【动手学深度学习】卷积神经网络CNN的研究详情



目录
🌊1. 研究目的
🌊2. 研究准备
🌊3. 研究内容
🌍3.1 卷积神经网络
🌍3.2 练习
🌊4. 研究体会
🌊1. 研究目的
- 特征提取和模式识别:CNN 在计算机视觉领域被广泛用于提取图像中的特征和进行模式识别;
- 目标检测和物体识别:CNN 在目标检测和物体识别方面表现出色;
- 图像分割和语义分析:CNN 可以用于图像分割任务,即将图像分割成不同的区域或对象,并对它们进行语义分析;
- 图像生成和样式转换:CNN 还可以用于图像生成和样式转换,例如生成逼真的图像、图像风格迁移等。
🌊2. 研究准备
- 根据GPU安装pytorch版本实现GPU运行研究代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌊3. 研究内容
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch以及torch.cuda.is_available() ,若返回TRUE则说明研究环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但研究运行是在CPU进行的,结果如下:

🌍3.1 卷积神经网络
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成基本数据操作的研究代码与练习结果如下:
代码实现如下:
导入必要库及实现部分
%matplotlib inlineimport torch
from torch import nn
from d2l import torch as d2lLeNet
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape)
模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)def evaluate_accuracy_gpu(net, data_iter, device=None): #@save"""使用GPU计算模型在数据集上的精度"""if isinstance(net, nn.Module):net.eval() # 设置为评估模式if not device:device = next(iter(net.parameters())).device# 正确预测的数量,总预测的数量metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# BERT微调所需的(之后将介绍)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())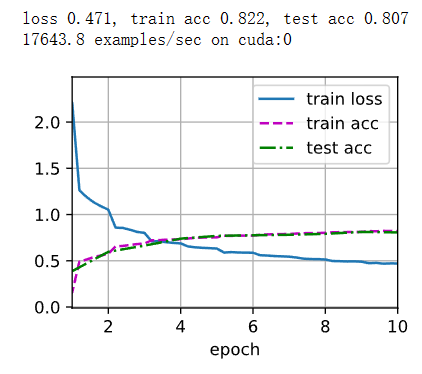
🌍3.2 练习
1.将平均汇聚层替换为最大汇聚层,会发生什么?
LeNet网络使用的是平均汇聚层(Average Pooling),将其替换为最大汇聚层(Max Pooling)会对网络的性能产生一些影响。
具体而言,将平均汇聚层替换为最大汇聚层会使网络更加注重图像中的突出特征。最大汇聚层在每个汇聚窗口中选择最大的值作为输出,而平均汇聚层则是取汇聚窗口中的平均值作为输出。因此,最大汇聚层更容易捕捉到图像中的显著特征,如边缘、纹理等。
从实验结果来看,使用最大汇聚层可能会导致网络的准确率提高。然而,这也取决于具体的数据集和任务。有时平均汇聚层在某些情况下可能更适用,因为它能够提供更平滑的特征表示。
总之,将LeNet网络中的平均汇聚层替换为最大汇聚层可能会改善网络的性能,特别是在突出图像中显著特征的任务中。但对于其他任务和数据集,可能需要进行实验和调整以确定最佳的汇聚方式。
当将LeNet网络中的平均汇聚层替换为最大汇聚层时,只需要将nn.AvgPool2d替换为nn.MaxPool2d即可。以下是修改后的代码:
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.MaxPool2d(kernel_size=2, stride=2), # 替换为最大汇聚层nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.MaxPool2d(kernel_size=2, stride=2), # 替换为最大汇聚层nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10)
)X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape: \t', X.shape)batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)def evaluate_accuracy_gpu(net, data_iter, device=None):"""使用GPU计算模型在数据集上的精度"""if isinstance(net, nn.Module):net.eval() # 设置为评估模式if not device:device = next(iter(net.parameters())).device# 正确预测的数量,总预测的数量metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# BERT微调所需的(之后将介绍)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

