mysql中optimizer trace的作用
大家好。对于MySQL 5.6以及之前的版本来说,查询优化器就像是一个黑盒子一样,我们只能通过EXPLAIN语句查看到最后 优化器决定使用的执行计划,却无法知道它为什么做这个决策。于是在MySQL5.6以及之后的版本中,MySQL新增了一个optimizer trace的功 能,这个功能可以让我们方便的查看优化器生成执行计划的整个过程,今天我们就来简单了解一下这个功能。
optimizer trace功能的开启与关闭由系统变量optimizer_trace决定,我们看一下:

可以看到enabled值为off ,表明这个功能默认是关闭的。 one_line的值是控制输出格式的,如果为on那么所有输出都将在一行中展示,不适合人阅读。
如果想打开optimizer trace功能,必须首先把enabled的值改为on ,我们可以通过下边这个sql语句修改enabled的值:
SET optimizer_trace="enabled=on";
enabled的值改为on后我们就可以输入我们想要查看优化过程的查询语句,当该查询语句执行完成后,就可以到information_schema数据库下的OPTIMIZER_TRACE表中查看完整的优化过程。这个 OPTIMIZER_TRACE 表有4个列,分别是:
QUERY : 表示我们的查询语句。
TRACE : 表示优化过程的JSON格式文本。
MISSING_BYTES_BEYOND_MAX_MEM_SIZE : 由于优化过程可能会输出很多,如果超过某个限制时,多余的文本将不会被显示,这个字段展示了被忽略的文本字节数。
INSUFFICIENT_PRIVILEGES : 表示是否没有权限查看优化过程,默认值是0。
完整的使用optimizer trace 功能的步骤总结如下:
#1. 打开optimizer trace功能 (默认情况下它是关闭的):
SET optimizer_trace="enabled=on";
#2. 输入自己的查询语句
SELECT ...;
#3. 从OPTIMIZER_TRACE表中查看上一个查询的优化过程
SELECT * FROM information_schema.OPTIMIZER_TRACE;
#4. 可能你还要观察其他语句执行的优化过程,重复上边的第2、3步。
#5. 当你停止查看语句的优化过程时,把optimizer trace功能关闭。
SET optimizer_trace="enabled=off"
下面我们以一个复杂一点的sql为例,来聊一聊如何使用optimizer trace功能。

