SpringBoot 集成 elasticsearch 7.x和对应版本不一致异常信息处理
开源框架springboot框架中集成es。使用
org.springframework.data.elasticsearch下的依赖,实现对elasticsearch的CURD,非常方便,但是springboot和elasticsearch版本对应很严格,对应版本不统一启动会报错。
文章目录
- 开源框架
- Elasticsearch 7.x安装
- Elasticsearch和springboot版本对应
- 配置elasticSearch
- 测试类
- springframework实现对象操作es
- es实体对象
- es接口
- AbstractResultMapper
- Mapper
- Service
- ServiceImpl
开源框架
开源框架

Elasticsearch 7.x安装
Elasticsearch 7.x 安装步骤
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
注意:
springboot集成的elasticSearch的版本可能和
我们自己使用的不一致,可能会导致项目报错,需要手动把版本
改成和我们使用的一致
版本不一致异常信息:
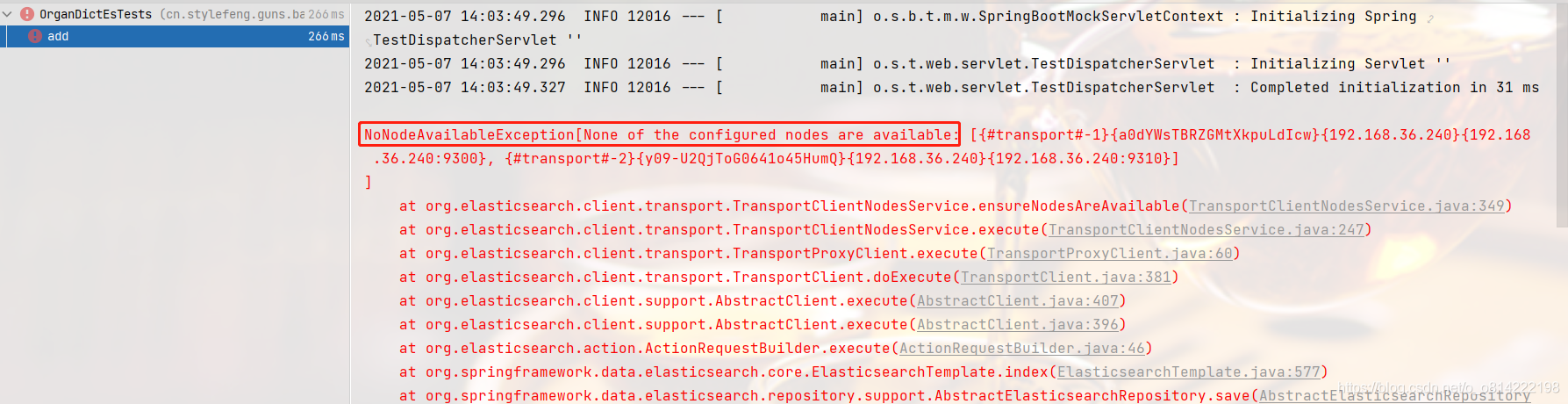
Elasticsearch和springboot版本对应
Elasticsearch和springboot版本对应
springboot 2.1.6 对应 Elasticsearch 6.3.2
springboot 2.2.5 对应 Elasticsearch 7.6.0
springboot 2.2.6 对应 Elasticsearch 7.7.0
配置elasticSearch
@Configuration
public class ESClient {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1",9200,"http")));return client;}
}测试类
@SpringBootTest
class EstestApplicationTests {@Autowired@Qualifier("restHighLevelClient")private RestHighLevelClient client;//测试创建索引库@Testvoid createIndex() throws IOException {//创建请求CreateIndexRequest request = new CreateIndexRequest("test1");//执行请求CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);System.out.println(response.toString());//org.elasticsearch.client.indices.CreateIndexResponse@6a5dc7e}//查看索引库是否存在 true存在,false不存在@Testvoid existsIndex() throws IOException {//创建请求GetIndexRequest request = new GetIndexRequest("test1");boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);System.out.println(exists);}//删除索引库@Testvoid deleteIndex() throws IOException {DeleteIndexRequest request = new DeleteIndexRequest("test1");AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);//删除成功返回true,失败返回falseSystem.out.println(delete.isAcknowledged());}//文档操作================================================================================//添加文档@Testvoid createDocument() throws IOException {//创建添加数据User user = new User("张三",23);//声明要保存到那个索引库IndexRequest request = new IndexRequest("test1");request.id("1").timeout("1s");//给请求放入数据request.source(JSON.toJSONString(user), XContentType.JSON);//执行请求IndexResponse resp = client.index(request, RequestOptions.DEFAULT);System.out.println(resp);System.out.println(resp.status());//CREATED}//修改文档@Testvoid updateDocument() throws IOException {//声明修改数据//User user = new User("李四",20);User user = new User();user.setName("王五");//声明索引库UpdateRequest request = new UpdateRequest("test1","1");//设置修改的文档id和请求超时时间request.id("1").timeout("1s");request.doc(JSON.toJSONString(user),XContentType.JSON);//执行修改 修改的时候,如果对象中某个字段没有给值,那么也会修改成默认值UpdateResponse update = client.update(request,RequestOptions.DEFAULT);System.out.println(update);System.out.println(update.status());//ok}//查看文档是否存在@Testvoid existsDocument() throws IOException {GetRequest request = new GetRequest("test1","1");boolean exists = client.exists(request, RequestOptions.DEFAULT);//存在返回true,不存在返回falseSystem.out.println(exists);}//删除文档@Testvoid deleteDocument() throws IOException {DeleteRequest request = new DeleteRequest("test1","1");DeleteResponse delete = client.delete(request, RequestOptions.DEFAULT);System.out.println(delete);System.out.println(delete.status());//ok}//根据id获取文档@Testvoid getDocument() throws IOException {GetRequest request = new GetRequest("test1","1");GetResponse resp = client.get(request, RequestOptions.DEFAULT);System.out.println(resp);//获取文档内容的字符串,没有数据为nullSystem.out.println(resp.getSourceAsString());}//批量操作,修改和删除操作只是改变request即可@Testvoid bulkadd() throws IOException {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");List<User> list = new ArrayList<>();list.add(new User("chen1",20));list.add(new User("chen2",20));list.add(new User("chen3",20));list.add(new User("chen4",20));list.add(new User("chen5",20));list.add(new User("chen6",20));list.add(new User("chen7",20));list.add(new User("chen8",20));//注意:id要是重复,则会覆盖掉for (int i = 0; i < list.size(); i++) {bulkRequest.add(new IndexRequest("test1").id(""+(i+1)).source(JSON.toJSONString(list.get(i)),XContentType.JSON));}//执行BulkResponse bulk = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(bulk);System.out.println(bulk.status());}//条件查询文档@Testvoid searchDocument() throws IOException {//声明请求SearchRequest request = new SearchRequest("test1");//创建查询构造器对象SearchSourceBuilder builder = new SearchSourceBuilder();//精准查询条件构造器,还可以封装很多的构造器,都可以使用QueryBuilders这个类构建//QueryBuilders里面封装了我们使用的所有查询筛选命令TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "chen1");//把查询条件构造器放入到查询构造器中builder.query(termQueryBuilder);//把条件构造器放入到请求中request.source(builder);//执行查询SearchResponse search = client.search(request, RequestOptions.DEFAULT);//这个查询就和我们使用命令返回的结果是一致的System.out.println(JSON.toJSONString(search.getHits().getHits()));for (SearchHit hit : search.getHits().getHits()) {//遍历获取到的hits,让每一个hit封装为map形式System.out.println(hit.getSourceAsMap());}}
}
springframework实现对象操作es
es实体对象
org.springframework.data.annotation.Id;
org.springframework.data.elasticsearch.annotations.Document;
org.springframework.data.elasticsearch.annotations.Field;
org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "bookinfosearch", type = "bookinfo")
public class BookInfoSearch implements Serializable {private static final long serialVersionUID = 1L;// 必须指定一个id,@Idprivate String id;// 这里配置了分词器,字段类型,可以不配置,默认也可// 名称@Field(type = FieldType.Text, analyzer = "ik_max_word")private String name;// 简称@Field(type = FieldType.Text, analyzer = "ik_max_word")private String bookName;//书本版本号private BigDecimal currentVersion;//书本首字母@Field(type = FieldType.Keyword)private String initials;//操作类型add update delete@Field(type = FieldType.Keyword)private String type;//书本分类信息的聚合体private List<String> tagJson;//分类Id@Field(type = FieldType.Keyword)private List<String> tagIds; //集合 1,2,3//分类名称@Field(type = FieldType.Keyword)private List<String> tagNames;//属性集合@Field(type = FieldType.Text, analyzer = "ik_smart")private List<String> attributes;//创建时间private Date createTime;//更新时间private Date updateTime;public String getId() {return id;}public void setId(String id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public BigDecimal getCurrentVersion() {return currentVersion;}public void setCurrentVersion(BigDecimal currentVersion) {this.currentVersion = currentVersion;}public String getInitials() {return initials;}public void setInitials(String initials) {this.initials = initials;}public String getType() {return type;}public void setType(String type) {this.type = type;}public List<String> getTagIds() {return tagIds;}public void setTagIds(List<String> tagIds) {this.tagIds = tagIds;}public List<String> getTagNames() {return tagNames;}public void setTagNames(List<String> tagNames) {this.tagNames = tagNames;}public List<String> getAttributes() {return attributes;}public void setAttributes(List<String> attributes) {this.attributes = attributes;}public Date getCreateTime() {return createTime;}public void setCreateTime(Date createTime) {this.createTime = createTime;}public Date getUpdateTime() {return updateTime;}public void setUpdateTime(Date updateTime) {this.updateTime = updateTime;}
}es接口
org.springframework.data.repository.CrudRepository
public interface KgInfoSearchMapper extends CrudRepository<KgInfoSearch, String> {
}
AbstractResultMapper
类抽象结果映射器
org.springframework.data.elasticsearch.core
java.lang.Object
org.springframework.data.elasticsearch.core.AbstractResultMapper
所有已实现的接口:
GetResultMapper,MultiGetResultMapper,ResultMapper,SearchResultMapper
构造函数和描述
AbstractResultMapper(EntityMapper entityMapper)
全部方法
EntityMapper getEntityMapper()
<T> T mapEntity(String source, Class<T> clazz)


