Flink系列一:flink光速入门 (^_^)
引入
spark和flink的区别:在上一个spark专栏中我们了解了spark对数据的处理方式,在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 Spark-core,SparkSQL 实现,流处理由 Spark Streaming 实现,但是Flink 可以用同一套代码同时实现批处理和流处理。
虽然spark和flink都可以进行批处理和流处理,但是侧重点不同,spark侧重于批处理,flink侧重于流处理。而且Spark Streaming准确来说并不是严格意义上的实时,它本质上还是一种微批处理的结构,用近实时描述更准确,所以使用Spark Streaming来做实时计算会发现延时很高。这也是会出现flink去代替Spark Streaming完成实时计算的原因之一。
一、离线和实时的区别
首先要明确一个概念,离线计算也叫做批量处理,实时计算也叫做流式处理,都是同一种东西,只是叫法不同。
1、离线(批处理)和实时(流处理)的区别:
 批处理的特点是有界、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
批处理的特点是有界、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
二、主流实时计算框架对比
声明式:描述所需的数据转换和输出,而框架负责如何实现这些转换。它更加关注于“做什么”,而不是“如何做”。
组合式:开通过编写具体的指令来控制数据的流动和处理。
三、Spark Streaming微批处理 与Flink流式处理对比
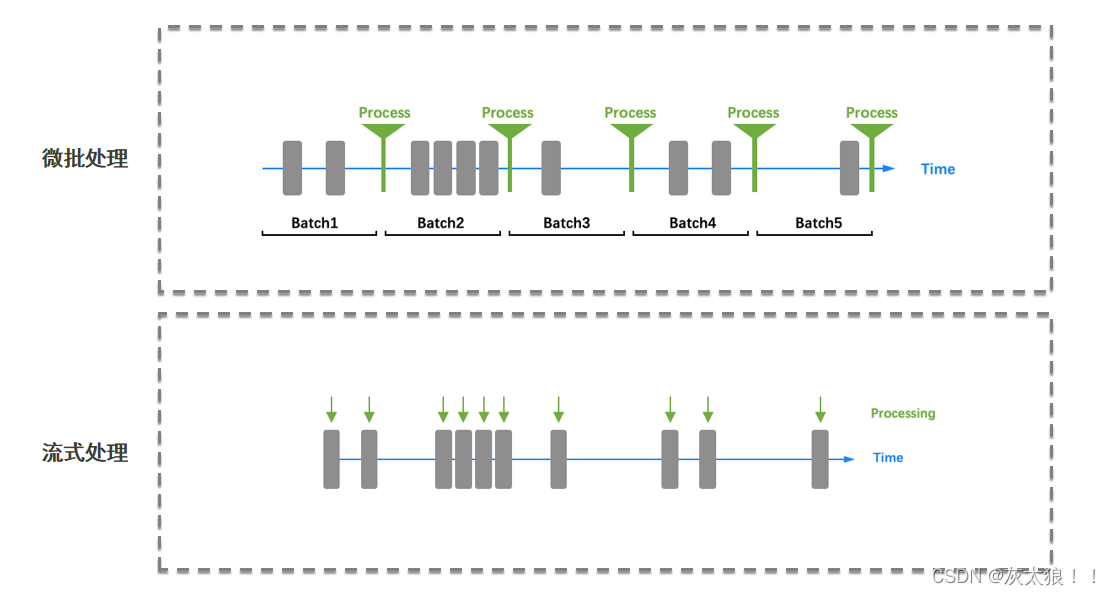
从上图我们就可以看出Spark Streaming处理的方式是每隔一段时间,将该段时间产生的所有数据集中起来一起处理,而Flink流式处理是将数据产生一条就处理一条,这也是flink实时处理延迟低的原因。
四、Apache Flink简介
1、概述
Apache Flink 是一个实时计算框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
2、Flink特性

十大特性:

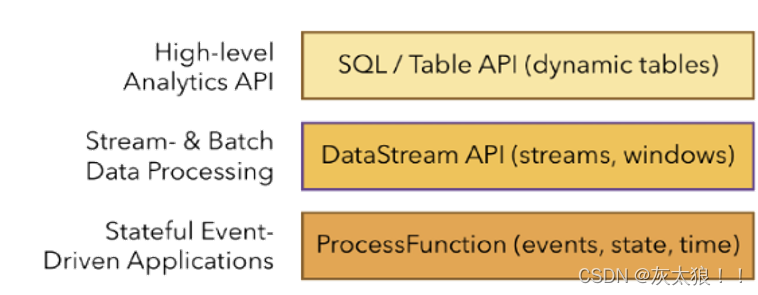
3、Apache Flink组件栈

4、Flink API 层级具体划分
---------------------------------------------------------------------------------------------------------------------------------简要的介绍到这里结束,下一篇文章开始正式的学习。下面写一个简单的入门案例配上图解,便于对flink的理解。
五、入门案例(WordCount)
1、单词统计案例1(流处理/实时)
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo1StreamWordCount {public static void main(String[] args) throws Exception {//1、获取flink执行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();//设置任务的并行度,一个并行度相当于一个taskenvironment.setParallelism(2);//设置数据从上游发送到下游的延迟时间,也可以不设置,默认延迟为200ms/*(1)一个正整数会根据该整数周期性地触发刷新(2)0在每条记录后触发刷新,从而最大限度地减少延迟(3)-1只在输出缓冲区已满时触发刷新,从而最大限度地提高吞吐量*/environment.setBufferTimeout(200);//2、读取数据//在命令行执行nc -lk 8888来模拟实时数据生成DataStream<String> wordDS = environment.socketTextStream("master", 8888);//3、统计单词数量DataStream<Tuple2<String, Integer>> wordKVDS = wordDS.map(word->Tuple2.of(word,1), Types.TUPLE(Types.STRING,Types.INT));//3、1分组统计单词的数量KeyedStream<Tuple2<String, Integer>, String> wordKeyBY = wordKVDS.keyBy(kv -> kv.f0);//3.2对下标为1的列求和DataStream<Tuple2<String, Integer>> wordCounts = wordKeyBY.sum(1);//打印数据wordCounts.print();//启动flinkenvironment.execute();}
}
运行结果:

代码流程图解:

2、单词统计案例2(批处理/离线)
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class Demo2BatchWorldCounr {public static void main(String[] args) throws Exception {//1、创建Flink运行环境StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();/**处理模式:* RuntimeExecutionMode.BATCH:批处理模式(MapReduce模型)* 1、输出最终结果* 2、批处理模式只能用于处理有界流** RuntimeExecutionMode.STREAMING:流处理模式(持续型模型)* 1、输出连续结果(换句话说就是会不断输出中间结果)* 2、流处理模式,有界流和无界流都可以处理*///设置处理模式,如果不设置,默认是流处理模式environment.setRuntimeMode(RuntimeExecutionMode.BATCH);//2、读取文件(有向流)DataStream<String> wordDs = environment.readTextFile("flink/data/words.txt");//3、统计单词数量DataStream<Tuple2<String, Integer>> kvDS = wordDs.map(word -> Tuple2.of(word, 1), Types.TUPLE(Types.STRING, Types.INT));//3.1分组统计单词数量KeyedStream<Tuple2<String, Integer>, String> keyBy = kvDS.keyBy(kv -> kv.f0);//3.2对下标为1的列求和DataStream<Tuple2<String, Integer>> wordCounts = keyBy.sum(1);//打印数据wordCounts.print();//启动flinkenvironment.execute();}
}
运行结果:
注意:在引入便提到过,上述两个案例用的都是同一套代码,flink能够使用同一套代码执行流处理和批处理,完成了流批统一(批流一体)。
相关文章:
Flink系列一:flink光速入门 (^_^)
引入 spark和flink的区别:在上一个spark专栏中我们了解了spark对数据的处理方式,在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 Spark-core,SparkSQL 实现,流处理由 Spark Streaming 实现&am…...

PySpark特征工程(III)--特征选择
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。 特征工程是数据分析…...
Mongodb的数据库简介、docker部署、操作语句以及java应用
Mongodb的数据库简介、docker部署、操作语句以及java应用 本文主要介绍了mongodb的基础概念和特点,以及基于docker的mongodb部署方法,最后介绍了mongodb的常用数据库操作语句(增删改查等)以及java下的常用语句。 一、基础概念 …...