可以看到该查询可能使用到的索引有3个,那么为什么优化器最终选择了idx_key1而不选择其他的索引或者直接全表扫描呢?这时候就可以通过otpimzer trace 功能来查看优化器的具体工作过程:
SET optimizer_trace="enabled=on";
SELECT * FROM s1 WHERE key1 > 'z' AND key2 < 1000000 AND key3 IN ('a', 'b', 'c') AND common_field = 'abc';
SELECT * FROM information_schema.OPTIMIZER_TRACE\G;
我们直接看一下通过查询OPTIMIZER_TRACE 表得到的输出:
*************************** 1. row ***************************
# 分析的查询语句是什么
QUERY: SELECT * FROM single_table WHERE key1 > 'z' AND key2 < 1000000 AND key3 IN ('a', 'b', 'c')AND common_field = 'abc'
# 优化的具体过程
TRACE: {"steps": [{"join_preparation": { # prepare阶段 "select#": 1,"steps": [{"IN_uses_bisection": true},{"expanded_query": "/* select#1 */ select `single_table`.`id` AS `id`,`single_table`.`key1` AS `key1`,`single_table`.`key2` AS `key2`,`single_table`.`key3` AS `key3`,`single_table`.`key_part1` AS `key_part1`,`single_table`.`key_part2` AS `key_part2`,`single_table`.`key_part3` AS `key_part3`,`single_table`.`common_field` AS `common_field` from `single_table` where ((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))"}]}},{"join_optimization": { # optimize阶段 "select#": 1,"steps": [{"condition_processing": { # 处理搜索条件"condition": "WHERE",# 原始搜索条件 "original_condition": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))","steps": [{# 等值传递转换 "transformation": "equality_propagation","resulting_condition": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))"},{# 常量传递转换 "transformation": "constant_propagation","resulting_condition": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))"},{# 去除没用的条件 "transformation": "trivial_condition_removal","resulting_condition": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))"}]}},{# 替换虚拟生成列 "substitute_generated_columns": {}},{# 表的依赖信息 "table_dependencies": [{"table": "`single_table`","row_may_be_null": false,"map_bit": 0,"depends_on_map_bits": []}]},{"ref_optimizer_key_uses": []},{# 预估不同单表访问方法的访问成本 "rows_estimation": [{"table": "`single_table`","range_analysis": {"table_scan": { # 全表扫描的行数以及成本 "rows": 9823,"cost": 1012.48},# 分析可能使用的索引 "potential_range_indexes": [{"index": "PRIMARY", # 主键不可用"usable": false,"cause": "not_applicable"},{"index": "idx_key2", # idx_key2可能被使用 "usable": true,"key_parts": ["key2"]},{"index": "idx_key1", # idx_key1可能被使用 "usable": true,"key_parts": ["key1","id"]},{"index": "idx_key3", # idx_key3可能被使用 "usable": true,"key_parts": ["key3","id"]},{"index": "idx_key_part", # idx_keypart不可用"usable": false,"cause": "not_applicable"}],"setup_range_conditions": [],"group_index_skip_scan": {"chosen": false,"cause": "not_group_by_or_distinct"},"skip_scan_range": {"potential_skip_scan_indexes": [{"index": "idx_key2","usable": false,"cause": "query_references_nonkey_column"},{"index": "idx_key1","usable": false,"cause": "query_references_nonkey_column"},{"index": "idx_key3","usable": false,"cause": "query_references_nonkey_column"}]},# 分析各种可能使用的索引的成本 "analyzing_range_alternatives": {"range_scan_alternatives": [{# 使用idx_key2的成本分析"index": "idx_key2",# 使用idx_key2的范围区间 "ranges": ["NULL < key2 < 1000000"],"index_dives_for_eq_ranges": true, # 是否使用index dive "rowid_ordered": false, # 使用该索引获取的记录是否按照主键排序 "using_mrr": false, # 是否使用mrr "index_only": false, # 是否是索引覆盖访问"in_memory": 1, "rows": 10000, # 使用该索引获取的记录条数 "cost": 3895.04, # 使用该索引的成本 "chosen": false, # 是否选择该索引"cause": "cost" # 因为成本太大所以不选择该索引 },{# 使用idx_key1的成本分析 "index": "idx_key1",# 使用idx_key1的范围区间 "ranges": ["'z' < key1"],"index_dives_for_eq_ranges": true, # 是否使用index dive "rowid_ordered": false, # 使用该索引获取的记录是否按照主键排序 "using_mrr": false, # 是否使用mrr"index_only": false, # 是否是索引覆盖访问"in_memory": 0.0769231,"rows": 1, # 使用该索引获取的记录条数"cost": 0.688947, # 使用该索引的成本 "chosen": true # 是否选择该索引},{# 使用idx_key3的成本分析 "index": "idx_key3",# 使用idx_key3的范围区间 "ranges": ["key3 = 'a'","key3 = 'b'","key3 = 'c'"],"index_dives_for_eq_ranges": true, # 是否使用index dive "rowid_ordered": false, # 使用该索引获取的记录是否按照主键排序 "using_mrr": false, # 是否使用mrr"index_only": false, # 是否是索引覆盖访问"in_memory": 0.0769231,"rows": 3, # 使用该索引获取的记录条数"cost": 2.04684, # 使用该索引的成本 "chosen": false, # 是否选择该索引"cause": "cost" # 因为成本太大所以不选择该索引 }],# 分析使用索引合并的成本 "analyzing_roworder_intersect": {"usable": false,"cause": "too_few_roworder_scans"}},# 对于上述单表查询最优的访问方法 "chosen_range_access_summary": {"range_access_plan": {"type": "range_scan","index": "idx_key1","rows": 1,"ranges": ["'z' < key1"]},"rows_for_plan": 1,"cost_for_plan": 0.688947,"chosen": true}}}]},{# 分析各种可能的执行计划 #(对多表查询这可能有很多种不同的方案,单表查询的方案上边已经分析过了,直接选取idx_key1就好)"considered_execution_plans": [{"plan_prefix": [],"table": "`single_table`","best_access_path": {"considered_access_paths": [{"rows_to_scan": 1,"access_type": "range","range_details": {"used_index": "idx_key1"},"resulting_rows": 1,"cost": 0.788947,"chosen": true}]},"condition_filtering_pct": 100,"rows_for_plan": 1,"cost_for_plan": 0.788947,"chosen": true}]},{# 尝试给查询添加一些其他的查询条件 "attaching_conditions_to_tables": {"original_condition": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))","attached_conditions_computation": [],"attached_conditions_summary": [{"table": "`single_table`","attached": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))"}]}},{"finalizing_table_conditions": [{"table": "`single_table`","original_table_condition": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))","final_table_condition ": "((`single_table`.`key1` > 'z') and (`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))"}]},{# 再稍稍的改进一下执行计划 "refine_plan": [{"table": "`single_table`","pushed_index_condition": "(`single_table`.`key1` > 'z')","table_condition_attached": "((`single_table`.`key2` < 1000000) and (`single_table`.`key3` in ('a','b','c')) and (`single_table`.`common_field` = 'abc'))"}]}]}},{"join_execution": { # execute阶段"select#": 1,"steps": []}}]
}
# 因优化过程文本太多而丢弃的文本字节大小,值为0时表示并没有丢弃
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0
# 权限字段
INSUFFICIENT_PRIVILEGES: 0
1 row in set (0.01 sec)
通过上述的信息我们得知,优化过程大致分为了三个阶段:prepare 阶段、optimize阶段和execute阶段。
我们所说的基于成本的优化主要集中在optimize阶段,对于单表查询来说,我们主要关注optimize阶段 的"rows_estimation"这个过程,这个过程深入分析了对单表查询的各种执行方案的成本;对于多表连接查询来 说,我们更多需要关注"considered_execution_plans"这个过程,这个过程里会写明各种不同的连接方式所对应的成本。反正优化器最终会选择成本最低的那种方案来作为最终的执行计划,也就是我们使用EXPLAIN语句所展现出的那种方案。
好了,到这里我们就讲完了,大家有什么想法欢迎留言讨论。也希望大家能给作者点个关注,谢谢大家!最后依旧是请各位老板有钱的捧个人场,没钱的也捧个人场,谢谢各位老板!
相关文章:
mysql中optimizer trace的作用
大家好。对于MySQL 5.6以及之前的版本来说,查询优化器就像是一个黑盒子一样,我们只能通过EXPLAIN语句查看到最后 优化器决定使用的执行计划,却无法知道它为什么做这个决策。于是在MySQL5.6以及之后的版本中,MySQL新增了一个optimi…...