public abstract class AbstractResultMapper implements ResultsMapper {private EntityMapper entityMapper;public AbstractResultMapper(EntityMapper entityMapper) {Assert.notNull(entityMapper, "EntityMapper must not be null!");this.entityMapper = entityMapper;}public <T> T mapEntity(String source, Class<T> clazz) {if (StringUtils.isEmpty(source)) {return null;} else {try {return this.entityMapper.mapToObject(source, clazz);} catch (IOException var4) {throw new ElasticsearchException("failed to map source [ " + source + "] to class " + clazz.getSimpleName(), var4);}}}public EntityMapper getEntityMapper() {return this.entityMapper;}
}
Mapper
org.springframework.data.elasticsearch
@Component
public class MyResultMapper extends AbstractResultMapper {private final MappingContext<? extends ElasticsearchPersistentEntity<?>, ElasticsearchPersistentProperty> mappingContext;public MyResultMapper() {this(new SimpleElasticsearchMappingContext());}public MyResultMapper(MappingContext<? extends ElasticsearchPersistentEntity<?>, ElasticsearchPersistentProperty> mappingContext) {super(new DefaultEntityMapper(mappingContext));Assert.notNull(mappingContext, "MappingContext must not be null!");this.mappingContext = mappingContext;}public MyResultMapper(EntityMapper entityMapper) {this(new SimpleElasticsearchMappingContext(), entityMapper);}public MyResultMapper(MappingContext<? extends ElasticsearchPersistentEntity<?>, ElasticsearchPersistentProperty> mappingContext,EntityMapper entityMapper) {super(entityMapper);Assert.notNull(mappingContext, "MappingContext must not be null!");this.mappingContext = mappingContext;}@Overridepublic <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {long totalHits = response.getHits().getTotalHits();float maxScore = response.getHits().getMaxScore();List<T> results = new ArrayList<>();for (SearchHit hit : response.getHits()) {if (hit != null) {T result = null;if (!StringUtils.isEmpty(hit.getSourceAsString())) {result = mapEntity(hit.getSourceAsString(), clazz);} else {result = mapEntity(hit.getFields().values(), clazz);}setPersistentEntityId(result, hit.getId(), clazz);setPersistentEntityVersion(result, hit.getVersion(), clazz);setPersistentEntityScore(result, hit.getScore(), clazz);populateScriptFields(result, hit);results.add(result);}}return new AggregatedPageImpl<T>(results, pageable, totalHits, response.getAggregations(), response.getScrollId(),maxScore);}private String concat(Text[] texts) {StringBuilder sb = new StringBuilder();for (Text text : texts) {sb.append(text.toString());}return sb.toString();}private <T> void populateScriptFields(T result, SearchHit hit) {if (hit.getFields() != null && !hit.getFields().isEmpty() && result != null) {for (java.lang.reflect.Field field : result.getClass().getDeclaredFields()) {ScriptedField scriptedField = field.getAnnotation(ScriptedField.class);if (scriptedField != null) {String name = scriptedField.name().isEmpty() ? field.getName() : scriptedField.name();DocumentField searchHitField = hit.getFields().get(name);if (searchHitField != null) {field.setAccessible(true);try {field.set(result, searchHitField.getValue());} catch (IllegalArgumentException e) {throw new ElasticsearchException("failed to set scripted field: " + name + " with value: " + searchHitField.getValue(), e);} catch (IllegalAccessException e) {throw new ElasticsearchException("failed to access scripted field: " + name, e);}}}}}for (HighlightField field : hit.getHighlightFields().values()) {try {PropertyUtils.setProperty(result, field.getName(), concat(field.fragments()));} catch (InvocationTargetException | IllegalAccessException | NoSuchMethodException e) {throw new ElasticsearchException("failed to set highlighted value for field: " + field.getName()+ " with value: " + Arrays.toString(field.getFragments()), e);}}}private <T> T mapEntity(Collection<DocumentField> values, Class<T> clazz) {return mapEntity(buildJSONFromFields(values), clazz);}private String buildJSONFromFields(Collection<DocumentField> values) {JsonFactory nodeFactory = new JsonFactory();try {ByteArrayOutputStream stream = new ByteArrayOutputStream();JsonGenerator generator = nodeFactory.createGenerator(stream, JsonEncoding.UTF8);generator.writeStartObject();for (DocumentField value : values) {if (value.getValues().size() > 1) {generator.writeArrayFieldStart(value.getName());for (Object val : value.getValues()) {generator.writeObject(val);}generator.writeEndArray();} else {generator.writeObjectField(value.getName(), value.getValue());}}generator.writeEndObject();generator.flush();return new String(stream.toByteArray(), Charset.forName("UTF-8"));} catch (IOException e) {return null;}}@Overridepublic <T> T mapResult(GetResponse response, Class<T> clazz) {T result = mapEntity(response.getSourceAsString(), clazz);if (result != null) {setPersistentEntityId(result, response.getId(), clazz);setPersistentEntityVersion(result, response.getVersion(), clazz);}return result;}@Overridepublic <T> LinkedList<T> mapResults(MultiGetResponse responses, Class<T> clazz) {LinkedList<T> list = new LinkedList<>();for (MultiGetItemResponse response : responses.getResponses()) {if (!response.isFailed() && response.getResponse().isExists()) {T result = mapEntity(response.getResponse().getSourceAsString(), clazz);setPersistentEntityId(result, response.getResponse().getId(), clazz);setPersistentEntityVersion(result, response.getResponse().getVersion(), clazz);list.add(result);}}return list;}private <T> void setPersistentEntityId(T result, String id, Class<T> clazz) {if (clazz.isAnnotationPresent(Document.class)) {ElasticsearchPersistentEntity<?> persistentEntity = mappingContext.getRequiredPersistentEntity(clazz);ElasticsearchPersistentProperty idProperty = persistentEntity.getIdProperty();// Only deal with String because ES generated Ids are strings !if (idProperty != null && idProperty.getType().isAssignableFrom(String.class)) {persistentEntity.getPropertyAccessor(result).setProperty(idProperty, id);}}}private <T> void setPersistentEntityVersion(T result, long version, Class<T> clazz) {if (clazz.isAnnotationPresent(Document.class)) {ElasticsearchPersistentEntity<?