回溯算法常见思路
回溯问题
回溯法,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
组合是不强调元素顺序的,排列是强调元素顺序。
回溯法**解决的问题都可以抽象为树形结构**
回溯三部曲。
- 回溯函数模板返回值以及参数
在回溯算法中,函数起名字为backtracking,函数返回值一般为void。
再来看一下参数,因为回溯算法需要的参数可不像二叉树递归的时候那么容易一次性确定下来,所以一般是先写逻辑,然后需要什么参数,就填什么参数。
void backtracking(参数)
- 回溯函数终止条件
既然是树形结构,那么我们在讲解二叉树的递归 (opens new window)的时候,就知道遍历树形结构一定要有终止条件。
所以回溯也有要终止条件。
什么时候达到了终止条件,树中就可以看出,一般来说搜到叶子节点了,也就找到了满足条件的一条答案,把这个答案存放起来,并结束本层递归。
所以回溯函数终止条件伪代码如下:
if (终止条件) {存放结果;return;
}- 回溯搜索的遍历过程
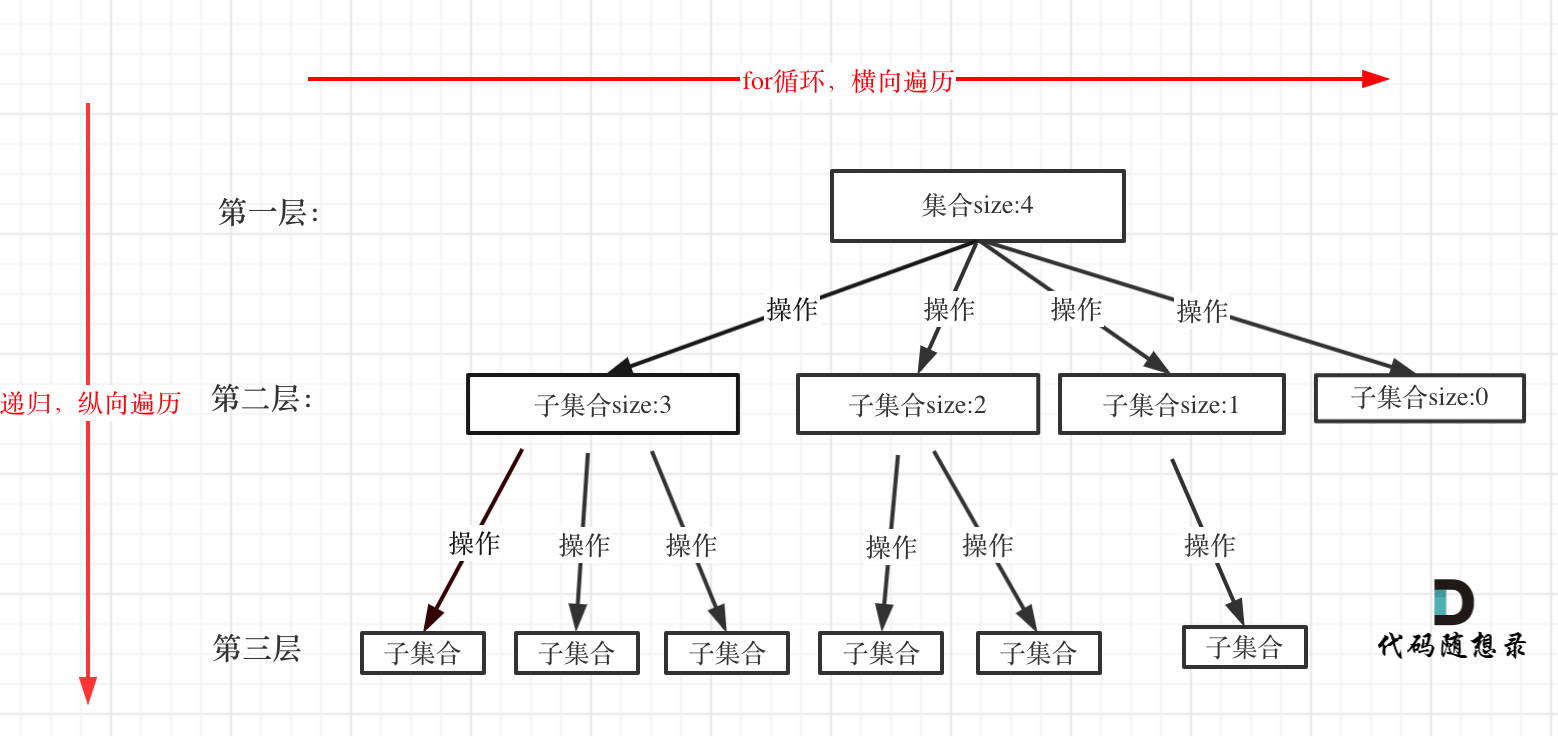
回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
回溯函数遍历过程伪代码如下:
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果
}for循环就是遍历集合区间,可以理解一个节点有多少个孩子,这个for循环就执行多少次。
backtracking这里自己调用自己,实现递归。
大家可以从图中看出for循环可以理解是横向遍历,backtracking(递归)就是纵向遍历,这样就把这棵树全遍历完了,一般来说,搜索叶子节点就是找的其中一个结果了。
分析完过程,回溯算法模板框架如下:
void backtracking(参数) {if (终止条件) {存放结果;return;}for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {处理节点;backtracking(路径,选择列表); // 递归回溯,撤销处理结果}
}剪枝精髓是:for循环在寻找起点的时候要有一个范围,如果这个起点到集合终止之间的元素已经不够 题目要求的k个元素了,就没有必要搜索了。
写 backtrack 函数时,需要维护走过的「路径」和当前可以做的「选择列表」,当触发「结束条件」时,将「路径」记入结果集。
回溯算法秒杀所有排列-组合-子集问题
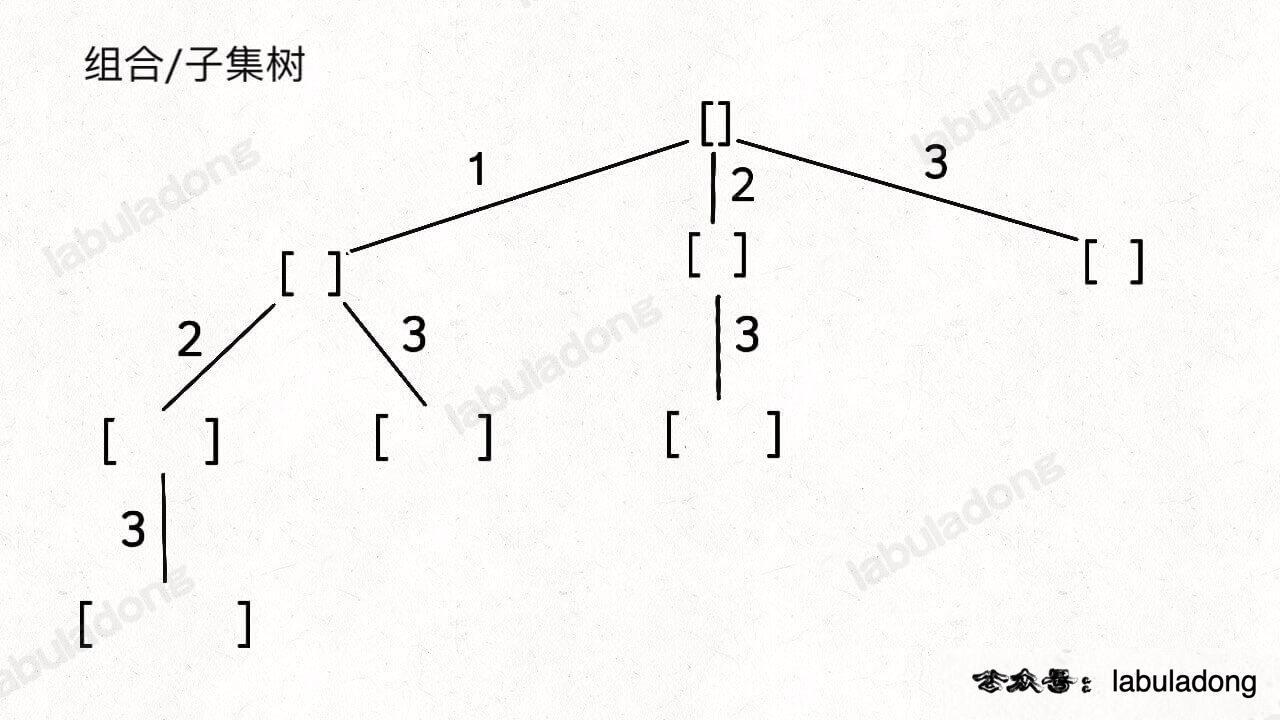
无论是排列、组合还是子集问题,简单说无非就是让你从序列 nums 中以给定规则取若干元素,主要有以下几种变体:
形式一、元素无重不可复选,即 nums 中的元素都是唯一的,每个元素最多只能被使用一次,这也是最基本的形式。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该只有 [7]。
形式二、元素可重不可复选,即 nums 中的元素可以存在重复,每个元素最多只能被使用一次。
以组合为例,如果输入 nums = [2,5,2,1,2],和为 7 的组合应该有两种 [2,2,2,1] 和 [5,2]。
形式三、元素无重可复选,即 nums 中的元素都是唯一的,每个元素可以被使用若干次。
以组合为例,如果输入 nums = [2,3,6,7],和为 7 的组合应该有两种 [2,2,3] 和 [7]。
17 电话号码的字母组合
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
理解本题后,要解决如下三个问题:
- 数字和字母如何映射 :map映射
- 两个字母就两个for循环,三个字符我就三个for循环,以此类推,然后发现代码根本写不出来 :回溯算法
- 输入1 * #按键等等异常情况
本题每一个数字代表的是不同集合,也就是求不同集合之间的组合
class Solution {// 每个数字到字母的映射String[] mapping = new String[] {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};List<String> res = new LinkedList<>();public List<String> letterCombinations(String digits) {if (digits.isEmpty()) {return res;}// 从 digits[0] 开始进行回溯backtrack(digits, 0, new StringBuilder());return res;}// 回溯算法主函数void backtrack(String digits, int start, StringBuilder sb) {if (sb.length() == digits.length()) {// 到达回溯树底部res.add(sb.toString());return;}// 回溯算法框架for (int i = start; i < digits.length(); i++) {int digit = digits.charAt(i) - '0';for (char c : mapping[digit].toCharArray()) {// 做选择sb.append(c);// 递归下一层回溯树backtrack(digits, i + 1, sb);// 撤销选择sb.deleteCharAt(sb.length() - 1);}}}78 子集(元素无重不可复选)需要start标记
