【机器学习】机器学习在深度学习领域中的作用:半监督学习的视角
👀时空之门👀
- 🔍引言
- 🎈半监督学习概述
- 🚝机器学习在深度学习领域中的作用
- ☘特征提取与表示学习
- 🍀复杂任务建模
- ❀结合半监督学习提升性能
- 🚀半监督学习在深度学习中的应用场景
- 📕图像识别与计算机视觉
- 🐱自然语言处理
- 💖半监督学习的未来与发展

🔍引言
随着信息技术的飞速发展,机器学习已经成为人工智能领域中的关键技术之一。在机器学习的众多分支中,深度学习以其强大的特征表示能力和高效的计算模型,成为解决复杂问题的有力工具。然而,在实际应用中,标注数据的获取往往成本高昂且耗时,这限制了深度学习模型的训练和应用。因此,如何在有限标注数据的情况下提高深度学习模型的性能,成为了一个重要的研究问题。半监督学习作为一种介于监督学习和非监督学习之间的方法,为解决这一问题提供了新的思路。本文将从半监督学习的视角出发,探讨机器学习在深度学习领域中的作用,分析其基本原理、应用场景以及面临的挑战,并通过代码示例展示半监督学习的实际应用。
🎈半监督学习概述
半监督学习是一种结合了监督学习和非监督学习的机器学习技术,旨在利用少量标注数据和大量未标注数据来提高学习器的性能。在实际应用中,标注数据的获取往往需要人工参与,成本高昂且耗时。而大量的未标注数据则相对容易获取,但难以直接用于监督学习。半监督学习通过利用未标注数据中的信息,辅助标注数据进行模型训练,从而提高了模型的泛化能力和准确性。
半监督学习的方法主要包括自训练(Self-training)、生成模型(Generative Models)、图模型(Graph-based Models)和协同训练(Co-training)等。这些方法各有特点,适用于不同的应用场景。其中,自训练方法通过迭代地利用模型对未标注数据进行预测和标注,逐步扩大标注数据集;生成模型方法则通过假设数据服从某种分布,利用未标注数据估计分布参数,进而对标注数据进行建模;图模型方法则利用数据之间的相似性关系构建图结构,通过图上的信息传播来辅助标注数据进行模型训练;协同训练方法则通过训练多个分类器,利用分类器之间的差异性来辅助标注数据进行模型训练。

🚝机器学习在深度学习领域中的作用
☘特征提取与表示学习
深度学习以其强大的特征提取和表示学习能力,在机器学习领域发挥着重要作用。在半监督学习中,深度学习模型同样可以利用其层次化的特征提取方式,从标注数据和未标注数据中提取出更加丰富的特征表示。这些特征表示不仅可以用于提高模型的分类性能,还可以用于其他相关任务,如聚类、降维等。
🍀复杂任务建模
深度学习模型具有强大的建模能力,可以处理更加复杂的数据和任务。在半监督学习中,深度学习模型可以利用未标注数据中的信息,辅助标注数据进行模型训练,从而实现对复杂任务的建模。例如,在图像识别领域,深度学习模型可以通过卷积神经网络(CNN)自动学习到图像中的局部特征和空间结构信息;在自然语言处理领域,深度学习模型可以通过循环神经网络(RNN)或Transformer等结构学习到文本中的序列依赖关系和语义信息。这些复杂的任务建模能力使得深度学习在各个领域都取得了显著的成果。
❀结合半监督学习提升性能
在半监督学习中,深度学习模型可以通过以下方式提升性能:
-
利用未标注数据扩大训练集:深度学习模型通常需要大量的标注数据进行训练。然而,在实际应用中,标注数据的获取往往成本高昂且耗时。半监督学习可以通过利用未标注数据来扩大训练集,从而提高模型的泛化能力和准确性。例如,可以使用自训练方法将未标注数据作为模型的输入,利用模型的预测结果作为标注数据来扩大训练集。
-
利用未标注数据辅助标注数据进行训练:在半监督学习中,标注数据和未标注数据往往具有相似的分布。因此,可以利用未标注数据中的信息来辅助标注数据进行模型训练。例如,可以使用生成模型方法假设数据服从某种分布,利用未标注数据估计分布参数,进而对标注数据进行建模;或者使用图模型方法利用数据之间的相似性关系构建图结构,通过图上的信息传播来辅助标注数据进行模型训练。
-
结合多种半监督学习方法:不同的半监督学习方法各有特点,适用于不同的应用场景。因此,可以结合多种半监督学习方法来提高深度学习模型的性能。例如,可以同时使用自训练方法和协同训练方法,通过迭代地利用模型对未标注数据进行预测和标注,以及利用多个分类器之间的差异性来辅助标注数据进行模型训练。