> persistentEntity = mappingContext.getPersistentEntity(clazz);ElasticsearchPersistentProperty versionProperty = persistentEntity.getVersionProperty();// Only deal with Long because ES versions are longs !if (versionProperty != null && versionProperty.getType().isAssignableFrom(Long.class)) {// check that a version was actually returned in the response, -1 would indicate that// a search didn't request the version ids in the response, which would be an issueAssert.isTrue(version != -1, "Version in response is -1");persistentEntity.getPropertyAccessor(result).setProperty(versionProperty, version);}}}private <T> void setPersistentEntityScore(T result, float score, Class<T> clazz) {if (clazz.isAnnotationPresent(Document.class)) {ElasticsearchPersistentEntity<?> entity = mappingContext.getRequiredPersistentEntity(clazz);if (!entity.hasScoreProperty()) {return;}entity.getPropertyAccessor(result) //.setProperty(entity.getScoreProperty(), score);}}
}
Service
/*** 查询* @param bookInfoSearchQueryParam 和实体对象字段一样* @return*/PageEsResult searchInfoByBookName(BookInfoSearchQueryParam bookInfoSearchQueryParam);
ServiceImpl
@Overridepublic PageEsResult searchInfoByBookName(BookInfoSearchQueryParam bookInfoSearchQueryParam) {BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();//1. 创建一个查询条件对象if (bookInfoSearchQueryParam != null && ObjectUtil.isNotEmpty(bookInfoSearchQueryParam.getKey())) {String key = bookInfoSearchQueryParam.getKey();key = QueryParser.escape(key);MultiMatchQueryBuilder matchQueryBuilder = QueryBuilders// 匹配多个字段 关键字 名称.multiMatchQuery(key, "name").analyzer("ik_max_word").field("name", 0.1f);queryBuilder.must(matchQueryBuilder);}if (bookInfoSearchQueryParam != null && ObjectUtil.isNotEmpty(bookInfoSearchQueryParam.getTagId())) {queryBuilder.must(QueryBuilders.termQuery("tagIds", bookInfoSearchQueryParam.getTagId()));}//2.创建聚合查询TermsAggregationBuilder agg = null;if (bookInfoSearchQueryParam != null && ObjectUtil.isNotEmpty(bookInfoSearchQueryParam.getAgg())) {agg = AggregationBuilders.terms(bookInfoSearchQueryParam.getAgg()).field(bookInfoSearchQueryParam.getAgg() + ".keyword").size(Integer.MAX_VALUE);;//keyword表示不使用分词进行聚合}String sortField = "";if (bookInfoSearchQueryParam != null && ObjectUtil.isNotEmpty(bookInfoSearchQueryParam.getSortField())) {sortField = bookInfoSearchQueryParam.getSortField();}String sortRule = "";if (bookInfoSearchQueryParam != null && ObjectUtil.isNotEmpty(bookInfoSearchQueryParam.getSortRule())) {sortRule = bookInfoSearchQueryParam.getSortRule();}NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();nativeSearchQueryBuilder.withTypes("bookinfo"); // 类型nativeSearchQueryBuilder.withIndices("bookinfosearch");//索引nativeSearchQueryBuilder.withQuery(queryBuilder); //添加查询条件if (agg != null) {nativeSearchQueryBuilder.addAggregation(agg);}if (bookInfoSearchQueryParam != null && ObjectUtil.isNotEmpty(bookInfoSearchQueryParam.getKey())) {HighlightBuilder.Field field = new HighlightBuilder.Field("name").preTags("<font style='color:red'>").postTags("</font>");HighlightBuilder.Field fieldAttributes = new HighlightBuilder.Field("attributes").preTags("<font style='color:red'>").postTags("</font>");field.fragmentSize(500);nativeSearchQueryBuilder.withHighlightFields(field, fieldAttributes);}nativeSearchQueryBuilder.withPageable(PageRequest.of(bookInfoSearchQueryParam.getPage(), bookInfoSearchQueryParam.getPageSize())); //符合查询条件的文档分页(不是聚合的分页)if (ObjectUtil.isNotEmpty(sortField) && ObjectUtil.isNotEmpty(sortRule)) {nativeSearchQueryBuilder.withSort(SortBuilders.fieldSort(sortField).order(SortOrder.valueOf(sortRule)));}NativeSearchQuery build = nativeSearchQueryBuilder.build();// 执行查询AggregatedPage<KgInfoSearch> testEntities = elasticsearchTemplate.queryForPage(build, BookInfoSearch.class, myResultMapper);// 取出聚合结果ggregations entitiesAggregations = testEntities.getAggregations();Terms terms = (Terms) entitiesAggregations.asMap().get(bookInfoSearchQueryParam.getAgg());// 遍历取出聚合字段列的值,与对应的数量if (terms != null && terms.getBuckets() != null && terms.getBuckets().size() > 0) {for (Terms.Bucket bucket : terms.getBuckets()) {String keyAsString = bucket.getKeyAsString(); // 聚合字段列的值long docCount = bucket.getDocCount();// 聚合字段对应的数量log.info("keyAsString={},value={}", keyAsString, docCount);list集合.add(keyAsString);}}//搜索数据保存搜索历史JSONObject jsonObject = new JSONObject();jsonObject.put("key", bookInfoSearchQueryParam.getKey());jsonObject.put("key", bookInfoSearchQueryParam.getKey());return 接收result;}
请求参数Param对象
在es实体对象基础上 添加搜索条件字段
private String sortField; //排序字段 时间:updateTime /字母:initialsprivate String sortRule; //sortRule 排序规则 - 顺序(ASC)/倒序(DESC)private boolean allQuery =false;//是否全部查询private String agg;//聚类查询字段名称private String sessionId;private int pageSize = 10;private int page = 0;
相关文章:
SpringBoot 集成 elasticsearch 7.x和对应版本不一致异常信息处理
开源框架springboot框架中集成es。使用org.springframework.data.elasticsearch下的依赖,实现对elasticsearch的CURD,非常方便,但是springboot和elasticsearch版本对应很严格,对应版本不统一启动会报错。 文章目录开源框架Elasticsearch 7.x安装Elastics…...
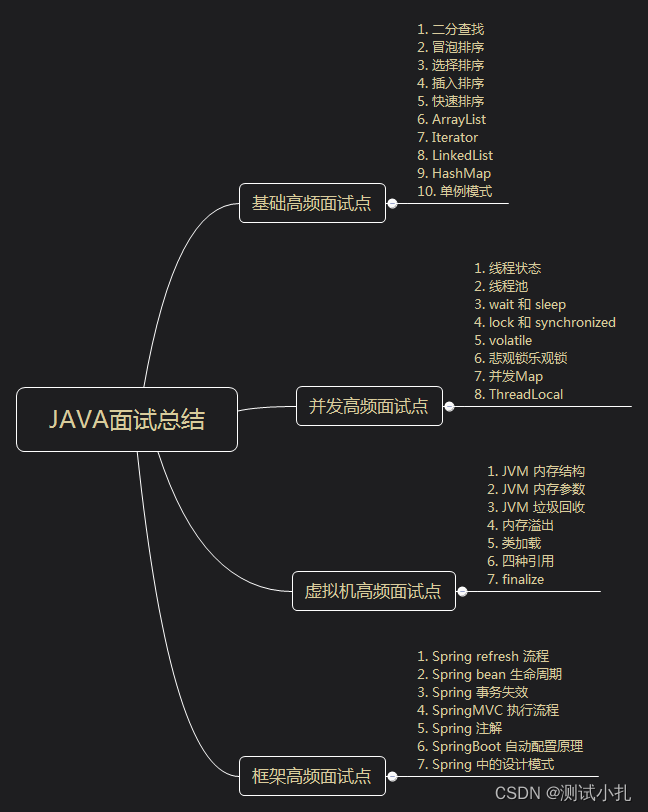
求职季必看系列:Java如何高效面试?
先看看这些java高频的面试重点吧 以下是初级程序员面试经常问到的问题: ■ Spring的三大特性是什么? ■ Spring IOC和AOP 你是如何理解并且使用的? ■ 说一下ElasticSearch为什么查询的快?是如何存储的?在项目中…...
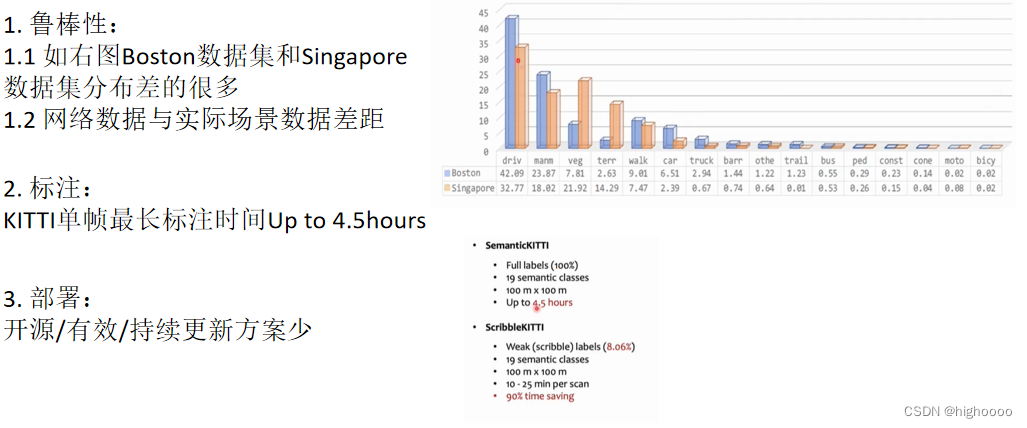
点云分割预研
文章目录激光雷达点云分割1.点云分割主流方案(模型角度)1.1 (a) 基于RGB-D图像1.2 (d) 基于点云1.3 (b) 基于投影图像1.4 (b) 基于投影图像 - SqueezeSeg/RangeNet1.4. 球映射2 点云分割主流方案(部署角度)3 点云分割常用指标4 点…...
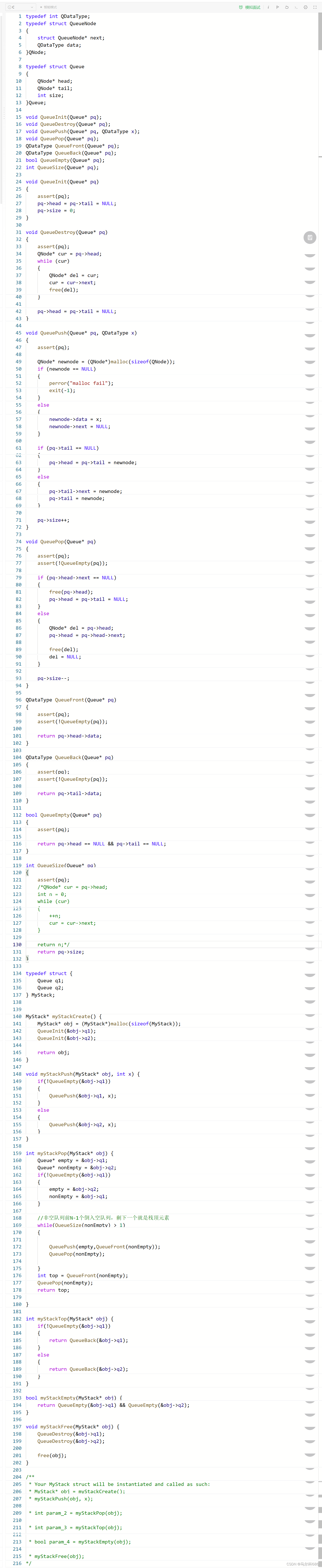
【数据结构】栈和队列 (栈 栈的概念结构 栈的实现 队列 队列的概念及结构 队列的实现 栈和队列面试题)
文章目录前言一、栈1.1 栈的概念结构1.2栈的实现二、队列2.1队列的概念及结构2.2队列的实现三、栈和队列面试题总结前言 一、栈 1.1 栈的概念结构 栈也是一种线性表,数据在逻辑上挨着存储。只允许在固定的一端进行插入和删除元素。进行插入和删除操作的一端叫栈顶…...