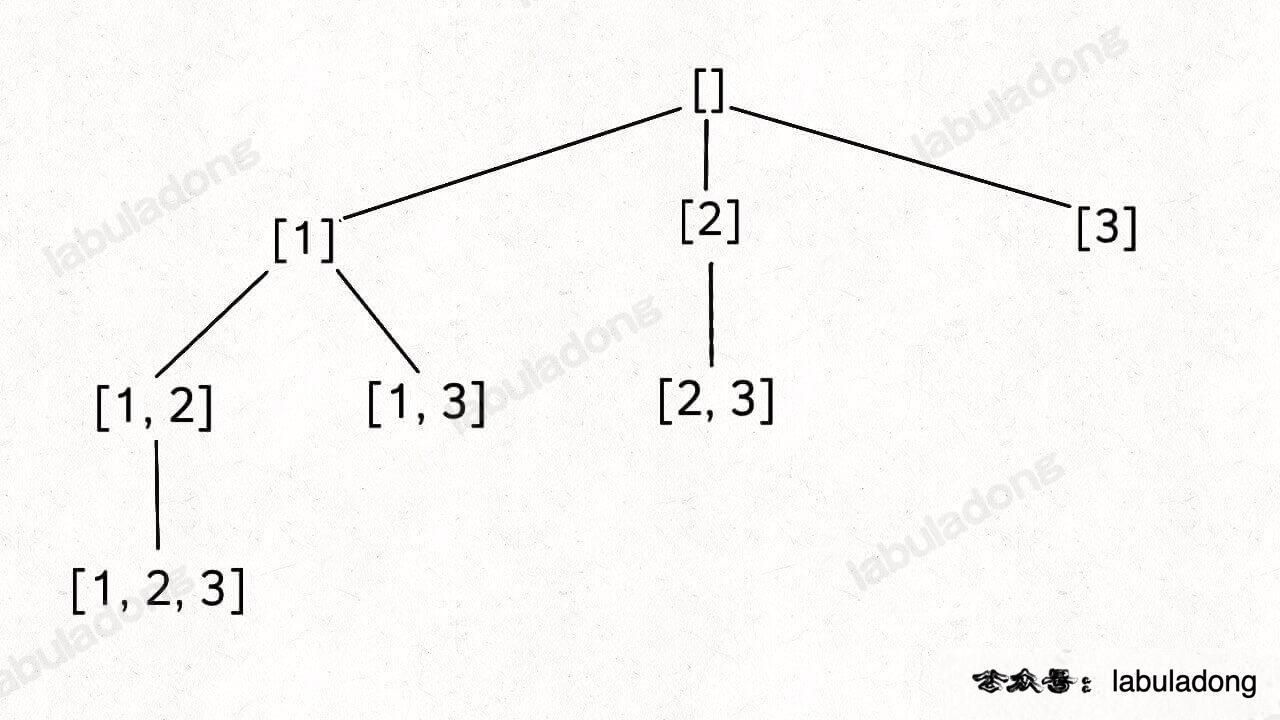
集合中的元素不用考虑顺序,[1,2,3] 中 2 后面只有 3,如果你添加了前面的 1,那么 [2,1] 会和之前已经生成的子集 [1,2] 重复。
如果把根节点作为第 0 层,将每个节点和根节点之间树枝上的元素作为该节点的值,那么第 n 层的所有节点就是大小为 n 的所有子集。比如大小为 2 的子集就是这一层节点的值。
使用start参数控制树枝的生长避免产生重复的子集,用track记录根节点到每个节点的路径的值,同时在前序位置把每个节点的路径值收集起来,完成回溯树的遍历就收集了所有子集
base case:
当 start == nums.length 时,叶子节点的值会被装入 res,但 for 循环不会执行,也就结束了递归。
class Solution {List<List<Integer>> res = new LinkedList<>();// 记录回溯算法的递归路径LinkedList<Integer> track = new LinkedList<>();// 主函数public List<List<Integer>> subsets(int[] nums) {backtrack(nums, 0);return res;}// 回溯算法核心函数,遍历子集问题的回溯树void backtrack(int[] nums, int start) {//base case//当 start == nums.length 时,叶子节点的值会被装入 res,但 for 循环不会执行,也就结束了递归。// 前序位置,每个节点的值都是一个子集res.add(new LinkedList<>(track));// 回溯算法标准框架for (int i = start; i < nums.length; i++) {// 做选择track.addLast(nums[i]);// 通过 start 参数控制树枝的遍历,避免产生重复的子集backtrack(nums, i + 1);// 撤销选择track.removeLast();}}
}77 组合(元素无重不可复选)
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
组合和子集是一样的:大小为 k 的组合就是大小为 k 的子集。
class Solution {List<List<Integer>> res = new LinkedList<>();// 记录回溯算法的递归路径LinkedList<Integer> track = new LinkedList<>();// 主函数public List<List<Integer>> combine(int n, int k) {backtrack(1, n, k);return res;}// 回溯算法核心函数,遍历子集问题的回溯树void backtrack(int start, int n, int k) {// base caseif (k == track.size()) {res.add(new LinkedList<>(track));return;}// 回溯算法标准框架for (int i = start; i <= n; i++) {// 做选择track.addLast(i);// 通过 start 参数控制树枝的遍历,避免产生重复的子集backtrack(i + 1, n, k);// 撤销选择track.removeLast();}}
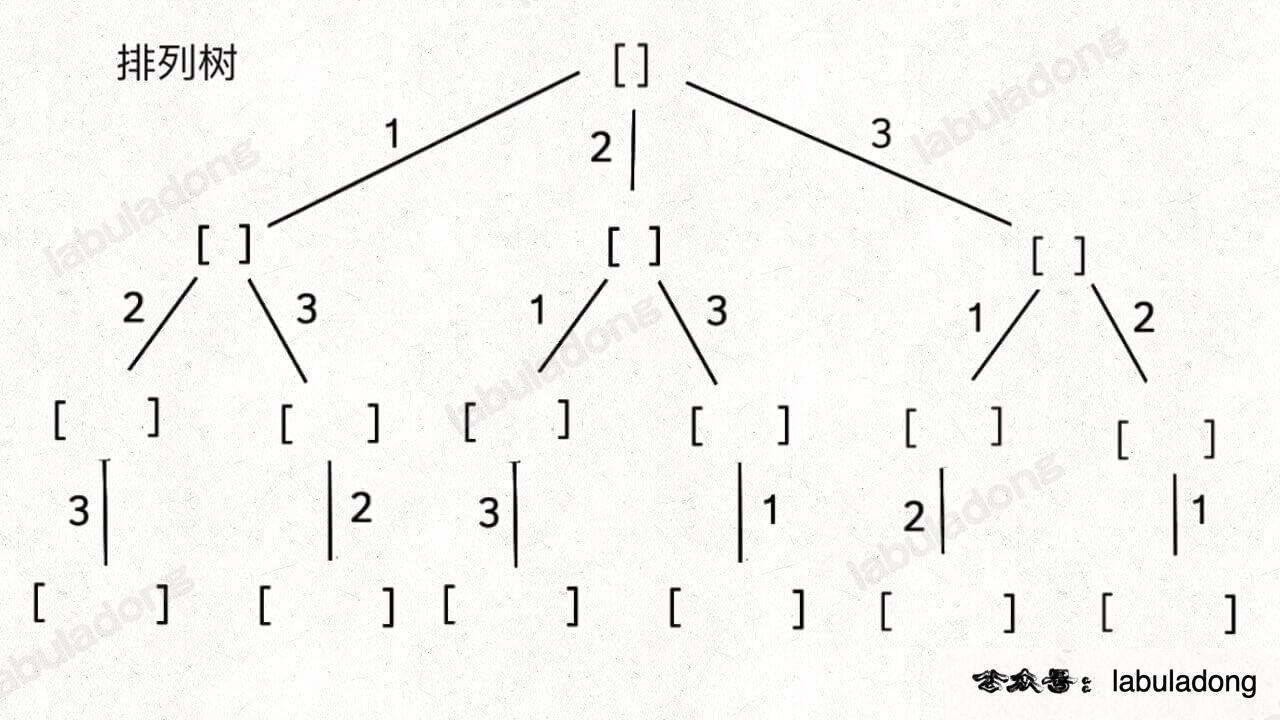
}全排列(元素无重不可复选)使用 used数组标记剩余可选择元素
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
刚才讲的组合/子集问题使用 start 变量保证元素 nums[start] 之后只会出现 nums[start+1..] 中的元素,通过固定元素的相对位置保证不出现重复的子集。
但排列问题本身就是让你穷举元素的位置,nums[i] 之后也可以出现 nums[i] 左边的元素,所以之前的那一套玩不转了,需要额外使用 used 数组来标记哪些元素还可以被选择。
class Solution {