2.尝试构建一个基于LeNet的更复杂的网络,以提高其准确性。
2.1.调整卷积窗口大小。
import torch
from torch import nn
from d2l import torch as d2lclass ComplexLeNet(nn.Module):def __init__(self):super(ComplexLeNet, self).__init__()self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)self.relu1 = nn.ReLU()self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(6, 16, kernel_size=3, padding=1)self.relu2 = nn.ReLU()self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Conv2d(16, 32, kernel_size=3, padding=1)self.relu3 = nn.ReLU()self.maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.flatten = nn.Flatten()self.fc1 = nn.Linear(32 * 3 * 3, 120)self.relu4 = nn.ReLU()self.fc2 = nn.Linear(120, 84)self.relu5 = nn.ReLU()self.fc3 = nn.Linear(84, 10)def forward(self, x):out = self.maxpool1(self.relu1(self.conv1(x)))out = self.maxpool2(self.relu2(self.conv2(out)))out = self.maxpool3(self.relu3(self.conv3(out)))out = self.flatten(out)out = self.relu4(self.fc1(out))out = self.relu5(self.fc2(out))out = self.fc3(out)return outnet = ComplexLeNet()# 打印网络结构
print(net)
在这个网络中,增加了一个卷积层和汇聚层。第一个卷积层使用5x5的卷积窗口,第二个和第三个卷积层使用3x3的卷积窗口。这样可以增加网络的深度和复杂度,提高特征提取的能力。可以根据实际情况进一步调整网络结构和超参数,以提高准确性。
2.2.调整输出通道的数量。
import torch
from torch import nn
from d2l import torch as d2lclass ComplexLeNet(nn.Module):def __init__(self):super(ComplexLeNet, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5, padding=2)self.relu1 = nn.ReLU()self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(10, 20, kernel_size=3, padding=1)self.relu2 = nn.ReLU()self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Conv2d(20, 40, kernel_size=3, padding=1)self.relu3 = nn.ReLU()self.maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.flatten = nn.Flatten()self.fc1 = nn.Linear(40 * 3 * 3, 120)self.relu4 = nn.ReLU()self.fc2 = nn.Linear(120, 84)self.relu5 = nn.ReLU()self.fc3 = nn.Linear(84, 10)def forward(self, x):out = self.maxpool1(self.relu1(self.conv1(x)))out = self.maxpool2(self.relu2(self.conv2(out)))out = self.maxpool3(self.relu3(self.conv3(out)))out = self.flatten(out)out = self.relu4(self.fc1(out))out = self.relu5(self.fc2(out))out = self.fc3(out)return outnet = ComplexLeNet()
# 打印网络结构
print(net)
在这个示例中,我们增加了每个卷积层的输出通道数量。第一个卷积层输出10个通道,第二个卷积层输出20个通道,第三个卷积层输出40个通道。通过增加输出通道的数量,网络可以更好地捕捉和表示输入数据中的特征。你可以根据实际情况进一步调整网络结构和超参数,以提高准确性。
2.3.调整激活函数(如ReLU)。
import torch
from torch import nn
from d2l import torch as d2lclass ComplexLeNet(nn.Module):def __init__(self):super(ComplexLeNet, self).__init__()self.conv1 = nn.Conv2d(1, 6, kernel_size=5, padding=2)self.relu1 = nn.LeakyReLU()self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv2 = nn.Conv2d(6, 16, kernel_size=3, padding=1)self.relu2 = nn.LeakyReLU()self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.conv3 = nn.Conv2d(16, 32, kernel_size=3, padding=1)self.relu3 = nn.LeakyReLU()self.maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.flatten = nn.Flatten()self.fc1 = nn.Linear(32 * 3 * 3, 120)self.relu4 = nn.LeakyReLU()self.fc2 = nn.Linear(120, 84)self.relu5 = nn.LeakyReLU()self.fc3 = nn.Linear(84, 10)def forward(self, x):out = self.maxpool1(self.relu1(self.conv1(x)))out = self.maxpool2(self.relu2(self.conv2(out)))out = self.maxpool3(self.relu3(self.conv3(out)))out = self.flatten(out)out = self.relu4(self.fc1(out))out = self.relu5(self.fc2(out))out = self.fc3(out)return outnet = ComplexLeNet()
# 打印网络结构
print(net)
2.4调整卷积层的数量。
import torch
from torch import nn
from d2l import torch as d2lclass ComplexLeNet(nn.Module):def __init__(self):super(ComplexLeNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(1, 32, kernel_size=3, padding=1), # 卷积层1nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, padding=1), # 卷积层2nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # 汇聚层1nn.Conv2d(64, 128, kernel_size=3, padding=1), # 卷积层3nn.ReLU(),nn.Conv2d(128, 256, kernel_size=3, padding=1), # 卷积层4nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # 汇聚层2)self.fc = nn.Sequential(nn.Linear(256 * 7 * 7, 512), # 全连接层1nn.ReLU(),nn.Linear(512, 256), # 全连接层2nn.ReLU(),nn.Linear(256, 10) # 输出层)def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.fc(x)return x# 创建复杂LeNet模型实例
net = ComplexLeNet()# 打印网络结构
print(net)

