GCN 代码解析(一) for pytorch
Graph Convolutional Networks 代码详解
- 前言
- 一、数据集介绍
- 二、文件整体架构
- 三、GCN代码详解
- 3.1 utils 模块
- 3.2 layers 模块
- 3.3 models 模块
- 3.4 模型的训练代码
- 总结
前言
在前文中,已经对图卷积神经网络(Graph Convolutional Neural Networks, GCN)的理论基础进行了深入探讨。接下来的章节将会进入新的阶段——将借助PyTorch,这一强大的深度学习框架,通过实战讲解来展示如何构建和训练一个图卷积神经网络。这一过程不仅将帮助读者巩固理论知识,更重要的是,它将引导读者迈出理论到实践的关键一步,从而在处理具有图结构数据的问题上实现质的飞跃。
通过本章节的学习,希望读者能够掌握图神经网络在代码层面的具体实现方法,并通过实际编码练习来加深对图神经网络工作原理的理解。我们将从数据准备开始,逐步深入到模型构建、训练和评估等核心环节,最终实现一个功能完整的图卷积神经网络项目。
一、数据集介绍
在学习模型是如何工作之前要明确模型的任务是什么?本文使用的是使用论文引用数据集中从而完成论文的分类任务。
首先看下数据集的形态,这个目录包含了Cora数据集(www.research.whizbang.com/data)的一个部分选择。
Cora数据集由机器学习论文组成。这些论文被分类为以下七个类别之一:
- 基于案例的(Case_Based)
- 遗传算法(Genetic_Algorithms)
- 神经网络(Neural_Networks)
- 概率方法(Probabilistic_Methods)
- 强化学习(Reinforcement_Learning)
- 规则学习(Rule_Learning)
- 理论(Theory)
选择论文的方式是,最终的语料库中每篇论文至少引用或被至少一篇其他论文引用。整个语料库中共有2708篇论文。
经过词干提取和去除停用词后,我们得到了一个包含1433个唯一词汇的词汇表。所有文档频率小于10的词汇都被移除。
目录包含两个文件:

.content文件包含论文的描述,格式如下:
<paper_id> <word_attributes>+ <class_label>
文件预览入下图:

每行的第一个条目包含论文的唯一字符串ID,后面是二进制值,指示词汇表中的每个单词是否出现在论文中(出现则表示为1,缺乏则表示为0)。最后,行中的最后一个条目包含论文的类别标签。
.cites文件包含语料库的引用图。每行以以下格式描述一个链接:
<ID of cited paper><ID of citing paper>
每行包含两个论文ID。第一个条目是被引用论文的ID,第二个ID代表包含引用的论文。链接的方向是从右向左。如果一行表示为“paper1 paper2”,则链接是“paper2->paper1”。
文件预览形式如下:

二、文件整体架构
为了深入学习图卷积神经网络(GCN)的编码实践,本章节将借助脑图形式,详细总结代码文件中的关键模块及其相互关联。这样做旨在将代码的各个组成部分串联起来,使得学习路径更加系统化。故此讲解的过程中也是按照脑图的顺序进行梳理,从而对代码具备一个全面正确的认识。