//全局变量List<List<Integer>> res = new LinkedList<>();LinkedList<Integer> track = new LinkedList<>();/* 主函数,输入一组不重复的数字,返回它们的全排列 */List<List<Integer>> permute(int[] nums) {// 「路径」中的元素会被标记为 true,避免重复使用boolean[] used = new boolean[nums.length];backtrack(nums, used);return res;}// 路径:记录在 track 中// 选择列表:nums 中不存在于 track 的那些元素(used[i] 为 false)// 结束条件:nums 中的元素全都在 track 中出现void backtrack(int[] nums ,boolean[] used) {// 触发结束条件if (track.size() == nums.length) {res.add(new LinkedList(track));return;}for (int i = 0; i < nums.length; i++) {// 排除不合法的选择if (used[i]) {// nums[i] 已经在 track 中,跳过 使用过就不再使用 全排列问题不包含重复的数字continue;}// 做选择track.add(nums[i]);used[i] = true;// 进入下一层决策树backtrack(nums, used);// 取消选择track.removeLast();used[i] = false;}}
}如果题目不让你算全排列,而是让你算元素个数为 k 的排列,怎么算?
也很简单,改下 backtrack 函数的 base case,仅收集第 k 层的节点值即可:
// 回溯算法核心函数
void backtrack(int[] nums, int k) {// base case,到达第 k 层,收集节点的值if (track.size() == k) {// 第 k 层节点的值就是大小为 k 的排列res.add(new LinkedList(track));return;}// 回溯算法标准框架for (int i = 0; i < nums.length; i++) {// ...backtrack(nums, k);// ...}
}子集 II (元素可重<需要剪枝> 不可复选)
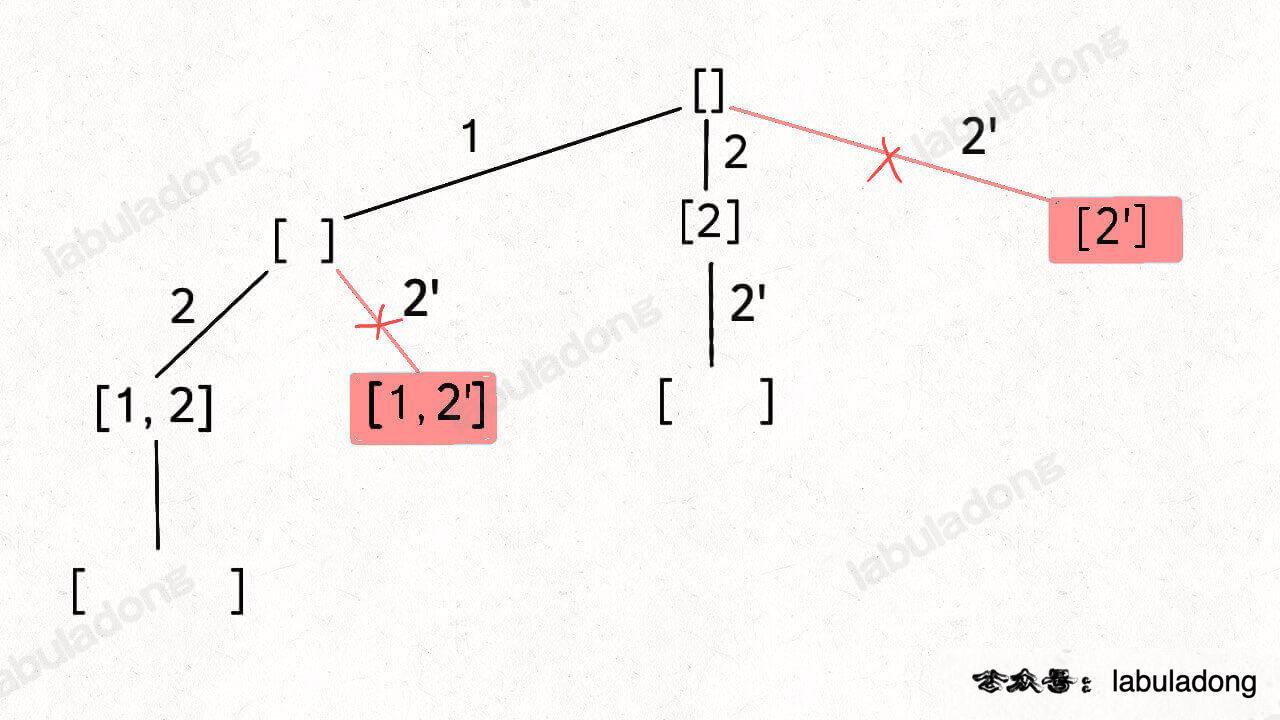
[2] 和 [1,2] 这两个结果出现了重复,所以我们需要进行剪枝,如果一个节点有多条值相同的树枝相邻,则只遍历第一条,剩下的都剪掉,不要去遍历
体现在代码上,需要先进行排序,让相同的元素靠在一起,如果发现 nums[i] == nums[i-1],则跳过
这段代码和之前标准的子集问题的代码几乎相同,就是添加了排序和**剪枝的逻辑**
class Solution {List<List<Integer>> res = new LinkedList<>();LinkedList<Integer> track = new LinkedList<>();public List<List<Integer>> subsetsWithDup(int[] nums) {// 先排序,让相同的元素靠在一起Arrays.sort(nums);backtrack(nums, 0);return res;}void backtrack(int[] nums, int start) {// 前序位置,每个节点的值都是一个子集res.add(new LinkedList<>(track));for (int i = start; i < nums.length; i++) {// 剪枝逻辑,值相同的相邻树枝,只遍历第一条if (i > start && nums[i] == nums[i - 1]) {continue;}track.addLast(nums[i]);backtrack(nums, i + 1);track.removeLast();}}
}组合总和 II (元素可重<需要剪枝> 不可复选)
组合问题和子集问题是等价的
只要额外用一个 trackSum 变量记录回溯路径上的元素和,然后将 base case 改一改即可解决这道题:
class Solution {List<List<Integer>> res = new LinkedList<>();// 记录回溯的路径LinkedList<Integer> track = new LinkedList<>();// 记录 track 中的元素之和int trackSum = 0;public List<List<Integer>> combinationSum2(int[] candidates, int target) {if (candidates.length == 0) {return res;}// 先排序,让相同的元素靠在一起Arrays.sort(candidates);backtrack(candidates, 0, target);return res;}// 回溯算法主函数void backtrack(int[] nums, int start, int target) {// base case,达到目标和,找到符合条件的组合if (trackSum == target) {res.add(new LinkedList<>(track));return;}// base case,超过目标和,直接结束if (trackSum > target) {return;}// 回溯算法标准框架for (int i = start; i < nums.length; i++) {// 剪枝逻辑,值相同的树枝,只遍历第一条if (i > start && nums[i] == nums[i - 1]) {continue;}// 做选择track.add(nums[i]);trackSum += nums[i];backtrack(nums, i + 1, target);track.removeLast();trackSum -= nums[i]; //新增变量也要回溯}}