🚀半监督学习在深度学习中的应用场景
📕图像识别与计算机视觉
在图像识别领域,半监督学习可以通过利用未标注图像中的信息来辅助标注图像进行模型训练。例如,可以使用自训练方法将未标注图像作为模型的输入,利用模型的预测结果作为标注数据来扩大训练集;或者使用图模型方法利用图像之间的相似性关系构建图结构,通过图上的信息传播来辅助标注图像进行模型训练。这些方法可以提高深度学习模型在图像识别任务中的性能。
图像识别与计算机视觉:自训练方法
在图像识别任务中,我们可以使用自训练方法(Self-training)来利用未标注的图像数据辅助标注数据进行深度学习模型的训练。自训练方法的基本思想是先使用有限的标注数据训练一个初始模型,然后用这个模型对未标注数据进行预测,将预测结果置信度较高的样本加入到训练集中,再重新训练模型。这样迭代进行,逐步扩大训练集,提高模型的性能。
以下是一个使用Keras实现的自训练方法代码示例:
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split # 加载CIFAR-10数据集
(x_train_full, y_train_full), (x_test, y_test) = cifar10.load_data() # 假设我们只有少量标注数据
n_labeled = 1000
x_train, y_train = x_train_full[:n_labeled], y_train_full[:n_labeled]
y_train = to_categorical(y_train, 10) # 剩余数据作为未标注数据
x_unlabeled = x_train_full[n_labeled:] # 初始模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', input_shape=(32, 32, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax')) # 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) # 初始训练
model.fit(x_train, y_train, epochs=10, batch_size=64) # 自训练迭代
n_iterations = 5
for iteration in range(n_iterations): # 使用当前模型对未标注数据进行预测 predictions = model.predict(x_unlabeled) # 选择置信度较高的样本(例如,选择预测概率最高的类别概率大于某个阈值的样本) # 这里简单起见,我们假设选择预测概率最高的前100个样本 confidence_scores = predictions.max(axis=1) top_indices = confidence_scores.argsort()[-100:][::-1] x_new_labeled = x_unlabeled[top_indices] y_new_labeled = predictions[top_indices].argmax(axis=1) y_new_labeled = to_categorical(y_new_labeled, 10) # 扩大训练集 x_train = np.concatenate((x_train, x_new_labeled), axis=0) y_train = np.concatenate((y_train, y_new_labeled), axis=0) # 重新训练模型 model.fit(x_train, y_train, epochs=10, batch_size=64) # 最终模型在测试集上的评估
loss, accuracy = model.evaluate(x_test, to_categorical(y_test, 10))
print(f'Test loss: {loss}, Test accuracy: {accuracy}')
注意:上述代码示例为了简化,直接使用了CIFAR-10数据集的一部分作为未标注数据,实际应用中可能需要根据具体情况来获取未标注数据。
🐱自然语言处理
在自然语言处理领域,半监督学习同样具有广泛的应用。例如,在文本分类任务中,可以使用协同训练方法训练多个分类器,利用分类器之间的差异性来辅助标注文本进行模型训练;或者在命名实体识别任务中,可以使用生成模型方法假设文本数据
自然语言处理:协同训练方法
在自然语言处理任务中,协同训练方法(Co-training)可以利用多个不同的特征视图(例如,词语、词性、句法结构等)来训练多个分类器,并通过这些分类器之间的差异性来辅助标注数据进行模型训练。以下是一个简化的协同训练方法代码示例:
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import Tfidf

💖半监督学习的未来与发展
- 理论与算法的创新:随着研究的深入,半监督学习的理论与算法将不断得到创新和完善。这将进一步提高半监督学习的性能和应用范围。
- 应用领域的拓展:随着技术的不断进步,半监督学习将在更多领域得到应用。例如,在医疗健康、金融、自动驾驶等领域,半监督学习将发挥重要作用。
- 与其他技术的融合:半监督学习将与其他技术如强化学习、迁移学习等进行融合,形成更加先进的人工智能技术。这将进一步推动人工智能技术的发展和应用。
相关文章:
【机器学习】机器学习在深度学习领域中的作用:半监督学习的视角
👀时空之门👀 🔍引言🎈半监督学习概述🚝机器学习在深度学习领域中的作用☘特征提取与表示学习🍀复杂任务建模❀结合半监督学习提升性能 🚀半监督学习在深度学习中的应用场景📕图像识…...
C#WPF数字大屏项目实战01--开发环境与项目创建
1、学习目标 -界面布局 ,- 模板调整,- 控件封装,- 图表,- 通信对接,- 动态更新 2、开发环境 开发工具:Visual Studio-2022-17.8.6-Community 运行时框架:.Net 6或Framework 4.5以上 UI框…...
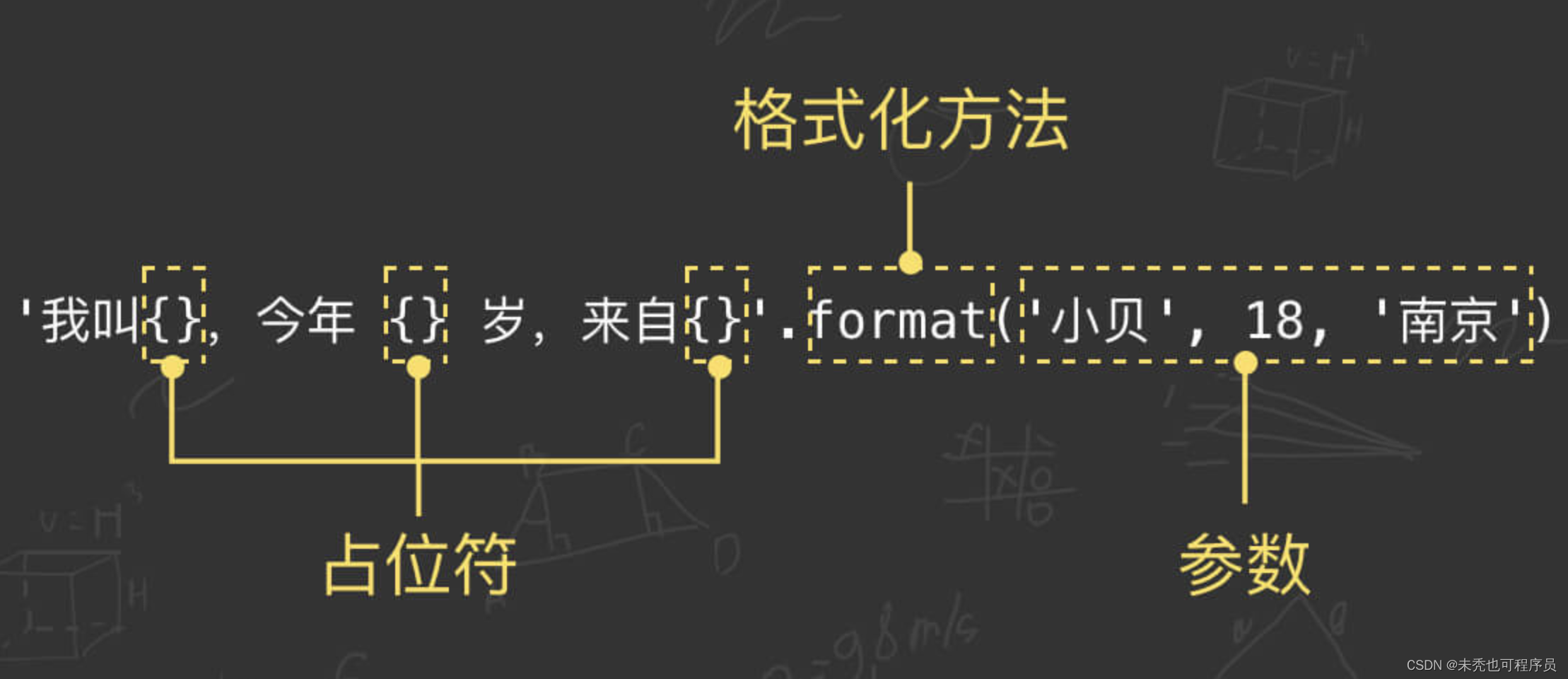
python中字符串的各类方法
大小写转换方法 upper() 用于将字符串中的小写字母转为大写字母。 abcd.upper() # ABCD aBcD.upper() # ABCD lower() 用于将字符串中的大写字母转为小写字母。 ABCD.lower() # abcd aBcD.lower() # abcd capitalize() 用于将字符串的第一个字母变成大写࿰…...
DataGrip 数据库连接客户端
I DataGrip 安装 1.1安装 打开dmg镜像,将“DataGrip.app”拖入应用程序中; 1.2 Act 打开应用程序,点击试用模式启动软件,然后将“jetbrains-agent-latest”拖到任意位置,然后拖入,弹出对话框,点击“Rest…...