Moonbeam生态说|解读2023年Web3发展的前景和亮点
「Moonbeam生态说」是Moonbeam中文爱好者社区组织的社区AMA活动。该活动为媒体和已部署Moonriver或Moonbeam的项目方提供了在主流Moonbeam非官方中文社区内介绍自己的项目信息,包括:项目介绍、团队介绍、技术优势和行业发展等,帮助社区内的Mo…...
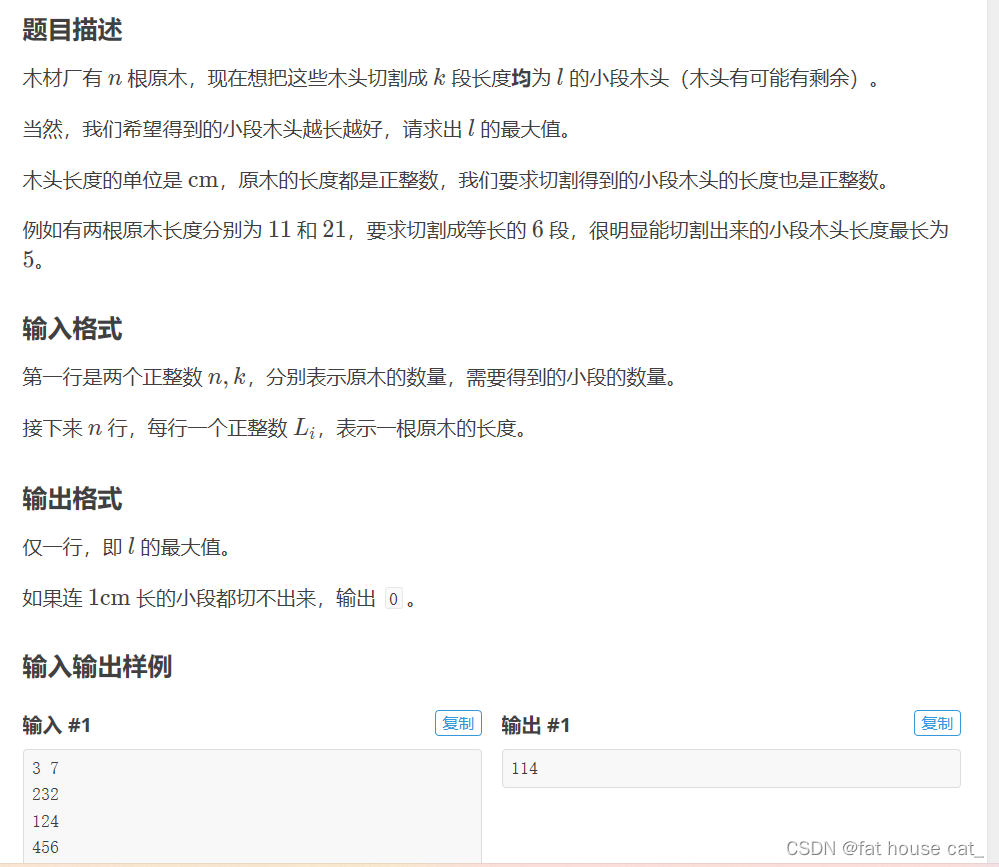
【刷题笔记】--二分-P2440 木材加工
题目: 思路: 先在所有树中找到最长的树,从 1 到 这个最长的树的长度 的所有数作为二分查找的值,让每棵树除这个值,表示可以切出几段出来,累加在一起得到s,s表示一共有几段。s与k比较…...