}全排列 II(元素可重<需要剪枝>不可复选)
对比一下之前的标准全排列解法代码,这段解法代码只有两处不同:
1、对 nums 进行了排序。
2、添加了一句额外的剪枝逻辑。
标准全排列算法之所以出现重复,是因为把相同元素形成的排列序列视为不同的序列,但实际上它们应该是相同的;而如果固定相同元素形成的序列顺序,当然就避免了重复。
class Solution {List<List<Integer>> res = new LinkedList<>();LinkedList<Integer> track = new LinkedList<>();boolean[] used;public List<List<Integer>> permuteUnique(int[] nums) {// 先排序,让相同的元素靠在一起Arrays.sort(nums);used = new boolean[nums.length];backtrack(nums);return res;}void backtrack(int[] nums) {if (track.size() == nums.length) {res.add(new LinkedList(track));return;}for (int i = 0; i < nums.length; i++) {if (used[i]) {continue;}// 新添加的剪枝逻辑,固定相同的元素在排列中的相对位置if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {continue; //i-1没使用过}track.add(nums[i]);used[i] = true;backtrack(nums);track.removeLast();used[i] = false;}}
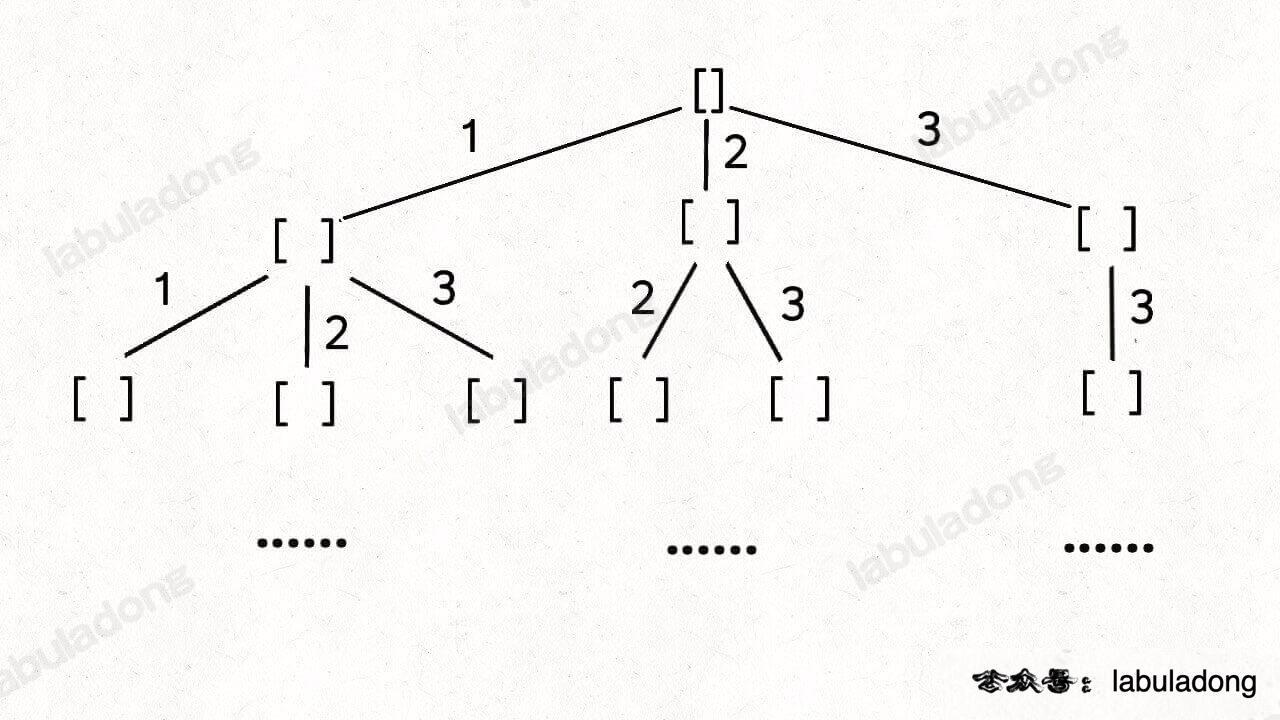
}组合总和(元素无重 可复选)
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?
我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:77.组合 (opens new window),216.组合总和III (opens new window)。
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:17.电话号码的字母组合
这道题说是组合问题,实际上也是子集问题:candidates 的哪些子集的和为 target?
标准的子集/组合问题是如何保证不重复使用元素的?
答案在于 backtrack 递归时输入的参数 start,这个 i 从 start 开始,那么下一层回溯树就是从 start`` ``+ 1 开始,从而保证 nums[start] 这个元素不会被重复使用:
如果我想让每个元素被重复使用,我只要把 i + 1 改成 i 即可
当然,这样这棵回溯树会永远生长下去,所以我们的递归函数需要设置合适的 base case 以结束算法,即路径和大于 target 时就没必要再遍历下去了。
class Solution {List<List<Integer>> res = new LinkedList<>();// 记录回溯的路径LinkedList<Integer> track = new LinkedList<>();// 记录 track 中的路径和int trackSum = 0;public List<List<Integer>> combinationSum(int[] candidates, int target) {if (candidates.length == 0) {return res;}backtrack(candidates, 0, target);return res;}// 回溯算法主函数void backtrack(int[] nums, int start, int target) {// base case,找到目标和,记录结果if (trackSum == target) {res.add(new LinkedList<>(track));return;}// base case,超过目标和,停止向下遍历if (trackSum > target) {return;}// 回溯算法标准框架for (int i = start; i < nums.length; i++) {// 选择 nums[i]trackSum += nums[i];track.add(nums[i]);// 递归遍历下一层回溯树// 同一元素可重复使用,注意参数 不使用i+1backtrack(nums, i, target);// 撤销选择 nums[i]trackSum -= nums[i];track.removeLast();}}
}排列(元素无重可复选)
标准的全排列算法利用 used 数组进行剪枝,避免重复使用同一个元素。如果允许重复使用元素的话,直接放飞自我,去除所有 used 数组的剪枝逻辑就行了。