JS片段:生成 UUID
Hi,这里是松桑,每天学习一个 JS 片段,涨涨🧀!今天带来的是如何生成 UUID,UUID作为全局唯一标识,使用常见广泛,包括分布式系统、数据库主键、会话标识、消息队列、日志追踪等等。 什么…...
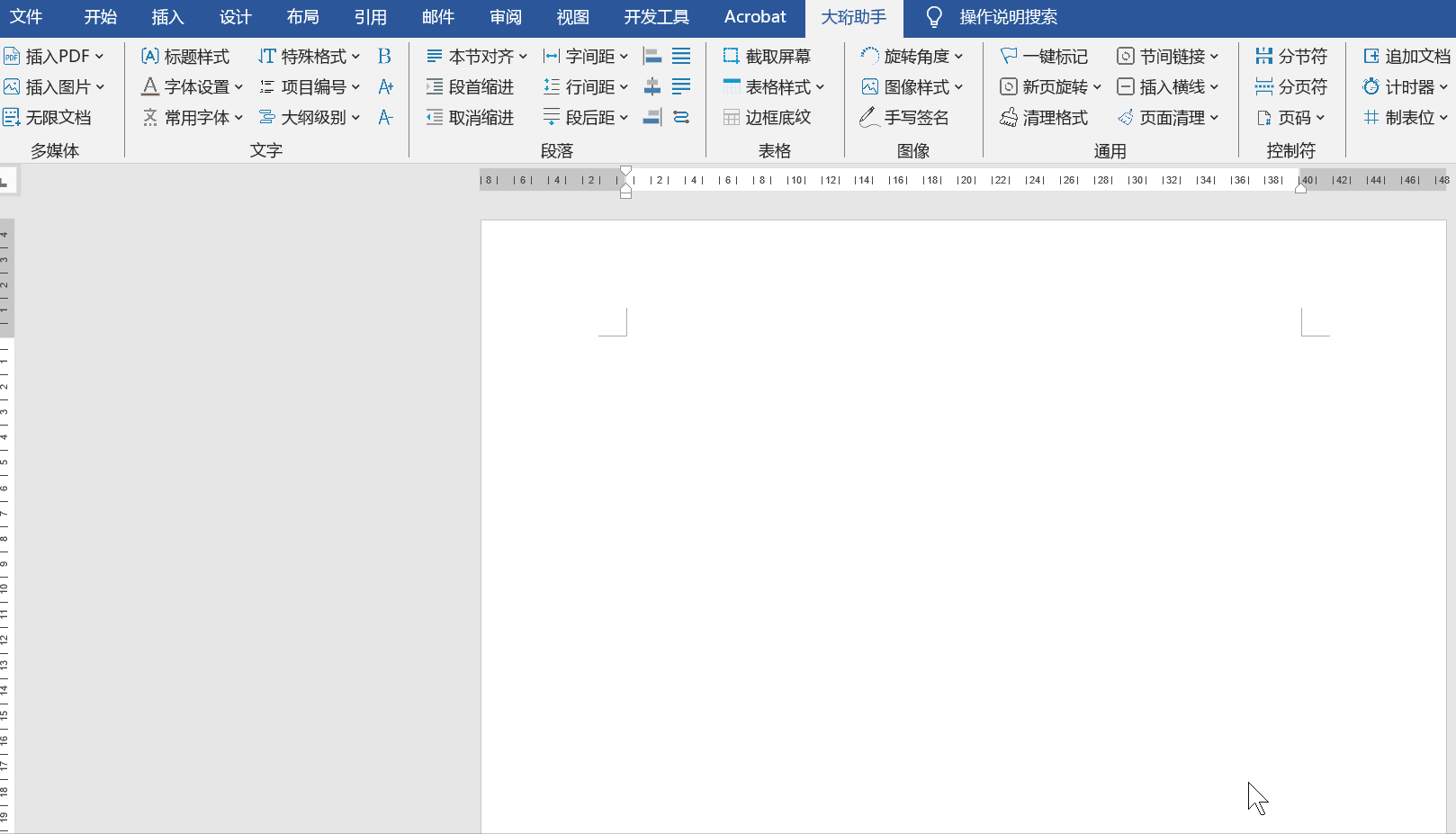