AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.25-2024.05.01
文章目录~
- 1.Soft Prompt Generation for Domain Generalization
- 2.Modeling Caption Diversity in Contrastive Vision-Language Pretraining
- 3.Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
- 4.HELPER-X: A Unified Instructable Embodied Agent to Tackle Four Interactive Vision-Language Domains with Memory-Augmented Language Models
- 5.Multi-Page Document Visual Question Answering using Self-Attention Scoring Mechanism
- 6.Hallucination of Multimodal Large Language Models: A Survey
- 7.Transitive Vision-Language Prompt Learning for Domain Generalization
- 8.Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
- 9.FlexiFilm: Long Video Generation with Flexible Conditions
- 10.Medical Vision-Language Pre-Training for Brain Abnormalities
- 11.Large Multi-modality Model Assisted AI-Generated Image Quality Assessment
- 12.Leveraging Cross-Modal Neighbor Representation for Improved CLIP Classification
- 13.MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
- 14.Open-Set Video-based Facial Expression Recognition with Human Expression-sensitive Prompting
- 15.PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
- 16.AAPL: Adding Attributes to Prompt Learning for Vision-Language Models
- 17.Training-Free Unsupervised Prompt for Vision-Language Models
1.Soft Prompt Generation for Domain Generalization
标题:用于领域泛化的软提示生成
author:Shuanghao Bai, Yuedi Zhang, Wanqi Zhou, Zhirong Luan, Badong Chen
publish:23 pages, 4 figures
date Time:2024-04-30
paper pdf:http://arxiv.org/pdf/2404.19286v1
摘要:
大型预训练视觉语言模型(VLMs)在下游任务中显示出了令人印象深刻的零误差能力,而人工设计的提示语并不是特定领域的最佳选择。为了让视觉语言模型进一步适应下游任务,我们提出了软提示来取代人工设计的提示,软提示作为一个学习向量,会根据特定领域的数据进行微调。之前的提示学习方法主要是从训练样本中学习固定提示和残留提示。然而,学习到的提示语缺乏多样性,忽略了未见领域的信息,可能会影响提示语的可迁移性。在本文中,我们从生成的角度重新构建了提示语学习框架,并针对领域泛化(DG)任务提出了一种简单而高效的方法,即软提示语生成(SPG)。据我们所知,我们是第一个将生成模型引入 VLMs 中的提示学习并探索其潜力的研究者,该研究完全依靠生成模型来生成软提示,从而确保了提示的多样性。具体来说,SPG 包括两个阶段的训练阶段和推理阶段。在训练阶段,我们为每个领域引入软提示标签,旨在结合生成模型的领域知识。在推理阶段,我们利用生成模型的生成器为未见过的目标领域获取特定于实例的软提示。在三个 DG 任务的五个领域泛化基准上进行的广泛实验表明,我们提出的 SPG 达到了最先进的性能。代码即将发布。
2.Modeling Caption Diversity in Contrastive Vision-Language Pretraining
标题:对比视觉语言预训练中的字幕多样性建模
author:Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
publish:14 pages, 8 figures, 7 tables, to be published at ICML2024
date Time:2024-04-30
paper pdf:http://arxiv.org/pdf/2405.00740v3
摘要:
有一千种方法可以为图像添加标题。另一方面,对比语言预训练(CLIP)的工作原理是将图像及其标题映射到一个单一的向量上,这就限制了类似 CLIP 的模型能够很好地代表描述图像的各种方式。在这项工作中,我们引入了 Llip(潜在语言图像预训练),它可以对与图像匹配的各种标题进行建模。Llip 的视觉编码器会输出一组视觉特征,这些特征会根据从文本中获取的信息混合成最终的表示形式。我们的研究表明,即使使用大规模编码器,Llip 在各种任务中的表现也优于 CLIP 和 SigLIP 等非文本化基准。在使用 ViT-G/14 编码器的零镜头分类基准测试中,Llip 平均提高了 2.9%。具体来说,在 ImageNet 上,Llip 的零镜头 Top-1 准确率达到 83.5%,比类似规模的 CLIP 高出 1.4%。我们还证明,在 MS-COCO 上,零点检索的准确率提高了 6.0%。我们对该方法引入的组件进行了全面分析,并证明 Llip 能带来更丰富的视觉表征。
3.Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM
标题:Q-GroundCAM:通过 GradCAM 量化视觉语言模型中的基础知识
author:Navid Rajabi, Jana Kosecka
publish:Accepted to CVPR 2024, Second Workshop on Foundation Models (WFM)
date Time:2024-04-29
paper pdf:http://arxiv.org/pdf/2404.19128v1
摘要:
视觉和语言模型(VLM)在各种任务中不断显示出卓越的零镜头(ZS)性能。然而,许多探究性研究表明,即使是表现最好的视觉语言模型也难以捕捉到场景合成理解的各个方面,缺乏在图像中正确定位语言短语的能力。VLM 最近的进步包括扩大了模型和数据集的规模,增加了训练目标和监督级别,以及模型架构的变化。为了描述 VLM 的定位能力(如短语定位、指代表达理解和关系理解),Pointing Game 已被用作带有边界框注释的数据集的评估指标。在本文中,我们介绍了一套新的定量指标,利用 GradCAM 激活来严格评估 CLIP、BLIP 和 ALBEF 等预训练 VLM 的接地能力。这些指标提供了一种可解释和可量化的方法,用于更详细地比较 VLM 的零点能力,并能测量模型接地的不确定性。这种表征揭示了模型大小、数据集大小及其性能之间有趣的权衡。
4.HELPER-X: A Unified Instructable Embodied Agent to Tackle Four Interactive Vision-Language Domains with Memory-Augmented Language Models