class Solution {List<List<Integer>> res = new LinkedList<>();LinkedList<Integer> track = new LinkedList<>();public List<List<Integer>> permuteRepeat(int[] nums) {backtrack(nums);return res;}// 回溯算法核心函数void backtrack(int[] nums) {// base case,到达叶子节点if (track.size() == nums.length) {// 收集叶子节点上的值res.add(new LinkedList(track));return;}// 回溯算法标准框架for (int i = 0; i < nums.length; i++) {// 做选择track.add(nums[i]);// 进入下一层回溯树backtrack(nums);// 取消选择track.removeLast();}}
}最后总结
来回顾一下排列/组合/子集问题的三种形式在代码上的区别。
由于子集问题和组合问题本质上是一样的,无非就是 base case 有一些区别,所以把这两个问题放在一起看。
形式一、元素无重不可复选,即 nums 中的元素都是唯一的,每个元素最多只能被使用一次,backtrack 核心代码如下:
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {// 回溯算法标准框架for (int i = start; i < nums.length; i++) {// 做选择track.addLast(nums[i]);// 注意参数backtrack(nums, i + 1);// 撤销选择track.removeLast();}
}/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {for (int i = 0; i < nums.length; i++) {// 剪枝逻辑if (used[i]) {continue;}// 做选择used[i] = true;track.addLast(nums[i]);backtrack(nums);// 撤销选择track.removeLast();used[i] = false;}
}形式二、元素可重不可复选,即 nums 中的元素可以存在重复,每个元素最多只能被使用一次,其关键在于排序和剪枝,backtrack 核心代码如下:
Arrays.sort(nums);
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {// 回溯算法标准框架for (int i = start; i < nums.length; i++) {// 剪枝逻辑,跳过值相同的相邻树枝if (i > start && nums[i] == nums[i - 1]) {continue;}// 做选择track.addLast(nums[i]);// 注意参数backtrack(nums, i + 1);// 撤销选择track.removeLast();}
}Arrays.sort(nums);
/* 排列问题回溯算法框架 */
void backtrack(int[] nums) {for (int i = 0; i < nums.length; i++) {// 剪枝逻辑if (used[i]) {continue;}// 剪枝逻辑,固定相同的元素在排列中的相对位置if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {continue;}// 做选择used[i] = true;track.addLast(nums[i]);backtrack(nums);// 撤销选择track.removeLast();used[i] = false;}
}形式三、元素无重可复选,即 nums 中的元素都是唯一的,每个元素可以被使用若干次,只要删掉去重逻辑即可,backtrack 核心代码如下:
/* 组合/子集问题回溯算法框架 */
void backtrack(int[] nums, int start) {// 回溯算法标准框架for (int i = start; i < nums.length; i++) {// 做选择track.addLast(nums[i]);// 注意参数backtrack(nums, i);// 撤销选择track.removeLast();}
}/* 排列问题回溯算法框架 */ //删除used逻辑
void backtrack(int[] nums) {for (int i = 0; i < nums.length; i++) {// 做选择track.addLast(nums[i]);backtrack(nums);// 撤销选择track.removeLast();}
}部分图引自代码随想录等
相关文章:
回溯算法常见思路
回溯问题 回溯法,一般可以解决如下几种问题: 组合问题:N个数里面按一定规则找出k个数的集合切割问题:一个字符串按一定规则有几种切割方式子集问题:一个N个数的集合里有多少符合条件的子集排列问题:N个数…...
AR眼镜定制开发_在AR眼镜中实现ChatGPT功能
AR眼镜定制方案中,需要考虑到强大的算力、轻巧的设计和更长的续航时间等基本要求。然而,AR眼镜的设计方案不仅仅需要在硬件和显示技术方面取得突破,还要在用户体验方面有所进展。 过去,由于造价较高,AR眼镜的普及和商业…...