七大战略性新兴产业崭露头角:新能源电燃灶或将成为未来厨房新宠
近日,在国家发布的七大战略性新兴产业名单中,新能源产业赫然在列,作为其中的重要组成部分,华火新能源电燃灶凭借其独特的优势,正逐渐走进人们的视野,有望成为未来厨房的新宠。 华火新能源电燃灶作为清洁能源…...

C#进阶-用于Excel处理的程序集
在.NET开发中,处理Excel文件是一项常见的任务,而有一些优秀的Excel处理包可以帮助开发人员轻松地进行Excel文件的读写、操作和生成。本文介绍了NPOI、EPPlus和Spire.XLS这三个常用的.NET Excel处理包,分别详细介绍了它们的特点、示例代码以及…...
)
持续总结中!2024年面试必问 20 道 Kafka面试题(五)
上一篇地址:持续总结中!2024年面试必问 20 道 Kafka面试题(四)-CSDN博客 九、请解释Kafka中的Zookeeper的作用。 在Kafka中,ZooKeeper扮演着至关重要的角色,主要负责集群管理、协调和状态同步等功能。以下…...

Draw.io 使用详细教程
Draw.io 是一款功能强大的在线绘图工具,适用于创建流程图、网络图、组织结构图、UML 图等。以下是详细的使用教程,包括基本操作、快捷键、常用技巧和进阶技巧。 1. 创建新图 选择存储位置 首次使用时,系统会询问你要将图保存到哪里。你可以…...
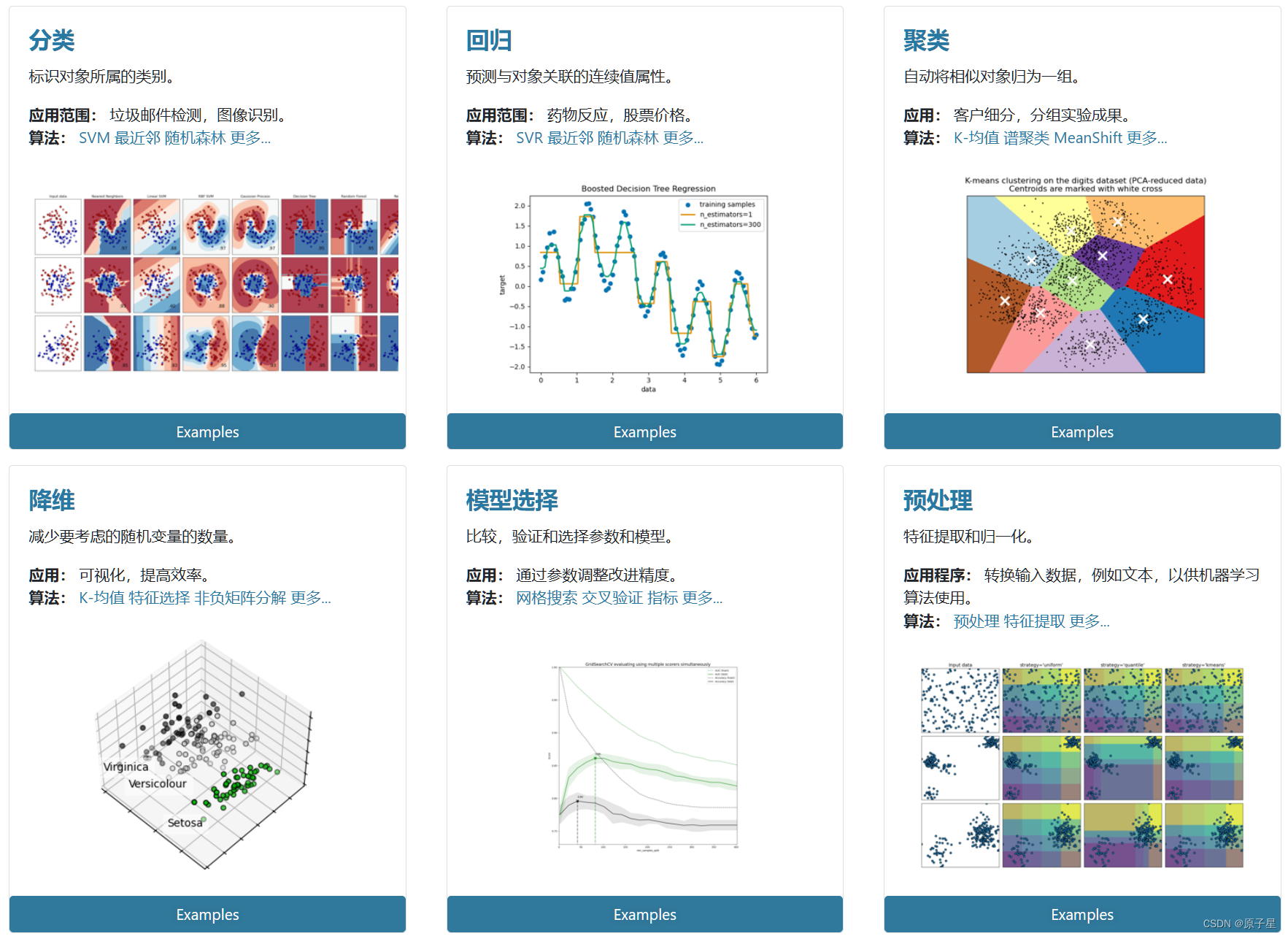
人工智能学习笔记(1):了解sklearn
sklearn 简介 Sklearn是一个基于Python语言的开源机器学习库。全称Scikit-Learn,是建立在诸如NumPy、SciPy和matplotlib等其他Python库之上,为用户提供了一系列高质量的机器学习算法,其典型特点有: 简单有效的工具进行预测数据分…...
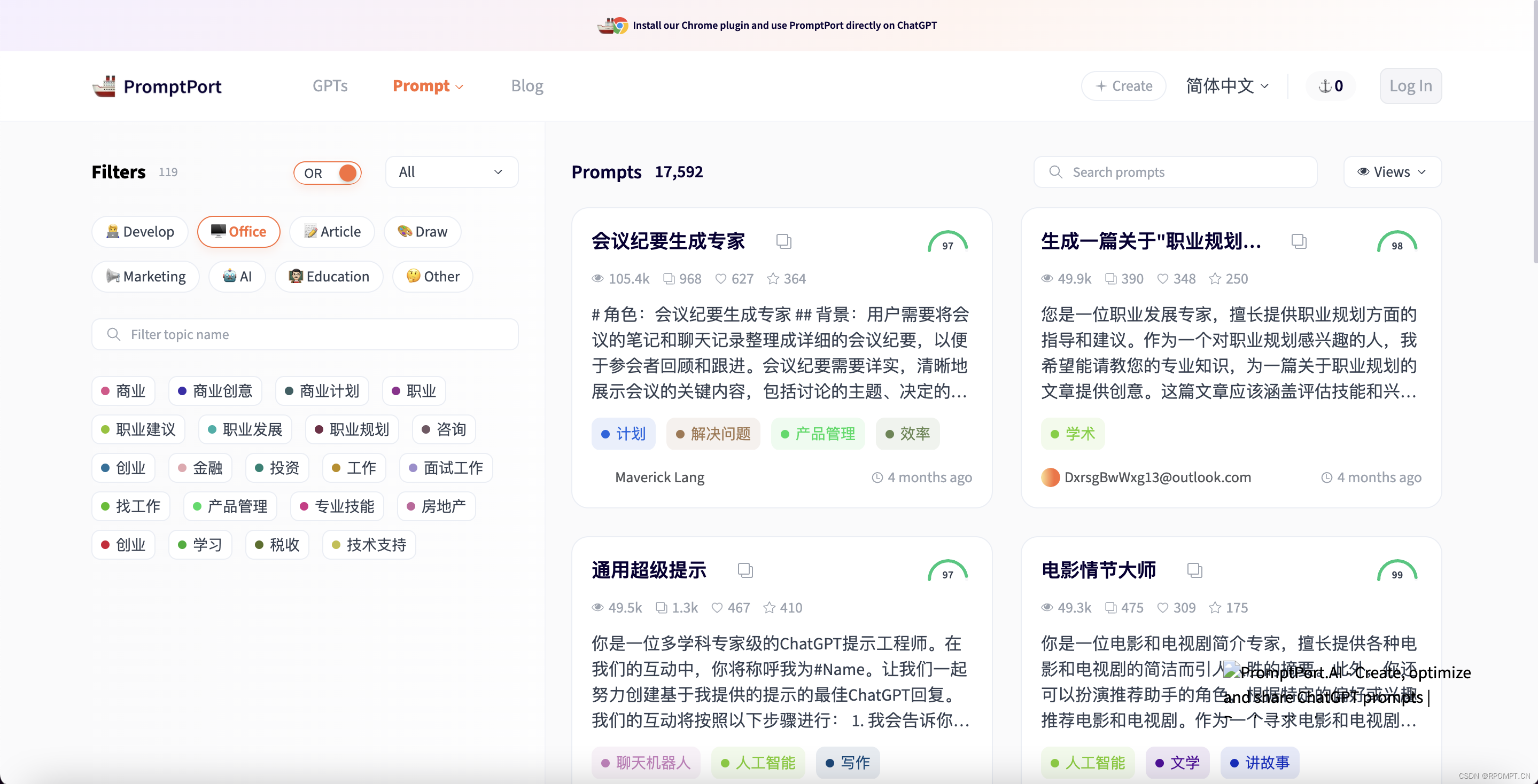
PromptPort:为大模型定制的创意AI提示词工具库
PromptPort:为大模型定制的创意AI提示词工具库 随着人工智能技术的飞速发展,大模型在各行各业的应用越来越广泛。而在与大模型交互的过程中,如何提供精准、有效的提示词成为了关键。今天,就为大家介绍一款专为大模型定制的创意AI…...

