快速入门C++正则表达式
正则表达式(Regular Expression,简称 Regex)是一种强大的文本处理工具,广泛用于字符串的搜索、替换、分析等操作。它基于一种表达式语言,使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。正则表达式不仅在各种编程和脚本语言中被广泛支持,还是很多文本编辑器和处理工具的重要功能。
当需要从一堆字符串中提取出(或者是替换掉)具有一定规则(规律)的子字符串,那么用正则表达式会非常简单。
语法介绍
特殊字符
特殊字符在正则表达式中的作用是非常重要的,可以定义一系列的匹配规则。
.
- 描述
匹配除换行符(\n)外的任意单个字符。
如果要匹配.字符,请用\.。
注意:
[.]内的.匹配的是.而不是任意单个字符(.)内的.匹配的是任意单个字符,而不是.
- 示例
a.c匹配的是abc、acc等,但无法匹配ac[a.c]匹配的是a、.、c,但无法匹配abc
*
- 描述
匹配前面子表达式任意多次(包含0次)。
如果要匹配*字符,请用\*。
注意:
- 子表达式的意思是可以单独拎出来作为正则表达式的字符串
- 在匹配时必须保证
*的前面有子表达式[*]内的*匹配的是*字符
- 示例
ab*c匹配的是ac、abc、abbbbc等。(这里的子表达式是b)[abc]*匹配的是a、b、c、ac、acb、abcc等。(这里的子表达式是[abc])(abc)*匹配的是abc、abcabc、abcabcabc等。(这里的子表达式是(abc))[a*c]匹配的是a、*、c。(这里不做量化字符)
^
- 描述
^字符的匹配规则有两种:
- 在方括号
[]内时,匹配不包含在方括号内的单个字符 - 不在方括号内时,匹配字符串中的起始位置(起始位置也可以匹配)
- 示例
^abc的匹配项有起始位置abc
比如输入字符串
abc is abcd中匹配的是最前面的abc,最后面的无法匹配。
[^abc]匹配的是除了a、b、c这三个字符外的所有其他单个字符
[ ]
- 描述
匹配方括号内包含的单个字符。
注意:
- 方括号内的
-字符如果是第一个或最后一个的字符,那么它就是匹配-字符- 方括号内的
-字符不是第一个也不是最后一个字符,那么它就是匹配一个范围- 如果方括号内的第一个字符是
]会把最前面的[]当做子表达式
- 示例
[abc]的匹配项有a、b、c。[a-z]的匹配项是a-z的范围,即匹配的是a-z的所有小写字母。[abcx-z]的匹配项有a、b、c以及x-z的范围。[-abc]的匹配项有-、a、b、c。[abc-]的匹配项有a、b、c、-。[]abc]的匹配项有[]空字符集、a、b、c、]。[]abc[]的匹配项有[]空字符集、a、b、c、[]空字符集。
$
- 描述
$字符的匹配规则有两种:
- 在方括号
[]内时,就是匹配$字符 - 不在方括号内时,匹配字符串的结束位置
- 示例
abc$的匹配项有abc结束位置
比如输入字符串
abcd is abc中匹配的是最后的abc(结束位置不可见)
[abc$]的匹配项有a、b、c、$
( )
- 描述
圆括号的主要作用是定义一个子表达式,并设置捕获组。
捕获组(分组捕获)的主要作用是匹配组内的子表达式,并将匹配上的内容记录下来。
这导致使用捕获组的正则表达式的效率降低。
如果要匹配(或)字符,请使用\(或\)。
后面章节详细介绍。
+
- 描述
匹配前面子表达式一次或零次。
如果要匹配+字符,请用\+。
注意:
- 子表达式的意思是可以单独拎出来作为正则表达式的字符串
- 在匹配时必须保证
+的前面有子表达式[+]内的+匹配的是+字符
- 示例
ab+c匹配的是abc、abbc、abbbc等,但不匹配ac。(这里的子表达式是b)[abc]+匹配的是a、b、c、ac、acb等,但不匹配[abc])(abc)+匹配的是abc、abcabc、abcabcabc等,但不匹配(abc))[a+c]匹配的是a、+、c。(这里不做量化字符)