netstat 命令详解
文章目录简介命令格式常用选项常用命令查询进程所占用的端口号查看端口号的使用情况显示所有连接和监听端口并显示每个连接相关的进程ID显示UDP、TCP协议的连接的统计信息并显示每个连接相关的进程 ID显示所有已建立的连接显示每个进程的连接数显示每个IP地址的连接数显示每种类…...
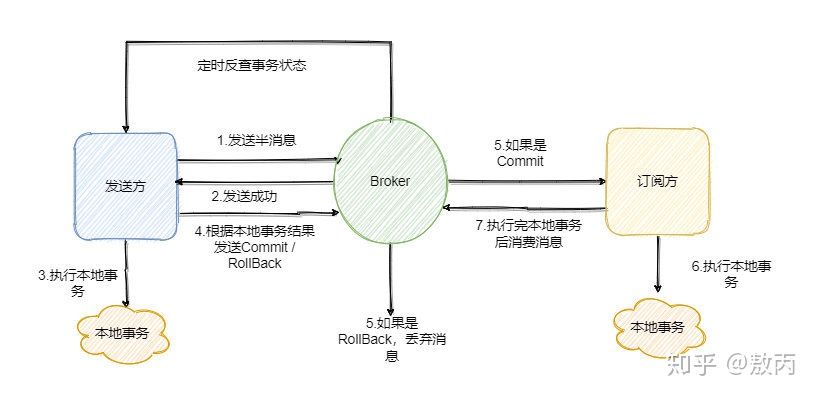
分布式 微服务
微服务学习 soa和微服务 业务系统实施服务化改造之后,原本共享的业务被拆分形成可复用的服务,可以在最大程度上避免共享业务的重复建设、资源连接瓶颈等问题。那么被拆分出来的服务是否也需要以业务功能为维度来进行拆分和独立部署,以降低业…...
Day912.多环境配置隔离 -SpringBoot与K8s云原生微服务实践
多环境配置隔离 Hi,我是阿昌,今天学习记录的是关于多环境配置隔离的内容。 多环境支持,是现在互联网开发研发和交付的主流基本需求。通过规范多环境配置可以规范开发流程,并同时提示项目的开发质量和效率等。 一个公司应该规范…...
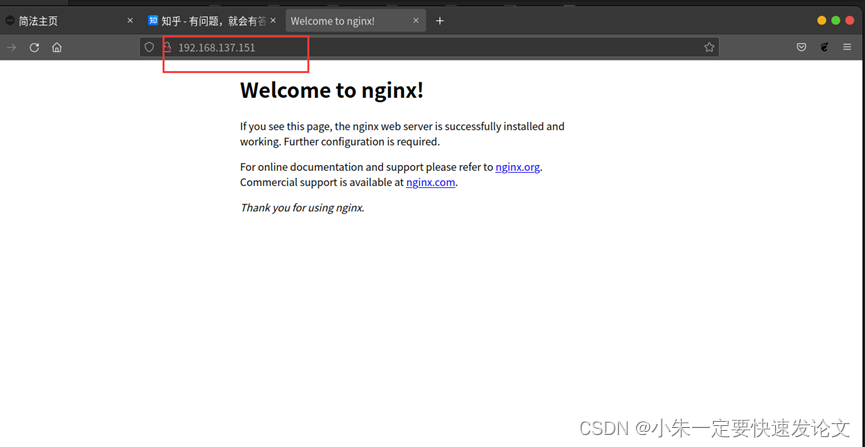
Imx6ull交叉编译nginx
Imx6ull交叉编译nginx 需要下好的包 Nginx(下载压缩包源码) nginx-rtmp-module(可以下载压缩包源码也可以 git clone https://github.com/arut/nginx-rtmp-module.git) pcre(下载源码) zlib(下载源码) openssl(下载源…...