模型的训练启动于utils文件,它负责对原始数据执行预处理步骤,生成便于模型训练和操作的格式化数据。接着,在layers文件中,我们按照GCN论文的指导,精心构建了图卷积网络层。这些网络层随后在models文件中被整合起来,形成一个完整的图卷积神经网络架构。最后,在train脚本中,我们执行模型的训练和评估,完成了从数据预处理到模型应用的整个流程。
三、GCN代码详解
接下来,将根据之前提及的不同文件及其顺序,深入剖析整个图卷积神经网络(GCN)的代码实现。这一过程将揭示每个组件的功能及其在整个模型中所扮演的角色。
3.1 utils 模块
import numpy as np
import scipy.sparse as sp
import torch
在模型的初始阶段,首先导入三个关键的库来处理数据和构建模型:
-
numpy:此库非常适合进行高效的**矩阵运算和数学处理。**通过导入为np,调用NumPy库提供的各种数学功能,它是Python科学计算的基石。 -
scipy.sparse:通常简称为sp,这个模块专注于稀疏矩阵的操作。在处理图数据时,邻接矩阵往往是稀疏的,使用稀疏矩阵能够有效地提升存储和计算效率。 -
torch:作为PyTorch框架的核心,它提供了一系列深度学习的基本工具和操作。使用PyTorch中的数据结构和函数,我们可以将数据转换为张量格式,并利用GPU加速计算过程。
通过这三个库的结合,能够高效地处理图数据,并将其转换为适用于PyTorch的格式,为图卷积神经网络的建模打下基础。
def encode_onehot(labels):classes = set(labels) # a = set('abracadabra') 去除重复元素 >>> a # {'a', 'r', 'b', 'c', 'd'}classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)} # 创建一个字典用来存放所有类别对应的独热编码'''import numpy as npa=np.identity(3)
print(a)# result[[1. 0. 0.][0. 1. 0.][0. 0. 1.]]'''labels_onehot = np.array(list(map(classes_dict.get, labels)), # map() 会根据提供的函数对指定序列做映射。dtype=np.int32)return labels_onehot
以上代码展示了将标签转换成独热编码的过程。
def normalize(mx):"""Row-normalize sparse matrix"""rowsum = np.array(mx.sum(1)) # 按行求和r_inv = np.power(rowsum, -1).flatten() # 倒数拉长并且降维r_inv[np.isinf(r_inv)] = 0. # 将所有无穷∞大的量替换为0r_mat_inv = sp.diags(r_inv)
'''diagonals = [[1, 2, 3, 4], [1, 2, 3], [1, 2]]
# 使用diags函数,该函数的第二个变量为对角矩阵的偏移量,
0:代表不偏移,就是(0,0)(1,1)(2,2)(3,3)...这样的方式写
k:正数:代表像正对角线的斜上方偏移k个单位的那一列对角线上的元素。
-k:负数,代表向正对角线的斜下方便宜k个单位的那一列对角线上的元素,由此看下边输出diags(diagonals, [0, -1, 2]).toarray()
array([[1, 0, 1, 0],[1, 2, 0, 2],[0, 2, 3, 0],[0, 0, 3, 4]])'''mx = r_mat_inv.dot(mx) # 矩阵乘法运算return mx # 返回归一化后的数据
def sparse_mx_to_torch_sparse_tensor(sparse_mx):"""Convert a scipy sparse matrix to a torch sparse tensor."""sparse_mx = sparse_mx.tocoo().astype(np.float32) # 将数据变成稀疏矩阵np类型indices = torch.from_numpy( # 索引 np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))values = torch.from_numpy(sparse_mx.data)# 数值shape = torch.Size(sparse_mx.shape) # 形状return torch.sparse.FloatTensor(indices, values, shape) # 变成torch的稀疏矩阵
def load_data(path="../data/cora/", dataset="cora"):"""Load citation network dataset (cora only for now)"""print('Loading {} dataset...'.format(dataset))
# 下面的idx_features_labels 打开的文件之所以是索引特征和标签简明文件存放的内容idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset), # 指定文件路径dtype=np.dtype(str)) # 指定文件类型features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32) # 0是索引-1是标签 # 使用索引取数值的时候左侧一定能取到右侧表示取不到的位置labels = encode_onehot(idx_features_labels[:, -1]) # 最后一列是标签# build graph '''重点构建图 #######################################################'''idx = np.array(idx_features_labels[:, 0], dtype=np.int32) # 取content文件中的第一列,就是找出有类别文件中的索引信息idx_map = {j: i for i, j in enumerate(idx)} # 对所有论文进行编码 存入字典中。输入论文编码就知道创建的索引信息----现阶段的目的是计算邻接矩阵的行列信息edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset), # 导入边信息dtype=np.int32)edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),# 将引用信息文件中的论文编码全部换成了索引信息dtype=np.int32).reshape(edges_unordered.shape) # 一开始展开的目的是需要序列数据,现在再次reshapeadj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(labels.shape[0], labels.shape[0]),dtype=np.float32) # 创建稀疏矩阵coo类型的adj,只需要给存在数据的行和列的数据以及数值,并且定义了类型和shape大小
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
这行代码是在构建一个对称的邻接矩阵adj。在图卷积神经网络中,邻接矩阵用于表示图中节点之间的连接关系。对于无向图而言,其邻接矩阵是对称的,即如果节点i与节点j相连,则adj[i, j]和adj[j, i]的值都应该为1。
然而,在创建初始邻接矩阵时,可能会存在一些不对称的情况,即adj[i, j]不等于adj[j, i]。为了纠正这种不对称性并确保邻接矩阵的一致性,需要进行以下操作:
-
adj + adj.T:首先,将邻接矩阵adj与其转置adj.T相加,确保所有的连接是双向的。 -