?
- 描述
匹配前面子表达式0次或1次。
如果要匹配?字符,请用\?。
- 示例
ab?c匹配的是ac或abc。(这里的子表达式是b)[ab?c]匹配的是a、b、?、c。(这里不做量化字符)
\
- 描述
反斜杠主要起转义字符的作用,这里的转义是双向的(原义转特殊,特殊转原义)。
- 原义转特殊:
\t表示制表符(Tab)\r表示回车符\n表示换行符\f表示换页符,用于打印文档中的换页\s表示任何空白字符,比如空格、制表符、回车符、换行符、换页符等\S表示非空白字符- 特殊转原义:
所有量词(*、+、?、{})的前面加\后,转义称为普通字符。
|
- 描述
匹配|前面的子表达式或者|后面的子表达式(二选一,只要匹配上一个就算成功)。
- 示例
ab|c的匹配项是ab 或 c,能匹配上ab和c[ab]|c能匹配上a、b、c
{ }
- 描述
{ }也是一个量词,表示匹配前面的子表达式的次数(或次数范围)。{ }有三种规范:
{n}:表示匹配前面子表达式n次,n是一个非负整数(大于等于0的整数){n,}:表示至少匹配前面子表达式n次,它是一个范围(大于等于n的整数),这里的n是一个非负整数{n,m}:表示至少匹配前面子表达式n次,最多匹配m次,且n<=m,这里的n和m都是非负整数
- 示例
abc{0}的匹配项是ab,这里的子表达式是cabc{2}的匹配项是abcc,这里的子表达式是cabc{2,}的匹配项是abcc、abccc、abcccc等abc{2,4}的匹配项是abcc、abccc以及abcccc(abc){2}的匹配项是abcabc[abc]{2}的匹配项是aa、ab、ac、ba、bb、bc、ca、cb以及cc
量化字符(量词)
量化字符是用来指定子表达式连续出现多少次才能匹配上。包含*、+、?、{},具体细节看上面特殊字符章节。
定位字符
定位字符是匹配字符串中特殊的位置,比如字符串的首和尾。
定位字符包含:
^
上面已经介绍了,这里就不介绍了。
$
上面已经介绍了,这里就不介绍了。
\b
匹配一个单词的边界,就是字符和空格之间的位置。比如:a cat in cats字符串中,\bcat\b只能匹配到前面的cat,但后面的cats中的cat无法匹配。
\B
匹配非单词边界,比如:a cat in cats字符串中,\bcat\B只能匹配到后面的cats中的cat,但前面的cat无法匹配。
扩展语法
速记字符
\d
匹配单个数字字符。
\w
匹配单个“单词字符”(字母数字字符加下划线)。
用\w+可以匹配用户名。
\s
匹配空白字符,比如空格、制表符、回车符、换行符、换页符等。
反向引用
反向引用指的是通过\n(这里的n表示数字,一般支持1-9,有些标准也支持9以上)来引用对应捕获组所匹配到的内容。
比如t1_t2_t3_t3_t2_t1字符串是能够被(..)_(..)_(..)_\3_\2_\1这样的正则完全匹配的,它的引用流程如下图: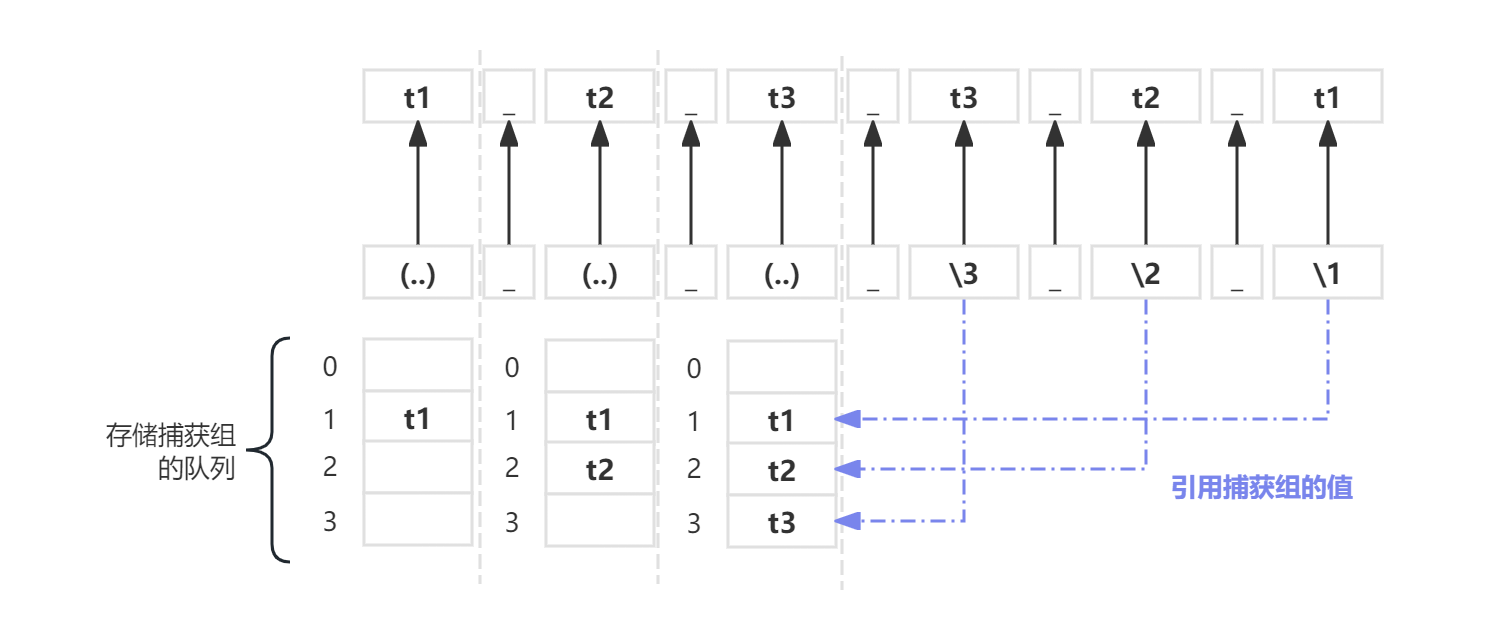
不同的语言底层实现的原理不一样。
存储捕获组的队列中下标0一般用来存储匹配成功的完整的字符串,示例中下标0位置存储的字符串应该是:
t1_t2_t3_t3_t2_t1
非捕获组
通过()实现的捕获组会影响性能,如果既要使用() 来进行分组,又不想作为捕获组被保存,所以需要使用非捕获组。
通过(?:..)可以实现非捕获组,示例如下:
还是用上面的示例:t1_t2_t3_t3_t2_t1字符串能够被(?:..)_(..)_(..)_\2_\1_t1完全匹配,其中(?:..)作为非捕获组匹配输入字符串的t1,不会被存储下来;然后后面在引用捕获组时,因为前面只有两个捕获组,所以引用计数最大是2。
C++中的正则表达式
C++11正式引入了正则表达式。
C++相关类和接口介绍
std::regex
std::regex是用于表示正则表达式的类,管理正则表达式。
std::regex_match