标题:HELPER-X:利用记忆增强语言模型解决四个交互式视觉语言领域问题的统一指导型嵌入式机器人
author:Gabriel Sarch, Sahil Somani, Raghav Kapoor, Michael J. Tarr, Katerina Fragkiadaki
publish:Videos and code https://helper-agent-llm.github.io/
date Time:2024-04-29
paper pdf:http://arxiv.org/pdf/2404.19065v1
摘要:
最近关于可指示代理的研究将记忆增强型大语言模型(LLM)用作任务规划器,这种技术可以检索与输入指令相关的语言程序示例,并将其用作大语言模型提示中的上下文示例,从而提高大语言模型在推断正确的行动和任务计划方面的性能。在本技术报告中,我们扩展了 HELPER 的功能,利用更广泛的示例和提示来扩展其内存,并集成了用于提问的附加应用程序接口。将 HELPER 简单地扩展为共享存储器后,该代理就能在执行对话计划、遵循自然语言指令、主动提问和常识性房间重组等领域开展工作。我们在四个不同的交互式视觉语言嵌入式代理基准上对该代理进行了评估:ALFRED、TEACh、DialFRED 和整理任务。在这些基准测试中,HELPER-X 使用单个代理,无需进行域内训练,就能取得寥寥无几的一流性能,而且与经过域内训练的代理相比,HELPER-X 仍具有很强的竞争力。
5.Multi-Page Document Visual Question Answering using Self-Attention Scoring Mechanism
标题:利用自我关注评分机制进行多页文档可视化问题解答
author:Lei Kang, Rubèn Tito, Ernest Valveny, Dimosthenis Karatzas
publish:Accepted to ICDAR2024
date Time:2024-04-29
paper pdf:http://arxiv.org/pdf/2404.19024v1
摘要:
文档是书面交流的二维载体,因此其解释需要一种多模式方法,将文本信息和视觉信息有效地结合起来。文档可视化问题解答(Document Visual Question Answering,简称 VQA)正是基于这种多模态特性,引起了文档理解界和自然语言处理界的极大兴趣。最先进的单页文档可视化问题解答方法表现出令人印象深刻的性能,但在多页情况下,这些方法就显得力不从心了。它们必须将所有页面串联成一个大页面进行处理,这需要大量的 GPU 资源,甚至在评估时也是如此。在这项工作中,我们针对多页面文档 VQA 任务提出了一种新方法和高效的训练策略。特别是,我们采用了纯视觉文档表示法,利用了来自文档理解模型 Pix2Struct 的编码器。我们的方法利用自我关注评分机制为每个文档页面生成相关性评分,从而能够检索相关页面。这种适应性使我们能够将单页文档 VQA 模型扩展到多页场景,在评估过程中不受页数限制,而且对 GPU 资源的需求极低。我们的大量实验表明,不仅无需光学字符识别(OCR)就能实现最先进的性能,而且在扩展到近 800 页文档的场景中也能保持性能,而在 MP-DocVQA 数据集中最多只有 20 页。我们的代码可在(url{https://github.com/leitro/SelfAttnScoring-MPDocVQA})上公开获取。
6.Hallucination of Multimodal Large Language Models: A Survey
标题:多模态大语言模型的幻觉:调查
author:Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
publish:140 references
date Time:2024-04-29
paper pdf:http://arxiv.org/pdf/2404.18930v1
摘要:
本研究全面分析了多模态大型语言模型(MLLM)(也称为大型视觉语言模型(LVLM))中的幻觉现象。尽管发展前景广阔,但 MLLM 经常会产生与视觉内容不一致的输出结果,这就是所谓的 “幻觉”(hallucination)。这一问题已引起越来越多的关注,促使人们努力检测和减少这种不准确性。我们回顾了在识别、评估和缓解这些幻觉方面的最新进展,详细概述了根本原因、评估基准、衡量标准以及为解决这一问题而开发的策略。此外,我们还分析了当前面临的挑战和局限性,提出了一些开放性问题,为今后的研究划定了潜在的路径。通过对幻觉成因、评估基准和缓解方法进行细化分类和描绘,本调查旨在加深对 MLLMs 中幻觉的理解,并激发该领域的进一步发展。通过我们全面而深入的回顾,我们将为正在进行的关于增强 MLLM 的稳健性和可靠性的对话做出贡献,为研究人员和从业人员提供有价值的见解和资源。相关资源请访问:https://github.com/showlab/Awesome-MLLM-Hallucination。
7.Transitive Vision-Language Prompt Learning for Domain Generalization
标题:跨视觉语言提示学习促进领域泛化
author:Liyuan Wang, Yan Jin, Zhen Chen, Jinlin Wu, Mengke Li, Yang Lu, Hanzi Wang
date Time:2024-04-29
paper pdf:http://arxiv.org/pdf/2404.18758v1
摘要:
视觉语言预训练使深度模型在未见领域的泛化方面向前迈进了一大步。最近基于视觉语言预训练模型的学习方法是实现领域泛化的利器,可以在很大程度上解决这一问题。然而,在目前的领域泛化问题中,领域不变性和类别可分性之间的权衡仍然是一个进步的关键。然而,仍有一些问题需要在领域不变性和类可分性之间进行权衡,而这在当前的 DG 问题中至关重要。在本文中,我们介绍了一种新颖的提示学习策略,它利用深度视觉提示来解决领域不变性问题,同时利用语言提示来确保类别可分性,再加上自适应加权机制来平衡领域不变性和类别可分性。广泛的实验证明,深度视觉提示能有效提取领域不变性特征,显著提高深度模型的泛化能力,并在三个数据集上取得了最先进的性能。
8.Do Vision & Language Decoders use Images and Text equally? How Self-consistent are their Explanations?
标题:视觉和语言解码器是否同样使用图像和文本?它们的解释有多自洽?
author:Letitia Parcalabescu, Anette Frank
publish:27 pages, from which 12 pages contain the text of the main paper. 8
figures, 11 tables
date Time:2024-04-29
paper pdf:http://arxiv.org/pdf/2404.18624v1
摘要:
视觉和语言模型(VLM)是目前多模态任务中性能最普遍的架构。除了预测之外,它们还能在事后或 CoT 设置中生成解释。然而,目前还不清楚它们在生成预测或解释时使用视觉和文本模式的程度。在这项工作中,我们将研究 VLMs 在生成解释时对模态的依赖程度是否与提供答案时不同。我们还通过将现有测试和测量方法扩展到 VLM 解码器,评估了 VLM 解码器在事后解释和 CoT 解释设置中的自洽性。我们发现,VLM 的自洽性低于 LLM。在所有测量任务中,VL 解码器的文字贡献都远远大于图像贡献。在生成解释时,图像的贡献明显大于生成答案时。与事后解释设置相比,CoT 中的这种差异更大。我们还在 VALSE 基准上对最先进的 VL 解码器进行了最新基准测试。我们发现,VL 解码器在应对 VALSE 测试的大多数现象时仍然很吃力。
9.FlexiFilm: Long Video Generation with Flexible Conditions