adj.T.multiply(adj.T > adj):计算adj的转置减去adj只在转置矩阵中的元素大于原矩阵时才计算,这样可以获取所有adj矩阵未能覆盖的对应连接。 -
- adj.multiply(adj.T > adj):从第一个步骤的结果中减去只有在adj的元素小于adj.T时才存在的元素,以避免重复计数任何连接。
最终结果是一个对称的邻接矩阵,完美地表示无向图的连接关系。这保证了当我们在图网络中传播信息时,连接的权重是相互的,并且流向节点i和节点j的信息是等价的。
features = normalize(features) # 特征归一化adj = normalize(adj + sp.eye(adj.shape[0])) # 邻接矩阵加上对角线idx_train = range(140) # 划分数据集idx_val = range(200, 500)idx_test = range(500, 1500)features = torch.FloatTensor(np.array(features.todense()))labels = torch.LongTensor(np.where(labels)[1]) # 取出数值为1的索引,就是真实labeladj = sparse_mx_to_torch_sparse_tensor(adj)idx_train = torch.LongTensor(idx_train)idx_val = torch.LongTensor(idx_val)idx_test = torch.LongTensor(idx_test)return adj, features, labels, idx_train, idx_val, idx_test
def accuracy(output, labels): # 准确率计算preds = output.max(1)[1].type_as(labels)correct = preds.eq(labels).double()correct = correct.sum()return correct / len(labels)
3.2 layers 模块
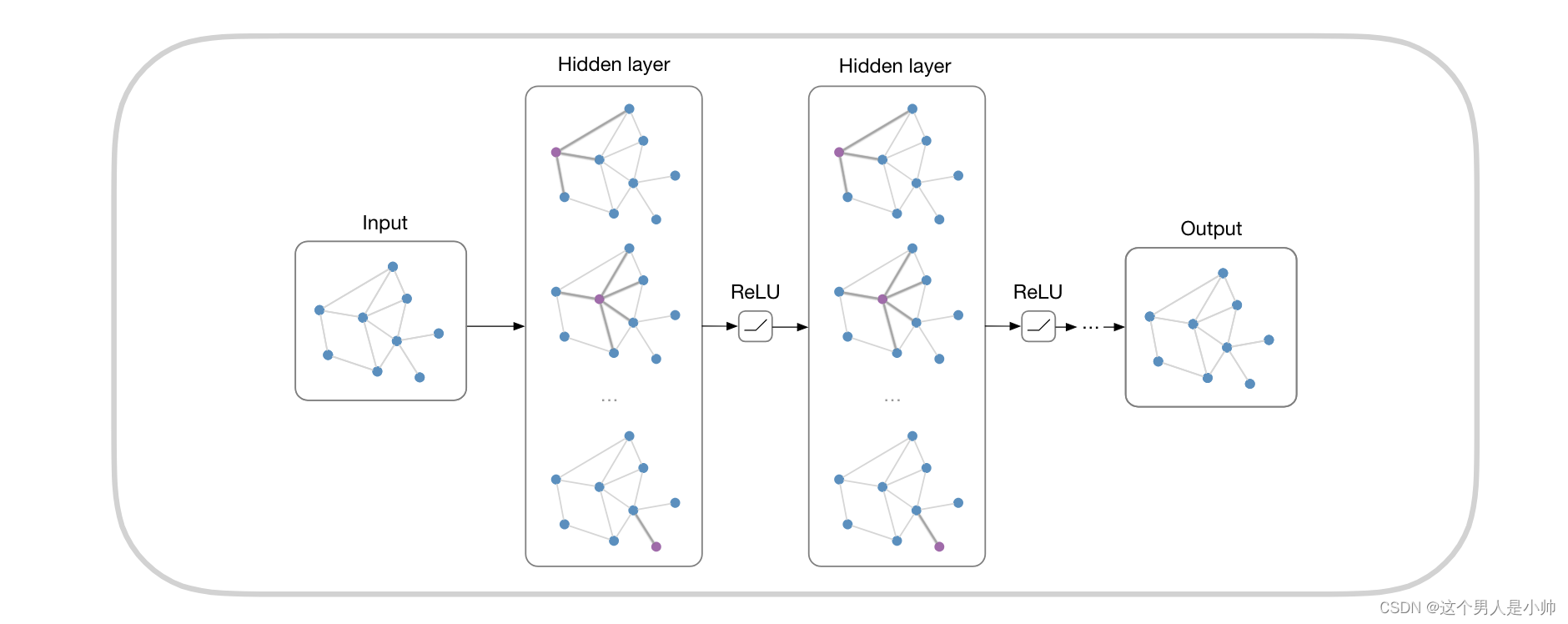
此模块定义了一个简单的图卷积网络层(GCN层),它实现了基本的图卷积操作,类似于在文献中所描述的原始GCN层。主要组件包括权重矩阵和可选偏置,其中权重矩阵通过一定的初始化策略进行参数初始化。在前向传递函数中,输入特征与权重矩阵相乘以获得支持(支持表示节点特征的转换),然后通过图的邻接矩阵进行传播,如果定义了偏置,将其添加到输出中。这样的层可以被堆叠使用来构建深层图神经网络。
import math #提供各种各样的数学擦欧总
import torch
from torch.nn.parameter import Parameter # 构建的参数可以求梯度
from torch.nn.modules.module import Module # 创建神经网络的基类
class GraphConvolution(Module):def __init__(self, in_features, out_features, bias=True): # 网络的输入和输出大小,是否引入偏置项super(GraphConvolution, self).__init__()self.in_features = in_featuresself.out_features = out_featuresself.weight = Parameter(torch.FloatTensor(in_features, out_features)) # 设置权重参数的维度if bias:self.bias = Parameter(torch.FloatTensor(out_features))else:self.register_parameter('bias', None)self.reset_parameters()def reset_parameters(self): # 控制权重随机的范围stdv = 1. / math.sqrt(self.weight.size(1))self.weight.data.uniform_(-stdv, stdv)if self.bias is not None:self.bias.data.uniform_(-stdv, stdv)def forward(self, input, adj):support = torch.mm(input, self.weight)output = torch.spmm(adj, support)if self.bias is not None:return output + self.biaselse:return outputdef __repr__(self): # 设置一个魔法方法,用于检测当前对象的输入输出大小,通过输出对象的方式return self.__class__.__name__ + ' (' \+ str(self.in_features) + ' -> ' \+ str(self.out_features) + ')'def reset_parameters(self): # 控制权重随机的范围,现在解释下:
假设我们在构建一个图卷积网络层,其输入特征维度为100(即每个节点的特征向量长度为100),输出特征维度也设置为100,那么权重矩阵self.weight的大小将是(100, 100),表示从输入特征到输出特征的线性变换。
-
计算标准差 (
stdv):- 首先,
self.weight.size(1)得到的是权重矩阵的第二维大小,即100。 - 然后,
math.sqrt(self.weight.size(1))计算输入特征维度100的平方根,即10。 - 最后,
1. / math.sqrt(self.weight.size(1))计算了10的倒数,得到stdv = 0.1。这个值用作初始化权重和偏置参数的均匀分布的标准差。
- 首先,
-
初始化权重 (
self.weight.data.uniform_(-stdv, stdv)):- 使用上一步计算得到的
stdv = 0.1,权重被初始化为在[-0.1, 0.1]之间的均匀分布。这意味着每个权重值都会随机地从这个区间中选取一个数值。
- 使用上一步计算得到的
-
初始化偏置 (
self.bias.data.uniform_(-stdv, stdv)):- 如果偏置不为
None,即模型选择使用偏置项,偏置也会被初始化为在[-0.1, 0.1]之间的均匀分布。这里的偏置是一个长度为输出特征维度,即100的向量。
- 如果偏置不为
通过这种方式初始化参数,保证了模型参数在一开始不会太大或太小,有利于优化算法更好、更快地找到误差的全局最小值,从而提高模型训练的效率和性能。‘
3.3 models 模块
该模块下的代码,定义了一个使用图卷积层构建的简单图卷积网络(GCN)架构,体现了GCN模型的典型结构和数据流动方式。
import torch.nn as nn
import torch.nn.functional as F # torch.nn 和nn.functional主要区别一个是类一个是函数,类需要实例化调用。
from pygcn.layers import GraphConvolution # 导入自建包class GCN(nn.Module):def __init__(self, nfeat, nhid, nclass, dropout):super(GCN, self).__init__()self.gc1 = GraphConvolution(nfeat, nhid)self.gc2 = GraphConvolution(nhid, nclass)self.dropout = dropoutdef forward(self, x, adj):x = F.relu(self.gc1(x, adj))x = F.dropout(x, self.dropout, training=self.training)x = self.gc2(x, adj)return F.log_softmax(x, dim=1)