std::regex_match是一个函数,用于检查整个字符串是否完全符合正则表达式的模式。
需要整个字符串完全符合正则表达式,否则匹配失败。
std::regex_search
std::regex_search是一个函数,用于在字符串中搜索与正则表达式匹配的部分。
std::regex_iterator
std::regex_iterator迭代器用于迭代所有符合正则表达式的匹配项。
std::regex_iterator是一个模板类,根据字符类型的区别衍生出以下:
cregex_iterator、wcregex_iterator、sregex_iterator、wsregex_iterator
示例:
// 对于 std::string
std::string s = "Example string";
std::regex re("E");
std::sregex_iterator it(s.begin(), s.end(), re), end;
for (; it != end; ++it) {std::cout << it->str() << std::endl;
}// 对于 std::wstring
std::wstring ws = L"Example wstring";
std::wregex wre(L"E");
std::wsregex_iterator wit(ws.begin(), ws.end(), wre), endw;
for (; wit != endw; ++wit) {std::wcout << wit->str() << std::endl;
}
std::regex_replace
std::regex_replace是一个函数,用于替换与正则表达式匹配的子串。
std::regex_token_iterator
std::regex_token_iterator迭代器用于分割字符串,基于正则表达式找到的匹配项或非匹配项。
std::regex_error
std::regex_error是一个异常处理类,用于报告正则表达式中的错误。
try {// 使用正则表达式
} catch (const std::regex_error& e) {// 处理正则表达式错误
}
实际应用场景代码
匹配文本
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example.";std::regex pattern("regular expression");if (std::regex_search(text, pattern)) {std::cout << "The pattern was found in the text." << std::endl;} else {std::cout << "The pattern was not found in the text." << std::endl;}return 0;
}
查找文本位置
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example. ""Another example of regular expression.";std::regex pattern("example");std::smatch match;std::regex_search(text, match, pattern);if (match.size() > 0) {std::cout << "The first match was found at position " << match.position() << std::endl;std::cout << "The matched text is: " << match[0] << std::endl;} else {std::cout << "The pattern was not found in the text." << std::endl;}return 0;