标题:FlexiFilm:在灵活的条件下生成长视频
author:Yichen Ouyang, jianhao Yuan, Hao Zhao, Gaoang Wang, Bo zhao
publish:9 pages, 9 figures
date Time:2024-04-29
paper pdf:http://arxiv.org/pdf/2404.18620v1
摘要:
生成连贯的长视频已成为一个重要而又具有挑战性的问题。现有的基于扩散的视频生成模型大多源自图像生成模型,在生成短视频时表现出良好的性能,但其简单的调节机制和采样策略–最初是为图像生成而设计的–在适用于长视频生成时却造成了严重的性能下降。这导致了突出的时间不一致性和过度曝光。因此,在这项工作中,我们引入了 FlexiFilm,一种为长视频生成量身定制的新扩散模型。我们的框架包含一个时间调节器,用于在生成和多模式条件之间建立更一致的关系,以及一个重采样策略,用于解决过度曝光问题。实证结果表明,FlexiFilm 能够生成长度一致的长视频,每个视频长度超过 30 秒,在定性和定量分析中均优于竞争对手。项目页面: https://y-ichen.github.io/FlexiFilm-Page/
10.Medical Vision-Language Pre-Training for Brain Abnormalities
标题:针对大脑异常的医学视觉语言预培训
author:Masoud Monajatipoor, Zi-Yi Dou, Aichi Chien, Nanyun Peng, Kai-Wei Chang
date Time:2024-04-27
paper pdf:http://arxiv.org/pdf/2404.17779v1
摘要:
对于需要理解视觉和语言元素的任务来说,视觉语言模型已变得越来越强大,在这些模态之间架起了一座桥梁。在多模态临床人工智能的背景下,对拥有特定领域知识的模型的需求日益增长,因为现有模型往往缺乏医疗应用所需的专业知识。在本文中,我们以大脑异常为例,演示如何从公共资源(如 PubMed)中自动收集医学图像-文本对齐数据进行预训练。特别是,我们提出了一个简化预训练过程的管道,首先从病例报告和已出版期刊中收集大量脑图像-文本数据集,然后构建一个为特定医疗任务量身定制的高性能视觉语言模型。我们还研究了医疗领域中将子图标映射到子标题的独特挑战。我们通过定量和定性的内在评估,对由此产生的模型进行了评估。由此产生的数据集和我们的代码可以在这里找到 https://github.com/masoud-monajati/MedVL_pretraining_pipeline
11.Large Multi-modality Model Assisted AI-Generated Image Quality Assessment
标题:大型多模态模型辅助人工智能生成的图像质量评估
author:Puyi Wang, Wei Sun, Zicheng Zhang, Jun Jia, Yanwei Jiang, Zhichao Zhang, Xiongkuo Min, Guangtao Zhai
date Time:2024-04-27
paper pdf:http://arxiv.org/pdf/2404.17762v1
摘要:
传统的基于深度神经网络(DNN)的图像质量评估(IQA)模型利用卷积神经网络(CNN)或变形器来学习质量感知特征表示,在自然场景图像上取得了值得称道的性能。然而,当应用于人工智能生成的图像(AGIs)时,这些基于 DNN 的 IQA 模型却表现不佳。造成这种情况的主要原因是,某些 AGIs 在生成过程中存在不可控性,导致语义不准确。因此,辨别语义内容的能力成为评估 AGI 质量的关键。传统的基于 DNN 的 IQA 模型受限于有限的参数复杂度和训练数据,很难捕捉到复杂的细粒度语义特征,这使得把握整个图像的语义内容的存在性和连贯性变得十分困难。针对当前 IQA 模型在语义内容感知方面的不足,我们引入了大型多模态模型辅助人工智能生成的图像质量评估(MA-AGIQA)模型,该模型利用语义信息引导来感知语义信息,并通过精心设计的文本提示来提取语义向量。此外,它还采用了专家混合(MoE)结构,将语义信息与基于 DNN 的传统 IQA 模型所提取的质量感知特征进行动态整合。在两个人工智能生成的内容数据集(AIGCQA-20k 和 AGIQA-3k)上进行的综合实验表明,MA-AGIQA 实现了最先进的性能,并证明了其在评估 AGI 质量方面的卓越泛化能力。代码见 https://github.com/wangpuyi/MA-AGIQA。
12.Leveraging Cross-Modal Neighbor Representation for Improved CLIP Classification
标题:利用跨模态邻域表征改进 CLIP 分类
author:Chao Yi, Lu Ren, De-Chuan Zhan, Han-Jia Ye
date Time:2024-04-27
paper pdf:http://arxiv.org/pdf/2404.17753v1
摘要:
CLIP 通过图像-文本对比学习任务的训练,展示了卓越的跨模态匹配能力。然而,如果不针对单模态场景进行特定优化,它在单模态特征提取方面的性能可能会不尽如人意。尽管如此,仍有一些研究直接将 CLIP 的图像编码器用于少镜头分类等任务,导致其预训练目标与特征提取方法不一致。这种不一致会降低图像特征表示的质量,从而对 CLIP 在目标任务中的有效性产生不利影响。在本文中,我们将文本特征视为 CLIP 空间中图像特征的精确邻域,并基于图像与其邻域文本之间的距离结构,提出了一种新颖的 CrOss-moDal nEighbor Representation(CODER)。这种特征提取方法更符合 CLIP 的预训练目标,从而充分发挥了 CLIP 强大的跨模态能力。构建高质量 CODER 的关键在于如何创建大量与图像匹配的高质量、多样化文本。我们引入了自动文本生成器(ATG),以无数据、无训练的方式自动生成所需的文本。我们将 CODER 应用于 CLIP 的零镜头和少镜头图像分类任务。各种数据集和模型的实验结果证实了 CODER 的有效性。代码见:https://github.com/YCaigogogo/CVPR24-CODER。
13.MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
标题:MovieChat+:用于长视频问题解答的问题感知稀疏内存
author:Enxin Song, Wenhao Chai, Tian Ye, Jenq-Neng Hwang, Xi Li, Gaoang Wang
date Time:2024-04-26
paper pdf:http://arxiv.org/pdf/2404.17176v1
摘要:
最近,整合视频基础模型和大型语言模型来构建视频理解系统可以克服特定预定义视觉任务的局限性。然而,现有的方法要么采用复杂的时空模块,要么严重依赖额外的感知模型来提取视频理解的时间特征,而且这些方法只能在短视频中表现良好。我们利用阿特金森-希夫林(Atkinson-Shiffrin)记忆模型的优势,将变形金刚中的代币作为记忆载体,结合我们专门设计的记忆机制,提出了 MovieChat 来克服这些挑战。我们采用零镜头方法,在不加入额外的可训练时序模块的情况下,提升了用于理解长视频的预训练多模态大型语言模型。MovieChat 在长视频理解方面取得了最先进的性能,同时还发布了 MovieChat-1K 基准,其中包含 1K 长视频、2K 时空基础标签和 14K 人工注释,用于验证我们方法的有效性。代码和数据集可通过以下网址访问:https://github.com/rese1f/MovieChat。
14.Open-Set Video-based Facial Expression Recognition with Human Expression-sensitive Prompting
标题:基于视频的开放集面部表情识别与人类表情敏感提示
