二叉树—堆(C语言实现)
一、树的概念及结构
1.树的概念
树是一种非线性的数据结构,它是有n(n > 0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一颗倒挂的树,也就是说它是根朝上,而叶朝下。
● 有一个特殊的结点,成为根结点,根结点没有前驱结点
● 除根节点外,其余节点被分成M(M > 0)个互不相交的集合T1、T2、......、Tm,其中每个集合Ti(1 <= i <= m)又是一颗结构与树相类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
● 因此,树是递归定义
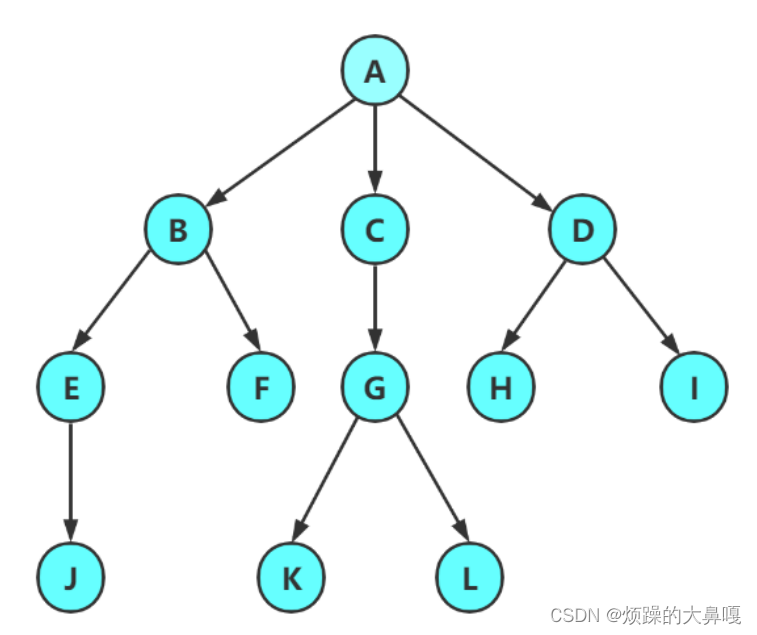
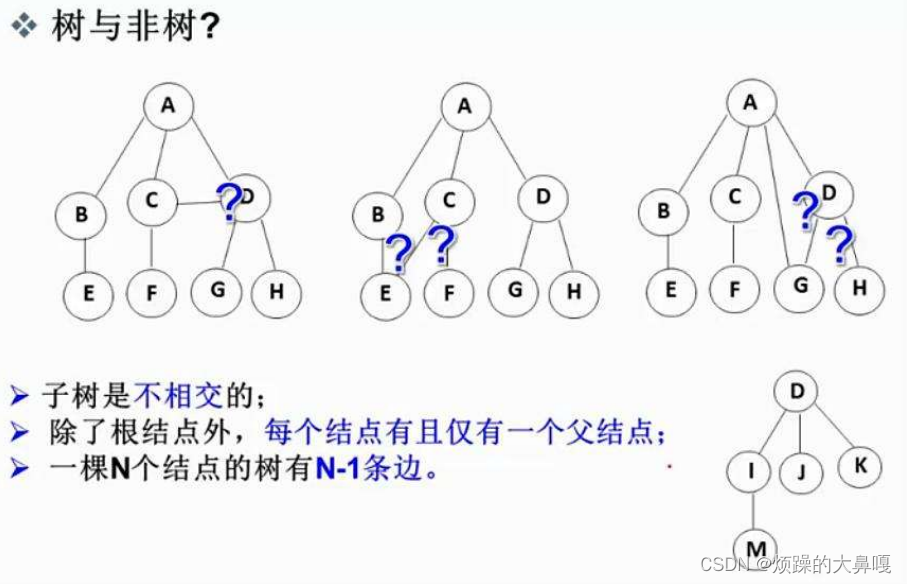
注意:树形结构中,子树之间不能有交集,否则就不是树形结构。