实习面试题(答案自敲)、
1、为什么要重写equals方法,为什么重写了equals方法后,就必须重写hashcode方法,为什么要有hashcode方法,你能介绍一下hashcode方法吗? equals方法默认是比较内存地址;为了实现内容比较,我们需要…...

二叉树讲解
目录 前言 二叉树的遍历 层序遍历 队列的代码 queuepush和queuepushbujia的区别 判断二叉树是否是完全二叉树 前序 中序 后序 功能展示 创建二叉树 初始化 销毁 简易功能介绍 二叉树节点个数 二叉树叶子节点个数 二叉树第k层节点个数 二叉树查找值为x的节点 判…...
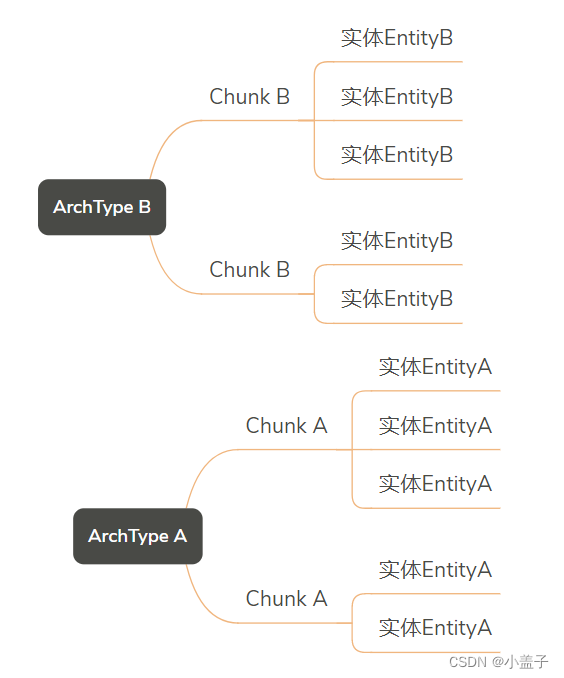
Unity DOTS技术(五)Archetype,Chunk,NativeArray
文章目录 一.Chunk和Archetype什么是Chunk?什么是ArchType 二.Archetype创建1.创建实体2.创建并添加组件3.批量创建 三.多线程数组NativeArray 本次介绍的内容如下: 一.Chunk和Archetype 什么是Chunk? Chunk是一个空间,ECS系统会将相同类型的实体放在Chunk中.当一个Chunk…...