author:Yuanyuan Liu, Yuxuan Huang, Shuyang Liu, Yibing Zhan, Zijing Chen, Zhe Chen
date Time:2024-04-26
paper pdf:http://arxiv.org/pdf/2404.17100v1
摘要:
在基于视频的面部表情识别(V-FER)中,模型通常是在具有固定数量的已知类别的封闭数据集上进行训练的。然而,这些 V-FER 模型无法处理现实世界中普遍存在的未知类别。在本文中,我们引入了一项具有挑战性的基于视频的开放集面部表情识别(OV-FER)任务,该任务不仅要识别已知类别,还要识别在训练过程中未遇到的新的未知人类面部表情。虽然现有方法通过利用大规模视觉语言模型(如 CLIP)来识别未见类别,从而解决开放集识别问题,但我们认为这些方法可能无法充分捕捉 OV-FER 任务所需的细微和微妙的人类表情模式。为了解决这一局限性,我们提出了一种新颖的人类表情敏感提示(HESP)机制,以显著增强 CLIP 对基于视频的面部表情细节进行有效建模的能力,从而提出一种基于 CLIP 的全新 OV-FER 方法。我们提出的 HESP 包括三个部分:1) 具有可学习提示表征的文本提示模块,用于补充 CLIP 的原始文本提示,并增强已知和未知情绪的文本表征;2) 视觉提示模块,利用表情敏感注意力对视频帧中的时间情绪信息进行编码,使 CLIP 具备提取丰富情绪信息的全新视觉建模能力;3) 精心设计的开放集多任务学习方案,可促进提示学习,并鼓励文本和视觉提示模块之间的互动。在四种 OV-FER 任务设置上进行的广泛实验表明,HESP 能显著提高 CLIP 的性能(在 AUROC 和 OSCR 上分别提高了 17.93% 和 106.18%),并在很大程度上优于其他最先进的开放集视频理解方法。
15.PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
标题:PLLaVA:从图像到视频的无参数 LLaVA 扩展,用于视频密集型字幕制作
author:Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, Jiashi Feng
date Time:2024-04-25
paper pdf:http://arxiv.org/pdf/2404.16994v2
摘要:
视觉语言预训练大大提高了各种图像语言应用的性能。然而,视频相关任务的预训练过程需要极其庞大的计算和数据资源,这阻碍了视频语言模型的发展。本文研究了一种直截了当、高效率、轻资源的方法,以调整现有的图像语言预训练模型,用于密集视频理解。我们的初步实验表明,在视频数据集上以多帧为输入直接微调预训练图像语言模型会导致性能饱和甚至下降。我们的进一步研究发现,这在很大程度上归因于学习到的高规范视觉特征的偏差。基于这一发现,我们提出了一种简单而有效的池化策略,以平滑沿时间维度的特征分布,从而减少极端特征的主要影响。新模型被称为池化 LLaVA,简称 PLLaVA。PLLaVA 在视频问答和字幕任务的现代基准数据集上取得了新的一流性能。值得注意的是,在最近流行的 VideoChatGPT 基准测试中,PLLaVA 在五个评估维度上的平均得分达到了 3.48 分(满分 5 分),比之前 GPT4V (IG-VLM) 的 SOTA 结果高出 9%。在最新的多选择基准 MVBench 中,PLLaVA 在 20 个子任务中平均达到 58.1% 的准确率,比 GPT4V (IG-VLM) 高出 14.5%。代码见 https://pllava.github.io/
16.AAPL: Adding Attributes to Prompt Learning for Vision-Language Models
标题:AAPL:为视觉语言模型的提示学习添加属性
author:Gahyeon Kim, Sohee Kim, Seokju Lee
publish:Accepted to CVPR 2024 Workshop on Prompting in Vision, Project Page:
https://github.com/Gahyeonkim09/AAPL
date Time:2024-04-25
paper pdf:http://arxiv.org/pdf/2404.16804v1
摘要:
大型预训练视觉语言模型的最新进展已经证明,在零镜头下游任务中的表现非常出色。在此基础上,最近的研究(如 CoOp 和 CoCoOp)提出了使用提示学习的方法,即用可学习向量替换提示中的上下文,从而显著改善人工制作的提示。然而,对未见类别的性能改进仍然微乎其微,为了解决这个问题,传统的零点学习技术中经常使用数据增强技术。通过实验,我们发现了 CoOp 和 CoCoOp 中存在的重要问题:通过传统图像增强学习到的上下文偏向于已见类别,这对未见类别的泛化产生了负面影响。为了解决这个问题,我们提出了对抗性标记嵌入(adversarial token embedding)技术,以便在诱导可学习提示中的偏差时,将低级视觉增强特征与高级类别信息分离开来。我们通过名为 “为提示学习添加属性”(AAPL)的新机制,引导可学习上下文有效地提取文本特征,重点关注未见类别的高级特征。我们在 11 个数据集上进行了实验,总体而言,与现有方法相比,AAPL 在少数几次学习、零次学习、跨数据集和域泛化任务中都表现出了良好的性能。
17.Training-Free Unsupervised Prompt for Vision-Language Models
标题:视觉语言模型的免训练无监督提示
author:Sifan Long, Linbin Wang, Zhen Zhao, Zichang Tan, Yiming Wu, Shengsheng Wang, Jingdong Wang
date Time:2024-04-25
paper pdf:http://arxiv.org/pdf/2404.16339v1
摘要:
提示学习已成为将大型预训练视觉语言模型(VLM)适应下游任务的最有效范式。最近,无监督提示调整方法(如 UPL 和 POUF)直接利用伪标签作为监督信息,在无标签数据上微调额外的适配模块。然而,不准确的伪标签很容易误导调优过程,导致表征能力低下。有鉴于此,我们提出了免训练无监督提示(TFUP),它最大限度地保留了固有的表征能力,并以免训练、免标记的方式,通过与基于相似性的预测概率的残余联系来增强表征能力。具体来说,我们整合了实例置信度和原型分数来选择具有代表性的样本,并利用这些样本定制可靠的特征缓存模型(FCM),以实现免训练推理。然后,我们设计了一种多级相似性测量(MSM),它同时考虑了特征级和语义级的相似性,将每个测试图像与缓存样本之间的距离计算为相应缓存标签的权重,从而生成基于相似性的预测概率。通过这种方法,TFUP 取得了惊人的性能,甚至在多个分类数据集上超过了基于训练的方法。在 TFUP 的基础上,我们提出了一种基于训练的方法(TFUP-T),以进一步提高适应性能。除了标准的交叉熵损失外,TFUP-T 还采用了额外的边际分布熵损失,从全局角度对模型进行约束。在多个基准测试中,与无监督适应方法和少量适应方法相比,我们的 TFUP-T 取得了新的一流分类性能。特别是,在最具挑战性的 Domain-Net 数据集上,TFUP-T 将 POUF 的分类准确率提高了 3.3%。
相关文章:
:2024.04.25-2024.05.01)
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.25-2024.05.01
文章目录~ 1.Soft Prompt Generation for Domain Generalization2.Modeling Caption Diversity in Contrastive Vision-Language Pretraining3.Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM4.HELPER-X: A Unified Instructable Embodied Agent t…...