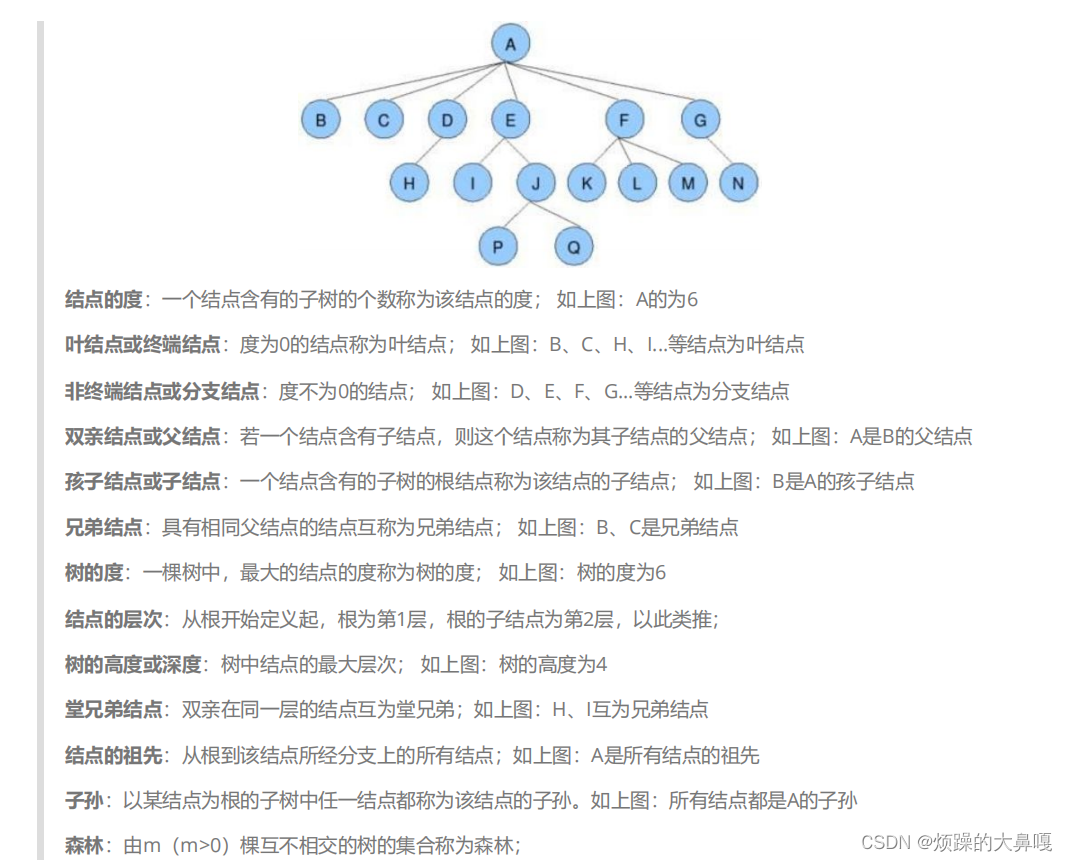
2.树的相关概念
3.树的表示
树结构相对线性表就比较复杂,要存储表示起来就比较麻烦,既然保存值域,也要保存结点和结点之间的关系,实际上数有很多表示方式比如:双亲表示法,孩子表示法,孩子双亲表示法以及孩子兄弟表示法等。我们这里就简单的理解其中最常用的孩子兄弟表示法。
typedef int DataType;
struct Node
{struct Node* firstChild1; // 第一个孩子结点struct Node* pNextBrother; // 指向其下一个兄弟结点DataType data; // 结点中的数据域
};
二、二叉树的概念及结构
1.概念
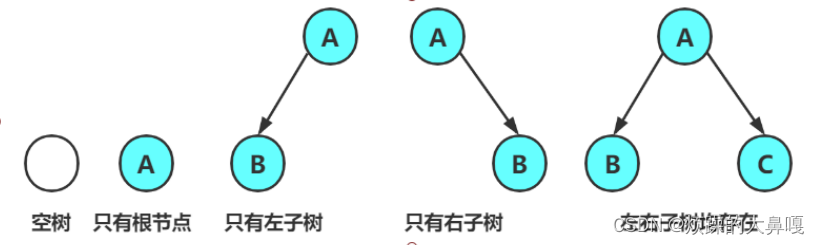
一颗二叉树是节点的一个有限集合,该集合:
1.由一个根结点加上两颗别称为左子树和右子树的二叉树组成2.或者为空