}
替换文本
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example. ""It contains some outdated terms.";std::regex pattern("outdated");std::string replaced_text = std::regex_replace(text, pattern, "modern");std::cout << "The replaced text is: " << replaced_text << std::endl;return 0;
}
分组匹配
#include <regex>
#include <iostream>int main() {std::string text = "This is a regular expression example (123) 456-7890";std::regex pattern("(([^ ]+) (\\d{3})-(\\d{4}))$");std::smatch match;std::regex_search(text, match, pattern);if (match.size() > 0) {std::cout << "The first match was found at position " << match.position() << std::endl;std::cout << "Group 1: " << match[1] << std::endl;std::cout << "Group 2: " << match[2] << std::endl;std::cout << "Group 3: " << match[3] << std::endl;std::cout << "Group 4: " << match[4] << std::endl;} else {std::cout << "The pattern was not found in the text." << std::endl;}return 0;
}
#include <regex>
#include <iostream>int main() {std::string text = "(123) 456-7890";std::regex pattern("(([^ ]+) (\\d{3})-(\\d{4}))$");std::smatch match;if (std::regex_match(s, match, r)) {std::cout << "Group 1: " << match[1] << std::endl;std::cout << "Group 2: " << match[2] << std::endl;std::cout << "Group 3: " << match[3] << std::endl;std::cout << "Group 4: " << match[4] << std::endl;}return 0;
}
资料
推荐两个学习使用正则表达式的网站:
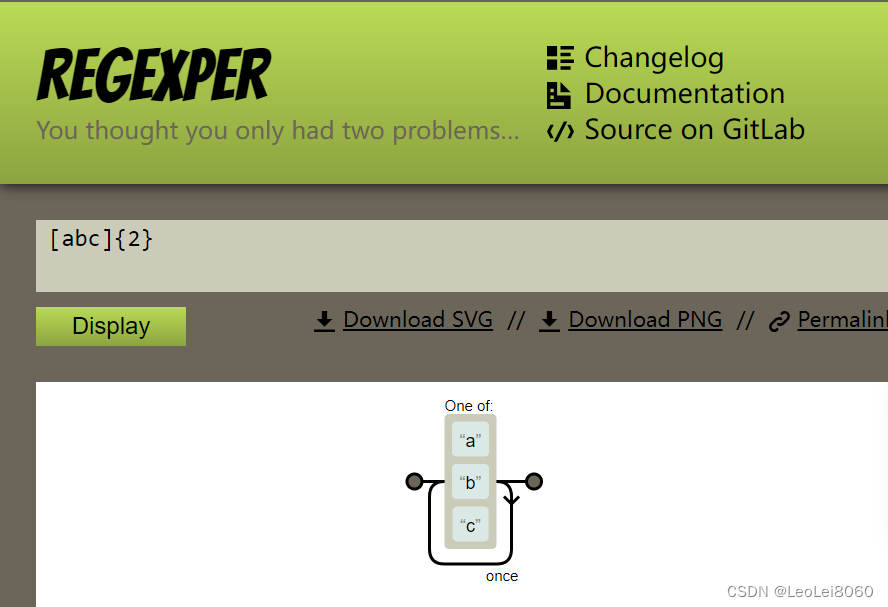
- https://regexper.com/
可以直观地理解正则表达式的逻辑:
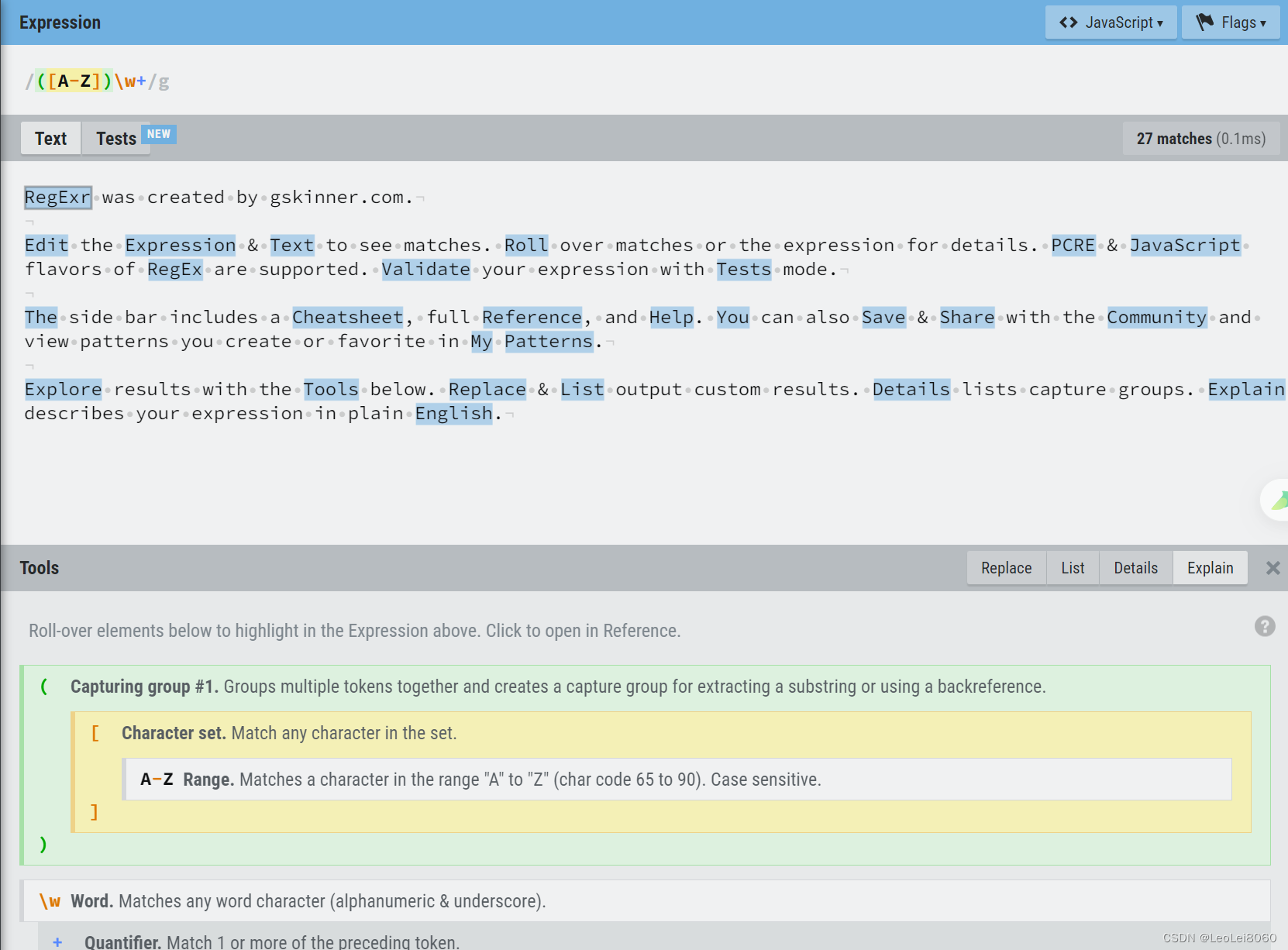
- https://regexr.com
通过该网站可以测试正则表达式的效果,并直观地看到匹配项:
相关文章:
快速入门C++正则表达式
正则表达式(Regular Expression,简称 Regex)是一种强大的文本处理工具,广泛用于字符串的搜索、替换、分析等操作。它基于一种表达式语言,使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。正则表达式不仅在…...