gdb调试常见指令
quit:退出gdb list/l:l 文件名:行号/函数名,l 行号/函数名 b:b 文件名:行号/函数名,b 行号/函数名 info/i: info b d:d 断电编号 disable/enable 断电编号:使能(关闭࿰…...

二进制安装mysql8.1
MySQL的安装各个版本步骤几乎一致,本文以安装8.1为例 创建用户及安装需要的依赖包 创建用户及用户组 groupadd mysql useradd -g mysql -s /sbin/nologin mysql 安装依赖包 apt install libncurses5 libncursesw5 libaio1 numactl wget -y 获取二进制包 可以…...

前端工程化工具系列(六)—— VS Code(v1.89.1):强大的代码编辑器
VS Code(Visual Studio Code)是一款由微软开发的强大且轻量级的代码编辑器,支持多种编程语言,并提供了丰富的扩展插件生态系统。 这里主要介绍如何使用配置 ESLint、Stylelint 等插件来提升开发效率。 1 自动格式化代码 最终要…...
重学java 59.Properties属性集集合嵌套集合下总结
不要咀嚼小小悲观,而忘掉整个世界 —— 24.6.3 一、Properties集合(属性集) 1.概述 Properties 继承 于HashTable 2.特点 a、key唯一,value可重复 b、无序 c、无索引 d、线程安全 e、不能存null键,null值 f、Propertie…...
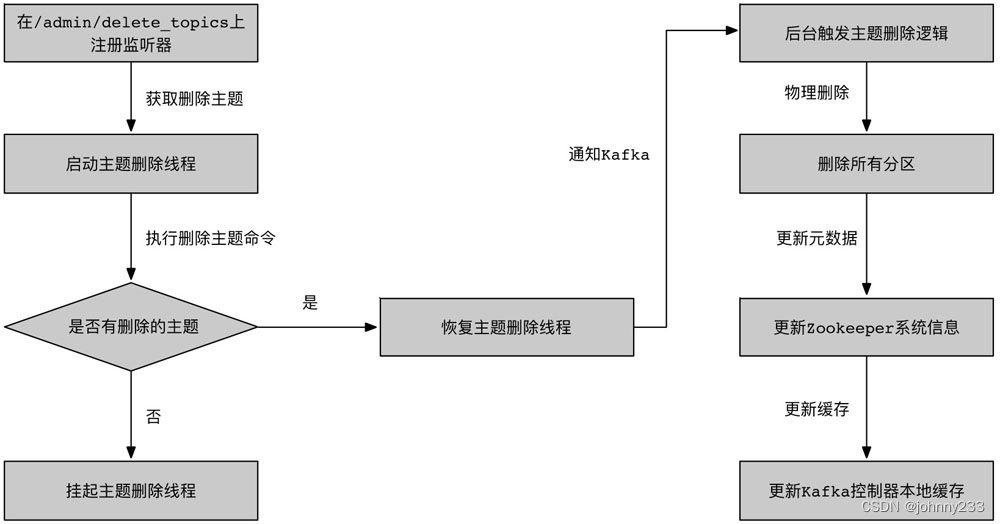
Kafka系列之高频面试题
基础 简介 特点: 高吞吐、低延迟:kafka每秒可以处理几十万条消息,延迟最低只有几毫秒,每个Topic可以分多个Partition,Consumer Group对Partition进行Consumer操作可扩展性:Kafka集群支持热扩展持久性、可…...