2.5.调整全连接层的数量。
import torch
from torch import nn
from d2l import torch as d2lclass ComplexLeNet(nn.Module):def __init__(self):super(ComplexLeNet, self).__init__()self.features = nn.Sequential(nn.Conv2d(1, 32, kernel_size=3, padding=1), # 卷积层1nn.ReLU(),nn.Conv2d(32, 64, kernel_size=3, padding=1), # 卷积层2nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # 汇聚层1nn.Conv2d(64, 128, kernel_size=3, padding=1), # 卷积层3nn.ReLU(),nn.Conv2d(128, 256, kernel_size=3, padding=1), # 卷积层4nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2), # 汇聚层2)self.fc = nn.Sequential(nn.Linear(256 * 7 * 7, 512), # 全连接层1nn.ReLU(),nn.Linear(512, 256), # 全连接层2nn.ReLU(),nn.Linear(256, 128), # 全连接层3nn.ReLU(),nn.Linear(128, 10) # 输出层)def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.fc(x)return x# 创建复杂LeNet模型实例
net = ComplexLeNet()# 打印网络结构
print(net)# 训练和评估复杂LeNet模型的代码与之前的示例相似,可以根据需要进行调整

2.6.调整学习率和其他训练细节(例如,初始化和轮数)。
学习率调整为0.001。 训练轮数调整为20。 添加了权重初始化函数init_weights,使用Xavier初始化方法对线性层和卷积层的权重进行初始化。
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape)batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)def evaluate_accuracy_gpu(net, data_iter, device=None): #@save"""使用GPU计算模型在数据集上的精度"""if isinstance(net, nn.Module):net.eval() # 设置为评估模式if not device:device = next(iter(net.parameters())).device# 正确预测的数量,总预测的数量metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# BERT微调所需的(之后将介绍)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU训练模型(在第六章定义)"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,样本数metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')lr, num_epochs = 0.001, 20
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
3.在MNIST数据集上尝试以上改进的网络。
import torch
from torch import nn
from d2l import torch as d2l# 定义更复杂的LeNet网络
net = nn.Sequential(nn.Conv2d(1, 10, kernel_size=5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(10, 20, kernel_size=5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(320, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, 10)
)# 数据集加载和准备
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)# 定义训练函数
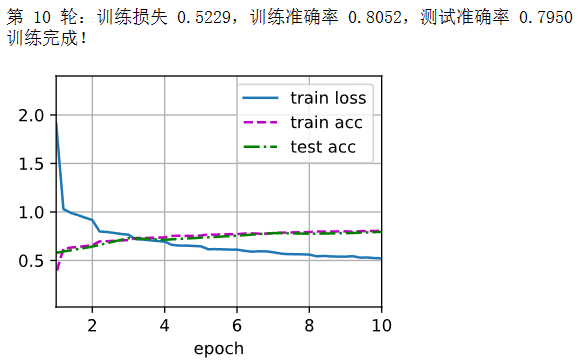
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_loss = metric[0] / metric[2]train_accuracy = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches, (train_loss, train_accuracy, None))test_accuracy = evaluate_accuracy_gpu(net, test_iter, device)animator.add(epoch + 1, (None, None, test_accuracy))print(f"第 {epoch+1} 轮:训练损失 {train_loss:.4f},训练准确率 {train_accuracy:.4f},测试准确率 {test_accuracy:.4f}")print("训练完成!")# 模型训练
lr, num_epochs = 0.01, 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_ch6(net, train_iter, test_iter, num_epochs, lr, device)
4.显示不同输入(例如毛衣和外套)时,LeNet第一层和第二层的激活值。
import torch
from torch import nn
from d2l import torch as d2l# 定义LeNet网络
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120),nn.Sigmoid(),nn.Linear(120, 84),nn.Sigmoid(),nn.Linear(84, 10)
)# 加载Fashion-MNIST数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)# 获取一个样本的输入数据
data = next(iter(test_iter))
X = data[0][:16] # 选择前16个样本进行展示# 计算第一层和第二层的激活值
activation1 = net[0](X)
activation2 = net[3](net[2](net[0](X)))# 打印激活值
print("第一层的激活值:", activation1.shape)
print("第二层的激活值:", activation2.shape)
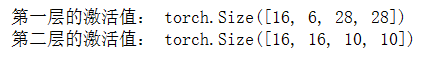
上述代码将打印LeNet网络的第一层和第二层的激活值的形状。可以通过调整X的选择来查看不同样本 的激活值。这里选择了测试集中的样本作为示例输入。
🌊4. 研究体会
通过这次课程的实验,我深入学习了卷积神经网络,通过使用Python和MXNet深度学习框架进行实验,对CNN的工作原理和实际应用有了更加深入的理解。以下是我在实验过程中的一些心得体会。
首先卷积层是CNN的核心组件之一,它能够有效地捕捉图像中的局部特征。在实验中,通过调整卷积核的大小和数量,探索了不同的特征提取方式。发现较小的卷积核可以捕捉到更细粒度的特征,而较大的卷积核则可以捕捉到更宏观的特征。此外,增加卷积核的数量可以提高模型的表达能力,但也会增加计算复杂度。
其次,池化层是CNN中另一个重要的组件,它可以减小特征图的尺寸,同时保留主要特征。在实验中,我尝试了最大池化和平均池化等不同的池化方式,并观察它们对模型性能的影响。发现最大池化能够更好地保留图像中的主要特征,并在一定程度上提高了模型的鲁棒性。
此外,我还学习了卷积神经网络中的一些关键技术,如批量归一化(Batch Normalization)和残差连接(Residual Connection)。批量归一化可以加速网络的训练过程,并提高模型的稳定性;而残差连接则可以解决深层网络中的梯度消失问题,有效提高了模型的准确性。在实验中,我应用了这些技术,并发现它们确实能够改善模型的性能。
在实验过程中,我深刻认识到CNN模型在处理图像数据时具有出色的特征提取和表示能力。通过卷积层和池化层的组合,模型能够有效地捕捉图像的局部和全局特征,并通过堆叠多个卷积层来提取更高级的特征。同时,卷积神经网络的参数共享和局部感受野的设计赋予它良好的平移不变性和空间层次性,使其非常适合处理具有空间结构的图像数据。
通过这次实验,我不仅加深了对CNN的理论理解,还学会了如何将理论知识应用于实际项目中。我通过编写代码、训练模型和分析结果,逐步掌握了CNN的实际操作技巧。

