Java线程池execute和submit的区别
前言
ThreadPoolExecutor提供了两种方法来执行异步任务,分别是execute和submit,也是日常开发中经常使用的方法,那么它俩有什么区别呢?
语义不同
首先是语义上的不同。execute声明在Executor接口,它接受一个Runnable类型的入参,且没有返回值,代表它可以异步执行一个没有返回结果的异步任务,你甚至不知道这个任务什么时候执行完毕。
public interface Executor {void execute(Runnable command);
}
而submit声明在ExecutorService,且有多个重载方法,最明显的区别就是submit方法均有Future返回值。Future代表未来结果的一个占位符,可以通过它拿到异步任务的执行结果,如果异步任务执行失败,也可以通过它拿到异常信息。
所以,下面三个方法的区别是:方法1的入参是Runnable没有返回结果,所以返回的Future是也拿不到结果的,只能判断异步任务是否执行完毕以及是否执行异常;方法2返回的Future可以拿到结果,值是第二个入参;方法3也可以拿到结果,值就是入参Callable返回的结果。
public interface ExecutorService extends Executor {[1] Future<?> submit(Runnable task);[2] <T> Future<T> submit(Runnable task, T result);[3] <T> Future<T> submit(Callable<T> task);
}
综上所述,execute和submit最明显的一个区别就是语义上的不同。execute用来执行没有返回结果的异步任务,且调用方不关心任务的执行结果;而submit用来执行有返回结果的异步任务,适用于调用方关心执行结果和异步任务执行有返回值的场景。
异常处理不同
execute和submit第二个区别是:异步任务执行异常时的处理不同。execute遇到异常会直接抛出来,而submit会默默吃掉异常。
如下示例,execute会把除0异常的堆栈打印出来,而submit则没有打印任何信息。
public static void main(String[] args) throws Exception {ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue<>());executor.execute(() -> {System.err.println("execute result:");System.err.println(1 / 0);});executor.submit(() -> {System.err.println("submit result:");System.err.println(1 / 0);});}
execute result:
Exception in thread "pool-1-thread-1" java.lang.ArithmeticException: / by zeroat ExecutorDemo2.lambda$main$0(ExecutorDemo2.java:18)at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)at java.base/java.lang.Thread.run(Thread.java:840)
submit result:
你可能会觉得疑惑,submit凭什么要默默吃掉异常,任务执行出错为什么不通知调用方呢?
事实上,submit针对异常的处理方式正和它的语义有关,它并没有吃掉异常,而是它认为方法执行异常也是结果的一部分,别忘了它是有Future返回值的,只不过它并没有粗暴的直接抛出异常,而是把异常记录在了Future返回值里面。如果要关心submit提交的异步任务的执行情况,可以通过下面这种方式:
Future<?> future = executor.submit(() -> {System.err.println("submit result:");System.err.println(1 / 0);
});
try {future.get();System.err.println("正常执行");
} catch (Exception e) {System.err.println("原来执行异常了:" + e.getMessage());
}
异常线程销毁重建
execute和submit第三个区别是:execute面对异常线程会销毁重建,而submit会继续复用异常线程。
看下面的例子,创建一个固定3个线程的线程池,先分别execute执行2个正常的任务和1个异常任务,sleep一会再次执行三个任务,我们发现3号线程因为执行异常被销毁了,线程池重新启动了4号线程。如果调用submit,则始终是一开始创建的三个线程在工作,不会出现线程的销毁和重建情况。
public static void main(String[] args) throws Exception {ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 3, 60L, TimeUnit.SECONDS, new LinkedBlockingQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());executor.execute(new Task(false));executor.execute(new Task(false));executor.execute(new Task(true));Thread.sleep(1000);System.err.println("===============");for (int i = 0; i < 3; i++) {executor.execute(new Task(false));}