算法学习笔记(7.1)-贪心算法(分数背包问题)
##问题描述 给定 𝑛 个物品,第 𝑖 个物品的重量为 𝑤𝑔𝑡[𝑖−1]、价值为 𝑣𝑎𝑙[𝑖−1] ,和一个容量为 𝑐𝑎&…...

气膜建筑的施工对周边环境影响大吗?—轻空间
随着城市化进程的加快,建筑行业的快速发展也带来了环境问题。噪音、灰尘和建筑废料等对周边居民生活和生态环境造成了不小的影响。因此,选择一种环保高效的施工方式变得尤为重要。气膜建筑作为一种新兴的建筑形式,其施工过程对周边环境的影响…...

【计算机网络】对应用层HTTP协议的重点知识的总结
˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN 如…...

30分钟快速入门TCPDump
TCPDump是一款功能强大的网络分析工具,它可以帮助网络管理员捕获并分析流经网络接口的数据包。由于其在命令行环境中的高效性与灵活性,TCPDump成为了网络诊断与安全分析中不可或缺的工具。本文将详细介绍TCPDump的基本用法,并提供一些高级技巧…...

Python | 刷题日记
1.海伦公式求三角形的面积 area根号下(p(p-a)(p-b)(p-c)) p是周长的一半 2.随机生成一个整数 import random xrandom.randint(0,9)#随机生成0到9之间的一个数 yeval(input("please input:")) if xy:print("bingo") elif x<y:pri…...
“JS逆向 | Python爬虫 | 动态cookie如何破~”
案例目标 目标网址:aHR0cHMlM0EvL21hdGNoLnl1YW5yZW54dWUuY29tL21hdGNoLzI= 本题目标:提取全部 5 页发布日热度的值,计算所有值的加和,并提交答案 常规 JavaScript 逆向思路 JavaScript 逆向工程通常分为以下三步: 寻找入口:逆向工程的核心在于找出加密参数的生成方式。…...
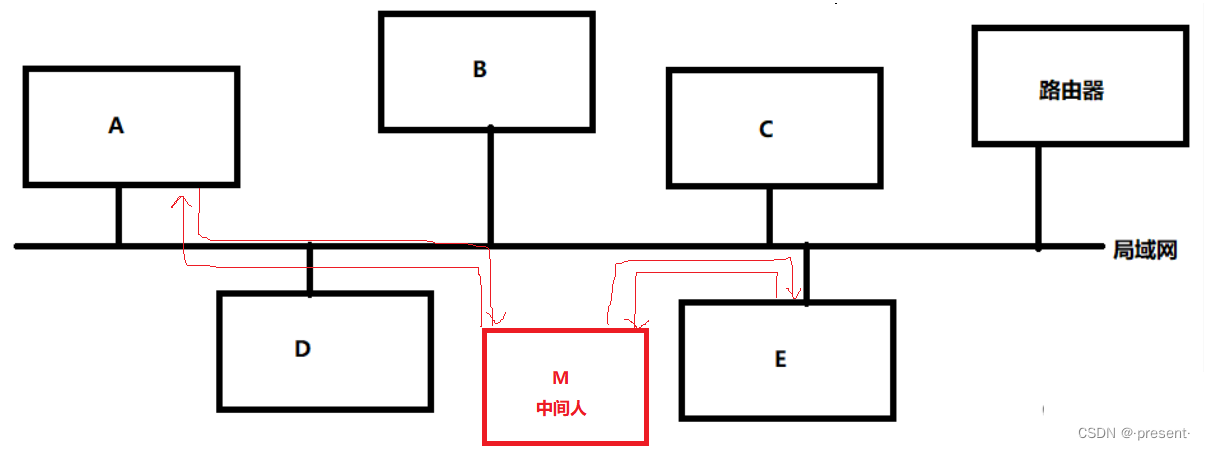
十.数据链路层——MAC/ARP
IP和数据链路层之间的关系 引言 在IP一节中,我们说IP层路由(数据转发)的过程,就像我们跳一跳游戏一样,从一个节点,转发到另一个节点 它提供了一种将数据从A主机跨网络发到B主机的能力 什么叫做跨网络??&a…...