相关文章:
【动手学深度学习】卷积神经网络CNN的研究详情
目录 🌊1. 研究目的 🌊2. 研究准备 🌊3. 研究内容 🌍3.1 卷积神经网络 🌍3.2 练习 🌊4. 研究体会 🌊1. 研究目的 特征提取和模式识别:CNN 在计算机视觉领域被广泛用于提取图像…...

2024年数字化经济与智慧金融国际会议(ICDESF 2024)
2024 International Conference on Digital Economy and Smart Finance 【1】大会信息 大会时间:2024-07-22 大会地点:中国成都 截稿时间:2024-07-10(以官网为准) 审稿通知:投稿后2-3日内通知 会议官网:h…...
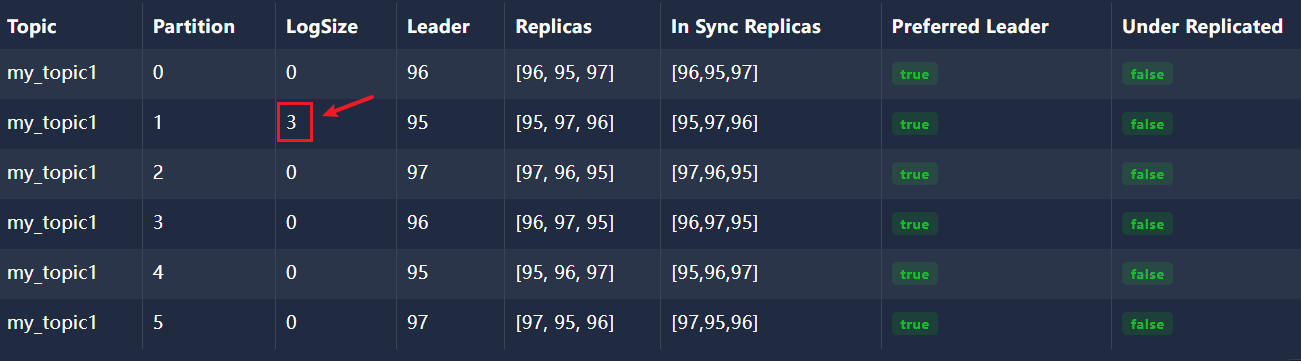
kafka-消费者服务搭建配置简单消费(SpringBoot整合Kafka)
文章目录 1、使用efak 创建 主题 my_topic1 并建立6个分区并给每个分区建立3个副本2、创建生产者发送消息3、application.yml配置4、创建消费者监听器5、创建SpringBoot启动类6、屏蔽 kafka debug 日志 logback.xml7、引入spring-kafka依赖 1、使用efak 创建 主题 my_topic1 并…...