由上图可知:
1.二叉树不存在度大于2的结点
2.二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
注意:对于任意的二叉树都是有以下几种情况符合而成的:
2.特殊的二叉树
(1)满二叉树:一个二叉树,如果每一层的结点数都要达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且总结点数是,则它就是满二叉树。
(2)完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树印出来的。对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点——对应时称之为完全二叉树。要注意的是满二叉树是一种特殊的完全二叉树。

3.二叉树的性质
(1)若规定根结点的层数为1,则一颗树非空二叉树的第i层上最多有个结点。
(2)若规定根结点的层数为1,则深度为h的二叉树的最大结点数是。
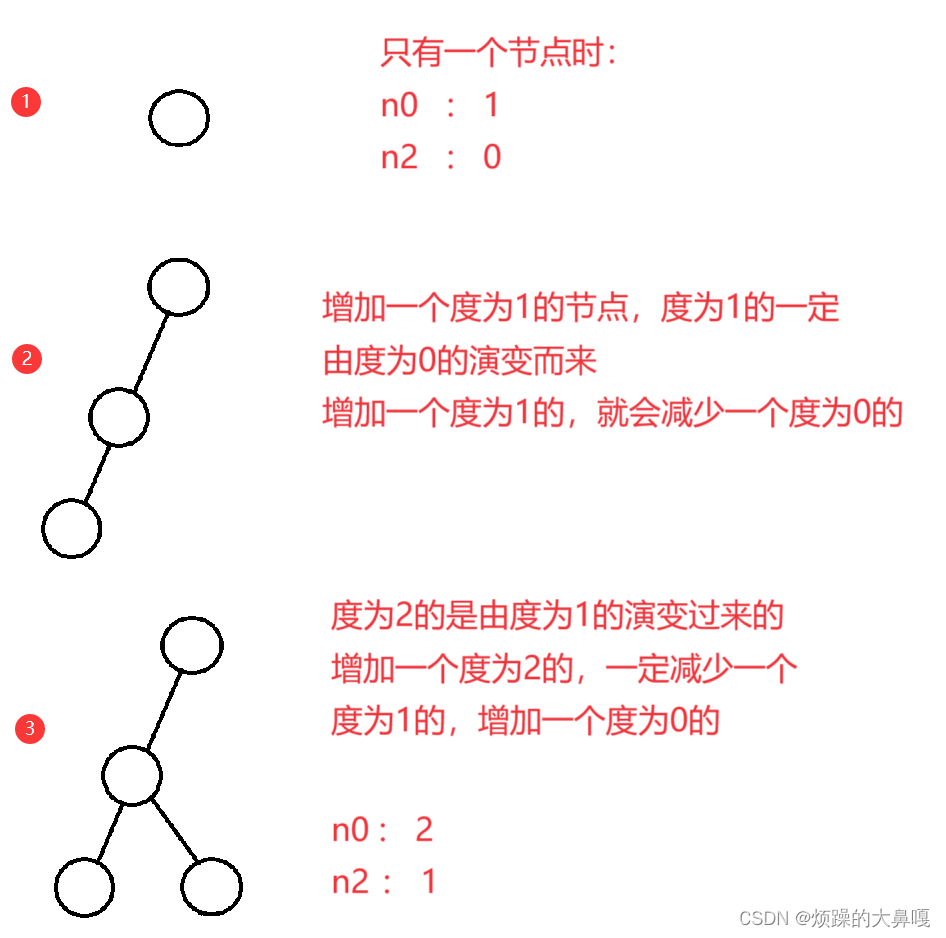
(3)对任何一颗二叉树,如果度为0其叶结点个数为n0,度为2的分支结点个数为n2,则有n0=n2+1
<1>类比归纳(图解) :
<2>定义推导:
假设二叉树有N个结点
从总结点数角度考虑:N = n0 + n1 + n2 ①
从边的角度考虑,N个结点的任意二叉树,总共有N-1条边
因为二叉树中每一个结点都有双亲,根结点没有双亲,每个结点向上与其双亲之间存在一条边,因此N个结点的二叉树总共有N-1条边。
因为度为0的节点没有孩子,故度为0的节点不产生边;度为1的结点只有一个孩子。故每个度为1的结点产生一条边;度为2的结点有两个孩子,故每个度为2的结点产生两条边,所以总边数为:n1 + 2*n2
故从边的角度考虑:N-1 = n1 + 2*n2 ②
结合①和②得:n0 + n1 + n2 = n1 + 2*n2 - 1
即n0 = n2 + 1
(4)若规定根结点的层数为1,具有n个结点的满二叉树的深度,(是log以2为底,n+1为对数)
(5)对于具有n个结点的完全二叉树,如果从上到下从左至右的数组顺序对所有节点从0开始编号,则对于序号为i的节点结点有:
1.若 i > 0,i 位置结点的双亲序号:( i -1) / 2;i = 0,i 为根节点编号,无双亲结点
2.若2i + 1 < n,左孩子序号:2i + 1,2i +1 >= n否则无左孩子
3.若2i + 2 < n,右孩子序号:2i + 2,2i + 2 >= n否则无右孩子
4.题目
1. 某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树中的叶子结点数为(B)
A 不存在这样的二叉树
B 200
C 198
D 199
由性质3:n0 = n2 + 1 = 199 + 1 = 200
2.在具有 2n 个结点的完全二叉树中,叶子结点个数为(A)
A n
B n+1
C n-1
D n/2
度为0 —> n0个,度为1 —> n1个,度为2 —> n2个
因为n0 + n1 + n2 = 2N,n0 = n2 + 1
则2n0 + n1 - 1 = 2N
因为完全二叉树的n1的数量是0 or 1,为了保证等号左侧与等号右侧统一成偶数,此时,n1 = 0
所以n0 = N
3.一棵完全二叉树的结点数位为531个,那么这棵树的高度为(B)
A 11
B 10
C 8
D 12

5.二叉树的存储结构
二叉树一般有两个结构,一种是顺序结构,一种是链式结构。
(1)顺序结构
顺序结构存储就是使用数组来存储,一般使用数字只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储。
二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树。

(2)链式存储
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来表示元素的逻辑关系。通常的方法是链表中每个结点右三个域组成,数据域和左右指针域,左右指针分别表示用来给出结点左孩子和右孩子所在的链节点的存储地址。
三、二叉树的顺序结构及实现
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(完全二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
1.堆的概念及结构
如果有一个关键码的集合K={ ,
,
,……,
},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:
且
(
且
)i = 0 , 1 , 2……,则称为小堆(大堆)。将根结点最大的堆交租最大堆或大根堆,根结点最小的堆叫做最小堆会小根堆。
2.堆的性质
(1)堆中某个结点的值总是不大于或不小于其父亲结点的值
(2)堆总是一颗完全二叉树