阿里云短信验证
1.了解阿里云用户权限操作 需要通过个人账户获得 授权码(id、密码),再通过这些信息获得服务 阿里云网址 :https://www.aliyun.com/ 1.登陆阿里云服务器2.进入个人账号然后点击 AccessKey 管理3.创建用户组4.添加用户组权限&…...
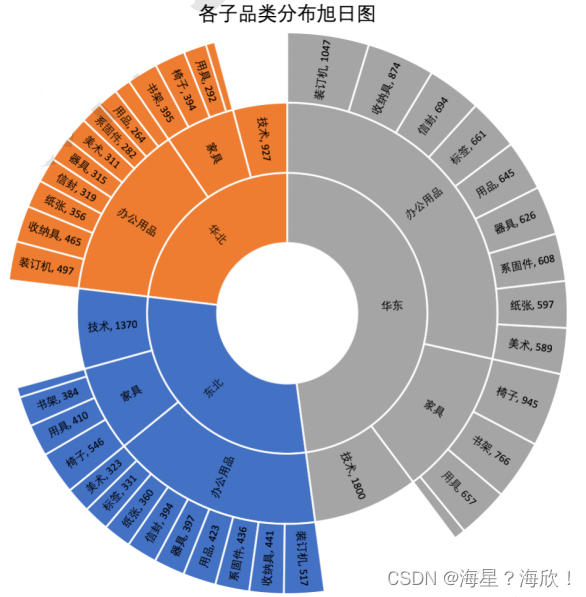
Excel常用可视化图表
目录柱状图与条形图折线图饼图漏斗图雷达图瀑布图及甘特图旭日图组合图excel图表:柱状数据条、excel热力图、mini图可视化工具的表现形式:看板、可视化大屏、驾驶舱 柱状图与条形图 条形图是柱状图的转置 类别: 单一柱状图:反映…...