C++STL---list常见用法
C STL中的list list是C标准模板库(STL)中的一个序列容器,它实现了一个双向链表。与vector和deque相比,list支持快速的任意位置插入和删除操作,但不支持快速随机访问。 基本操作 创建和初始化 #include <list> …...
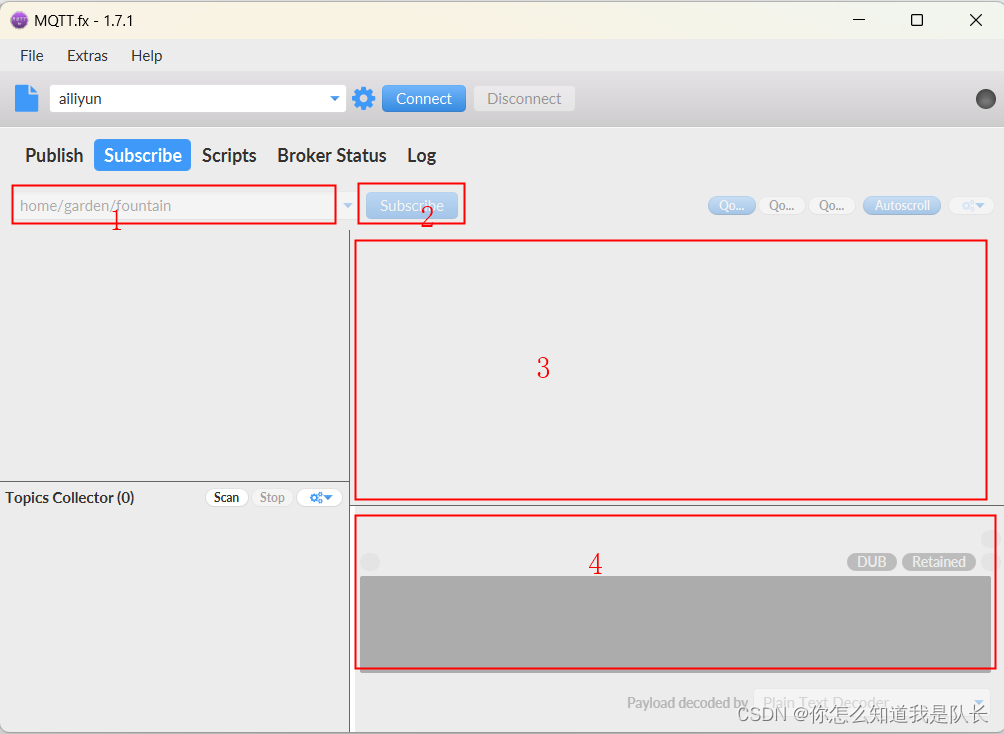
MQTT.FX的使用
背景 在如今物联网的时代下,诞生了许多的物联网产品,这些产品通过BLE、WIFI、4G等各种各样的通信方式讲数据传输到各种各样的平台。 除了各个公司私有的云平台外,更多的初学者会接触到腾讯云、阿里云之类的平台。设备接入方式也有着多种多样…...

SRS、ZLMediakit音视频流媒体服务器
SRS、ZLMediakit都是做为webrtc的SFU(selective forward unit) WebRTC 开发实践:为什么你需要 SFU 服务器 https://mp.weixin.qq.com/s?__bizMzAxNTc1MjM0Mw&mid2652213442&idx1&sn33f0393a2dbc2b6a39c613bb238ec145&chksm…...

大模型Prompt-Tuning技术进阶
LLM的Prompt-Tuning主流方法 面向超大规模模型的Prompt-Tuning 近两年来,随之Prompt-Tuning技术的发展,有诸多工作发现,对于超过10亿参数量的模型来说,Prompt-Tuning所带来的增益远远高于标准的Fine-tuning,小样本甚至…...

统一响应,自定义校验器,自定义异常,统一异常处理器
文章目录 1.基本准备(构建一个SpringBoot模块)1.在A_universal_solution模块下创建新的子模块unified-processing2.pom.xml引入基本依赖3.编写springboot启动类4.启动测试 2.统一响应处理1.首先定义一个响应枚举类 RespBeanEnum.java 每个枚举对象都有co…...

完整状态码面试背
{"100": "继续","101": "切换协议","102": "处理中","103": "早期提示","200": "成功","201": "已创建","202": "已接受",&qu…...
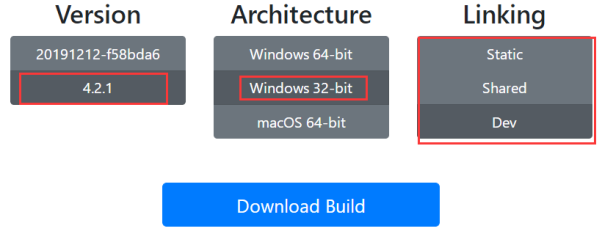
QT+FFmpeg+Windows开发环境搭建(加薪点)
01、Windows 环境搭建 FFMPEG官网:http://ffmpeg.org/ 02、下载4.2.1版本源码 源码:https://ffmpeg.org/releases/ffmpeg-4.2.1.tar.bz2 03、下载4.2.1编译好的文件 下载已经编译好的FFMPEG)(迅雷下载很快) 网址:https://ffmpeg.zeranoe.com/builds/ 32位下载地址:(迅雷…...