java —— 缓冲字符输入流/缓冲字符输出流
缓冲字符输入流/缓冲字符输出流是对字符输入流/字符输出流的加强,在使用中仍旧要借助于字符输入流/字符输出流才能完成实现。与字符输入流/字符输出流按照字符为单位进行输入/输出不同的是,缓冲字符输入流/缓冲字符输出流能够以行为单位进行读取和写入。…...

blender从视频中动作捕捉,绑定到人物模型
总共分为3个步骤: 1、从视频中捕捉动作模型 小K动画网-AIGC视频动捕平台 地址:https://xk.yunbovtb.com/ 需要注册 生成的FBX文件,不能直接导入到blender中, 方法有2种: 第一种:需要转换一下&#x…...

掘金滑块验证码安全升级,继续破解
去年发过一篇文章,《使用前端技术破解掘金滑块验证码》,我很佩服掘金官方的气度,不但允许我发布这篇文章,还同步发到了官方公众号。最近发现掘金的滑块验证码升级了,也许是我那篇文章起到了一些作用,逼迫官…...
数据结构练习题——Java实现
20240531-时间复杂度 1、消失的数字 方法一:位运算 两个数字一样的数组,其中一个数组中少了一个数字,定义一个变量分别异或两个数组,结果即为缺少的数字 class Solution {public int missingNumber(int[] nums) {int xor 0;int…...
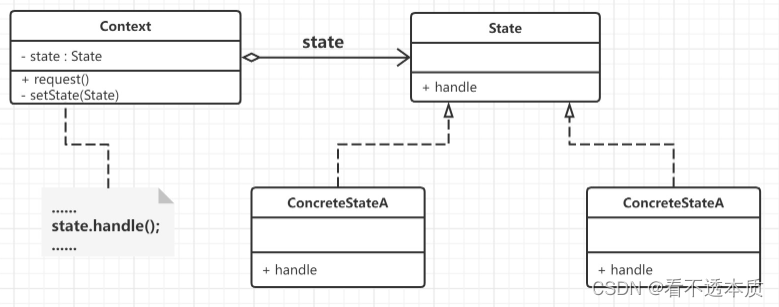
行为设计模式之状态模式
文章目录 概述定义结构图 2.代码示例小结 概述 定义 状态模式(state pattern)的定义: 允许一个对象在其内部状态改变时改变它的行为。 对象看起来似乎修改了它的类。 状态模式就是用于解决系统中复杂对象的状态转换以及不同状态下行为的封装问题.。状态模式将一个对象的状态…...
找回以前的视频:技术与实践3个指南
你们有没有发现现在视频已经成为我们生活中不可或缺的一部分了?不管是在工作场合做演示、在学习时看教学视频,还是在休闲娱乐时追剧看电影,视频都扮演着超级重要的角色。 然而误删或手机故障的发生很可能将以前的视频清除。本文将深入探讨手…...