3.堆的实现
<1>堆的创建图示
通过插入数据和向上调整算法实现,后面会有解释

<2>Heap.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int HPDateType;
typedef struct Heap
{HPDateType* a;int size;int capacity;
}HP;//交换函数
void swap(HPDateType* p1, HPDateType* p2);//初始化和销毁
void HPInit(HP* php);
void HPDestory(HP* php);//向上调整算法
void AdjustUp(HPDateType* a, int child);
//插入数据
void HPPush(HP* php, HPDateType x);void AdjustDown(HPDateType* a, int n, int parent);
//删除数据
void HPPop(HP* php);
//返回堆顶的元素
HPDateType HPTop(HP* php);
//判空
bool HPEmpty(HP* php);<3>Heap.c
(1)交换函数
//交换函数
void swap(HPDateType* p1, HPDateType* p2)
{HPDateType tmp = *p1;*p1 = *p2;*p2 = tmp;
}(2)初始化
void HPInit(HP* php)
{assert(php);php->a = NULL;php->capacity = php->size = 0;
}(3)销毁
void HPDestory(HP* php)
{assert(php);free(php);php->a = NULL;php->capacity = php->size = 0;
}(4)向上调整算法
//向上调整算法
void AdjustUp(HPDateType* a, int child)
{int parent = (child - 1) / 2;//堆的父子关系while (child > 0){if (a[child] < a[parent])//向上调整{swap(&a[child], &a[parent]);//交换位置child = parent;//最初的parent赋值给childparent = (child - 1) / 2;//重新规划parent}else{break;}}
}(5)插入数据(建堆)
堆的创建过程图示:
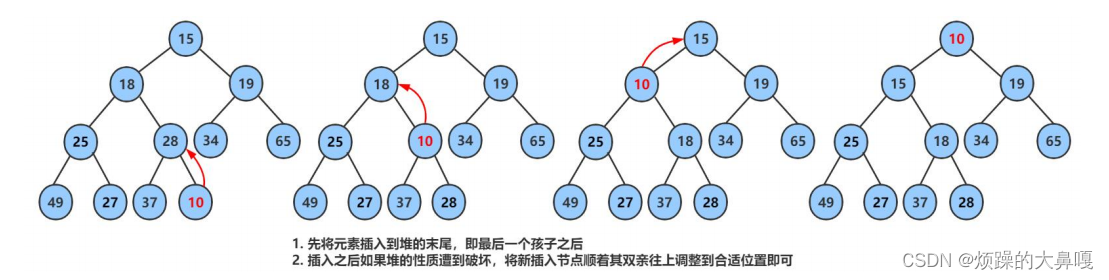
时间复杂度为:logN

//插入数据
void HPPush(HP* php, HPDateType x)
{assert(php);//空间不够if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDateType* tmp = (HPDateType*)realloc(php->a, newcapacity * sizeof(HPDateType));if (tmp == NULL){perror("realloc fail!");return;}php->a = tmp;php->capacity = newcapacity;}php->a[php->size] = x;//插在数组的结尾php->size++;AdjustUp(php->a, php->size - 1);//传的是下标,用来找父子关系
}(6)向下调整算法
我们通过从根结点开始的向下调整算法可以把它调整成一个小堆。向下调整算法的前提:左右子树必须是一堆,才能调整。

//向下调整算法(前提:左右字树是小堆/左右子树是大堆)
void AdjustDown(HPDateType* a,int n,int parent)
{//假设法:先假设左孩子小int child = parent * 2 + 1;//child >= n说明孩子已经不存在了,超出二叉树范围了(叶子)while (child < n) {//找出小的那个孩子if (a[child] > a[child + 1] && child +1 < n){++child;//让右孩子成为小的}if (a[child] < a[parent]){swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}(7)删除数据
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据交换,然后删除数组最后一个数据,在进行向下调整算法

//删除数据(堆顶的数据)
//不能挪动数据,覆盖删除堆顶数据—>关系错乱
//堆顶数据交换到最后一个数据,再删除最后一个数据,在进行向下调整算法
void HPPop(HP* php)
{assert(php);assert(php->size > 0);swap(&php->a[0], &php->a[php->size - 1]);php->size--;//先size--了,缩小数组大小//所以调用完AdjustDown()函数后,交换到最后一位的堆顶元素就已经被删除了AdjustDown(php->a, php->size, 0);}(8)返回栈顶元素
//返回堆顶的元素
HPDateType HPTop(HP* php)
{assert(php);assert(php->size > 0);return php->a[0];
}(9)判空
//判空
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}<4>test.c
void TestHeap1()
{int a[ ] = { 2,4,5,6,1,7,8,9 };HP hp;HPInit(&hp);for (size_t i = 0; i < sizeof(a) / sizeof(int); i++){HPPush(&hp, a[i]);}while (!HPEmpty(&hp)){printf("%d ", HPTop(&hp));HPPop(&hp);}
}
int main()
{TestHeap1();return 0;
}4.堆的应用
<1>堆排序
(1)建堆
升序:建大堆
降序:建小堆
(2)排序
● 向上调整建堆思想:
例如,我们想得到升序,先建好大堆,再将堆的最后一个元素与栈顶元素交换,此时数组的最后一个空间存储的就是集合中的最大元素(位置锁定了),然后对新的堆顶元素进行向下调整之后,栈顶元素就是集合中第二大的元素。再将栈顶元素与数组的倒数第二个位置进行交换,逐此往复。直到所有元素都锁定了。