SIP通话分析
20240603 - 引言 分析SIP协议的时候,发现了几个问题。虽然说,从整体上来看这个SIP的通话流程也没麻烦,实际上从RFC的概述部分就已经基本上就已经了解了全貌。但在实际的场景中,很多字段起到的作用就不太一样了。 虽然一开始的时…...
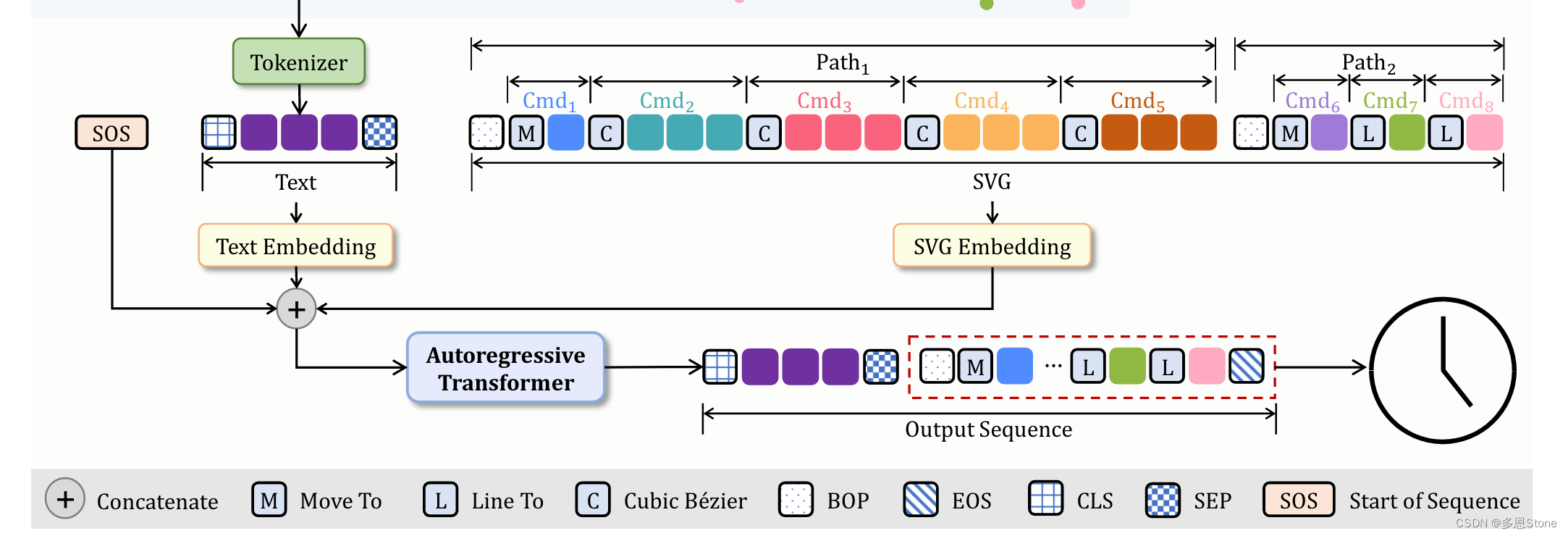
【SVG 生成系列论文(九)】如何通过文本生成 svg logo?IconShop 模型推理代码详解
SVG 生成系列论文(一) 和 SVG 生成系列论文(二) 分别介绍了 StarVector 的大致背景和详细的模型细节。SVG 生成系列论文(三)和 SVG 生成系列论文(四)则分别介绍实验、数据集和数据增…...