3.4 模型的训练代码
from __future__ import division # __future__可以理解成一个先行版,在这里得到版本是先行版
from __future__ import print_functionimport time
import argparse # 用于参数调用
import numpy as npimport torch
import torch.nn.functional as F
import torch.optim as optim from pygcn.utils import load_data, accuracy # 两部的都是自己写的
from pygcn.models import GCN
# Training settings
parser = argparse.ArgumentParser() # 对类进行实例化,这个类的特殊在于能够处理命令行的输入
parser.add_argument('--no-cuda', action='store_true', default=False,help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False,help='Validate during training pass.')
parser.add_argument('--seed', type=int, default=42, help='Random seed.')
parser.add_argument('--epochs', type=int, default=200,help='Number of epochs to train.')
parser.add_argument('--lr', type=float, default=0.01,help='Initial learning rate.')
parser.add_argument('--weight_decay', type=float, default=5e-4,help='Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden', type=int, default=16,help='Number of hidden units.')
parser.add_argument('--dropout', type=float, default=0.5,help='Dropout rate (1 - keep probability).')args = parser.parse_args() #对参数进行分析
args.cuda = not args.no_cuda and torch.cuda.is_available()
np.random.seed(args.seed) # 随机数种子设置
torch.manual_seed(args.seed)
if args.cuda:torch.cuda.manual_seed(args.seed)
# Load data
adj, features, labels, idx_train, idx_val, idx_test = load_data() # 给地址# Model and optimizer
model = GCN(nfeat=features.shape[1],# 实例化模型nhid=args.hidden,nclass=labels.max().item() + 1,dropout=args.dropout)
optimizer = optim.Adam(model.parameters(),# 实例化优化器lr=args.lr, weight_decay=args.weight_decay)if args.cuda:model.cuda()features = features.cuda()adj = adj.cuda()labels = labels.cuda()idx_train = idx_train.cuda()idx_val = idx_val.cuda()idx_test = idx_test.cuda()def train(epoch):t = time.time()model.train()optimizer.zero_grad()output = model(features, adj)loss_train = F.nll_loss(output[idx_train], labels[idx_train])acc_train = accuracy(output[idx_train], labels[idx_train])loss_train.backward()optimizer.step()if not args.fastmode:# Evaluate validation set performance separately,# deactivates dropout during validation run.model.eval()output = model(features, adj)loss_val = F.nll_loss(output[idx_val], labels[idx_val])acc_val = accuracy(output[idx_val], labels[idx_val])print('Epoch: {:04d}'.format(epoch+1),'loss_train: {:.4f}'.format(loss_train.item()),'acc_train: {:.4f}'.format(acc_train.item()),'loss_val: {:.4f}'.format(loss_val.item()),'acc_val: {:.4f}'.format(acc_val.item()),'time: {:.4f}s'.format(time.time() - t))def test():model.eval()output = model(features, adj)loss_test = F.nll_loss(output[idx_test], labels[idx_test])acc_test = accuracy(output[idx_test], labels[idx_test])print("Test set results:","loss= {:.4f}".format(loss_test.item()),"accuracy= {:.4f}".format(acc_test.item()))# Train model
t_total = time.time()
for epoch in range(args.epochs):train(epoch)
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))# Testing
test()
上述部分和其他深度学习代码并无差异如果感兴趣可以参考pytorch模块下的作业代码深入理解。
总结
当前代码主要的工作量就是在数据的处理以及网络的构建,其他并无明显差异,在图卷积网络(GCN)和图神经网络(GNN)的构建与学习过程中,数据的处理和网络架构的设计无疑是占据主要工作量的两大核心领域。这些任务之所以充满挑战,很大程度上在于需要精巧地表征和处理具有图结构的数据,并创新性地构建能够捕捉其复杂模式的网络结构。为了更有效地提高模型性能,学习过程中应着重关注和深入探索网络搭建和数据预处理的相关知识和技术。通过对这些关键部分进行深刻理解和不断练习,可以实现模型效率的显著提升,并且更好地将理论应用于解决实际问题。
相关文章:
GCN 代码解析(一) for pytorch
Graph Convolutional Networks 代码详解 前言一、数据集介绍二、文件整体架构三、GCN代码详解3.1 utils 模块3.2 layers 模块3.3 models 模块3.4 模型的训练代码 总结 前言 在前文中,已经对图卷积神经网络(Graph Convolutional Neural Networks, GCN&am…...