向上调整建堆的时间复杂度: O(N*logN)

void swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void AdjustUp(int* a, int child)
{int parent = (child - 1) / 2;//堆的父子关系while (child > 0){if (a[child] < a[parent])//向上调整{swap(&a[child], &a[parent]);//交换位置child = parent;//最初的parent赋值给childparent = (child - 1) / 2;//重新规划parent}else{break;}}
}//堆排序
//->时间复杂度:O(N* logN)
//这里我们把数组当做完全二叉树
void HeapSort(int* a, int n)
{//向上调整建堆//降序,建小堆 (升序,建大堆)for (int i = 0; i < n; i++){AdjustUp(a, i);}int end = n - 1;while (end > 0){//把最大的数换到最后一位swap(&a[0], &a[end]);//在将第一个数向下调整,选出次大的数AdjustDown(a, end, 0);//最后一位数据被固定,数组的范围缩小--end;}
}void TestHeap3()
{int a[] = { 5,4,3,16,17,20 };HeapSort(a, sizeof(a) / sizeof(int));
}
int main()
{TestHeap3();return 0;
}● 向下调整建堆思想
以最后一个有子树的元素为根结点所形成的树开始建堆(向下调整算法),下来是以倒数第二个有子树的元素为根节点所形成的树建堆,直到以栈顶元素为根结点所形成的树建堆完成。

向下调整建堆的时间复杂度: O(N)

#include<stdio.h>
#include<stdlib.h>
void swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}void AdjustDown(int* a, int n,int parent)
{//建小堆int child = 2 * parent + 1;//先假设左孩子小while (child < n){if (a[child] > a[child + 1]){child++;}if (a[child] < a[parent]){swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}else{break;}}
}void HPSort(int* a, int n)
{//向下调整建堆(从最后一个有子树的元素开始向上建)->666 //数组最后一个元素的小标为n-1for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);}
}int main()
{int a[] = { 5,6,2,3,7,8,9,1,4 };int n = sizeof(a) / sizeof(a[0]);HPSort(a, n);for (int i = 0; i < n; i++){printf("%d ",a[i]);}return 0;
}<2>Top—K问题
即求数据集合中前K个最大的元素或最小的元素,一般情况下数据量都比较大。
对于Top—K问题,能想到的最简单直接的方式就是排序
void TestHeap2()
{int a[] = { 27,15,19,18,28,34,65,49,25,37 };HP hp;HPInit(&hp);for (size_t i = 0; i < sizeof(a) / sizeof(int); i++){HPPush(&hp, a[i]);}//找出最小的前k个int k = 0;scanf("%d", &k);while (k--){printf("%d ", HPTop(&hp));HPPop(&hp);}printf("\n");
}int main()
{TestHeap2();return 0;
}但是:如果数据量非常大,排序就不太可取了(可能数据都不能快速全部加载到内存中)。
最佳的方式就是用堆来解决。
(1)用数据集合中前K个元素来建堆——>O(K)
求前K个最大的元素,则建小堆
求前K个最小的元素,则建大堆
(2)用剩余的N-K个元素一次与堆顶元素进行比较,不满足则替换堆顶元素——>O((N-K)*logN)
将剩余的N-K个元素一次与对顶元素比较完后,堆中剩余的K歌元素就是所求的前K个最小的或最大的元素。
合计时间复杂度是O(N)
#include<stdio.h>
#include<stdlib.h>
#include<time.h>void swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}void AdjustDown(int* a, int n,int parent)
{//建小堆int child = 2 * parent + 1;//先假设左孩子小while (child < n){if (a[child] > a[child + 1]){child++;}if (a[child] < a[parent]){swap(&a[child], &a[parent]);parent = child;child = 2 * parent + 1;}else{break;}}
}void PrintTopK(int* a, int n, int k)
{// 1. 建堆--用a中前k个元素建堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, n, i);//小堆}// 2. 将剩余n-k个元素依次与堆顶元素交换,不满则则替换for (int j = k; j < n-1; j++){if (a[0] < a[j]){a[0] = a[j];AdjustDown(a, n, 0);}}for (int s = 0; s < k - 1; s++){printf("%d ", a[s]);}printf("\n");
}
void TestTopk()
{int n = 10000;int* a = (int*)malloc(sizeof(int) * n);srand(time(0));for (size_t i = 0; i < n; ++i){a[i] = rand() % 1000000;}a[5] = 1000000 + 1;a[1231] = 1000000 + 2;a[531] = 1000000 + 3;a[5121] = 1000000 + 4;a[115] = 1000000 + 5;a[2335] = 1000000 + 6;a[9999] = 1000000 + 7;a[76] = 1000000 + 8;a[423] = 1000000 + 9;a[3144] = 1000000 + 10;printf("最大的前k个数\n");int k;scanf("%d", &k);PrintTopK(a, n, k);
}
int main()
{TestTopk();return 0;
}另一种写法,在文件中生成:
void CreateNDate()
{// 造数据int n = 10000;srand(time(0));const char* file = "data.txt";FILE* fin = fopen(file, "w");if (fin == NULL){perror("fopen error");return;}for (size_t i = 0; i < n; ++i){int x = rand() % 1000000;fprintf(fin, "%d\n", x);}fclose(fin);
}void HeapTest()
{int k;printf("请输入K:");scanf("%d", &k);int* a = (int*)malloc(sizeof(int) * k);if (a == NULL){perror("malloc error");return;}//打开文件,读前k个数const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen error");return;}for (int i = 0; i < k; i++){fscanf(fout,"%d", &a[i]);}//建有k个数的小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(a, k, i);}//读取剩下的N-K个int x = 0;while (fscanf(fout,"%d", &x) > 0){if (a[0] < x){a[0] = x;AdjustDown(a, k, 0);}}//打印for (int i = 0; i < k; i++){printf("%d ", a[i]);}printf("\n");
}int main()
{CreateNDate();HeapTest();return 0;
}相关文章:
二叉树—堆(C语言实现)
一、树的概念及结构 1.树的概念 树是一种非线性的数据结构,它是有n(n > 0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一颗倒挂的树,也就是说它是根朝上,而叶朝下。 ● 有一个特殊的结点…...

