ToxVidLLM:一个用于检测有害视频的多模态多任务框架
在一个社交媒体平台赋予用户成为内容创作者力量的时代,数字领域见证了前所未有的信息传播激增,到2023年,近82%的互联网流量是视频内容。因此,像抖音和YouTub这样的平台已经成为主要的信息来源。一个显著的统计数据凸显了这些平台的巨大影响:仅在YouTube上,用户每天就共同观看超过十亿小时的视频内容。视频内容的病毒性质是一把双刃剑:它促进了新闻的快速传播,同时也加速了有害言论的传播。
我们推荐一个先进的多模态多任务框架,用于视频内容中的毒性检测,利用大型语言模型(LLMs),并结合了进行情感和严重性分析的附加任务。ToxVidLLM结合了三个关键模块——编码器模块、跨模态同步模块和多任务模块——构建了一个为复杂视频分类任务定制的通用多模态LLM。
1 有害代码混合多模态(ToxCMM)数据集
选择YouTube作为主要数据源,重点是代码混合语言对话,主要是印地语和英语。为了收集相关内容,我们使用YouTube API抓取印度网络系列和印地语"烤"视频,将下载的视频细分为更小的子视频,以便在句子级别进行注释,并最大化包含有害内容。数据集包含931个视频,采用印地语-英语代码混合格式。
使用了配置有OpenAI库中单词时间戳的Whisper转录模型为每个视频生成文字转录。然后我们通过手动删除由于语音中断或结巴导致不清楚的单词和符号来提高文字转录的质量。从视频中提取单个话语涉及记录它们的开始和结束时间。
1.1 数据注释
为了更好地阐明注释过程,我们将注释部分分为两个子部分:(i) 注释培训和(ii) 主要注释。注释培训:三位博士学者监督注释过程,他们精通有害和冒犯内容,实际注释由三位精通印地语和英语的本科生进行。
数据集考虑了两个毒性类别(非毒性/毒性)、三个情感类别(积极/中立/消极)以及每个视频样本的严重性得分在三点量表上(0、1、2)。得分0表示没有毒性迹象,1表示帖子包含毒性迹象,但并不严重,2分表示帖子包含强有力的毒性证据(例如,身体威胁或兴奋自杀)。
1.2 数据集统计
数据集总共包含4021个话语,其中1697个被归类为有害,其余2324个被标记为非有害。ToxCMM数据集的类别统计数据如表1所示。该数据集中的每个话语平均包含8.68个单词,平均持续时间为8.89秒。平均而言,数据集中的每个话语包含约68.20%的印地语单词,这意味着超过三分之二的单词是印地语,其余的单词是英语。
2 方法论
给定一个表示为V的话语视频片段,我们的任务基本上是一个分类问题,目标是确定视频是否包含有害内容,以及为其分配情感和严重性标签。每个视频V表示为一系列帧F = {f1, f2, ... fn},附带相关的音频A,以及视频的文字转录T = {w1, w2, ... wm},由一系列单词组成,构建一个基于深度学习的视频分类器,表示为C:C(T; F; A) → y,其中y表示给定任务的视频的实际标签。我们将基于LLM的多模态多任务框架ToxVidLLM划分为三个不同的组件:即编码器模块、跨模态同步模块和多任务模块。
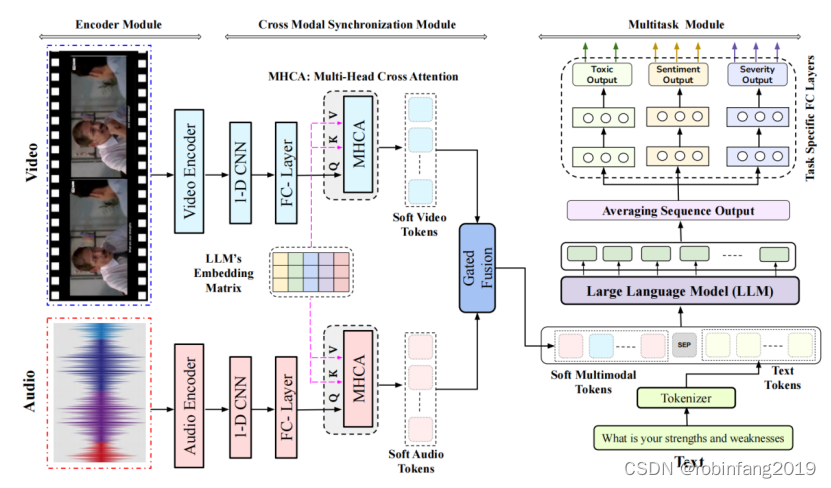
2.1 编码器模块
2.1.1 文本编码器
模型选择: 在 HingBERT 模型系列中进行实验,包括 HingMBERT、HingRoBERTa、HingGPT 和 IndicBERT。HingBERT 系列模型专门针对印地语和英语混合语(Hinglish)进行预训练,能够有效地处理混合语言文本。
作用: 将视频字幕中的文本转换为嵌入表示,捕捉文本内容的语义信息。
2.1.2 音频编码器
模型选择: 使用两个最先进的(SOTA)模型,即Whisper和MMS。
- Whisper: 由 OpenAI 开发,是一个多语言语音识别模型,在大型音频数据集上进行训练,能够有效地识别和理解语音内容。