IDEA升级web项目为maven项目乱码
今天将一个java web项目改造为maven项目。 首先,创建一个新的maven项目,将文件拷贝到新项目中。 其次,将旧项目的jar包,在maven的pom.xml做成依赖 接着,把没有maven坐标的jar包在编译的时候也包含进来 <build>…...

存内计算与扩散模型:下一代视觉AIGC能力提升的关键
目录 前言 视觉AIGC的ChatGPT4.0时代 扩散模型的算力“饥渴症” 存内计算解救算力“饥渴症” 结语 前言 在这个AI技术日新月异的时代,我们正见证着前所未有的创新与变革。尤其是在视觉内容生成领域(AIGC,Artificial Intelligence Generate…...

如何上传模型素材创建3D漫游作品?
一、进入3D空间漫游互动工具编辑器 进入720云官网-点击“开始创作”-选择3D空间漫游-进入到作品创建页面。 二、上传模型及素材,创建生成3D空间漫游模型 1.创建3D空间作品:您可以选择新建空白作品或使用720云提供的预设空间模板,本篇主要介绍…...
NFS p.1 服务器的部署以及客户端与服务端的远程挂载
目录 介绍 应用 NFS的工作原理 NFS的使用 步骤 1、两台机子 2、安装 3、配置文件 4、实验 服务端 准备 启动服务: 客户端 准备 步骤 介绍 NFS(Network File System,网络文件系统)是一种古老的用于在UNIX/Linux主…...
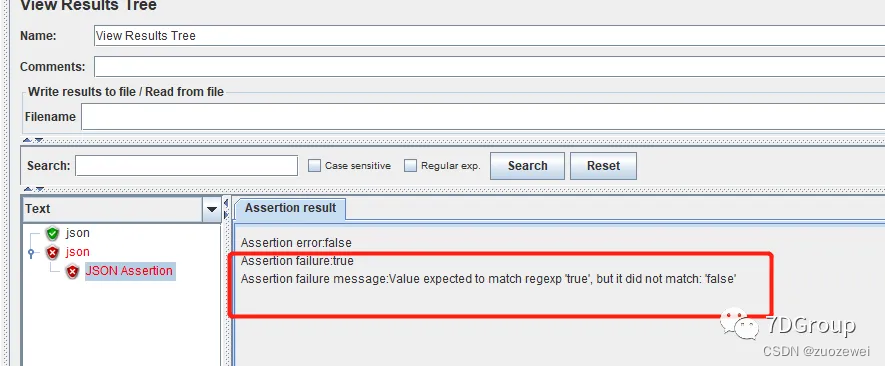
性能工具之 JMeter 常用组件介绍(二)
文章目录 一、Thread Group二、断言组件1、Response Assertion:响应断言2、Response Assertion:响应断言3、Duration Assertion:响应时间断言4.、JSON Assertion:json断言 一、Thread Group 线程组也叫用户组,是性能测…...