儿童有声挂图的芯片AD156—云信通讯
有声挂图是一种结合了图像和声音的媒体形式,用户可以触发图像上的声音,从而获得与图像内容相关的音频信息。这种融合了视觉和听觉的交互方式,既满足了人们对美感和观感的需求,又提高了信息传递的效果和效率。 有声挂图作为孩子的…...
:2024.04.25-2024.05.01)
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.04.25-2024.05.01
文章目录~ 1.Soft Prompt Generation for Domain Generalization2.Modeling Caption Diversity in Contrastive Vision-Language Pretraining3.Q-GroundCAM: Quantifying Grounding in Vision Language Models via GradCAM4.HELPER-X: A Unified Instructable Embodied Agent t…...

gdb调试常见指令
quit:退出gdb list/l:l 文件名:行号/函数名,l 行号/函数名 b:b 文件名:行号/函数名,b 行号/函数名 info/i: info b d:d 断电编号 disable/enable 断电编号:使能(关闭࿰…...

二进制安装mysql8.1
MySQL的安装各个版本步骤几乎一致,本文以安装8.1为例 创建用户及安装需要的依赖包 创建用户及用户组 groupadd mysql useradd -g mysql -s /sbin/nologin mysql 安装依赖包 apt install libncurses5 libncursesw5 libaio1 numactl wget -y 获取二进制包 可以…...

前端工程化工具系列(六)—— VS Code(v1.89.1):强大的代码编辑器
VS Code(Visual Studio Code)是一款由微软开发的强大且轻量级的代码编辑器,支持多种编程语言,并提供了丰富的扩展插件生态系统。 这里主要介绍如何使用配置 ESLint、Stylelint 等插件来提升开发效率。 1 自动格式化代码 最终要…...
重学java 59.Properties属性集集合嵌套集合下总结
不要咀嚼小小悲观,而忘掉整个世界 —— 24.6.3 一、Properties集合(属性集) 1.概述 Properties 继承 于HashTable 2.特点 a、key唯一,value可重复 b、无序 c、无索引 d、线程安全 e、不能存null键,null值 f、Propertie…...
Kafka系列之高频面试题
基础 简介 特点: 高吞吐、低延迟:kafka每秒可以处理几十万条消息,延迟最低只有几毫秒,每个Topic可以分多个Partition,Consumer Group对Partition进行Consumer操作可扩展性:Kafka集群支持热扩展持久性、可…...

SIP通话分析
20240603 - 引言 分析SIP协议的时候,发现了几个问题。虽然说,从整体上来看这个SIP的通话流程也没麻烦,实际上从RFC的概述部分就已经基本上就已经了解了全貌。但在实际的场景中,很多字段起到的作用就不太一样了。 虽然一开始的时…...
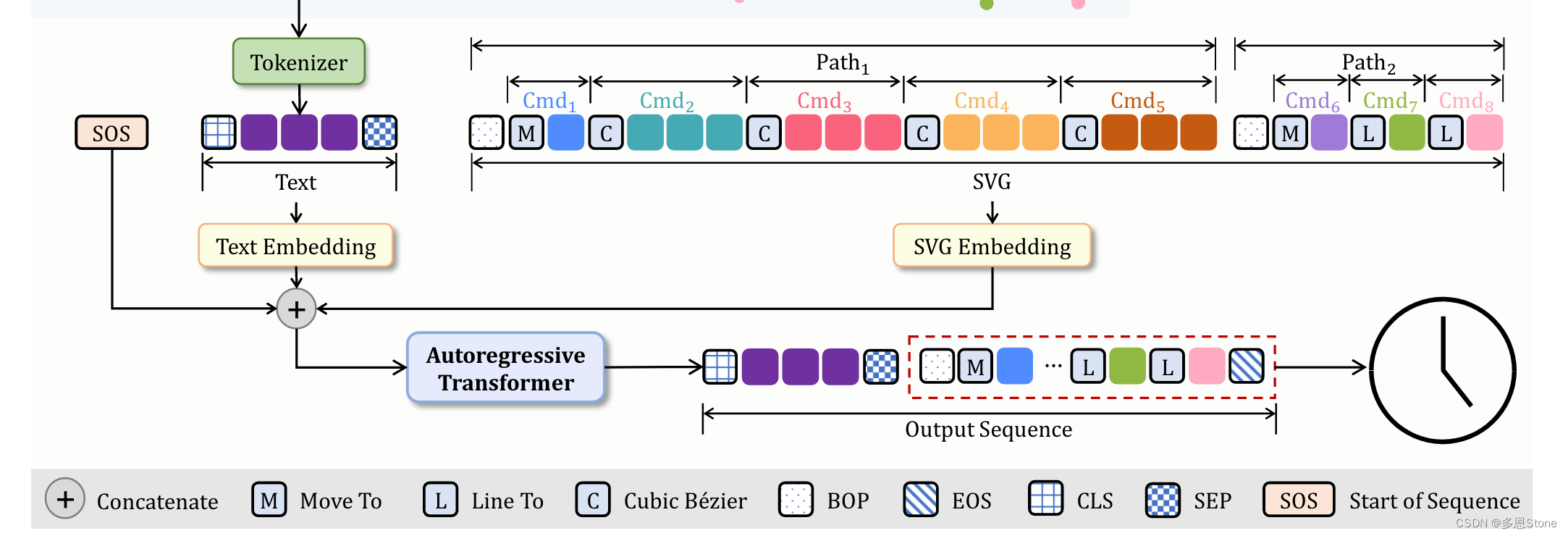
【SVG 生成系列论文(九)】如何通过文本生成 svg logo?IconShop 模型推理代码详解
SVG 生成系列论文(一) 和 SVG 生成系列论文(二) 分别介绍了 StarVector 的大致背景和详细的模型细节。SVG 生成系列论文(三)和 SVG 生成系列论文(四)则分别介绍实验、数据集和数据增…...