- MMS (Massively Multilingual Speech): 由 Facebook AI 开发,是一个用于语音识别的预训练模型,能够在多种语言上进行训练和使用。
作用: 将视频中的音频信号转换为嵌入表示,捕捉语音内容的信息,例如说话人的语气、语调等。
2.1.3 视频编码器
模型选择: 使用了两个基于 Transformer 的视频模型:VideoMAE 和 Timesformer。
- VideoMAE: 使用掩码自编码器进行自监督视频预训练,能够有效地捕捉视频中的时空信息。
- Timesformer: 将 Transformer 架构扩展到视频理解任务,能够有效地捕捉视频中的时间关系。
作用: 将视频帧转换为嵌入表示,捕捉视频内容的信息,例如场景、动作、表情等。
2.2 跨模态同步模块
跨模态同步模块是 ToxVidLLM 模型中至关重要的一环,它负责将来自不同模态(视频、音频、文本)的特征进行对齐,以便更好地融合信息并提升毒性检测的性能。
2.2.1 编码阶段
首先,使用预训练模型分别对视频和音频进行编码,提取其特征表示:
- 视频编码: 使用 VideoMAE 或 Timesformer 等模型,捕捉视频中的空间和时间信息。
- 音频编码: 使用 Whisper 或 MMS 等模型,提取音频信号中的语义信息。
经过编码后,视频和音频的特征表示分别记为 Zv 和 Za。
2.2.2 抽象特征提取
为了降低计算成本并限制前缀中的 token 数量,使用 1 维卷积层 (Conv) 对 Zv 和 Za 进行压缩,使其长度缩短到固定的值 SL’。
接着,使用全连接层 (FC) 调整特征维度,使其与 LLM 的 token 嵌入矩阵维度 dt 相匹配。
经过抽象特征提取后,视频和音频的特征表示分别记为 Cv 和 Ca。
2.2.3 多头交叉注意力 (MHCA)
为了将视频和音频的特征表示与文本特征表示对齐,使用 MHCA 机制。
MHCA 机制将 Cv 和 Ca 作为 Query (Q),将文本特征表示 Et 作为 Key (K) 和 Value (V)。
通过比较 Q 和 K,计算注意力权重,并使用加权求和的方式更新 Q,从而将视频和音频的特征表示映射到文本嵌入空间。
经过 MHCA 处理后,视频和音频的特征表示分别记为 Csv 和 Csa。
2.2.4 门控融合
为了更好地融合视频和音频的特征,使用门控融合策略。
门控融合通过学习权重矩阵 Pv 和 Pa,以及标量偏置 bg,将 Csa 和 Csv 进行线性组合。
2.3 多任务模块
任务模块是 ToxVidLLM 模型中的核心部分,它负责同时进行毒性检测、严重程度分析和情感分析三个任务。
2.3.1 输入
多任务模块的输入包括来自跨模态同步模块的融合特征表示 Jva,以及文本特征表示 Et。
为了更好地融合文本和融合特征,将 Jva 和 Et 通过特殊 token [SEP] 进行连接,形成一个多模态输入序列。
2.3.2 LLM 处理
使用预训练的 LLM 模型(如 HingRoberta 或 HingGPT)对多模态输入序列进行处理。
LLM 模型会生成一个序列输出,每个 token 对应一个向量表示。
2.3.3 任务特定层
将 LLM 的序列输出进行平均池化,得到一个全局特征表示。
将全局特征表示分别输入到三个任务特定的全连接层,每个层对应一个任务(毒性检测、严重程度分析、情感分析)。
每个任务特定层会输出一个向量表示,该向量包含了该任务所需的信息。
2.3.4 输出层
将三个任务特定层的输出分别输入到输出层,进行 softmax 操作,得到三个任务的预测概率分布。
最终,根据预测概率分布,可以得到每个视频的毒性标签、严重程度标签和情感标签。
2.4 加权交叉熵损失函数
ToxVidLLM 模型进行了多任务学习,同时进行毒性检测、严重程度分析和情感分析三个任务。为了平衡不同任务之间的权重,使用了加权交叉熵损失函数:Loss_f = ∑(β_k * Loss_k)