Linux 主机一键安全整改策略
为防止linux主机被恶意攻击,和受到攻击后能更快定位到源头,需要对linux主机做一些参数配置。 比如禁用root的远程登录、用户多次密码验证失败后被锁、禁止系统账号交互式登录等等。 下面是linux主机安全整改的一些简单介绍,最后会通过脚本一…...

Hot100——二叉树
树的定义: public static class TreeNode{int val;TreeNode left;TreeNode right;TreeNode(){};TreeNode(int val){ this.val val; };TreeNode(int val, TreeNode left, TreeNode right){this.val val;this.left left;this.right right;}} 深度优先遍历&#x…...

C++ static_cast、dynamic_cast、const_cast 和 reinterpret_cast 用处和区别
在 C 中,static_cast、dynamic_cast、const_cast 和 reinterpret_cast 是四种类型转换运算符,它们各自有不同的用途和行为: static_cast 用于编译时已知类型的转换,如基本数据类型转换、派生类到基类的转换、指针和引用的转换等…...
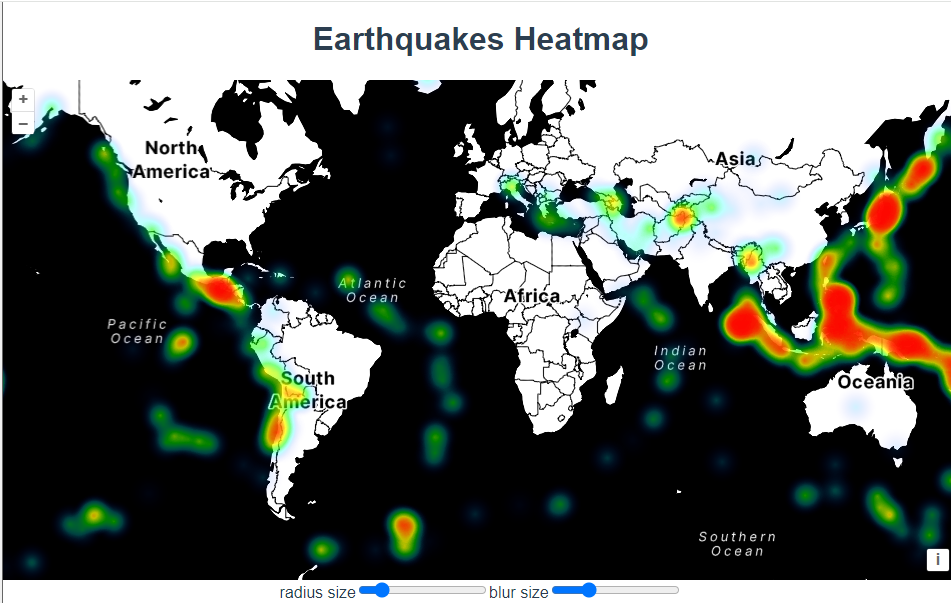
三十七、openlayers官网示例Earthquakes Heatmap解析——在地图上加载热力图
官网demo地址: Earthquakes Heatmap 这篇主要介绍了热力图HeatmapLayer HeatmapLayer 是一个用于在地图上显示热力图的图层类型,通常用于表示地理数据中的密度或强度。例如,它可以用来显示地震、人口密度或其他空间数据的热点区域。在这个示…...