有哪些兼职软件一天能赚几十元?盘点十个能长期做下去的挣钱软件
在当今这个信息泛滥的时代,众人纷纷寻求迅速致富的捷径。许多人在从事兼职或副业时,并不期望取得巨大的成就,只要每天能额外收入数十元,便已心满意足。 今天,我将带领大家深入探究,揭开那些隐藏在日常生活…...

ubuntu 22.04配置静态ip
ubuntu 22.04配置静态ip vim /etc/netplan/01-network-manager-all.yaml# Let NetworkManager manage all devices on this system network:renderer: NetworkManagerethernets:enp4s0f1:addresses:- 192.168.1.18/24dhcp4: falseroutes:- to: defaultvia: 192.168.1.1nameser…...

C++ 使用 nlohmann/json 库
C常用 json 库有: Jsoncpp boost ison Qt Json (不推荐使用) nlohman::json (推荐使用) 其中Qt中json解析的相关类只在qt中有用,为了避免以后不用qt无法解析json,建议使用nlohmann/json,适用于任何C框架。 1. 简介 nlohmann是一…...

【Java面试】六、Spring框架相关
文章目录 1、单例Bean不是线程安全的2、AOP3、Spring中事务的实现4、Spring事务失效的场景4.1 情况一:异常被捕获4.2 情况二:抛出检查异常4.3 注解加在非public方法上 5、Bean的生命周期6、Bean的循环引用7、Bean循环引用的解决:Spring三级缓…...

【GIC400】——PLIC,NVIC 和 GIC 中断对比
文章目录 PLIC,NVIC 和 GIC 中断对比中断向量表PLIC中断向量表中断使能中断服务函数NVIC中断向量表中断使能中断服务函数GIC中断向量表系列文章 【ARMv7-A】——异常与中断 【ARMv7-A】——异常中断处理概述...
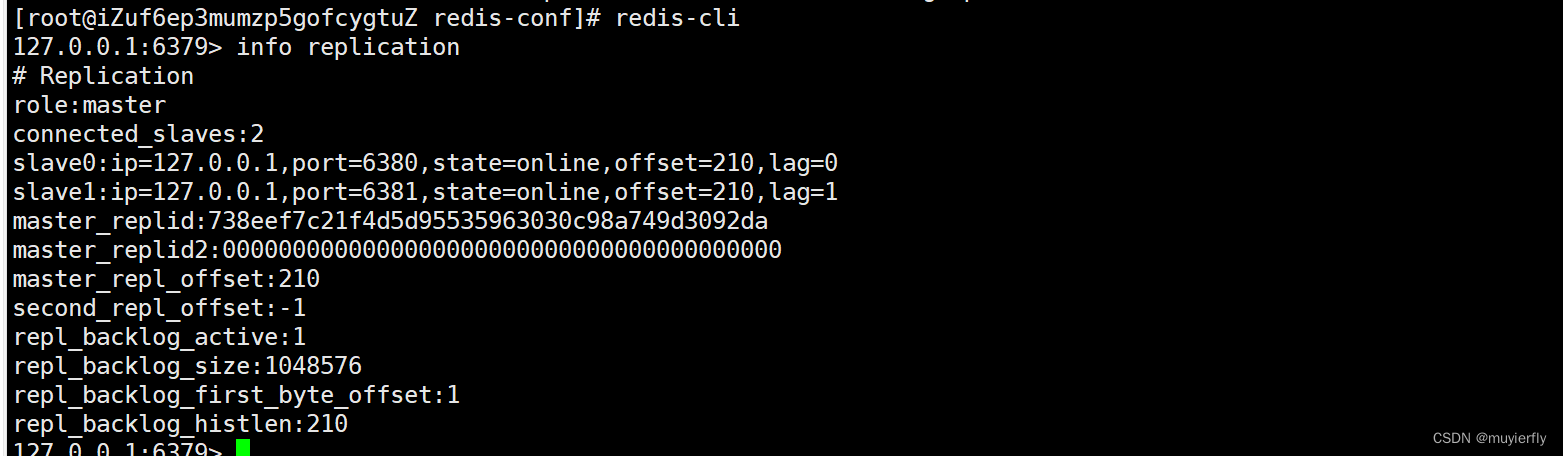
17.Redis之主从复制
1.主从复制是怎么回事? 分布式系统, 涉及到一个非常关键的问题: 单点问题 单点问题:如果某个服务器程序, 只有一个节点(只搞一个物理服务器, 来部署这个服务器程序) 1.可用性问题,如果这个机器挂了,意味着服务就中断了~ 2.性能/支持的并发量也是比较有限…...

计算机类专业应该怎么选学校和方向?优先选这些!
👆点击关注 获取更多编程干货👆 高考季临近,不少有意向报考计算机专业的同学在为院校和细分专业的选择而苦恼,以下是一些建议,希望能帮到大家! 01 选校建议 在选择计算机科学(CS)…...

Amazon云计算AWS(二)
目录 三、简单存储服务S3(一)S3的基本概念和操作(二)S3的数据一致性模型(三)S3的安全措施 四、非关系型数据库服务SimpleDB和DynamoDB(一)非关系型数据库与传统关系数据库的比较&…...

实战
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 实战一:大乐透号码生成器 使用Random模块模拟大乐透号码生成器。选号规则为:前区在1~35的范围内随机产生不重复的…...