- Loss_f 表示最终的损失值。
- Loss_k 表示第 k 个任务的交叉熵损失值。
- β_k 表示第 k 个任务的权重,由模型在训练过程中学习得到。用于控制不同任务对最终损失的贡献程度。例如,如果毒性检测任务比其他任务更重要,可以将 β_k 设置得更高,从而使模型在训练过程中更加关注毒性检测任务的预测精度。
3 结论
3.1 模态编码器选择
在音频编码器方面,Whisper 模型在所有实验设置中均优于 MMS 模型,证明了其在处理音频数据方面的优越性能。
在视频编码器方面,VideoMAE 模型在所有实验设置中均优于 TimeSformer 模型,证明了其在提取视频特征方面的有效性。
在文本编码器方面,HingRoBERTa 模型在所有实验设置中均优于其他模型,证明了其在处理 Hindi-English 混合代码文本方面的优势。
3.2 单模态、双模态和三模态的比较
- 单模态实验表明,文本模态在毒性检测任务中始终优于视频和音频模态,突出了文本信息在视频毒性检测中的重要性。
- 双模态实验表明,文本+音频配置始终优于其他两种组合,证明了音频信息对毒性检测任务的补充作用。
- 三模态实验表明,三模态配置在所有任务中都取得了最佳性能,证明了文本、音频和视频信息在视频毒性检测中的互补作用。
3.3 ToxVidLLM 模型的优势
- ToxVidLLM 模型在所有实验中都显著优于基线模型,证明了其有效性。
- ToxVidLLM 模型的多任务学习机制能够有效提升毒性检测任务的性能。
- ToxVidLLM 模型的 MHCA 和门控融合机制能够有效地融合不同模态的特征,从而提升模型的性能。
4 相关知识
4.1 MHCA 进行跨模态同步
ToxVidLLM 模型选择使用 MHCA 进行跨模态同步,而不是其他方法,主要基于以下几个原因:
4.1.1 文本信息的重要性
在视频内容中,文本信息往往比音频和视频信息更能直接反映说话者的意图和情绪。
MHCA 可以有效地将文本信息作为引导,帮助模型理解和融合其他模态的信息。
4.1.2 统一表示空间
MHCA 可以通过计算不同模态之间的注意力权重,将它们映射到一个统一的表示空间中。
这有助于模型在不同模态之间建立关联,并更准确地识别毒性内容。
4.1.3 优于其他方法
与简单的拼接方法相比,MHCA 可以避免模态信息之间的冲突,并赋予不同模态不同的权重。
与其他注意力机制相比,MHCA 可以更有效地捕获不同模态之间的长期依赖关系。
4.1.4 实验验证
在 ToxVidLLM 的消融研究中,移除 MHCA 模块会导致模型性能显著下降,这进一步证明了 MHCA 在跨模态同步中的重要性。
4.2 ToxVidLLM 模型代码和数据集下载
GitHub - justaguyalways/ToxVidLM_ACL_2024: Code and Datasets for our accepted long paper at ACL 2024, regarding toxicity detection in code-mixed hinglish video content
相关文章:
ToxVidLLM:一个用于检测有害视频的多模态多任务框架
在一个社交媒体平台赋予用户成为内容创作者力量的时代,数字领域见证了前所未有的信息传播激增,到2023年,近82%的互联网流量是视频内容。因此,像抖音和YouTub这样的平台已经成为主要的信息来源。一个显著的统计数据凸显了这些平台的…...
比较(二)利用python绘制雷达图
比较(二)利用python绘制雷达图 雷达图(Radar Chart)简介 雷达图可以用来比较多个定量变量,也可以用于查看数据集中变量的得分高低,是显示性能表现的理想之选。缺点是变量过多容易造成阅读困难。 快速绘制…...