curl 92 HTTP/2 stream 5 was not closed cleanly: CANCEL
source ~/.bash_profile flutter clean Command exited with code 128: git fetch --tags Standard error: 错误:RPC 失败。curl 92 HTTP/2 stream 5 was not closed cleanly: CANCEL (err 8) 错误:预期仍然需要 2737 个字节的正文 fetch-pack: unexpec…...
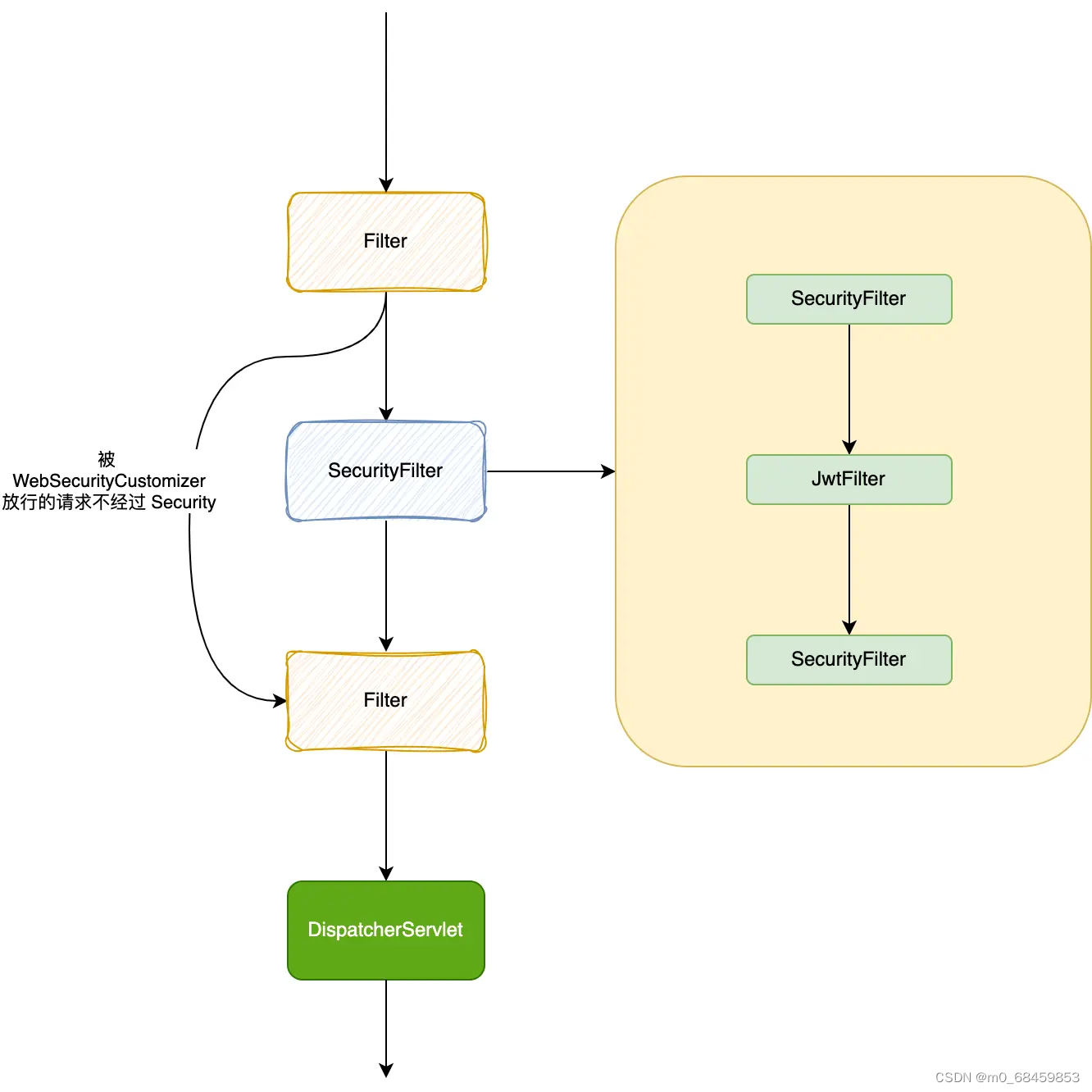
Spring Security 注册过滤器关键点与最佳实践
在 Spring Security 框架中,注册过滤器是实现身份验证和授权的关键组件。正确配置和使用注册过滤器对于确保应用程序的安全性至关重要。以下是一些关于 Spring Security 注册过滤器的注意事项和最佳实践。 过滤器链顺序: 注册过滤器通常位于过滤器链的末…...

力扣2024.考试的最大困扰度
力扣2024.考试的最大困扰度 注意同时>k才处理 class Solution {public:int maxConsecutiveAnswers(string answerKey, int k) {int n answerKey.size(),res0;unordered_map<int,int> cnt;for(int i0,j0;i<n;i){cnt[answerKey[i] - a] ;while(cnt[T - a] > k …...