}static class Task implements Runnable {private boolean throwException;public Task(boolean throwException) {this.throwException = throwException;}@SneakyThrows@Overridepublic void run() {if (throwException) {System.err.println("error:" + Thread.currentThread().getName());throw new RuntimeException();}Thread.sleep(1);System.err.println("task:" + Thread.currentThread().getName());}
}
error:pool-1-thread-3
task:pool-1-thread-2
task:pool-1-thread-1
Exception in thread "pool-1-thread-3" java.lang.RuntimeExceptionat ExecutorDemo$Task.run(ExecutorDemo.java:36)at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1136)at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:635)at java.base/java.lang.Thread.run(Thread.java:840)
===============
task:pool-1-thread-1
task:pool-1-thread-4
task:pool-1-thread-2
源码浅析
最后,从源码层面看看导致execute和submit区别的原因。
execute方法道尽了线程池的工作流程,如果工作线程数小于核心线程数,面对提交的任务会创建新线程去执行,否则尝试入队,队列满则继续创建线程直到最大线程数。
public void execute(Runnable command) {if (command == null)throw new NullPointerException();int c = ctl.get();if (workerCountOf(c) < corePoolSize) {// 小于核心线程数,启动新线程if (addWorker(command, true))return;c = ctl.get();}if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);}else if (!addWorker(command, false))reject(command);
}
在线程池里,线程会被封装成Worker对象,它的run方法是个while循环,不停的从任务队列workQueue里面取出异步任务并执行,不过它在执行任务时,如果遇到异常,会直接抛出来。并且在finally里面会把异常线程从workers里面移除,后续当工作线程数小于核心线程数时又会继续创建新的线程。
final void runWorker(Worker w) {Thread wt = Thread.currentThread();Runnable task = w.firstTask;w.firstTask = null;w.unlock();boolean completedAbruptly = true;try {while (task != null || (task = getTask()) != null) {w.lock();if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {beforeExecute(wt, task);try {task.run();afterExecute(task, null);} catch (Throwable ex) {afterExecute(task, ex);throw ex; // 直接抛出异常}} finally {task = null;w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {processWorkerExit(w, completedAbruptly);}
}
而submit之所以不会抛出异常,是因为它对提交的任务进行了一层封装,Runnable封装成了FutureTask:
public Future<?> submit(Runnable task) {if (task == null) throw new NullPointerException();RunnableFuture<Void> ftask = newTaskFor(task, null);execute(ftask);return ftask;
}
FutureTask就是Future的实现类,它重写了run方法,对异常进行了捕获,如果发生异常会把异常记录下来,而不是直接抛出,调用者可以通过Future来获得异常信息。
public void run() {if (state != NEW ||!RUNNER.compareAndSet(this, null, Thread.currentThread()))return;try {Callable<V> c = callable;if (c != null && state == NEW) {V result;boolean ran;try {result = c.call();ran = true;} catch (Throwable ex) {// 捕获异常result = null;ran = false;setException(ex);// 记录异常}if (ran)set(result);}} finally {runner = null;int s = state;if (s >= INTERRUPTING)handlePossibleCancellationInterrupt(s);}
}
尾巴
execute和submit都可以执行异步任务,但是有三大区别,分别是:1.语义上的区别,是否关心任务的执行情况和返回结果;2.遇到遇到是直接抛出还是先记录下来;3.异常线程是销毁重建还是继续复用。在源码层面,本质上submit只是针对提交的任务又做了一层包装,FutureTask重写了run()捕获了异常信息并记录了下来,方便调用者从Future里面拿到执行结果。
相关文章:

Java线程池execute和submit的区别
前言 ThreadPoolExecutor提供了两种方法来执行异步任务,分别是execute和submit,也是日常开发中经常使用的方法,那么它俩有什么区别呢? 语义不同 首先是语义上的不同。execute声明在Executor接口,它接受一个Runnable…...

什么是json
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。它基于JavaScript编程语言的一个子集,但是由于其文本格式清晰、易于解析,并且能够以键/值对的形式表示复杂的数据结构,因此它被广泛用于不同的编程语言和…...

基于聚类和回归分析方法探究蓝莓产量影响因素与预测模型研究附录
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 目录 背景数据说明数据来源思考 附录数据预处理导入包以及数据读取数据预览数据处理 相关性分析聚类分析数据处理确定聚类数建立k均值聚类模型 …...

java类型转换
pom <dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.76</version></dependency>BeanUtils 在这里插入代码片list<Map>转换成List<bean> public static <T> L…...
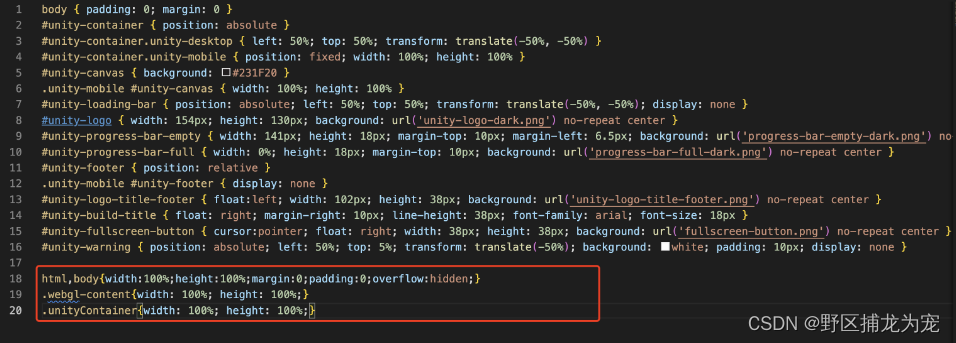
Unity打包Webgl端进行 全屏幕自适应
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一:修改 index.html二:将非移动端设备,canvas元素的宽度和高度会设置为100%。三:修改style.css总结 下载地址&#x…...
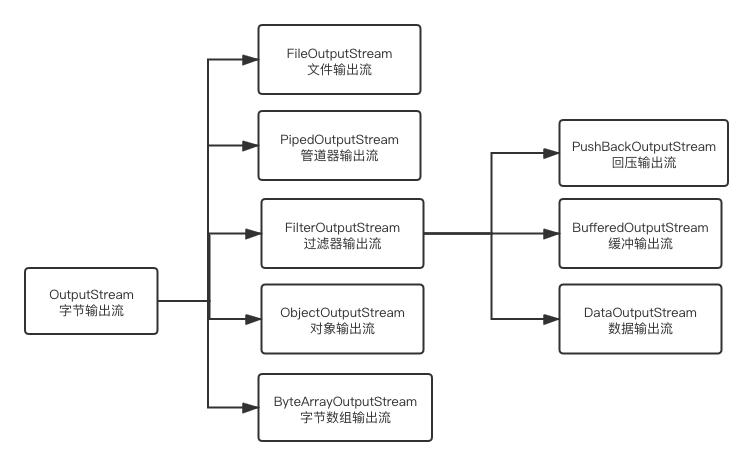
36. 【Java教程】输入输出流
本小节将会介绍基本输入输出的 Java 标准类,通过本小节的学习,你将了解到什么是输入和输入,什么是流;输入输出流的应用场景,File类的使用,什么是文件,Java 提供的输入输出流相关 API 等内容。 1…...
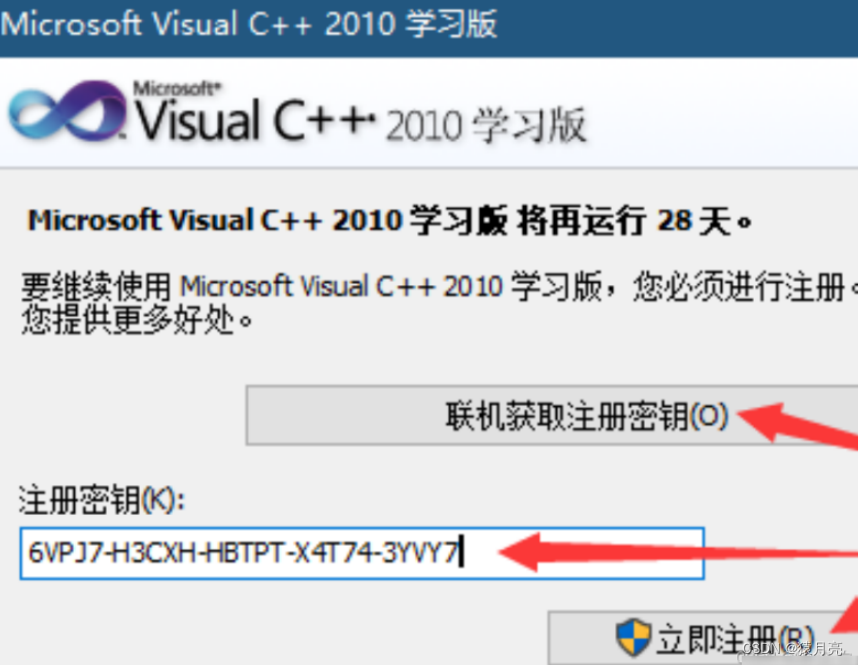
Visual C++2010学习版详细安装教程(超详细图文)
Visual C 介绍 Visual C(简称VC)是微软公司推出的一种集成开发环境(IDE),主要用于开发C和C语言的应用程序。它提供了强大的编辑器、编译器、调试器、库和框架支持,以及丰富的工具和选项,使得开…...

matlab图像处理入门
matlab在学校科研,仿真及基于模型开发的工作中有重要作用,在图像处理方面由于省去了复杂的上位机开发流程,因此可以让用户快速开发验证算法,下面简要介绍其在图像处理方面的应用。 matlab开发图像处理算法的流程主要是,…...