有哪些兼职软件一天能赚几十元?盘点十个能长期做下去的挣钱软件
在当今这个信息泛滥的时代,众人纷纷寻求迅速致富的捷径。许多人在从事兼职或副业时,并不期望取得巨大的成就,只要每天能额外收入数十元,便已心满意足。 今天,我将带领大家深入探究,揭开那些隐藏在日常生活…...

ubuntu 22.04配置静态ip
ubuntu 22.04配置静态ip vim /etc/netplan/01-network-manager-all.yaml# Let NetworkManager manage all devices on this system network:renderer: NetworkManagerethernets:enp4s0f1:addresses:- 192.168.1.18/24dhcp4: falseroutes:- to: defaultvia: 192.168.1.1nameser…...

C++ 使用 nlohmann/json 库
C常用 json 库有: Jsoncpp boost ison Qt Json (不推荐使用) nlohman::json (推荐使用) 其中Qt中json解析的相关类只在qt中有用,为了避免以后不用qt无法解析json,建议使用nlohmann/json,适用于任何C框架。 1. 简介 nlohmann是一…...

【Java面试】六、Spring框架相关
文章目录 1、单例Bean不是线程安全的2、AOP3、Spring中事务的实现4、Spring事务失效的场景4.1 情况一:异常被捕获4.2 情况二:抛出检查异常4.3 注解加在非public方法上 5、Bean的生命周期6、Bean的循环引用7、Bean循环引用的解决:Spring三级缓…...

【GIC400】——PLIC,NVIC 和 GIC 中断对比
文章目录 PLIC,NVIC 和 GIC 中断对比中断向量表PLIC中断向量表中断使能中断服务函数NVIC中断向量表中断使能中断服务函数GIC中断向量表系列文章 【ARMv7-A】——异常与中断 【ARMv7-A】——异常中断处理概述...
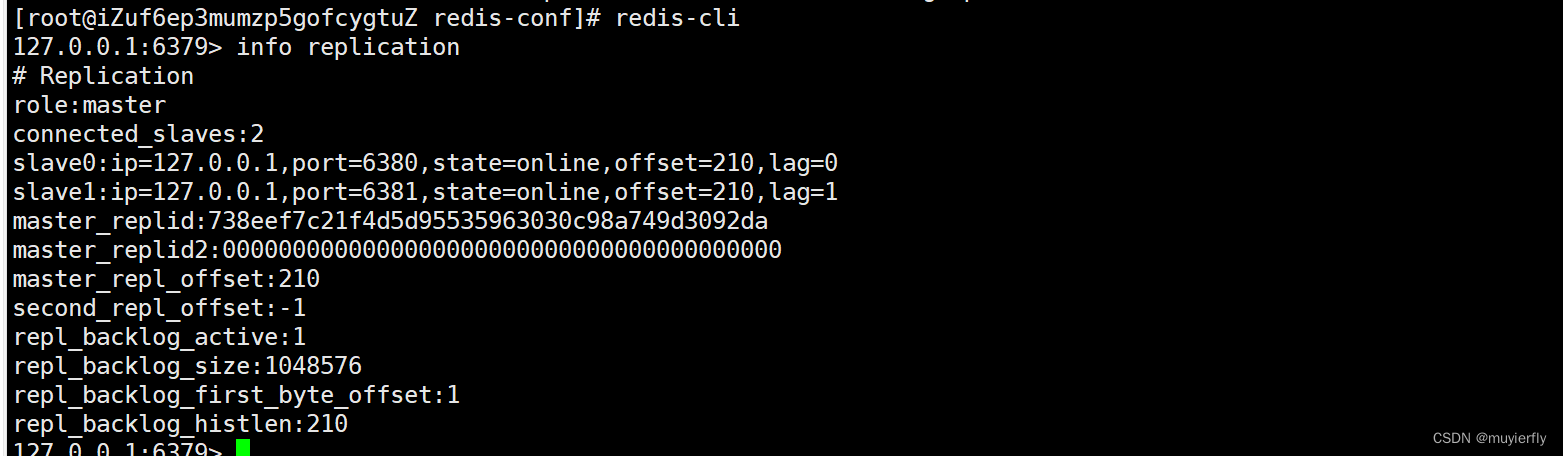
17.Redis之主从复制
1.主从复制是怎么回事? 分布式系统, 涉及到一个非常关键的问题: 单点问题 单点问题:如果某个服务器程序, 只有一个节点(只搞一个物理服务器, 来部署这个服务器程序) 1.可用性问题,如果这个机器挂了,意味着服务就中断了~ 2.性能/支持的并发量也是比较有限…...