2024年云计算、信号处理与网络技术国际学术会议(ICCCSPNT 2024)
2024年云计算、信号处理与网络技术国际学术会议(ICCCSPNT 2024) 2024 International Academic Conference on Cloud Computing, Signal Processing, and Network Technology(ICCCSPNT 2024) 会议简介: 2024年云计算、…...
希尔排序法
希尔排序为插入排序的优化,即将数组分组,将每一组进行插入排序,每一组排成有序后,最后整体就变有序了。 上面gap2,即5,14,18,27,68为一组;13,20&a…...

thinkphp6.0版本下子查询sql处理
目录 一:背景 二:查询实例 三:总结 一:背景 我们在实际业务的开发过程中,经常会碰到这样的场景,查询某些部门的客户信息,查询下过订单的客户信息。这里查询客户信息实际上就用到了子查询&…...
flowable工作流 完成任务代码 及扩展节点审核人(实现多级部门主管 审核等)详解【JAVA+springboot】
低代码项目 使用flowable 工作流 完成任务代码 详解 可以看到 complete()方法 传递了流程变量参数var 前端传递此参数就可以实现 流程中 审批 更新流程变量参数var 也可以进行更多扩展 实现流程中更新表单内容功能 启动流程实例代码 实现对于流程自定义 动态节点审核人 功…...

