理阻塞问题 场景: 复杂度较大的计算(解析)某个数值、加解密计算等请求中遇到阻塞,避免长时间等待网络波动,避免长时间请求,浪费时间 1. requests 请求超时机制 reqeusts 依赖中的…...

基于ComfyUI API的AIGC自动绘画系统架构设计与实现
1. ComfyUI API自动绘画系统架构设计 第一次接触ComfyUI API时,我被它独特的节点式工作流设计惊艳到了。与传统的Stable Diffusion WebUI不同,ComfyUI将整个AI绘画流程拆解成可自由组合的模块,这种设计理念让自动化系统开发变得异常清晰。下面…...

ComfyUI-Impact-Pack:批量图像处理的效率引擎与智能处理终极指南
ComfyUI-Impact-Pack:批量图像处理的效率引擎与智能处理终极指南 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址…...

3种跨平台传输方案对比:如何实现Windows与iOS设备文件秒传
3种跨平台传输方案对比:如何实现Windows与iOS设备文件秒传 【免费下载链接】AirDropPlus A file transfer and clipboard synchronization tool between Windows and iOS devices implemented by Python and Shortcuts. 项目地址: https://gitcode.com/gh_mirrors…...

Kubernetes集群中containerd运行时集成Harbor与阿里云私有仓库及镜像加速器的实战配置指南
1. 为什么需要集成多种镜像仓库? 在Kubernetes生产环境中,容器镜像的来源往往不是单一的。你可能需要从多个渠道获取镜像:企业内部搭建的Harbor私有仓库存放核心业务镜像,阿里云私有仓库托管第三方组件,公共镜像加速器…...

3步精通:ncmdump网易云音乐NCM格式转换实战指南
3步精通:ncmdump网易云音乐NCM格式转换实战指南 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为网易云音乐下载的加密NCM文件无法在车载音响、专业播放器或其他设备上播放而烦恼吗?ncmdump是一款专为解…...

使用LaTeX撰写基于YOLOv12的学术论文:图表与算法排版最佳实践
使用LaTeX撰写基于YOLOv12的学术论文:图表与算法排版最佳实践 写论文,尤其是涉及复杂模型和大量实验的计算机视觉方向论文,最头疼的往往不是实验本身,而是如何把那些漂亮的图表、复杂的算法和严谨的参考文献,优雅地“…...

[拆解LangChain执行引擎]一个实例理解LangChain的几种流模式
invoke/ainvoke方法看起来是采用简单的请求/回复消息交换模式,客户端需等待整个流程执行完毕后才能得到结果,其实方法背后还是会调用stream/astream方法以流的方式进行交互。如果我们直接调用调用这两个方法,并采用相应的流模式,我…...

AIGlasses OS Pro在智能导航中的应用:实时道路分割与信号识别实操
AIGlasses OS Pro在智能导航中的应用:实时道路分割与信号识别实操 1. 智能导航技术概述 一副看似普通的智能眼镜,如何实现精准的道路导航和信号识别?这背后是AIGlasses OS Pro智能视觉系统的强大能力在发挥作用。作为专为智能眼镜设计的视觉…...

HY-MT1.5-1.8B提效实战:批量SRT翻译系统部署步骤
HY-MT1.5-1.8B提效实战:批量SRT翻译系统部署步骤 本文介绍如何快速部署HY-MT1.5-1.8B翻译模型,实现SRT字幕文件的批量翻译处理,大幅提升多语言字幕制作效率。 1. 环境准备与模型下载 在开始部署前,我们先简单了解下HY-MT1.5-1.8B…...

PHP调用Workerman5.0实现一对一聊天
要实现一对一聊天功能,使用 Workerman 5.0 作为后端,前端可以使用 WebSocket 进行通信。以下是实现步骤和代码示例。1. 安装 Workerman首先,确保你已经安装了 Workerman。可以通过 Composer 安装:1composer require workerman/wor…...