Visual Studio怎么用?
Visual Studio的使用涉及多个方面,以下是一个清晰的使用指南,涵盖了Visual Studio的基本功能、安装、界面介绍、项目创建、代码编写、调试和发布等关键步骤: 一、Visual Studio简介 Visual Studio是由微软公司开发的一款集成开发环境&#…...

Python工程中,__init__.py文件有什么用
在Python工程中,__init__.py 文件有几个重要的用途: 标识目录为包: 在Python 3.3之前,__init__.py 文件的存在是为了告诉解释器,该目录是一个Python包。这使得包中的模块可以被导入和使用。即使在Python 3.3之后可以没…...

YOLOv10环境搭建推理测试
引子 两个多月前YOLOv9发布(感兴趣的童鞋可以移步YOLOv9环境搭建&推理测试_yolov9安装-CSDN博客),这才过去这么短的时间,YOLOv10就横空出世了。现在YOLO系列搞得就和追剧一样了。。。OK,那就让我们开始吧。 一、…...
tomcat-memcached会话共享配置
目录 1、安装memcache服务 2、把依赖的jar包移至tomcat/lib目录下 3、配置tomcat/conf/context.xml 4、重启tomcat服务 1、安装memcache服务 具体安装步骤此处不详细说明,自行根据实际情况安装即可 2、把依赖的jar包移至tomcat/lib目录下 3、配置tomcat/conf/c…...

404错误页面源码,简单实用的html错误页面模板
源码描述 小编精心准备一款404错误页面源码,简单实用的html错误页面模板,简单大气的页面布局,可以使用到不同的网站中,相信大家一定会喜欢的 效果预览 源码下载 https://www.qqmu.com/3375.html...

AI程序员来了,大批码农要失业
根据GitHub发布的《Octoverse 2021年度报告》,2021年中国有755万程序员,排名全球第二。 ChatGPT的出现,堪比在全球互联网行业点燃了一枚“核弹”,很多人都会担心“自己的工作会不会被AI取代”。 而2024年的AI进展速度如火箭般&am…...

车联网安全入门——CAN总线模糊测试
文章目录 车联网安全入门——CAN总线模糊测试介绍主要特点使用场景 模糊测试(Fuzz Testing)CAN 总线模糊测试(CAN Packet Fuzzing)主要步骤工具和软件主要目标 Can-Hax安装使用获得指纹模糊测试 SavvyCAN 总结参考 车联网安全入门…...
—预编译模式下占位符动态排序字段失效)
JDBC常见异常(10)—预编译模式下占位符动态排序字段失效
场景需求 需要根据不同的列进行对应的排序操作,实现动态列名排序 类似🐟动态查询或更新 但是JDBC预编译模式下占位符的排序字段失效 SQL语句 分页查询 select * from (select t.*, rownum rn from(select * from emp order by empno desc) t where …...

爬虫入门教程:爬虫概述
在数字化时代,数据已经成为我们生活和工作中不可或缺的一部分。而如何高效、准确地获取这些数据,成为了许多领域面临的共同问题。今天,我们就来一起探讨一下爬虫技术,这个能够自动从互联网上抓取信息的神奇工具。 一、什么是爬虫…...

【工具】windows下VMware17解锁mac安装选项(使用unlocker427)
目录 0.简介 1.环境 2.安装前后对比 3.详细安装过程 3.1 下载unlocker427 1)下载地址 2)下载unlocker427.zip 3)解压之后是这样的 4)复制iso中的两个文件到你本地的VMware的安装目录下 5)复制windows下的所有…...

JS 自测题 —— 手写 class
现有三种菜单:button 类型,select 类型,modal 类型。 共同特点 title icon 属性isDisabled 方法(可直接返回 false)exec 方法,执行菜单的逻辑 不同 button 类型,执行 exec 时打印 helloselect …...
:使用YOLOV8和KerasCV进行高效的图像物体识别)
Keras深度学习框架实战(7):使用YOLOV8和KerasCV进行高效的图像物体识别
1、绪论 1.1 KerasCV简介 KerasCV是一个专注于计算机视觉任务的模块化组件库,基于Keras构建,可与TensorFlow、JAX或PyTorch等框架配合使用。 概念与定位: KerasCV是Keras API的水平扩展,提供了一系列新的第一方Keras对象&#x…...

Django视图层探索:GET/POST请求处理、参数传递与响应方式详解
系列文章目录 Django入门全攻略:从零搭建你的第一个Web项目Django ORM入门指南:从概念到实践,掌握模型创建、迁移与视图操作Django ORM实战:模型字段与元选项配置,以及链式过滤与QF查询详解Django ORM深度游ÿ…...

磁盘配额的具体操作
磁盘配额: linux的磁盘空间有两个方面:第一个是物理空间,也就是磁盘的容量 第二个inode号耗尽,也无法写入 linux根分区:根分区的空间完全耗尽,服务程序崩溃,系统也无法启动了。 为了防止有人…...