Linux主机安全可视化运维(免费方案)
本文介绍如何使用免费的主机安全软件,在自有机房或企业网络实现对Linux系统进行可视化“主机安全”管理。 一、适用对象 本文适用于个人或企业内的Linux服务器运维场景,实现免费、高效、可视化的主机安全管理。提前发现主机存在的安全风险,全方位实时监控主机运行时入侵事…...

Vite + Vue 3 前端项目实战
一、项目创建 npm install -g create-vite #安装 Vite 项目的脚手架工具 # 或者使用yarn yarn global add create-vite#创建vite项目 create-vite my-vite-project二、常用Vue项目依赖安装 npm install unplugin-auto-import unplugin-vue-components[1] 安装按需自动导入组…...

python-字符替换
[题目描述] 给出一个字符串 s 和 q 次操作,每次操作将 s 中的某一个字符a全部替换成字符b,输出 q 次操作后的字符串输入 输入共 q2 行 第一行一个字符串 s 第二行一个正整数 q,表示操作次数 之后 q 行每行“a b”表示把 s 中所有的a替换成b输…...
团队项目开发使用git工作流(IDEA)【精细】
目录 开发项目总体使用git流程 图解流程 1.创建项目仓库[组长完成] 2. 创建项目,并进行绑定远程仓库【组长完成】 3.将项目与远程仓库(gitee)进行绑定 3.1 创建本地的git仓库 3.2 将项目添加到缓存区 3.3 将项目提交到本地仓库&#…...