手写防抖debounce
手写防抖debounce 应用场景 当需要在事件频繁触发时,只执行最后一次操作,可以使用防抖函数来控制函数的执行频率,比如窗口resize事件和输入框input事件; 这段代码定义了一个名为 debounce 的函数,它接收两个参数:fn…...

anaconda pycharm jupter分别是
Anaconda Anaconda是一个面向数据科学的Python发行版,它包含了Python解释器、conda包管理器、以及大量的科学计算和数据分析库。Anaconda的主要功能是提供一个易于管理的环境,用于安装、运行和更新Python包,同时支持创建和切换不同的Python环…...
【JMeter接口自动化】第3讲 Jmeter语言及外观配置
Jmeter语言配置 方法一:暂时生效,下次打开JMeter还会恢复默认配置 Jmeter安装后,默认语言是英文,可以在“选项”——“选择语音”中更改 方法二,修改配置文件,永久生效 修改jmeter.properties文件 Jmete…...

浅谈云原生安全
一、云原生安全的层级概念 "4C" Code-Container-Cluster-Cloud 二、云原生各个层级的安全实践有哪些? 1、针对于Cloud针对的是公有云层面,其实就一点 1、使用主账号子角色,赋予最小权限原则进行资源管理。 2、对于Cluster 1、从C…...
[线程与网络] 网络编程与通信原理(五): 深入理解网络层IP协议与数据链路层以太网协议
🌸个人主页:https://blog.csdn.net/2301_80050796?spm1000.2115.3001.5343 🏵️热门专栏:🍕 Collection与数据结构 (92平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm1001.2014.3001.5482 🧀Java …...