虹科分享 | 网络流量监控 | 数据包丢失101
什么是数据包? 数据包是二进制数据的基本单位,在网络连接的设备之间编号和传输,无论是在本地还是通过互联网。一旦数据包到达其目的地,它就会与其他数据包一起按编号重新组合,回到最初传输的较大消息中。 数据包是我们…...

毕设常用模块之舵机介绍以及使用方法
舵机 舵机是一种位置伺服的驱动器,主要是由外壳、电路板、无核心马达、齿轮与位置检测器所构成。其工作原理是由接收机或者单片机发出信号给舵机,其内部有一个基准电路,产生周期为 20ms,宽度为 1.5ms 的基准信号,将获…...

残酷现实:大部分的App小程序,日活<100
残酷现实:99%的APP小程序,日活<100 日活跃用户数量(DAU)是一个核心指标 Daily Active Users 互联网的难度系数一路拉高 只有流过血的战士,才能意识到战场的残酷 趣讲大白话:赵本山小品台词, 残酷的现实已直逼我心理…...
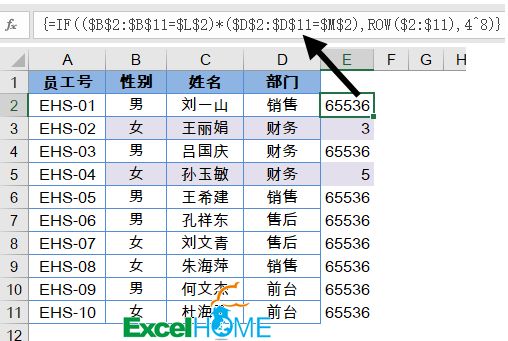
excel 一对多数据查询公式 经典用法
所谓一对多,就是符合某个指定条件的有多个结果,要把这些结果都提取出来。 下面咱们就说说一对多查询的典型用法,先看数据源: A~D列是一些员工信息,要根据F2单元格指定的学历,提取出所有“本科”的人员姓名…...
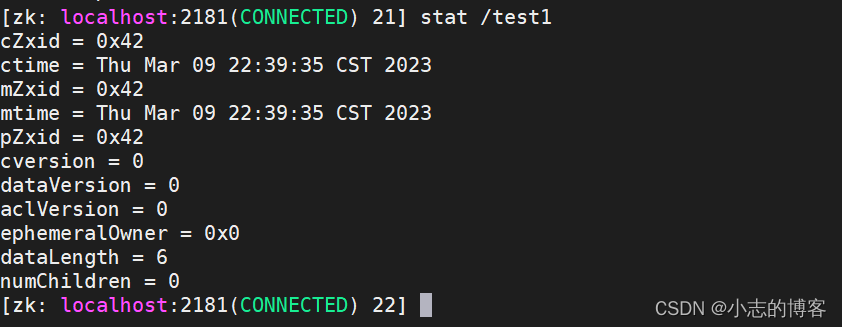
Zookeeper3.5.7版本——客户端命令行操作(节点删除与查看)
目录一、节点删除示例1.1、节点删除1.2、递归节点删除二、查看节点状态示例一、节点删除示例 1.1、节点删除 在客户端上创建 test 节点,并查看该节点 [zk: localhost:2181(CONNECTED) 5] create /test "123456"删除 test 节点,并查看该节点 […...

一句话设计模式6:享元模式
享元模式:局部单例模式。 文章目录 享元模式:局部单例模式。前言一、享元模式的作用二、如何实现享元模式总结前言 享元模式其实很简单,但是如果用好,确实可以达到减少内存,事半功倍的效果;适合 系统要创建大量相似对象,相同对象等; 一、享元模式的作用 1 享元模式可以解决对象…...
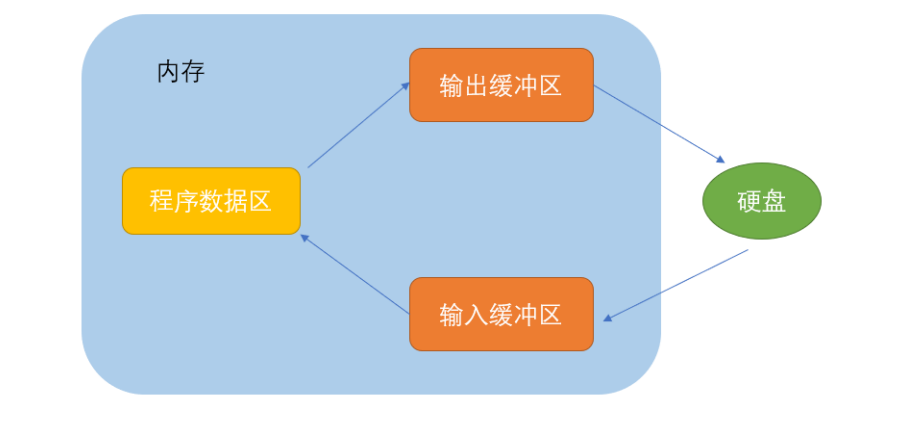
【C语言进阶】文本与二进制操作文件,优化通讯录。
前言:上篇文章,我们已经学习了有关本地磁盘文件的常用文件操作,已经能够对本地文件进行调用与读写。我们磁盘中还存在着一些内容用二进制存储的文件,这也就是我们今天将要讲解的内容。一、文本文件与二进制文件根据数据的组织形式…...
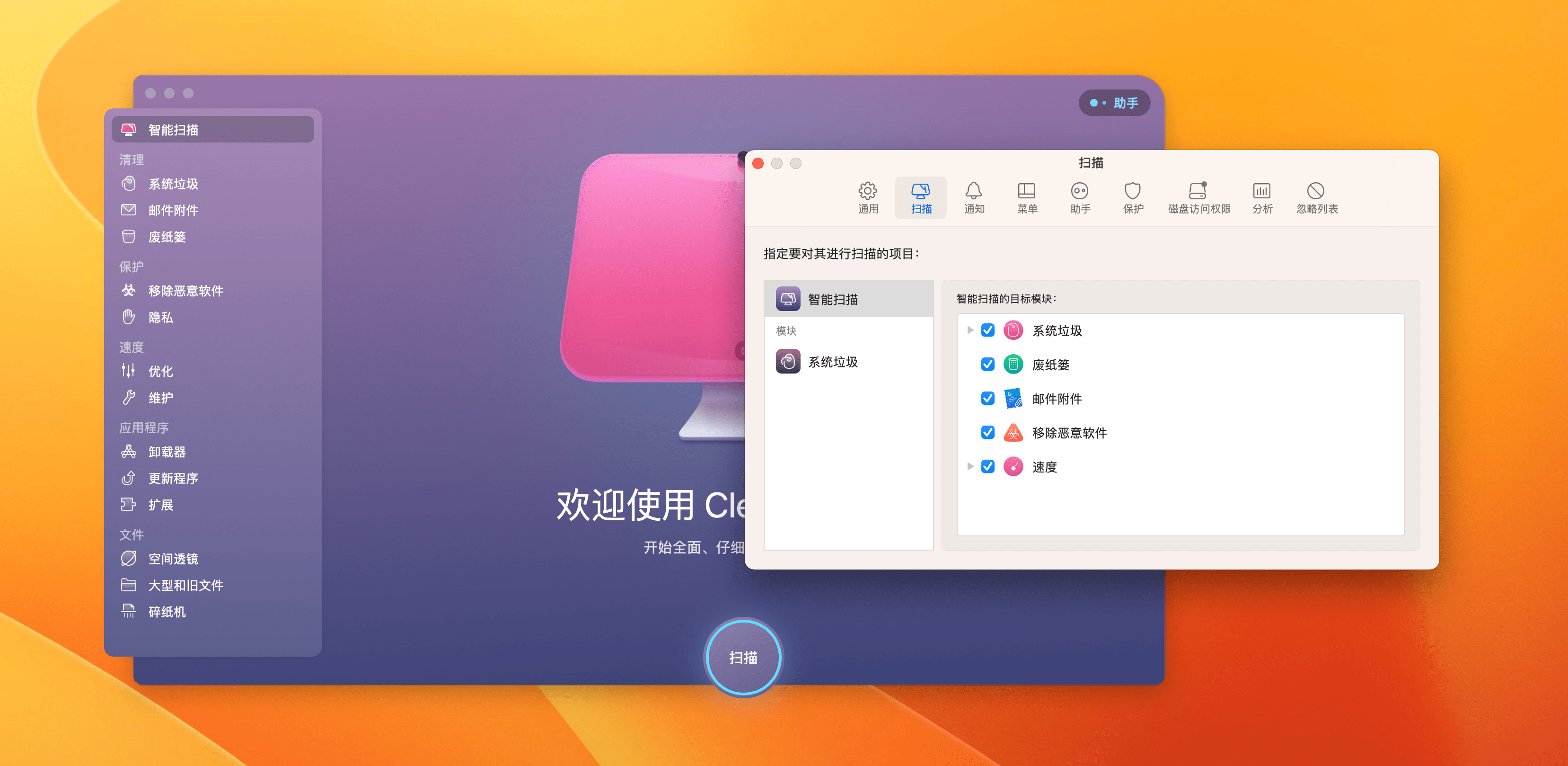
CleanMyMac X4.20最新Mac系统垃圾清理工具
CleanMyMac X是一款Mac系统垃圾清理工具,可以清除Mac系统多余的语言包、系统缓存、应用程序、PowerPc软件运行库等,是硬盘瘦身的好工具。在面对一款多功能型的软件时,复杂的操作面板是最容易让人头疼的,好在 CleanMyMac 一直以来都原生支持简体中文语言&…...