爬虫案例实战
文章目录 一、窗口切换实战二、京东数据抓取 一、窗口切换实战 案例实战:使用selenium实现打开百度和腾讯两个窗口并切换 知识点:用到selenium中execute_script()执行js代码及switch_to.window()方法 全部代码如下: import time import war…...
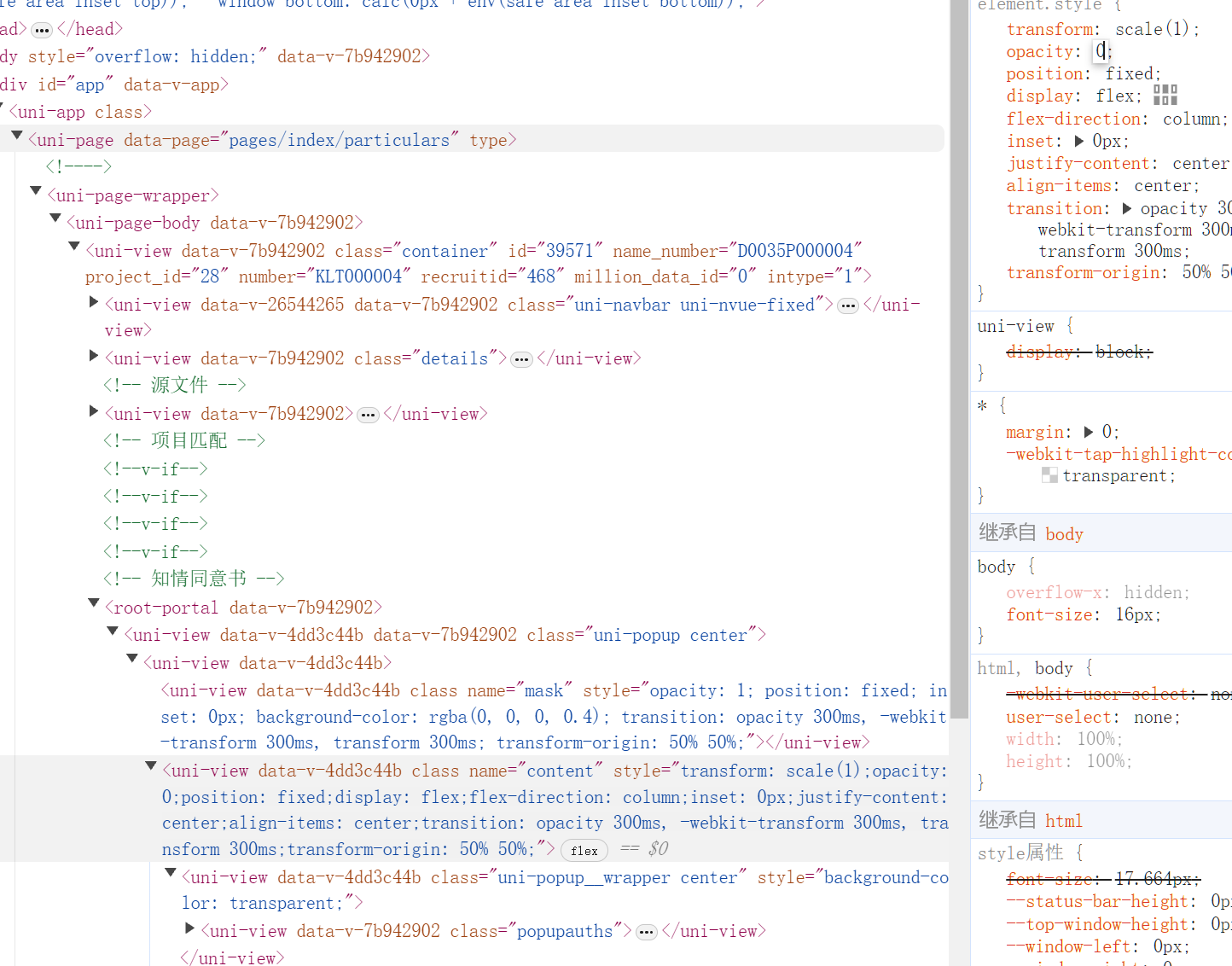
uniapp uni-popup内容被隐藏问题
今天开发新需求的时候发现uni-popup 过一会就被隐藏掉只留下遮罩(css被更改了),作者进行了如下调试。 1.讲uni-popup放入其他节点内 失败! 2.在生成dom后在打开 失败! 3.uni-popup将该节点在包裹一层 然后将统计设置样式,v-if v-s…...

leetcode155 最小栈
题目 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。void push(int val) 将元素val推入堆栈。void pop() 删除堆栈顶部的元素。int top() 获取堆栈顶部的元素。i…...
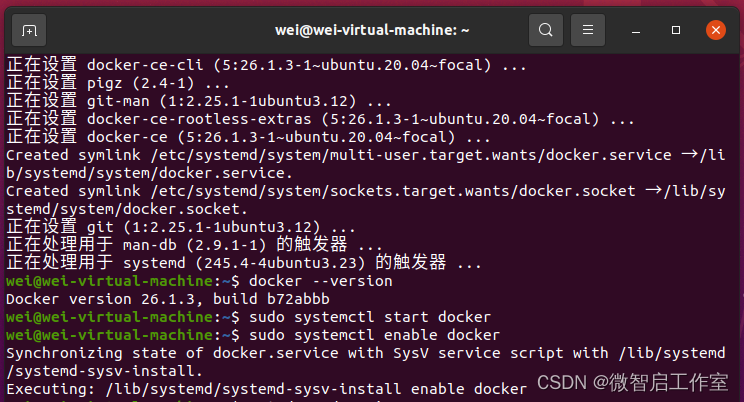
在Ubuntu乌班图上安装Docker
最近在学习乌班图相关的内容,找了一些文档安装的都是报错的,于是记录一下学习过程,希望也能帮助有缘人,首先查看乌班图的系统版本,我的是如下的: cat /proc/version以下是在Ubuntu 20.04版本上安装Docker。…...