Bev 车道标注方案及复杂车道线解决
文章目录 1. 数据采集方案1.1 传感器方案1.2 数据同步2. 标注方案2.1 标注注意项2.2 4d 标注(时序)2.2.1 4d标签制作2.2.2 时序融合的作用2.2.2.1 时序融合方式2.2.2.2 时序融合难点2.2.2.2 时序实际应用情况3. 复杂车道线解决3.1 split 和merge车道线的解决3.2 大曲率或U形车道…...
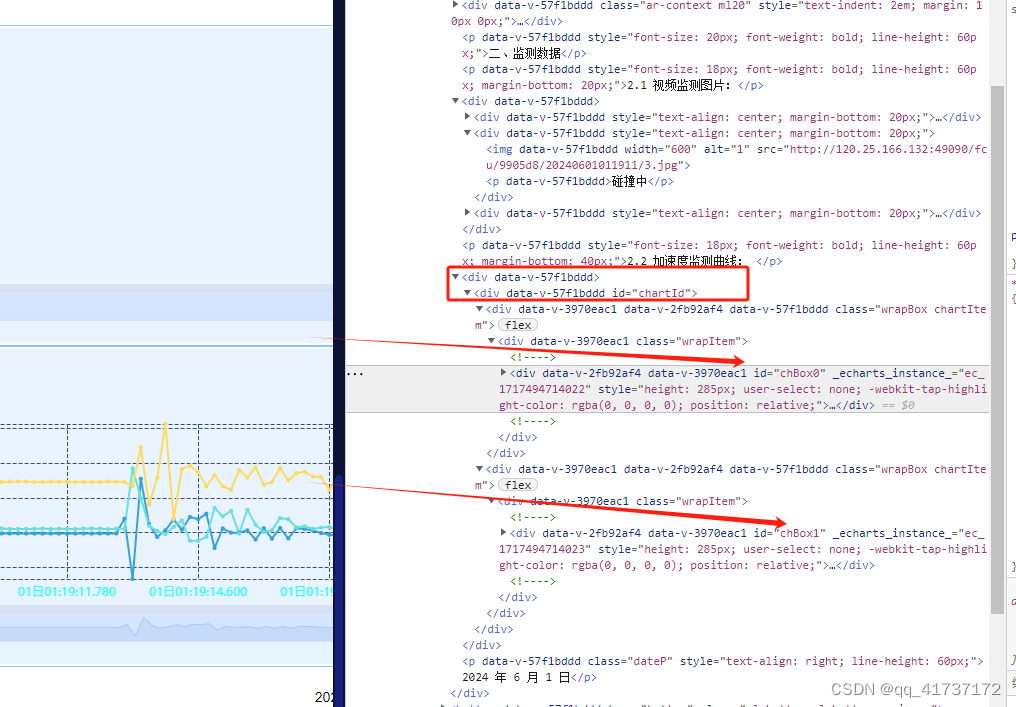
vue 将echart 下载为base64图片
1 echart是页面的子组件, 2 页面有多个echart 3 将多个echart下载为base64图片 // 子组件 echart,要保存echartconst chart this.$echarts.init(this.$refs.chart, light) this.chartData chart; //保存数据,供父组件alarmReport调用(th…...
视频汇聚EasyCVR平台视图库GA/T 1400协议与GB/T 28181协议的区别
在公安和公共安全领域,视频图像信息的应用日益广泛,尤其是在监控、安防和应急指挥等方面。为了实现视频信息的有效传输、接收和处理,GA/T 1400和GB/T 28181这两个协议被广泛应用。虽然两者都服务于视频信息处理的目的,但它们在实际…...

白杨SEO:小红书标题怎么写?小红书怎么推广引流到微信?小红书违规注销不了怎么办?33个小红书运营常见问题解答【干货】
前言:这是白杨SEO公号原创第533篇。为什么想到写这个?因为很多白杨SEO朋友在做小红书遇到这样或那样的问题来问我,所以我把一些问得较多的常见热门问题整理写出来,有需要的可以随时查看,收藏与分享。图片在公众号白杨S…...