【电源专题】一体成型电感为什么需要注意耐压问题
对于电感,我们在电路上使用的很多,如升压、降压、滤波等电路中基本上使用到了电感。电感的种类有很多,电感从不同的角度会有不同的分类。如可以根据否屏蔽、工艺类型、磁性材料类型等可分为多类,这在文章:【分立元件】电感器(inductor)——简介中有做了一些简单的介绍。…...

如何看待时间序列与机器学习?
GPT-4o 时间序列与机器学习的关联在于,时间序列数据是一种重要的结构化数据形式,而机器学习则是一种强大的工具,用于从数据中提取有用的模式和信息。在很多实际应用中,时间序列与机器学习可以结合起来,发挥重要作用。…...

vue图标不显示
静态:有可能路径错误 <img src"../../assets/images/index1.png"> <img src"/assets/images/index2.png"> 动态:需要解析 <div v-for"item in userList" :key"item.id"> <img :src"getUrl(i…...

文件夹如何加密码全攻略,5个文件夹加密方法新手也能学
文件夹如何加密码?在这个互联网时代,隐私保护越来越受到大家的重视。我们在日常工作中,有时候会接触一些比较重要的文件,为了不让这些文件信息被泄露,所以我们可以给文件夹设置密码保护。那要怎么给文件夹设置密码呢&a…...

useState和store的区别
useState 和 useStore 是 React 应用中用于管理数据状态的两种不同的 Hook。它们在功能和用途上有一些区别: useState useState 是 React 提供的一个 Hook,用于在函数组件中添加局部状态。每个 useState 调用都会返回一个数组,包含两个元素…...
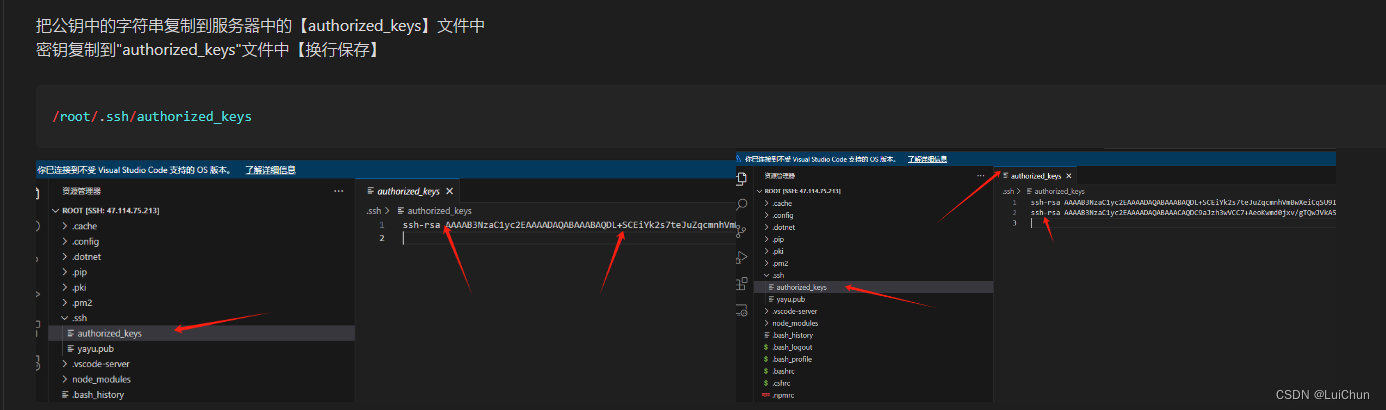
vscode远程登录阿里云服务器【使用密钥方式--后期无需再进行密码登录】【外包需要密码】
1:windows主机上生成【私钥】【公钥】 1.1生成公钥时不设置额外密码 1.2生成公钥时设置额外密码【给外包人员使用的方法】 2:在linux服务器中添加【公钥】 3:本地vscode连接linux服务器的配置 操作流程如下 1.1本地终端中【生成免密登录…...