【Redis数据库百万字详解】数据持久化
文章目录 一、持久化1.1、什么是持久化1.2、持久化方式1.3、RDB优缺点1.4、AOF优缺点 二、RDB持久化触发机制2.1、手动触发2.2、自动触发 三、RDB持久化配置3.1、配置文件3.2、配置查询/设置3.3、禁用持久化3.4、RDB文件恢复 四、RDB持久化案例4.1、手动持久化4.2、自动持久化案…...

“人工智能+”政策下,企业AI转型的机遇与路径
在“人工智能”政策的大力推动下,企业引入AI项目与产品正成为提升竞争力、实现转型提效的关键举措。对于山东地区,尤其是威海地区的企业而言,把握这一趋势,积极探索AI技术的应用,无疑是顺应时代发展的明智选择。企业引…...

Java基础实战:用快马平台快速构建学生成绩管理系统巩固核心知识
最近在复习Java基础知识,发现光看理论很容易遗忘,于是决定通过一个小项目来巩固核心概念。这个简易学生成绩管理系统虽然功能简单,但涵盖了Java基础的多个重要知识点,特别适合像我这样的初学者练手。 项目整体设计思路 首先考虑…...

从数学直觉到代码实践:Harris角点检测的算法拆解与性能调优
1. 角点检测:计算机视觉的基石 想象一下你正在玩一个拼图游戏。当两块拼图能够严丝合缝地拼接在一起时,往往是因为它们在某些关键位置完美匹配——这些位置通常是拼图块的拐角处。计算机视觉中的角点检测,本质上就是在做类似的事情࿱…...

Kandinsky-5.0-I2V-Lite-5s Web工具深度解析:非聊天页,专注图生视频的生产级界面
Kandinsky-5.0-I2V-Lite-5s Web工具深度解析:非聊天页,专注图生视频的生产级界面 1. 工具概述 Kandinsky-5.0-I2V-Lite-5s是一款专为图生视频任务设计的轻量级AI模型,它通过简洁直观的Web界面,让用户能够快速将静态图片转化为动…...

忍者像素绘卷GPU优化部署教程:双显卡加速与显存平衡详解
忍者像素绘卷GPU优化部署教程:双显卡加速与显存平衡详解 1. 认识忍者像素绘卷 忍者像素绘卷是一款基于Z-Image-Turbo深度优化的图像生成工作站,专为像素艺术创作而设计。它将16-Bit复古游戏美学与现代AI技术完美结合,为创作者提供了一个独特…...

AssetRipper终极指南:如何免费快速提取Unity游戏资源
AssetRipper终极指南:如何免费快速提取Unity游戏资源 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper AssetRipper是一款强…...

新手友好:基于快马平台快速上手dhnvr416h-hd设备数据监控开发
新手友好:基于快马平台快速上手dhnvr416h-hd设备数据监控开发 最近在做一个物联网项目,需要对接dhnvr416h-hd设备的数据监控功能。作为刚接触这个领域的新手,我发现理解设备数据格式和通信流程是最关键的第一步。好在通过InsCode(快马)平台的…...

旧Mac如何重获新生?开源工具实现系统升级完整指南
旧Mac如何重获新生?开源工具实现系统升级完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 随着苹果不断推出新的macOS版本,许多…...

MLCC陶瓷电容选型避坑指南:从X7R到C0G,5个关键参数决定电路稳定性
MLCC陶瓷电容选型避坑指南:从X7R到C0G,5个关键参数决定电路稳定性 当你在设计一个精密电源模块时,突然发现输出电压在高温环境下出现异常波动;或者调试射频电路时,明明计算无误的滤波网络却始终达不到预期效果——这些…...
)
别只刷题了!用Python/C++搞定考研机试高频算法(附PIPIOJ真题代码重构与优化)
从暴力解法到优雅实现:Python/C双语言拆解考研机试高频算法 考研机试不仅考察算法理解,更检验工程化编码能力。许多考生能写出正确但冗长的代码,却在时间优化和代码简洁性上失分。本文将用Python和C对比实现六大高频题型,重点分析…...