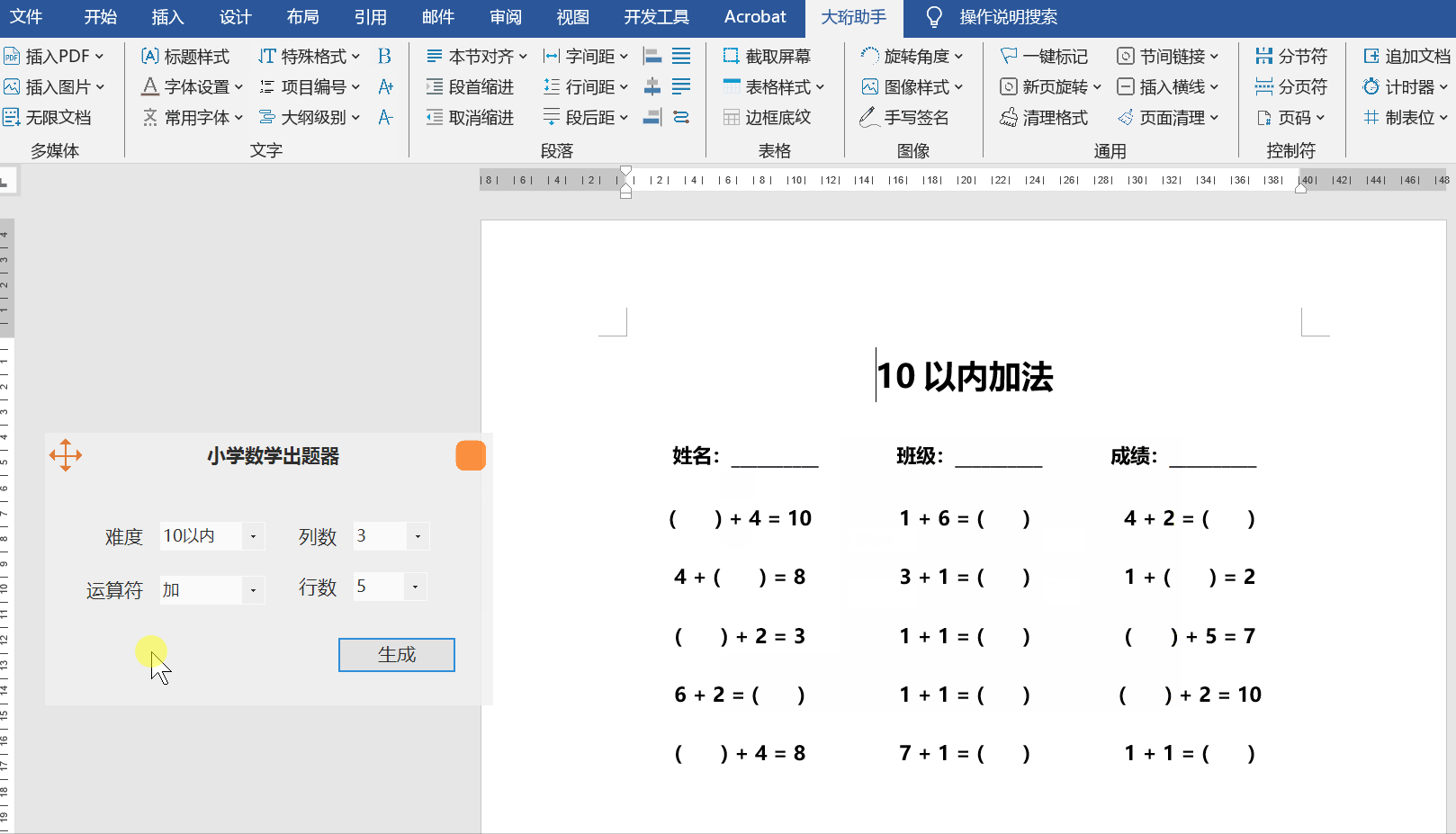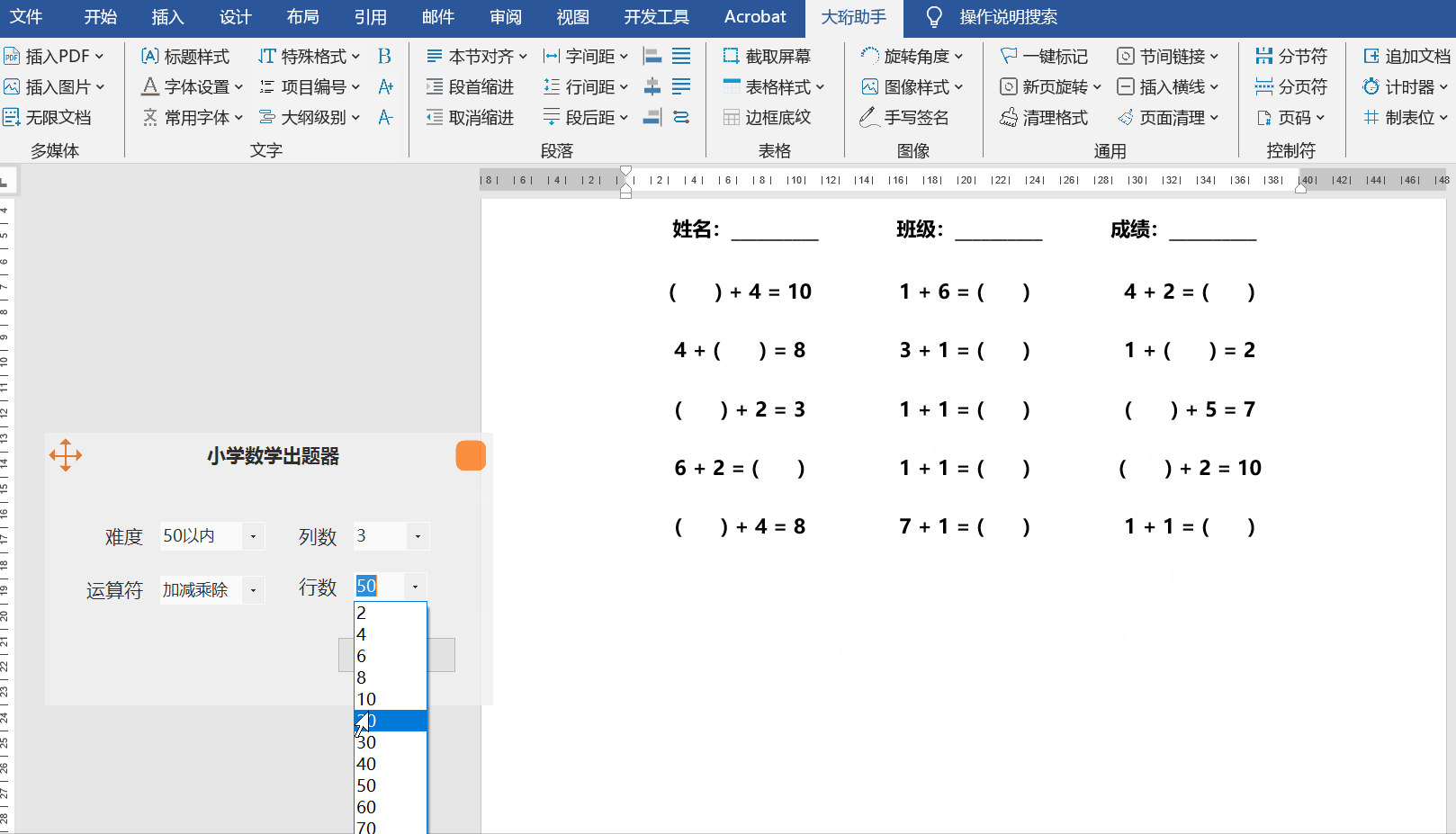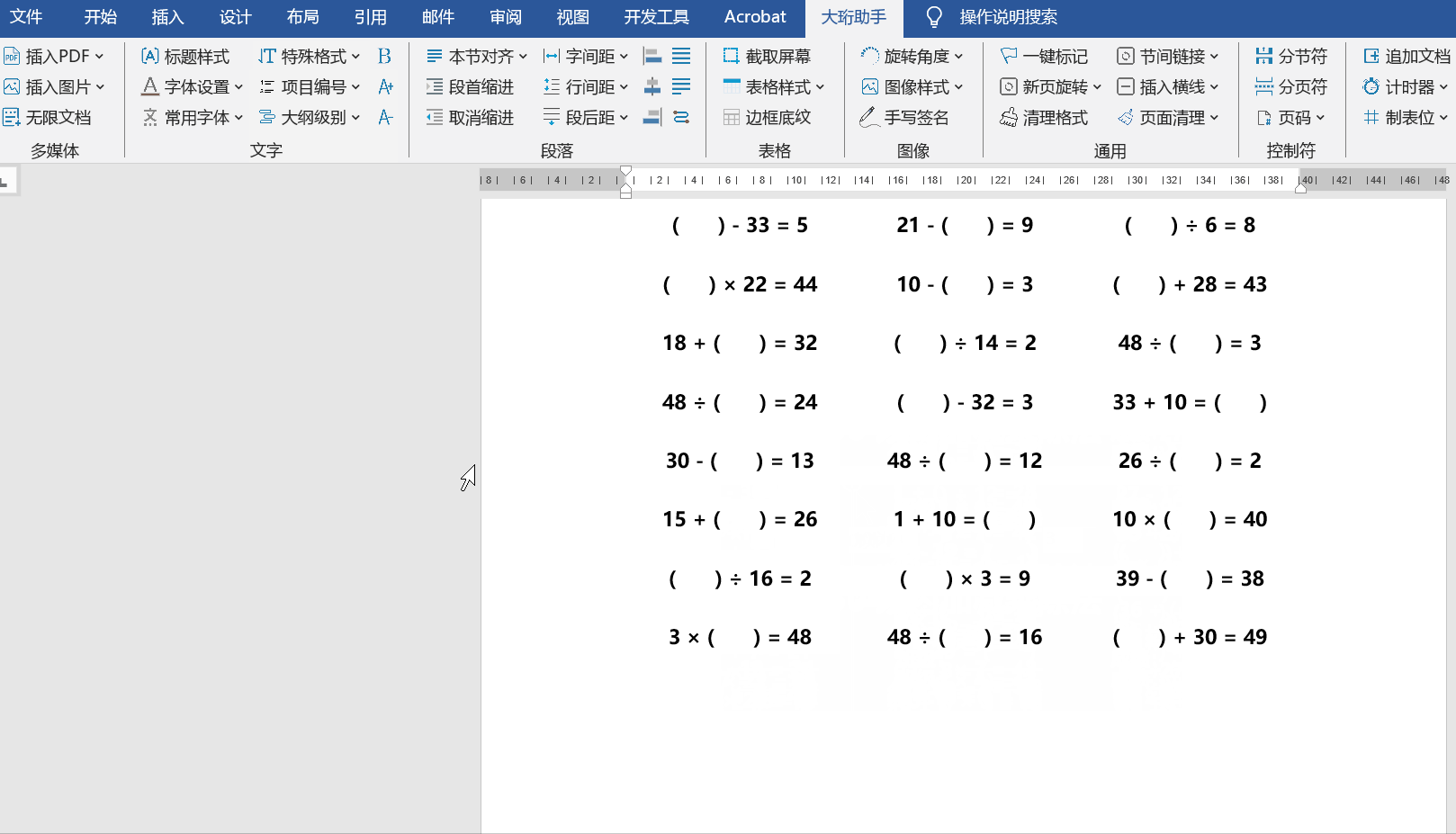
小学数学出题器-Word插件-大珩助手