【C++】vector模拟实现
🔥个人主页: Forcible Bug Maker 🔥专栏: STL || C 目录 前言🔥vector需要实现的接口函数🔥vector的模拟实现swap交换默认成员函数迭代器接口reserve和resizesize和capacityoperator[ ]下标获取push_back和…...
生成随机图片
package com.zhuguohui.app.lib.tools;/*** Created by zhuguohui* Date: 2024/6/1* Time: 13:39* Desc:获取随机图片*/ public class RandomImage {// static final String url "https://picsum.photos/%d/%d?random%d";static final String url "https://…...
回溯算法常见思路
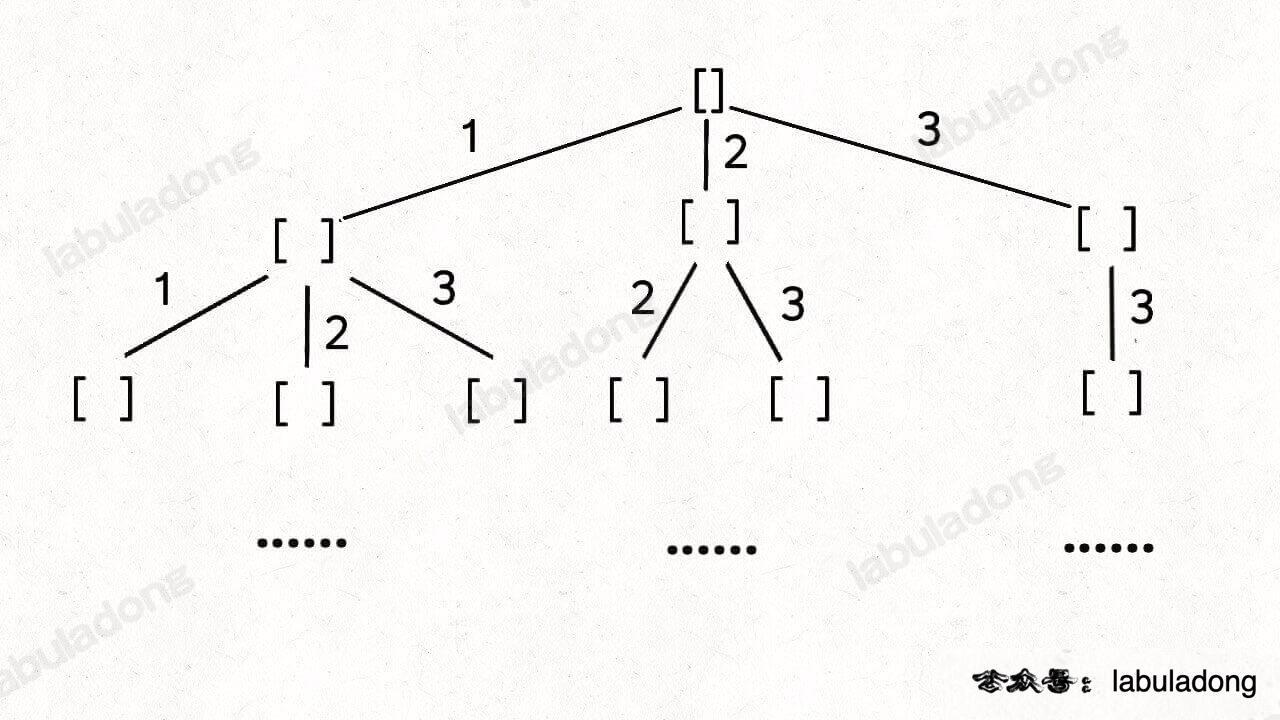
回溯问题 回溯法,一般可以解决如下几种问题: 组合问题:N个数里面按一定规则找出k个数的集合切割问题:一个字符串按一定规则有几种切割方式子集问题:一个N个数的集合里有多少符合条件的子集排列问题:N个数…...

Web开发全栈实践:构建一个图像描述生成与分享社区网站
Web开发全栈实践:构建一个图像描述生成与分享社区网站 你有没有想过,如果上传一张照片,就能立刻得到一段生动有趣的文字描述,还能和其他人分享、讨论这些描述,那会是一个什么样的网站?今天,我们…...
Elsevier Tracker:三步搞定学术投稿焦虑,你的论文审稿终极监控方案
Elsevier Tracker:三步搞定学术投稿焦虑,你的论文审稿终极监控方案 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 还在为 Elsevier 期刊投稿后的漫长等待而焦虑吗?每天手动刷新页…...

无需代码基础:MogFace高精度人脸检测可视化工具快速上手
无需代码基础:MogFace高精度人脸检测可视化工具快速上手 1. 工具简介:零门槛的人脸检测神器 想象一下这样的场景:你刚拍完一张集体照,想知道照片里有多少人;或者你需要从监控视频中快速找出特定人物。传统方法要么需…...
openEuler欧拉系统LVM动态扩容实战:从规划到文件系统在线扩展)
(六)openEuler欧拉系统LVM动态扩容实战:从规划到文件系统在线扩展
1. 为什么需要动态扩容? 最近接手了一个跑在openEuler上的业务系统,数据量每天都在疯涨。上周监控突然报警,根目录只剩下10%的空间,眼看着就要撑爆了。这种情况要是放在以前,估计得停机扩容,但现在有了LVM&…...

OpenClaw模型切换:千问3.5-9B与其他模型的性能对比
OpenClaw模型切换:千问3.5-9B与其他模型的性能对比 1. 为什么需要关注模型切换 上周我在调试一个自动化文档整理流程时,发现OpenClaw执行结果时好时坏——有时能完美分类归档,有时却把会议纪要误认为技术文档。排查后发现是默认模型对长文本…...
)
5分钟学会用PHPStudy搭建Pikachu靶场(含一句话木马实战)
5分钟实战:用PHPStudy快速搭建Pikachu靶场与一句话木马攻防演练 在网络安全领域,动手实践往往比理论阅读更能快速提升技能。本文将带您完成一次完整的本地环境搭建与基础渗透测试演练——从零开始配置PHPStudy环境、部署Pikachu靶场,到实战演…...

OpenClaw成本优化:Qwen2.5-VL-7B自部署降低图文任务Token消耗
OpenClaw成本优化:Qwen2.5-VL-7B自部署降低图文任务Token消耗 1. 图文任务Token消耗的痛点 作为长期使用OpenClaw处理图文任务的开发者,我最初依赖云端API完成所有操作。每次执行包含图片识别的任务时,Token消耗就像开了闸的水龙头——一个…...

OpenClaw技能扩展实战:用Qwen3.5-9B自动生成技术博客并发布
OpenClaw技能扩展实战:用Qwen3.5-9B自动生成技术博客并发布 1. 为什么选择OpenClawQwen3.5-9B组合 去年我开始尝试用AI辅助技术写作时,最头疼的就是内容生产链路的断裂——用大模型生成草稿后,还需要手动复制到编辑器、调整格式、添加Front…...

Using Vulkan -- Atomics
原子操作的类型变体 想要更好地理解各类相关扩展,首先需要了解 Vulkan 提供的不同原子操作类型,主要分为以下维度: 数据类型 floatint 位宽 16 bit32 bit64 bit 操作类型 加载(loads)存储(stores&am…...

嵌入式线段树库:轻量级区间查询与更新实现
1. Segment Tree 库概述:面向嵌入式场景的高效区间查询与更新数据结构Segment Tree(线段树)是一种经典的分治型二叉树数据结构,专为解决高频次、动态化、区间性数组操作而设计。在资源受限的嵌入式系统(如 Arduino、ES…...