GCN 代码解析(一) for pytorch
Graph Convolutional Networks 代码详解 前言一、数据集介绍二、文件整体架构三、GCN代码详解3.1 utils 模块3.2 layers 模块3.3 models 模块3.4 模型的训练代码 总结 前言 在前文中,已经对图卷积神经网络(Graph Convolutional Neural Networks, GCN&am…...

2024年云计算、信号处理与网络技术国际学术会议(ICCCSPNT 2024)
2024年云计算、信号处理与网络技术国际学术会议(ICCCSPNT 2024) 2024 International Academic Conference on Cloud Computing, Signal Processing, and Network Technology(ICCCSPNT 2024) 会议简介: 2024年云计算、…...
希尔排序法
希尔排序为插入排序的优化,即将数组分组,将每一组进行插入排序,每一组排成有序后,最后整体就变有序了。 上面gap2,即5,14,18,27,68为一组;13,20&a…...

thinkphp6.0版本下子查询sql处理
目录 一:背景 二:查询实例 三:总结 一:背景 我们在实际业务的开发过程中,经常会碰到这样的场景,查询某些部门的客户信息,查询下过订单的客户信息。这里查询客户信息实际上就用到了子查询&…...
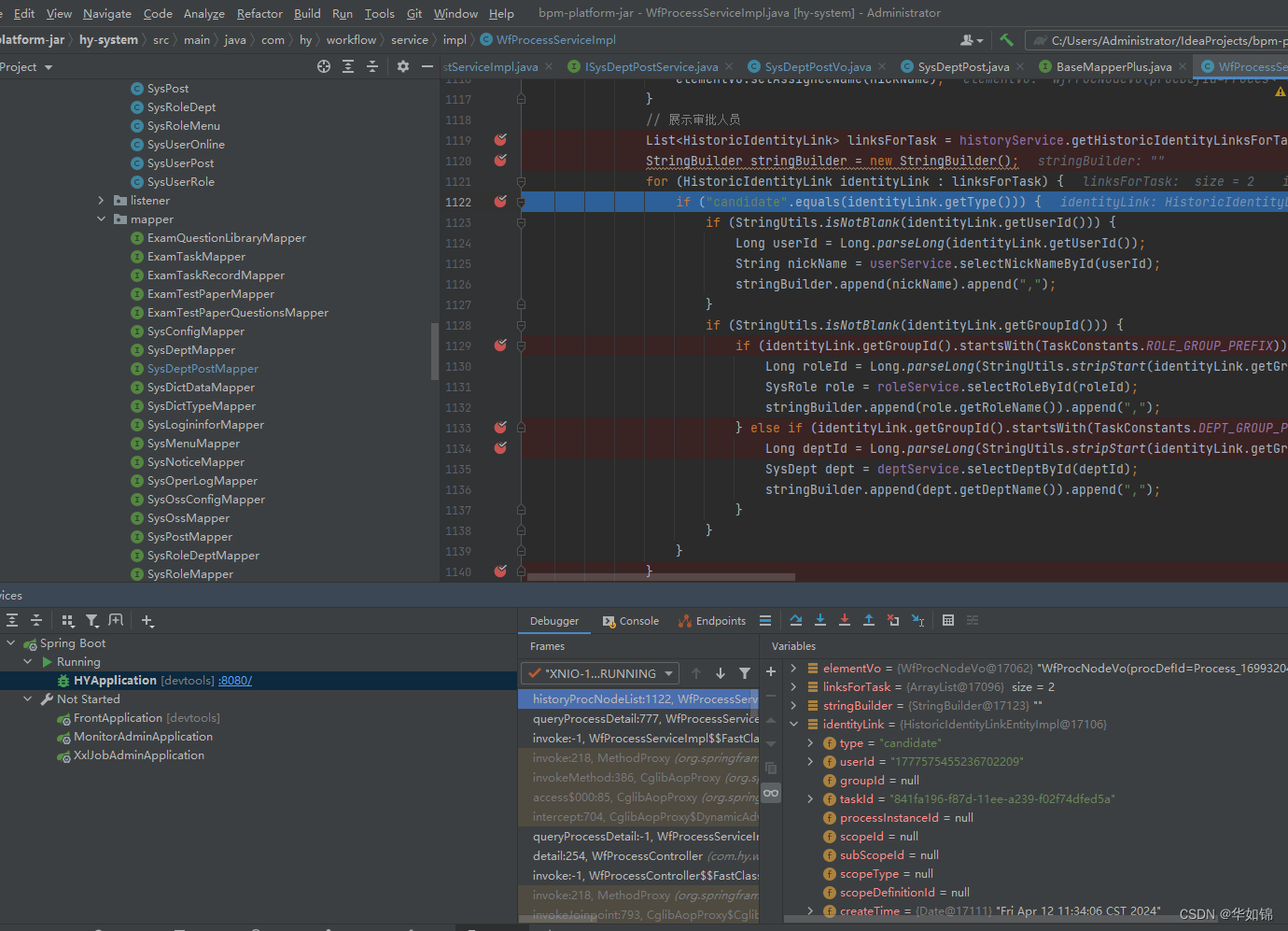
flowable工作流 完成任务代码 及扩展节点审核人(实现多级部门主管 审核等)详解【JAVA+springboot】
低代码项目 使用flowable 工作流 完成任务代码 详解 可以看到 complete()方法 传递了流程变量参数var 前端传递此参数就可以实现 流程中 审批 更新流程变量参数var 也可以进行更多扩展 实现流程中更新表单内容功能 启动流程实例代码 实现对于流程自定义 动态节点审核人 功…...