STM 32_HAL_SDIO_SD卡
STM32的SDIO(Secure Digital Input Output) 接口是一种用于SD卡和MMC卡的高速数据传输接口。它允许STM32微控制器与多种存储卡和外设进行通信,支持多媒体卡(MMC卡)、SD存储卡、SDI/O卡和CE-ATA设备。STM32的SDIO控制器…...
人脸识别系统之动态人脸识别
二.动态人脸识别 1.摄像头人脸识别 1.1.导入资源包 import dlib import cv2 import face_recognition from PIL import Image, ImageTk import tkinter as tk import os注:这些导入语句允许您在代码中使用这些库和模块提供的功能,例如创建…...
: 获取并绘制JSON标注文件目标区域(可单独保存目标小图))
Opencv实用笔记(一): 获取并绘制JSON标注文件目标区域(可单独保存目标小图)
文章目录 背景代码 背景 如果我们想要根据json标注文件,获取里面的指定目标的裁剪区域,那么我们可以根据以下代码来实现(也可以校验标注情况)。 代码 from tqdm import tqdm import os, json, cv2, copy import numpy as npdef…...

LabVIEW在高校电力电子实验中的应用
概述:本文介绍了如何利用LabVIEW优化高校电力电子实验,通过图形化编程实现参数调节、实时数据监控与存储,并与Simulink联动,提高实验效率和数据处理能力。 需求背景高校实验室在进行电机拖动和电力电子实验时,通常使用…...

Outfit字体:如何用专业几何无衬线字体打造品牌视觉革命
Outfit字体:如何用专业几何无衬线字体打造品牌视觉革命 【免费下载链接】Outfit-Fonts The most on-brand typeface 项目地址: https://gitcode.com/gh_mirrors/ou/Outfit-Fonts 你是否曾为寻找一款既能体现品牌个性,又能在各种数字场景中完美呈现…...

LeaguePrank:英雄联盟客户端个性化引擎完全指南
LeaguePrank:英雄联盟客户端个性化引擎完全指南 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 1. 价值定位:重新定义游戏界面体验 1.1 产品核心价值 LeaguePrank作为开源的英雄联盟客户端个性化引擎…...
应用程序设计)
基于STM32LXXX的无线收发芯片(CMT2300A-EQR)应用程序设计
一、简介: CMT2300A是一款超低功耗,高性能,适用于各种127至 1020 MHz无线应用的OOK,(G)FSK射频收发器。它是 CMOSTEK NextGenRFTM射频产品线的一部分,这条产品线 包含完整的发射器,接收器和收发器。CMT2300A的高集成 度,简化了系统设计中所需的外围物料。高达+20 dBm及-…...

告别重复输入:快马助你打造高效openclaw命令管理工具
最近在团队协作中频繁使用openclaw工具时,发现每次手动输入冗长的命令参数特别容易出错,尤其是当需要切换不同环境配置时,常常因为输错一个参数导致整个流程卡住。于是决定用Python开发一个小工具来提升操作效率,顺便把实现过程记…...

Emby高级功能革新解锁方案:emby-unlocked颠覆式技术实现与部署指南
Emby高级功能革新解锁方案:emby-unlocked颠覆式技术实现与部署指南 【免费下载链接】emby-unlocked Emby with the premium Emby Premiere features unlocked. 项目地址: https://gitcode.com/gh_mirrors/em/emby-unlocked 在数字媒体日益普及的今天…...

口碑好的3D动画源头厂家哪家专业
咱做3D动画的时候,都想找个专业靠谱的源头厂家。毕竟质量有保障,价格也会更实惠。那么现在市场上口碑好的3D动画源头厂家都有哪些呢?今天就带大家好好分析一下,顺便给大家推荐一家我觉得超棒的厂家——玄熠数字视觉科技࿰…...
)
山东大学2022-2023学期实时绘制期末考试真题(回忆版)
山东大学2022年到2023年实时绘制期末考试 (一共9到小题,每题10分或12分,包含多个小问,上午考完下午回忆写的,大体就这些,复习时还是应该全面一点。) AABB包围盒构建过程;中间节点和叶…...

如何打造专属漫画体验?Venera主题定制全攻略
如何打造专属漫画体验?Venera主题定制全攻略 【免费下载链接】venera A comic app 项目地址: https://gitcode.com/gh_mirrors/ve/venera 核心价值:为什么要定制Venera主题? 在数字阅读时代,个性化体验已成为提升用户满意…...

Notepad-- 终极中文编辑器:从零开始打造你的专属高效文本工作流
Notepad-- 终极中文编辑器:从零开始打造你的专属高效文本工作流 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

3步解锁Arduino红外遥控:终极实战指南
3步解锁Arduino红外遥控:终极实战指南 【免费下载链接】Arduino-IRremote Infrared remote library for Arduino: send and receive infrared signals with multiple protocols 项目地址: https://gitcode.com/gh_mirrors/ar/Arduino-IRremote 想要让Arduino…...