阿里季报图解:营收2434亿 AI迎商业化拐点,模型及应用ARR年底破300亿,派息25亿美元
雷递网 雷建平 5月13日阿里巴巴(美股代码:“baba”,港股代号:9988)今日发布2026年第一季度的财报。财报显示,阿里2026年第一季度营收为2433.8亿元(352.83亿美元),同比增长…...

PHP文件上传绕过新思路:用.htaccess+GIF89a头绕过exif_imagetype检测的完整操作指南
突破文件上传限制的进阶技巧:.htaccess与GIF89a的协同利用 在Web应用安全领域,文件上传功能一直是攻防对抗的前沿阵地。当开发者采用exif_imagetype()等函数验证文件类型时,攻击者往往会寻找更隐蔽的绕过方式。本文将深入剖析如何通过.htacce…...

白嫖使用 Claude Opus 4.7 一个月,新手保姆级教程
挖槽,最近亚马逊做了一次大善人,为它自家的 Kiro 做拉新活动,新注册账号可以直接获得一个月的 Kiro Pro 会员,价值 20 美刀。 教程非常详细,所以有点长,想看最短流程版的可以直接划到文章末尾。 Kiro 是什…...

Redis高级数据结构:超越String的Redis世界
Redis高级数据结构:超越String的Redis世界 引言 Redis不仅仅是"一个KV存储",它提供了丰富的数据结构,是现代应用架构中不可或缺的组件。深入理解Redis的数据结构,能够帮助我们设计出更高效、更优雅的解决方案。本文将…...

别只会改设置!Chrome/Edge浏览器主页被劫持的三种隐藏原因与根治方法
浏览器主页劫持的深度攻防:从表象到根源的终极解决方案 每次打开浏览器,那个陌生的主页是否让你感到烦躁?大多数人会直奔浏览器设置试图修改,却发现根本无效。这背后隐藏着远比表面设置更复杂的机制——快捷方式参数注入、注册表钩…...
---ESP32S3矩阵Matrix开发板之搭建开发环境)
【花雕学编程】Arduino动手做(252)---ESP32S3矩阵Matrix开发板之搭建开发环境
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里准备逐一动手试试多做实验,不管成功与否,都会记录下来——小小的…...

告别91卫图!用QGIS Python脚本批量下载Google/Bing卫星图,附完整代码
开源GIS实战:Python脚本自动化下载Google/Bing卫星影像全攻略 当你在深夜赶制城市规划方案时,突然发现91卫图下载的影像分辨率不足;当科研项目需要批量获取区域卫星数据时,商业软件高昂的授权费用让你望而却步——这可能是每个GIS…...

图片重复检测革命:AntiDupl.NET如何智能清理你的数字相册
图片重复检测革命:AntiDupl.NET如何智能清理你的数字相册 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 在数字摄影普及的今天,我们每个人的硬…...

企业云盘同步机制深度对比:巴别鸟/坚果云/飞书/OneDrive横评
团队协作场景下,文件同步是高频操作。一次同步卡顿可能导致整个团队等待;一次版本冲突可能让几小时的工作归零。选型时,销售会告诉你"我们同步很流畅",但到底怎么个流畅法,才是本文要拆解的核心。 本文从技术…...

安全测试人员必备:手把手教你用WePE+Ghost镜像在VMware里快速部署Win7靶机环境
安全测试人员必备:手把手教你用WePEGhost镜像在VMware里快速部署Win7靶机环境 在网络安全学习和渗透测试领域,拥有一个随时可用的标准化测试环境至关重要。对于刚入门的安全研究员、白帽子或需要进行漏洞复现的技术人员来说,Windows 7系统仍然…...