Word大珩助手是一款功能丰富的Office Word插件,旨在提高用户在处理文档时的效率。它具有多种实用的功能,能够帮助用户轻松修改、优化和管理Word文件,从而打造出专业而精美的文档。 【新功能】小学数学出题器 1、实现了难度设定;…...
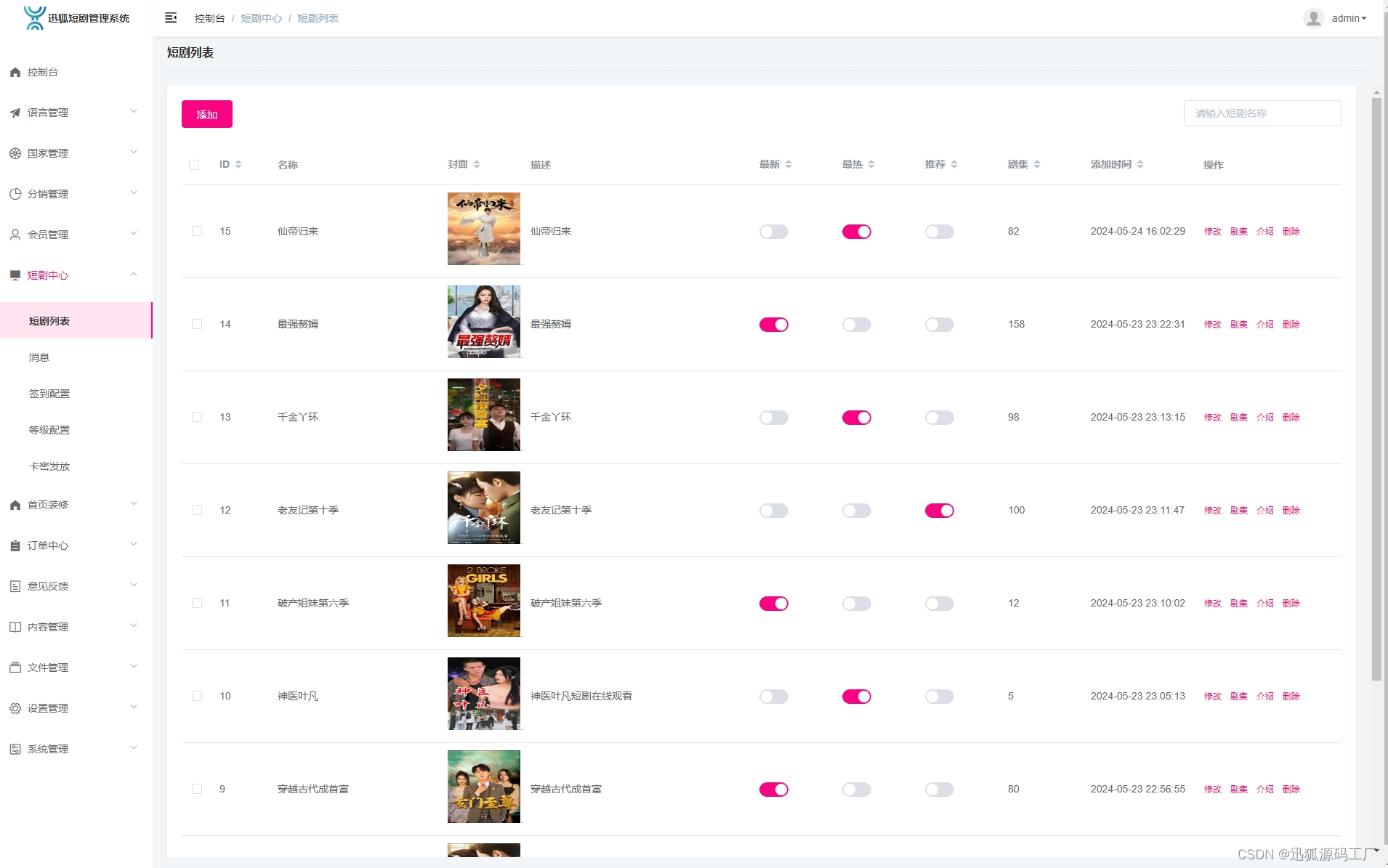
短剧平台源码:打造个性化娱乐体验的核心功能
在数字化媒体的浪潮中,短剧平台源码扮演着至关重要的角色,它不仅是构建短剧平台的技术基础,更是提供个性化娱乐体验的关键。本文将深入探讨短剧平台源码的核心功能,包括推荐短剧、本周热门/热播、个性化推荐、追剧功能、观看历史、…...