关于线程池面试题,使用“豆包”训练答案
我提问: 问题描述 下面是一个有关线程池调度的面试真题,来自于疯狂创客圈社群: 一个线程池的核心线程数为10个,最大线程数为20个,阻塞队列的容量为30。现在提交45个 任务,每个任务的耗时为500毫秒。 请问&…...
【WRF理论第二期】模型目录介绍
WRF理论第二期:模型目录介绍 1 WRF主目录2 WPS主目录3 编译后的可执行文件4 运行目录参考 了解 WRF 模型的目录结构有助于有效地管理和操作模型,从而确保模拟和分析工作的顺利进行。以下分解介绍WRF主目录、WPS主目录等。 Github-wrf-model/WRF 1 WRF…...
从了解到掌握 Spark 计算框架(一)Spark 简介与基础概念
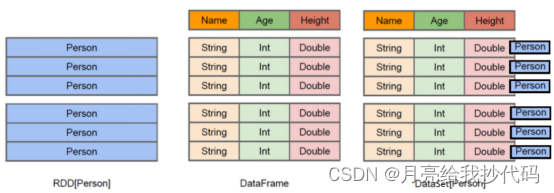
文章目录 什么是 Spark?核心特点 Spark 对比 MapReduceSpark 编程模型RDDDataFrameDataset Spark 运行模式Spark 生态 什么是 Spark? Spark 是一个基于内存的分布式计算框架,最初由加州大学伯克利分校的 AMPLab 开发,后来捐赠给了…...

linux bind函数
bind函数的目的是让把客户端对应的端口(port)地址和ip地址绑定到客户端 [参考](Linux之bind 函数(详细篇)_linux bind函数-CSDN博客)...
Flink系列一:flink光速入门 (^_^)
引入 spark和flink的区别:在上一个spark专栏中我们了解了spark对数据的处理方式,在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 Spark-core,SparkSQL 实现,流处理由 Spark Streaming 实现&am…...

PySpark特征工程(III)--特征选择
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。 特征工程是数据分析…...
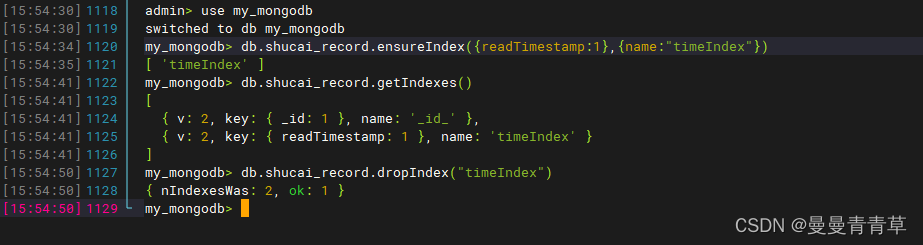
Mongodb的数据库简介、docker部署、操作语句以及java应用
Mongodb的数据库简介、docker部署、操作语句以及java应用 本文主要介绍了mongodb的基础概念和特点,以及基于docker的mongodb部署方法,最后介绍了mongodb的常用数据库操作语句(增删改查等)以及java下的常用语句。 一、基础概念 …...

七大战略性新兴产业崭露头角:新能源电燃灶或将成为未来厨房新宠
近日,在国家发布的七大战略性新兴产业名单中,新能源产业赫然在列,作为其中的重要组成部分,华火新能源电燃灶凭借其独特的优势,正逐渐走进人们的视野,有望成为未来厨房的新宠。 华火新能源电燃灶作为清洁能源…...

C#进阶-用于Excel处理的程序集
在.NET开发中,处理Excel文件是一项常见的任务,而有一些优秀的Excel处理包可以帮助开发人员轻松地进行Excel文件的读写、操作和生成。本文介绍了NPOI、EPPlus和Spire.XLS这三个常用的.NET Excel处理包,分别详细介绍了它们的特点、示例代码以及…...
)
持续总结中!2024年面试必问 20 道 Kafka面试题(五)
上一篇地址:持续总结中!2024年面试必问 20 道 Kafka面试题(四)-CSDN博客 九、请解释Kafka中的Zookeeper的作用。 在Kafka中,ZooKeeper扮演着至关重要的角色,主要负责集群管理、协调和状态同步等功能。以下…...