【Python】超时请求或计算的处理
超时机制 一般应用于处理阻塞问题 场景: 复杂度较大的计算(解析)某个数值、加解密计算等请求中遇到阻塞,避免长时间等待网络波动,避免长时间请求,浪费时间 1. requests 请求超时机制 reqeusts 依赖中的…...

前端 JS 经典:LRU 缓存算法
前言:什么是 LRU 呢,单词全拼 Least Recently Used,意思是最久未使用。这个算法是做缓存用的,比如,你要缓存一组数据,你要划分缓存块出来,因为不可能每个数据都做缓存,那么划出来的这…...

Python3 笔记:ljust、rjust 和 center
1、ljust() 方法返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。 ljust(self, width, fillchar , /) width -- 指定字符串长度。 fillchar -- 填充字符,默认为空格。 str1 sentence str2 word…...

恒压频比开环控制系统Matlab/Simulink仿真分析(SPWM控制方式)
介绍恒压频比的开环控制方法驱动永磁同步电机的转动,首先分析恒压频比的控制原理,然后在Matlab/Simulink中进行永磁同步电机恒压频比开环控制系统的仿真分析,最后将Simulink中的恒压频比控制算法生成代码加载到实际工程中进行工程实现。 一、…...

chatgpt4和文心一言的简单对比
功能1. 写一个ebpf程序监控udp延迟 文心一言 答案 编写一个完整的eBPF程序来监控UDP延迟涉及多个步骤,包括编写eBPF C代码、编译、加载到内核,以及用户空间程序来读取eBPF map中的数据。以下是一个简化的示例框架,展示如何使用eBPF来监控U…...

React 为什么使用map来渲染列表 而不是其他循环方法
1. 声明式与函数式编程 React强调声明式编程,这意味着你只需要关心代码“做什么”,而不是“怎么做”。.map()函数是一种高阶函数,它属于函数式编程范畴,能够返回一个新数组,这非常适合用于生成组件列表。 使用.map()…...
【Axure高保真】tab切换输入表单
今天和大家分享tab切换输入表单的原型模板,这个模板方便我们快速制作表单,里面包含了输入框、下拉列表、选择器共10多种常用的元件,后续也可以根据需要自行添加到中继器里。点击tab标签可以分类填写对应的内容,这个原型模板是用中…...

OrangePi AI Pro 测试体验
感谢CSDN活动提供的OrangePi AI Pro ,之前一直用的树莓派,正好体验一下新的国产设备, 1、开机体验 整个设备包装不错,链接键盘、屏幕和鼠标,整体开机体验不错,内置OS不错,这个系统内嵌了中文输…...
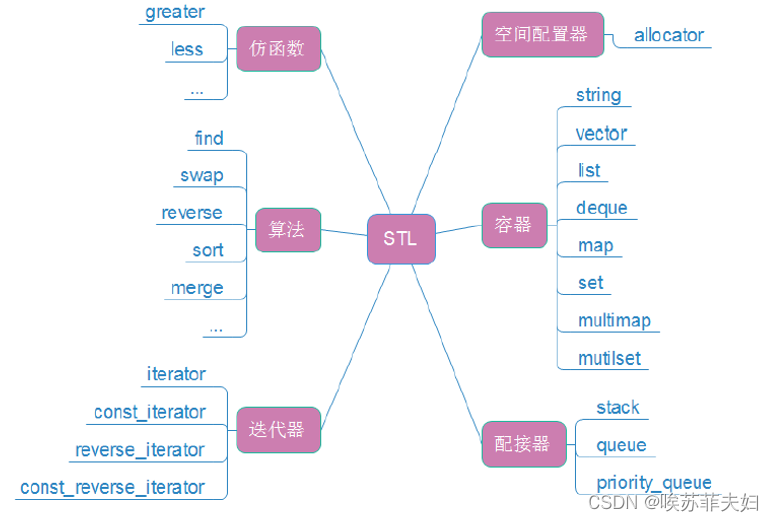
【C++】:模板初阶和STL简介
目录 一,泛型编程二,函数模板2.1 函数模板概念2.2 函数模板格式2.3 函数模板的原理2.4 函数模板的实例化2.5 模板参数的匹配原则 三,类模板3.1 类模板的定义格式3.2 类模板的实例化 四,STL简介(了解)4.1 什…...