【MySQL】MySQL 图形化界面 - 使用说明(MySQL Workbench)
一、安装软件 Navicat,SQLyog 这些软件都不错,不过都需要收费,当然也有破解版。下面用 MySQL Workbench,它是官方提供的工具。 二、使用操作 这个软件本质是一个客户端,现在要让数据库能够远程登录。不过一般不会远程…...

Shell 编程之免交互
一、Here Document 语法格式: 命令 << 标记 ...... ...... 标记 1.用wc -l的命令统计输入的文字的行数 [rootlocalhost ~]# wc -l <<EOF > aaa > bbb > ccc > EOF 3 备注: 显示行数。 2.整体赋值给变量,通过ech…...

github有趣项目:Verilog在线仿真( DigitalJS+edaplayground)
DigitalJS https://github.com/tilk/digitaljs这个项目是一个用Javascript实现的数字电路模拟器。 它旨在模拟由硬件设计工具合成的电路 像 Yosys(这里是 Github 存储库),它有一个配套项目 yosys2digitaljs,它可以转换 Yosys 将文…...

性能测试学习-基本使用-元件组件介绍(二)
jmeter优点是:开源免费,小巧,丰富的学习资料和扩展组件 缺点是:1.不支持IP欺骗,分析和报表能力相对于LR欠缺精确度(以分钟为单位) 工具用户量分析报表IP欺骗费用体积扩展性Loadrunner多(万)精…...

基于大模型的智慧零售教育科研平台——技术方案
一、概述 1.1背景 随着数字经济的快速发展和全社会数字化水平的升级,人工智能的积极作用越来越凸显,人工智能与各个行业的深度融合已成为促进传统产业转型升级的重要方式之一。ChatGPT的出现掀起了又一波人工智能发展热潮,人工智能行业发展势…...

C# using的几个用途
using 关键字有三个主要用途: 1.using 语句定义一个范围,在此范围的末尾将释放对象: string filePath "example.txt"; string textToWrite "Hello, this is a test message!"; // Use the using statement to ensure …...

MyBatis3.4全集笔记
MyBatis 1. MyBatis 简介 MyBatis 本是apache的一个开源项目iBatis, 2010年这个项目由apache software foundation 迁移到了google code,并且改名为MyBatis 。2013年11月迁移到Github。 iBATIS一词来源于“internet”和“abatis”的组合,是一个基于Ja…...
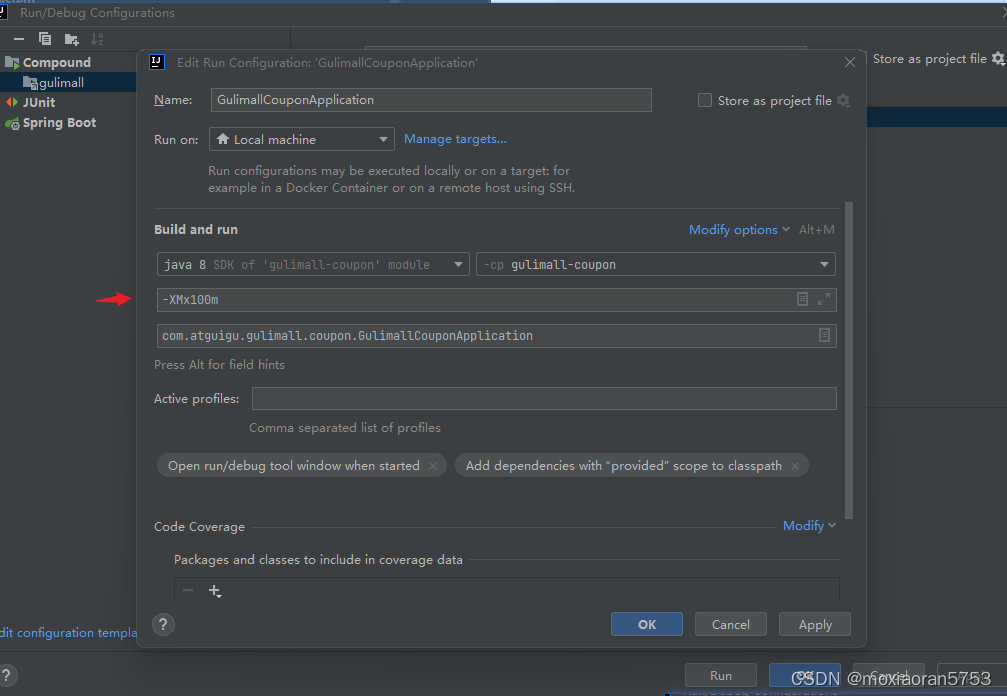
IDEA一键启动多个微服务
我们在做微服务项目开发的时候,每次刚打开IDEA,就需要把各个服务一个个依次启动,特别是服务比较多时,逐个点击不仅麻烦还费时。下面来说一下如何一键启动多个微服务。 操作步骤 点击Edit Configurations 2.点击“”,…...