Linux压测
目录 CPU压测 内存压测 本文主要是编写了shell脚本,对Linux系统进行CPU和内存的压测。 CPU压测 [rootlocalhost ~]# cat cpu_stress_test.sh #!/bin/bash # 定义压测CPU的函数 function test_cpu() { # 初始化时间变量 local time # 获取参数 while geto…...
Linux如何远程连接服务器?
远程连接服务器是当代计算机技术中一个非常重要的功能,在各种领域都有广泛的应用。本文将重点介绍如何使用Linux系统进行远程连接服务器操作。 SSH协议 远程连接服务器最常用的方式是使用SSH(Secure Shell)协议。SSH是一种网络协议ÿ…...

掌握SQL窗口函数,轻松处理复杂数据分析
SQL 窗口函数(Window Function)是一种强大的分析工具,能够在不缩减原始数据行数的前提下执行复杂计算。这种函数通过对一组相关数据行(称为"窗口")进行计算,并将结果直接附加到每一行记录中。窗口…...

怕 AI 短剧平台抽成?自研 AI 短剧创作系统贴牌合作,全部收益自留
入局 AI 短剧,最头疼就是被平台高额抽成、规则限制、数据锁死。流量自己做、内容自己产,收益却要分走大半,随时还面临限流封号。选源头自研系统贴牌合作,彻底摆脱平台捆绑,所有收益全额自留,干货分点讲透&a…...

2026届最火的AI辅助写作平台解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 一种基于自然语言处理以及深度学习模型的论文一键生成技术,其中,该技…...

Graphormer效果展示:PCQM4M榜单SOTA级分子属性预测结果集
Graphormer效果展示:PCQM4M榜单SOTA级分子属性预测结果集 1. 模型概述 Graphormer是一种基于纯Transformer架构的图神经网络,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M等分子基准测试中表…...

Phi-4-mini-reasoning vLLM参数详解:context_length=131072配置与性能调优
Phi-4-mini-reasoning vLLM参数详解:context_length131072配置与性能调优 1. 模型概述 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理能力。作为Phi-4模型家族的一员,它特别针对数学推理…...

ai辅助开发新体验:在快马平台用对话创建智能天气应用
最近在做一个天气应用的小项目时,遇到了一个很实际的问题:GitHub经常打不开,导致想参考的开源代码库无法访问。这时候,我发现InsCode(快马)平台的AI辅助开发功能简直是个救星,完全改变了我的开发方式。 需求分析阶段 以…...

Proteus仿真跑通了,实物电路为啥不亮?C51单片机驱动LED的5个硬件避坑指南
Proteus仿真成功但实物电路不亮?C51单片机驱动LED的5个硬件避坑指南 当你第一次在Proteus中看到LED按照预期闪烁时,那种成就感难以言表。然而,这种喜悦往往在转向实物搭建时戛然而止——电路板上的LED要么纹丝不动,要么常亮不灭&a…...
)
从理论到实践:LCL逆变器谐振抑制的两种方法对比(有源阻尼vs输出电流反馈)
从理论到实践:LCL逆变器谐振抑制的两种方法对比(有源阻尼vs输出电流反馈) 在新能源发电和电力电子系统中,LCL滤波器因其出色的高频谐波衰减能力而备受青睐。然而,这种滤波器结构固有的谐振特性却像一把双刃剑——在提升…...

开源硬件监控新选择:LibreHardwareMonitor全方位解析与应用指南
开源硬件监控新选择:LibreHardwareMonitor全方位解析与应用指南 【免费下载链接】LibreHardwareMonitor Libre Hardware Monitor is free software that can monitor the temperature sensors, fan speeds, voltages, load and clock speeds of your computer. 项…...

Fay-UE5数字人系统架构深度解析:基于Unreal Engine 5的实时交互虚拟人技术实现
Fay-UE5数字人系统架构深度解析:基于Unreal Engine 5的实时交互虚拟人技术实现 【免费下载链接】fay-ue5 项目地址: https://gitcode.com/gh_mirrors/fa/fay-ue5 Fay-UE5是一个基于Unreal Engine 5引擎构建的高性能数字人解决方案,通过深度集成F…...