Draw.io 使用详细教程
Draw.io 是一款功能强大的在线绘图工具,适用于创建流程图、网络图、组织结构图、UML 图等。以下是详细的使用教程,包括基本操作、快捷键、常用技巧和进阶技巧。 1. 创建新图 选择存储位置 首次使用时,系统会询问你要将图保存到哪里。你可以…...
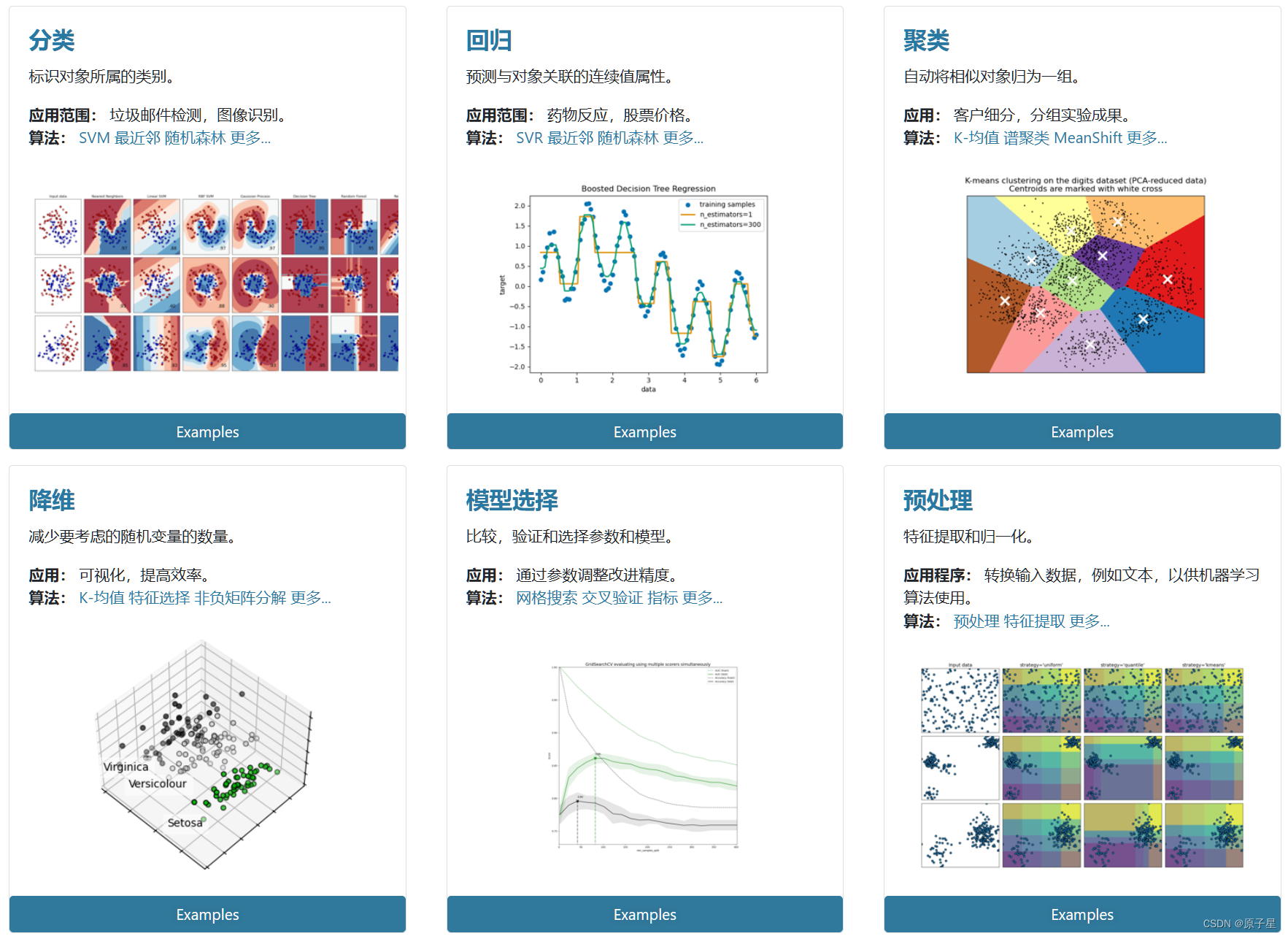
人工智能学习笔记(1):了解sklearn
sklearn 简介 Sklearn是一个基于Python语言的开源机器学习库。全称Scikit-Learn,是建立在诸如NumPy、SciPy和matplotlib等其他Python库之上,为用户提供了一系列高质量的机器学习算法,其典型特点有: 简单有效的工具进行预测数据分…...
4一、终极问题:定位为什么始终依赖“设备”在传统技术体系中,“)
镜像视界|无感定位终极形态:无需设备的人体空间定位技术突破——基于视频空间反演与多摄像机融合的无标签定位体系封面主视觉(建议)4一、终极问题:定位为什么始终依赖“设备”在传统技术体系中,“
镜像视界|无感定位终极形态:无需设备的人体空间定位技术突破——基于视频空间反演与多摄像机融合的无标签定位体系一、终极问题:定位为什么始终依赖“设备”在传统技术体系中,“定位”几乎等同于“设备”。无论是GPS、UWB、蓝牙还…...