【电源专题】一体成型电感为什么需要注意耐压问题
对于电感,我们在电路上使用的很多,如升压、降压、滤波等电路中基本上使用到了电感。电感的种类有很多,电感从不同的角度会有不同的分类。如可以根据否屏蔽、工艺类型、磁性材料类型等可分为多类,这在文章:【分立元件】电感器(inductor)——简介中有做了一些简单的介绍。…...

如何看待时间序列与机器学习?
GPT-4o 时间序列与机器学习的关联在于,时间序列数据是一种重要的结构化数据形式,而机器学习则是一种强大的工具,用于从数据中提取有用的模式和信息。在很多实际应用中,时间序列与机器学习可以结合起来,发挥重要作用。…...

vue图标不显示
静态:有可能路径错误 <img src"../../assets/images/index1.png"> <img src"/assets/images/index2.png"> 动态:需要解析 <div v-for"item in userList" :key"item.id"> <img :src"getUrl(i…...

文件夹如何加密码全攻略,5个文件夹加密方法新手也能学
文件夹如何加密码?在这个互联网时代,隐私保护越来越受到大家的重视。我们在日常工作中,有时候会接触一些比较重要的文件,为了不让这些文件信息被泄露,所以我们可以给文件夹设置密码保护。那要怎么给文件夹设置密码呢&a…...

useState和store的区别
useState 和 useStore 是 React 应用中用于管理数据状态的两种不同的 Hook。它们在功能和用途上有一些区别: useState useState 是 React 提供的一个 Hook,用于在函数组件中添加局部状态。每个 useState 调用都会返回一个数组,包含两个元素…...
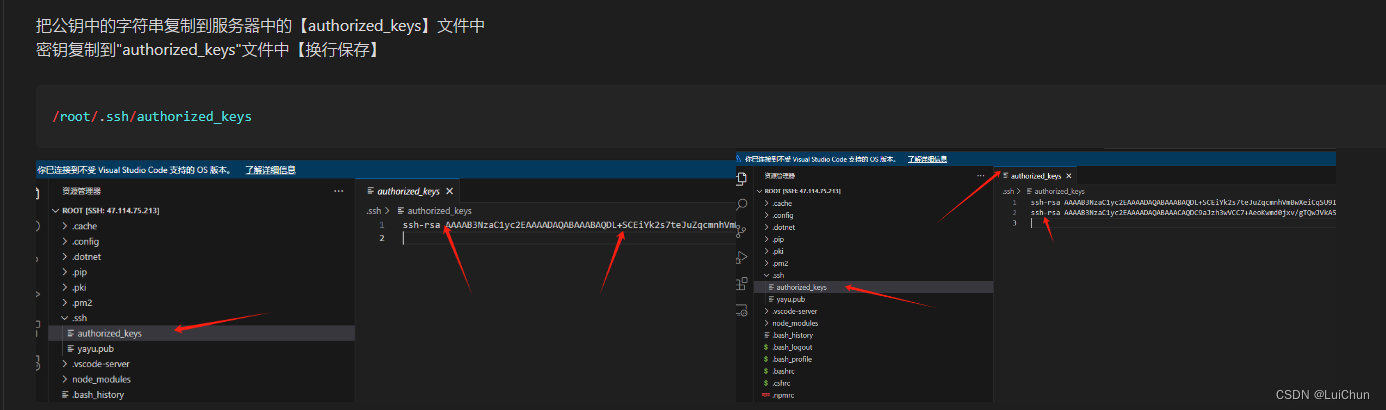
vscode远程登录阿里云服务器【使用密钥方式--后期无需再进行密码登录】【外包需要密码】
1:windows主机上生成【私钥】【公钥】 1.1生成公钥时不设置额外密码 1.2生成公钥时设置额外密码【给外包人员使用的方法】 2:在linux服务器中添加【公钥】 3:本地vscode连接linux服务器的配置 操作流程如下 1.1本地终端中【生成免密登录…...