解决uniapp里的onNavigationBarSearchInputClicked不生效
如何在uniapp里使用onNavigationBarSearchInputClicked。 1、在page.json里配置 "pages": [{"path": "pages/index/index","style": {"navigationBarTitleText": "首页","navigationStyle": "cu…...

Windows下搭建Cmake编译环境进行C/C++文件的编译
文章目录 1.下载Cmake2.安装MinGW-w643.进行C/C文件的编译 1.下载Cmake 网址:https://cmake.org/download/ 下载完成后安装,勾选“Add CMake to the system PATH for the current user" 点击Finish完成安装,在cmd窗口验证一下是否安…...

实用新型专利申请材料的撰写与准备
在科技创新日益活跃的今天,实用新型专利的申请与保护显得尤为重要。实用新型专利作为一种重要的知识产权形式,对于推动科技进步、促进经济发展具有重要意义。 首先我们需要明确实用新型专利的定义。实用新型专利是指对产品的形状、构造或者其结合所提出…...

代码随想录算法训练营第60天|● 84.柱状图中最大的矩形
84. 柱状图中最大的矩形 和昨天的思路完全一样 单调栈直接解了 双指针法特别麻烦 class Solution:def largestRectangleArea(self, heights: List[int]) -> int:heights.insert(0,0)heights.append(0)stack[0]res0for i in range(1,len(heights)):while stack and heights…...

让AI给你写代码(9.3):一点改进,支持扩展本地知识库
改进目标,当输入提示问题后,能匹配到本地知识库的需求,然后AI按匹配到的需求给出代码并进行自动测试; 如果无法匹配到本地需求,可以直接输入生成逻辑,再由AI生成,然后支持用户把新需求插入本地库…...

探索煤化工厂巡检机器人的功能、应用及前景
大家都知道、煤化工厂是以煤为原料生产化工产品的工厂,存在易燃易爆、高温、中毒等隐患等。因此,对煤化工厂进行巡检是非常必要的。巡检旨在是定时对厂内设备运行异常、泄漏等问题,并及时进行处理,保障工作场所的安全。除了以上存…...

【活动】GPT-4O:AI语言生成技术的新里程碑
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 GPT-4O:AI语言生成技术的新里程碑引言GPT系列简史回顾GPT-1: 初露锋…...
实验笔记之——DPVO(Deep Patch Visual Odometry)
本博文记录本文测试DPVO的过程,本博文仅供本人学习记录用~ 《Deep Patch Visual Odometry》 代码链接:GitHub - princeton-vl/DPVO: Deep Patch Visual Odometry 目录 配置过程 测试记录 参考资料 配置过程 首先下载代码以及创建conda环境 git clo…...
力扣----轮转数组
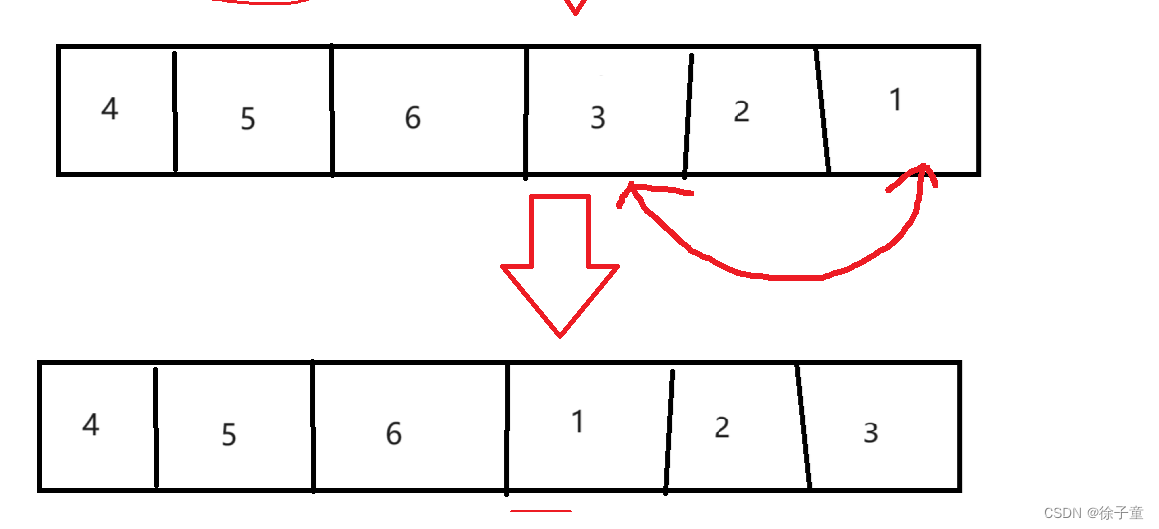
题目链接:189. 轮转数组 - 力扣(LeetCode) 思路一 我们可以在进行每次轮转的时候,先将数组的最后一个数据的值存储起来,接着将数组中前n-1个数据依次向后移,最后将存储起来的值赋给数组中的第一个数据。 …...