java配置文件解析yml/xml/properties文件
XML 以mybatis.xml:获取所有Environment中的数据库并连接session为例 import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException;import javax.xml.parsers.DocumentBuilder; impo…...
grpc接口调用
grpc接口调用 准备依赖包clientserver 参考博客: Grpc项目集成到java方式调用实践 gRpc入门和springboot整合 java 中使用grpc java调用grpc服务 准备 因为需要生成代码,所以必备插件 安装后重启 依赖包 <?xml version"1.0" encoding&…...
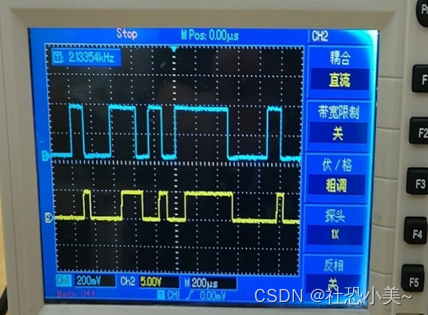
通信技术振幅键控(ASK)调制与解调硬件实验
一、实验目的 1. 掌握用键控法产生ASK信号的方法; 2. 掌握ASK非相干解调的原理。 二、实验内容 1. 观察ASK已调信号的波形; 2. 观察ASK解调信号的波形。 三、实验器材 1. 双踪示波器; 2. 通信原理实验箱信号源模块、③、④、⑦号模块。…...
并生成.bin)
STM32CubeMX实战:10分钟为你的G474项目配置双区IAP(Boot+App)并生成.bin
STM32CubeMX实战:10分钟为G474项目配置双区IAP(BootApp)并生成.bin 在嵌入式开发中,IAP(在应用编程)技术是实现设备固件远程升级的核心方案。对于STM32开发者而言,传统手动配置IAP往往涉及繁琐…...

CosyVoice多语言语音合成实测:中英文混合文本生成,自然流畅
CosyVoice多语言语音合成实测:中英文混合文本生成,自然流畅 1. 测试环境与模型介绍 1.1 测试硬件配置 本次测试使用的硬件环境如下: 组件规格GPUNVIDIA RTX 4090 (24GB)CPUIntel i9-13900K内存64GB DDR5操作系统Ubuntu 22.04 LTS 1.2 Co…...

学生项目福音:AI超清画质增强快速入门,WebUI界面开箱即用
学生项目福音:AI超清画质增强快速入门,WebUI界面开箱即用 1. 为什么你需要AI画质增强技术 1.1 低清图像的普遍困扰 作为学生开发者,你可能经常遇到这样的场景:课程项目需要展示清晰的图片素材,但手头只有模糊的截图…...

DAMO-YOLO目标检测环境搭建DAMO-YOLO数据集代训练DAMO-YOLO代码改进更新可搭建windows系统和ubuntu系统的环境,搭建完直接可用可训练任意目标检测的coco格式数
DAMO-YOLO目标检测环境搭建 DAMO-YOLO数据集代训练 DAMO-YOLO代码改进更新 可搭建windows系统和ubuntu系统的环境,搭建完直接可用 可训练任意目标检测的coco格式数据集,你提供数据集,反馈训练结果和模型测试值 有需要可私聊...

3个突破式方法破解NCM加密:让音乐收藏在全设备自由流转
3个突破式方法破解NCM加密:让音乐收藏在全设备自由流转 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 当你精心收藏的网易云音乐下载到本地却发现是无法播放的NCM格式,当车载音响无法识别手机里的加密音乐文…...

OpenClaw隐私计算:千问3.5-9B处理加密数据技巧
OpenClaw隐私计算:千问3.5-9B处理加密数据技巧 1. 为什么需要加密数据自动化处理 作为金融行业的技术从业者,我经常需要处理包含客户信息的Excel报表和PDF合同。这些文件既需要被分析处理,又必须满足严格的合规要求——原始数据不能以明文形…...

Goldpinger完全指南:如何实时可视化Kubernetes节点间网络连接
Goldpinger完全指南:如何实时可视化Kubernetes节点间网络连接 【免费下载链接】goldpinger Debugging tool for Kubernetes which tests and displays connectivity between nodes in the cluster. 项目地址: https://gitcode.com/gh_mirrors/go/goldpinger …...

Linux基础之目录结构
初学Linux,首先需要弄清Linux 标准目录结构 / root — 启动Linux时使用的一些核心文件。如操作系统内核、引导程序Grub等。home — 存储普通用户的个人文件 ftp — 用户所有服务httpdsambauser1user2 bin — 系统启动时需要的执行文件(二进制…...

智能开门柜自动售货机哪里生产
当你考虑引入一台智能开门柜自动售货机时,脑海中浮现的第一个问题往往是:“这东西,哪里生产的靠谱?”这背后,是对设备质量、技术稳定性和长期服务的深度关切。今天,我们就来深入剖析智能开门柜的生产格局&a…...

2025 ICPC武汉邀请赛 G [根号分治 容斥原理+DP]
Problem - G - Codeforces 观察题目,我们可以用贡献法, 计算每个格子的贡献,然后累加起来,对于重复的部分我们要减去 1.路径数量 首先,计算两个位置间有多少种路径互通,我们可以利用组合数进行计算&#x…...