解决uniapp里的onNavigationBarSearchInputClicked不生效
如何在uniapp里使用onNavigationBarSearchInputClicked。 1、在page.json里配置 "pages": [{"path": "pages/index/index","style": {"navigationBarTitleText": "首页","navigationStyle": "cu…...

Windows下搭建Cmake编译环境进行C/C++文件的编译
文章目录 1.下载Cmake2.安装MinGW-w643.进行C/C文件的编译 1.下载Cmake 网址:https://cmake.org/download/ 下载完成后安装,勾选“Add CMake to the system PATH for the current user" 点击Finish完成安装,在cmd窗口验证一下是否安…...

网站纠错页面对 SEO 有什么作用_网站图片和视频优化对 SEO 有什么技巧
网站纠错页面对 SEO 有什么作用 在网站管理和搜索引擎优化(SEO)方面,纠错页面的作用常常被忽视。网站纠错页面实际上对 SEO 有着重要的影响。当用户访问一个网站时,如果遇到 404 错误(页面未找到)或其他错…...

Pandas索引器 loc 和 iloc 比较及代码示例
Pandas 索引器 loc 和 iloc 比较及代码示例 以下是针对 Pandas 中 loc 和 iloc 的深度对比分析及代码示例,结合核心差异、使用场景和底层机制展开说明: 一、核心差异解析 特性loc (标签索引)iloc (位置索引)索引类型行/列标签(字符串、日期等…...

千问3.5-27B中文优化实践:提升OpenClaw指令理解准确率
千问3.5-27B中文优化实践:提升OpenClaw指令理解准确率 1. 为什么需要专门优化中文指令理解 上周我在用OpenClaw整理项目文档时,发现一个有趣现象:当我用英文说"organize these PDFs by date"时,AI能准确按日期分类文件…...

测试流程图显示
一、原理解析 / 概念介绍 1.1 自动化序列化流水线 hive_generator 处于开发链路的“后台”,负责将 Dart 对象转换为 Hive 识别的二进制流编码逻辑。 #mermaid-svg-bbx9YEu5DFSBhCuG{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;…...

STM32精准延时实现与Keil调试技巧
1. 精准延时在单片机开发中的重要性在STM32等嵌入式系统开发中,精准延时是基础但至关重要的功能。我最近调试一块自制的STM32开发板时,就遇到了需要精确控制时序的场景。比如在驱动LCD屏幕时,某些控制信号需要维持15ms的精确延时,…...

程序员副业指南:从技术到变现全攻略
CSDN程序员副业图谱技术文章大纲副业图谱概述副业图谱的定义与背景CSDN平台在程序员副业中的作用副业图谱的核心价值(技能变现、职业发展等)常见程序员副业类型技术博客与内容创作(如CSDN专栏、公众号)在线教育与课程开发…...

新手学吉他必看,这5个常见误区,避开了少走3个月弯路
经常会看到很多新手学吉他,学着学着就卡壳学不下去了,不是嫌按弦手疼,就是曲子弹不下去。特别是一些自学的朋友,网上随便东找些课,西看些视频,学下来进步很慢,3个月之后就改打“退堂鼓”了。其实…...


大厂真实高频的 LLM 大模型面试 36 题例题详解
一、基础原理篇(8 题) 1. 什么是 Transformer?核心结构是什么? 答:Transformer 是基于自注意力机制的 seq2seq 模型,完全替代 RNN 结构。核心结构: Encoder(编码)+ Decoder(解码) 多头注意力(Multi-Head Attention) 前馈网络 FFN 层归一化、残差连接举例:GPT 只…...

宽带任意阶贝塞尔光束模型与超表面实现案例
宽带任意阶 贝塞尔光束 超表面 模型 fdtd 案例内容:主要包括文章的两个贝塞尔光束模型,一个零阶贝塞尔光束一个一阶贝塞尔光束,采用二氧化钛介质单元执行几何相位来构建; 案例包括fdtd模型、fdtd设计脚本、Matlab计算代码和复现结…...