计算机类专业应该怎么选学校和方向?优先选这些!
👆点击关注 获取更多编程干货👆 高考季临近,不少有意向报考计算机专业的同学在为院校和细分专业的选择而苦恼,以下是一些建议,希望能帮到大家! 01 选校建议 在选择计算机科学(CS)…...

Amazon云计算AWS(二)
目录 三、简单存储服务S3(一)S3的基本概念和操作(二)S3的数据一致性模型(三)S3的安全措施 四、非关系型数据库服务SimpleDB和DynamoDB(一)非关系型数据库与传统关系数据库的比较&…...

实战
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 实战一:大乐透号码生成器 使用Random模块模拟大乐透号码生成器。选号规则为:前区在1~35的范围内随机产生不重复的…...

【C++】vector模拟实现
🔥个人主页: Forcible Bug Maker 🔥专栏: STL || C 目录 前言🔥vector需要实现的接口函数🔥vector的模拟实现swap交换默认成员函数迭代器接口reserve和resizesize和capacityoperator[ ]下标获取push_back和…...

抖音视频批量下载开源工具终极指南:从零到精通的完整教程
抖音视频批量下载开源工具终极指南:从零到精通的完整教程 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...
用C++实现信奥题 P6862 [RC-03] 随机树生成器)
打卡信奥刷题(3062)用C++实现信奥题 P6862 [RC-03] 随机树生成器
P6862 [RC-03] 随机树生成器 题目描述 小 R 有一个随机树生成器,其工作原理如下: 输入 nnn,则对于每个 1<i≤n1<i\le n1<i≤n,随机选择一个 [1,i)[1,i)[1,i) 中的节点作为其父亲。返回这棵树。 给定 n,kn,kn,k࿰…...
)
StructBERT中文相似度模型部署:支持多模型并行服务(BERT/RoBERTa/StructBERT)
StructBERT中文相似度模型部署:支持多模型并行服务(BERT/RoBERTa/StructBERT) 想快速搭建一个能理解中文句子相似度的AI服务吗?比如判断“今天天气真好”和“阳光明媚的一天”是不是一个意思,或者自动给用户提问匹配最…...

NEURAL MASK 时尚设计应用:AI辅助生成服装图案与面料效果
NEURAL MASK 时尚设计应用:AI辅助生成服装图案与面料效果 最近和几位做服装设计的朋友聊天,他们都在感慨,找灵感、画草图、做面料效果图,一套流程下来,时间成本太高了。有时候一个系列要出几十个图案,光是…...
)
Silvaco TCAD实战:从零搭建nmos器件全流程(附Athena操作截图)
Silvaco TCAD实战:从零搭建NMOS器件全流程解析 在半导体工艺仿真领域,掌握TCAD工具就像获得了一把打开微观世界的钥匙。作为行业标准的Silvaco TCAD套件,其Athena模块专门针对工艺仿真而设计,能够精确模拟从硅片清洗到最终器件成型…...

OpenClaw多任务队列:Qwen3.5-9B并行处理图片批分析
OpenClaw多任务队列:Qwen3.5-9B并行处理图片批分析 1. 为什么需要批量图片分析 上周我接到一个朋友的需求:他经营一家小型电商店铺,每天需要处理上百张商品截图,包括提取商品特征、检查图片合规性、生成简短的描述文案。手动操作…...

让Kindle电子书封面重获新生:开源工具Fix-Kindle-Ebook-Cover使用指南
让Kindle电子书封面重获新生:开源工具Fix-Kindle-Ebook-Cover使用指南 【免费下载链接】Fix-Kindle-Ebook-Cover A tool to fix damaged cover of Kindle ebook. 项目地址: https://gitcode.com/gh_mirrors/fi/Fix-Kindle-Ebook-Cover 深夜的阅读时光本该是惬…...
,告别AI胡说八道,收藏这一篇就够了!)
零基础搞懂Harness Engineering(超详细保姆级教程),告别AI胡说八道,收藏这一篇就够了!
2026年第一季度,大模型应用层最具统治力的热词,绝对是「Harness」。 今年三月,LangChain 发布了一篇题为《The Anatomy of an Agent Harness》的实证文章,彻底点燃了所有人的焦虑与狂热。他们在这份报告里引用了一个实验数据对比…...

5分钟彻底解决Windows效率难题:PowerToys中文版让系统增强零门槛上手
5分钟彻底解决Windows效率难题:PowerToys中文版让系统增强零门槛上手 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾因Windows系统功…...

socket.io-redis-adapter高级特性:服务器端事件广播与响应处理
socket.io-redis-adapter高级特性:服务器端事件广播与响应处理 【免费下载链接】socket.io-redis-adapter Adapter to enable broadcasting of events to multiple separate socket.io server nodes. 项目地址: https://gitcode.com/gh_mirrors/so/socket.io-redi…...