Fish-Speech-1.5与LLM集成:构建智能对话系统的完整指南
Fish-Speech-1.5与LLM集成:构建智能对话系统的完整指南 1. 引言 想象一下,你正在开发一个智能客服系统,用户用语音提问,系统不仅能理解问题,还能用自然流畅的语音回答。这听起来像是科幻电影里的场景,但现…...

突破网盘下载瓶颈:技术工具革新文件获取效率
突破网盘下载瓶颈:技术工具革新文件获取效率 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 / 迅…...

Wan2.2-I2V-A14B多场景应用:文旅宣传/电商主图/社交媒体动态生成
Wan2.2-I2V-A14B多场景应用:文旅宣传/电商主图/社交媒体动态生成 1. 开箱即用的视频创作利器 想象一下,你只需要输入一段文字描述,就能自动生成一段高清视频。这就是Wan2.2-I2V-A14B文生视频模型带来的革命性体验。无论你是文旅行业的宣传人…...
)
从LVGL菜单组件反推:手搓一个轻量级C语言菜单框架(适合RTOS/单片机)
从LVGL菜单组件反推:手搓一个轻量级C语言菜单框架(适合RTOS/单片机) 在嵌入式开发中,菜单系统是人机交互的重要组成部分。虽然LVGL等GUI库提供了现成的菜单组件,但理解其底层实现原理对于开发资源受限的MCU应用至关重要…...

嵌入式软件缺陷预防与设计规范实战指南
1. 嵌入式软件缺陷预防与设计规范作为一名在嵌入式领域摸爬滚打多年的工程师,我见过太多因为软件缺陷导致的灾难性后果。从航天器失联到医疗设备故障,这些事故背后往往都隐藏着本可以在设计阶段就规避的代码问题。今天我想分享的是:为什么一个…...

广州PMP培训机构怎么选?才聚是标准答案
选广州PMP培训机构,核心看官方授权、师资、通过率、本地化服务、学考一体化,才聚在广州确实是综合实力最强、最稳妥的 “标准答案”。 一、在选择时,可以从下面几个方面来评估一家培训机构,看看哪家更适合你: 官方授权…...

解锁论文写作新姿势:书匠策AI,你的期刊论文智囊团
在学术的浩瀚海洋中,每一位探索者都渴望拥有一盏明灯,照亮前行的道路。对于广大教育领域的学者、研究生乃至本科生而言,撰写一篇高质量的期刊论文不仅是学术能力的体现,更是通往更高学术殿堂的钥匙。然而,面对繁琐的选…...
)
LeRobot数据采集全流程解析:从环境配置到动作回放(SO-100实战)
LeRobot数据采集全流程实战:从环境搭建到动作复现的SO-100深度指南 当我们需要让机器人学会新技能时,数据采集是构建智能系统的第一步。LeRobot作为Hugging Face推出的机器人学习平台,通过标准化流程降低了开发门槛。本文将带你完整走通SO-10…...

深度解析jqktrader:基于Python的同花顺自动化交易架构设计与实战应用
深度解析jqktrader:基于Python的同花顺自动化交易架构设计与实战应用 【免费下载链接】jqktrader 同花顺自动程序化交易 项目地址: https://gitcode.com/gh_mirrors/jq/jqktrader 在量化交易技术快速发展的今天,传统手动交易已无法满足高频、精准…...

Windows右键菜单瘦身秘籍:3个技巧让你的文件操作快如闪电
Windows右键菜单瘦身秘籍:3个技巧让你的文件操作快如闪电 【免费下载链接】ContextMenuManager 🖱️ 纯粹的Windows右键菜单管理程序 项目地址: https://gitcode.com/gh_mirrors/co/ContextMenuManager 你是否经历过这样的尴尬时刻?在…...