【Python3】random.choices 权重随机选取 详解
random.choices是Python 3中random模块中的一个函数,用于从指定的序列中以指定的权重随机选择元素。下面我将对该函数进行详细介绍,并提供一些示例代码和注意事项。 函数签名: random.choices(population, weightsNone, *, cum_weightsNone…...

【面试题-015】Redis的线程模型是什么 为什么速度快
redis面试题 Redis的线程模型是什么 为什么速度快? Redis是一个开源的、高性能的键值对(key-value)数据库。它之所以速度快,主要得益于以下几个方面的设计: 单线程模型: Redis的操作是单线程的ÿ…...

EasyV开发人员的使用说明书
在可视化大屏项目时,开发人员通常需要承担以下任务: 技术实现:根据设计师提供的设计稿,利用前端技术(如HTML、CSS、JavaScript等)和后端技术(根据具体项目需求,可能是Java、Python、…...

构造列表初始化和构造初始化区别
构造列表初始化和构造初始化在C等编程语言中,是两种不同的初始化类实例成员的方式。以下是它们之间的主要区别: 构造列表初始化(初始化列表) 定义:初始化列表以一个冒号开始,接着是一个以逗号分隔的数据成…...

Message passing mechanism (消息传递机制)
objc_msgSend 是 Objective-C 运行时系统中的一个核心函数,用于实现消息传递机制。在 Objective-C 中,方法调用实际上是消息传递的过程,当你在代码中调用一个方法时,编译器会将其转换为 objc_msgSend 函数的调用。 objc_msgSend …...

基于单片机的全自动咖啡机控制系统设计
一、摘要 全自动咖啡机控制系统控制系统对于现今的日常家居生活和商业模式售卖都有着重大的影响力,随着社会快节奏的发展,传统的人工冲泡模式效率远远满足不了人们的日常需求,并且在冲调多口味咖啡方面,也没有良好的原料精准配比。…...

突破下载瓶颈:3个鲜为人知的ComfyUI加速方案,速度提升300%的秘密
突破下载瓶颈:3个鲜为人知的ComfyUI加速方案,速度提升300%的秘密 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and…...

从 Agent 到 Skill:揭秘 AI 产品经理进阶的真正关键!
文章深入探讨了 AI 产品经理应如何理解和应用 Agent 与 Skill。文章指出,当前许多 AI 产品经理将注意力过度集中于 Agent,而忽略了 Skill 的重要性。实际上,Skill 是定义 Agent 在具体任务中行为、标准和质量的关键。文章详细阐述了 Skill 的…...

服务器速度很慢
表现:20K/s ssh有时候能打开,有时候打不开结果:没有交话费,欠费。解决方式:充值200元现在能打开了,另外添加了一个参数:ProxyPreserveHost off但是很可能没用,因为我一开始直接访问…...

终极指南:Spinnaker资源生命周期管理的完整流程与最佳实践
终极指南:Spinnaker资源生命周期管理的完整流程与最佳实践 【免费下载链接】spinnaker Spinnaker is an open source, multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence. 项目地址: https://gitcode.…...
)
收藏备用!小白程序员必看,大模型核心原理拆解(通俗易懂版)
本文专为CSDN小白程序员、AI入门者打造,用“技术拆解通俗类比”的方式,深入解析大模型的核心原理,避开专业术语壁垒。明确大模型的AI分支定位,拆解其三大底层逻辑,补充微调、提示工程的实操要点,澄清新手常…...

**用Python实现高效分子结构建模与能量计算:从零开始构建你的计算化学工具链**在现代计算化学中,**Python已成
用Python实现高效分子结构建模与能量计算:从零开始构建你的计算化学工具链 在现代计算化学中,Python已成为科研人员首选的编程语言之一,它不仅语法简洁、生态丰富,还具备强大的科学计算能力。本文将带你一步步搭建一个基于Python的…...

如何利用 HTML 结构优化网页内容结构_通过 HTML 结构优化内容层次化对 SEO 的作用是什么
如何利用 HTML 结构优化网页内容结构_通过 HTML 结构优化内容层次化对 SEO 的作用是什么 在当今的互联网时代,搜索引擎优化(SEO)已经成为网站成功的关键因素之一。一个好的 SEO 策略不仅能够提高网站的可见度,还能够吸引更多的访…...

GHelper全面革新:华硕笔记本硬件控制的智能突破方案
GHelper全面革新:华硕笔记本硬件控制的智能突破方案 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar…...

彻底卸载Windows 10 OneDrive:开源脚本的完整解决方案
彻底卸载Windows 10 OneDrive:开源脚本的完整解决方案 【免费下载链接】OneDrive-Uninstaller Batch script to completely uninstall OneDrive in Windows 10 项目地址: https://gitcode.com/gh_mirrors/on/OneDrive-Uninstaller 你是否曾为Windows 10内置的…...