【软件开发】Java学习路线
本路径视频教程均来自尚硅谷B站视频,Java学习课程我已经收藏在一个文件夹下,B站文件夹同时会收藏其他Java视频,感谢关注。指路:https://www.bilibili.com/medialist/detail/ml3113981545 2024Java学习路线(快速版&…...

git拉去代码报错“Failed to connect to 127.0.0.1 port 31181: Connection refused“
最近参与了一个新项目,在使用git clone 克隆代码时遇到了一个报错"fatal: unable to access ‘https://example.git/’: Failed to connect to 127.0.0.1 port 31181: Connection refused",今天就和大家分享下解决过程。 报错详情 在使用git clone 克隆…...

解读信创产业根基,操作系统发展历程
信创产业根基之一操作系统 操作系统是一个关键的控制程序,负责协调、管理和控制计算机硬件和软件资源。作为硬件的首要软件扩展,它位于裸机与用户之间,充当了两者之间的桥梁。通过其核心程序,操作系统高效地管理着系统中的各类资源…...

使用Python爬取华为市场游戏类APP应用
文章目录 1. 写在前面2. 接口分析3. 爬虫开发4. 下载链接获取 【🏠作者主页】:吴秋霖 【💼作者介绍】:擅长爬虫与JS加密逆向分析!Python领域优质创作者、CSDN博客专家、阿里云博客专家、华为云享专家。一路走来长期坚守…...
)
告别二维图纸!用管线大师3分钟搞定地下管网三维建模(附Cesium加载教程)
告别二维图纸!用管线大师3分钟搞定地下管网三维建模(附Cesium加载教程) 市政工程师老张盯着屏幕上密密麻麻的CAD线条已经三个小时了。这些代表地下管网的二维线段,在他眼里逐渐模糊成一片灰色的迷宫。"要是能直接看到立体的管…...

Qwen3-ASR-0.6B作品分享:航空管制语音→航班号/高度层/应答机编码提取
Qwen3-ASR-0.6B作品分享:航空管制语音→航班号/高度层/应答机编码提取 你有没有想过,那些听起来像“天书”一样的航空管制对话,背后藏着多少关键信息?飞行员和管制员在无线电里快速交流,每一句指令都关乎飞行安全。如…...

DeepSeek-OCR效果展示:中英文混排+数学公式+跨页表格精准还原
DeepSeek-OCR效果展示:中英文混排数学公式跨页表格精准还原 1. 引言:当文档解析遇到真正的挑战 你有没有遇到过这样的场景? 一份技术文档,里面既有中文说明,又有英文术语,中间还夹杂着复杂的数学公式&am…...

解放你的双手:OpenKore如何让RO游戏效率提升300%的实战指南
解放你的双手:OpenKore如何让RO游戏效率提升300%的实战指南 【免费下载链接】openkore A free/open source client and automation tool for Ragnarok Online 项目地址: https://gitcode.com/gh_mirrors/op/openkore 想象一下,当其他玩家还在手动…...

OpenClaw怎么部署?2026年华为云1分钟超简单部署OpenClaw及大模型百炼APIKey流程
OpenClaw怎么部署?2026年华为云1分钟超简单部署OpenClaw及大模型百炼APIKey流程。OpenClaw作为2026年主流的AI自动化助理平台,可通过阿里云轻量服务器实现724小时稳定运行,并快速接入钉钉,让AI在企业群聊、个人工作流中自动执行任…...

Python flask django框架的环保公益活动管理与宣传系统的设计与开发
目录同行可拿货,招校园代理 ,本人源头供货商环保公益活动管理与宣传系统的功能分析用户管理模块活动管理模块报名与签到系统宣传与分享功能数据统计与分析消息通知系统地图与导航集成积分与奖励机制后台管理系统项目技术支持源码获取详细视频演示 :文章底部获取博主…...

vant-weapp版本升级技术指南:从0.x到最新版的平滑迁移方案
vant-weapp版本升级技术指南:从0.x到最新版的平滑迁移方案 【免费下载链接】vant-weapp 轻量、可靠的小程序 UI 组件库 项目地址: https://gitcode.com/gh_mirrors/va/vant-weapp 引言 在小程序开发过程中,组件库的版本升级是一项常见但具有挑战…...
)
律师不懂代码也能用!华为云AI法律文件生成器配置指南(2024最新版)
律师零代码玩转AI:华为云法律文件生成器2024实操手册 当律所的打印机还在嗡嗡作响时,前沿律所已经用AI完成了十份标准合同的生成。这不是未来图景——2024年的华为云ModelArts平台,已经将法律AI工具的门槛降到了可视化操作级别。作为亲测三个…...

3个掌握步骤:ST7789py_mpy驱动库实现嵌入式显示系统构建
3个掌握步骤:ST7789py_mpy驱动库实现嵌入式显示系统构建 【免费下载链接】st7789py_mpy 项目地址: https://gitcode.com/gh_mirrors/st/st7789py_mpy 在嵌入式开发领域,高效可靠的显示驱动是人机交互的核心桥梁。ST7789py_mpy作为一款专为MicroP…...

终极指南:KOReader开源电子书阅读器如何打造完美个性化阅读体验
终极指南:KOReader开源电子书阅读器如何打造完美个性化阅读体验 【免费下载链接】koreader An ebook reader application supporting PDF, DjVu, EPUB, FB2 and many more formats, running on Cervantes, Kindle, Kobo, PocketBook and Android devices 项目地址…...