快马平台十分钟速成:用AI大模型构建你的第一个智能客服对话Agent原型
最近在尝试用AI大模型构建智能客服对话系统,发现InsCode(快马)平台特别适合快速验证这类原型。花十分钟就能搭建出具备基础功能的对话agent,和大家分享下具体实现思路: 界面设计 先用HTML搭建基础框架,主要包含三个部分࿱…...

如何解决bilibili-api中BV号与AV号转换的技术难题?
如何解决bilibili-api中BV号与AV号转换的技术难题? 【免费下载链接】bilibili-api 哔哩哔哩常用API调用。支持视频、番剧、用户、频道、音频等功能。原仓库地址:https://github.com/MoyuScript/bilibili-api 项目地址: https://gitcode.com/gh_mirrors…...

Whitlow/218 Linker如何革新抗体药物开发中的稳定性与生产难题?
一、抗体工程领域面临何种关键性技术瓶颈?抗体药物作为生物制药领域最具前景的治疗方向之一,在肿瘤、自身免疫疾病和传染病等重大疾病治疗中展现出卓越疗效。然而,在抗体药物研发过程中,两个关键技术难题始终制约着其进一步发展&a…...

数据库自动化指标采集与智能评分系统实践与构想
在数据库运维中,定期巡检是保障系统稳定性的基石。作者结合 MySQL 的运行机制,使用 Python 自主开发了一套数据库巡检脚本。本文将演示如何通过该脚本自动化采集 MySQL 的关键性能指标、生成可视化 HTML 报告,并引入综合评分机制评估数据库健…...

实战指南:基于快马AI生成贴合业务场景的问卷系统,超越通用opencode
在开发一个在线问卷调查系统时,很多开发者会直接使用现成的opencode或开源组件。但实际业务中,通用方案往往难以完全匹配特定需求。最近我在InsCode(快马)平台上尝试了一个实战项目,通过AI生成高度定制化的问卷系统后台API,效果远…...

提升vue开发效率的秘诀,快马平台一键生成通用组件库
最近在重构公司的中后台管理系统时,发现很多重复性的工作占用了大量开发时间。经过实践总结,我发现通过合理封装通用组件和工具集,可以显著提升Vue3项目的开发效率。今天就来分享下我的实战经验。 通用表格组件的封装 这个组件基于Element Pl…...

microeco工具SpiecEasi网络分析功能的高效使用
microeco工具SpiecEasi网络分析功能的高效使用 【免费下载链接】microeco An R package for data analysis in microbial community ecology 项目地址: https://gitcode.com/gh_mirrors/mi/microeco microeco是一个用于微生物群落生态学数据分析的R语言工具包࿰…...

Win11Debloat完整指南:如何一键清理Windows系统,提升51%性能的免费神器
Win11Debloat完整指南:如何一键清理Windows系统,提升51%性能的免费神器 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other …...

别再让MATLAB并行池浪费你的内存!保姆级教程教你手动精准管理Parallel Pool
MATLAB并行池内存优化实战:从自动管理到精准控制 在科学计算和工程仿真领域,MATLAB的Parallel Computing Toolbox无疑是提升运算效率的利器。但许多资深用户都曾经历过这样的困扰:完成大规模并行计算后,发现系统内存依然被并行池占…...